报文微信接收离线消息
微信接收离线消息 时间:2021-02-21 阅读:()
收稿日期:20160317;修回日期:20160519基金项目:国家自然科学基金资助项目(61501128)作者简介:刘珍(1986),博士,主要研究方向为互联网流量分类、机器学习(jeannylz@yahoo.
com);王若愚,博士,主要研究方向为计算机网络、模式分类;蔡先发,博士,主要研究方向为模式识别;唐德玉,博士,主要研究方向为数据挖掘.
互联网流量分类中流量特征研究刘珍1,王若愚2,蔡先发1,唐德玉1(1.
广东药科大学医药信息工程学院,广州510006;2.
华南理工大学信息工程研究中心,广州510006)摘要:为了系统性分析互联网流量特征,根据统计对象或统计角度研究流量特征的归类法,展开评述了每类流量特征;针对流量特征的稳定性问题,分析报文抽样、网络环境和模糊化技术对流量特征的影响;从分类能力、稳定性、时效性和分类粒度等方面评述流量特征的优缺点,为流量特征应用提供指导性建议;最后总结了流量特征的未来研究方向.
关键词:互联网流量特征;互联网流量分类;网络测量;机器学习;连接图中图分类号:TP393.
06文献标志码:A文章编号:10013695(2017)01000807doi:10.
3969/j.
issn.
10013695.
2017.
01.
002SurveyontrafficfeaturesinInternettrafficclassificationLiuZhen1,WangRuoyu2,CaiXianfa1,TangDeyu1(1.
SchoolofMedicalInformationEngineering,GuangdongPharmaceuticalUniversity,Guangzhou510006,China;2.
Information&NetworkEngineering&ResearchCenter,SouthChinaUniversityofTechnology,Guangzhou510006,China)Abstract:InordertosystematicallyanalyzeInternettrafficfeatures,thispaperresearchedthetaxonomyoftrafficfeaturesbasedontheobjectsusedforbuildingtrafficfeatures,andoverviewedtherelatedtrafficfeaturesineachcategory.
Itfurtheranalyzedthestabilityoftrafficfeatures,theimpactofpacketsampling,networkenvironmentandobfuscatingontrafficfeatures.
Andthenitcomparedthedifferentkindsoftrafficfeaturesfromclassificationaccuracy,stability,timelinessandgranularity.
Finally,thispaperconcludedfutureworksabouttrafficfeatures.
Keywords:Internettrafficfeatures;Internettrafficclassification;networkmeasurement;machinelearning;connectivitygraph引言互联网流量分类是网络测量的一个重要分支,旨在通过特定的技术手段,从大量的网络流量中识别单类应用或区分多类应用(如Web、Attack、P2P等)的流量.
互联网流量分类技术不仅是网络管理员进行流量整形、网络容量规划、异常检测、QoS部署和网络计费的重要手段,也是研究者开展应用协议研究的重要依据[1].
流量特征用于描述和测量网络流量,其作为流量分类算法的输入,是实现IP报文到网络应用识别的重要桥梁.
为了适应新应用或应对旧应用的逃避检测策略,互联网流量分类方法在不断改进,流量特征也随之演进.
早期每种网络应用采用固定的端口号,端口号作为流量特征便可实现IP报文到网络应用的映射,如80端口号对应HTTP的上层应用,但是端口号映射法随着动态端口和端口伪装技术出现而逐步失效.
随之出现了基于载荷特征字段的深度报文探测(deeppacketinception,DPI)方法[2],此方法基于载荷为每种应用提取有代表性的正则表达式或字符串作为流量特征,用于实现网络流量分类,但是这类方法无法识别载荷加密的报文.
为了克服动态端口号、端口伪装和载荷加密等,出现基于连接图和基于机器学习的流量分类方法,并成为近年来的研究热点.
例如,Karagiannis等人[3]提出基于主机通信行为的方法,从社会、功能和应用三个层面分析了网络应用的行为,基于源IP、目的IP、源端口、目的端口和传输层协议建立主流应用(Attack、Web、Games、Chat、P2P等)的通信行为模式,运用启发式规则进行流量分类.
此类方法中,将主机间的连接数等作为流量特征描述网络流量.
基于机器学习的流量分类方法将机器学习方法引入网络流量分类领域[4],这类技术利用流(flow)表现出来的不同统计特征进行流量分类,如流长度、报文数、报文到达时间间隔及其统计运算等.
但是大部分文献使用不同的流量特征,且流量特征描述不统一.
如何区分和选取流量特征仍未得到系统性研究.
此外,采用报文抽样技术获取的流量数据可能因流量中丢失了部分报文而导致某些流量特征值不稳定.
不同网络的流量数据表现出不同的特点,对于骨干网,经常因网络繁忙而发生拥塞,造成"报文到达时间间隔"特征的鉴别能力不再可靠.
系统分析和归类流量特征并探讨流量特征的稳定性,对流量特征选取和训练鲁棒的流量分类器尤为重要.
本文系统性地研究互联网流量特征,论述了运营网中进行互联网流量分类的重要意义,指出流量特征在解决流量分类问题中的关键性作用和面临的开放性问题.
介绍了相关概念,总结归纳基于机器学习和连接图的流量分类方法的相关流量特征,提出流量特征的归类法(taxonomy);分析流量特征的影响因素,主要分析报文抽样、网络环境和流量模糊化技术对流量特征的影响,对不同类型的流量特征进行了比较分析,并对流第34卷第1期2017年1月计算机应用研究ApplicationResearchofComputersVol34No1Jan.
2017量特征未来的研究方向进行了展望.
流量特征归类与分析相关概念a)单向流(unidirectionalflow).
在单向通信方向上,由具有相同五元组{源IP地址,目的IP地址,源端口号,目的端口号,传输层协议}值的报文分组序列组成,如图1中的流1和流2所示.
b)双向流(bidirectionalflow).
在同一源和目的节点{IP,port}之间的通信中,由方向相反的两条单向流组成,如图1表示的流1和流2合并组成双向流.
c)流量特征.
用于描述或测量网络流量,利用IP报文或网络流进行统计计算,如报文长度、报文数目、流持续时间等,如图1标志的流量特征.
d)流样本.
流样本通常是指由流量特征向量值表达的网络流.
流量特征在大量的互联网流量分类文献中,多种流量特征被提出,比较常用的特征有报文大小、流持续时间、报文到达时间间隔等相关特征.
根据流量特征的统计对象,互联网流量特征的归类法如图2所示.
!
"#$%&'()*+,-.
$%&'()#/$.
$%&'()012.
$%&'3,-*,456*,7$&'8$&'2!
"#$%&'.
9:;121基于报文头部的流量特征基于报文头部的流量特征从单个报文头部的字段提取得到,如表1所示,包括帧头部、IP头部和传输层头部.
帧头部的特征包括帧长度、报文长度等;IP头部包括IP头校验和、IP协议、TTL(timetolive)标记等;传输层头部包括端口号、TCP标记、push标记、UDP标记等.
但是,基于报文头部的特征在类间的区分能力有限,如Alshammari等人[5]的研究结果表明,相比于基于流的流量特征,基于报文头部的流量特征的分类性能较弱.
为了保证流量分类性能,基于报文头部的流量特征通常与基于流的特征一起作为特征集合描述网络流量.
表1基于报文头部的流量特征文献流量特征[5]帧头部:报文长度、帧长度、采集长度、帧是否标记IP头部:头部长度、保留位、分配偏移、TTL、校验和等TCP头部:分片长度、序号、下一个序号、头部长度、标记、校验和、窗口大小等UDP头部:长度、校验和、校验和设置为真(假)[6]IP头部:TOS(typeofservice),TTL,报文长度,IP协议类型,比特率UDP或TCP头部:源端口号、目的端口号122基于流的流量特征流级别的流量特征是统计每条流中多个报文分组表现出的统计特性,此类特征应用较为广泛.
根据统计的网络流对象,流级别的流量特征可进一步分为单流特征和多流特征,分别如表2和3所示.
1)单流特征McGregor和Roughan等人[7,8]运用报文大小、报文到达时间间隔等处理基于机器学习的流量分类问题.
单流特征中最有代表的是Moore等人[42]提出的248个特征,主要从端口号、报文分组大小和报文到达时间间隔等方面进行特征统计,并得到广泛应用[11,43~49].
这些传统的单流特征从提取角度可进一步分为报文相关、时间相关和连接相关的流量特征.
表2表明,大多文献采用报文相关和时间相关的流量特征.
报文相关的流量特征包括报文数、报文大小(如均值、中值、方差等)、某标志位设置的报文数、总体字节数等;时间相关的流量特征主要包括报文到达时间间隔、流持续时间、空闲时间的平均值、方差等;连接相关的流量特征包括吞吐量、丢包率、窗口大小等.
但是,这些传统流量特征的取值易受网络环境的影响,如报文到达时间间隔、窗口大小、吞吐量等与实际的网络带宽使用情况有关.
随后,从新角度提取的流量特征被提出,如基于报文大小取值分布[21,22].
报文大小分布的统计特性不仅表现报文的大小,还可反映通信过程中报文大小的变化情况,较鲁棒于网络环境的影响,能在一定程度上提高分类鲁棒性.
近期文献又提出了新的特征统计对象,如文献[24]提出将消息用于特征统计计算(前向和后向消息大小),文中将消息定义为在同方向上连续通信的多个报文;文献[50]根据通信两端报文传输的一个往返(round)进行特征提取,如Ii的TiA和TiB的数据片段的个数和字节数、Ii和Ii+1的时间间隔、TiA和TiB的平均时间间隔等,其中Ii、TiA和TiB的定义如图3所示.
更有文献[26,27]以报文载荷作为特征的提取对象,如计算载荷数据的取值分布,其中载荷的取值不代表特定的含义,这不同于DPI方法(为每种应用提取有代表的字符串).
.
另一方面,为了实现在线的流量分类问题,提出子流(subflow)特征的概念,即仅对网络流中的K个报文(K通常小于10)进行统计特征值的计算,而无须等到一条流的结束.
如文献[28]对一条流的前K个报文提取三个特征:报文方向、载荷大小和时间戳;文献[29]提取早期有序的带载荷报文的报文大小,并讨论分析多少个带载荷报文对流量分类性能有较大贡献,实验结果表明第3~8个报文对分类性能贡献较大,前两个报文的贡献较小.
在众多的单流特征中,报文长度和报文到达时间间隔及其统计(如平均值、最小值、最大值等)的运用频率较高[51],如文献[11~13]都采用了的报文数、字节数、报文大小、报文到达时间间隔相关的20个流量特征.
但是,单流特征易受网络环境、报文抽样、模糊化技术的影响,如何提高单流特征的鲁棒性仍是开放性问题.
2)多流特征多流特征是对聚合的多条网络流进行统计特征提取,其中统计的流量范围可分为主机的流量、网络段的流量、节点的流量和会话的流量,如表3所示.
·9·第1期刘珍,等:互联网流量分类中流量特征研究表2单流特征文献报文相关时间相关连接相关[7]报文大小(最小值、最大值、四分位数),字节数流持续时间,报文到达时间间隔,空闲时间事务和块传输之间的转换次数[8]报文大小的平均值、方差值、均方根,报文数等流持续时间,报文到达时间间隔连接对称性,丢包率,延时等[9]端口号,报文大小(最小值、最大值、平均值、标准差),报文数,带某标记的报文数,总体字节数等报文到达时间间隔(最小值、最大值、平均值、标准差),流持续时间,传输时间,空闲时间,报文到达时间间隔傅里叶变换等吞吐量,初始化窗口大小,分片大小等[10]报文数目,报文大小,传输层协议,端口号等流持续时间窗口大小[11~13]双向的报文数,双向的字节数,报文大小(最小值、最大值、平均值、标准差)报文到达时间间隔(最小值、最大值、平均值、标准差)[14]报文大小(最小值、最大值、平均值、标准差)及其偏斜度(skewness)、峰度(kurtosis);载荷大小(最小值、最大值、平均值、标准差)及其偏斜度、峰度报文到达时间间隔(最小值、最大值、平均值、标准差)及其偏斜度、峰度[15,16]双向报文数,双向字节数,报文大小(最小值、最大值、平均值、标准差)报文到达时间间隔(最小值、最大值、平均值、标准差),流持续时间[17]总体字节数,带有TCP载荷的报文数,带有push标志位的报文数,报文字节数的中值和标准差流持续时间[18]传输层协议,IP地址,端口号,报文数,第一个和最后一个报文的时间戳,正向和反向报文数等流持续时间,报文到达时间间隔的平均值、最大值、最小值,前向和后向报文到达时间间隔平均值、最大值、最小值[19]总体报文数,总体字节数,双向报文数比,双向字节数比,传输层协议,双向的端口号等流持续时间,报文数与流持续时间的比值,字节数与流持续时间的比值,流持续时间与报文数的比值,报文到达时间间隔[20]传输层协议,报文个数,上行和下行流量,流速率,总载荷字节数等流持续时间,报文到达时间间隔报文分布[21]报文大小分布,端口号[22]报文大小比率px(px表示报文大小为x的报文数比率,x=1,…,n)[23]报文大小和报文到达时间间隔联合分布,上行报文数与上下行报文数的比值,双向流持续时间等消息相关[24]前向第m个消息的大小,后向第m个消息的大小通信相关[25]基于状态机,给定一个状态,状态间的转移概率和对于报文提取的某些特征(报文长度和方向)载荷相关[26]对一条流中的C个报文,提取每个报文的前N个字节,将这些字节分成G个组,每个组由b位组成,因此每个组的取值范围为[0,2b-1],利用卡方检验方法,建立特征向量X=[X1,X2,…,Xg]Xg=∑2b-1i=0(O(g)i-E(g)i)2E(g)i,O(g)i表示第g组取第i个值的报文个数,E(g)i表示在g组里面取第i个取值的期望值[27]一个项(term)表示包括i个字节的滑动窗口内的载荷数据,一个项的大小为i字节,项集合的大小为28i,特征向量表示为[w1,w2,…,wm]Twj表示在一个报文中第j项出现的频率,m表示项的全集大小子流特征[28]第j个报文的方向,载荷大小和时间戳,j=1,…,M[29]有序的前10个报文的大小[30]子流的前向和后向的报文大小差异(最小值、最大值、平均值、标准差),报文大小(最小值、最大值、平均值、标准差),报文到达时间间隔(最小值、最大值、平均值、标准差)[31]对TCP连接开始的前4~10个报文(包括TCP连接3次握手的数据包)的报文大小和报文到达时间间隔的统计信息,以及与TCP标志位相关的统计信息等[32]端口号,前N个报文的载荷大小,前N个报文的有向信息熵(描述某个报文载荷取值的随机性),双向N个报文的有向信息熵之和,前N个报文的方向[33]前p个报文的源端口号,目的端口号,总报文数,总字节数,报文载荷大小(最小值、最大值、平均值、标准差),报文长度(最小值、最大值、平均值、标准差),流持续时间,报文到达时间间隔(最小值、最大值、平均值、标准差)等林平等人[20]在多流特征方面,基于主机的流量提出源源、源宿、宿源和宿宿流量相关流的统计特征("源源"是指源地址与待分类流的源地址相同的流集合,"源宿"是指宿地址与待分类流的源地址相同的流集合,"宿源"指源地址与待分类流的宿地址相同的流集合,"宿宿"是指宿地址与待分类流的宿地址相同的流集合).
Jiang等人[35]基于网络段的流量提取流量特征,如某网段内的流容量在时间、地点和应用上的分布等.
Valenti等人[36]为分类P2P流量,基于节点{IP,port}从双向流提取102个统计特征,如当前时间槽的流数目、当前时间槽与前一时间槽的报文速率的变化等.
Bermolen等人[37]提取在一定时间间隔内发送k个报文或字节到观察节点{IP,port}的节点数的比例.
Lee等人[41]将某应用在两个主机间通信的所有网络流组成一个会话,提出基于会话的流量特征,如会话的持续时间、会话的流数目等.
多流特征比单流特征包含的信息量更丰富,表现更为稳定,其中基于主机和节点的流量特征通常用于P2P的识别或者异常行为探测;多流特征也可与单流特征共同用于流量分类[20].
123基于连接图的流量特征基于连接图(connectivitygraph)的流量分类方法,通常将图的性质所表现的流量特征与基于流的流量特征相结合用于分类.
该部分主要叙述基于图的流量特征,具体情况如表4所示.
根据近期文献的连接图,顶点可归纳为四种:主机[52,53]、{IP,port}对[54,55]、网络流[56]、五元组[57].
对于主机和{IP,port}对,通常边表示两个顶点之间有数据通信:主机之间只要有数据传输则建立一条边[52,55],主机间的每条边对应一条网络流[53].
网络流为顶点的连接图中,边则代表网络流间的关系[56].
在五元组为顶点的连接图中,则对在一条流中的五元组建立边[57].
基于连接图的流量特征能表现网络应用在主机间的通信行为,具有较高的稳定性,不易受网络环境和网络应·01·计算机应用研究第34卷用更新的影响.
各种连接图特征的定义如表4所示.
表3多流特征文献流量特征主机[34]以主机为对象(IP地址),每流的平均报文数目,小字节报文(≤144Byte)的百分比,大字节报文(≥1392Byte)的百分比,中字节(>144,<1392)报文分布的信息熵,目的IP个数;源端口数和目的IP数的比值,目的端口数与目的IP数的比值,IP地址的第二个字节的信息熵与第四个字节的信息熵的比值;IP地址的第三个字节的信息熵与第四个字节的信息熵的比值[20]源源集合、源宿集合、宿源集合、宿宿集合的流数、源端口数、目的IP数、目的端口数、传输层协议网络前缀[35]流量字节容量;流量字节容量的时间、空间和应用分布;流字节大小分布;上载流量与下载流量的比值节点{IP,port}[36]当前时槽聚合流、报文和字节信息,当前时槽与前一时槽的变化(聚合流数、报文数、字节数),聚合流的计数比率(报文、字节)[37]在一定时间间隔内(5s)发送k个报文或字节到观察节点{IP,port}的节点数的比例[38]报文大小变化的均方差,上行下行流量的比值,资源请求端与资源提供端的IP和port数量的比值[39]平均、最大报文大小,报头大小,平均报文到达时间间隔,平均、最大流长度,上行和下行流量等[40]基于建立流量矩阵,计算节点出度熵,节点入度熵,熵指数R(出入度熵的差异)会话[41]第一个报文到达相对时间,最后一个报文到达相对时间,会话持续时间,会话流数目,流长度,第二时段的流长度,流长度标准差,流长度方差与流长度均值平方的比值,传输层协议表4基于连接图特征文献流量特征[52]基于TDG,顶点的平均边数,有输入也有输出顶点所占百分比,按升序排序的所有顶点间的距离中处于第90%位置的距离[55]基于TAG,主机hi所有边中属于类别Ck的边数与hi的总边数的比值,主机hj所有边中属于类别Ck的边数与hj的总边数的比值,hi的总边数,hj的总边数[53]基于TG,一条边的两个端点pi和pj,求pi所有边中属于类ci的概率和pj所有边中属于类ci的概率,两概率的平均值取做ci的后验概率[56]基于TCG,PR边数与CR边数的比值,DHR边数(DNS(domainnamesystem)请求到DNS请求)与DHR边数的比值[57]基于CPG,每一列的节点数ni(i是列的序号,i=1,…,5),在i到j方向上只有一个出度的节点数(j=±i),在i到j方向上的平均度数,i到j方向上的最大度数,具有最大度数的节点的后向度数[54]基于HCG,计算两个节点{IP,port}的相似度,若两个节点有直接通信(相邻),则相似度为无穷大,否则为各自相邻节点集合共享的节点数1)主机作为图中的顶点文献[52]提出TDG(trafficdispersiongraphs),定义如下:给定一组网络流S,采集于固定时间间隔,TDG定义为有向图G(V,E),点集V对应S的IP地址,对于u,v∈V,如果在u和v之间有网络流f∈S,表示u和v之间有连接,那么(u,v)∈E.
文献[53]提出TG(tracegraph),构建方法如下:一个顶点代表一个终端主机,一条边代表一条流,部分流具有类别属性;未知网络流则通过分析邻近网络流的类别属性进行类别鉴定.
2){IP,port}对作为图中的顶点文献[54]提出HCG,定义如下:HCG表示为G(V,E),将节点{IP,port}抽象为一个点vi∈V,若vi和vj之间有通信,则在vi和vj之间建立一条边eij∈E.
HCG的边表征了节点之间的交互,从行为学的角度,只要节点A向节点B发送了报文,则A必然存在向B索取某种信息或资源的意图,因此HCG根据以下原则建立边:对于UDP流,若A向B传送了报文;对于TCP流,若有SYN(synchronous)报文发送.
文献[55]提出TAG(trafficactivitygraph),定义如下:顶点代表终端节点{IP,port},若两个终端节点之间有通信就有一条边(一条边可能包含了多条流,论文基于了这样的假设:在一定时间间隔内,两终端节点之间的所有网络流属于同一种应用).
顶点的组成表示为{IH,OH},IH表示ISP(Internetserviceprovider)网络内部的IP,OH表示ISP网络外部的IP,TAG由二部图组成,即ISP网络内部或者网络外部的节点间的通信不表现出来.
3)流作为图中的顶点文献[56]提出TCG(trafficcausalitygraphs),定义如下:TCG中的点和边分别表示网络流和流间的因果关系.
TCG集中于四种类型因果关系:CR(communicationrelationship)、PR(propagationrelationship)、DHR(dynamicporthostrelationship)和SHR(staticporthostrelationship).
观察的两条网络流分别表示为f1和f2,四种类型的边分别定义如下:a)如果f1和f2满足protocol(f1)=protocol(f2),srcIp(f1)=dstIp(f2),srcPort(f1)=dstPort(f2),dstIp(f1)=srcIp(f2),dstPort(f1)=srcPort(f2),那么f1和f2之间建立CR关系边(表示一对一主机间的直接通信,即请求与响应的关系).
b)否则,如果f1和f2满足dstIp(f1)=srcIp(f2),那么f1和f2之间建立PR关系边(表示一条网络流传递信息到其他的网络流,如代理和转播).
c)否则,如果f1和f2满足srcIp(f1)=srcIp(f2),srcPort(f1)≠srcPort(f2),那么f1和f2之间建立DHR关系边(表示使用同一个IP地址但不同端口号的网络流间的关系,如Web浏览器使用多个端口号与服务器创建连接).
d)否则,如果f1和f2满足srcIp(f1)=srcIp(f2),srcPort(f1)=srcPort(f2),那么f1和f2之间建立SHR关系边(表示使用相同IP地址和端口号的网络流之间的关系,如某些端口扫描应用利用同一端口号进行一系列的端口扫描,或者服务器使用一个端口号去响应多个客户端的请求).
4)五元组作为图中顶点文献[57]基于CPG(communicationpatterngraph)提取特征.
CPG定义如下:图中的五种顶点分别表示源IP地址、协议、源端口号、目的端口号、目的IP地址的唯一取值;根据网络流的五元组取值进行连线,产生CPG的边,如图4所示,根据上面的两组五元组取值,CPG建立了七个顶点和六条边.
!
"0$0--.
"0$!
"#$%&,)*1'()2**+)#$%!
,2*流量特征提取工具为了便于流量特征的自动统计计算,已有研究组织开发了开源的流量特征提取工具,这些工具可根据需要提取不同的流量特征,几种常用的流量特征提取工具介绍如下.
1)TcptraceTcptrace(http://www.
tcptrace.
org/index.
html)是为分析TCP流量数据文件而开发,它的输入可以是各种流行的基于报文采集程序输出的文件,如tcpdump、snoop、EtherPeek、HPNetMetrix、WinDump.
Tcptrace能输出每个通信连接上观察到的各种信息,如持续时间、字节数、发送和接收到的片段,重传、往返时间,吞吐量等,也可以得到多个图形,用于进一步分析.
·11·第1期刘珍,等:互联网流量分类中流量特征研究2)TstatTstat(http://tstat.
tlc.
polito.
it/measure.
shtml)是Tcptrace上的进一步开发,可以在普通PC硬件或者数据采集卡进行在线的报文数据采集.
除此之外,Tstat还可分析已有的数据报文,支持各种dump格式,如libpcap库支持的格式等.
双向的TCP流分析可得到新的统计特征,如阻塞窗口大小、乱序片段等,这些信息在服务器和客户端有所区分,还可区分内网主机和外网主机.
3)NetMateNetMate(http://sourceforge.
net/projects/netmatemeter/)是网络流量测量和监控工具,可用于报文计数、延时或丢包测量和报文采集.
它的工作是监听网络流量,并将报文进行组流和计算网络流的测量指标,也可进行离线的流量测量,如测量报文数目、流量容量、报文速率、最小/最大/平均报文到达时间间隔和最小/最大/平均报文长度等.
4)WireSharkWireShark(https://www.
wireshark.
org/)是网络报文分析器,可用于在线采集网络报文,并解析报文,在界面显示报文内容;也可分析已有的报文数据,如由tcpdump/WinDump、Wireshark等采集的报文数据;Wireshark提供多种过滤规则,进行报文过滤.
基于此工具的报文分析功能可获取基于报头的相关特征[5].
流量特征的稳定性分析报文抽样对流量特征的影响Duffield等人[58]分析了随机1/N报文抽样对流量特征的影响,实验结果表明当N取值较大时,不同网络应用的流长度分布趋于接近,即流长度的类间区分能力减弱;张进等人[59]指出等概率抽样虽然能很好地保留数据包级流量信息,但却无法较完整地保留流级的流量信息,如并发流数目、流长度分布、各条数据流的流量.
Pescapé等人[6]深入分析了255个流量特征在抽样前后的稳定性,作者采用FleissChisquare和Hellingerdistance作为信息丢失的评估指标,研究结果表明大部分的流量特征受抽样影响显著,即255个特征中仅有34个有较好鲁棒性,其中10个特征来自于IP层,20个特征来自于TCP层,4个特征来自于UDP层;总结得出基于单个报文的特征比基于多个报文的特征较为鲁棒.
CarelaEspanol等人[60]基于未经报文抽样的流量数据研究在分类问题中随机1/N报文抽样对流量特征的影响,以原始的流量数据构建训练集,以经过抽样的流量数据构建测试集,并采用C4.
5决策树进行流量分类,结果表明有三个因素影响分类准确率:流分裂、流大小分布的变化、流量特征逆向估计错误,如报文数目、报文大小、流持续时间和报文到达时间间隔等流量特征出现显著性的逆向估计错误.
以上研究表明,报文抽样会明显减少报文个数,流量特征会有比较显著的变化.
Tammaro等人[61]分析多种报文抽样对单流特征和聚合流统计特征的影响,实验结果表明基于单个报文进行统计的流量特征鲁棒于报文抽样,复杂的统计特征比简单的流统计特征更稳定.
网络环境对流量特征的影响在流量数据的采集时间和采集地点对流量特征的影响方面,Este等人[62]分析了随着采集时间和采集地点的改变,流量特征携带的互信息的变化情况,关注的流量特征包括往返时延、IP内网/外网、报文载荷大小、报文到达时间间隔、报文传输方向.
它们的结果表明,针对三种网络的流量数据,报文载荷大小的互信息最高,且在不同流量数据间无显著性差异.
文献[63]指出报文到达时间间隔中的报文传输时间易受网络阻塞等因素影响,针对此问题,提取每流报文到达时间间隔后,去除其间可能隐含的报文传输延迟再进行统计计算,从而提高此特征的稳定性.
模糊化技术对流量特征的影响某些网络应用为了逃避检测,采用模糊化技术削弱流量特征的有效性,常见的流量特征模糊化有四种[64]:a)端口号模糊化,如P2P为逃避检测使用随机端口或熟知端口;b)报文载荷模糊化,如报文填充和载荷数据加密;c)流级别模糊化,如网络带宽动态变化、网络拥塞、报文发送时序变化等;d)连接级别的模糊化,如与服务器的动态连接、随机连接、隧道伪装等.
这些模糊化技术导致了流量特征取值的动态变化,例如,报文大小改变导致相关的流统计特征值变化,将削弱基于此的流量分类器的网络应用鉴别能力.
文献[65]在流量统计特征模糊化操作方面进行了总结.
a)基于TCP的网络应用模糊化报文大小的一种简单方式是随机清除发送缓冲区,即随机将缓冲的数据立即发出去,不用等到达到MTU(maximumtransmissionunit)的时刻,另一种方式是随机填充传输的数据报文;b)模糊化报文方向的方式为:在三次握手完成后,客户或服务端等待随机的时间后发送数据报文,等待随机的时间使得第一个报文的发送方向随机.
针对报文载荷和流级别的模糊化,文献[65]通过分析总结报文载荷及流取值的模糊化规律提出了34种新型流量特征.
但是这些新特征依赖于特定的流量数据,特征的取值规律和处理技术与网络环境相关,极易被新型网络环境和网络应用攻破.
流量特征的比较和未来研究方向流量特征比较分析本节根据分类能力、分类粒度、稳定性和时效性对各类流量特征进行了比较分析,如表5所示.
表5互联网流量特征比较特征种类分类能力分类粒度稳定性时效性基于报文头部的特征单流(全流)特征单流(子流)特征多流特征基于连接图的特征较低较高,与分类算法相关粗粒度或细粒度,与分类方法相关粗粒度在没有采用模糊化技术情况下,有较好的鲁棒性报文和时间相关的特征都易受报文抽样、报文丢失、网络阻塞等影响能反映连接通信行为的多流特征比单流特征的稳定性好稳定性较高高低中低低a)在分类能力方面,基于报文头部的特征在类间的区分能力较弱[5],其他流量特征在文献[4,51]中表现出较好的流量分类性能,实验表现的分类结果还与分类算法相关.
b)在分类粒度方面,基于报文头部和基于网络流的流量特征都可实现粗粒度[9]和细粒度[27]的分类,这要根据分类算法而定;基于连接图的方法中,描述主机连接的流量特征大多用于粗粒度的分类[52].
c)在分类稳定性方面,基于报文头部的流量特征仅依赖于单个报文进行特征提取,因此受报文抽样或网络环境的影响小;单流特征中,基于多个报文或时间的流量特征易受丢包或网络阻塞等的影响,不过报文相关的特征比时间相关的特征的稳定性更高,如文献[61]表明最大报文大小比RTT更稳定;基·21·计算机应用研究第34卷于多条流的特征中,能反映网络应用行为的流量特征具有较好的稳定性[37],而某些流量特征,如基于报文和到达时间间隔的PDF(probabilitydensityfunctions)的稳定性较差[66].
d)在时效性方面,基于报文头部的特征仅提取头部某些字段,统计开销小;单流特征中基于子流的流量特征无须等待流结束后进行特征计算,可用于在线分类;然而多流特征和基于连接图的流量特征需要在大量的流量数据上进行统计特征计算,时效性较低.
每篇文献采用的实验数据和分类方法不同,很难对这些流量特征进行公平的比较,流量特征表现出来的分类能力、分类粒度、稳定性和时效性还与具体的分类算法相关.
表5给出的归纳总结仅针对大部分情况而言,当然存在与表5不同的情况,如文献[56]表明基于TCG的方法能实现细粒度的分类,可分类出不同的浏览器应用程序(MicrosoftInternet、Mozilla、Explorer、Firefox、GoogleChrome).
流量特征未来研究方向基于现阶段的流量特征研究现状,未来的研究工作主要概括为以下五个方面:a)鲁棒性流量统计特征研究.
报文载荷和流级别的流量特征都可被模糊化技术弱化,未来趋于寻找稳定的流量特征,如能全局描述应用行为的流量特征,或者多流特征和基于连接图的流量特征相结合.
b)在线流量分类技术研究.
目前,描述通信行为的流量特征通常建立在大量的流量数据上面,为了实现在线分类,还需寻找提高此类流量特征的时效性的方法.
c)移动互联网流量特征提取研究.
网络应用在持续不断的发展,不断有新应用出现,特别是如今移动互联网中流行的移动终端应用(如微信、移动QQ等),而这些应用大多基于HTTP,描述特定协议的流量特征可能在移动终端应用上的区分能力较弱,流量特征的区分能力面临如何细分这些网络应用,即不仅区分出上层应用协议,还要区分功能.
d)网络流量特征面临的报文抽样技术研究.
报文抽样技术被广泛应用于流量数据的采集过程,抽样后的流量数据仅是全部流量数据的一部分,流量特征的部分信息会被丢失.
但是在网络流量分类领域,分析抽样技术对流量特征的影响还比较缺乏,如何选择抽样技术以及如何弥补流量特征在抽样后的信息丢失,使其能有效地进行流量分类仍是难点.
e)网络流量数据的不平衡问题研究[67].
某些高频率应用(如Web)拥有大量的流量,而某些应用如VoIP(voiceoverInternetprotocol)拥有相对较少的流量;在选取流量特征过程中可能偏向于有效分类拥有大量流量的应用,忽略了其他应用上的分类能力,选取流量特征过程中要注重流量数据的不平衡问题.
结束语互联网流量特征用于描述和测量网络流量,是互联网流量分类的关键基础,本文系统性地总结了基于机器学习和连接图的流量分类方法所采用的流量特征,主要工作包括以下四个方面:a)对流量特征的统计对象进行了归类,即基于报文头部的流量特征、基于流的流量特征和基于连接图的流量特征.
在基于流的流量特征中,进一步分为单流特征和多流特征,单流特征的应用最为广泛,本文进一步根据统计角度将传统流量特征分为报文相关、时间相关和连接相关的特征;对于近期提出的流量特征,进一步分为报文分布相关、消息相关、通信相关、载荷相关和子流相关等流量特征;b)在流量特征提取方面,总结了现今常用的特征自动统计工具,包括Tcptrace、Tstat、NetMate和Wireshark等;c)尽管多种流量特征被提出,但是流量特征在分类性能上不能保持稳定,受报文抽样、网络环境和模糊化技术多种因素影响,本文对这三方面的相关工作进行了分析和总结;d)本文基于当前研究,从分类能力、分类粒度、稳定性和时效性方面比较分析各类流量特征,并给出流量特征在未来的主要研究方向.
参考文献:[1]NguyenTTT.
Anovelapproachforpracticalrealtime,machinelearningbasedIPtrafficclassification[D].
Melbourne:SwinburneUniversityofTechnology,2009.
[2]SenS,SpatscheckO,WangD.
Accurate,scalableinnetworkidentificationofP2Ptrafficusingapplicationsignatures[C]//Procofthe13thInternationalConferenceonWorldWideWeb.
NewYork:ACMPress,2004:512521.
[3]KaragiannisT,PapagiannakiK,FaloutsosM.
BLINC:multileveltrafficclassificationinthedark[C]//ProcofACMSIGCOMMConferenceonApplications,Technologies,Architectures,andProtocolsforComputerCommunications.
NewYork:ACMPress,2005:229240.
[4]刘琼,刘珍,黄敏.
基于机器学习的IP流量分类研究[J].
计算机科学,2010,37(12):3540.
[5]AlshammariR,ZincirHeywoodAN.
Canencryptedtrafficbeidentifiedwithoutportnumbers,IPaddressesandpayloadinspection[J].
ComputerNetworks,2011,55(6):13261350.
[6]PescapéA,RossiD,TammaroD,etal.
Ontheimpactofsamplingontrafficmonitoringandanalysis[C]//Procofthe22ndInternationalTeletrafficCongress.
2010:18.
[7]McgregorA,HallM,LorierP,etal.
Flowclusteringusingmachinelearningtechniques[C]//Procofthe5thPassiveandActiveMeasurementWorkshop.
Berlin:Springer,2004:205214.
[8]RoughanM,SenS,SpatscheckO,etal.
Classofservicemappingforqos:astatisticalsignaturebasedapproachtoIPtrafficclassification[C]//Procofthe4thACMSIGCOMMConferenceonInternetMeasurement.
NewYork:ACMPress,2004:135148.
[9]MooreA,ZuevD.
Internettrafficclassificationusingbayesiananalysistechniques[C]//ProcofACMInternationalConferenceonMeasurementandModelingofComputerSystems.
NewYork:ACMPress,2005:5060.
[10]YuanRuixi,LiZhu,GuanXiaohong,etal.
AnSVMbasedmachinelearningmethodforaccurateinternettrafficclassification[J].
InformationSystemsFrontiers,2010,12(2):149156.
[11]ZhangJ,ChenX,XiangY,etal.
Robustnetworktrafficclassification[J].
IEEE/ACMTransonNetworking,2015,23(4):12571270.
[12]ZhangJun,XiangYang,WangYu,etal.
Networktrafficclassificationusingcorrelationinformation[J].
IEEETransonParallelandDistributedSystems,2013,24(1):104117.
[13]ZhangJun,XiangYang,ZhouWanlei,etal.
UnsupervisedtrafficclassificationusingflowstatisticalpropertiesandIPpacketpayload[J].
JournalofComputerandSystemSciences,2013,79(5):573585.
[14]XuMing,ZhuWenbo,XuJian,etal.
Towardsselectingoptimalfeaturesforflowstatisticalbasednetworktrafficclassification[C]//Procofthe17thNetworkOperationsandManagementSymposium.
2015:479482.
[15]WangYu,XiangYang,ZhangJun,etal.
Internettrafficclusteringwith·31·第1期刘珍,等:互联网流量分类中流量特征研究sideinformation[J].
JournalofComputerandSystemSciences,2014,80(5):10211036.
[16]ZhangJun,ChenChao,XiangYang,etal.
Semisupervisedandcompoundclassificationofnetworktraffic[C]//Procofthe32ndInternationalConferenceonDistributedComputingSystems.
2012:617621.
[17]SantiagoLPS,DeCastroJL,BessaMaiaJE.
NTCS:arealtimeflowbasednetworktrafficclassificationsystem[C]//ProcofInternationalConferenceonNetworkandServiceManagement.
2014:368371.
[18]CamachoJ,PadillaP,GarcíaTeodoroP,etal.
Ageneralizabledynamicflowpairingmethodfortrafficclassification[J].
ComputerNetworks,2013,57(14):27182732.
[19]董仕,丁伟.
基于流记录偏好度的多分类器融合流量识别模型[J].
通信学报,2013,34(10):143152.
[20]林平,余循宜,刘芳,等.
基于流统计特性的网络流量分类算法[J].
北京邮电大学学报,2008,31(2):1519.
[21]LinYingdan,LuChunnan,LaiYC,etal.
Applicationclassificationusingpacketsizedistributionandportassociation[J].
JournalofNetworkandComputerApplications,2009,32(5):10231030.
[22]QinTao,WangLei,LiuZhaoli,etal.
RobustapplicationidentificationmethodsforP2PandVoIPtrafficclassificationinbackbonenetworks[J].
KnowledgeBasedSystems,2015,82(3):152162.
[23]DainottiA,PescapéA,KimH.
Trafficclassificationthroughjointdistributionsofpacketlevelstatistics[C]//ProcofIEEEGlobalCommunicationsConference.
2011:16.
[24]HajjarA,KhalifeJ,DíazVerdejoJ.
Networktrafficapplicationidentificationbasedonmessagesizeanalysis[J].
JournalofNetworkandComputerApplications,2015,58(12):130143.
[25]YinCG,LiSQ,LiQ.
NetworktrafficclassificationviaHMMundertheguidanceofsyntacticstructure[J].
ComputerNetworks,2012,56(6):18141825.
[26]FinamoreA,MelliaM,MeoM,etal.
KISSstochasticpacketinspectionclassifierforUDPtraffic[J].
IEEE/ACMTransonNetworking,2010,18(5):15051515.
[27]ParkB,HongJWK,WonYJ.
Towardfinegrainedtrafficclassification[J].
IEEECommunicationsMagazine,2011,49(7):104111.
[28]RizziaA,IacovazziaA,BaiocchiaA,etal.
AlowcomplexityrealtimeInternettrafficflowsneurofuzzyclassifier[J].
ComputerNetworks,2015,91(11):752771.
[29]PengLizhi,YangBo,ChenYuehui.
Effectivepacketnumberforearlystageinternettrafficidentification[J].
Neurocomputing,2015,156(5):252267.
[30]NguyenTTT,ArmitageG,BranchP,etal.
TimelyandcontinuousmachinelearningbasedclassificationforInteractiveIPtraffic[J].
IEEE/ACMTransonNetworking,2012,20(6):18801894.
[31]张宏莉,鲁刚.
分类不平衡协议流的机器学习算法评估与比较[J].
软件学报,2012,23(6):15001516.
[32]杨哲,李领治,纪其进,等.
基于最短划分距离的网络流量决策树分类方法[J].
通信学报,2012,33(3):90102.
[33]LiJun,ZhangShunyi,LiCuilian,etal.
Compositelightweighttrafficclassificationsystemfornetworkmanagement[J].
InternationalJournalNetworkManagement,2010,20(2):85105.
[34]DewaeleG,HimuraY,BorgnatP,etal.
Unsupervisedhostbehaviorclassificationfromconnectionpatterns[J].
InternationalJournalofNetworkManagement,2010,20(5):317337.
[35]JiangHongbo,GeZihui,JinShudong,etal.
Networkprefixleveltrafficprofiling:characterizing,modeling,andevaluation[J].
ComputerNetworks,2010,54(18):33273340.
[36]ValentiS,RossiD.
IdentifyingkeyfeaturesforP2Ptrafficclassification[C]//ProcofIEEEInternationalConferenceonCommunications.
2011:16.
[37]BermolenP,MelliaM,MeobM,etal.
Abacus:accuratebehavioralclassificationofP2PTVtraffic[J].
ComputerNetworks,2011,55(6):13941411.
[38]李致远,王汝传.
一种基于机器学习的P2P网络流量识别方法[J].
计算机研究与发展,2012,48(12):22532260.
[39]陆悠,李伟,罗军舟,等.
一种基于选择性协同学习的网络用户异常行为检测方法[J].
计算机学报,2014,37(1):2840.
[40]叶春明,王珍,陈思,等.
基于节点行为特征分析的网络流量分类方法[J].
电子与信息学报,2014,36(9):21582165.
[41]LeeS,SongJ,AhnS,etal.
Sessionbasedclassificationofinternetapplicationsin3Gwirelessnetworks[J].
ComputerNetworks,2011,55(17):39153931.
[42]MooreA,ZuevD,CroganM.
Discriminatorsforuseinflowbasedclassification[R].
London:DepartmentofComputerScience,QueenMaryUniversityofLondon,2005.
[43]AlHarthiA,TariZ,KhalilI,etal.
Towardanefficientandscalablefeatureselectionapproachforinternettrafficclassification[J].
ComputerNetworks,2013,57(9):20402057.
[44]HongYang,HuangChangcheng,NandyB,etal.
Iterativetuningsupportvectormachinefornetworktrafficclassification[C]//ProcofIFIP/IEEEInternationalSymposiumonIntegratedNetworkManagement.
2015:458466.
[45]LiDong,HuGuyu,WangYibing,etal.
Networktrafficclassificationvianonconvexmultitaskfeaturelearning[J].
Neurocomputing,2015,152(3):322332.
[46]DivakaranDM,SuLe,LiauYS,etal.
SLIC:selflearningintelligentclassifierfornetworktraffic[J].
ComputerNetworks,2015,91:283297.
[47]赵小欢,夏靖波,李明辉.
基于随机森林算法的网络流量分类方法[J].
电子科学研究院学报,2013,8(2):184190.
[48]高文,钱亚冠,吴春明,等.
网络流量特征选择方法中的分治投票策略研究[J].
电子学报,2015,43(4):795799.
[49]刘珍,王若愚,刘琼.
基于Bootstrapping的因特网流量分类方法研究[J].
北京邮电大学学报,2014,5(37):6670,79.
[50]HuangNF,JaiGY,ChaoHC,etal.
Applicationtrafficclassificationattheearlystagebycharacterizingapplicationrounds[J].
InformationSciences,2013,232(5):130142.
[51]KhalifeJ,HajjarA,DiazVerdejoJ.
Amultileveltaxonomyandrequirementsforanoptimaltrafficclassificationmodel[J].
InternationalJournalofNetworkManagement,2014,24(2):101120.
[52]IliofotouM,KimH,FaloutsosM,etal.
Graption:agraphbasedP2Ptrafficclassificationframeworkfortheinternetbackbone[J].
ComputerNetworks,2011,55(8):19091920.
[53]GallagherB,IliofotouM,EliassiRadT,etal.
Linkhomophilyintheapplicationlayeranditsusageintrafficclassification[C]//ProcofINFOCOM.
2010:221225.
[54]张震,汪斌强,陈鸿昶,等.
互联网中基于用户连接图的流量分类机制[J].
电子与信息学报,2013,35(4):958964.
[55]JinY,DuffieldN,HaffnerP,etal.
Inferringapplicationsatthenetworklayerusingcollectivetrafficstatistics[C]//Procofthe22ndInternationalTeletrafficCongress.
2010:18.
[56]AsaiH,FukudaK,EsakiH.
Trafficcausalitygraphs:profilingnetworkapplicationsthroughtemporalandspatialcausalityofflows[C]//Procofthe23rdInternationalTeletrafficCongress.
2011:95102.
[57]MongkolluksameeS,VisoottivisethV,FukudaK.
Enhancingtheperformanceofmobiletrafficidentificationwithcommunicationpatterns[C]//Procofthe39thAnnualInternationalComputers,Software&ApplicationsConference.
2015:336345.
(下转第41页)·41·计算机应用研究第34卷指标,即地域的连续性、节点的同构性、节点对基础设施的共享性以及人口规模的均衡性.
为满足城市社区划分的指标,本文以云聚合的凝聚、重组和循环过程为理论支撑,提出了基于云聚合理论的社区划分算法.
本文采用MATLAB对城市社区划分算法进行实验,并与经典的同类凝聚算法及真实的城市社区结构进行对比,验证了本文算法的真实性、有效性及优越性.
本文提出的云聚合理论是一种新型的理论,基于云聚合理论的城市社区划分算法是在社区划分算法基础上的一次突破,为城市社区的划分与规划提供了有效的手段,但文中的划分算法仍存在局限.
在本文的基础上,进一步的研究工作可以从以下三个方面展开:a)节点的定义,本文将城市的社区视为最小单位个体———节点,忽略了组成社区节点的家庭抑或个人之间存在的异构性;b)节点同构性和基础设施共享性的精细化,本文仅将人口、年龄、人均占地面积和基础设施个数作为节点的属性,同时基础设施也只考虑了学校、医院和商场,存在局限性;c)更进一步的算法有效性分析,本文通过将实验划分结果与真实的城市社区结构进行比较,从而说明划分算法的有效性,但是由于条件限制,本文主要采集的数据局限于南京主城区,需要进一步对大范围的社区节点进行数据采集和分析,从而进一步验证算法的有效性.
参考文献:[1]DuttS.
NewfasterKernighanLintypegraphpartitioningalgorithms[C]//ProcofIEEE/ACMInternationalConferenceonComputerAidedDesign.
LosAlumitos:IEEEComputerSocietyPress,1993:370377.
[2]MannaK,ChoubeyV,ChattopadhyayS,etal.
ThermalvarianceawareapplicationmappingformeshbasednetworkonchipdesignusingKernighanLinpartitioning[C]//ProcofInternationalConferenceonParallel,DistributedandGridComputing.
2014:274279.
[3]RuanJianhua,ZhangWeixiong.
Anefficientspectralalgorithmfornetworkcommunitydiscoveryanditsapplicationstobiologicalandsocialnetworks[C]//Procofthe7thIEEEInternationalConferenceonDataMining.
WashingtonDC:IEEEComputerSociety,2007:643648.
[4]GouShuiping,ZhuangXiong.
ParallelsparsespectralclusteringforSARimagesegmentation[J].
IEEEJournalofSelectedTopicsinAppliedEarthObservationsandRemoteSensing,2013,6(4):19491963.
[5]WangHuiqing,ChenJunjie,HuangShaobin,etal.
Aheuristicinitializationindependentspectralclustering[C]//Procofthe5thInternationalConferenceonInternetComputingforScienceandEngineering.
WashingtonDC:IEEEComputerSociety,2010:8184.
[6]OnoH.
Fastrandomwalksonfinitegraphsandgraphtopologicalinformation[C]//Procofthe2ndInternationalConferenceonNetworkingandComputing.
WashingtonDC:IEEEComputerSociety,2011:360363.
[7]PallaG,DerenyiI,FarkasI,etal.
Uncoveringtheoverlappingcommunitystructureofcomplexnetworksinnatureandsociety[J].
Nature,2005,435(7043):814818.
[8]PallaG,FarkasI,PollnerP,etal.
Directednetworkmodules[J].
NewJournalofPhysical,2007,9(6):186.
[9]NewmanMEJ.
Fastalgorithmfordetectingcommunitystructureinnetworks[J].
PhysicalReviewE,2004,69(6):066133.
[10]GirvanM,NewmanMEJ.
Communitystructureinsocialandbiologicalnetworks[J].
ProceedingsoftheNationalAcademyofSciencesoftheUSA,2001,99(12):78217826.
[11]TylerJ,WilkinsonD,HubermanB.
Emailasspectroscopy:automateddiscoveryofcommunitystructurewithinorganizations[C]//Procofthe1stInternationalConferenceonCommunitiesandTechnologies.
2003:8196.
[12]RadicchiF,CastellanoC,CecconiF,etal.
Definingandidentifyingcommunitiesinnetworks[J].
ProceedingsoftheNationalAcademyofSciencesoftheUSA,2004,101(9):26582663.
[13]ChenGuoqiang,GuoXiaofang.
Ageneticalgorithmbasedonmodularitydensityfordetectingcommunitystructureincomplexnetworks[C]//ProcofInternationalConferenceonComputationalIntelligenceandSecurity.
WashingtonDC:IEEEComputerSociety,2011:151154.
[14]ClausetA,NewmanMEJ,MooreC.
Findingcommunitystructureinverylargenetworks[J].
PhysicalReviewE,2005,70(6):066111.
[15]DinhTN,ThaiM.
Findingcommunitystructurewithperformanceguaranteesinscalefreenetworks[C]//ProcofIEEEInternationalConferenceonPrivacy,Security,Risk,andTrust.
2011:888891.
[16]WangXiaohan,ChenZhaoqun.
Edgebalanceratio:powerlawfromverticestoedgesindirectedcomplexnetwork[J].
IEEEJournalofSelectedTopicsinSignalProcessing,2013,7(2):184194.
[17]TangJin,JiangBo,ChangChinchen,etal.
Graphstructureanalysisbasedoncomplexnetwork[J].
DigitalSignalProcessing,2012,22(5):713725.
[18]李孝伟,陈福才,刘力雄.
一种融合节点与链接属性的社交网络社区划分算法[J].
计算机应用研究,2013,30(5):14771480.
(上接第14页)[58]DuffieldN,LundC,ThorupM.
Estimatingflowdistributionsfromsampledflowstatistics[J].
IEEE/ACMTransonNetworking,2003,13(5):325336.
[59]张进,邬江兴,钮晓娜.
空间高效的数据包公平抽样算法[J].
软件学报,2010,21(10):24422655.
[60]CarelaEspanolV,BarletRosP,CabellosAparicioA,etal.
AnalysisoftheimpactofsamplingonNetFlowtrafficclassification[J].
ComputerNetworks,2011,55(5):10831099.
[61]TammaroD,ValentiS,RossiD,etal.
Exploitingpacketsamplingmeasurementsfortrafficcharacterizationandclassification[J].
InternationalJournalofNetworkManagement,2012,22(6):451476.
[62]EsteA,GringoliF,SalgarelliL.
Onthestabilityoftheinformationcarriedbytrafficflowfeaturesatthepacketlevel[J].
ACMSIGCOMMComputerCommunicationReview,2009,39(3):1318.
[63]JaberM,CascellaRG,BarakatC.
Canwetrusttheinterpackettimefortrafficclassification[C]//ProcofIEEEInternationalConferenceonCommunications.
2011:15.
[64]IliofotouM,GallagherB,EliassiRadT,etal.
ProfilingbyAssociation:aresilienttrafficprofilingsolutionfortheInternetbackbone[C]//ProcofACMConferenceonEmergingNetworkingExperimentandTechnology.
NewYork:ACMPress,2010.
112.
[65]HjelmvikE,JohnW.
Breakingandimprovingprotocolobfuscation[R].
Gothenburg:ChalmersUniversityofTechnology,2010:134.
[66]LuGang,ZhangHongli,QassrawiM,etal.
Comparisonandanalysisofflowfeaturesatthepacketlevelfortrafficclassification[C]//ProcofInternationalConferenceonConnectedVehicles&Expo.
WashingtonDC:IEEEComputerSociety,2012:262267.
[67]LiuZhen,WangRY,TaoM,etal.
Aclassorientedfeatureselectionapproachformulticlassimbalancedtrafficdatasetsbasedonlocalandglobalmetricsfusion[J].
Neurocomputing,2015,168(11):365381.
·14·第1期顾宏博,等:基于云聚合理论的城市社区划分算法研究
com);王若愚,博士,主要研究方向为计算机网络、模式分类;蔡先发,博士,主要研究方向为模式识别;唐德玉,博士,主要研究方向为数据挖掘.
互联网流量分类中流量特征研究刘珍1,王若愚2,蔡先发1,唐德玉1(1.
广东药科大学医药信息工程学院,广州510006;2.
华南理工大学信息工程研究中心,广州510006)摘要:为了系统性分析互联网流量特征,根据统计对象或统计角度研究流量特征的归类法,展开评述了每类流量特征;针对流量特征的稳定性问题,分析报文抽样、网络环境和模糊化技术对流量特征的影响;从分类能力、稳定性、时效性和分类粒度等方面评述流量特征的优缺点,为流量特征应用提供指导性建议;最后总结了流量特征的未来研究方向.
关键词:互联网流量特征;互联网流量分类;网络测量;机器学习;连接图中图分类号:TP393.
06文献标志码:A文章编号:10013695(2017)01000807doi:10.
3969/j.
issn.
10013695.
2017.
01.
002SurveyontrafficfeaturesinInternettrafficclassificationLiuZhen1,WangRuoyu2,CaiXianfa1,TangDeyu1(1.
SchoolofMedicalInformationEngineering,GuangdongPharmaceuticalUniversity,Guangzhou510006,China;2.
Information&NetworkEngineering&ResearchCenter,SouthChinaUniversityofTechnology,Guangzhou510006,China)Abstract:InordertosystematicallyanalyzeInternettrafficfeatures,thispaperresearchedthetaxonomyoftrafficfeaturesbasedontheobjectsusedforbuildingtrafficfeatures,andoverviewedtherelatedtrafficfeaturesineachcategory.
Itfurtheranalyzedthestabilityoftrafficfeatures,theimpactofpacketsampling,networkenvironmentandobfuscatingontrafficfeatures.
Andthenitcomparedthedifferentkindsoftrafficfeaturesfromclassificationaccuracy,stability,timelinessandgranularity.
Finally,thispaperconcludedfutureworksabouttrafficfeatures.
Keywords:Internettrafficfeatures;Internettrafficclassification;networkmeasurement;machinelearning;connectivitygraph引言互联网流量分类是网络测量的一个重要分支,旨在通过特定的技术手段,从大量的网络流量中识别单类应用或区分多类应用(如Web、Attack、P2P等)的流量.
互联网流量分类技术不仅是网络管理员进行流量整形、网络容量规划、异常检测、QoS部署和网络计费的重要手段,也是研究者开展应用协议研究的重要依据[1].
流量特征用于描述和测量网络流量,其作为流量分类算法的输入,是实现IP报文到网络应用识别的重要桥梁.
为了适应新应用或应对旧应用的逃避检测策略,互联网流量分类方法在不断改进,流量特征也随之演进.
早期每种网络应用采用固定的端口号,端口号作为流量特征便可实现IP报文到网络应用的映射,如80端口号对应HTTP的上层应用,但是端口号映射法随着动态端口和端口伪装技术出现而逐步失效.
随之出现了基于载荷特征字段的深度报文探测(deeppacketinception,DPI)方法[2],此方法基于载荷为每种应用提取有代表性的正则表达式或字符串作为流量特征,用于实现网络流量分类,但是这类方法无法识别载荷加密的报文.
为了克服动态端口号、端口伪装和载荷加密等,出现基于连接图和基于机器学习的流量分类方法,并成为近年来的研究热点.
例如,Karagiannis等人[3]提出基于主机通信行为的方法,从社会、功能和应用三个层面分析了网络应用的行为,基于源IP、目的IP、源端口、目的端口和传输层协议建立主流应用(Attack、Web、Games、Chat、P2P等)的通信行为模式,运用启发式规则进行流量分类.
此类方法中,将主机间的连接数等作为流量特征描述网络流量.
基于机器学习的流量分类方法将机器学习方法引入网络流量分类领域[4],这类技术利用流(flow)表现出来的不同统计特征进行流量分类,如流长度、报文数、报文到达时间间隔及其统计运算等.
但是大部分文献使用不同的流量特征,且流量特征描述不统一.
如何区分和选取流量特征仍未得到系统性研究.
此外,采用报文抽样技术获取的流量数据可能因流量中丢失了部分报文而导致某些流量特征值不稳定.
不同网络的流量数据表现出不同的特点,对于骨干网,经常因网络繁忙而发生拥塞,造成"报文到达时间间隔"特征的鉴别能力不再可靠.
系统分析和归类流量特征并探讨流量特征的稳定性,对流量特征选取和训练鲁棒的流量分类器尤为重要.
本文系统性地研究互联网流量特征,论述了运营网中进行互联网流量分类的重要意义,指出流量特征在解决流量分类问题中的关键性作用和面临的开放性问题.
介绍了相关概念,总结归纳基于机器学习和连接图的流量分类方法的相关流量特征,提出流量特征的归类法(taxonomy);分析流量特征的影响因素,主要分析报文抽样、网络环境和流量模糊化技术对流量特征的影响,对不同类型的流量特征进行了比较分析,并对流第34卷第1期2017年1月计算机应用研究ApplicationResearchofComputersVol34No1Jan.
2017量特征未来的研究方向进行了展望.
流量特征归类与分析相关概念a)单向流(unidirectionalflow).
在单向通信方向上,由具有相同五元组{源IP地址,目的IP地址,源端口号,目的端口号,传输层协议}值的报文分组序列组成,如图1中的流1和流2所示.
b)双向流(bidirectionalflow).
在同一源和目的节点{IP,port}之间的通信中,由方向相反的两条单向流组成,如图1表示的流1和流2合并组成双向流.
c)流量特征.
用于描述或测量网络流量,利用IP报文或网络流进行统计计算,如报文长度、报文数目、流持续时间等,如图1标志的流量特征.
d)流样本.
流样本通常是指由流量特征向量值表达的网络流.
流量特征在大量的互联网流量分类文献中,多种流量特征被提出,比较常用的特征有报文大小、流持续时间、报文到达时间间隔等相关特征.
根据流量特征的统计对象,互联网流量特征的归类法如图2所示.
!
"#$%&'()*+,-.
$%&'()#/$.
$%&'()012.
$%&'3,-*,456*,7$&'8$&'2!
"#$%&'.
9:;121基于报文头部的流量特征基于报文头部的流量特征从单个报文头部的字段提取得到,如表1所示,包括帧头部、IP头部和传输层头部.
帧头部的特征包括帧长度、报文长度等;IP头部包括IP头校验和、IP协议、TTL(timetolive)标记等;传输层头部包括端口号、TCP标记、push标记、UDP标记等.
但是,基于报文头部的特征在类间的区分能力有限,如Alshammari等人[5]的研究结果表明,相比于基于流的流量特征,基于报文头部的流量特征的分类性能较弱.
为了保证流量分类性能,基于报文头部的流量特征通常与基于流的特征一起作为特征集合描述网络流量.
表1基于报文头部的流量特征文献流量特征[5]帧头部:报文长度、帧长度、采集长度、帧是否标记IP头部:头部长度、保留位、分配偏移、TTL、校验和等TCP头部:分片长度、序号、下一个序号、头部长度、标记、校验和、窗口大小等UDP头部:长度、校验和、校验和设置为真(假)[6]IP头部:TOS(typeofservice),TTL,报文长度,IP协议类型,比特率UDP或TCP头部:源端口号、目的端口号122基于流的流量特征流级别的流量特征是统计每条流中多个报文分组表现出的统计特性,此类特征应用较为广泛.
根据统计的网络流对象,流级别的流量特征可进一步分为单流特征和多流特征,分别如表2和3所示.
1)单流特征McGregor和Roughan等人[7,8]运用报文大小、报文到达时间间隔等处理基于机器学习的流量分类问题.
单流特征中最有代表的是Moore等人[42]提出的248个特征,主要从端口号、报文分组大小和报文到达时间间隔等方面进行特征统计,并得到广泛应用[11,43~49].
这些传统的单流特征从提取角度可进一步分为报文相关、时间相关和连接相关的流量特征.
表2表明,大多文献采用报文相关和时间相关的流量特征.
报文相关的流量特征包括报文数、报文大小(如均值、中值、方差等)、某标志位设置的报文数、总体字节数等;时间相关的流量特征主要包括报文到达时间间隔、流持续时间、空闲时间的平均值、方差等;连接相关的流量特征包括吞吐量、丢包率、窗口大小等.
但是,这些传统流量特征的取值易受网络环境的影响,如报文到达时间间隔、窗口大小、吞吐量等与实际的网络带宽使用情况有关.
随后,从新角度提取的流量特征被提出,如基于报文大小取值分布[21,22].
报文大小分布的统计特性不仅表现报文的大小,还可反映通信过程中报文大小的变化情况,较鲁棒于网络环境的影响,能在一定程度上提高分类鲁棒性.
近期文献又提出了新的特征统计对象,如文献[24]提出将消息用于特征统计计算(前向和后向消息大小),文中将消息定义为在同方向上连续通信的多个报文;文献[50]根据通信两端报文传输的一个往返(round)进行特征提取,如Ii的TiA和TiB的数据片段的个数和字节数、Ii和Ii+1的时间间隔、TiA和TiB的平均时间间隔等,其中Ii、TiA和TiB的定义如图3所示.
更有文献[26,27]以报文载荷作为特征的提取对象,如计算载荷数据的取值分布,其中载荷的取值不代表特定的含义,这不同于DPI方法(为每种应用提取有代表的字符串).
.
另一方面,为了实现在线的流量分类问题,提出子流(subflow)特征的概念,即仅对网络流中的K个报文(K通常小于10)进行统计特征值的计算,而无须等到一条流的结束.
如文献[28]对一条流的前K个报文提取三个特征:报文方向、载荷大小和时间戳;文献[29]提取早期有序的带载荷报文的报文大小,并讨论分析多少个带载荷报文对流量分类性能有较大贡献,实验结果表明第3~8个报文对分类性能贡献较大,前两个报文的贡献较小.
在众多的单流特征中,报文长度和报文到达时间间隔及其统计(如平均值、最小值、最大值等)的运用频率较高[51],如文献[11~13]都采用了的报文数、字节数、报文大小、报文到达时间间隔相关的20个流量特征.
但是,单流特征易受网络环境、报文抽样、模糊化技术的影响,如何提高单流特征的鲁棒性仍是开放性问题.
2)多流特征多流特征是对聚合的多条网络流进行统计特征提取,其中统计的流量范围可分为主机的流量、网络段的流量、节点的流量和会话的流量,如表3所示.
·9·第1期刘珍,等:互联网流量分类中流量特征研究表2单流特征文献报文相关时间相关连接相关[7]报文大小(最小值、最大值、四分位数),字节数流持续时间,报文到达时间间隔,空闲时间事务和块传输之间的转换次数[8]报文大小的平均值、方差值、均方根,报文数等流持续时间,报文到达时间间隔连接对称性,丢包率,延时等[9]端口号,报文大小(最小值、最大值、平均值、标准差),报文数,带某标记的报文数,总体字节数等报文到达时间间隔(最小值、最大值、平均值、标准差),流持续时间,传输时间,空闲时间,报文到达时间间隔傅里叶变换等吞吐量,初始化窗口大小,分片大小等[10]报文数目,报文大小,传输层协议,端口号等流持续时间窗口大小[11~13]双向的报文数,双向的字节数,报文大小(最小值、最大值、平均值、标准差)报文到达时间间隔(最小值、最大值、平均值、标准差)[14]报文大小(最小值、最大值、平均值、标准差)及其偏斜度(skewness)、峰度(kurtosis);载荷大小(最小值、最大值、平均值、标准差)及其偏斜度、峰度报文到达时间间隔(最小值、最大值、平均值、标准差)及其偏斜度、峰度[15,16]双向报文数,双向字节数,报文大小(最小值、最大值、平均值、标准差)报文到达时间间隔(最小值、最大值、平均值、标准差),流持续时间[17]总体字节数,带有TCP载荷的报文数,带有push标志位的报文数,报文字节数的中值和标准差流持续时间[18]传输层协议,IP地址,端口号,报文数,第一个和最后一个报文的时间戳,正向和反向报文数等流持续时间,报文到达时间间隔的平均值、最大值、最小值,前向和后向报文到达时间间隔平均值、最大值、最小值[19]总体报文数,总体字节数,双向报文数比,双向字节数比,传输层协议,双向的端口号等流持续时间,报文数与流持续时间的比值,字节数与流持续时间的比值,流持续时间与报文数的比值,报文到达时间间隔[20]传输层协议,报文个数,上行和下行流量,流速率,总载荷字节数等流持续时间,报文到达时间间隔报文分布[21]报文大小分布,端口号[22]报文大小比率px(px表示报文大小为x的报文数比率,x=1,…,n)[23]报文大小和报文到达时间间隔联合分布,上行报文数与上下行报文数的比值,双向流持续时间等消息相关[24]前向第m个消息的大小,后向第m个消息的大小通信相关[25]基于状态机,给定一个状态,状态间的转移概率和对于报文提取的某些特征(报文长度和方向)载荷相关[26]对一条流中的C个报文,提取每个报文的前N个字节,将这些字节分成G个组,每个组由b位组成,因此每个组的取值范围为[0,2b-1],利用卡方检验方法,建立特征向量X=[X1,X2,…,Xg]Xg=∑2b-1i=0(O(g)i-E(g)i)2E(g)i,O(g)i表示第g组取第i个值的报文个数,E(g)i表示在g组里面取第i个取值的期望值[27]一个项(term)表示包括i个字节的滑动窗口内的载荷数据,一个项的大小为i字节,项集合的大小为28i,特征向量表示为[w1,w2,…,wm]Twj表示在一个报文中第j项出现的频率,m表示项的全集大小子流特征[28]第j个报文的方向,载荷大小和时间戳,j=1,…,M[29]有序的前10个报文的大小[30]子流的前向和后向的报文大小差异(最小值、最大值、平均值、标准差),报文大小(最小值、最大值、平均值、标准差),报文到达时间间隔(最小值、最大值、平均值、标准差)[31]对TCP连接开始的前4~10个报文(包括TCP连接3次握手的数据包)的报文大小和报文到达时间间隔的统计信息,以及与TCP标志位相关的统计信息等[32]端口号,前N个报文的载荷大小,前N个报文的有向信息熵(描述某个报文载荷取值的随机性),双向N个报文的有向信息熵之和,前N个报文的方向[33]前p个报文的源端口号,目的端口号,总报文数,总字节数,报文载荷大小(最小值、最大值、平均值、标准差),报文长度(最小值、最大值、平均值、标准差),流持续时间,报文到达时间间隔(最小值、最大值、平均值、标准差)等林平等人[20]在多流特征方面,基于主机的流量提出源源、源宿、宿源和宿宿流量相关流的统计特征("源源"是指源地址与待分类流的源地址相同的流集合,"源宿"是指宿地址与待分类流的源地址相同的流集合,"宿源"指源地址与待分类流的宿地址相同的流集合,"宿宿"是指宿地址与待分类流的宿地址相同的流集合).
Jiang等人[35]基于网络段的流量提取流量特征,如某网段内的流容量在时间、地点和应用上的分布等.
Valenti等人[36]为分类P2P流量,基于节点{IP,port}从双向流提取102个统计特征,如当前时间槽的流数目、当前时间槽与前一时间槽的报文速率的变化等.
Bermolen等人[37]提取在一定时间间隔内发送k个报文或字节到观察节点{IP,port}的节点数的比例.
Lee等人[41]将某应用在两个主机间通信的所有网络流组成一个会话,提出基于会话的流量特征,如会话的持续时间、会话的流数目等.
多流特征比单流特征包含的信息量更丰富,表现更为稳定,其中基于主机和节点的流量特征通常用于P2P的识别或者异常行为探测;多流特征也可与单流特征共同用于流量分类[20].
123基于连接图的流量特征基于连接图(connectivitygraph)的流量分类方法,通常将图的性质所表现的流量特征与基于流的流量特征相结合用于分类.
该部分主要叙述基于图的流量特征,具体情况如表4所示.
根据近期文献的连接图,顶点可归纳为四种:主机[52,53]、{IP,port}对[54,55]、网络流[56]、五元组[57].
对于主机和{IP,port}对,通常边表示两个顶点之间有数据通信:主机之间只要有数据传输则建立一条边[52,55],主机间的每条边对应一条网络流[53].
网络流为顶点的连接图中,边则代表网络流间的关系[56].
在五元组为顶点的连接图中,则对在一条流中的五元组建立边[57].
基于连接图的流量特征能表现网络应用在主机间的通信行为,具有较高的稳定性,不易受网络环境和网络应·01·计算机应用研究第34卷用更新的影响.
各种连接图特征的定义如表4所示.
表3多流特征文献流量特征主机[34]以主机为对象(IP地址),每流的平均报文数目,小字节报文(≤144Byte)的百分比,大字节报文(≥1392Byte)的百分比,中字节(>144,<1392)报文分布的信息熵,目的IP个数;源端口数和目的IP数的比值,目的端口数与目的IP数的比值,IP地址的第二个字节的信息熵与第四个字节的信息熵的比值;IP地址的第三个字节的信息熵与第四个字节的信息熵的比值[20]源源集合、源宿集合、宿源集合、宿宿集合的流数、源端口数、目的IP数、目的端口数、传输层协议网络前缀[35]流量字节容量;流量字节容量的时间、空间和应用分布;流字节大小分布;上载流量与下载流量的比值节点{IP,port}[36]当前时槽聚合流、报文和字节信息,当前时槽与前一时槽的变化(聚合流数、报文数、字节数),聚合流的计数比率(报文、字节)[37]在一定时间间隔内(5s)发送k个报文或字节到观察节点{IP,port}的节点数的比例[38]报文大小变化的均方差,上行下行流量的比值,资源请求端与资源提供端的IP和port数量的比值[39]平均、最大报文大小,报头大小,平均报文到达时间间隔,平均、最大流长度,上行和下行流量等[40]基于建立流量矩阵,计算节点出度熵,节点入度熵,熵指数R(出入度熵的差异)会话[41]第一个报文到达相对时间,最后一个报文到达相对时间,会话持续时间,会话流数目,流长度,第二时段的流长度,流长度标准差,流长度方差与流长度均值平方的比值,传输层协议表4基于连接图特征文献流量特征[52]基于TDG,顶点的平均边数,有输入也有输出顶点所占百分比,按升序排序的所有顶点间的距离中处于第90%位置的距离[55]基于TAG,主机hi所有边中属于类别Ck的边数与hi的总边数的比值,主机hj所有边中属于类别Ck的边数与hj的总边数的比值,hi的总边数,hj的总边数[53]基于TG,一条边的两个端点pi和pj,求pi所有边中属于类ci的概率和pj所有边中属于类ci的概率,两概率的平均值取做ci的后验概率[56]基于TCG,PR边数与CR边数的比值,DHR边数(DNS(domainnamesystem)请求到DNS请求)与DHR边数的比值[57]基于CPG,每一列的节点数ni(i是列的序号,i=1,…,5),在i到j方向上只有一个出度的节点数(j=±i),在i到j方向上的平均度数,i到j方向上的最大度数,具有最大度数的节点的后向度数[54]基于HCG,计算两个节点{IP,port}的相似度,若两个节点有直接通信(相邻),则相似度为无穷大,否则为各自相邻节点集合共享的节点数1)主机作为图中的顶点文献[52]提出TDG(trafficdispersiongraphs),定义如下:给定一组网络流S,采集于固定时间间隔,TDG定义为有向图G(V,E),点集V对应S的IP地址,对于u,v∈V,如果在u和v之间有网络流f∈S,表示u和v之间有连接,那么(u,v)∈E.
文献[53]提出TG(tracegraph),构建方法如下:一个顶点代表一个终端主机,一条边代表一条流,部分流具有类别属性;未知网络流则通过分析邻近网络流的类别属性进行类别鉴定.
2){IP,port}对作为图中的顶点文献[54]提出HCG,定义如下:HCG表示为G(V,E),将节点{IP,port}抽象为一个点vi∈V,若vi和vj之间有通信,则在vi和vj之间建立一条边eij∈E.
HCG的边表征了节点之间的交互,从行为学的角度,只要节点A向节点B发送了报文,则A必然存在向B索取某种信息或资源的意图,因此HCG根据以下原则建立边:对于UDP流,若A向B传送了报文;对于TCP流,若有SYN(synchronous)报文发送.
文献[55]提出TAG(trafficactivitygraph),定义如下:顶点代表终端节点{IP,port},若两个终端节点之间有通信就有一条边(一条边可能包含了多条流,论文基于了这样的假设:在一定时间间隔内,两终端节点之间的所有网络流属于同一种应用).
顶点的组成表示为{IH,OH},IH表示ISP(Internetserviceprovider)网络内部的IP,OH表示ISP网络外部的IP,TAG由二部图组成,即ISP网络内部或者网络外部的节点间的通信不表现出来.
3)流作为图中的顶点文献[56]提出TCG(trafficcausalitygraphs),定义如下:TCG中的点和边分别表示网络流和流间的因果关系.
TCG集中于四种类型因果关系:CR(communicationrelationship)、PR(propagationrelationship)、DHR(dynamicporthostrelationship)和SHR(staticporthostrelationship).
观察的两条网络流分别表示为f1和f2,四种类型的边分别定义如下:a)如果f1和f2满足protocol(f1)=protocol(f2),srcIp(f1)=dstIp(f2),srcPort(f1)=dstPort(f2),dstIp(f1)=srcIp(f2),dstPort(f1)=srcPort(f2),那么f1和f2之间建立CR关系边(表示一对一主机间的直接通信,即请求与响应的关系).
b)否则,如果f1和f2满足dstIp(f1)=srcIp(f2),那么f1和f2之间建立PR关系边(表示一条网络流传递信息到其他的网络流,如代理和转播).
c)否则,如果f1和f2满足srcIp(f1)=srcIp(f2),srcPort(f1)≠srcPort(f2),那么f1和f2之间建立DHR关系边(表示使用同一个IP地址但不同端口号的网络流间的关系,如Web浏览器使用多个端口号与服务器创建连接).
d)否则,如果f1和f2满足srcIp(f1)=srcIp(f2),srcPort(f1)=srcPort(f2),那么f1和f2之间建立SHR关系边(表示使用相同IP地址和端口号的网络流之间的关系,如某些端口扫描应用利用同一端口号进行一系列的端口扫描,或者服务器使用一个端口号去响应多个客户端的请求).
4)五元组作为图中顶点文献[57]基于CPG(communicationpatterngraph)提取特征.
CPG定义如下:图中的五种顶点分别表示源IP地址、协议、源端口号、目的端口号、目的IP地址的唯一取值;根据网络流的五元组取值进行连线,产生CPG的边,如图4所示,根据上面的两组五元组取值,CPG建立了七个顶点和六条边.
!
"0$0--.
"0$!
"#$%&,)*1'()2**+)#$%!
,2*流量特征提取工具为了便于流量特征的自动统计计算,已有研究组织开发了开源的流量特征提取工具,这些工具可根据需要提取不同的流量特征,几种常用的流量特征提取工具介绍如下.
1)TcptraceTcptrace(http://www.
tcptrace.
org/index.
html)是为分析TCP流量数据文件而开发,它的输入可以是各种流行的基于报文采集程序输出的文件,如tcpdump、snoop、EtherPeek、HPNetMetrix、WinDump.
Tcptrace能输出每个通信连接上观察到的各种信息,如持续时间、字节数、发送和接收到的片段,重传、往返时间,吞吐量等,也可以得到多个图形,用于进一步分析.
·11·第1期刘珍,等:互联网流量分类中流量特征研究2)TstatTstat(http://tstat.
tlc.
polito.
it/measure.
shtml)是Tcptrace上的进一步开发,可以在普通PC硬件或者数据采集卡进行在线的报文数据采集.
除此之外,Tstat还可分析已有的数据报文,支持各种dump格式,如libpcap库支持的格式等.
双向的TCP流分析可得到新的统计特征,如阻塞窗口大小、乱序片段等,这些信息在服务器和客户端有所区分,还可区分内网主机和外网主机.
3)NetMateNetMate(http://sourceforge.
net/projects/netmatemeter/)是网络流量测量和监控工具,可用于报文计数、延时或丢包测量和报文采集.
它的工作是监听网络流量,并将报文进行组流和计算网络流的测量指标,也可进行离线的流量测量,如测量报文数目、流量容量、报文速率、最小/最大/平均报文到达时间间隔和最小/最大/平均报文长度等.
4)WireSharkWireShark(https://www.
wireshark.
org/)是网络报文分析器,可用于在线采集网络报文,并解析报文,在界面显示报文内容;也可分析已有的报文数据,如由tcpdump/WinDump、Wireshark等采集的报文数据;Wireshark提供多种过滤规则,进行报文过滤.
基于此工具的报文分析功能可获取基于报头的相关特征[5].
流量特征的稳定性分析报文抽样对流量特征的影响Duffield等人[58]分析了随机1/N报文抽样对流量特征的影响,实验结果表明当N取值较大时,不同网络应用的流长度分布趋于接近,即流长度的类间区分能力减弱;张进等人[59]指出等概率抽样虽然能很好地保留数据包级流量信息,但却无法较完整地保留流级的流量信息,如并发流数目、流长度分布、各条数据流的流量.
Pescapé等人[6]深入分析了255个流量特征在抽样前后的稳定性,作者采用FleissChisquare和Hellingerdistance作为信息丢失的评估指标,研究结果表明大部分的流量特征受抽样影响显著,即255个特征中仅有34个有较好鲁棒性,其中10个特征来自于IP层,20个特征来自于TCP层,4个特征来自于UDP层;总结得出基于单个报文的特征比基于多个报文的特征较为鲁棒.
CarelaEspanol等人[60]基于未经报文抽样的流量数据研究在分类问题中随机1/N报文抽样对流量特征的影响,以原始的流量数据构建训练集,以经过抽样的流量数据构建测试集,并采用C4.
5决策树进行流量分类,结果表明有三个因素影响分类准确率:流分裂、流大小分布的变化、流量特征逆向估计错误,如报文数目、报文大小、流持续时间和报文到达时间间隔等流量特征出现显著性的逆向估计错误.
以上研究表明,报文抽样会明显减少报文个数,流量特征会有比较显著的变化.
Tammaro等人[61]分析多种报文抽样对单流特征和聚合流统计特征的影响,实验结果表明基于单个报文进行统计的流量特征鲁棒于报文抽样,复杂的统计特征比简单的流统计特征更稳定.
网络环境对流量特征的影响在流量数据的采集时间和采集地点对流量特征的影响方面,Este等人[62]分析了随着采集时间和采集地点的改变,流量特征携带的互信息的变化情况,关注的流量特征包括往返时延、IP内网/外网、报文载荷大小、报文到达时间间隔、报文传输方向.
它们的结果表明,针对三种网络的流量数据,报文载荷大小的互信息最高,且在不同流量数据间无显著性差异.
文献[63]指出报文到达时间间隔中的报文传输时间易受网络阻塞等因素影响,针对此问题,提取每流报文到达时间间隔后,去除其间可能隐含的报文传输延迟再进行统计计算,从而提高此特征的稳定性.
模糊化技术对流量特征的影响某些网络应用为了逃避检测,采用模糊化技术削弱流量特征的有效性,常见的流量特征模糊化有四种[64]:a)端口号模糊化,如P2P为逃避检测使用随机端口或熟知端口;b)报文载荷模糊化,如报文填充和载荷数据加密;c)流级别模糊化,如网络带宽动态变化、网络拥塞、报文发送时序变化等;d)连接级别的模糊化,如与服务器的动态连接、随机连接、隧道伪装等.
这些模糊化技术导致了流量特征取值的动态变化,例如,报文大小改变导致相关的流统计特征值变化,将削弱基于此的流量分类器的网络应用鉴别能力.
文献[65]在流量统计特征模糊化操作方面进行了总结.
a)基于TCP的网络应用模糊化报文大小的一种简单方式是随机清除发送缓冲区,即随机将缓冲的数据立即发出去,不用等到达到MTU(maximumtransmissionunit)的时刻,另一种方式是随机填充传输的数据报文;b)模糊化报文方向的方式为:在三次握手完成后,客户或服务端等待随机的时间后发送数据报文,等待随机的时间使得第一个报文的发送方向随机.
针对报文载荷和流级别的模糊化,文献[65]通过分析总结报文载荷及流取值的模糊化规律提出了34种新型流量特征.
但是这些新特征依赖于特定的流量数据,特征的取值规律和处理技术与网络环境相关,极易被新型网络环境和网络应用攻破.
流量特征的比较和未来研究方向流量特征比较分析本节根据分类能力、分类粒度、稳定性和时效性对各类流量特征进行了比较分析,如表5所示.
表5互联网流量特征比较特征种类分类能力分类粒度稳定性时效性基于报文头部的特征单流(全流)特征单流(子流)特征多流特征基于连接图的特征较低较高,与分类算法相关粗粒度或细粒度,与分类方法相关粗粒度在没有采用模糊化技术情况下,有较好的鲁棒性报文和时间相关的特征都易受报文抽样、报文丢失、网络阻塞等影响能反映连接通信行为的多流特征比单流特征的稳定性好稳定性较高高低中低低a)在分类能力方面,基于报文头部的特征在类间的区分能力较弱[5],其他流量特征在文献[4,51]中表现出较好的流量分类性能,实验表现的分类结果还与分类算法相关.
b)在分类粒度方面,基于报文头部和基于网络流的流量特征都可实现粗粒度[9]和细粒度[27]的分类,这要根据分类算法而定;基于连接图的方法中,描述主机连接的流量特征大多用于粗粒度的分类[52].
c)在分类稳定性方面,基于报文头部的流量特征仅依赖于单个报文进行特征提取,因此受报文抽样或网络环境的影响小;单流特征中,基于多个报文或时间的流量特征易受丢包或网络阻塞等的影响,不过报文相关的特征比时间相关的特征的稳定性更高,如文献[61]表明最大报文大小比RTT更稳定;基·21·计算机应用研究第34卷于多条流的特征中,能反映网络应用行为的流量特征具有较好的稳定性[37],而某些流量特征,如基于报文和到达时间间隔的PDF(probabilitydensityfunctions)的稳定性较差[66].
d)在时效性方面,基于报文头部的特征仅提取头部某些字段,统计开销小;单流特征中基于子流的流量特征无须等待流结束后进行特征计算,可用于在线分类;然而多流特征和基于连接图的流量特征需要在大量的流量数据上进行统计特征计算,时效性较低.
每篇文献采用的实验数据和分类方法不同,很难对这些流量特征进行公平的比较,流量特征表现出来的分类能力、分类粒度、稳定性和时效性还与具体的分类算法相关.
表5给出的归纳总结仅针对大部分情况而言,当然存在与表5不同的情况,如文献[56]表明基于TCG的方法能实现细粒度的分类,可分类出不同的浏览器应用程序(MicrosoftInternet、Mozilla、Explorer、Firefox、GoogleChrome).
流量特征未来研究方向基于现阶段的流量特征研究现状,未来的研究工作主要概括为以下五个方面:a)鲁棒性流量统计特征研究.
报文载荷和流级别的流量特征都可被模糊化技术弱化,未来趋于寻找稳定的流量特征,如能全局描述应用行为的流量特征,或者多流特征和基于连接图的流量特征相结合.
b)在线流量分类技术研究.
目前,描述通信行为的流量特征通常建立在大量的流量数据上面,为了实现在线分类,还需寻找提高此类流量特征的时效性的方法.
c)移动互联网流量特征提取研究.
网络应用在持续不断的发展,不断有新应用出现,特别是如今移动互联网中流行的移动终端应用(如微信、移动QQ等),而这些应用大多基于HTTP,描述特定协议的流量特征可能在移动终端应用上的区分能力较弱,流量特征的区分能力面临如何细分这些网络应用,即不仅区分出上层应用协议,还要区分功能.
d)网络流量特征面临的报文抽样技术研究.
报文抽样技术被广泛应用于流量数据的采集过程,抽样后的流量数据仅是全部流量数据的一部分,流量特征的部分信息会被丢失.
但是在网络流量分类领域,分析抽样技术对流量特征的影响还比较缺乏,如何选择抽样技术以及如何弥补流量特征在抽样后的信息丢失,使其能有效地进行流量分类仍是难点.
e)网络流量数据的不平衡问题研究[67].
某些高频率应用(如Web)拥有大量的流量,而某些应用如VoIP(voiceoverInternetprotocol)拥有相对较少的流量;在选取流量特征过程中可能偏向于有效分类拥有大量流量的应用,忽略了其他应用上的分类能力,选取流量特征过程中要注重流量数据的不平衡问题.
结束语互联网流量特征用于描述和测量网络流量,是互联网流量分类的关键基础,本文系统性地总结了基于机器学习和连接图的流量分类方法所采用的流量特征,主要工作包括以下四个方面:a)对流量特征的统计对象进行了归类,即基于报文头部的流量特征、基于流的流量特征和基于连接图的流量特征.
在基于流的流量特征中,进一步分为单流特征和多流特征,单流特征的应用最为广泛,本文进一步根据统计角度将传统流量特征分为报文相关、时间相关和连接相关的特征;对于近期提出的流量特征,进一步分为报文分布相关、消息相关、通信相关、载荷相关和子流相关等流量特征;b)在流量特征提取方面,总结了现今常用的特征自动统计工具,包括Tcptrace、Tstat、NetMate和Wireshark等;c)尽管多种流量特征被提出,但是流量特征在分类性能上不能保持稳定,受报文抽样、网络环境和模糊化技术多种因素影响,本文对这三方面的相关工作进行了分析和总结;d)本文基于当前研究,从分类能力、分类粒度、稳定性和时效性方面比较分析各类流量特征,并给出流量特征在未来的主要研究方向.
参考文献:[1]NguyenTTT.
Anovelapproachforpracticalrealtime,machinelearningbasedIPtrafficclassification[D].
Melbourne:SwinburneUniversityofTechnology,2009.
[2]SenS,SpatscheckO,WangD.
Accurate,scalableinnetworkidentificationofP2Ptrafficusingapplicationsignatures[C]//Procofthe13thInternationalConferenceonWorldWideWeb.
NewYork:ACMPress,2004:512521.
[3]KaragiannisT,PapagiannakiK,FaloutsosM.
BLINC:multileveltrafficclassificationinthedark[C]//ProcofACMSIGCOMMConferenceonApplications,Technologies,Architectures,andProtocolsforComputerCommunications.
NewYork:ACMPress,2005:229240.
[4]刘琼,刘珍,黄敏.
基于机器学习的IP流量分类研究[J].
计算机科学,2010,37(12):3540.
[5]AlshammariR,ZincirHeywoodAN.
Canencryptedtrafficbeidentifiedwithoutportnumbers,IPaddressesandpayloadinspection[J].
ComputerNetworks,2011,55(6):13261350.
[6]PescapéA,RossiD,TammaroD,etal.
Ontheimpactofsamplingontrafficmonitoringandanalysis[C]//Procofthe22ndInternationalTeletrafficCongress.
2010:18.
[7]McgregorA,HallM,LorierP,etal.
Flowclusteringusingmachinelearningtechniques[C]//Procofthe5thPassiveandActiveMeasurementWorkshop.
Berlin:Springer,2004:205214.
[8]RoughanM,SenS,SpatscheckO,etal.
Classofservicemappingforqos:astatisticalsignaturebasedapproachtoIPtrafficclassification[C]//Procofthe4thACMSIGCOMMConferenceonInternetMeasurement.
NewYork:ACMPress,2004:135148.
[9]MooreA,ZuevD.
Internettrafficclassificationusingbayesiananalysistechniques[C]//ProcofACMInternationalConferenceonMeasurementandModelingofComputerSystems.
NewYork:ACMPress,2005:5060.
[10]YuanRuixi,LiZhu,GuanXiaohong,etal.
AnSVMbasedmachinelearningmethodforaccurateinternettrafficclassification[J].
InformationSystemsFrontiers,2010,12(2):149156.
[11]ZhangJ,ChenX,XiangY,etal.
Robustnetworktrafficclassification[J].
IEEE/ACMTransonNetworking,2015,23(4):12571270.
[12]ZhangJun,XiangYang,WangYu,etal.
Networktrafficclassificationusingcorrelationinformation[J].
IEEETransonParallelandDistributedSystems,2013,24(1):104117.
[13]ZhangJun,XiangYang,ZhouWanlei,etal.
UnsupervisedtrafficclassificationusingflowstatisticalpropertiesandIPpacketpayload[J].
JournalofComputerandSystemSciences,2013,79(5):573585.
[14]XuMing,ZhuWenbo,XuJian,etal.
Towardsselectingoptimalfeaturesforflowstatisticalbasednetworktrafficclassification[C]//Procofthe17thNetworkOperationsandManagementSymposium.
2015:479482.
[15]WangYu,XiangYang,ZhangJun,etal.
Internettrafficclusteringwith·31·第1期刘珍,等:互联网流量分类中流量特征研究sideinformation[J].
JournalofComputerandSystemSciences,2014,80(5):10211036.
[16]ZhangJun,ChenChao,XiangYang,etal.
Semisupervisedandcompoundclassificationofnetworktraffic[C]//Procofthe32ndInternationalConferenceonDistributedComputingSystems.
2012:617621.
[17]SantiagoLPS,DeCastroJL,BessaMaiaJE.
NTCS:arealtimeflowbasednetworktrafficclassificationsystem[C]//ProcofInternationalConferenceonNetworkandServiceManagement.
2014:368371.
[18]CamachoJ,PadillaP,GarcíaTeodoroP,etal.
Ageneralizabledynamicflowpairingmethodfortrafficclassification[J].
ComputerNetworks,2013,57(14):27182732.
[19]董仕,丁伟.
基于流记录偏好度的多分类器融合流量识别模型[J].
通信学报,2013,34(10):143152.
[20]林平,余循宜,刘芳,等.
基于流统计特性的网络流量分类算法[J].
北京邮电大学学报,2008,31(2):1519.
[21]LinYingdan,LuChunnan,LaiYC,etal.
Applicationclassificationusingpacketsizedistributionandportassociation[J].
JournalofNetworkandComputerApplications,2009,32(5):10231030.
[22]QinTao,WangLei,LiuZhaoli,etal.
RobustapplicationidentificationmethodsforP2PandVoIPtrafficclassificationinbackbonenetworks[J].
KnowledgeBasedSystems,2015,82(3):152162.
[23]DainottiA,PescapéA,KimH.
Trafficclassificationthroughjointdistributionsofpacketlevelstatistics[C]//ProcofIEEEGlobalCommunicationsConference.
2011:16.
[24]HajjarA,KhalifeJ,DíazVerdejoJ.
Networktrafficapplicationidentificationbasedonmessagesizeanalysis[J].
JournalofNetworkandComputerApplications,2015,58(12):130143.
[25]YinCG,LiSQ,LiQ.
NetworktrafficclassificationviaHMMundertheguidanceofsyntacticstructure[J].
ComputerNetworks,2012,56(6):18141825.
[26]FinamoreA,MelliaM,MeoM,etal.
KISSstochasticpacketinspectionclassifierforUDPtraffic[J].
IEEE/ACMTransonNetworking,2010,18(5):15051515.
[27]ParkB,HongJWK,WonYJ.
Towardfinegrainedtrafficclassification[J].
IEEECommunicationsMagazine,2011,49(7):104111.
[28]RizziaA,IacovazziaA,BaiocchiaA,etal.
AlowcomplexityrealtimeInternettrafficflowsneurofuzzyclassifier[J].
ComputerNetworks,2015,91(11):752771.
[29]PengLizhi,YangBo,ChenYuehui.
Effectivepacketnumberforearlystageinternettrafficidentification[J].
Neurocomputing,2015,156(5):252267.
[30]NguyenTTT,ArmitageG,BranchP,etal.
TimelyandcontinuousmachinelearningbasedclassificationforInteractiveIPtraffic[J].
IEEE/ACMTransonNetworking,2012,20(6):18801894.
[31]张宏莉,鲁刚.
分类不平衡协议流的机器学习算法评估与比较[J].
软件学报,2012,23(6):15001516.
[32]杨哲,李领治,纪其进,等.
基于最短划分距离的网络流量决策树分类方法[J].
通信学报,2012,33(3):90102.
[33]LiJun,ZhangShunyi,LiCuilian,etal.
Compositelightweighttrafficclassificationsystemfornetworkmanagement[J].
InternationalJournalNetworkManagement,2010,20(2):85105.
[34]DewaeleG,HimuraY,BorgnatP,etal.
Unsupervisedhostbehaviorclassificationfromconnectionpatterns[J].
InternationalJournalofNetworkManagement,2010,20(5):317337.
[35]JiangHongbo,GeZihui,JinShudong,etal.
Networkprefixleveltrafficprofiling:characterizing,modeling,andevaluation[J].
ComputerNetworks,2010,54(18):33273340.
[36]ValentiS,RossiD.
IdentifyingkeyfeaturesforP2Ptrafficclassification[C]//ProcofIEEEInternationalConferenceonCommunications.
2011:16.
[37]BermolenP,MelliaM,MeobM,etal.
Abacus:accuratebehavioralclassificationofP2PTVtraffic[J].
ComputerNetworks,2011,55(6):13941411.
[38]李致远,王汝传.
一种基于机器学习的P2P网络流量识别方法[J].
计算机研究与发展,2012,48(12):22532260.
[39]陆悠,李伟,罗军舟,等.
一种基于选择性协同学习的网络用户异常行为检测方法[J].
计算机学报,2014,37(1):2840.
[40]叶春明,王珍,陈思,等.
基于节点行为特征分析的网络流量分类方法[J].
电子与信息学报,2014,36(9):21582165.
[41]LeeS,SongJ,AhnS,etal.
Sessionbasedclassificationofinternetapplicationsin3Gwirelessnetworks[J].
ComputerNetworks,2011,55(17):39153931.
[42]MooreA,ZuevD,CroganM.
Discriminatorsforuseinflowbasedclassification[R].
London:DepartmentofComputerScience,QueenMaryUniversityofLondon,2005.
[43]AlHarthiA,TariZ,KhalilI,etal.
Towardanefficientandscalablefeatureselectionapproachforinternettrafficclassification[J].
ComputerNetworks,2013,57(9):20402057.
[44]HongYang,HuangChangcheng,NandyB,etal.
Iterativetuningsupportvectormachinefornetworktrafficclassification[C]//ProcofIFIP/IEEEInternationalSymposiumonIntegratedNetworkManagement.
2015:458466.
[45]LiDong,HuGuyu,WangYibing,etal.
Networktrafficclassificationvianonconvexmultitaskfeaturelearning[J].
Neurocomputing,2015,152(3):322332.
[46]DivakaranDM,SuLe,LiauYS,etal.
SLIC:selflearningintelligentclassifierfornetworktraffic[J].
ComputerNetworks,2015,91:283297.
[47]赵小欢,夏靖波,李明辉.
基于随机森林算法的网络流量分类方法[J].
电子科学研究院学报,2013,8(2):184190.
[48]高文,钱亚冠,吴春明,等.
网络流量特征选择方法中的分治投票策略研究[J].
电子学报,2015,43(4):795799.
[49]刘珍,王若愚,刘琼.
基于Bootstrapping的因特网流量分类方法研究[J].
北京邮电大学学报,2014,5(37):6670,79.
[50]HuangNF,JaiGY,ChaoHC,etal.
Applicationtrafficclassificationattheearlystagebycharacterizingapplicationrounds[J].
InformationSciences,2013,232(5):130142.
[51]KhalifeJ,HajjarA,DiazVerdejoJ.
Amultileveltaxonomyandrequirementsforanoptimaltrafficclassificationmodel[J].
InternationalJournalofNetworkManagement,2014,24(2):101120.
[52]IliofotouM,KimH,FaloutsosM,etal.
Graption:agraphbasedP2Ptrafficclassificationframeworkfortheinternetbackbone[J].
ComputerNetworks,2011,55(8):19091920.
[53]GallagherB,IliofotouM,EliassiRadT,etal.
Linkhomophilyintheapplicationlayeranditsusageintrafficclassification[C]//ProcofINFOCOM.
2010:221225.
[54]张震,汪斌强,陈鸿昶,等.
互联网中基于用户连接图的流量分类机制[J].
电子与信息学报,2013,35(4):958964.
[55]JinY,DuffieldN,HaffnerP,etal.
Inferringapplicationsatthenetworklayerusingcollectivetrafficstatistics[C]//Procofthe22ndInternationalTeletrafficCongress.
2010:18.
[56]AsaiH,FukudaK,EsakiH.
Trafficcausalitygraphs:profilingnetworkapplicationsthroughtemporalandspatialcausalityofflows[C]//Procofthe23rdInternationalTeletrafficCongress.
2011:95102.
[57]MongkolluksameeS,VisoottivisethV,FukudaK.
Enhancingtheperformanceofmobiletrafficidentificationwithcommunicationpatterns[C]//Procofthe39thAnnualInternationalComputers,Software&ApplicationsConference.
2015:336345.
(下转第41页)·41·计算机应用研究第34卷指标,即地域的连续性、节点的同构性、节点对基础设施的共享性以及人口规模的均衡性.
为满足城市社区划分的指标,本文以云聚合的凝聚、重组和循环过程为理论支撑,提出了基于云聚合理论的社区划分算法.
本文采用MATLAB对城市社区划分算法进行实验,并与经典的同类凝聚算法及真实的城市社区结构进行对比,验证了本文算法的真实性、有效性及优越性.
本文提出的云聚合理论是一种新型的理论,基于云聚合理论的城市社区划分算法是在社区划分算法基础上的一次突破,为城市社区的划分与规划提供了有效的手段,但文中的划分算法仍存在局限.
在本文的基础上,进一步的研究工作可以从以下三个方面展开:a)节点的定义,本文将城市的社区视为最小单位个体———节点,忽略了组成社区节点的家庭抑或个人之间存在的异构性;b)节点同构性和基础设施共享性的精细化,本文仅将人口、年龄、人均占地面积和基础设施个数作为节点的属性,同时基础设施也只考虑了学校、医院和商场,存在局限性;c)更进一步的算法有效性分析,本文通过将实验划分结果与真实的城市社区结构进行比较,从而说明划分算法的有效性,但是由于条件限制,本文主要采集的数据局限于南京主城区,需要进一步对大范围的社区节点进行数据采集和分析,从而进一步验证算法的有效性.
参考文献:[1]DuttS.
NewfasterKernighanLintypegraphpartitioningalgorithms[C]//ProcofIEEE/ACMInternationalConferenceonComputerAidedDesign.
LosAlumitos:IEEEComputerSocietyPress,1993:370377.
[2]MannaK,ChoubeyV,ChattopadhyayS,etal.
ThermalvarianceawareapplicationmappingformeshbasednetworkonchipdesignusingKernighanLinpartitioning[C]//ProcofInternationalConferenceonParallel,DistributedandGridComputing.
2014:274279.
[3]RuanJianhua,ZhangWeixiong.
Anefficientspectralalgorithmfornetworkcommunitydiscoveryanditsapplicationstobiologicalandsocialnetworks[C]//Procofthe7thIEEEInternationalConferenceonDataMining.
WashingtonDC:IEEEComputerSociety,2007:643648.
[4]GouShuiping,ZhuangXiong.
ParallelsparsespectralclusteringforSARimagesegmentation[J].
IEEEJournalofSelectedTopicsinAppliedEarthObservationsandRemoteSensing,2013,6(4):19491963.
[5]WangHuiqing,ChenJunjie,HuangShaobin,etal.
Aheuristicinitializationindependentspectralclustering[C]//Procofthe5thInternationalConferenceonInternetComputingforScienceandEngineering.
WashingtonDC:IEEEComputerSociety,2010:8184.
[6]OnoH.
Fastrandomwalksonfinitegraphsandgraphtopologicalinformation[C]//Procofthe2ndInternationalConferenceonNetworkingandComputing.
WashingtonDC:IEEEComputerSociety,2011:360363.
[7]PallaG,DerenyiI,FarkasI,etal.
Uncoveringtheoverlappingcommunitystructureofcomplexnetworksinnatureandsociety[J].
Nature,2005,435(7043):814818.
[8]PallaG,FarkasI,PollnerP,etal.
Directednetworkmodules[J].
NewJournalofPhysical,2007,9(6):186.
[9]NewmanMEJ.
Fastalgorithmfordetectingcommunitystructureinnetworks[J].
PhysicalReviewE,2004,69(6):066133.
[10]GirvanM,NewmanMEJ.
Communitystructureinsocialandbiologicalnetworks[J].
ProceedingsoftheNationalAcademyofSciencesoftheUSA,2001,99(12):78217826.
[11]TylerJ,WilkinsonD,HubermanB.
Emailasspectroscopy:automateddiscoveryofcommunitystructurewithinorganizations[C]//Procofthe1stInternationalConferenceonCommunitiesandTechnologies.
2003:8196.
[12]RadicchiF,CastellanoC,CecconiF,etal.
Definingandidentifyingcommunitiesinnetworks[J].
ProceedingsoftheNationalAcademyofSciencesoftheUSA,2004,101(9):26582663.
[13]ChenGuoqiang,GuoXiaofang.
Ageneticalgorithmbasedonmodularitydensityfordetectingcommunitystructureincomplexnetworks[C]//ProcofInternationalConferenceonComputationalIntelligenceandSecurity.
WashingtonDC:IEEEComputerSociety,2011:151154.
[14]ClausetA,NewmanMEJ,MooreC.
Findingcommunitystructureinverylargenetworks[J].
PhysicalReviewE,2005,70(6):066111.
[15]DinhTN,ThaiM.
Findingcommunitystructurewithperformanceguaranteesinscalefreenetworks[C]//ProcofIEEEInternationalConferenceonPrivacy,Security,Risk,andTrust.
2011:888891.
[16]WangXiaohan,ChenZhaoqun.
Edgebalanceratio:powerlawfromverticestoedgesindirectedcomplexnetwork[J].
IEEEJournalofSelectedTopicsinSignalProcessing,2013,7(2):184194.
[17]TangJin,JiangBo,ChangChinchen,etal.
Graphstructureanalysisbasedoncomplexnetwork[J].
DigitalSignalProcessing,2012,22(5):713725.
[18]李孝伟,陈福才,刘力雄.
一种融合节点与链接属性的社交网络社区划分算法[J].
计算机应用研究,2013,30(5):14771480.
(上接第14页)[58]DuffieldN,LundC,ThorupM.
Estimatingflowdistributionsfromsampledflowstatistics[J].
IEEE/ACMTransonNetworking,2003,13(5):325336.
[59]张进,邬江兴,钮晓娜.
空间高效的数据包公平抽样算法[J].
软件学报,2010,21(10):24422655.
[60]CarelaEspanolV,BarletRosP,CabellosAparicioA,etal.
AnalysisoftheimpactofsamplingonNetFlowtrafficclassification[J].
ComputerNetworks,2011,55(5):10831099.
[61]TammaroD,ValentiS,RossiD,etal.
Exploitingpacketsamplingmeasurementsfortrafficcharacterizationandclassification[J].
InternationalJournalofNetworkManagement,2012,22(6):451476.
[62]EsteA,GringoliF,SalgarelliL.
Onthestabilityoftheinformationcarriedbytrafficflowfeaturesatthepacketlevel[J].
ACMSIGCOMMComputerCommunicationReview,2009,39(3):1318.
[63]JaberM,CascellaRG,BarakatC.
Canwetrusttheinterpackettimefortrafficclassification[C]//ProcofIEEEInternationalConferenceonCommunications.
2011:15.
[64]IliofotouM,GallagherB,EliassiRadT,etal.
ProfilingbyAssociation:aresilienttrafficprofilingsolutionfortheInternetbackbone[C]//ProcofACMConferenceonEmergingNetworkingExperimentandTechnology.
NewYork:ACMPress,2010.
112.
[65]HjelmvikE,JohnW.
Breakingandimprovingprotocolobfuscation[R].
Gothenburg:ChalmersUniversityofTechnology,2010:134.
[66]LuGang,ZhangHongli,QassrawiM,etal.
Comparisonandanalysisofflowfeaturesatthepacketlevelfortrafficclassification[C]//ProcofInternationalConferenceonConnectedVehicles&Expo.
WashingtonDC:IEEEComputerSociety,2012:262267.
[67]LiuZhen,WangRY,TaoM,etal.
Aclassorientedfeatureselectionapproachformulticlassimbalancedtrafficdatasetsbasedonlocalandglobalmetricsfusion[J].
Neurocomputing,2015,168(11):365381.
·14·第1期顾宏博,等:基于云聚合理论的城市社区划分算法研究
星梦云-年中四川100G高防云主机月付仅60元,西南高防月付特价活动,,买到就是赚到!
官方网站:点击访问星梦云活动官网活动方案:机房CPU内存硬盘带宽IP防护流量原价活动价开通方式成都电信优化线路4vCPU4G40G+50G10Mbps1个100G不限流量210元/月 99元/月点击自助购买成都电信优化线路8vCPU8G40G+100G15Mbps1个100G不限流量370元/月 160元/月点击自助购买成都电信优化线路16vCPU16G40G+100G20Mb...

Friendhosting,美国迈阿密机房新上线,全场45折特价优惠,100Mbps带宽不限流量,美国/荷兰/波兰/乌兰克/瑞士等可选,7.18欧元/半年
近日Friendhosting发布了最新的消息,新上线了美国迈阿密的云产品,之前的夏季优惠活动还在进行中,全场一次性45折优惠,最高可购买半年,超过半年优惠力度就不高了,Friendhosting商家的优势就是100Mbps带宽不限流量,有需要的朋友可以尝试一下。Friendhosting怎么样?Friendhosting服务器好不好?Friendhosting服务器值不值得购买?Friendho...
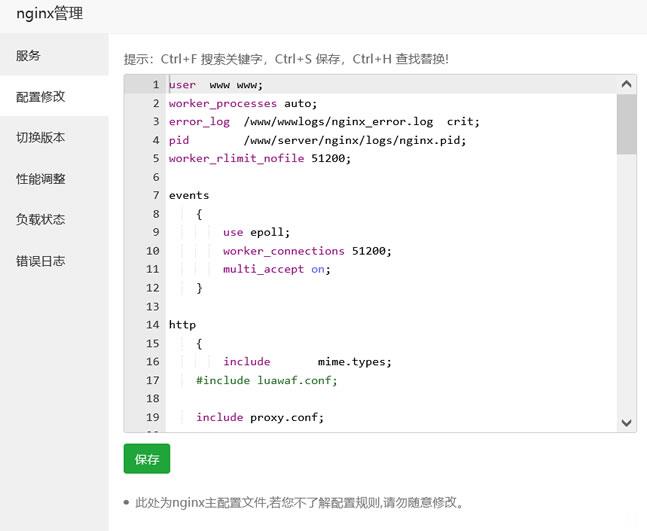
宝塔面板批量设置站点404页面
今天遇到一个网友,他在一个服务器中搭建有十几个网站,但是他之前都是采集站点数据很大,但是现在他删除数据之后希望设置可能有索引的文章给予404跳转页面。虽然他程序有默认的404页面,但是达不到他引流的目的,他希望设置统一的404页面。实际上设置还是很简单的,我们找到他是Nginx还是Apache,直接在引擎配置文件中设置即可。这里有看到他采用的是宝塔面板,直接在他的Nginx中设置。这里我们找到当前...
微信接收离线消息为你推荐
-
快递打印如何用打印机打印快递单在线漏洞检测如果检测网站是否有漏洞?个性qq资料QQ个性资料ghostxp3目前最好的ghost xp3是什么?1433端口怎么开启本机1433端口ios7固件下载ios7发布当天是否有固件下载bt封杀现在是全面封杀BT下载了吗?现在都找不到BT下载影片了网站优化方案网站建设及优化的方案宽带接入服务器用wifi连不上服务器怎么办网站排名靠前怎么让自己的网站排名靠前