文档分词工具
分词工具 时间:2021-03-24 阅读:()
第32卷第4期华侨大学学报(自然科学版)Vol.
32No.
42011年7月JournalofHuaqiaoUniversity(NaturalScience)Jul.
2011文章编号:10005013(2011)04040104一种改进的朴素贝叶斯文本分类方法陈叶旺,余金山(华侨大学计算机科学与技术学院,福建泉州362021)摘要:针对网络中所存在的大量以网页等非结构化形式存在的文本资源,提出一种改进的朴素贝叶斯分类方法.
首先,通过卡方检验方法求文档特征并对文档降维,提高特征词区分性信息;然后,以文本特征来代替原始词条进行朴素贝叶斯对类.
实验表明,该方法不仅理论上易于建立和更新,而且分类的精确率也得到提高.
关键词:文本分类;朴素贝叶斯方法;文档特征;卡方检验中图分类号:TP311.
13文献标志码:A文本挖掘中最基本的两项工作就是分类和聚类,几乎在所有文本挖掘的应用领域都离不开文本的分类和聚类[1].
文本分类是文本挖掘的一个重要内容,是指按照预先定义的主题类别,为文档集合中的每个文档确定一个类别.
通过自动文本系统把文档进行归类,可以帮助人们更好地寻找需要的信息和知识.
随着文本信息的快速增长,特别是Internet上在线文本信息的激增,文本自动分类已经成为处理和组织大量文档数据的关键技术.
与此同时,人们对于内容搜索的准确率、查全率等方面的要求会越来越高,因而对文本分类技术需求大为增加,如何构造一个有效的文本分类系统仍然是文本挖掘的一个主要研究方向.
近年来,国内外研究人员对文本分类问题进行深入研究,他们采用很多不同方法来构造分类器[26].
在文本分类系统中,文本被表示成一个文本特征向量,文本特征用词来表示.
即文本表示采用BOW模型.
目前,大多数文本分类系统都是使用这种文本特征表示方法等.
本文主要是以改进的朴素贝叶斯方法来实现资源分类.
1基于文档词汇的朴素贝叶斯粗粒度分类文本分类中常用的统计方法是利用文本的概率模型,其基本思想是利用词和文本的联合概率估计文本所属类别的概率.
朴素贝叶斯假设文本是基于词的Unigram模型,即文本中词的出现依赖于文本类别,但不依赖于其他词及文本的长度.
也就是说,词与词之间相互独立的.
因而在对文本进行分类前需要对文本进行分词.
分词工具主要基于中文基本词库和专业词库,其词库可动态变换和加载.
如对于一段与农业有关的文本"黄瓜的叶子发霉有小黑点",经过处理和分词后,可以得到的词汇集合为{黄瓜,叶子,发霉,有,小,黑点}.
中文词库采用联合国粮食及农业组织(FAO)的中文农业叙词表和中文基本词库,词汇数量分别为37060,119850个,前者优先于后者.
经过分词处理后,按全概率理论和贝叶斯定理有犘(犮狘犱)=犘(犮)*犘(犱狘犮)犘(犱).
(1)式(1)中:犮为类别;犱为一个文档,分解为一个词汇向量犱=(狑1,狑2,…,狑犽);犘(犱)可以认为是一个常数,在分类过程中不起作用;犘(犮)为文档属于这个类别的先验概率,犘(犮)=|犮|/|犇|,|犮|为类别为犮的训练文档的数量,|犇|为训练集文档总数;犘(犱|犮)=∏犻=犽犻=1犘(狑犻|犮),犘(狑犻|犮)为词汇狑犻在训练文档中属收稿日期:20100613通信作者:陈叶旺(1978),男,讲师,博士,主要从事数据挖掘的研究.
Email:ywchen@hqu.
edu.
cn.
基金项目:福建省自然科学基金资助项目(A0810013);华侨大学高层次人才科研启动项目(09BS619)于类别犮的概率.
即有犘(狑犻狘犮)=∑犼=狘犮狘犼=1狋(狑犻,犼)/∑犿=狘犮狘犿=1犾(犮犿).
(2)式(2)中:狋(狑犻,犼)为词汇狑犻在第犼个训练文档中出现的次数;∑犿=狘犮狘犿=1犾(犮犿)为类别为犮的训练文档的总长度;|犮|为类别为犮的训练文档的数量.
综合式(1),可以得到犘狑(犮狘犱)=犘(犮)*∏犻=犽犻=1犘(狑犻狘犮)=狘犮狘狘犇狘*∏犻=犽犻=1∑犼=狘犮狘犼=1狋(狑犻,犼)∑犿=狘犮狘犿=1犾(犮犿).
(3)式(3)中:犘狑(犮|犱)为基于词汇统计的朴素贝叶斯概率.
如上所述,基本贝叶斯分类法对文档中出现的所有词汇进行统计.
然而,当需进行分类文档的数量较大时,其词汇向量往往达到数十万,多数词汇的犘(狑|犮)相当小几乎为0,可以看成一个巨型稀疏矩阵.
因而可以通过一些方法进行必要过滤,以大量减少不必要运算.
2基于文档特征的朴素贝叶斯粗粒度分类为进行有效过滤,需先对文档做特征选择,然后根据文档特征进行概率统计,以达到降维效果.
卡方(ChiSquare)检验的主要思想是:词条与类别之间符合χ2分布,词条的χ2统计量表示词条对某个类别的贡献大小.
统计量越高,词条和类别之间的独立性越小、相关性越强,即词条对此类别的贡献越大.
特征选择的方法是χ2统计值[7].
即在所有训练文档中,对所有与类别犮相关的词汇狋按χ2值进行排序,有χ2(狋,犮)=犖*(犃*犇-犆*犅)2(犃+犆)*(犅+犇)*(犃+犅)*(犆+犇).
(4)式(4)中:狋为词汇;犮为文档分类;犖为训练文档总数;犃为在所有属于犮类的训练文档中狋出现的次数;犅为在所有不属于犮类的训练文档中狋出现的次数;犆为所有属于犮类但没有狋出现的训练文档数;犇为所有即不属于犮类也没有狋出现的训练文档数.
对于所有的χ2值,选定一个阈值犎,以获得一个词汇集合犉={狋|χ2(狋,犮)>犎},并以集合犉中的所有词汇来作为类别犮的特征.
那么,将式(1)中的犘(犱|犮)按文档特征来计算概率值,则为犘(犱狘犮)=∏犻=犽犻=1犘(犳犻狘犮)=∏犻=犽犻=1∑犼=狘犮狘犼=1狋(狑犻,犼)∑犿=狘犮狘犿=1犾(犮犿).
(5)式(5)中:犳犻为文档犱中出现的属于类别犮的第犻个特征值,犽为特征总数;∑犼=狘犮狘犼=1狋(狑犻,犼)为特征犳犻在所有类别为犮的训练文档中出现的次数;犘(犳犻|犮)为特征犳犻属于类别犮的概率.
综合式(1),则有犘犳(犮狘犱)=犘(犮)*∏犻=犽犻=1犘(犳犻狘犮)=狘犮狘狘犇狘*∏犻=犽犻=1∑犼=狘犮狘犼=1狋(狑犻,犼)∑犿=狘犮狘犿=1犾(犮犿).
(6)式(6)中:犘犳(犮|犱)为基于特征统计的朴素贝叶斯概率.
由于采用概率分类,一个文档犱可以同时属于两个以上分类,即取其按概率值排序的前犖个类别作为文档犱的分类.
3评测实验与分析在Java环境下,使用Eclipse作为开发平台,实验主要分为相对独立的两步.
(1)基于词汇统计的朴素贝叶斯和卡方文本特征选择.
使用Weka开源软件包中提供的相应算204华侨大学学报(自然科学版)2011年法,对朴素贝叶斯稍作修改,使其按输入特征值来做自动分类.
从3类文档集中选出一部分做为训练集,表1训练文档集分类Tab.
1Trainingdocumentsclassification语料库名称训练文档数量类数目词汇总量花卉知识8004794601新浪国际足球新闻80041035783农作物病虫害知识8004854823并按训练集相应本体元知识做简单的人工分类,如表1所示.
为简化工作,按这些文档资源所在网站的分类作为人工分类结果,除去作为训练种子的文件,剩下的都用来作为测试数据集.
对于所有经过粗粒度分类的文档,按式(5)取犖=1,即取最大概率值作为一个文档的自动分类结果.
通过这个自动分类结果与原先文档所处的人工分类作比较,得到查准率(犚P)和查全率(犚r).
(2)对于粗粒度分类正确的结果,选出其中一部分,再用本体实例来进标注.
用贝叶斯分类器对表1中的3种文档集进行分类实验,分别取了不同数量的训练语料来进行测试,图1训练语料的规模对分类结果的影响Fig.
1Effectoftrainingcorpussizeontheresultsofclassification结果如图1所示.
从图1的结果可以看出,随着训练语料的增多,分类效果就越来越好;但到一定程度后,训练语料的规模对分类效果的影响不大.
对于两种贝叶斯分类方法的实验测试,结果如表2所示.
表2中:狀为平均每个文档特征数.
经过χ2阈值犎的调整,两种贝叶斯方法的查准率(犚P)和查全率(犚r)相差不多,与文[7]报告的结果接近,说明少数词汇对文本分类起到关键作用.
两个方法时间开销,如表3所示.
从表3可知,训练时间改进方法时间开销有所增加.
因为要多做卡方值计算,经过算法优化后,卡方时间开销随文档数量增加而平缓增长,如表第2列与第4列所示;然而,测试时间却达到一个数量级减少,如表第3列与第5列所示.
这说明基于特征统计的贝叶斯方法实现了较好的时间性能.
表2两种文档分类方法的测试结果统计Tab.
2Statisticsofthetestresultsforbothdocumentclassfication语料库名称基于词汇贝叶斯犚P/%犚r/%基于特征贝叶斯犚P/%犚r/%犎狀花卉知识78.
378.
985.
777.
22.
3416新浪国际足球新闻81.
882.
189.
479.
91.
5734农作物病虫害知识82.
381.
588.
880.
51.
5730表3两种文档分类方法的时间开销统计Tab.
3Timeoverheadstatisticsforbothdocumentclassificationms语料库名称基于词汇贝叶斯训练时间测试时间基于特征贝叶斯训练时间测试时间花卉知识254752346402275339021新浪国际足球新闻3098014317229763211212农作物病虫害知识24754271212281704104134讨论以上结果表明,使用本文方法进行分类,具有较高的查准率和查全率.
方法的效率主要受以下3个方面因素的影响.
(1)本体知识本身质量.
包括知识表达方式、内容全面性;(2)文档质量.
包括文档内容文字表达、段落排版、有无错别字、文档格式等;(3)文档解析器质量.
若解析器不能正确解析文档内容,则语义标注无从谈起.
使用系统中的几种文档解析器,分别解析一定量的相应格式的文档,提取文档内容,再进行对比.
对304第4期陈叶旺,等:一种改进的朴素贝叶斯文本分类方法比方式是人工把文档内容提出来,与解析器提出的内容进行字符串比较.
结果表明,html和xml解析器解析文档质量较好,其平均解析准确度分别为87.
5%,89.
3%,基本上能抓取出文档主要内容.
doc解析器次之,其平均解析准确度为79.
4%.
这是因为提取不出的word中存在一些特殊字符,图、表格式,或者可能应为经过加密而不能打开等原因.
pdf解析器解析效果较差,其平均解析准确度只有48.
6%.
主要原因是一些pdf文档质量不是很好,其特殊的排版格式和编码方式也造成解析困难.
但是,经过latex和word转化而成的pdf文档同样能有较好的解析结果,一般能达到doc解析器的水平.
因此,本系统解析器品质有待提高.
文本分类是文本挖掘的一个重要内容,是指按照预先定义的主题类别,为文档集合中的每个文档确定一个类别.
通过自动文本系统把文档进行归类,可以帮助人们更好地寻找需要的信息和知识.
文中提出的基于贝叶斯分类的改进方法不仅理论上易于建立和更新,而且分类的精确率也得到了提高.
参考文献:[1]喻小光,陈维斌,陈荣鑫.
一种数据规约的近似挖掘方法的实现[J].
华侨大学学报:自然科学版,2008,28(3):370374.
[2]SEBASTIANIF.
Machinelearninginautomatedtextcategorization[J].
ACMComputingSurveys,2002,34(1):147.
[3]HAOLili,HAOLizhu.
AutomaticidentificationofstopwordsinChinesetextclassification[C]∥Proceedingsofthe2008InternationalConferenceonComputerScienceandSoftwareEngineering.
WashingtonDC:IEEEComputerSociety,2008:718722.
[4]LEWISDD,RINGUETTEM.
Acomparisonoftwolearningalgorithmsfortextcategorization[C]∥ThirdAnnualSymposiumonDocumentAnalysisandInformationRetrieval.
LasVegas:[s.
n.
],1994:8193.
[5]YANGYiming,LIUXin.
Areexaminationoftextcategorizationmethods[C]∥Proceedingsofthe22ndAnnualInternationalACMSIGIRConferenceonResearchandDevelopmentinInformationRetrieval.
NewYork:ACMPress,1999:4249.
[6]黄萱菁,吴立德,石崎洋之,等.
独立于语种的文本分类方法[J].
中文信息学报,2000,14(6):17.
[7]YANGYiming,PEDERSENJO.
Acomparativestudyonfeatureselectionintextcategorization[C]∥ProceedingsoftheFourteenthInternationalConferenceonMachineLearning.
SanFrancisco:MorganKaufmannPublishersInc,1997:412420.
犃狀犐犿狆狉狅狏犲犱犜犲狓狋犆犾犪狊狊犻犳犻犮犪狋犻狅狀犕犲狋犺狅犱犅犪狊犲犱狅狀犅犪狔犲狊CHENYewang,YUJinshan(CollegeofComputerScienceandTechnology,HuaqiaoUniversity,Quanzhou362021,China)犃犫狊狋狉犪犮狋:Therearehugeamountofunstructuredtextresourcesininternet,arefinedNaveBayesbasedtextcategorizationmethodisproposedinthispaperforclassifyingtheseresources.
Firstly,thismethodrefinestextbycalculatingthefeaturesofthetextinordertoimprovethetext′srecognizability,andthenNaveBayesisusedtoclassifytheseresourcesbasedonthesefeaturesinsteadoftheoriginalwords.
Theexperimentsshowthatthenewmethodiseasysettingupandrenewintheory,andtheaccuraterateoftheclassificationisalsoimproved.
犓犲狔狑狅狉犱狊:textcategorization;NaveBayes;textfeature;ChiSquaretest(责任编辑:钱筠英文审校:吴逢铁)404华侨大学学报(自然科学版)2011年
32No.
42011年7月JournalofHuaqiaoUniversity(NaturalScience)Jul.
2011文章编号:10005013(2011)04040104一种改进的朴素贝叶斯文本分类方法陈叶旺,余金山(华侨大学计算机科学与技术学院,福建泉州362021)摘要:针对网络中所存在的大量以网页等非结构化形式存在的文本资源,提出一种改进的朴素贝叶斯分类方法.
首先,通过卡方检验方法求文档特征并对文档降维,提高特征词区分性信息;然后,以文本特征来代替原始词条进行朴素贝叶斯对类.
实验表明,该方法不仅理论上易于建立和更新,而且分类的精确率也得到提高.
关键词:文本分类;朴素贝叶斯方法;文档特征;卡方检验中图分类号:TP311.
13文献标志码:A文本挖掘中最基本的两项工作就是分类和聚类,几乎在所有文本挖掘的应用领域都离不开文本的分类和聚类[1].
文本分类是文本挖掘的一个重要内容,是指按照预先定义的主题类别,为文档集合中的每个文档确定一个类别.
通过自动文本系统把文档进行归类,可以帮助人们更好地寻找需要的信息和知识.
随着文本信息的快速增长,特别是Internet上在线文本信息的激增,文本自动分类已经成为处理和组织大量文档数据的关键技术.
与此同时,人们对于内容搜索的准确率、查全率等方面的要求会越来越高,因而对文本分类技术需求大为增加,如何构造一个有效的文本分类系统仍然是文本挖掘的一个主要研究方向.
近年来,国内外研究人员对文本分类问题进行深入研究,他们采用很多不同方法来构造分类器[26].
在文本分类系统中,文本被表示成一个文本特征向量,文本特征用词来表示.
即文本表示采用BOW模型.
目前,大多数文本分类系统都是使用这种文本特征表示方法等.
本文主要是以改进的朴素贝叶斯方法来实现资源分类.
1基于文档词汇的朴素贝叶斯粗粒度分类文本分类中常用的统计方法是利用文本的概率模型,其基本思想是利用词和文本的联合概率估计文本所属类别的概率.
朴素贝叶斯假设文本是基于词的Unigram模型,即文本中词的出现依赖于文本类别,但不依赖于其他词及文本的长度.
也就是说,词与词之间相互独立的.
因而在对文本进行分类前需要对文本进行分词.
分词工具主要基于中文基本词库和专业词库,其词库可动态变换和加载.
如对于一段与农业有关的文本"黄瓜的叶子发霉有小黑点",经过处理和分词后,可以得到的词汇集合为{黄瓜,叶子,发霉,有,小,黑点}.
中文词库采用联合国粮食及农业组织(FAO)的中文农业叙词表和中文基本词库,词汇数量分别为37060,119850个,前者优先于后者.
经过分词处理后,按全概率理论和贝叶斯定理有犘(犮狘犱)=犘(犮)*犘(犱狘犮)犘(犱).
(1)式(1)中:犮为类别;犱为一个文档,分解为一个词汇向量犱=(狑1,狑2,…,狑犽);犘(犱)可以认为是一个常数,在分类过程中不起作用;犘(犮)为文档属于这个类别的先验概率,犘(犮)=|犮|/|犇|,|犮|为类别为犮的训练文档的数量,|犇|为训练集文档总数;犘(犱|犮)=∏犻=犽犻=1犘(狑犻|犮),犘(狑犻|犮)为词汇狑犻在训练文档中属收稿日期:20100613通信作者:陈叶旺(1978),男,讲师,博士,主要从事数据挖掘的研究.
Email:ywchen@hqu.
edu.
cn.
基金项目:福建省自然科学基金资助项目(A0810013);华侨大学高层次人才科研启动项目(09BS619)于类别犮的概率.
即有犘(狑犻狘犮)=∑犼=狘犮狘犼=1狋(狑犻,犼)/∑犿=狘犮狘犿=1犾(犮犿).
(2)式(2)中:狋(狑犻,犼)为词汇狑犻在第犼个训练文档中出现的次数;∑犿=狘犮狘犿=1犾(犮犿)为类别为犮的训练文档的总长度;|犮|为类别为犮的训练文档的数量.
综合式(1),可以得到犘狑(犮狘犱)=犘(犮)*∏犻=犽犻=1犘(狑犻狘犮)=狘犮狘狘犇狘*∏犻=犽犻=1∑犼=狘犮狘犼=1狋(狑犻,犼)∑犿=狘犮狘犿=1犾(犮犿).
(3)式(3)中:犘狑(犮|犱)为基于词汇统计的朴素贝叶斯概率.
如上所述,基本贝叶斯分类法对文档中出现的所有词汇进行统计.
然而,当需进行分类文档的数量较大时,其词汇向量往往达到数十万,多数词汇的犘(狑|犮)相当小几乎为0,可以看成一个巨型稀疏矩阵.
因而可以通过一些方法进行必要过滤,以大量减少不必要运算.
2基于文档特征的朴素贝叶斯粗粒度分类为进行有效过滤,需先对文档做特征选择,然后根据文档特征进行概率统计,以达到降维效果.
卡方(ChiSquare)检验的主要思想是:词条与类别之间符合χ2分布,词条的χ2统计量表示词条对某个类别的贡献大小.
统计量越高,词条和类别之间的独立性越小、相关性越强,即词条对此类别的贡献越大.
特征选择的方法是χ2统计值[7].
即在所有训练文档中,对所有与类别犮相关的词汇狋按χ2值进行排序,有χ2(狋,犮)=犖*(犃*犇-犆*犅)2(犃+犆)*(犅+犇)*(犃+犅)*(犆+犇).
(4)式(4)中:狋为词汇;犮为文档分类;犖为训练文档总数;犃为在所有属于犮类的训练文档中狋出现的次数;犅为在所有不属于犮类的训练文档中狋出现的次数;犆为所有属于犮类但没有狋出现的训练文档数;犇为所有即不属于犮类也没有狋出现的训练文档数.
对于所有的χ2值,选定一个阈值犎,以获得一个词汇集合犉={狋|χ2(狋,犮)>犎},并以集合犉中的所有词汇来作为类别犮的特征.
那么,将式(1)中的犘(犱|犮)按文档特征来计算概率值,则为犘(犱狘犮)=∏犻=犽犻=1犘(犳犻狘犮)=∏犻=犽犻=1∑犼=狘犮狘犼=1狋(狑犻,犼)∑犿=狘犮狘犿=1犾(犮犿).
(5)式(5)中:犳犻为文档犱中出现的属于类别犮的第犻个特征值,犽为特征总数;∑犼=狘犮狘犼=1狋(狑犻,犼)为特征犳犻在所有类别为犮的训练文档中出现的次数;犘(犳犻|犮)为特征犳犻属于类别犮的概率.
综合式(1),则有犘犳(犮狘犱)=犘(犮)*∏犻=犽犻=1犘(犳犻狘犮)=狘犮狘狘犇狘*∏犻=犽犻=1∑犼=狘犮狘犼=1狋(狑犻,犼)∑犿=狘犮狘犿=1犾(犮犿).
(6)式(6)中:犘犳(犮|犱)为基于特征统计的朴素贝叶斯概率.
由于采用概率分类,一个文档犱可以同时属于两个以上分类,即取其按概率值排序的前犖个类别作为文档犱的分类.
3评测实验与分析在Java环境下,使用Eclipse作为开发平台,实验主要分为相对独立的两步.
(1)基于词汇统计的朴素贝叶斯和卡方文本特征选择.
使用Weka开源软件包中提供的相应算204华侨大学学报(自然科学版)2011年法,对朴素贝叶斯稍作修改,使其按输入特征值来做自动分类.
从3类文档集中选出一部分做为训练集,表1训练文档集分类Tab.
1Trainingdocumentsclassification语料库名称训练文档数量类数目词汇总量花卉知识8004794601新浪国际足球新闻80041035783农作物病虫害知识8004854823并按训练集相应本体元知识做简单的人工分类,如表1所示.
为简化工作,按这些文档资源所在网站的分类作为人工分类结果,除去作为训练种子的文件,剩下的都用来作为测试数据集.
对于所有经过粗粒度分类的文档,按式(5)取犖=1,即取最大概率值作为一个文档的自动分类结果.
通过这个自动分类结果与原先文档所处的人工分类作比较,得到查准率(犚P)和查全率(犚r).
(2)对于粗粒度分类正确的结果,选出其中一部分,再用本体实例来进标注.
用贝叶斯分类器对表1中的3种文档集进行分类实验,分别取了不同数量的训练语料来进行测试,图1训练语料的规模对分类结果的影响Fig.
1Effectoftrainingcorpussizeontheresultsofclassification结果如图1所示.
从图1的结果可以看出,随着训练语料的增多,分类效果就越来越好;但到一定程度后,训练语料的规模对分类效果的影响不大.
对于两种贝叶斯分类方法的实验测试,结果如表2所示.
表2中:狀为平均每个文档特征数.
经过χ2阈值犎的调整,两种贝叶斯方法的查准率(犚P)和查全率(犚r)相差不多,与文[7]报告的结果接近,说明少数词汇对文本分类起到关键作用.
两个方法时间开销,如表3所示.
从表3可知,训练时间改进方法时间开销有所增加.
因为要多做卡方值计算,经过算法优化后,卡方时间开销随文档数量增加而平缓增长,如表第2列与第4列所示;然而,测试时间却达到一个数量级减少,如表第3列与第5列所示.
这说明基于特征统计的贝叶斯方法实现了较好的时间性能.
表2两种文档分类方法的测试结果统计Tab.
2Statisticsofthetestresultsforbothdocumentclassfication语料库名称基于词汇贝叶斯犚P/%犚r/%基于特征贝叶斯犚P/%犚r/%犎狀花卉知识78.
378.
985.
777.
22.
3416新浪国际足球新闻81.
882.
189.
479.
91.
5734农作物病虫害知识82.
381.
588.
880.
51.
5730表3两种文档分类方法的时间开销统计Tab.
3Timeoverheadstatisticsforbothdocumentclassificationms语料库名称基于词汇贝叶斯训练时间测试时间基于特征贝叶斯训练时间测试时间花卉知识254752346402275339021新浪国际足球新闻3098014317229763211212农作物病虫害知识24754271212281704104134讨论以上结果表明,使用本文方法进行分类,具有较高的查准率和查全率.
方法的效率主要受以下3个方面因素的影响.
(1)本体知识本身质量.
包括知识表达方式、内容全面性;(2)文档质量.
包括文档内容文字表达、段落排版、有无错别字、文档格式等;(3)文档解析器质量.
若解析器不能正确解析文档内容,则语义标注无从谈起.
使用系统中的几种文档解析器,分别解析一定量的相应格式的文档,提取文档内容,再进行对比.
对304第4期陈叶旺,等:一种改进的朴素贝叶斯文本分类方法比方式是人工把文档内容提出来,与解析器提出的内容进行字符串比较.
结果表明,html和xml解析器解析文档质量较好,其平均解析准确度分别为87.
5%,89.
3%,基本上能抓取出文档主要内容.
doc解析器次之,其平均解析准确度为79.
4%.
这是因为提取不出的word中存在一些特殊字符,图、表格式,或者可能应为经过加密而不能打开等原因.
pdf解析器解析效果较差,其平均解析准确度只有48.
6%.
主要原因是一些pdf文档质量不是很好,其特殊的排版格式和编码方式也造成解析困难.
但是,经过latex和word转化而成的pdf文档同样能有较好的解析结果,一般能达到doc解析器的水平.
因此,本系统解析器品质有待提高.
文本分类是文本挖掘的一个重要内容,是指按照预先定义的主题类别,为文档集合中的每个文档确定一个类别.
通过自动文本系统把文档进行归类,可以帮助人们更好地寻找需要的信息和知识.
文中提出的基于贝叶斯分类的改进方法不仅理论上易于建立和更新,而且分类的精确率也得到了提高.
参考文献:[1]喻小光,陈维斌,陈荣鑫.
一种数据规约的近似挖掘方法的实现[J].
华侨大学学报:自然科学版,2008,28(3):370374.
[2]SEBASTIANIF.
Machinelearninginautomatedtextcategorization[J].
ACMComputingSurveys,2002,34(1):147.
[3]HAOLili,HAOLizhu.
AutomaticidentificationofstopwordsinChinesetextclassification[C]∥Proceedingsofthe2008InternationalConferenceonComputerScienceandSoftwareEngineering.
WashingtonDC:IEEEComputerSociety,2008:718722.
[4]LEWISDD,RINGUETTEM.
Acomparisonoftwolearningalgorithmsfortextcategorization[C]∥ThirdAnnualSymposiumonDocumentAnalysisandInformationRetrieval.
LasVegas:[s.
n.
],1994:8193.
[5]YANGYiming,LIUXin.
Areexaminationoftextcategorizationmethods[C]∥Proceedingsofthe22ndAnnualInternationalACMSIGIRConferenceonResearchandDevelopmentinInformationRetrieval.
NewYork:ACMPress,1999:4249.
[6]黄萱菁,吴立德,石崎洋之,等.
独立于语种的文本分类方法[J].
中文信息学报,2000,14(6):17.
[7]YANGYiming,PEDERSENJO.
Acomparativestudyonfeatureselectionintextcategorization[C]∥ProceedingsoftheFourteenthInternationalConferenceonMachineLearning.
SanFrancisco:MorganKaufmannPublishersInc,1997:412420.
犃狀犐犿狆狉狅狏犲犱犜犲狓狋犆犾犪狊狊犻犳犻犮犪狋犻狅狀犕犲狋犺狅犱犅犪狊犲犱狅狀犅犪狔犲狊CHENYewang,YUJinshan(CollegeofComputerScienceandTechnology,HuaqiaoUniversity,Quanzhou362021,China)犃犫狊狋狉犪犮狋:Therearehugeamountofunstructuredtextresourcesininternet,arefinedNaveBayesbasedtextcategorizationmethodisproposedinthispaperforclassifyingtheseresources.
Firstly,thismethodrefinestextbycalculatingthefeaturesofthetextinordertoimprovethetext′srecognizability,andthenNaveBayesisusedtoclassifytheseresourcesbasedonthesefeaturesinsteadoftheoriginalwords.
Theexperimentsshowthatthenewmethodiseasysettingupandrenewintheory,andtheaccuraterateoftheclassificationisalsoimproved.
犓犲狔狑狅狉犱狊:textcategorization;NaveBayes;textfeature;ChiSquaretest(责任编辑:钱筠英文审校:吴逢铁)404华侨大学学报(自然科学版)2011年
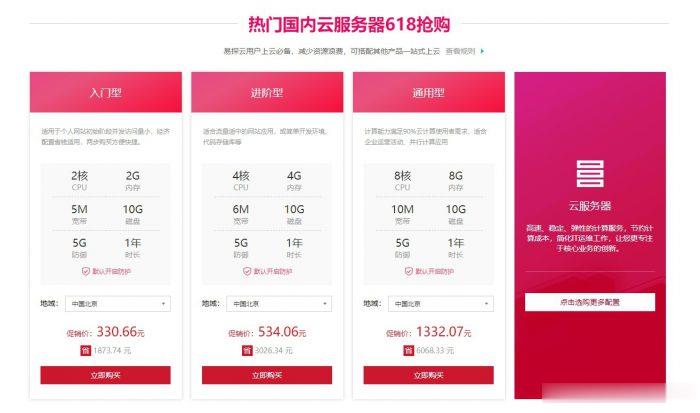
易探云2核2G5M仅330元/年起,国内挂机宝云服务器,独立ip
易探云怎么样?易探云是国内一家云计算服务商家,致力香港服务器、国内外服务器租用及托管等互联网业务,目前主要地区为运作香港BGP、香港CN2、广东、北京、深圳等地区。目前,易探云推出深圳或北京地区的适合挂机和建站的云服务器,国内挂机宝云服务器(可选深圳或北京地区),独立ip;2核2G5M挂机云服务器仅330元/年起!点击进入:易探云官方网站地址易探云国内挂机宝云服务器推荐:1、国内入门型挂机云服务器...
棉花云1折起(49元), 国内BGP 美国 香港 日本
棉花云官网棉花云隶属于江西乐网科技有限公司,前身是2014年就运营的2014IDC,专注海外线路已有7年有余,是国内较早从事海外专线的互联网基础服务提供商。公司专注为用户提供低价高性能云计算产品,致力于云计算应用的易用性开发,并引导云计算在国内普及。目前公司研发以及运营云服务基础设施服务平台(IaaS),面向全球客户提供基于云计算的IT解决方案与客户服务(SaaS),拥有丰富的国内BGP、双线高防...

UCloud新人优惠中国香港/日本/美国云服务器低至4元
UCloud优刻得商家这几年应该已经被我们不少的个人站长用户认知,且确实在当下阿里云、腾讯云服务商不断的只促销服务于新用户活动,给我们很多老用户折扣的空间不多。于是,我们可以通过拓展选择其他同类服务商享受新人的福利,这里其中之一就选择UCloud商家。UCloud服务商2020年创业板上市的,实际上很早就有认识到,那时候价格高的离谱,谁让他们只服务有钱的企业用户呢。这里希望融入到我们大众消费者,你...
分词工具为你推荐
-
网络访问为什么Wifi无internet访问www.299pp.com免费PP电影哪个网站可以看啊www.78222.com我看一个网站.www.snw58.com里面好有意思呀,不知道里面的信息是不是真实的www.bbb551.combbb是什么意思lcoc.top日本Ni-TOP是什么意思?sodu.tw台湾的可以看小说的网站sodu.tw今天sodu.org为什么打不开了?www.175qq.com求带名字的情侣网名!bk乐乐《哭泣的Bk》是Bk乐乐唱的吗?dpscycle寻求LR 高输出宏