文件反垃圾邮件系统的内容过滤模块设计与实现(计算机应用范文)
封面
《反垃圾邮件系统的内容过滤模块设计与实现》Word格式可编辑可修改
精心整理放心阅读欢迎下载
文档信息
反垃圾邮件系统的内容过滤模块设计与实现
摘要介绍了一种反垃圾邮件系统的内容过滤模块的总体设计 以及内容过滤模块中采用的关键技术——多文档文本提取技术涉及HTML文档、 P DF文档、 MS-WO RD文档、 CHM文档的文本提取技术及压缩文件中的文档处理技术从而更好地完善反垃圾邮件系统 以提高垃圾邮件识别率、拦截率降低资源的消耗。 关键词垃圾邮件反垃圾邮件系统过滤模块1引言 国际互联网技术为人们进行交流、协同工作、资源及内容共享等提供了一条崭新途径。随着通信技术及计算机技术的飞速发展互联网络的使用日益普及 已成为当前信息时代的一种极为重要的信息传播载体对社会的发展起到了巨大的推进作用且信息传播及时、便捷。据美国电脑工业年鉴公司估计 2010年全球互联网用户将超过7.65亿人。互联网络安全涉及到加密、计算机病毒防范、入侵检测、接入控制、网上媒体信息内容监管、安全管理、垃圾邮件处理等众多关键技术问题。在电子邮件为我们提供充分便利的同时不断产生的垃圾邮件和不良邮件也正在给我们的工作、生活制造着难以计数的麻烦和无法预计的危害。2004年11月份的数字显示垃圾邮件的比例接近74在发送的垃圾邮件中钓鱼欺诈性邮件占了24这使得它成为了增长速度最快的垃圾邮件类型其它数量较大的垃圾邮件类型包括广告23 、医疗11 、色情14 。 互联网络上存在着海量媒体信息 皆可能成为邮件的内容就给邮件的处理带来复杂多样性文字监管问题也就显得越来越重要 当然也越来越困难。虽然要求尽快建
立垃圾邮件相关的法律规范倡仪通过法律手段制裁垃圾邮件解决垃圾邮件问题但建立垃圾邮件相关的法律规范本身就是一个较长时间的一个过程且垃圾邮件仍然会存在、产生并在传播。 信息产业部、 中国互联网协会、 中国通信标准化协会2006年6月21日启动12321全国反垃圾邮件总动员活动普及反垃圾邮件知识营造绿色网络环境。中国互联网协会反垃圾邮件中心公布的调查结果显示 目前反垃圾邮件工作取得一定成效。从2006年3月到2006年6月 中国互联网用户收到的垃圾邮件比例由63.97%下降到61.99%。用户平均每周收到垃圾邮件数量为17.93封与2006年3月的每周19. 33封相比减少1.4封。这即说明反垃圾邮件仍是一个持续又长久的过程。尽管《互联网电子邮件服务管理办法》规定业已出台2006年3月30日起正式施行 但仍要采取各种必要的措施进行预防及使用这如同法律一样不可缺既要打击犯罪又要教育以预防犯罪。对邮件进行适时处理阻止垃圾邮件的泛滥成灾通过总结策略一般采用的是关键字内容过滤技术采取“截获样本、解析特征、生成规则、规则下发、 内容过滤” 这种类似传统杀病毒系统的原理。下面就对邮件的内容过滤模块作一简单研究分析。 2 内容过滤模块的总体设计邮件过滤系统设计思想主要是用来监控和拦截网络上传输的含有有害信息的邮件数据报。针对这一设计思想可以把网络邮件过滤系统的主要功能概括为以下几个模块[4] 。 (1)抓取数据报文即数据的分离过程 (2)对数据报文进行过滤分析对邮件SMTP POP3数据包进行组合 (3)查找设定的邮件地址、 IP地址等过滤条件对邮件内容中的M I ME编码进行解码还原出原始邮件内容对内容进行分析检索关键字对可疑邮件进行记录 (4)有关人员通过专
用的客户端软件查看可疑邮件并远程对软件的运行进行配置和管理。 图1普通电子邮件系统的SMTP服务过程 垃圾邮件有很强的繁殖力如果不加以整治就会对合法邮件造成危害干扰互联网络的正常工作。 电子邮件过滤技术是目前反垃圾邮件用到的主要技术。电子邮件过滤通常可以从两方面实现一种是基于客户端的垃圾邮件过滤一种是基于服务器端的垃圾邮件过滤。而在网络中对可疑邮件进行过滤、堵截的最佳方法是基于服务器端的垃圾邮件过滤 即通过在邮件服务器上加设邮件过滤器来实现邮件过滤。 普通电子邮件系统的SMTP服务过程如图1。 加了垃圾邮件过滤模块的电子邮件系统的服务过程如图2 图2.加了垃圾邮件过滤模块的电子邮件系统的服务过程 主要在于增添一个邮件数据提取接口。当来自于Internet的邮件被通过POP3等系统接收时 邮件数据提取接口将提取到的邮件数据内容送交邮件过滤服务器用户暂时不阅览该邮件而是等待邮件过滤服务器的控制命令。 内容过滤模块对邮件信息中的文本内容进行检查与过滤。检查的对象具体为邮件的其他部分内容、正文内容与文本附件内容。邮件过滤服务器根据预定义的策略和规则对邮件内容进行检查并采用多线程同时处理多封邮件实现对邮件内容快速扫描并利用关键词库完成匹配确定该邮件是否为合法邮件。 3 内容过滤模块中关键技术——多文档文本提取 多文档文本提取技术主要见图3.All_To_Txt模块所描述的文档模块流程情况从文档中提取出纯文本流再结合自动分词、词频统计、关键词提取等过程完成文本的提取。 图3. All_To_Txt模块文档模块 3. 1H TML文档的文本提取技术 超文本标记语言HTML是Web的通用语言是创建Web页和发布Web信息的格式是Web设计的基础是控
制Web浏览器在屏幕上显示内容的核心技术。 HTML用于编制可以在不同的平台上实施链接的超文本文件。 HT ML的标记可以表达超文本的新闻、邮件、文档及超媒体——包含在线的图形、视像的信息体。H TML文档具有最基本的结构框架“头”和“体” 。 HT ML文档均用于在浏览器上显示而支持HTTP的浏览器均为WINDOWS式的图形用户接口
GU I界面 因此HTML文档的基本结构是依据这一要求而设计确定的。一个GU I的视窗通常由标题栏和窗口体作为其最基本的构成。H TML文档结构的“头”和“体”正应于这一要求。 1 H TML容器标记 HT ML文档的第一个标记是HTML的容器标记它向浏览器指示其后的代码应使用由H TML制定的语法和结构规则来处理。相应的结束标记出现在文件的结尾处。 注意不要把HTML文档的任何文本放置在这两个标记的外面否则其结果是不可预见的。 2头标记head 和是一对头标签是标记文件头区域的分界线
„. 它包含着不在网页上直接实施或显示的项目。有在浏览器的标题栏中显示的文档标题名称title和该文档有关的属性参数。它是HTML文档的第一个部分是一个可选项。 尽管H TML规定一些元素只能在它的内部使用。 在文档头中能用于浏览显示的元素仅有标题title 其他的元素均不显示。 TITLE 标题也是一个可选元素用一对标签(„)标记定义了在浏览器的标题栏中显示的内容。标题元素总是嵌套在头元素中的。 3体标记body体BOD Y是HT ML文档中的主体反映在浏览器的屏幕的正文区域它包含了文档的内容——即在网页上可见的资料。 和是一对体标签用于标记„除了头以外的其余的文档内容。与头元素一样是一个复合元素可在体标签内嵌套其他的字符和元素。 4一个
最简单的HTML文档的组成 头和体结合就能组成一个HTML文档。
3.2 PDF文档的文本提取技术 PDF的文件结构(即物理结构)包括四个部分文件头、文件体、交叉引用表和文件尾。文件头(Header)指明了该文件所遵从PDF规范的版本号它出现在PDF文件的第一行。如PDF-1.2表示该文件格式符合PDF1.2规范。文件体(Body)由一系列的PDF间接对象组成。这些间接对象构成了PDF文件的具体内容如字体、页面、 图像等等。交叉引用表(Cross-reference Table)则是为了能对间接对象进行随机存取而设立的一个间接对象地址索引表。文件尾(Trailer)声明了交叉引用表的地址指明文件体的根对象(Catalog) 还保存了加密等安全信息。根据文件尾提供的信息 PDF的浏览器可以找到交叉引用表和整个PDF文件的根对象从而实现整个PDF文件的随机存取。 PDF文件主体文档架构反映了文件体中间接对象间的等级层次关系。 PDF的文档结构是一种树型结构。树的根节点就是PDF文件的根对象(Catalog) 。根节点下有四个子树页面树(PagesTree) 、书签树(Outline Hierarchy) 、线程树(Article Threads) 、名字树(Named Destinat ion) 。 PDF文本的物理格式主要描速文字如何显示在页面上包括文字的字体、大小、颜色、位置等属性在多数的PDF文件中一般为了减少文件的大小都会对文本流进行压缩编码常见是deflate压缩编码。压缩的文本流需要先进行解码然后才可以得到便于理解的文本流。 PDF文件文本内容的基本提取过程为先读取PDF文件可以根据查找、匹配特征标识符来查找到文本对象TextObject 分离出文本流Text Stream 进行Deflate解码得到含有文本内容的文本流根据语法分析生成正确的text格式。PDF文件的版本一般存放在文件的头部 PDF文件的其他一些信息可
以根据交叉应用表也可以根据特征标识符定位该部分信息。文件信息的提取主要是通过文件结构找出文件信息所在的位置然后通过语法分析分离出我们需要的部分在通过编码或语法转换使生成正确的格式。 由于文件的交叉引用表可能会出现损害可以根据特征标识符来定位文件的信息存放的位置。 转贴于3.3 MS-Word /PowerPoint文档的文本提取技术 Microsoft的Office产品中都提供了OLE Automati on 自动化程序的接口。如果你使用VB VBA和Script脚本调用Off ice功能的话其实比使用VC调用要简单的多。 比如在WORD中调出菜单“工具(T)宏(M)录制新宏(R)” 这时候它开始记录你在WORD中任何菜单和键盘的操作把你的操作过程保存起来 以便再次重复调用。而保存这些操作的记录其实就是使用了VBA程序Visual Basic for Application 。而我们下面要实现的功能也同样要参考VBA的方法。 为了更有逻辑更有层次地操作Office Microsoft把应用(Application)按逻辑功能划分为树形结构只有了解了逻辑层次我们才能正确的操纵Off ice。举例来讲如果给出一个VBScript语句是 "c:abc.doc"。那么我们就知道了这个操作的过程是第一步取得App l icati on第二步从Application中取得Act iveDocument第三步调用Document的函数SaveAs参数是一个字符串型的文件名。 使用的基本步骤为创建或打开已有的一个MFC的程序工程。按照VC6操作Ctrl+W执行ClassWizard Add Class. . .From a type Library. . .在Office 目录中找到你想使用的类型库Office2000中Word的类型库文件保存在C:Program FilesMicrosoft
Off i ceOff i ceMSWORD9.OLB 也可根据使用的Off ice版本从有关
表中查得相应的类型库文件。选择类型库文件后在弹出的对话窗中继续选择要添加的类。 初始化C OM方法一找到App的InitItance()函数在其中添加AfxOleInit()函数的调用方法二在需要调用COM功能的地方CoInitial ize(NULL) 调用完毕后CoUninitialize() 。在你需要调用Off ice功能函数的cpp文件中为了方便操作VARIANT类型变量使用CComVari ant模板类。 3.4 CHM文档的文本提取技术 CHM格式有一个初始化头 占38H字节后面是header section和到正文段的偏移量。加在一起这些被称为文件头。 header section一共有两个section一个是文件目录另一个包含着文件长度和一些未知信息。 初始化头 header section 0及header section 1本段共84个字节从这里开始往后都是数据块分为两种一种是列表块(listing chunks) 一种是索引块(index chunks)其中列表块的格式如下 开始是四个字节PMGL然后的四个字节是目录块尾部的空白区的长度或是quickref区域的长度第三双字恒为0第四双字是前一个列表块的块号如果这是第一个块该值为-1第五双字是后一个列表块的块号如果这是最后一块该值为-1从这里开始是目录列表项按文件名排序并且大小写不分 quickref区是从数据块的后面向前写每隔n个项出现一个quickref且n的值为1+(1<< “密度” ) 其格式从后至前为第一个字整个数据块中的项数第二个字从第0项到第n项之间的偏移量第三个字从第0项到第2n项之间的偏移量 以此类推 目录列表的每一项的格式如下 encint型名字长度后面是UTF-8编码的名称 encint型正文段 encint型偏移量 encint型长度其中偏移量是从解压缩之后的正文段的开始来计算的 同样长度也是表示解
压缩之后的长度。在目录中存在两种文件用户数据文件和格式信息文件格式信息文件以两个连续的冒号“ ”开头用户数据文件以“/”开头。 索引块前四个字节为PMG I后面四个字节是块尾部的quickref或是空白区的长度。从这里开始是目录索引项的开始每一个目录索引项的结构如下 enci nt型的名称长度 UFT-8编码的名称 以此名称开始的列表块的块号。 quickref的格式和排列与列表块中相同。 当有索引块的层次较多时将不再存储数据块号而是存储下一层的索引号。正文在版本3中正文一般紧跟着文件头而且在文件头表之后有一个双字用来指定其位置。在版本2中正文部分紧跟着文件头而且所有此类文件中的正文部分的第0段都放在这个位置上其它的正文段都放在within content section0名称列表文件 content section 0中文件名为
": :DataSpace/NameLi st"其中包含着所有正文段的名称其格式如下 第一个字 以字计数的文件长度第二个字文件中的entry数 对于每一个entry格式为 第一个字 以字计数的名字长度不包括最后的NULL结尾符 以word 0表示所有entry的结束。名称的编码类似于UFT-16。 段的名称目前为止只有两种Uncompressed和MSCompressed分别表示自解释文件和MicrosoftLZX压缩算法压缩的文件。 section data: 对于段号不为0的段还有一个文件为: :DataSpace/ StorageContent里面存放着该段的压缩信息所以当解析非0段时需要两步工作第一步取得第0段并将其解圧取得段名第二步才能利用段名找到相应的段。其余与格式相关的文件 : :DataSpacetorageControlData共0x20个字节存储关于压缩的信息 压缩段这一段用LZX压缩要进行解压
- 文件反垃圾邮件系统的内容过滤模块设计与实现(计算机应用范文)相关文档
- 梭子鱼梭子鱼垃圾邮件防火墙配置
- 教程邮件营销中容易被ISP检索的敏感字眼(垃圾关键词)
- 合作垃圾邮件关键词(国内邮箱)
- 概率基于内容的反垃圾邮件技术比较分析
- 过滤行为识别技术在反垃圾邮件系统中的应用
- 管辖权探析以服务器所在地为根据来确定反垃圾邮件案件管辖权
GreenCloudVPS$20/年多国机房可选,1核@Ryzen 3950x/1GB内存/30GB NVMe/10Gbps端口月流量2TB
GreencloudVPS此次在四个机房都上线10Gbps大带宽VPS,并且全部采用AMD处理器,其中美国芝加哥机房采用Ryzen 3950x处理器,新加坡、荷兰阿姆斯特丹、美国杰克逊维尔机房采用Ryzen 3960x处理器,全部都是RAID-1 NVMe硬盘、DDR4 2666Mhz内存,GreenCloudVPS本次促销的便宜VPS最低仅需20美元/年,支持支付宝、银联和paypal。Gree...

搬瓦工:香港PCCW机房即将关闭;可免费升级至香港CN2 GIA;2核2G/1Gbps大带宽高端线路,89美元/年
搬瓦工怎么样?这几天收到搬瓦工发来的邮件,告知香港pccw机房(HKHK_1)即将关闭,这也不算是什么出乎意料的事情,反而他不关闭我倒觉得奇怪。因为目前搬瓦工香港cn2 GIA 机房和香港pccw机房价格、配置都一样,可以互相迁移,但是不管是速度还是延迟还是丢包率,搬瓦工香港PCCW机房都比不上香港cn2 gia 机房,所以不知道香港 PCCW 机房存在还有什么意义?关闭也是理所当然的事情。点击进...
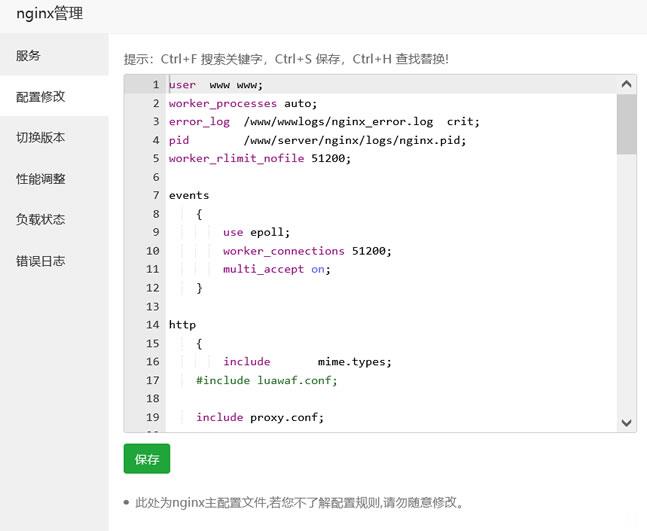
宝塔面板批量设置站点404页面
今天遇到一个网友,他在一个服务器中搭建有十几个网站,但是他之前都是采集站点数据很大,但是现在他删除数据之后希望设置可能有索引的文章给予404跳转页面。虽然他程序有默认的404页面,但是达不到他引流的目的,他希望设置统一的404页面。实际上设置还是很简单的,我们找到他是Nginx还是Apache,直接在引擎配置文件中设置即可。这里有看到他采用的是宝塔面板,直接在他的Nginx中设置。这里我们找到当前...
-
网页解密如何给网页解密手游运营手册游戏发展国主机开发怎么做 怎么开发主机1433端口如何打开SQL1433端口照片转手绘怎么把图片P成手绘qq怎么发邮件如何通过QQ发送邮件ejb开发EJB是什么?二层交换机什么是三层交换机?什么是二层叫交换机?有什么区别?电子商务网站模板做电子商务网站用什么cms或者模版比较好?Qzongqzong皮肤上怎样写字微信怎么看聊天记录什么方法可以知道微信的聊天记录