增量qq数据库查询
qq数据库查询 时间:2021-04-19 阅读:()
云享家|"别了XX",不能别了你的数据库!
在全民业务上云的今天,数据库这个大后方作为业务和应用支撑的弹药库,重要性就不言而喻了.
然而数据库迁移的正确姿势,你真的Get了么yugong(意译:愚公)项目是阿里的开源项目,该项目使用纯Java开发,主要作用是进行数据库迁移,目前该项目主要支持从oracle数据库向Mysql和DRDS数据库进行迁移.
本期的"云享家"将为您解析Oracle在线迁移云平台的具体技术细节.
环境要求操作系统a.
纯java开发,有bat和shell脚本,windows/linux均可支持.
b.
jdk建议使用1.
6.
25以上的版本,稳定可靠,目前阿里巴巴使用基本为此版本.
数据库a.
源库为Oracle,目标库可为mysql/drds/Oracle.
基于标准jdbc协议开发,对数据库暂无版本要求.
需要的数据库账户权限:1.
源库(oracle)GRANTSELECT,INSERT,UPDATE,DELETEONXXXTOXXX;#常见CRUD权限GRANTCREATEANYMATERIALIZEDVIEWTOXXX;GRANTDROPANYMATERIALIZEDVIEWTOXXX;BespinGlobalBespinGlobalhttps://mp.
weixin.
qq.
com/s__biz=MzIxMDczMTkwNg==&mid=22.
.
.
第1页共11页2018/12/1417:442.
目标库(mysql/oracle)GRANTSELECT,INSERT,UPDATE,DELETEONXXXTOXXX;项目介绍整个迁移方案,分为两部分:全量迁移1.
增量迁移2.
过程描述:增量数据收集(创建oracle表的增量物化视图)1.
进行全量复制2.
进行增量复制(并行进行数据校验)3.
原库停写,切到新库4.
架构1.
一个JvmContainer对应多个instance,每个instance对应于一张表的迁移任务2.
instance分为三部分-extractor(从源数据库上提取数据,可分为全量/增量实现)-translator(将源库上的数据按照目标库的需求进行自定义转化)-applier(将数据更新到目标库,可分为全量/增量/对比的实现)部署下载github地址:https://github.
com/alibaba/yugongBespinGlobalhttps://mp.
weixin.
qq.
com/s__biz=MzIxMDczMTkwNg==&mid=22.
.
.
第2页共11页2018/12/1417:44gitclonehttps://github.
com/alibaba/yugong.
git目录结构解压缩发布包后,可得如下目录结构:drwxr-xr-x2rootroot4096Jun2915:32bindrwxr-xr-x4rootroot4096Jun2915:23confdrwxr-xr-x2rootroot4096Jun1915:06lib-rw-r--r--1rootroot18045Mar22016LICENSEdrwxrwxrwx4rootroot4096Jun2915:10logs-rw-r--r--1rootroot3767Mar52016README.
md配置文件说明默认值参数名字参数说明默认值数据库配置相关yugong.
database.
source.
usernameyugong.
database.
source.
passwordyugong.
database.
source.
typeyugong.
database.
source.
urlyugong.
database.
source.
encode源数据库的相关账户和链接信息driverurl示例:1.
ORACLE:jdbc:oracle:thin:@10.
20.
144.
29:1521:ointest2.
MYSQL:jdbc:mysql://10.
20.
144.
34:3306/testencode默认为UTF-8,其他无默认值yugong.
database.
target.
usernameyugong.
database.
target.
passwordyugong.
database.
target.
typeyugong.
database.
target.
urlyugong.
database.
target.
目标数据库的相关账户和链接信息encode默认为UTF-8,其他无默认值BespinGlobalhttps://mp.
weixin.
qq.
com/s__biz=MzIxMDczMTkwNg==&mid=22.
.
.
第3页共11页2018/12/1417:44encodeyugong.
table.
white需要同步表,白名单,定义需要同步的表几点说明:1.
表名支持like匹配,比如'%'匹配一个或者多个字符,下划线'_'匹配单个字符,可以通过单斜杠\进行转义符定义.
2.
表明为schema+tablename组成,多个表可加逗号分隔3.
如果白名单为空,代表整个库所有表,否则按指定的表进行同步例子:1.
yugong_example_%(可以匹配yugong_example打头的字符串)2.
alibaba.
yugong_example_test_(可以匹配alibaba.
yugong_example_test1/alibaba.
yugong_example_test2)无yugong.
table.
black需要同步表,黑名单,需要忽略同步的表配置方式可参考yugong.
table.
white无yugong.
table.
mode运行模式,目前支持的模式为:1.
MARK(开启增量记录,比如oracle就是创建物化视图)2.
FULL(全量模式)3.
INC(增量模式)4.
ALL(自动全量+增量模式)5.
CHECK(数据对比模式)6.
CLEAR(清理增量记录,比如ora无BespinGlobalhttps://mp.
weixin.
qq.
com/s__biz=MzIxMDczMTkwNg==&mid=22.
.
.
第4页共11页2018/12/1417:44cle就是删除物化视图)yugong.
table.
concurrent.
enable多张表之前是否开启并行处理,如果false代表需要串行处理trueyugong.
table.
concurrent.
size允许并行处理的表数5yugong.
table.
retry.
times表同步出错后的重试次数3yugong.
table.
retry.
interval表同步出错后的重试时的时间间隔,单位ms1000yugong.
table.
batchApply是否开启jdbcbatch处理trueyugong.
table.
onceCrawNumextractor/applier每个批次最多处理记录数1000yugong.
table.
tpslimittps限制,0代表不限制0yugong.
table.
ignoreSchema是否忽略schema同步(如果mysql和oracle对应的schema不同,可设置为true)falseyugong.
table.
skipApplierExceptiontrue代表当applier出现数据库异常时,比如约束键冲突,可对单条出异常的数据进行忽略.
同时记录skipedrecorddata信息,日志中包含record的所有列信息,包括主键.
falseextractor配置相关yugong.
extractor.
dump是否记录extractor提取到的所有数据falseyugong.
extractor.
concurrent.
enableextractor是否开启并行处理,目前主要应用为增量模式反查源表trueyugong.
extractor.
concurrent.
globalextractor是启用全局线程池模式,如果true代表所有extractor任务都使用一组线程池,线程池大小由concurrent.
size控制falseBespinGlobalhttps://mp.
weixin.
qq.
com/s__biz=MzIxMDczMTkwNg==&mid=22.
.
.
第5页共11页2018/12/1417:44查看日志对应日志结构为:全量完成的日志:(会在yugong/table.
log和${table}/table.
log中出现记录)table[OTTER2.
TEST_ALL_ONE_PK]isend!
增量日志:(会在${table}/table.
log中出现记录)ALL(全量+增量)模式日志:(会在${table}/table.
log中出现记录)CHECK日志:(会在${table}/check.
log中出现diff记录)BespinGlobalhttps://mp.
weixin.
qq.
com/s__biz=MzIxMDczMTkwNg==&mid=22.
.
.
第6页共11页2018/12/1417:44同步过程数据日志:会通过extractor.
log/applier.
log分别记录extractor和applier的数据记录,因为有DataTranslator的存在,两者记录可能不一致,所以分开两份记录.
统计信息:-progress统计,会在主日志下,输出当前全量/增量/异常表的数据,可通过该日志,全局把握整个迁移任务的进度,输出类似:{未启动:0,全量中:2,增量中:3,已追上:3,异常数:0}-stat统计,会在每个表迁移日志下,输出当前迁移的tps信息{总记录数:180000,采样记录数:5000,同步TPS:4681,最长时间:215,最小时间:212,平均时间:213}切换流程1.
当任务处于追上状态时候,表示已经处于实时同步状态2.
后续通过源数据库进行停写,稍等1-2分钟后(保证延时的数据最终得到同步,此时源库和目标库当前数据是完全一致的)3.
检查增量持续处于NO_UPDATE状态,可关闭该迁移任务(shstop.
sh),即可发布新程序,使用新的数据库,完成切换的流程.
自定义数据转换如果要迁移的oracle和mysql的表结构不同,比如表名,字段名有差异,字段类型不兼容,需要使用自定义数据转换.
如果完全相同那就可以跳过此章节整个数据流为:DB->Extractor->DataTranslator->Applier->DB,本程序预留DataTranslator接口,允许外部用户自定义数据处理逻辑,比如:1.
表名不同2.
字段名不同3.
字段类型不同4.
字段个数不同运行过程join其他表的数据做计算等.
BespinGlobalhttps://mp.
weixin.
qq.
com/s__biz=MzIxMDczMTkwNg==&mid=22.
.
.
第7页共11页2018/12/1417:44举例/***一个迁移的例子,涵盖一些基本转换操作***例子包含特性:*1.
schema/table名不同.
oracle中为otter2.
yugong_example_oracle,mysql中为test.
yugong_example_mysql*2.
字段名字不同.
oracle中的name字段,映射到mysql的display_name*3.
字段逻辑处理.
mysql的display_name字段数据来源为oracle库的:name+'('alias_name+')'*4.
字段类型不同.
oracle中的amount为number类型,映射到mysql的amount为varchar文本型*5.
源库多一个字段.
oracle中多了一个alias_name字段*6.
目标库多了一个字段.
mysql中多了一个gmt_move字段,(简单的用迁移时的当前时间进行填充)**测试的表结构:*//oracle表*createtableotter2.
yugong_example_oracle*(*idNUMBER(11),*namevarchar2(32),*alias_namechar(32)default''notnull,*amountnumber(11,2),*scorenumber(20),*text_bblob,*text_cclob,*gmt_createdatenotnull,*gmt_modifieddatenotnull,*CONSTRAINTyugong_example_oracle_pk_idPRIMARYKEY(id)*);**//mysql表*createtabletest.
yugong_example_mysql*(*idbigint(20)unsignedauto_increment,BespinGlobalhttps://mp.
weixin.
qq.
com/s__biz=MzIxMDczMTkwNg==&mid=22.
.
.
第8页共11页2018/12/1417:44*display_namevarchar(128),*amountvarchar(32),*scorebigint(20)unsigned,*text_bblob,*text_ctext,*gmt_createtimestampnotnull,*gmt_modifiedtimestampnotnull,*gmt_movetimestampnotnull,*CONSTRAINTyugong_example_mysql_pk_idPRIMARYKEY(id)*);***/publicclassYugongExampleOracleDataTranslatorextendsAbstractDataTranslatorimplementsDataTranslator{publicbooleantranslator(Recordrecord){//1.
schema/table名不同//record.
setSchemaName("test");record.
setTableName("yugong_example_mysql");if(recordinstanceofIncrementRecord){if(IncrementOpType.
D==((IncrementRecord)record).
getOpType()){//忽略deletereturnsuper.
translator(record);}}//2.
字段名字不同ColumnValuenameColumn=record.
getColumnByName("name");nameColumn.
getColumn().
setName("display_name");//3.
字段逻辑处理ColumnValuealiasNameColumn=record.
getColumnByName("alias_name");StringBuilderdisplayNameValue=newStringBuilder(64);displayNameValue.
append(ObjectUtils.
toString(nameColumn.
getValue())).
append('(').
append(ObjectUtils.
toString(aliasNameColumn.
getValue())).
append(')');nameColumn.
setValue(displayNameValue.
toString());//4.
字段类型不同BespinGlobalhttps://mp.
weixin.
qq.
com/s__biz=MzIxMDczMTkwNg==&mid=22.
.
.
第9页共11页2018/12/1417:44ColumnValueamountColumn=record.
getColumnByName("amount");amountColumn.
getColumn().
setType(Types.
VARCHAR);amountColumn.
setValue(ObjectUtils.
toString(amountColumn.
getValue()));//5.
源库多一个字段record.
getColumns().
remove(aliasNameColumn);//6.
目标库多了一个字段ColumnMetagmtMoveMeta=newColumnMeta("gmt_move",Types.
TIMESTAMP);ColumnValuegmtMoveColumn=newColumnValue(gmtMoveMeta,newDate());record.
addColumn(gmtMoveColumn);//ColumnValuetext_c=record.
getColumnByName("text_c");//try{//text_c.
setValue(newString((byte[])text_c.
getValue(),"GBK"));//}catch(UnsupportedEncodingExceptione){//e.
printStackTrace();//}returnsuper.
translator(record);}}运行模式详细介绍MARK模式(MARK)开启增量日志的记录,如果是oracle就是创建物化视图.
CLEAR模式(CLEAR)清理增量日志的记录,如果是oracle就是删除物化视图.
全量模式(FULL)全量模式,顾名思议即为对源表进行一次全量操作,遍历源表所有的数据后,插入目标表.
全量有两种处理方式:1.
分页处理:如果源表存在主键,只有一个主键字段,并且主键字段类型为Number类型,默认会选择该分页处理模式.
优点:支持断点续做,对源库压力相对较小.
缺点:迁移速度慢2.
once处理:通过select*from访问整个源表的某一个mvcc版本的数据,通过cursor.
next遍历整个结果集.
优点:迁移速度快,为分页处理的5倍左右.
缺点:源库压力大,如果源库并发修改量大,会导致数据库MVCC版本过多,出现栈错误.
还有就是不支持断点续做.
特别注意如果全量模式运行过程中,源库有变化时,不能保证源库最近变化的数据能同步到目标表,这时需要配合增量模式.
具体操作就是:在运行全量模式之前,先开启增量模式的记录日志功能,然后BespinGlobalhttps://mp.
weixin.
qq.
com/s__biz=MzIxMDczMTkwNg==&mid=22.
.
.
第10页共11页2018/12/1417:44阅读原文开启全量模式,完成后,再将最近变化的数据通过增量模式同步到目标表.
增量模式(INC)全量模式,顾名思议即为对源表增量变化的数据插入目标表,增量模式依赖记录日志功能.
目前增量模式的记录日志功能,是通过oracle的物化视图功能.
创建物化视图.
CREATEMATERIALIZEDVIEWLOGON${tableName}withprimarykey.
·运行增量模式之前,需要先开启记录日志的功能,即预先创建物化视图.
特别是配合全量模式时,创建物化视图的时间点要早于运行全量之前,这样才可以保证数据能全部同步到目标表·增量模式没有完成的概念,它只有追上的概念,具体的停止需有业务进行判断,可以看一下切换流程.
自动模式(ALL)自动模式,是对全量+增量模式的一种组合,自动化运行,减少操作成本.
自动模式的内部实现步骤:1.
开启记录日志功能.
(创建物化视图)2.
运行全量同步模式.
(全量完成后,自动进入下一步)3.
运行增量同步模式.
(增量模式,没有完成的概念,所以也就不会自动退出,需要业务判断是否可以退出,可以看一下切换流程)对比模式(CHECK)对比模式,即为对源库和目标库的数据进行一次全量对比,验证一下迁移结果.
对比模式为一种可选运行,做完全量/增量/自动模式后,可选择性的运行对比模式,来确保本次迁移的正确性.
愚公项目是在阿里去IOE的过程中诞生,其要解决的目标就是帮助用户完成从Oracle数据迁移到MySQL上.
是后续的DTS工具重要组成部分.
经过生产系统的验证,是一种可靠的数据库迁移工具.
关键在于其支持的增量的方式的迁移,能够在数据上云的过程中减少大量的停机时间.
数据库的迁移不仅是数据迁移,包含的更多技术细节问题.
BespinGlobal能够提供大量的数据库迁移的技术支持.
更多详情阅读原文BespinGlobalhttps://mp.
weixin.
qq.
com/s__biz=MzIxMDczMTkwNg==&mid=22.
.
.
第11页共11页2018/12/1417:44
在全民业务上云的今天,数据库这个大后方作为业务和应用支撑的弹药库,重要性就不言而喻了.
然而数据库迁移的正确姿势,你真的Get了么yugong(意译:愚公)项目是阿里的开源项目,该项目使用纯Java开发,主要作用是进行数据库迁移,目前该项目主要支持从oracle数据库向Mysql和DRDS数据库进行迁移.
本期的"云享家"将为您解析Oracle在线迁移云平台的具体技术细节.
环境要求操作系统a.
纯java开发,有bat和shell脚本,windows/linux均可支持.
b.
jdk建议使用1.
6.
25以上的版本,稳定可靠,目前阿里巴巴使用基本为此版本.
数据库a.
源库为Oracle,目标库可为mysql/drds/Oracle.
基于标准jdbc协议开发,对数据库暂无版本要求.
需要的数据库账户权限:1.
源库(oracle)GRANTSELECT,INSERT,UPDATE,DELETEONXXXTOXXX;#常见CRUD权限GRANTCREATEANYMATERIALIZEDVIEWTOXXX;GRANTDROPANYMATERIALIZEDVIEWTOXXX;BespinGlobalBespinGlobalhttps://mp.
weixin.
qq.
com/s__biz=MzIxMDczMTkwNg==&mid=22.
.
.
第1页共11页2018/12/1417:442.
目标库(mysql/oracle)GRANTSELECT,INSERT,UPDATE,DELETEONXXXTOXXX;项目介绍整个迁移方案,分为两部分:全量迁移1.
增量迁移2.
过程描述:增量数据收集(创建oracle表的增量物化视图)1.
进行全量复制2.
进行增量复制(并行进行数据校验)3.
原库停写,切到新库4.
架构1.
一个JvmContainer对应多个instance,每个instance对应于一张表的迁移任务2.
instance分为三部分-extractor(从源数据库上提取数据,可分为全量/增量实现)-translator(将源库上的数据按照目标库的需求进行自定义转化)-applier(将数据更新到目标库,可分为全量/增量/对比的实现)部署下载github地址:https://github.
com/alibaba/yugongBespinGlobalhttps://mp.
weixin.
qq.
com/s__biz=MzIxMDczMTkwNg==&mid=22.
.
.
第2页共11页2018/12/1417:44gitclonehttps://github.
com/alibaba/yugong.
git目录结构解压缩发布包后,可得如下目录结构:drwxr-xr-x2rootroot4096Jun2915:32bindrwxr-xr-x4rootroot4096Jun2915:23confdrwxr-xr-x2rootroot4096Jun1915:06lib-rw-r--r--1rootroot18045Mar22016LICENSEdrwxrwxrwx4rootroot4096Jun2915:10logs-rw-r--r--1rootroot3767Mar52016README.
md配置文件说明默认值参数名字参数说明默认值数据库配置相关yugong.
database.
source.
usernameyugong.
database.
source.
passwordyugong.
database.
source.
typeyugong.
database.
source.
urlyugong.
database.
source.
encode源数据库的相关账户和链接信息driverurl示例:1.
ORACLE:jdbc:oracle:thin:@10.
20.
144.
29:1521:ointest2.
MYSQL:jdbc:mysql://10.
20.
144.
34:3306/testencode默认为UTF-8,其他无默认值yugong.
database.
target.
usernameyugong.
database.
target.
passwordyugong.
database.
target.
typeyugong.
database.
target.
urlyugong.
database.
target.
目标数据库的相关账户和链接信息encode默认为UTF-8,其他无默认值BespinGlobalhttps://mp.
weixin.
qq.
com/s__biz=MzIxMDczMTkwNg==&mid=22.
.
.
第3页共11页2018/12/1417:44encodeyugong.
table.
white需要同步表,白名单,定义需要同步的表几点说明:1.
表名支持like匹配,比如'%'匹配一个或者多个字符,下划线'_'匹配单个字符,可以通过单斜杠\进行转义符定义.
2.
表明为schema+tablename组成,多个表可加逗号分隔3.
如果白名单为空,代表整个库所有表,否则按指定的表进行同步例子:1.
yugong_example_%(可以匹配yugong_example打头的字符串)2.
alibaba.
yugong_example_test_(可以匹配alibaba.
yugong_example_test1/alibaba.
yugong_example_test2)无yugong.
table.
black需要同步表,黑名单,需要忽略同步的表配置方式可参考yugong.
table.
white无yugong.
table.
mode运行模式,目前支持的模式为:1.
MARK(开启增量记录,比如oracle就是创建物化视图)2.
FULL(全量模式)3.
INC(增量模式)4.
ALL(自动全量+增量模式)5.
CHECK(数据对比模式)6.
CLEAR(清理增量记录,比如ora无BespinGlobalhttps://mp.
weixin.
qq.
com/s__biz=MzIxMDczMTkwNg==&mid=22.
.
.
第4页共11页2018/12/1417:44cle就是删除物化视图)yugong.
table.
concurrent.
enable多张表之前是否开启并行处理,如果false代表需要串行处理trueyugong.
table.
concurrent.
size允许并行处理的表数5yugong.
table.
retry.
times表同步出错后的重试次数3yugong.
table.
retry.
interval表同步出错后的重试时的时间间隔,单位ms1000yugong.
table.
batchApply是否开启jdbcbatch处理trueyugong.
table.
onceCrawNumextractor/applier每个批次最多处理记录数1000yugong.
table.
tpslimittps限制,0代表不限制0yugong.
table.
ignoreSchema是否忽略schema同步(如果mysql和oracle对应的schema不同,可设置为true)falseyugong.
table.
skipApplierExceptiontrue代表当applier出现数据库异常时,比如约束键冲突,可对单条出异常的数据进行忽略.
同时记录skipedrecorddata信息,日志中包含record的所有列信息,包括主键.
falseextractor配置相关yugong.
extractor.
dump是否记录extractor提取到的所有数据falseyugong.
extractor.
concurrent.
enableextractor是否开启并行处理,目前主要应用为增量模式反查源表trueyugong.
extractor.
concurrent.
globalextractor是启用全局线程池模式,如果true代表所有extractor任务都使用一组线程池,线程池大小由concurrent.
size控制falseBespinGlobalhttps://mp.
weixin.
qq.
com/s__biz=MzIxMDczMTkwNg==&mid=22.
.
.
第5页共11页2018/12/1417:44查看日志对应日志结构为:全量完成的日志:(会在yugong/table.
log和${table}/table.
log中出现记录)table[OTTER2.
TEST_ALL_ONE_PK]isend!
增量日志:(会在${table}/table.
log中出现记录)ALL(全量+增量)模式日志:(会在${table}/table.
log中出现记录)CHECK日志:(会在${table}/check.
log中出现diff记录)BespinGlobalhttps://mp.
weixin.
qq.
com/s__biz=MzIxMDczMTkwNg==&mid=22.
.
.
第6页共11页2018/12/1417:44同步过程数据日志:会通过extractor.
log/applier.
log分别记录extractor和applier的数据记录,因为有DataTranslator的存在,两者记录可能不一致,所以分开两份记录.
统计信息:-progress统计,会在主日志下,输出当前全量/增量/异常表的数据,可通过该日志,全局把握整个迁移任务的进度,输出类似:{未启动:0,全量中:2,增量中:3,已追上:3,异常数:0}-stat统计,会在每个表迁移日志下,输出当前迁移的tps信息{总记录数:180000,采样记录数:5000,同步TPS:4681,最长时间:215,最小时间:212,平均时间:213}切换流程1.
当任务处于追上状态时候,表示已经处于实时同步状态2.
后续通过源数据库进行停写,稍等1-2分钟后(保证延时的数据最终得到同步,此时源库和目标库当前数据是完全一致的)3.
检查增量持续处于NO_UPDATE状态,可关闭该迁移任务(shstop.
sh),即可发布新程序,使用新的数据库,完成切换的流程.
自定义数据转换如果要迁移的oracle和mysql的表结构不同,比如表名,字段名有差异,字段类型不兼容,需要使用自定义数据转换.
如果完全相同那就可以跳过此章节整个数据流为:DB->Extractor->DataTranslator->Applier->DB,本程序预留DataTranslator接口,允许外部用户自定义数据处理逻辑,比如:1.
表名不同2.
字段名不同3.
字段类型不同4.
字段个数不同运行过程join其他表的数据做计算等.
BespinGlobalhttps://mp.
weixin.
qq.
com/s__biz=MzIxMDczMTkwNg==&mid=22.
.
.
第7页共11页2018/12/1417:44举例/***一个迁移的例子,涵盖一些基本转换操作***例子包含特性:*1.
schema/table名不同.
oracle中为otter2.
yugong_example_oracle,mysql中为test.
yugong_example_mysql*2.
字段名字不同.
oracle中的name字段,映射到mysql的display_name*3.
字段逻辑处理.
mysql的display_name字段数据来源为oracle库的:name+'('alias_name+')'*4.
字段类型不同.
oracle中的amount为number类型,映射到mysql的amount为varchar文本型*5.
源库多一个字段.
oracle中多了一个alias_name字段*6.
目标库多了一个字段.
mysql中多了一个gmt_move字段,(简单的用迁移时的当前时间进行填充)**测试的表结构:*//oracle表*createtableotter2.
yugong_example_oracle*(*idNUMBER(11),*namevarchar2(32),*alias_namechar(32)default''notnull,*amountnumber(11,2),*scorenumber(20),*text_bblob,*text_cclob,*gmt_createdatenotnull,*gmt_modifieddatenotnull,*CONSTRAINTyugong_example_oracle_pk_idPRIMARYKEY(id)*);**//mysql表*createtabletest.
yugong_example_mysql*(*idbigint(20)unsignedauto_increment,BespinGlobalhttps://mp.
weixin.
qq.
com/s__biz=MzIxMDczMTkwNg==&mid=22.
.
.
第8页共11页2018/12/1417:44*display_namevarchar(128),*amountvarchar(32),*scorebigint(20)unsigned,*text_bblob,*text_ctext,*gmt_createtimestampnotnull,*gmt_modifiedtimestampnotnull,*gmt_movetimestampnotnull,*CONSTRAINTyugong_example_mysql_pk_idPRIMARYKEY(id)*);***/publicclassYugongExampleOracleDataTranslatorextendsAbstractDataTranslatorimplementsDataTranslator{publicbooleantranslator(Recordrecord){//1.
schema/table名不同//record.
setSchemaName("test");record.
setTableName("yugong_example_mysql");if(recordinstanceofIncrementRecord){if(IncrementOpType.
D==((IncrementRecord)record).
getOpType()){//忽略deletereturnsuper.
translator(record);}}//2.
字段名字不同ColumnValuenameColumn=record.
getColumnByName("name");nameColumn.
getColumn().
setName("display_name");//3.
字段逻辑处理ColumnValuealiasNameColumn=record.
getColumnByName("alias_name");StringBuilderdisplayNameValue=newStringBuilder(64);displayNameValue.
append(ObjectUtils.
toString(nameColumn.
getValue())).
append('(').
append(ObjectUtils.
toString(aliasNameColumn.
getValue())).
append(')');nameColumn.
setValue(displayNameValue.
toString());//4.
字段类型不同BespinGlobalhttps://mp.
weixin.
qq.
com/s__biz=MzIxMDczMTkwNg==&mid=22.
.
.
第9页共11页2018/12/1417:44ColumnValueamountColumn=record.
getColumnByName("amount");amountColumn.
getColumn().
setType(Types.
VARCHAR);amountColumn.
setValue(ObjectUtils.
toString(amountColumn.
getValue()));//5.
源库多一个字段record.
getColumns().
remove(aliasNameColumn);//6.
目标库多了一个字段ColumnMetagmtMoveMeta=newColumnMeta("gmt_move",Types.
TIMESTAMP);ColumnValuegmtMoveColumn=newColumnValue(gmtMoveMeta,newDate());record.
addColumn(gmtMoveColumn);//ColumnValuetext_c=record.
getColumnByName("text_c");//try{//text_c.
setValue(newString((byte[])text_c.
getValue(),"GBK"));//}catch(UnsupportedEncodingExceptione){//e.
printStackTrace();//}returnsuper.
translator(record);}}运行模式详细介绍MARK模式(MARK)开启增量日志的记录,如果是oracle就是创建物化视图.
CLEAR模式(CLEAR)清理增量日志的记录,如果是oracle就是删除物化视图.
全量模式(FULL)全量模式,顾名思议即为对源表进行一次全量操作,遍历源表所有的数据后,插入目标表.
全量有两种处理方式:1.
分页处理:如果源表存在主键,只有一个主键字段,并且主键字段类型为Number类型,默认会选择该分页处理模式.
优点:支持断点续做,对源库压力相对较小.
缺点:迁移速度慢2.
once处理:通过select*from访问整个源表的某一个mvcc版本的数据,通过cursor.
next遍历整个结果集.
优点:迁移速度快,为分页处理的5倍左右.
缺点:源库压力大,如果源库并发修改量大,会导致数据库MVCC版本过多,出现栈错误.
还有就是不支持断点续做.
特别注意如果全量模式运行过程中,源库有变化时,不能保证源库最近变化的数据能同步到目标表,这时需要配合增量模式.
具体操作就是:在运行全量模式之前,先开启增量模式的记录日志功能,然后BespinGlobalhttps://mp.
weixin.
qq.
com/s__biz=MzIxMDczMTkwNg==&mid=22.
.
.
第10页共11页2018/12/1417:44阅读原文开启全量模式,完成后,再将最近变化的数据通过增量模式同步到目标表.
增量模式(INC)全量模式,顾名思议即为对源表增量变化的数据插入目标表,增量模式依赖记录日志功能.
目前增量模式的记录日志功能,是通过oracle的物化视图功能.
创建物化视图.
CREATEMATERIALIZEDVIEWLOGON${tableName}withprimarykey.
·运行增量模式之前,需要先开启记录日志的功能,即预先创建物化视图.
特别是配合全量模式时,创建物化视图的时间点要早于运行全量之前,这样才可以保证数据能全部同步到目标表·增量模式没有完成的概念,它只有追上的概念,具体的停止需有业务进行判断,可以看一下切换流程.
自动模式(ALL)自动模式,是对全量+增量模式的一种组合,自动化运行,减少操作成本.
自动模式的内部实现步骤:1.
开启记录日志功能.
(创建物化视图)2.
运行全量同步模式.
(全量完成后,自动进入下一步)3.
运行增量同步模式.
(增量模式,没有完成的概念,所以也就不会自动退出,需要业务判断是否可以退出,可以看一下切换流程)对比模式(CHECK)对比模式,即为对源库和目标库的数据进行一次全量对比,验证一下迁移结果.
对比模式为一种可选运行,做完全量/增量/自动模式后,可选择性的运行对比模式,来确保本次迁移的正确性.
愚公项目是在阿里去IOE的过程中诞生,其要解决的目标就是帮助用户完成从Oracle数据迁移到MySQL上.
是后续的DTS工具重要组成部分.
经过生产系统的验证,是一种可靠的数据库迁移工具.
关键在于其支持的增量的方式的迁移,能够在数据上云的过程中减少大量的停机时间.
数据库的迁移不仅是数据迁移,包含的更多技术细节问题.
BespinGlobal能够提供大量的数据库迁移的技术支持.
更多详情阅读原文BespinGlobalhttps://mp.
weixin.
qq.
com/s__biz=MzIxMDczMTkwNg==&mid=22.
.
.
第11页共11页2018/12/1417:44
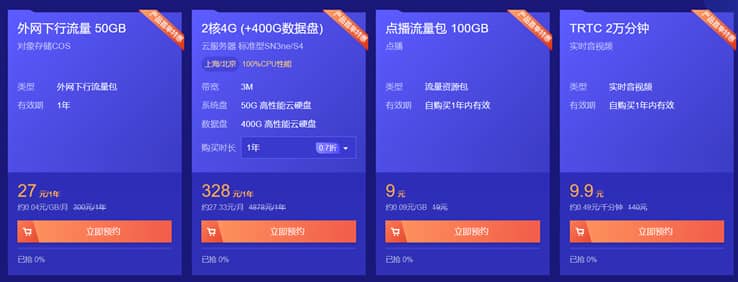
腾讯云CVM云服务器大硬盘方案400GB和800GB数据盘方案
最近看到群里的不少网友在搭建大数据内容网站,内容量有百万篇幅,包括图片可能有超过50GB,如果一台服务器有需要多个站点的话,那肯定默认的服务器50GB存储空间是不够用的。如果单独在购买数据盘会成本提高不少。这里我们看到腾讯云促销活动中有2款带大数据盘的套餐还是比较实惠的,一台是400GB数据盘,一台是800GB数据盘,适合他们的大数据网站。 直达链接 - 腾讯云 大数据盘套餐服务器这里我们看到当前...
NameSilo域名优惠码活动
NameSilo是通过之前的感恩节优惠活动中认识到这家注册商的,于是今天早上花了点时间专门了解了NameSilo优惠码和商家的详细信息。该商家只销售域名,他们家的域名销售价格还是中规中矩的,没有像godaddy域名标价和使用优惠之后的价格悬殊很大,而且其特色就是该域名平台提供免费的域名停放、免费隐私保护等功能。namesilo新注册域名价格列表,NameSilo官方网站:www.namesilo....

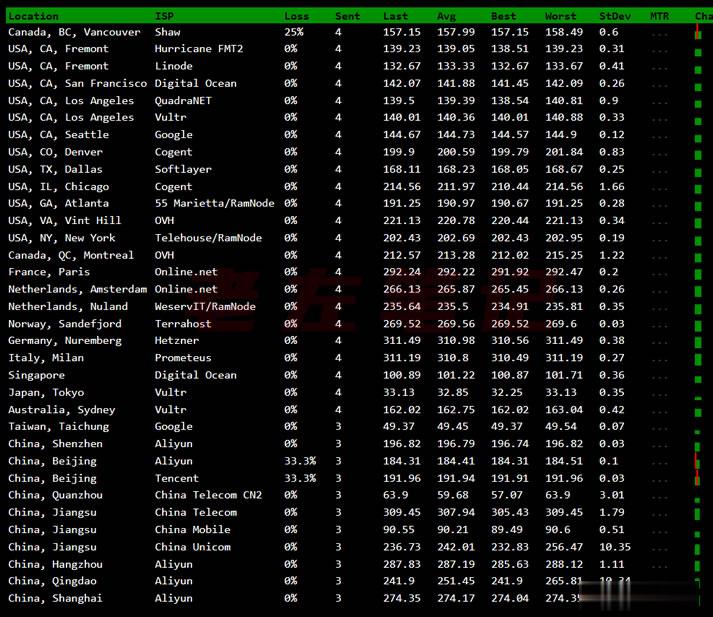
Vultr VPS韩国首尔机房速度和综合性能参数测试
Vultr 商家有新增韩国首尔机房,这个是继日本、新加坡之后的第三个亚洲机房。不过可以大概率知道肯定不是直连中国机房的,因为早期的日本机房有过直连后来取消的。今天准备体验看看VULTR VPS主机商的韩国首尔机房的云服务器的速度和性能。1、全球节点PING速度测试这里先通过PING测试工具看看全球几十个节点的PING速度。看到好像移动速度还不错。2、路由去程测试测试看看VULTR韩国首尔机房的节点...
qq数据库查询为你推荐
-
操作http360邮箱360免费申请邮箱在那里重庆网站制作重庆网站制作,哪家专业,价格最优?申请支付宝账户如何申请支付宝账户ipad代理ipad在哪里买是正品?信息cuteftp香港空间香港有什么标志性建筑?powerbydedecms如何去掉dedecms自带广告以及Power by dedecms联系我们代码如何查询统一社会信用代码关闭评论iOS12抖音直播怎样关闭评论?