第3章数据在计算机中的表示
3.
1数据与数制计算机中使用的数据一般可以分为两大类:数值数据和字符数据.
数值数据常用于表示数的大小与正负;字符数据则用于表示非数值的信息,例如:英文、汉字、图形和语音等数据.
数据在计算机中是以电子器件的物理状态(如:开、关状态)来表示的,因此,各种数据在计算机中都是用二进制编码的形式来表示.
3.
1.
1数据及其分类1.
数据在计算机系统中,各种字母、数字符号的组合、语音、图形、图像等统称为数据,数据经过加工后就成为信息.
在计算机科学中,数据是指所有能输入到计算机并被计算机程序处理的符号的总称,是用于输入电子计算机进行处理,具有一定意义的数字、字母、符号和模拟量等的通称.
数据种类很多.
2.
数据分类(1)按性质分数据按性质可分为:①定位的,如各种坐标数据;②定性的,如表示事物属性的数据(居民地、河流、道路等);③定量的,反映事物数量特征的数据,如长度、面积、体积等几何量或重量、速度等物理量;④定时的,反映事物时间特性的数据,如年、月、日、时、分、秒等.
(2)按表现形式分数据按表现形式可分为:①数字数据,如各种统计或量测数据;②模拟数据,由连续函数组成,是指在某个区间连续变化的物理量,又可以分为图形数据(如点、线、面)、符号数据、文字数据和图像数据等,如声音的大小和温度的变化等.
(3)按记录方式分数据按记录方式可分为:地图、表格、影像、磁带、纸带.
按数字化方式分为矢量数据、格网数据等.
3.
1.
2数制数制是学习数据在计算机中表示的基础,不掌握数制的运算很难理解各种数据在计算机中的表示.
数制也称计数制,是指用一组固定的符号和统一的规则来表示数值的方法.
按进位的方法进行计数,称为进位计数制.
在日常生活和计算机中采用的是进位计数制.
在日常生活中,人们最常用的是十进位计数制,即按照"逢十进一"的原则进行计数的.
第3章数据在计算机中的表示43在进位计数制中有数码、数位(位置)、基数和位权等用语.
数码是在一个计数制中用来表示数值的符号;数位是指数码在一个数中所处的位置;基数是指在某种进位计数制中,每个数位上的数码所代表数值大小的基准数;位权是基数位置的幂次,表示数码在不同位置上所代表的数值.
例如,一个十进制数中每个数位上可以使用的数码为0、1、2、3、4、5、6、7、8、9十个数码,基数为十.
基数为十的进位计数制按"逢十进一"的原则进行计数.
数码所处的位置不同,代表数值的大小也不一样.
例如,在十进位计数制中,小数点左边第一位为个位数,其位权为100,第二位为十位数,其位权为101,第三位是百位数,其位权为102,……;小数点右边第一位是十分位数,其位权为101,第二位是百分位数,其位权为102,第三位是千分位数,其位权为103,…….
十进数的7675从右面起的第一位5是个位,第二位7是十位,第三位6是百位,第四位是7千位,…….
"个、十、百、千……"在数学上叫做"位权"或"权".
每一位上的数码与该位"位权"的乘积表示了该位数值的大小.
基数、位权和进位原则是进位计数制中的三个要素.
在微机中,常用的是十进制、二进制、八进制和十六进制,它们对应的关系如表31所示.
表31十进制、二进制、八进制、十六进制的对应关系十进制二进制八进制十六进制000011112102231133410044510155611066711177810001089100111910101012A11101113B12110014C13110115D14111016E15111117F1.
十进制数十进位计数制简称十进制.
十进制数具有下列特点:(1)基数:10.
(2)数码:0、1、2、3、4、5、6、7、8、9.
(3)每一个数码根据它在这个数中所处的位置(数位),按"逢十进一"来决定其实际数值,即各数位的位权是以10为底的幂次.
大学计算机基础——面向计算思维44例如(356.
456)10,以小数点为界,从小数点往左依次为个位、十位、百位,从小数点往右依次为十分位、百分位、千分位.
因此,小数点左边第一位6代表数值6,即6*100,第二位5代表数值50,即5*101;第三位3代表数值300,即3*102;小数点右边第一位4代表数值0.
4,即4*101;第二位5代表数值0.
05,即5*102;第三位6代表数值0.
006,即6*103.
因而该数可表示为如下形式:(356.
456)10=3*102+5*101+6*l00+4*101+5*102+6*103由上述分析可归纳出,任意一个十进制数D,可表示成如下形式:(D)10=Dn1*10n1+Dn2*10n2+…+D1*101+D0*100+D1*101+D2*102+…+Dm*10m式中Di(i:n1,n2,…,m1)为数位上的数码,其取值范围为0~9;n为整数位个数,m为小数位个数,10为基数,10n1,10n2,……,101,100,101,…l0m是十进制数的位权.
因为人们习惯使用十进制数,所以在计算机中,一般用十进制数作为数据的输入和输出.
2.
二进制数二进位计数制简称二进制.
二进制数具有下列特点:(1)基数:2.
(2)数码:0、1.
(3)每个数码根据它在这个数中的数位,按"逢二进一"来决定其实际数值.
例如:(11011.
01)2=1*24+1*23+0*22+1*21+1*20+1*21+0*22+1*23=(27.
625)10任意一个二进制数B,可以表示成如下形式:(B)2=Bn1*2n1+Bn2*2n2+…+B1*21+B0*20+B1*21+…+Bm*2m式中Bi为数位上的数码,其取值范围为0~1;n为整数位个数,m为小数位个数.
2为基数.
2n1,2n2,…,21,20,21,…,2m是二进制数的位权.
计算机中数的存储和运算都使用二进制数.
3.
八进制数八进位计数制简称八进制.
八进制数具有下列特点:(1)基数:8.
(2)数码:0、1、2、3、4、5、6、7.
(3)每个数码根据它在这个数中的数位,按"逢八进一"来决定其实际的数值.
例如:(432.
24)8=4*82+3*81+2*80+2*81+4*82=(282.
3125)10任意一个八进制数Q,可以表示成如下形式:(Q)8=Qn1*8n1+Qn2*8n2+…+Q1*81+Q0*80+Q1*81+…+Qm+1*8m+1+Qm*8m式中Qi为数位上的数码,其取值范围为0~7;n为整数位个数,m为小数位个数.
8为基数,8n1,8n2,……,81,80,81,……,8m是八进制数的位权.
八进制数是计算机中常用的一种计数方法,它可以弥补二进制数书写位数过长的不足.
4.
十六进制数十六进位计数制简称为十六进制.
十六进制数具有下列特点:(1)基数:16.
(2)数码:0、1、2、3、4、5、6、7、8、9、A、B、C、D、E、F.
由于数字只有0~9十个,而十六进制要使用十六个数字,而每位上只能有一个数码,所以用A~F六个英文字母分别表示数字10~15.
第3章数据在计算机中的表示45(3)每个数码根据它在这个数中的数位,按"逢十六进一"来决定其实际的数值.
例如:(A3B.
48)16=A*162+3*161+B*160+4*161+8*162=(2619.
28125)10任意一个十六进制数H,可表示成如下形式:(H)16=Hn1*16n1+Hn2*16n2+…+H1*161+H0*160+H1*161+…+Hm*16m其中Hi为数位上的数码,其取值范围为0~F;n为整数位个数,m为小数位个数.
16为基数,16n1,16n2,……,161,160,161,……,16m为十六进制数的位权.
十六进制数是计算机中常用的一种计数方法,它可以弥补二进制数书写位数过长的不足.
总结以上四种计数制,可将它们的特点概括为:(1)每一种计数制都有一个固定的基数R(R为大于1的整数),它的每一数位可取R个不同的数码,分别为0~R1;(2)每一种计数制都有自己的位权,并且遵循"逢R进一"的原则.
对于任一个R进位计数制数S,可表示为:(S)R=±(Sn1Rn1+Sn2Rn2+…+S1R1+S0R0+S1R1+…+SmRm)=miiin1SR-=-±式中Si表示各数位上的数码,其取值范围为0~R1,R为计数制的基数,i为数位的编号(整数位取n1~0,小数位取1~m).
另外,在表示十六进制数时,在数码后加H,如(A3B.
48)16,可写成A3B.
48H.
3.
1.
3不同进制数之间的转换不同进位计数制之间的转换,实质是基数间的转换.
一般转换的原则是:如果两个有理数相等,则两数的整数部分和小数部分一定分别相等.
因此,各数制之间进行转换时,通常对整数部分和小数部分分别进行转换.
1.
非十进制数转换成十进制数非十进制数转换成十进制数的方法是,把各个非十进制数按位权展开求和即可.
即把二进制数(或八进制数,或十六进制数)写成2(或8或16)的各次幂之和的形式,然后计算其结果.
【例31】把下列二进制数转换成十进制数.
(1110101)2=1*26+1*25+l*24+0*23+1*22+0*21+1*20=64+32+16+0+4+0+1=(117)10(10101.
101)2=1*24+0*23+1*22+0*21+1*20+1*21+0*22+1*23=16+0+4+0+1+0.
5+0+0.
125=(21.
625)10【例32】把下列八进制数转换成十进制数.
(305)8=3*82+0*81+5*80=192+5=(197)10(456.
124)8=4*82+5*81+6*80+1*81+2*82+4*83=256+40+6+0.
125+0.
03125+0.
0078125=(302.
1640625)10【例33】把下列十六进制数转换成十进制数.
(2A4F)16=2*163+A*162+4*161+F*160=8192+2560+64+15=(10831)10大学计算机基础——面向计算思维46(3B2F.
A8)16=3*163+B*162+2*161+F*160+A*161+8*162=12288+2816+32+15+0.
625+0.
03125=(15151.
65625)102.
十进制数转换成非十进制数(1)十进制数转换成二进制数把十进制数转换为二进制数的方法是:整数转换用"除2取余法";小数转换用"乘2取整法".
所谓除2取余法,就是将已知十进制数反复除以2,若每次相除之后余数为1,则对应于二进制数的相应位为1;余数为0,则相应位为0.
第一次除法得到的余数是二进制数的低位,最后一次余数是二进制数的高位.
从低位到高位逐次进行,直到商为0.
最后一次除法所得的余数为Kn1,则Kn1、Kn2、……、K1、K0即为所求的二进制数.
例如:将(100)10转换成二进制整数,其全过程可表示如下:余数2100025002251逆2120排260列2312110(100)10=(K6K5K4K3K2K1K0)2=(1100100)2十进制纯小数转换成二进制纯小数,采用乘2取整法,就是将已知十进制纯小数反复乘以2,每次乘2之后,所得新的整数部分为1,相应位为1,如果整数部分为0,则相应位为0.
从高位向低位逐次进行,直到乘2取整后的小数部分为0或满足精度要求,若保留m位小数,对m+1位小数进行0舍1入.
最后一次乘2所得的整数部分为Km.
转换后,所得的纯二进制小数为K1K2…Km.
例如:将(0.
625)10转换成纯二进制小数,转换过程如下:0.
625整数*2正11.
250…………整数部分=1,K1排*2列00.
500…………整数部分=0,K2*211.
000…………整数部分=1,K3(0.
625)10=(0.
K1K2K3)2=(0.
101)2再如:将(0.
6531)10转换成纯二进制小数,转换过程如下:第3章数据在计算机中的表示470.
6531整数*211.
3062…………整数部分=1,K1*200.
6124…………整数部分=0,K2*2正11.
2248…………整数部分=1,K3排*2列00.
4496…………整数部分=0,K4*200.
8992…………整数部分=0,K5*211.
7984…………整数部分=1,K6*211.
5968…………整数部分=1,K7*211.
1936…………整数部分=1,K8*200.
3872…………整数部分=0,K9如只取八位小数能满足精度要求,则得(0.
6531)10=(0.
K1K2……Km)2≈(0.
K1K2K3K4K5K6K7K8)=(0.
10100111)2可见,十进制纯小数不一定能转换成完全等值的二进制纯小数.
遇到这种情况时,根据精度要求,取近似值.
则(100.
6531)10≈(1100100.
10100111)2(2)十进制数转换成八进制数十进制数转换成八进制数的方法是:整数部分转换采用"除8取余法";小数部分转换采用"乘8取整法".
(3)十进制数转换成十六进制数将十进制数转换成十六进制数的方法是:整数部分转换采用"除16取余法";小数部分转换采用"乘16取整法".
3.
二进制数与十六进制数之间的转换(1)二进制数转换成十六进制数对于二进制整数,只要自右到左将每四位二进制数分为一组,不足四位时,在左面添0,补足四位;对于二进制小数,只要自左到右将每四位二进制数分为一组,不足四位时,在右面添0,补足四位,然后将每组用相应的十六进制数代替,即可完成转换.
大学计算机基础——面向计算思维48例如:把(1011000001101.
0100101)2转换成十六进制数.
(0001011000001101.
01001010)2(160D4A)16则(1011000001101.
0100101)2=(160D.
4A)16(2)十六进制数转换成二进制数将十六进制数转换成二进制数,只要将每一位十六进制数用四位相应的二进制数表示即可完成转换.
例如:将(18A3.
5E)16转换成二进制数.
(18A3.
5E)16(0001100010100011.
01011110)2则(18A3.
5E)16=(1100010100011.
0101111)24.
二进制数与八进制数之间的转换(1)二进制数转换成八进制数对于二进制整数,只要自右到左将每三位二进制数分为一组,不足三位时,在左面添0,补足三位;对于二进制小数,只要自左到右将每三位二进制数分为一组,不足三位时,在右面添0,补足三位,然后将每组用相应的八进制数代替,即可完成转换.
例如:把(101110111.
0100101)2转换成八进制数.
(101110111.
010010100)2(567.
224)8则(101110111.
0100101)2=(567.
224)8(2)八进制数转换成二进制数将八进制数转换成二进制数,只要将每一位八进制数用三位相应的二进制数表示即可完成转换.
例如:将(1703.
53)8转换成二进制数.
(170353)8(001111000011101011)2则(1703.
53)8=(1111000011.
101011)23.
2数值在计算机中的表示3.
2.
1数值编码1.
机器数在日常生活中我们用到的数有正有负,在计算机中,使用的是二进制数,只有0和1两第3章数据在计算机中的表示49种值.
那么在计算机中如何表示正负数呢把+、号也用0和1表示(0表示正号,1表示负号)放在存储器的最高位,数值的绝对值放在除符号位以外的部分,这种数值在计算机中的二进制表示形式,称为机器数,如图31所示.
图31在计算机中用一个字节表示一个数示意图机器数也有不同的表示法,常用的有3种:原码、补码和反码.
2.
真值机器数所对应的原来的数值称为该机器数的真值.
如机器数10011100的真值为28(0011100).
在数的表示中,机器数与真值的区别是:真值带符号如0011100(28),真值在机器中的表示形式为机器数10011100.
例如:真值数为+0111001(+57),其对应的机器数为00111001,其中最高位为0,表示该数为正数.
3.
原码、反码和补码机器数中,数值和符号全部数字化.
计算机在进行数值运算时,采用把各种符号位和数值位一起编码的方法.
常见的有原码、补码和反码表示法.
(1)原码原码表示法是机器数的一种简单的表示法.
其符号位用0表示正号,用l表示负号,数值一般用二进制形式表示.
设有一数为X,则原码表示可记作[x]原.
例如,X1=+0001010X2=0001010其原码记作:[X1]原=[+0001010]原=00001010[X2]原=[1001010]原=10001010原码表示数值的范围与二进制位数有关.
当用8位二进制原码来表示整数时,其表示范围:最大值为01111111,其真值为(127)10或为(+1111111)2;最小值为11111111,其真值为(127)10或为(1111111)2.
在原码表示法中,对0有两种表示形式:[+0]原=00000000[0]原=10000000(2)反码机器数的反码可由原码得到.
如果机器数是正数,则该机器数的反码与原码一样;如果机器数是负数,则该机器数的反码是对它的原码(符号位除外)各位取反而得到的.
设有一数X,则X的反码表示记作[X]反.
10011100数值位符号位大学计算机基础——面向计算思维50例如:X1=+0000110(+6)X2=1000110(6)那么[X1]原=00000110[X1]反=[X1]原=00000110[X2]原=10000110[X2]反=111111001当用8位二进制反码来表示整数时,其表示范围为:127~+127.
在反码表示法中,对0有两种表示形式:[+0]原=00000000[0]反=11111111(3)补码机器数的补码可由反码得到.
如果机器数是正数,则该机器数的补码与反码相同,当然也与原码一样;如果机器数是负数,则该机器数的补码是在其反的末位上加1.
设有一数X,则X的码表示记作[X]补.
例如:[+6]补=[+6]反=[+6]原=00000110[6]原=10000110[6]反=11111001[6]补=1111101011111001111111010在补码表示法中,对0的表示只有一种,即:[+0]补=00000000[0]补=00000000当用8位二进制补码来表示整数时,其表示范围为:最大为01111111,其真值为(127)10或为(+1111111)2;最小为10000000,其真值为(128)10或为(10000000)2.
补码在微型机中是一种重要的编码形式,请注意:1)采用补码后,可以方便地将减法运算转化成加法运算,运算过程得到简化.
正数的补码即是它所表示的数值的真值,而负数的补码的数值部份却不是它所表示的数的真值.
采用补码进行运算,所得结果仍为补码.
2)与原码、反码不同,数值0的补码只有一个,即[0]补=00000000.
[+0]原=00000000[0]反=1111111111111111+1100000000[0]补=00000000.
第3章数据在计算机中的表示513)若字长为8位,则补码所表示的范围为128~+127;进行补码运算时,应注意所得结果不应超过补码所能表示数的范围.
设有一数X,则X的补码表示记作[X]补.
例如,X1=+1110110X2=1101010那么,[X1]原=01110110[X1]补=01110110即[X1]原=[X1]补=01110110[X2]原=11101010[X2]反=10010101[X2]补=10010101+1=10010110【例34】已知[X]原=101110l0,求[X]补.
分析如下:由[X]原求[X]补的原则是:若机器数为正数,则[X]原=[X]补;若机器数为负数,则该机器数的补码可对它的原码(符号位除外)所有位求反,再在末位加l而得到.
现给定的机器数为负数,故有[X]补=[X]反+1,即[X]原=10111010[X]反=1100010111000101111000110[X]补=11000110【例35】已知[X]补=11110110,求[X]原.
分析如下:对于机器数为正数,则[X]原=[X]补;对于机器数为负数,则有[X]原=[[X]补]补;现给定的为负数,故有:[X]补=11110110[[X]补]反=1000100110001001110001010[[X]补]补=10001010=[X]原用补码表示法可以使减法运算成为加法运算.
例如49的运算如下:4的补码形式为:000001009的补码形式为:+1111011111111011大学计算机基础——面向计算思维52结果为11111011,是5的补码形式.
又如:(9)+(4)的运算如下:9的补码形式为:111101114的补码形式为:+11111100111110011最高位的1自动丢失,运算结果为11110011,是13的补码形式.
由上可见,利用补码可以方便地进行运算,在数的有效范围内,符号位如同数值一样参加运算,也允许产生最高位的进位(补自动丢失),所以使用较广泛.
3.
2.
2数值在计算机中的表示在计算机中,一般用若干个二进制位表示一个数或一条指令,把它们作为一个整体来处理、存储和传送.
这种作为一个整体来处理的二进制位串,称为计算机字.
表示数据的字称为数据字,表示指令的字称为指令字.
计算机是以字为单位进行处理、存储和传送的,所以运算器中的加法器、累加器以及其他一些寄存器,都选择与字长相同位数.
字长一定,则计算机数据字所能表示的数的范围也就确定了.
例如,使用16位字长的计算机,它可以表示无符号整数的最大值是(65535)10=(1111111111111111)2.
运算时,若数值超出机器数所能表示的范围,就会停止运算和处理,这种现象称为溢出.
1.
定点数计算机中运算的数,有整数,也有小数,如何表示整数和小数呢那就是规定小数点的位置固定不变,这时的机器数称为定点数.
(1)定点整数定点整数就是将小数点的位置固定在存储器的末端,这时机器数所表示的数就是纯整数.
假设机器字长为16位,符号位占1位,数值部分占15位,于是机器数:0111111111111111所表示的整数为十进制的+32767,如图32所示.
图32定点整数在计算机中的表示示意图16位定点整数补码表示数的范围:最大为0111111111111111,其真值为(215)10=(32767)10;最小为1000000000000000,其真值为(32768)10.
(2)定点小数定点小数就是将小数点的位置固定在符号位的右端,数值部分的左端,这时机器数所表数据位符号位0111111111111111固定小数点位第3章数据在计算机中的表示53示的数就是纯小数.
假设机器字长为16位,符号位占1位,数值部分占15位,于是机器数0111111111111111(即0.
111111111111111)所表示的纯小数为十进制的+(1215),如图33所示.
16位定点小数补码表示数的范围:最大为0.
111111111111111,其真值为(1215)10;最小为1.
000000000000000,其真值为(1)10.
图33定点小数在计算机中的表示示意图定点表示法所能表示的数值范围很有限,为了扩大定点数的表示范围,可以通过编程技术,采用多个字节来表示一个定点数,例如,采用4个字节或8个字节等.
2.
浮点数在计算机中处理的数,除整数处,大多处理的是实数,即既带整数又带小数的数.
在计算机中,为了能表示实数,采用浮点表示法.
在同样字长的情况下,浮点表示法能表示的数的范围扩大了,浮点表示法就是小数点在数中的位置是浮动的,浮点表示法由两部分组成,即尾数和阶码.
例如,0.
3125*103,则0.
3125为尾数,3是阶码.
在浮点表示法中,小数点的位置是浮动的,阶码可以取不同的数值.
例如,十进制数3125.
8125可表示为:3.
1258125*10+3、3125.
8125*100、3125812.
5*103等多种形式.
为了便于计算机中小数点的表示,规定将浮点数写成规格化的形式,即尾数的绝对值大于等于0.
1并且小于1,从而唯一地规定了小数点的位置.
十进制数3125.
8125以规格化形式表示为:0.
31258125*104.
对于任意二进制数在计算机中的浮点表示法包括两个部分:一部分是阶码(表示指数,记作E);另一部分是尾数(表示有效数字,记作M).
设任意一数N可以表示为:N=M2E其中2为基数,E为阶码,M为尾数.
假设机器字长为16位,阶码部分用一个字节表示,尾数部分用一个字节表示,则机器数0000011001000001所表示的数为十进制的+(21+27)26,即+32.
5,如图34所示.
其中:阶码E=(00000110)2=(6)10尾数M=(0.
1000001)2=(0.
5078125)10数值N=M2E=0.
5078125*26=(32.
5)10数据位符号位0111111111111111固定小数点位大学计算机基础——面向计算思维54图34浮点数在计算机中的表示示意图由尾数部分隐含的小数点位置可知,尾数总是≤1的数字,它给出该浮点数的有效数字.
尾数部分的符号位确定该浮点数的正负.
阶码给出的总是整数,它确定小数点浮动的位数,若阶符为正,则相当于小数点向右移动;若阶符为负,则相当于小数点向左移动.
浮点数表示法对尾数有如下规定:1/2≤MN^n~1111SIUS/O_oDEL大学计算机基础——面向计算思维56由表34可知,ASCII码字符可分为两大类:(1)打印字符:即从键盘输入并显示的95个字符,如大、小写英文字母各26个(小写字母的ASCII值比大写字母的ASCII值大32),数字0~9这10个数字字符的高3位编码(d6d5d4)为011,低4位为0000~1001.
当去掉高3位时,低4位正好是二进制形式的0~9.
(2)不可打印字符:共33个,其编码值为0~31(0000000~0011111)2和(1111111)2,不对应任何可印刷字符.
不可打印字符通常为控制符,用于计算机通信中的通信控制或对设备的功能控制.
如编码值为127(1111111),是删除控制DEL码,它用于删除光标之后的字符.
ASCII码字符的码值可用7位二进制代码或2位十六进制来表示.
例如字母D的ASCII码值为(1000100)2或84H,数字4的码值为(0110100)2或34H等.
计算机内部存储与操作常以字节为单位,即8个二进制位为单位.
因此一个英文字符在计算机内实际是用8位表示.
在正常情况下,最高位d7为0.
在需要奇偶校验时,这一位可用于存放奇偶校验的值,此时称为校验位.
2.
扩展ASCII码字符计算机内部存储与操作常以字节为单位,而ASCII码字符是用7位二进制数表示一个字符,在一个字节中,高位全为0,这就造成一个二进制位的浪费.
因此有的单位或部门就对ASCII码字符进行了扩展,用8位二进制数表示一个英文字符,这就是扩展ASCII码字符.
EBCDIC就是典型的扩展ASCII码字符.
EBCDIC(ExtendedBinaryCodedDecimalInterchangeCode)为国际商用机器公司(IBM)于1963~1964年间推出的字符编码表,根据早期打孔机式的二进化十进数(BCD,BinaryCodedDecimal)排列而成.
在了解了数值与英文字符在计算机内的表示后,读者可能会产生一个问题:二者在计算机内都是二进制数,如何区分数值和英文字符呢例如,内存中存放一个二进制数:01000010,它究竟表示数值66,还是表示字母"B"而对一个孤立的字节,确实无法区分,但存放和使用这个数据的软件,会以其他方式保存有关的类型信息,指明这个信息是何种类型.
以下汉字信息也是如此.
3.
3.
2汉字字符在计算机中的表示汉字是汉语书写的最基本单元,其使用最晚始于商代,历经甲骨文、大篆、小篆、隶书、楷书(草书、行书)诸般书体变化.
秦始皇统一中国,李斯整理小篆,"书同文"的历史从此开始.
尽管汉语方言发音差异很大,但是书写系统的统一减少了方言差异造成的交流障碍.
三千余年来,汉字的书写方式变化不大,使得后人得以阅读古文而不生窒碍.
但近代西方文明进入东亚之后,整个汉字文化圈的各个国家纷纷掀起了学习西方的思潮,其中,放弃使用汉字是这场运动的一个重要方面.
这些运动的立论以为:跟西方拼音文字相比,汉字是繁琐笨拙的.
许多使用汉字的国家即进行了不同程度的汉字简化,甚至还有完全拼音化的尝试.
日文假名的拉丁转写方案以及汉语多种拼音方案的出现都是基于这种思想.
中国大陆将汉字笔划参考行书草书加以省简,于1956年1月28日审订通过《简化字总表》,在中国及新加坡使用至今.
中国香港、台湾地区则一直使用繁体中文.
目前在使用汉语的地区,大都使用两种规范汉字,分别是繁体中文(繁体字)和简体中文(简体字).
英文文字是拼音文字,所有文字均由26个字母拼组而成,所以使用一个字节表示一个字第3章数据在计算机中的表示57符足够了.
但汉字是象形文字,汉字的计算机处理技术比英文字符复杂得多,一般用两个字节表示一个汉字.
1.
汉字输入码汉字输入码也叫外码,是为了通过键盘字符把汉字输入到计算机中而设计的一种编码.
英文输入时,想输入什么字符便按什么键,输入码和内码是一致的.
而汉字输入则不同,可能要按几个键才能输入一个汉字.
汉字和键盘字符组合的对应方式称为汉字输入编码方案.
外码是针对不同汉字输入法而言的,通过键盘按某种输入法进行汉字输入时,人与计算机进行信息交换所用的编码称为"汉字外码".
对于同一汉字而言,输入法不同,其外码也是不同的.
例如,对于汉字"啊",在区位码输入法中的外码是1601,在拼音输入中的外码是a,而在五笔字型输入法中的外码是kbsk.
汉字的输入码一般采用英文小写字母编码,所以输入汉字时,键盘应处在小写状态.
汉字的输入码种类繁多,可分以下4种类型,音码、形码、音形码、形音码.
衡量一个输入码的优劣标准如下:l编码短,可以减少击键次数;l重码少,可以实现盲打;l好学好记,便于学习和掌握.
但到目前为止,还没有一种全部符合上述要求的汉字输入方法.
(1)音码音码输入码主要是以汉语拼音为基础进行拼音输入的编码方案,如全拼、简拼、智能ABC、搜狗输入法等.
优点是简单易学,甚至不需要再学习,与人们习惯一致.
缺点是汉字同音多,即重码字多,输入汉字时要选字,则输入速度慢.
搜狗输入法可以以词组为单位,很好地弥补了重码字多、输入速度慢的不足.
(2)形码形码输入码主要是根据汉语的特点,按汉字固有的形状,把汉字先拆分成部首,然后组合进行拼形输入的编码方案,如首尾码输入法、五笔字型输入法、郑码输入法等.
优点是不考虑字的读音,见字识码,重码字少,输入速度快,强化训练后可以实现盲打.
缺点是拆字法没有统一的国家标准,拆字难,编码规则繁,记忆量大,需要学习和记忆.
五笔字型输入法使用广泛,适合专业录入人员,可实现盲打,但必须记住字根、掌握汉字的间架结构和书写顺序,学会拆字和形成编码.
(3)音形码音形码输入码集拼音与拼形于一体,以拼音为主,兼顾拼形的编码方案,如音形码、自然码、钱码等.
优点是它兼容了拼音、拼形输入的优点,大大减少了重码汉字,提高了输入速度.
缺点是既要考虑字音,又要考虑字形,编码比较麻烦.
(4)形音码形音码输入码集拼形与拼音于一体,以拼形为主,兼顾拼音形的编码方案,它兼容了拼形、拼音输入的优点,几乎没有重码汉字.
典型代表是形音码输入法,兼容了五笔字输入法和拼音输入法,并且对两种输入法进行适当调整的一种编码.
(5)数字码数字码也称流水码,它是用0~9十个数字字符进行编码的编码方案,如电报码、区位码大学计算机基础——面向计算思维58等.
优点是无重码,不仅能对汉字编码,还能对各种字母、数字符号进行编码.
缺点是人为规定的编码,属于无理码,只能作为专业人员使用.
(6)基于模式识别的智能化输入法模式识别与智能系统是在信号处理、人工智能、控制论、计算机技术等学科基础上发展起来的新型学科.
该学科以各种传感器为信息源,以信息处理与模式识别的理论技术为核心,以数学方法与计算机为主要工具,探索对各种媒体信息进行处理、分类、理解,并在此基础上构造具有某些智能特性的系统或装置的方法、途径与实现,以提高系统性能.
基于模式识别的智能化汉字输入法就是在此基础上产生的,如语音识别输入、手写输入法、扫描输入法等.
现在汉字输入法还在进一步研究中,将来有一天,汉字输入不再是人们使用计算机的瓶颈,人们坐在电脑前,畅游在计算机世界里,尽情享受着计算机世界带给我们的快乐与便利.
不管哪种汉字输入法,都是操作者向计算机输入汉字的手段,而在计算机内部都是以汉字机内码表示和存储的.
2.
汉字国标码汉字国标码也叫汉字交换码,主要是用作汉字信息交换的.
1980年,为了使每个汉字有一个全国统一的代码,我国颁布了汉字编码的国家标准:GB2312-80《信息交换用汉字编码字符集(基本集)》,这就是国标码,简称GB码.
这个字符集是我国中文信息处理技术的发展基础,也是目前国内所有汉字系统的统一标准.
国标码是一个四位十六进制数,区位码是一个四位的十进制数,每个国标码或区位码都对应着一个唯一的汉字或符号,但因为十六进制数我们很少用到,所以大家常用的是区位码,它的前两位叫做区码,后两位叫做位码.
在国标GB2312-80中有6763个常用汉字.
国标GB2312规定,所有的国标汉字与符号组成一个94*94的矩阵.
在此方阵中,每一行称为一个"区",每一列称为一个"位",因此,这个方阵实际上组成了一个有94个区(区号分别为01~94)、每个区内有94个位(位号分别为01~94)的汉字字符集.
一个汉字所在的区号和位号简单地组合在一起就构成了该汉字的"区位码".
在汉字的区位码中,高两位为区号,低两位为位号.
由此可见,区位码与汉字或符号之间是一一对应的.
区号对应第一字节,位号对应第二字节.
01~09区为符号、数字区,16~87区为汉字区,10~15区、88~94区是有待进一步标准化的空白区.
GB2312将收录的汉字分成两级:第一级是常用汉字计3755个,置于16~55区,按汉语拼音字母/笔形顺序排列;第二级汉字是次常用汉字计3008个,置于56~87区,按部首/笔画顺序排列.
汉字区位码并不等于国标码,国标码是由区位码稍作转换得到的,其转换方法为:将十进制区码和位码各加32(或将十进制区码和位码转换为十六进制的区码和位码,再将区码和位码各加十六进制的20H)就构成了国标码.
如"啊"字的区位码为1601,则"啊"字的国标码为4833(3021H),它是经过下面的转换得到的:16+32=48,01+32=33(或(16)10=(10H)16,(01)10=(01H)16,10H+20H=30H,01H+20H=21H).
3.
汉字机内码汉字机内码,简称"内码",指计算机内部存储,处理加工和传输汉字时所用的二进制编码.
输入码被接受后就由汉字操作系统的"输入码转换模块"转换为机内码,与所采用的键盘输入法无关.
机内码是汉字最基本的编码,不管是什么汉字系统和汉字输入方法,输入的汉字外码到机器内部都要转换成机内码,才能被存储和进行各种处理.
国标码是汉字信息交换的标准编码,但因其前后字节的最高位为0,与ASCII码发生冲突,第3章数据在计算机中的表示59如"啊"字,国标码为30H和21H,而英文字符"0"和"!
"的ASCII码也为30H和21H,现假如内存中有两个字节为30H和21H,这到底是一个汉字,还是两个英文字符"0"和"!
"呢于是就出现了二义性,显然,国标码是不可能在计算机内部直接采用的,于是,汉字的机内码采用变形国标码,其变换方法为:将国标码的每个字节都加上十进制128(十六进制80H),即将两个字节的最高位由0改1,其余7位不变,如:由上面我们知道,"啊"字的国标码为3021H,前字节为(00110000)2,后字节为(00100001)2,高位改1为(10110000)2,后字节为(10100001)2,即为(1011000010100001)2,即为B0A1H.
因此,汉字"啊"的机内码就是B0A1H.
请大家自己计算一下"中"字的机内码.
显然,汉字机内码的每个字节都大于128,这就解决了与西文字符的ASCII码冲突的问题.
如上所述,汉字输入码、区位码、国标码与机内码都是汉字的编码形式,它们之间有着千丝万缕的联系,但其间的区别也是不容忽视的.
4.
汉字字型码汉字字型码又称汉字字模,用于汉字在显示屏或打印机输出.
汉字字型码通常有两种表示方式:点阵和矢量表示方法.
用点阵表示字型时,汉字字型码指的是这个汉字字型点阵的代码.
根据输出汉字的要求不同,点阵的多少也不同.
简易型汉字为16*16点阵,提高型汉字为24*24点阵、32*32点阵、48*48点阵等,如图35所示.
图3516*16点阵汉字字形码示意图汉字字形点阵规模愈大,字型愈清晰美观,所占存储空间也愈大.
以16*16点阵为例,存储一个汉字要占16*16/8=32个字节.
把所有汉字字形所构成的集合叫汉字库,汉字库分为点阵字库和矢量字库.
点阵字模占的存储空间较大,而且不同的点阵字模要有不同的汉字字库,所以汉字字库一般在外存存放,当显示输出汉字时才检索字库,输出相应的字模得到相应的字形.
大学计算机基础——面向计算思维60矢量表示方式存储的是描述汉字字型的轮廓特征,当要输出汉字时,通过计算机的计算,由汉字字型描述生成所需大小和形状的汉字点阵.
矢量化字型描述与最终文字显示的大小、分辨率无关,因此可以产生高质量的汉字输出.
Windows中使用的TrueType技术就是汉字的矢量表示方式.
TrueType(简称TT)是由美国Apple公司和Microsoft公司联合提出的一种新型数字化字形描述技术.
TT是一种彩色数字函数描述字体轮廓外形的一套内容丰富的指令集合,这些指令中包括字型构造、颜色填充、数字描述函数、流程条件控制、栅格处理器(TT处理器)控制、附加提示信息控制等指令.
TT采用几何学中的二次B样条曲线及直线来描述字体的外形轮廓,二次B样条曲线具有一阶连续性和正切连续性.
抛物线可由二次B样条曲线来精确表示,更为复杂的字体外形可用B样长曲线的数学特性以数条相接的二次B样条曲线及直线来表示.
描述TT字体的文件(内含TT字体描述信息、指令集、各种标记表格等)可能通用于Mac和PC平台.
在Mac平台上,它以"Sfnt"资源的形式存放,在Windows平台上以TTF文件出现.
为保证TT的跨平台兼容性,字体文件的数据格式采用Motorola式数据结构(高位在前,低位在后)存放.
所有Intel平台的TT解释器在执行之前,只要进行适当的预处理即可.
Windows的TT解释器已包含在其GDI(图形设备接口)中,所以任何Windows支持的输出设备,都能用TT字体输出.
TT技术具有以下优势:(1)真正的所见即所得效果.
由于TT支持几乎所有的输出设备,因而对于目标输出设备而言,无论系统的屏幕、激光打印机或激光照排机,所有在操作系统中安装了TT字体均能在输出设备上以指定的分辨率输出,所以多数排版类应用程序可以根据当前目标输出设备的分辨率等参数,来对页面进行精确的布局.
(2)支持字体嵌入技术,保证文件的跨系统传递性.
TT嵌入技术解决了跨系统间的文件和字体的一致性问题.
在应用程序中,存盘的文件可将文件中使用的所有TT字体采用嵌入方式一并存入文件.
使整个文件及其所使用的字体可方便地传递到其他计算机的同一系统中使用.
字体嵌入技术保证了接收该文件的计算机即使未安装所传送文件使用的字体,也可通过装载随文件一同嵌入的TT字体来对文件进行保持原格式,使用原字体进行打印和修改.
(3)操作系统平台的兼容性.
Mac和Windows平台均提供系统级的TT支持.
所以在不同操作系统平台间的同名应用程序文件有跨平台兼容性.
如Mac机上的PageMaker可以使用在如果已安装了文件中所用的所有TT字体,则该文件在Mac上产生的最终输出效果将与在Windows下的输出保持高度一致.
(4)ABC字宽值.
在TT字体中的每个字符都有其各自的字宽值,TT所用的字宽描述方法比传统的PS的Type1更为完善和科学.
它采用ABC字宽表,即将传统上的一个字符的字宽值划分为三部分:A宽度为在放置字符轮廓前的空白间距,B宽度为字符轮廓本身的间距,C为字符轮廓右方的空白间距.
A+B+C即相当于传统的字宽值,同时A或C间距可以分别为负值,以产生特殊的排字效果.
采用ABC字宽值可避免传统上使用整字字宽值而引起的累积舍入误差.
同时可以避免由此产生的行尾的最后一个字符移至下一行,或行左首字符无法对齐等输出时不可预料的后果.
排版应用程序在计算一行的累积字宽时所产生的舍入误差,可以分散到整行中每一字符的A和C间距中,保证了断行的高度准确性和用户定义的左右边界尺寸第3章数据在计算机中的表示61的精确性.
在Windows98以上系统中,系统使用得最多的就是*.
TTF(TrueType)轮廓字库文件,它既能显示也能打印,并且支持无极变倍,在任何情况下都不会出现锯齿问题.
而*.
FOT则是与*.
TTF文件对应的字体资源文件,它是TTF字体文件的资源指针,指明了系统所使用的TTF文件的具体位置,而不用必须指定到FONTS文件夹中.
*.
FNT(矢量字库)和*.
FON(显示字库)的应用范围都比较广泛.
另外,那些使用过老版本的WPS的用户可能对*.
PS文件还有一定的印象,*.
PS实际上是DOS下轮廓字库的一种形式,其性能与*.
TTF基本类似,采用某些特殊方法之后,我们甚至还可以实现在Windows中直接使用这些*.
PS字库(*.
PS1、*.
PS2都是PS字库).
点阵字形与矢量字形的区别是:点阵字形编码、存储方式简单,显示和打印汉字时不需要转换,直接在字库中取字形输出即可,但字形放大后产生的效果差,而且同一种字体不同的点阵需要不同的汉字库.
矢量字形正好与前者相反.
5.
汉字地址码每个汉字字形码在汉字字库中的相对位移地址称为汉字地址码.
需要向输出设备输出汉字时,必须通过地址码,才能在汉字字库中找到所需要的汉字字形码位置,取出所需要的字形,最终在输出设备上形成可见的汉字字形.
为了能快速地找到所需要的汉字字形码,地址码和机内码要有简明的对应转换关系.
综上所述,在一个汉字处理系统中,输入、内部处理和输出汉字,对汉字的编码要求也不一样,因此要进行一系列的汉字编码及转换.
汉字信息处理中各编码及流程如图36所示.
图36汉字信息处理系统模型6.
其他汉字编码除GB码外,目前常用的还有:UCS码、Unicode码、GBK、Big5码等.
(1)UCS码为了统一表示世界各国、各地区的文字,便于全球范围的信息交流,1993年,国际标准化组织公布了名为"通用多八位编码字集"的国际标准ISO/IEC10646(UniversalMultipleOctetCodedCharacterSet,UCS).
UCS为世界上正在使用的各种文字,规定了统一的编码方案,为多文种的信息交换和信息处理创造了基本条件.
UCS是所有其他字符集标准的一个超集.
它保证与其他字符集是双向兼容的,也就是说,如果将任何文本字符串翻译到UCS格式,然后再翻译回原编码,不会丢失任何信息.
UCS整个字符集可以容纳128组,每组有256个平面,每个平面有256行,每行有256个字位,这样大的空间完全包容世界上的所有文字.
全世界的字符在UCS中用4个字节(组号、平面号、行号、和字位号)唯一地表示.
第一个平面(00组中的00平面)称为基本多文种平面(BMP).
它包含字母文字、音节文字和表意文字等.
它分为四个区:A、I、O、R.
输入码汉字输入国际码机内码地址码字形码汉字输出大学计算机基础——面向计算思维62A区:19903个字位,用于字母文字、音节文字和各种符号;I区:20992个字位,用于中、日、韩(CJK)统一的表意文字;O区:16384个字位,留于未来标准化用.
R区:8190个字位,作为基本多文种平面的限制使用区,它包括专用字符、兼容字符等.
例如,ASCII码字符"A",它的ASCII码为41H,它在UCS中的编码为00000041H.
汉字"大",它在GB2312中编码为3473H,它在UCS中的编码为00005927H.
UCS的实际表现形式为UTF8/UTF16/UFT32编码.
(2)Unicode码Unicode是另一个国际编码标准,采用双字节表示世界上的主要文字,其字符集与UCS的BMP相同.
内容包含符号6811个、汉字20902个(其中:大陆提出的汉字17124个,台湾提出的汉字17258个,并集后共提出的汉字为20158个,未提出字符共744个).
韩文拼音11172个,造字区6400个,保留20249个,共计65534个.
由于UCS中每个字符需要用4个字节表示,消耗的存储空间也就多.
事实上全世界正在使用的各种文字,经常使用的只是其中的一部分,其数量不足65536(216),因此,UCS字符集中最前面一部分,即0组的0号平面被规定为"基本多文种平面"(BMP),用于放置全世界的主要文字、音节文字和包括控制符在内的各种符号.
"基本多文种平面"的字符,其4字节代码的前2字节都是0,在绝大多数应用场合,可以用后2个字节作为其代码.
这就构成了Unicode代码,以2字节统一表示世界上的主要文字,得到越来越广泛的应用.
支持Unicode编码的相关电脑系统软件,如UNIX、Windows已有推出,但是由于Unicode的ASCII码是用双字节编码(即一般电脑系统中的单字节ASCII码前加0x00),同时其汉字编码与各国的现有编码也不兼容,造成现有的软件和数据不能直接使用,所以目前完全使用Unicode软件系统的用户并不多,大多数只将它作为一个国际语言编码标准来使用.
(3)GBK码GBK全称《汉字内码扩展规范》(GBK即"国标""扩展"汉语拼音的第一个字母,英文名称:ChineseInternalCodeSpecification),中华人民共和国全国信息技术标准化技术委员会于1995年12月1日制订,国家技术监督局标准化司、电子工业部科技与质量监督司于1995年12月15日联合以技监标函〔1995〕229号文件的形式,将它确定为技术规范指导性文件.
这一版的GBK规范为1.
0版.
GBK向下与GB2312编码兼容,向上支持ISO10646.
1国际标准,是前者向后者过渡过程中的一个承上启下的产物.
我国1993年发布的GB13000.
1国家标准等同于UCS.
GBK编码是在GB2312-80标准基础上的内码扩展规范,使用了双字节编码方案,其编码范围从8140至FEFE(剔除xx7F),共23940个码位,收录了21003个汉字,882个符号,共计21885个字符.
完全兼容GB2312-80标准,支持国际标准ISO/IEC10646-1和国家标准GB13000-1中的全部中日韩汉字,并包含了Big5编码中的所有汉字.
目前中文版的Windows等都支持GBK编码方案.
全拼、紫光拼音等输入法,能够录入如"镕、镕、炁、夬、喆、嚞、姤、赟、龑、昳、堃、慜、靕、臹"等GBK简繁体汉字.
(4)Big5码Big是在1984年由中国台湾地区13家厂商与台湾地区财团法人信息工业策进会为五大中第3章数据在计算机中的表示63文套装软件(宏碁、神通、佳佳、零壹、大众)所设计的中文内码,所以就称为Big5中文内码,虽然五大套装软件并没有成功,但Big5码却深远地影响了中文电脑内码,直至今日.
"五大码"的英文名称"Big5"后来被人按英文字序译回中文,以致现在有"五大码"和"大五码"两个中文名称.
Big5码,是通行于中国台湾、香港地区的一个繁体字编码方案.
大五码是使用繁体中文社群中最常用的电脑汉字字符集标准,共收录13060个中文字.
Big5虽普及于中国的台湾、香港与澳门等繁体中文通行区,但长期以来并非当地的国家标准,而只是业界标准.
倚天中文系统、Windows等主要系统的字符集都是以Big5为基准,但厂商又各自增删,衍生出多种不同版本.
2003年,Big5被收录到台湾官方标准的附录当中,取得了较正式的地位.
这个最新版本被称为Big5-2003.
(5)关于汉字编码为进行信息交换,各汉字使用地区都制订了一系列汉字字符集标准.
1)GB2312-80字符集,收入6763个汉字,682个符号,共计7445个字符.
这个字符集是我国中文信息处理技术的发展基础,也是目前国内所有汉字系统的统一基础标准.
2)GB2313字符集,收入汉字6763个,符号715个,总计7478个字符,这是大陆普遍使用的简体字符集.
楷体GB2313、仿宋GB2313、华文行楷等市面上绝大多数字体支持显示这个字符集,亦是大多数输入法所采用的字符集.
市面上绝大多数所谓的繁体字体,其实采用的是GB2313字符集简体字的编码,用字体显示为繁体字,而不是直接用GBK字符集中繁体字的编码,错误百出.
3)BIG5字符集,收入13060个繁体汉字,808个符号,总计13868个字符,目前普遍使用于中国的台湾、香港等地区.
台湾教育部标准宋体、楷体等港台大多数字体支持这个字符集的显示.
4)GBK字符集,又称大字符集(GB=GuóBiāo国标,K=扩展),包含以上两种字符集汉字,收入21003个汉字,882个符号,共计21885个字符,包括了中日韩(CJK)统一汉字20902个、扩展A集(CJKExtA)中的汉字52个.
Windows95\98简体中文版就带有这个GBK.
txt文件.
宋体、隶书、黑体、幼圆、华文中宋、华文细黑、华文楷体、标楷体(DFKaiSB)、ArialUnicodeMS、MingLiU、PMingLiU等字体支持显示这个字符集.
Big5(繁体中文)与GB2313(简体中文)编码不相兼容,字符在不同的操作系统中会产生乱码.
文本文字的简体与繁体(文字及编码)之间的转换,可用BabelPad、TextPro或Convertz之类的转码软件来解决.
若是程序,如WindowsXP操作系统,可用MicrosoftAppLocaleUtility1.
0解决;Windows2000的操作系统,可用:中文之星、四通利方、南极星、金山快译之类的转码软件解决.
5)GB18030字符集,是我国继GB2312-1980和GB13000.
1-1993之后最重要的汉字编码标准,是我国计算机系统必须遵循的基础性标准之一.
GB18030有两个版本:GB18030-2000和GB18030-2005.
GB18030-2000是GBK的取代版本,它的主要特点是在GBK基础上增加了CJK统一汉字扩充A的汉字.
GB18030-2005的主要特点是在GB18030-2000基础上增加了CJK统一汉字扩充B的汉字.
它还去掉了单字节编码的欧元符号80H.
GB18030有1611668个码位,在GB18030-2005中定义了76556个字符.
随着我国汉字大学计算机基础——面向计算思维64整理和编码研究工作的不断深入,以及国际标准ISO/IEC10646的不断发展,GB18030所收录的字符将在新版本中增加.
6)方正超大字符集,包含GB18030字符集、CJKExtB中的36862个汉字,共计64395个汉字.
宋体方正超大字符集支持这个字符集的显示.
MicrosoftOfficeXP或2003简体中文版就自带这个字体.
Windows2000的操作系统需安装超大字符集支持包"Surrogate更新".
7)ISO/IEC10646/Unicode字符集,这是全球可以共享的编码字符集,两者相互兼融,涵盖了世界上主要语文的字符,其中包括简繁体汉字,计有:CJK统一汉字20902个,CJKExtA6582个,ExtB42711个,共计70195个汉字.
SimSunExtB(宋体)、MingLiUExtB(细明体)能显示全部ExtB汉字.
至今尚无单独一款字体能够显示全部70195个汉字,但可用海峰五笔、新概念五笔、仓颉输入法世纪版、新版的微软新注音、仓颉输入法6.
0版(单码功能)等输入法录入.
ExtC还有2万多个汉字.
详情请参阅香港中文大学网站、马来西亚仓颉之友网站、福建陈清钰个人网站.
8)汉字构形数据库2.
3版,内含楷书字形60082个、小篆11100个、楚系简帛文字2627个、金文3459个、甲骨文177个、异体字12768组.
可以安装该程序,亦可以解压后使用其中的字体文件,对于整理某些古代文献十分有用.
如果超出了输入法所支持的字符集,就不能录入计算机.
如果没有相应字体的支持,则显示为黑框、方框或空白.
如果操作系统或应用软件不支持该字符集,则显示为问号(一个或两个).
在网页上亦存在同样的情况.
3.
4图形和图像在计算机中的表示3.
4.
1图形在计算机中的表示1.
图形在计算机中图形和图像是两个不同的概念.
图形一般是指通过绘图软件绘制的由直线、圆、圆弧、矩形、任意曲线等几何图形组成的画面.
2.
图形在计算机中的表示图形是一种矢量图.
矢量图是用数学的方式来描述一幅图形.
矢量图形的描述包括形状、色彩、位置等.
矢量图形本身就用数字化形式来表述.
图形的最大优点在于可以分别控制处理图中的各个部分,如在屏幕上移动、旋转、放大、缩小而不失真,不同的物体还可以在屏幕上重叠并保持各自的特性,必要时仍可分开.
但对于一幅复杂的彩色照片,很难用数学来描述,因此也难以用矢量图来表示.
3.
4.
2图像在计算机中的表示1.
图像图像是由扫描仪、照像机、摄像机等输入的画面.
形一般是指通过绘图软件绘制的由直线、圆、圆弧、矩形、任意曲线等几何图形组成的画面.
2.
静态图像在计算机中的表示自然景物成像后可以复制成照片、录像带进行保存,这样的图像称为模拟图像.
它们是第3章数据在计算机中的表示65连续的,不能直接用计算机进行处理,还需要进一步转化处理.
静态图像在计算机中是用位图来表示的,位图也叫点阵图像,是由若干个排列成行、列的点构成,这些点称为像素(Pixels),用以描述图像中各点的明暗强度与颜色.
每个像素点的亮度和颜色信息用若干数据位来表示,这些数据位的个数称为图像的颜色深度或灰度级.
图像的数字化就是将模拟图像转化成位图的过程,通常包括采样和量化.
采样就是将连续的模拟图像变换成离散点的操作过程.
在这个过程中,采样间隔是个重要参数,它决定了在一定的面积内取多少个像素点.
在同等面积内,像素点数越多,分辨率就越高,图像质量越好.
采样后,图像成为离散的像素点,但其灰度仍是连续的.
还需要将像素的灰度转换成离散的整数值,即量化.
若一幅数字图像的量化灰度级为8bit,就可以有28=256个灰度级差.
颜色深度与显示的颜色数目之间的关系如表34所示.
表34颜色深度与显示的颜色数目之间的关系颜色深度(bit)颜色总数图像名称12(21)单色图像(黑白二色)416(24)索引16色图像8256(28)索引256色图像1665536(216)HIColor图像(实际只显示32768种颜色)2416777216(224)TrueColor图像(真彩色)图像的分辨率越高、颜色深度越深,则数字化后的图像效果越逼真,图像数据量也越大.
但是,经采样、量化形成的图像丢掉了部分数据,与模拟图像必然有一定的差距.
但这个差距通常控制得相当小,以至人的肉眼难以分辨,人们可以将数字化图像等同于模拟图像.
3.
动画和视频动画和视频是图形和图像的动态形式.
动态图像是由一系列的静态画面按一定的顺序排列组成,并配以同步的声音.
每一个静态画面称为一"帧",当每秒以24帧的速度播放时,由于视觉的暂留现象产生动态效果.
动态的图像有动画和视频两种方式.
动画的每一幅画面是通过工具软件(如Flash等)对图像素材进行编辑制作而成;而视频影像是对信号源(如电视机、摄像机等)进行采样和量化后制作而成.
动画是用人工合成的方法对真实世界的一种模拟,而视频影像则是对真实世界的记录.
4.
图像压缩技术随着数字化时代的发展,需要存储、传输和处理的信息的数量成指数级地增加.
图像作为数字信息的重要组成部分,是信息交流的重要载体,也是蕴含信息量最大的媒体.
因此图像压缩作为图像处理的一个重要组成部分,一直是人们研究的一个热点.
(1)图像压缩的基本原理图像数据之所以能被压缩,就是因为数据中存在着冗余.
图像数据的冗余主要表现为:图像中相邻像素间的相关性引起的空间冗余;图像序列中不同帧之间存在相关性引起的时间冗余;不同彩色平面或频谱带的相关性引起的频谱冗余.
数据压缩的目的就是通过去除这些数据冗余来减少表示数据所需的比特数.
由于图像数据量的庞大,在存储、传输、处理时非常困难,大学计算机基础——面向计算思维66因此图像数据的压缩就显得非常重要.
信息时代带来了"信息爆炸",使数据量大增,因此,无论传输或存储都需要对数据进行有效的压缩.
在遥感技术中,各种航天探测器采用压缩编码技术,将获取的巨大信息送回地面.
图像压缩是数据压缩技术在数字图像上的应用,它的目的是减少图像数据中的冗余信息从而用更加高效的格式存储和传输数据.
(2)图像压缩基本方法图像压缩可以是有损数据压缩也可以是无损数据压缩.
对于如绘制的技术图、图表或者漫画优先使用无损压缩,这是因为有损压缩方法,尤其是在低的位速条件下将会带来压缩失真.
如医疗图像或者用于存档的扫描图像等这些有价值的内容的压缩也尽量选择无损压缩方法.
有损方法非常适合于自然的图像,例如一些应用中图像的微小损失是可以接受的(有时是无法感知的),这样就可以大幅度地减小位速.
(3)图像压缩的标准经典的视频压缩算法已渐形成一系列的国际标准体系,如H.
26x系列建议、H.
320系列建议、JPEG以及MPEG系列等标准.
(4)衡量数据压缩技术的重要指标l压缩比,即压缩前后所需的信息存储之比要大.
l恢复效果,即要尽可能恢复到原始数据.
l压缩、解压速度,尤其解压速度更为重要,因为解压是实时的.
l实现压缩的软、硬件开销要小.
3.
4.
3常用的图像文件格式在图形图像数据处理中,可用于图形图像文件存储的格式很多,现分类列出常用的文件格式.
1.
静态图像格式(1)JPEG格式JPEG是由联合照片专家组(JointPhotographicExpertsGroup)开发的.
它既是一种文件格式,又是一种压缩技术.
JPEG作为一种很灵活的格式,具有调节图像质量的功能,允许用不同的压缩比例对这种文件压缩.
作为先进的压缩技术,它用有损压缩方式去除冗余的图像和彩色数据,在获取极高的压缩率的同时能展现十分丰富生动的图像.
JPEG格式是现在使用最为广泛的格式之一,也是目前最优秀的数字化摄影图像的存储方式,JPEG还是万维网中图像处理时使用的主要文件格式之一.
(2)PSD格式这种图像文件格式是Photoshop7.
0默认的格式.
其文件格式后缀为PSD和PDD.
它是由Adobe公司专门开发的适用于Photoshop、ImageReady的图像格式.
它支持从BMP到CMYK的所有色彩模型类型,是最能体现Photoshop7.
0功能与特征的优化格式.
这种格式已经得到了广泛的应用.
它支持Photoshop7.
0特有的一些图像信息,包括能够存储图层、蒙板通道和其他的图像信息,而且这种格式的文件是进行了压缩的,其压缩比例和JPEG差不多,并且压缩后不失真,不会影响到图像的质量.
第3章数据在计算机中的表示67(3)BMP格式BMP(Bitmap)是Windows操作系统中的标准图像文件格式.
这种格式的特点是包含的图像信息较丰富,几乎不进行压缩,但文件占用了较大的存储空间.
BMP格式支持RGB、索引颜色、灰度和位图颜色模式A.
基本上绝大多数图像处理软件都支持此格式.
在Windows系统中系统所用的大部分图像都是以该格式保存的,如墙纸图像、屏幕保护图像等.
BMP格式图像的文件可以使用RLE(RunLengthEncoding,运行长度编码)的无损压缩方案进行压缩.
(4)GIF格式GIF(GraphicsInterchangeFormat)是CompuServe公司开发的图像文件格式,采用了压缩存储技术.
GIF格式同时支持线图、灰度和索引图像,但最多支持256种色彩的图像.
GIF格式的特点是压缩比高,磁盘空间占用较少、下载速度快.
GIF文件内部分成许多存储块,用来存储多幅图像或者是决定图像表现行为的控制块,用以实现动画和交互式应用.
2.
动态图像格式数字化视频的数据量巨大,通常采用特定的压缩算法对数据进行压缩,根据压缩算法的不同,保存数字化视频的常用格式如下:(1)MPEG/MPGMPEG(MovingPictureExpertsGroup)是1988年成立的一个专家组.
1991年制定了一个MPEG1国际标准,采用的算法简称为MPEG算法,是目前最常见的视频压缩方式,可对包括声音在内的运动图像进行压缩.
最大压缩可达约1:200,用该算法压缩的数据称为MPEG数据,由该数据产生的文件称MPEG文件,常以MPG为后缀,部分采用MPEG格式压缩的视频文件也以DAT为扩展名.
(2)AVIAVI(AudioVideoInterleaved)是一种音频视像交叉记录的数字视频文件格式.
1992年初,Microsoft公司推出了AVI技术,是对视频文件采用的一种有损压缩方式.
在AVI文件中,运动图像和伴音数据是以交替的方式进行存储的.
这种组织数据的方式使得读取视频数据流时能更有效地从存储媒介得到连续的信息.
(3)MOVMOV是Apple(苹果)公司创立的一种视频格式,它是图像及视频处理软件QuickTime所支持的格式,在很长的一段时间里,它都只是在苹果公司的Mac机上存在,随着个人多媒体电脑近几年的飞速普及,Apple公司不失时机地推出了QuickTime的Windows版本.
QuickTime能够通过Internet提供实时的数字化信息流、工作流与文件回放功能.
(4)ASFASF(AdvancedStreamingFormat)是微软公司推出的高级流媒体格式,也是一个在Internet上实时传播多媒体的技术标准.
由于它使用了MPEG4的压缩算法,所以压缩率和图像的质量都很不错.
它应用的主要部件是NetShow服务器和NetShow播放器.
将媒体信息编译成ASF流后,发送到NetShow服务器,再由NetShow服务器发送给网络上的所有NetShow播放器,从而实现单路广播或多路广播.
(5)RMRM格式是RealNetworks公司开发的一种新型流式视频文件格式,又称RealMedia,是大学计算机基础——面向计算思维68目前Internet上最流行的跨平台的客户/服务器结构多媒体应用标准,它采用音频/视频流和同步回放技术,实现了网上全带宽的多媒体回放.
RealPlayer就是在网上收听收看这些实时音频、视频和动画的最佳工具.
只要用户的线路允许,使用RealPlayer可以不必下载完音频/视频内容就能实现网络在线播放,更容易上网查找和收听、收看各种广播、电视.
3.
5声音在计算机中的表示3.
5.
1声音在计算机中的表示声音是通过空气的震动发出,通常用模拟波的方式表示它.
振幅反映声音的音量,频率反映了音调.
音频是连续变化的模拟信号,而计算机只能处理数字信号,要使计算机能处理音频信号,必须把模拟音频信号转换成用"0""1"表示的数字信号,这就是音频的数字化,将模拟信号数字化,会涉及到采样、量化及编码等多种技术.
音频信号的数字化过程如图37所示.
(a)话筒录音(b)音频信号采样(c)采样信号量化(d)音频文件图37音频信号的数字化过程每隔一个时间间隔在模拟声音波形上取一个幅度值,称为采样,采样频率是指一秒钟内采样的次数.
采样频率越高,声音的保真度越好.
根据采样定理,采样频率应不低于声音信号最高频率的两倍.
人耳能听到声音的频率范围大约为20Hz~20kHz,所以要得到高保真效果,采样频率应大于40kHz.
量化是用数字化的方法反映采样后的声波信号幅度值的大小.
量化时采用的二进制数的位数称为量化位数,也叫采样精度或采样位数.
它决定了模拟信号数字化以后声音的动态范围.
量化位数越多,音效也就越好.
采样时的量化是通过声卡中A/D模数转换器来实现的.
量化位数有一般有8位、16位等.
表35是常见声音信号的采样频率和量化精度.
表35常见声音信号的采样频率和量化精度信号类型采样频率/kHz量化精度/位电话88调幅广播11.
0258调频广播22.
0516数字激光唱盘44.
116第3章数据在计算机中的表示69经过量化后得到的数字信息,还必须按一定格式转换成计算机可以识别的二进制形式,才能在计算机中保存.
用二进制形式表示量化值的过程称为编码.
3.
5.
2声音文件格式数字音频信息在计算机中是以文件的形式保存,存储声音信息的文件可以有多种格式,如WAV、MIDI、MP3、WMA等.
1.
WAV格式WAV格式的文件又称波形文件,是用不同的采样率对声音的模拟波形进行采样得到的一系列离散的采样点,以不同的量化位数(16位、32位或64位)把这些采样点的值转换成二进制数得到的.
WAV是数字音频技术中最常用的格式,它还原的音质较好,被称为"无损的音乐",但所需存储空间较大,是目前PC机上广为流行的声音文件格式,几乎所有的音频编辑软件都能够读取WAV格式.
2.
MIDI格式MIDI是MusicalInstrumentDigitalInterface(乐器数字接口)的缩写.
它是由世界上主要电子乐器制造厂商建立起来的一个通信标准,并于1988年正式提交给MIDI制造商协会,成为数字音乐的一个国际标准.
MIDI标准使不同厂家生产的电子合成乐器可以互相发送和接收音乐数据.
MIDI文件记录的是一系列指令而不是数字化后的波形数据,所以它占用存储空间比Wav文件要小很多.
一个MIDI文件每存1分钟的音乐只用大约5~10KB.
3.
MPEG格式MPEG标准主要有以下五个,MPEG1、MPEG2、MPEG4、MPEG7及MPEG21等.
该专家组建于1988年,专门负责为CD建立视频和音频标准,而成员都是视频、音频及系统领域的技术专家.
及后,他们成功将声音和影像的记录脱离了传统的模拟方式,建立了ISO/IEC1172压缩编码标准,并制定出MPEG格式,令视听传播方面进入了数码化时代.
因此,大家现时泛指的MPEGX版本,就是由ISO(InternationalOrganizationforStandardization)所制定而发布的视频、音频、数据的压缩标准.
MPEG标准的视频压缩编码技术主要利用了具有运动补偿的帧间压缩编码技术以减小时间冗余度,利用DCT技术以减小图像的空间冗余度,利用熵编码则在信息表示方面减小了统计冗余度.
这几种技术的综合运用,大大增强了压缩性能.
MPEG3是对MPEGLayer3的简称,是当前使用最广泛的数字化声音格式.
其技术采用MPEGLayer3标准对WAVE音频文件进行压缩而成,特点是能以较小的比特率、较大的压缩率达到近乎CD音质.
MPEG音频文件的压缩是一种有损压缩,其压缩率可达10:1~12:1,由于其文件尺寸小、音质好,所以网上音乐大量使用MP3格式.
4.
WMA格式WMA(WindowsMediaAudio)是微软自己开发的WindowsMediaAudio技术.
它支持流式播放.
WMA格式的可保护性极强,甚至可以限定播放机器、播放时间及播放次数,具有相当的版权保护能力,它比起MP3压缩技术,WMA无论从技术性能(支持音频流)还是压缩率(比MP3高一倍)都超过了MP3格式.
用它来制作接近CD品质的音频文件,其体积仅相当于MP3的1/3.
大学计算机基础——面向计算思维70本章小结在计算机科学中,数据是指所有能输入到计算机并被计算机程序处理的符号的总称,是用于输入电子计算机进行处理,具有一定意义的数字、字母、符号和模拟量等的通称.
数据的种类很多,无论什么数据在计算机中都是用二进制代码表示的.
把数值的正、负号也用0、1表示放在存储器的最高位形成的数叫机器数,该机器数所对应原来的数值叫做该机器数的真值.
机器数常用的有原码、反码、补码表示法.
本章较详细地介绍了英文字符、汉字、图形、图像和声音在计算机中的表示.
- 第3章数据在计算机中的表示相关文档
- 招标编号:竹政采(公)〔2019〕59-3号
- 《现代教育技术应用》公共课期末考核要求
- 课程ps字体效果
- 《PhotoShop的图像修饰》教学设计
- 虚拟现实应用技术
- 图层ps字体效果
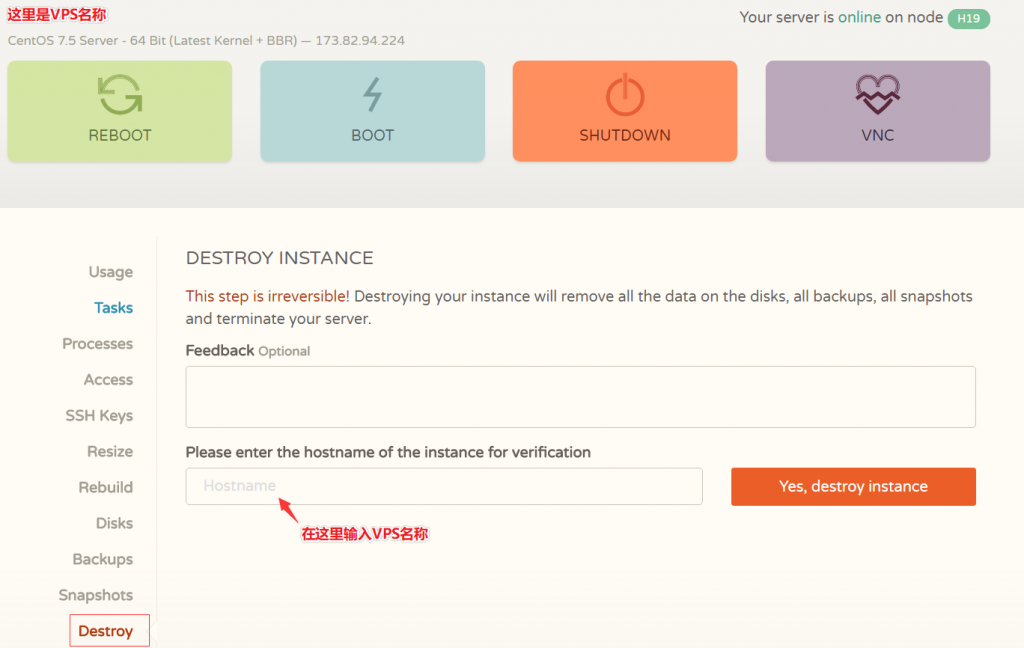
LOCVPS:美国XEN架构VPS七折,全场八折,日本/新加坡XEN架构月付29.6元起
LOCVPS发来了针对XEN架构VPS的促销方案,其中美国洛杉矶机房7折,其余日本/新加坡/中国香港等机房全部8折,优惠后日本/新加坡机房XEN VPS月付仅29.6元起。这是成立较久的一家国人VPS服务商,目前提供美国洛杉矶(MC/C3)、和中国香港(邦联、沙田电信、大埔)、日本(东京、大阪)、新加坡、德国和荷兰等机房VPS主机,基于XEN或者KVM虚拟架构,均选择国内访问线路不错的机房,适合建...

CloudCone2核KVM美国洛杉矶MC机房机房2.89美元/月,美国洛杉矶MC机房KVM虚拟架构2核1.5G内存1Gbps带宽,国外便宜美国VPS七月特价优惠
近日CloudCone发布了七月的特价便宜优惠VPS云服务器产品,KVM虚拟架构,性价比最高的为2核心1.5G内存1Gbps带宽5TB月流量,2.89美元/月,稳定性还是非常不错的,有需要国外便宜VPS云服务器的朋友可以关注一下。CloudCone怎么样?CloudCone服务器好不好?CloudCone值不值得购买?CloudCone是一家成立于2017年的美国服务器提供商,国外实力大厂,自己开...
杭州王小玉网-美国CERA 2核8G内存19.9元/月,香港,日本E3/16G/20M CN2带宽150元/月,美国宿主机1500元,国内宿主机1200元
官方网站:点击访问王小玉网络官网活动方案:买美国云服务器就选MF.0220.CN 实力 强 强 强!!!杭州王小玉网络 旗下 魔方资源池 “我亏本你引流活动 ” mf.0220.CNCPU型号内存硬盘美国CERA机房 E5 2696v2 2核心8G30G总硬盘1个独立IP19.9元/月 续费同价mf.0220.CN 购买湖北100G防御 E5 2690v2 4核心4G...
-
fontfamily这是什么字体,求解.. font-family: PahuengaCassRegular;邮箱怎么写正确的邮箱格式怎么写天天酷跑刷积分教程葫芦侠3楼几十万的积分怎么刷天天酷跑积分怎么刷中小企业信息化什么是中小企业信息化途径bluestackbluestacks安卓模拟器有什么用网站优化方案网站建设及优化的方案微信电话本怎么用怎么用微信打电话域名库域名赎回期过了多长时间可以注册freebsd安装FreeBSD怎么安装怎样申请支付宝如何申请支付宝