数据库recovery教程
1SQLite权威指南TheDefinitiveGuidetoSQLite(内容摘要)MichaelOwensCopyright.
2006byMichaelOwens本书的示例代码可到http://www.
apress.
com下载.
2推荐者的话最近对SQLite很感兴趣,认真学习有一个多月了.
学习时基本找不到既好又系统的中文文章,也买不到好的中文书籍,看来SQLite在国内还是不够流行,这么好的东西,可惜了.
以我中等偏下的眼界,《TheDefinitiveGuidetoSQLite》是我所见到的最好的"SQLite入门+大全"了,可惜也是英文的.
实在找不到别的,也只好看它了,尽管我英语很不好.
由于英语很不好,又因为是打字员出身的干部,所以多年来养成了一个更不好的毛病,就是在不得不看英文资料时总喜欢一边看一边翻,主要是怕下次再看时还是看不懂.
看《TheDefinitiveGuidetoSQLite》时这个毛病也没改,当然了,看的时候就是挑着看的,翻的也只是书中的一小部分了.
一般情况下看完也就看完了,很少有"下次再看"的机会,这次例外.
由于越学越觉着SQLite好玩,就想向身边的人也介绍一下,就"再看"了.
越看越羞愧,本来英语就差,还随看随翻,结果可想而知.
但由于没什么动力,也就无意再重新润色了,就这样吧,反正也没什么人看,估计遗害不会太广.
SQLite是没有版权的,但这本书却是受版权保护的,也不知我这样做是否合法.
发到网上也只是想做一个好事,响应SQLite的共享精神.
估计不会有人来告我吧,反正我没钱.
另外,我也只翻译了书中很小的一部分,也许根本算不上翻译(不能乱抬高自己),就算是对SQLite和《TheDefinitiveGuidetoSQLite》一书的一个推荐吧,同样对SQLite感兴趣但又看不懂我的中文的兄弟,强烈建议看原文.
感谢RichardHipp编出这么好的程序,感谢MichaelOwens写出这么好的书.
"空转"只是我的网名之一,网上网下知之者甚少,也就是一起骑车的几个人知道吧.
如果本文对您能有一点点帮助,也算是我对SQLite做了一点贡献吧.
本文中带有"空注"的内容是我个人所做的简单说明和忏悔,与原作者无关(以我的翻译水平,估计全文跟原作者都没什么关).
接触SQLite时间不长,所以本文难免会有很多错误,不是故意误导大家,是真的水平低.
如果有兄弟想对我提出指导,我的邮箱是:njgaoyi@yahoo.
com.
cn.
如果我没有回信,不是因为不想回,是因为我很少上网,在此先行谢过.
分析源程序时,发现每个SQLite源文件的头部都有这样一段话:Theauthordisclaimscopyrighttothissourcecode.
Inplaceofalegalnotice,hereisablessing:Mayyoudogoodandnotevil.
Mayyoufindforgivenessforyourselfandforgiveothers.
Mayyousharefreely,nevertakingmorethanyougive.
这几句话我很喜欢,翻译不好,就拿原文出来吧,与大家共勉.
空转Ver1.
00:2009-11-07于南京(如果以后有时间、兴趣,就把翻译过的内容好好修改一下,或者再多翻一些.
但愿还有以后的版本)3总目录前言第1章SQLite介绍第2章入门第3章关系模型第4章SQL第5章设计和概念第6章核心CAPI第7章扩充CAPI第8章语言扩展第9章SQLite内核附录ASQL参考附录BCAPI参考附录CCodd的12条准则索引4目录SQLite权威指南.
1总目录3目录4前言1第1章SQLite介绍.
2内嵌式数据库2开发者的数据库3管理员的数据库3SQLite的历史.
3谁使用SQLite.
4体系结构4接口(Interface)5编译器(Compiler)5虚拟机(VirtualMachine)5后端(Back-end)6工具和测试代码(UtilitiesandTestCode)7SQLite的特色.
7零配置7兼容性7紧凑性7简单8适应性8不受拘束的授权8可靠性8易用性8性能和限制9附加信息9第2章入门10从哪得到SQLite.
10在Windows上使用SQLite.
10获得命令行程序10获得SQLite的动态链接库(DLL)10在Windows环境下编译SQLite源代码.
10用MicrosoftVisualC++构建SQLiteDLL11用MicrosoftVisualC++构建SQLiteCLP.
11使用SQLite数据库.
11Shell模式下使用CLP.
11在命令行方式下执行CLP15数据库管理15创建、备份和删除数据库.
155获得数据库文件的信息.
15其它SQLite工具.
16第3章关系模型17第4章SQL.
18关系模型18查询语言18SQL的发展.
18示例数据库18建立19运行示例19语法19命令20常量20保留字和标识符20注释20创建一个数据库21创建表21改变表21在数据库中查询22关系操作22操作管道23过滤23限定和排序25函数(Function)和聚合(Aggregate)26分组(Grouping)27去掉重复27多表连接27名称和别名28修改数据28插入记录28修改记录28删除记录29数据完整性29实体完整性29域完整性30存储类(StorageClasses)31弱类型(manifesttyping)32类型亲和性(TypeAffinity)33事务35事务的范围36冲突解决36数据库锁36死锁37事务的种类386数据库管理38视图38索引39触发器39附加(Attaching)数据库.
40清洁数据库40数据库配置40系统表42查看Query的执行.
42第5章设计和概念44API.
44SQLite版本3的新特性.
44主要的数据结构45核心API.
46操作控制52扩充API.
53事务54事务的生命周期54锁的状态55读事务56写事务56调整页缓冲区58等待加锁59编码60使用多个连接60表锁61有趣的临时表62定案的重要性63共享缓冲区模式63第6章核心CAPI.
65封装的查询65连接和断开连接65执行Query66字符串处理69GetTable查询.
70预处理的查询71取记录73参数化的查询76错误和意外76处理错误76处理忙状态78操作控制78提交Hook函数.
78回卷Hook函数.
787修改Hook函数.
78授权函数79线程84共享缓冲区模式85线程和内存管理85第7章扩充CAPI.
86API.
86注册函数86步进函数86返回值86函数86返回值86一个完整的例子86一个实际的应用程序.
88聚合88一个实际的例子88排序法90排序法定义90一个简单的例子90按需排序(CollationonDemand)93一个实际的应用程序.
93第8章语言扩展100第9章SQLite内核.
101虚拟数据库引擎(VDBE)101栈(Stack)103程序体103程序开始与停止104指令的类型105B-Tree和Pager模型105数据库文件格式106B-TreeAPI.
109编译器111分词器(Tokenizer)111分析器(Parser)112代码生成器(CodeGenerator)113优化1141前言2000年春天,当我刚开始编写SQLite时,根本没想到它会在编程社区受到如此强烈的认可.
今天,有成百万的SQLite拷贝在默默地运行,在计算机中,或在不同公司生产的各种各样的小设备中.
你可能已经在无意识的情况下使用过SQLite,在你的手机、MP3或机顶盒里可能就有SQLite.
在你的计算机里也可能至少会有一个SQLite的拷贝,它可能来自Apple的MacOSX,或者在大多数的Linux版本中,或者在Windows中安装某个第三方软件时.
很多Web网站的后台都使用SQLite,这要感谢它已经被包含为PHP5语言的一部分.
SQLite也被用于很多航空电子设备、建模和仿真程序、工业控制、智能卡、决策支持包、医药信息系统等.
因为没有SQLite使用的全面报告,所以,肯定还有很多我不知道的SQLite部署.
SQLite的普及很大程度上应该归功于MichaelOwens.
Mike在TheLinuxJournal(June2003)和TheC/C++UsersJournal(March2004)上的文章吸引了无数程序员.
每篇文章发表后,SQLite网站的访问量都会显著上升.
通过这本书你可以看到Mike的才华和他所做的大量工作,相信你不会失望.
本书包含了关于SQLite所需要了解的所有内容,你应该一直把它放在伸手可及的地方.
SQLite是自由软件.
尽管我是它的架构师和代码的主要编写者,但SQLite并不是我的程序.
SQLite不属于任何人,也不在版权的保护范围之内.
所有曾经为SQLite项目贡献过代码的人都签署过一个宣誓书将他们的贡献发布到公共域,我把这些宣誓书的原件保存在办公室的保险箱里.
我还尽力保证在SQLite中不使用专利算法,这些预防措施意味着你可以以任何形式使用SQLite,而不需要付版税、许可证费用或受到其它任何限制.
SQLite仍然在发展.
但我和其他开发者都坚守它的核心价值.
我们将保持代码的小规模——核心库不会超过250KB.
我们将保持公共API和文件格式的向上兼容性.
我们将继续保证SQLite是充分测试的和无bug的.
我们希望你总是能够将新版本的SQLite放到你老的程序中,既得到它新的特性和优化,又不需要或仅需要很少的代码改动,且不需要做进一步的调试.
2004年,我们将SQLite从版本2升级到版本3时确实没能保持向上兼容性,但从那以后,我们已经能够达到上述所有目标并准备在将来继续这样做.
没有SQLite版本4的计划.
真诚希望你觉着SQLite是有用的,我代表SQLite的所有贡献者保证,使用SQLite你会:做出美好的产品,你的产品将会是快速、稳定和易用的.
寻求宽恕并宽恕他人.
因为你已经免费地得到了SQLite,也请你免费地给予他人一些东西作为回报.
做一回志愿者,贡献出其它的软件项目或找到其它途径来回报.
RichardHippCharlotte,NCApril11,20062第1章SQLite介绍SQLite是一个开源的、内嵌式的关系型数据库.
它最初发布于2000年,在便携性、易用性、紧凑性、有效性和可靠性方面有突出的表现.
内嵌式数据库SQLite是一个内嵌式的数据库.
数据库服务器就在你的程序中,其好处是不需要网络配置和管理.
数据库的服务器和客户端运行在同一个进程中.
这样可以减少网络访问的消耗,简化数据库管理,使你的程序部署起来更容易.
所有需要你做的都已经和你的程序一起编译好了.
如图1-1所示.
一个Perl脚本、一个标准C/C++程序和一个使用PHP编写的Apache进程都使用SQLite.
Perl脚本导入DBI::SQLite模板,并通过它来访问CAPI.
PHP采用与C相似的方式访问CAPI.
总之,它们都需要访问CAPI.
尽管它们每个进程中都有独立的数据库服务器,但它们可以操作相同的数据库文件.
SQLite利用操作系统功能来完成数据的同步和加锁.
图1-1内嵌的主进程中的SQLite目前市场上有多种为内嵌应用所设计的关系型数据库产品,如SybaseSQLAnywhere、InterSystemsCaché、PervasivePSQL和微软的JetEngine.
有些厂家从他们的大型数据库产品翻新出内嵌式的变种,如IBM的DB2Everyplace、Oracle的10g和微软的SQLServerDesktopEngine.
开源的数据库MySQL和Firebird都提供内嵌式的版本.
在所有这些产品中,3仅有两个是完全开放源代码的且不收许可证费用——Firebird和SQLite.
在这两个当中,仅有一个是专门为内嵌式应用设计的——SQLite.
开发者的数据库SQLite具有多方面的特性.
它是一个数据库,一个程序库,一个命令行工具,也是一个学习关系型数据库的很好的工具.
确实有很多途径可以使用它——内嵌环境、网站、操作系统服务、脚本语言和应用程序.
对于程序员来说,SQLite就象一个数据传送带,提供了一种方便的将应用程序绑定的数据的方法.
就象传送带一样,对SQLite的使用没有终点.
除了仅仅作为一个存储容器,SQLite还可以作为一个单纯的数据处理的工具.
如果大小和复杂性合适,使用SQLite可以很容易地将应用程序所使用的数据结构转化为表,并保存在一个内在数据库中.
用此方法,你可以操作互相关联的数据,可以完成很繁重的任务页不必写自己的算法来对数据结构操作和排序.
如果你是一个程序员,想像一下在你的程序中自行完成下面SQL语句所代表的工作需要多少代码:SELECTAVG(z-y)FROMtableGROUPBYxHAVINGx>MIN(z)ORx.
mcolsqlite>.
honsqlite>.
w415333103sqlite>explainSELECTnameFROMepisodesLIMIT10;SQLite会显示编译后的VDBE汇编程序,如列表1-1所示.
列表1-1VDBE汇编程序addropcodep1p2p3p4p5comment0Trace000001Integer1010002MustBeInt100003IfZero1130004Goto0140005OpenRead0203006Rewind0120007Column022008ResultRow210009AddImm1-100010IfZero11200011Next0700112Close0000013Halt0000014Transaction0000015VerifyCookie04000016TableLock020episodes0017Goto05000程序由17条指令组成.
通过对给定的操作数完成特别的操作,这些指令将会返回episodes表前10个记录的name字段的值.
episodes表是本书示例数据库的一部分.
从多个方面都可以看出,VDBE是SQLite的核心:它上面的各模块都是用于创建VDBE程序,它下面的各模块都是用于执行VDBE程序,每次执行一条指令.
后端(Back-end)后端由B-tree、页缓冲(pagecache,pager)和操作系统接口(即系统调用)构成.
B-tree和pagecache共同对数据进行管理.
它们操作的是数据库页,这些页具有相同的大小,就像集装箱.
页里面的"货物"是表示信息的大量bit,这些信息包括记录、字段和索引入口等.
B-tree和pager都不知道信息的具体内容,它们只负责"运输"这些页,页不关心这些"集装箱"里面是什么.
B-tree的主要功能就是索引,它维护着各个页之间的复杂的关系,便于快速找到所需数据.
它把页组织成树型的结构(这是它名称的由来),这种树是为查询而高度优化了的.
Page为B-tree服务,为它提供页.
Pager的主要作用就是通过OS接口在B-tree和磁盘之间传递页.
7磁盘操作是计算机到目前为止所必须做的最慢的事情.
所以,pager尽力提高速度,其方法是把经常使用的页存放到内存当中的页缓冲区里,从而尽量减少操作磁盘的次数.
它使用特殊的算法来预测下面要使用哪些页,从而使B-tree能够更快地工作.
工具和测试代码(UtilitiesandTestCode)工具模块中包含各种各样的实用功能,还有一些如内存分配、字符串比较、Unicode转换之类的公共服务也在工具模块中.
这个模块就是一个包罗万象的工具箱,很多其它模块都需要调用和共享它.
测试模块中包含了无数的回归测试语句,用来检查数据库代码的每个细微角落.
这个模块是SQLite性能如此可靠的原因之一.
SQLite的特色尽管SQLite是如此之小,却提供了如此之多的特色和性能.
它支持ANSISQL92的一个大子集(包括事务、视图、检查约束、关联子查询和复合查询等),还支持其它很多关系型数据库的特色,如触发器、索引、自动增长字段和LIMIT/OFFSET子句等.
SQLite还有很多独特的特色,如内在数据库、动态类型和冲突解决(下面解释).
如本章开始时所述,在SQLite的观念和实现中,都遵循着一系列指导原则.
下面就来详述这些原则.
零配置从SQLite的设计之始,就没准备在应用时使用DBA.
配置和管理SQLite就像得到它一样简单.
SQLite包含了正好适合于一个程序员的脑筋的特色.
兼容性SQLite在设计时特别注意了兼容性.
它可以编译运行在Windows、Linux、BSD、MacOSX及商用的Unix系统如Solaris、HPUX和AIX,还可以应用于很多嵌入式平台如QNX、VxWorks、Symbian、PalmOS和WindowsCE.
它可以无缝地工作在16-bit、32-bit和64-bit体系结构中并且能同时适应字节的大端格式和小端格式.
SQLite的兼容性并不只表现在代码上,还表现在其数据库文件上.
SQLite的数据库文件在其所支持的所有操作系统、硬件体系结构和字节顺序上都是二进制一致的.
你可以在SunSPARC工作站上创建一个SQLite数据库然后在Mac或Windows的机器上——甚至移动电话上——使用它,而不需要做任何转换和修改.
此外,SQLite数据库可以支撑2TB的数据量(受操作系统限制),还内置地同时支持UTF-8和UTF-16编码.
紧凑性SQLite的设计可以说是功能齐全但体积很小:1个头文件,1个库,不需要扩展的数据库服8务.
所有的东西,包括客户端、服务器和虚拟机等,都被打包在1/4兆大小之内.
如果在编译时去掉一些不需要的特性,程序库可以缩小至170KB(在x86硬件平台上使用GNUC进行编译).
此外,还有一个SQLite的私有版本,大小是69KB,可以运行在智能卡上(参"附加信息"一节).
空注:我下载的DLL有500多KB.
简单作为程序库,SQLite的API可以算是最简单最易用的了.
SQLite既有很好的文档又很容易望文知意.
适应性SQLite的几个特性使其成为一个适应性极强的数据库.
作为一个内嵌式的数据库,SQLite在以下两个方面都做得最好:强有力而可伸缩的关系型数据库前端,简单而紧凑的B-tree后端.
不受拘束的授权SQLite的全部代码都在公共域中,不需要授权.
SQLite的任何一部分都没有附加版权要求.
所有曾经为SQLite项目贡献过代码的人都签署过一个宣誓书将他们的贡献发布到公共域.
也就是说,无论你如何使用SQLite的代码都不会有法律方面的限制.
你可以修改、合并、发布、出售或将这些代码用于任何目的,商业和中非商业的,不需要支付任何费用,不会受到任何限制.
可靠性SQLite的源代码不但免费,还编写得很好.
SQLite源代码包含大约30000行标准C代码,它是干净的、模块化的和完好注释的.
SQLite源代码易理解、易定制.
SQLite的核心软件(库和工具)由约30000行代码组成,但分发的程序中还包含有超过30000行的回归测试代码,它们覆盖了97%的核心代码.
也就是说,超过一半的SQLite项目代码是专门用于回归测试的,也就是说,差不多每写一行功能代码,都要写一行测试代码对它进行测试.
易用性SQLite还提供一些独特的功能来提高易用性,包括动态类型、冲突解决和"附加"多个数据库到一个连接的能力.
9性能和限制SQLite是一个快速数据库.
但"快速"这个词本身是一个主观的和不明确的词.
诚实地讲,有些事情SQLite能比其它数据库做得快,也有些事情不能.
这么说吧,利用SQLite提供的配置参数,SQLite是足够快速和高效的.
跟大多数其它数据库一样,SQLite使用B-tree处理索引,使用B+tree处理表数据.
因此,在对单表进行查询时,SQLite要快于(或至少相当于)其它数据库的速度.
在一些情况下SQLite可能不如大型数据库快,但大多数这些情况是可理解的.
SQLite是一个内嵌式的数据库,设计用于中小规模的应用程序.
这些限制是符合设计目的的.
很多新用户错误地假设使用SQLite可以代替大型关系型数据库,这有时行,但有时不行,依赖于你准备用SQLite来做什么.
一般情况下,SQLite在三个主要的方面具有局限性:l并发.
l数据库大小.
l网络.
尽管SQLite做得已经很好了,但仍有部分特性未能实现,包括:l外键约束空注:SQLite的最新版本3.
6.
19好像已经支持了.
l完整的触发器支持.
l完整的ALTERTABLE支持.
l事务嵌套.
lRIGHT和FULLOUTERJOIN.
l可修改视图.
lGRANT和REVOKE.
附加信息SQLite网站有丰富的信息,包括官方文档、邮件列表、Wiki和其它的一般信息,它的网址是www.
sqlite.
org.
SQLite社区也是很有帮助的,你可能从邮件列表中找到任何你所需要的东西.
另外,SQLite的作者提供了SQLite的专业培训和支持,包括定制程序(如移植到嵌入式平台)和增强的SQLite版本,这些版本包括内置了加密功能的版本和为嵌入式应用优化的极小化版本.
更多的信息可以从www.
hwaci.
com/sw/sqlite/prosupport.
html中找到.
10第2章入门无论您使用何种操作系统,SQLite都很容易上手.
对大多数用户,安装SQLite并创建一个新的数据库不会超过5分钟,且不需要任何经验.
空注:本章我只看了Windows操作系统下使用VC的内容.
从哪得到SQLiteSQLite网站(www.
sqlite.
org)同时提供SQLite的已编译版本和源程序.
编译版本可同时适用于Windows和Linux.
有几种形式的二进制包供选择,以适应SQLite的不同使用方式.
包括:l静态链接的命令行程序(CLP)lSQLite动态链接库(DLL)lTcl扩展SQLite源代码以两种形式提供,以适应不同的平台.
一种为了在Windows下编译,另一种为了在POSIX平台(如Linux,BSD,andSolaris)下编译,这两种形式下源代码本身是没有差别的.
在Windows上使用SQLite无论你是作为终端用户还是作为程序员来使用SQLite,SQLite都可以很容易地安装在Windows环境下.
本节我们将讨论所有相关的内容——安装二进制包或在最普通的编译环境下使用源代码.
获得命令行程序SQLite命令行程序(CLP)是开始使用SQLite的一个比较好的选择.
略,参原文.
获得SQLite的动态链接库(DLL)SQLite的DLL文件供编译好的程序动态连接SQLite.
大多数使用SQLite的软件都会拥有自己的SQLiteDLL拷贝并随软件自动安装.
在Windows环境下编译SQLite源代码在Windows环境下编译SQLite源代码是很简单的.
根据你所使用的编译器和你要做什么,有几种方法来编译SQLite.
最常见的环境是MicrosoftVisualC++或MinGW,本节都会加以11介绍.
关于使用其它编译器编译SQLite的内容,可参考SQLiteWiki(www.
sqlite.
org/cvstrac/wikip=HowToCompile).
用MicrosoftVisualC++构建SQLiteDLL通过以下步聚,可使用源代码,在VisualC++上构建SQLiteDLL:1.
启动VisualStudio.
在解包的SQLite源程序目录中创建一个新的DLL"空"项目.
高:不同版本操作略有不同,不详细解释了.
2.
将全部SQLite源文件加入到项目中来.
包括所有的.
c文件和.
h文件.
除了:shell.
c:该文件包括main()函数,用于创建CLP可执行程序.
tclsqlite.
c:该文件用于TCL支持.
空注:我使用的版本(sqlite-source-3_6_18.
zip)有些函数有重复定义,还得去掉两个文件,不知会引起什么后果,它们是fts3.
c和fts3_tokenizer.
c.
3.
执行构建(Build)命令,OK.
还可以选择构建线程完全的DLL或发布(Release)版的DLL,参原文.
用MicrosoftVisualC++构建SQLiteCLP方法基本同上.
创建项目时选择Win32ConsoleApplication,添加文件时把shell.
c也加上,即可.
使用SQLite数据库SQLite的CLP是使用和管理SQLite数据库最常用的方法.
它可运行于多种平台,学会使用CLP,可以保证你永远有一个通用和熟悉的途径来管理你的数据库.
CLP其实是两个程序.
它可以运行在命令行模式下完成各种数据库管理任务,也可以运行在Shell模式下,以交互的方式执行查询操作.
Shell模式下使用CLP运行DOSshell,进入工作目录,在命令行上键入sqlite3命令,命令后跟随一个可选的数据库文件名.
如果在命令行上不指定数据库名,SQLite将会使用一个内存数据库,其内容在退出CLP时将会丢失.
CLP以交互形式运行,你可以在其上执行查询、获得schema信息、导入/导出数据和执行其它各种各样的数据库任务.
CLP认为你输入的任何语句都是一个查询命令(query),除非命令是以点(.
)开始,这些命令用于特殊操作.
键入.
help或.
h可以得到这些操作的完整列表.
键入.
exit或.
e退出CLP.
让我们从创建一个称为test.
db的数据库开始.
在DOSshell下键入:sqlite3test.
db尽管我们提供了数据库名,但如果这个数据库并不存在,SQLite并不会真正地创建它.
SQLite会等到你真正地向其中增加了数据库对象之后才创建它,比如在其中创建了表或视图.
这样做的原因是给你机会在将数据库写到外部文件之前对数据库做一些永久性的设置,如页的大12小等.
有些设置,如页大小、字符集(UTF-8或UTF-16)等,一旦数据库创建之后就不能再修改了.
这个中间期是你能改它们的唯一机会.
我们采用默认设置,因此,要将数据库写到磁盘,我们仅需要在其中创建一个表.
输入如下语句:sqlite>createtabletest(idintegerprimarykey,valuetext);现在你有了一个称为test.
db的数据库文件,其中包含一个表test,该表包含两个字段.
l一个称为id的主键字段,它带有自动增长属性.
无论何时你定义一个整型主键字段,SQLite都会对该字段应用自动增长属性.
l一个简单的称为value的文本字段.
向表中插入几行数据:sqlite>insertintotest(value)values('eenie');sqlite>insertintotest(value)values('meenie');sqlite>insertintotest(value)values('miny');sqlite>insertintotest(value)values('mo');将插入的数据取回:sqlite>.
modecolsqlite>.
headersonsqlite>SELECT*FROMtest;系统显示:idvalue1eenie2meenie3miny4moSELECT语句前的两个命令(.
headersand.
mode)用于改进输出的格式.
可以看到SQLite为id字段赋予了连接的整数值,而这些值我们在INSERT语句中并没的提供.
对于自动增长的字段,你可能会关心最后插入的一条记录该字段的取值,此值可以用SQL函数last_insert_rowid()得到.
sqlite>selectlast_insert_rowid();last_insert_rowid()4在退出CLP之前,让我们来为数据库创建一个索引和一个视图,后面的内容中将会用到它们.
sqlite>createindextest_idxontest(value);sqlite>createviewschemaasselect*fromsqlite_master;使用.
exit命令退出CLP.
sqlite>.
exitC:\Temp>获得数据库的Schema信息有几个shell命令用于获得有关数据库内容的信息.
你可以键入命令.
tables[pattern]来得到所有表和视图的列表,其中[pattern]可以是任何类SQL的操作符.
执行上述命令会返回符合条件的所有表和视图,如果没有pattern项,返回所有表和视图.
sqlite>.
tables13schematest可以看到我们创建的表test和视图schema.
同样的,要显示一个表的索引,可以键入命令.
indices[tablename]:sqlite>.
indicestesttest_idx可以看到我们为表test所创建的名为test_idx的索引.
使用.
schema[tablename]可以得到一个表或视图的定义(DDL)语句.
如果没提供表名,则返回所有数据库对象(包括table、indexe、view和index)的定义语句:sqlite>.
schematestCREATETABLEtest(idintegerprimarykey,valuetext);CREATEINDEXtest_idxontest(value);sqlite>.
schemaCREATETABLEtest(idintegerprimarykey,valuetext);CREATEVIEWschemaasselect*fromsqlite_master;CREATEINDEXtest_idxontest(value);更详细的schema信息可以通过SQLite唯一的一个系统视图sqlite_master得到.
这个视图是一个系统目录,它的结构如表2-1所示.
表2-1sqlite_master表结构编号字段说明1type值为"table"、"index"、"trigger"或"view"之一.
2name对象名称,值为字符串.
3tbl_name如果是表或视图对象,此字段值与字段2相同.
如果是索引或触发器对象,此字段值为与其相关的表名.
4rootpage对触发器或视图对象,此字段值为0.
对表或索引对象,此字段值为其根页的编号.
5SQL字符串,创建此对象时所使用的SQL语句.
查询当前数据库的sqlite_master表,返回:sqlite>.
modecolsqlite>.
headersonsqlite>selecttype,name,tbl_name,sqlfromsqlite_masterorderbytype;typenametbl_namesqlindextest_idxtestCREATEINDEXtest_idxontest(value)tabletesttestCREATETABLEtest(idintegerprimaryviewschemaschemaCREATEVIEWschemaasselect*fromsTip:使用向上的箭头键可以回滚到前面输入过的命令.
数据导出可以使用.
dump命令将数据库导出为SQL格式的文件.
不使用任何参数,.
dump将导出整个数据库.
如果提供参数,CLP把参数理解为表名或视图名.
sqlite>.
outputfile.
sql14sqlite>.
dumpsqlite>.
outputstdout数据导入有两种方法可以导入数据,用哪种方法决定于要导入的文件的格式.
如果文件由SQL语句构成,可以使用.
read命令导入(执行)文件.
如果文件是由逗号或其它定界符分隔的值(comma-separatedvalues,CSV)组成,可使用.
import[file][table]命令.
此命令将解析指定的文件并尝试将数据插入到指定的表中.
sqlite>.
showecho:offexplain:offheaders:onmode:columnnullvalue:""output:stdoutseparator:"|"width:.
read命令用来导入由.
dump命令创建的文件.
如果要使用前面作为备份文件所导出的file.
sql,需要先移除已经存在的数据库对象(test表和schema视图),然后用下面方法导入:sqlite>droptabletest;sqlite>dropviewschema;sqlite>.
readfile.
sql格式化CLP提供了几个格式化选项命令.
最简单的是.
echo,如果设置.
echoon,则新输入的命令在执行前都会回显,默认值是off.
.
headers设置为on时,查询结果显示时带有字段名.
当遇到NULL值时,如果需要以一个字符串来显示,使用.
nullvalue命令设置,如:sqlite>.
nullvalueNULL默认情况下使用空串.
如果要改变CLP的shell提示符,使用.
prompt[value],如:sqlite>.
prompt'sqlite3>'sqlite3>.
mode命令可以设置结果数据的几种输出格式.
可选的格式为csv、column、html、insert、line、list、tabs和tcl.
默认值是list,在此模式下显示结果时列间以默认的分隔符分隔.
如果你想以CSV格式输出一个表的数据,可如下操作:sqlite3>.
outputfile.
csvsqlite3>.
separator,sqlite3>select*fromtest;sqlite3>.
outputstdout文件file.
csv的内容为:1,eenie2,meenie153,miny4,mo因为有一个CSV模式,所以下面的命令会得到相似的结果:sqlite3>.
outputfile.
csvsqlite3>.
modecsvsqlite3>select*fromtest;sqlite3>.
outputstdout在命令行方式下执行CLP在DOS或UNIX的命令行方式下,直接执行SQLite的数据库操作.
数据库管理所有的数据库管理任务都可以在shell和命令行模式下完成.
创建、备份和删除数据库数据库的备份有两种方法.
第1种是使用.
dump,可得到SQL格式的文件.
在命令行方式下可如下做:sqlite3test.
db.
dump>test.
sql在CLP中可如下做:sqlite>.
outputfile.
sqlsqlite>.
dumpsqlite>.
exit相应地,导入一个SQL格式备份的数据库可如下做:sqlite3test.
dbALTERTABLEcontactsADDCOLUMNemailTEXTNOTNULLDEFAULT''COLLATENOCASE;sqlite>.
schemacontactsCREATETABLEcontacts(idINTEGERPRIMARYKEY,nameTEXTNOTNULLCOLLATENOCASE,phoneTEXTNOTNULLDEFAULT'UNKNOWN',emailTEXTNOTNULLDEFAULT''COLLATENOCASE,UNIQUE(name,phone));显示了当前的表定义.
表还可以由SELECT语句创建,你可以在创建表结构的同时创建数据.
这种特别的CREATETABLE语句将在"插入记录"一节中介绍.
在数据库中查询SELECT是SQL命令中最大最复杂的命令.
SELECT的很多操作都来源于关系代数.
关系操作SELECT中使用3大类13种关系操作:.
基本的操作.
Restriction(限制).
Projection.
CartesianProduct(笛卡尔积).
Union(联合).
Difference(差).
Rename(重命名).
附加的操作.
Intersection(交叉).
NaturalJoin(自然连接).
Assign(指派OR赋值).
扩展的操作.
GeneralizedProjection.
LeftOuterJoin.
RightOuterJoin.
FullOuterJoin基本的关系操作,除重命名外,在集合论中都有相应的理论基础.
附加操作是为了方便,它们可以用基本操作来完成,一般情况下,附加操作可以作为常用基本操作序列的快捷方式.
扩展操作为基本操作和附加操作增加特性.
ANSISQL的SELECT可以完成上述所有的关系操作.
这些操作覆盖了Codd最初定义的所有关系运算符,只有一个例外——divide.
SQLite支持ANSISQL中除right和fullouterjoin之外的所有操作(这些操作可用其它间接的方法完成).
23操作管道从语法上来说,SELECT命令用一系列子句将很多关系操作组合在一起.
每个子句代表一种特定的关系操作.
几乎所有这些子句都是可选的,你可以只选你所需要的操作.
SELECT是一个很大的命令.
下面是SELECT的一个简单形式:SELECTDISTINCTheadingFROMtablesWHEREpredicateGROUPBYcolumnsHAVINGpredicateORDERBYcolumnsLIMITcount,offset;每个保留字——DISTINCT、FROM、WHERE和HAVING——都是一个单独的子句.
每个子句由保留字和跟随的参数构成.
表4-1SELECT的子句编号子句操作输入1FROMJoinListoftables2WHERERestrictionLogicalpredicate3ORDERBYListofcolumns4GROUPBYRestrictionListofcolumns5HAVINGRestrictionLogicalpredicate6SELECTRestrictionListofcolumnsorexpressions7DISTINCTRestrictionListofcolumns8LIMITRestrictionIntegervalue9OFFSETRestrictionIntegervalue图4-3SELECTphases过滤如果SELECT是SQL中最复杂的命令,那么WHERE就是SELECT中最复杂的子句.
值"值"可以按它们所属的域(或类型)来分类,如数字值(1,2,3,etc.
)或字符串值("Jujy-Fruit").
值可以表现为文字的值(1,2,3or"JujyFruit")、变量(一般是如foods.
name的列名)、表达式(3+2/5)或函数的结果(COUNT(foods.
name))值.
24操作符操作符使用一个或多个值做为输入并产生一个新值做为输出.
这所以叫"操作符"是因为它完成某种操作并产生某种结果.
二目操作符操作两个输入值(或称操作数),三目操作符操作三个操作数,单目操作符操作一个操作数,等等.
图4-7单目、二目和三目操作符二目操作符二目操作符是最常用的SQL操作符.
表4-2列出了SQLite所支持的二目操作符.
表中按优先级从高到低的次序排列,同色的一组中具有相同的优先级,圆括号可以覆盖原有的优先级.
表4-2二目操作符操作符类型作用||StringConcatenation*ArithmeticMultiply/ArithmeticDivide%ArithmeticModulus+ArithmeticAdd–ArithmeticSubtract>BitwiseLeftshift&LogicalAnd|LogicalOrRelationalGreaterthan>=RelationalGreaterthanorequalto=RelationalEqualto==RelationalEqualtoRelationalNotequalto!
=RelationalNotequaltoINLogicalInANDLogicalAndORLogicalOrLIKERelationalStringmatching25GLOBRelationalFilenamematchingLIKE操作符一个很有用的关系操作符是LIKE.
LIKE的作用与相等(=)很像,但却是通过一个模板来进行字符串匹配.
例如,要查询所有名称以字符"J"开始的食品,可使用如下语句:sqlite>SELECTid,nameFROMfoodsWHEREnameLIKE'J%';idname156Juicebox236JuicyFruitGum243JellowithBananas244JujyFruit245JuniorMints370Jambalaya模板中的百分号(%)可与任意0到多个字符匹配.
下划线(_)可与任意单个字符匹配.
sqlite>SELECTid,nameFROMfoodsWHEREnameLIKE'%ac%P%';idname127GuacamoleDip168PeachSchnapps198MackinawPeaches另一个有用的窍门是使用NOT:sqlite>SELECTid,nameFROMfoodsWHEREnamelike'%ac%P%'ANDnameNOTLIKE'%Sch%'idname38Pie(Blackberry)Pie127GuacamoleDip198Mackinawpeaches限定和排序可以用LIMIT和OFFSET保留字限定结果集的大小和范围.
LIMIT指定返回记录的最大数量.
OFFSET指定偏移的记录数.
例如,下面的命令返回food_types表中id排第2的记录:SELECT*FROMfood_typesLIMIT1OFFSET1ORDERBYid;保留字OFFSET在结果集中跳过一行(Bakery),保留字LIMIT限制最多返回一行(Cereal).
上面语句中还有一个ORDERBY子句,它使记录集在返回之前按一个或多个字段的值排序.
例如:sqlite>SELECT*FROMfoodsWHEREnameLIKE'B%'ORDERBYtype_idDESC,nameLIMIT10;idtype_idname38215BakedBeans38315BakedPotatow/Sour38415BigSalad38515Broccoli2636214Bouillabaisse32812BLT32712BaconClub(noturke32612Bologna32912BrisketSandwich27410Bacon函数(Function)和聚合(Aggregate)SQLite提供了多种内置的函数和聚合,可以用在不同的子句中.
函数的种类包括:数学函数,如ABS()计算绝对值;字符串格式函数,如UPPER()和LOWER(),它们将字符串的值转化为大写或小写.
例如:sqlite>SELECTUPPER('hellonewman'),LENGTH('hellonewman'),ABS(-12);UPPER('hellonewman')LENGTH('hellonewman')ABS(-12)HELLONEWMAN1212函数名是不分大小写的(或upper()和UPPER()是同一个函数).
函数可以接受字段值作为参数:sqlite>SELECTid,UPPER(name),LENGTH(name)FROMfoodsWHEREtype_id=1LIMIT10;idUPPER(name)LENGTH(name)1BAGELS62BAGELS,RAISIN143BAVARIANCREAMPIE184BEARCLAWS105BLACKANDWHITECOOKIES236BREAD(WITHNUTS)177BUTTERFINGERS138CARROTCAKE119CHIPSAHOYCOOKIES1810CHOCOLATEBOBKA15因为函数可以是任意表达式的一部分,所以函数也可以用在WHERE子句中:sqlite>SELECTid,UPPER(name),LENGTH(name)FROMfoodsWHERELENGTH(name)SELECTCOUNT(*)FROMfoodsWHEREtype_id=1;count2747分组(Grouping)聚合的精华部分是分组.
聚合不只是能够计算整个结果集的聚合值,你还可以把结果集分成多个组,然后计算每个组的聚合值.
这些都可以在一步当中完成,方法就是使用GROUPBY子句,如:sqlite>SELECTtype_idFROMfoodsGROUPBYtype_id;type_id123.
.
.
15去掉重复操作管道中的下一个限制是DISTINCT.
DISTINCT处理SELECT的结果并过滤掉其中重复的行.
例如,你想从foods表中取得所有不同的type_id值:sqlite>SELECTDISTINCTtype_idFROMfoods;type_id123.
.
.
15多表连接连接(join)是SELECT命令的第一个操作,它产生初始的信息,供语句的其它部分过滤和处理.
连接的结果是一个合成的关系(或表),它是SELECT后继操作的输入.
也许从一个例子开始是最简单的.
sqlite>SELECTfoods.
name,food_types.
nameFROMfoods,food_typesWHEREfoods.
type_id=food_types.
idLIMIT10;namenameBagelsBakeryBagels,raisinBakery28BavarianCreamPieBakeryBearClawsBakeryBlackandWhitecookiesBakeryBread(withnuts)BakeryButterfingersBakeryCarrotCakeBakeryChipsAhoyCookiesBakeryChocolateBobkaBakery名称和别名当把多个表连接在一起时,字段可能重名.
SELECTB.
nameFROMAJOINBUSING(a);修改数据跟SELECT命令相比,用于修改数据的语句就太简单太容易理解了.
有3个DML语句用于修改数据——INSERT、UPDATE和DELETE.
插入记录使用INSERT命令向表中插入记录.
使用INSERT命令可以一次插入1条记录,也可以使用SELECT命令一次插入多条记录.
INSERT语句的一般格式为:INSERTINTOtable(column_list)VALUES(value_list);Table指明数据插入到哪个表中.
column_list是用逗号分隔的字段名表,这些字段必须是表中存在的.
value_list是用逗号分隔的值表,这些值与column_list中的字段一一对应.
例如,下面语句向foods表插入数据:sqlite>INSERTINTOfoods(name,type_id)VALUES('CinnamonBobka',1);修改记录UPDATE命令用于修改一个表中的记录.
UPDATE命令可以修改一个表中一行或多行中的一个或多个字段.
UPDATE语句的一般格式为:UPDATEtableSETupdate_listWHEREpredicate;update_list是一个或多个"字段赋值"的列表,字段赋值的格式为column_name=value.
WHERE子句的用法与SELECT语句相同,确定需要进行修改的记录.
如:UPDATEfoodsSETname='CHOCOLATEBOBKA'WHEREname='ChocolateBobka';SELECT*FROMfoodsWHEREnameLIKE'CHOCOLATE%';idtype_name101CHOCOLATEBOBKA111ChocolateEclairs29121ChocolateCreamPie2229Chocolates,boxof2239ChocolateChipMint2249ChocolateCoveredCherries删除记录DELETE用于删除一个表中的记录.
DELETE语句的一般格式为:DELETEFROMtableWHEREpredicate;同样,WHERE子句的用法与SELECT语句相同,确定需要被删除的记录.
如:DELETEFROMfoodsWHEREname='CHOCOLATEBOBKA';数据完整性数据完整性用于定义和保护表内部或表之间数据的关系.
有四种完整性:域完整性、实体完整性、参照完整性和用户定义完整性.
实体完整性唯一约束因为唯一(UNIQUE)约束是主键的基础,所以先介绍它.
一个唯一约束要求一个字段或一组字段的所有值互不相同,或者说唯一.
如果你试图插入一个重复值,或将一个值改成一个已存在的值,数据库将引发一个约束非法,并取消操作.
唯一约束可以在字段级或表级定义.
NULL和UNIQUE:问题:如果一个字段已经声明为UNIQUE,可以向这个字段插入多少个NULL值回答:与数据库的种类有关.
PostgreSQL和Oracle可以插入多个.
Informix和MicrosoftSQLServer只能一个.
DB2、SQLAnywhere和BorlandInter-Base不能.
SQLite采用了与PostgreSQL和Oracle相同的解决方案.
另一个困扰大家的关于NULL的经典问题是:两个NULL值是否相等你没有足够的信息来证明它们相等,但也没有足够的信息证明它们不等.
SQLite的观点是假设所有的NULL都是不同的.
所以你可以向唯一字段中插入任意多个NULL值.
主键约束在SQLite中,当你定义一个表时总要确定一个主键,不管你自己有没有定义.
这个字段是一个64-bit整型字段,称为ROWID.
它还有两个别名——_ROWID_和OID,用这两个别名同样可以取到它的值.
它的默认取值按照增序自动生成.
SQLite为主键字段提供自动增长特性.
30域完整性默认值保留字DEFAULT为字段提供一个默认值.
如果用INSERT语句插入记录时没有为该定做指定值,则为它赋默认值.
DEFAULT不是一个约束(constraint),因为它没有强制任何事情.
这所以把它归为域完整性,是因为它提供了处理NULL值的一个策略.
如果一个字段没有指定默认址,在插入时也没有为该字段指定值,SQLite将向该字段插入一个NULL.
例如,contacts.
name字段有一个默认值'UNKNOWN',请看下面例子:sqlite>INSERTINTOcontacts(name)VALUES('Jerry');sqlite>SELECT*FROMcontacts;idnamephoneJerryUNKNOWNDEFAULT还可以接受3种预定义格式的ANSI/ISO预定字用于生成日期和时间值.
CURRENT_TIME将会生成ANSI/ISO格式(HH:MM:SS)的当前时间.
CURRENT_DATE会生成当前日期(格式为YYYY-MM-DD).
CURRENT_TIMESTAMP会生成一个日期时间的组合(格式为YYYY-MM-DDHH:MM:SS).
例如:CREATETABLEtimes(idint,dateNOTNULLDEFAULTCURRENT_DATE,timeNOTNULLDEFAULTCURRENT_TIME,timestampNOTNULLDEFAULTCURRENT_TIMESTAMP);INSERTINTOtimes(1);INSERTINTOtimes(2);SELECT*FROMStimes;iddatetimetimestamp12006-03-1523:30:252006-03-1523:30:2522006-03-1523:30:402006-03-1523:30:40NOTNULL约束CHECK约束排序法(Collation)排序法定义如何唯一地确定文本的值.
排序法主要用于规定文本值如何进行比较.
不同的排序法有不同的比较方法.
例如,某种排序法是大小写不敏感的,于是'JujyFruit'和'JUJYFRUIT'被认为是相等的.
另外一个排序法或许是大小写敏感的,这时上面两个字符串就不相等了.
SQLite有3种内置的排序法.
默认为BINARY,它使用一个C函数memcmp()来对文本进行逐字节的比较.
这很适合于大多数西方语言,如英语.
NOCASE对26个字母是大小写不敏感的.
FinallythereisREVERSE,whichisthereverseoftheBINARYcollation.
REVERSEis31morefortesting(andperhapsillustration)thananythingelse.
SQLiteCAPI提供了一种创建定制排序法的手段,详见第7章.
存储类(StorageClasses)如前文所述,SQLite在处理数据类型时与其它的数据库不同.
区别在于它所支持的类型以及这些类型是如何存储、比较、强化(enforc)和指派(assign).
下面各节介绍SQLite处理数据类型的独特方法和它与域完整性的关系.
对于数据类型,SQLite的域完整性被称为域亲和性(affinity)更合适.
在SQLite中,它被称为类型亲和性(typeaffinity).
为了理解类型亲和性,你必须先要理解存储类和弱类型(manifesttyping).
SQLite有5个原始的数据类型,被称为存储类.
存储类这个词表明了一个值在磁盘上存储的格式,其实就是类型或数据类型的同义词.
这5个存储类在表4-6中描述.
表4-6SQLite存储类名称说明INTEGER整数值是全数字(包括正和负).
整数可以是1,2,3,4,6或8字节.
整数的最大范围(8bytes)是{-9223372036854775808,0,+9223372036854775807}.
SQLite根据数字的值自动控制整数所占的字节数.
空注:参可变长整数的概念.
REAL实数是10进制的数值.
SQLite使用8字节的符点数来存储实数.
TEXT文本(TEXT)是字符数据.
SQLite支持几种字符编码,包括UTF-8和UTF-16.
字符串的大小没有限制.
BLOB二进制大对象(BLOB)是任意类型的数据.
BLOB的大小没有限制.
NULLNULL表示没有值.
SQLite具有对NULL的完全支持.
SQLite通过值的表示法来判断其类型,下面就是SQLite的推理方法:lSQL语句中用单引号或双引号括起来的文字被指派为TEXT.
l如果文字是未用引号括起来的数据,并且没有小数点和指数,被指派为INTEGER.
l如果文字是未用引号括起来的数据,并且带有小数点或指数,被指派为REAL.
l用NULL说明的值被指派为NULL存储类.
l如果一个值的格式为X'ABCD',其中ABCD为16进制数字,则该值被指派为BLOB.
X前缀大小写皆可.
SQL函数typeof()根据值的表示法返回其存储类.
使用这个函数,下面SQL语句返回的结果为:sqlite>selecttypeof(3.
14),typeof('3.
14'),typeof(314),typeof(x'3142'),typeof(NULL);typeof(3.
14)typeof('3.
14')typeof(314)typeof(x'3142')typeof(NULL)realtextintegerblobnullSQLite单独的一个字段可能包含不同存储类的值.
请看下面的示例:sqlite>DROPTABLEdomain;sqlite>CREATETABLEdomain(x);sqlite>INSERTINTOdomainVALUES(3.
142);sqlite>INSERTINTOdomainVALUES('3.
142');sqlite>INSERTINTOdomainVALUES(3142);32sqlite>INSERTINTOdomainVALUES(x'3142');sqlite>INSERTINTOdomainVALUES(NULL);sqlite>SELECTROWID,x,typeof(x)FROMdomain;返回结果为:rowidxtypeof(x)13.
142real23.
142text33142integer41Bblob5NULLnull这带来一些问题.
这种字段中的值如何存储和比较如何对一个包含了INTEGER、REAL、TEXT、BLOB和NULL值的字段排序一个整数和一个BLOB如何比较哪个更大它们能相等吗答案是:具有不同存储类的值可以存储在同一个字段中.
可以被排序,因为这些值可以相互比较.
有完善定义的规则来做这件事.
不同存储类的值可以通过它们各自类的"类值"进行排序,定义如下:1.
NULL存储类具有最低的类值.
一个具有NULL存储类的值比所有其它值都小(包括其它具有NULL存储类的值).
在NULL值之间,没有特别的可排序值.
2.
INTEGER或REAL存储类值高于NULL,它们的类值相等.
INTEGER值和REAL值通过其数值进行比较.
3.
TEXT存储类的值比INTEGER和REAL高.
数值永远比字符串的值低.
当两个TEXT值进行比较时,其值大小由"排序法"决定.
4.
BLOB存储类具有最高的类值.
具有BLOB类的值大于其它所有类的值.
BLOB值之间在比较时使用C函数memcmp().
所以,当SQLite对一个字段进行排序时,首先按存储类排序,然后再进行类内的排序(NULL类内部各值不必排序).
下面的SQL说明了存储类值的不同:sqlite>SELECT3CREATETABLEdomain(iint,nnumeric,ttext,bblob);sqlite>INSERTINTOdomainVALUES(3.
142,3.
142,3.
142,3.
142);sqlite>INSERTINTOdomainVALUES('3.
142','3.
142','3.
142','3.
142');sqlite>INSERTINTOdomainVALUES(3142,3142,3142,3142);sqlite>INSERTINTOdomainVALUES(x'3142',x'3142',x'3142',x'3142');sqlite>INSERTINTOdomainVALUES(null,null,null,null);sqlite>SELECTROWID,typeof(i),typeof(n),typeof(t),typeof(b)FROMdomain;返回:rowidtypeof(i)typeof(n)typeof(t)typeof(b)1realrealtextreal2realrealtexttext3integerintegertextinteger4blobblobblobblob5nullnullnullnull下面的SQL说明存储类的排序情况:sqlite>SELECTROWID,b,typeof(b)FROMdomainORDERBYb;返回:rowidbtypeof(b)355NULLnull13.
142real33142integer23.
142text41Bblobsqlite>SELECTROWID,b,typeof(b),bselectROWID,b,typeof(i),i>'2.
9'fromdomainORDERBYb;rowidbtypeof(ii>'2.
9'5NULLnullNULL13.
142real133142integer123.
142real141Bblob1也算是"强类型(STRICTTYPING)"如果你需要比类型亲和性更强的域完整性,可以使用CHECK约束.
你可以使用一个单独的内置函数和一个CHECK约束来实现一个"假的"强类型.
事务事务定义了一组SQL命令的边界,这组命令或者作为一个整体被全部执行,或者都不执行.
36事务的典型实例是转帐.
事务的范围事务由3个命令控制:BEGIN、COMMIT和ROLLBACK.
BEGIN开始一个事务,之后的所有操作都可以取消.
COMMIT使BEGIN后的所有命令得到确认;而ROLLBACK还原BEGIN之后的所有操作.
如:sqlite>BEGIN;sqlite>DELETEFROMfoods;sqlite>ROLLBACK;sqlite>SELECTCOUNT(*)FROMfoods;COUNT(*)412上面开始了一个事务,先删除了foods表的所有行,但是又用ROLLBACK进行了回卷.
再执行SELECT时发现表中没发生任何改变.
SQLite默认情况下,每条SQL语句自成事务(自动提交模式).
冲突解决如前所述,违反约束会导致事务的非法结束.
大多数数据库(管理系统)都是简单地将前面所做的修改全部取消.
SQLite有其独特的方法来处理约束违反(或说从约束违反中恢复),被称为冲突解决.
如:sqlite>UPDATEfoodsSETid=800-id;SQLerror:PRIMARYKEYmustbeuniqueSQLite提供5种冲突解决方案:REPLACE、IGNORE、FAIL、ABORT和ROLLBACK.
lREPLACE:当发违反了唯一完整性,SQLite将造成这种违反的记录删除,替代以新插入或修改的新记录,SQL继续执行,不报错.
lIGNORElFAILlABORTlROLLBACK数据库锁在SQLite中,锁和事务是紧密联系的.
为了有效地使用事务,需要了解一些关于如何加锁的知识.
SQLite采用粗放型的锁.
当一个连接要写数据库,所有其它的连接被锁住,直到写连接结束了它的事务.
SQLite有一个加锁表,来帮助不同的写数据库都能够在最后一刻再加锁,以保证最大的并发性.
SQLite使用锁逐步上升机制,为了写数据库,连接需要逐级地获得排它锁.
SQLite有5个不同的锁状态:未加锁(UNLOCKED)、共享(SHARED)、保留(RESERVED)、未决(PENDING)37和排它(EXCLUSIVE).
每个数据库连接在同一时刻只能处于其中一个状态.
每种状态(未加锁状态除外)都有一种锁与之对应.
最初的状态是未加锁状态,在此状态下,连接还没有存取数据库.
当连接到了一个数据库,甚至已经用BEGIN开始了一个事务时,连接都还处于未加锁状态.
未加锁状态的下一个状态是共享状态.
为了能够从数据库中读(不写)数据,连接必须首先进入共享状态,也就是说首先要获得一个共享锁.
多个连接可以同时获得并保持共享锁,也就是说多个连接可以同时从同一个数据库中读数据.
但哪怕只有一个共享锁还没有释放,也不允许任何连接写数据库.
如果一个连接想要写数据库,它必须首先获得一个保留锁.
一个数据库上同时只能有一个保留锁.
保留锁可以与共享锁共存,保留锁是写数据库的第1阶段.
保留锁即不阻止其它拥有共享锁的连接继续读数据库,也不阻止其它连接获得新的共享锁.
一旦一个连接获得了保留锁,它就可以开始处理数据库修改操作了,尽管这些修改只能在缓冲区中进行,而不是实际地写到磁盘.
对读出内容所做的修改保存在内存缓冲区中.
当连接想要提交修改(或事务)时,需要将保留锁提升为排它锁.
为了得到排它锁,还必须首先将保留锁提升为未决锁.
获得未决锁之后,其它连接就不能再获得新的共享锁了,但已经拥有共享锁的连接仍然可以继续正常读数据库.
此时,拥有未决锁的连接等待其它拥有共享锁的连接完成工作并释放其共享锁.
一旦所有其它共享锁都被释放,拥有未决锁的连接就可以将其锁提升至排它锁,此时就可以自由地对数据库进行修改了.
所有以前对缓冲区所做的修改都会被写到数据库文件.
死锁为什么需要了解锁的机制呢为了避免死锁.
考虑下面表4-7所假设的情况.
两个连接——A和B——同时但完全独立地工作于同一个数据库.
A执行第1条命令,B执行第2、3条,等等.
表4-7一个死锁的假设情况A连接B连接sqlite>BEGIN;sqlite>BEGIN;sqlite>INSERTINTOfooVALUES('x');sqlite>SELECT*FROMfoo;sqlite>COMMIT;SQLerror:databaseislockedsqlite>INSERTINTOfooVALUES('x');SQLerror:databaseislocked两个连接都在死锁中结束.
B首先尝试写数据库,也就拥有了一个未决锁.
A再试图写,但当其INSERT语句试图将共享锁提升为保留锁时失败.
为了讨论的方便,假设连接A和B都一直等待数据库可写.
那么此时,其它的连接甚至都不能够再读数据库了,因为B拥有未决锁(它能阻止其它连接获得共享锁).
那么时此,不仅A和B不能工作,其它所有进程都不能再操作此数据库了.
如果避免此情况呢当然不能让A和B通过谈判解决,因为它们甚至不知道彼此的存在.
答案是采用正确的事务类型来完成工作.
38事务的种类SQLite有三种不同的事务,使用不同的锁状态.
事务可以开始于:DEFERRED、MMEDIATE或EXCLUSIVE.
事务类型在BEGIN命令中指定:BEGIN[DEFERRED|IMMEDIATE|EXCLUSIVE]TRANSACTION;一个DEFERRED事务不获取任何锁(直到它需要锁的时候),BEGIN语句本身也不会做什么事情——它开始于UNLOCK状态.
默认情况下就是这样的,如果仅仅用BEGIN开始一个事务,那么事务就是DEFERRED的,同时它不会获取任何锁;当对数据库进行第一次读操作时,它会获取SHARED锁;同样,当进行第一次写操作时,它会获取RESERVED锁.
由BEGIN开始的IMMEDIATE事务会尝试获取RESERVED锁.
如果成功,BEGINIMMEDIATE保证没有别的连接可以写数据库.
但是,别的连接可以对数据库进行读操作;但是,RESERVED锁会阻止其它连接的BEGINIMMEDIATE或者BEGINEXCLUSIVE命令,当其它连接执行上述命令时,会返回SQLITE_BUSY错误.
这时你就可以对数据库进行修改操作了,但是你还不能提交,当你COMMIT时,会返回SQLITE_BUSY错误,这意味着还有其它的读事务没有完成,得等它们执行完后才能提交事务.
EXCLUSIVE事务会试着获取对数据库的EXCLUSIVE锁.
这与IMMEDIATE类似,但是一旦成功,EXCLUSIVE事务保证没有其它的连接,所以就可对数据库进行读写操作了.
上节那个例子的问题在于两个连接最终都想写数据库,但是它们都没有放弃各自原来的锁,最终,SHARED锁导致了问题的出现.
如果两个连接都以BEGINIMMEDIATE开始事务,那么死锁就不会发生.
在这种情况下,在同一时刻只能有一个连接进入BEGINIMMEDIATE,其它的连接就得等待.
BEGINIMMEDIATE和BEGINEXCLUSIVE通常被写事务使用.
就像同步机制一样,它防止了死锁的产生.
基本的准则是:如果你正在使用的数据库没有其它的连接,用BEGIN就足够了.
但是,如果你使用的数据库有其它的连接也会对数据库进行写操作,就得使用BEGINIMMEDIATE或BEGINEXCLUSIVE开始你的事务.
数据库管理数据库管理用于控制数据库如何操作.
从SQL的角度,数据库管理包括一些主题如会视图(view)、触发器(trigger)和索引(indexe).
另外,SQLite包括自己一些独特的管理,如数据库pragma,可以用来配置数据库参数.
视图物化的视图在关系模型中称为数据可修改的视图.
39索引索引的利用理解索引何时被利用及何时不被利用是重要的.
SQLite有明确的条件来决定是否使用索引.
如果可能,在WHERE子名中有下列表达式时,SQLite将使用单字段索引:columnexpressionexpressioncolumncolumnIN(expression-list)columnIN(subquery)多字段索引的使用有很明确的条件.
这最好用例子来说.
假设你有如下定义的一个表:CREATETABLEfoo(a,b,c,d);触发器当特定的表上发生特定的数据库事件时,触发器会执行特定的SQL命令.
创建触发器的一般语法如下:CREATE[TEMP|TEMPORARY]TRIGGERname[BEFORE|AFTER][INSERT|DELETE|UPDATE|UPDATEOFcolumns]ONtableactionUPDATE触发器不同于INSERTandDELETE触发器,UPDATE触发器可以定义在一个表的特定的字段上.
Thegeneralformofthiskindoftriggerisasfollows:CREATETRIGGERname[BEFORE|AFTER]UPDATEOFcolumnONtableactionThefollowingisaSQLscriptthatshowsanUPDATEtriggerinaction:.
hon.
mcol.
w50.
echoonCREATETEMPTABLElog(x);CREATETEMPTRIGGERfoods_update_logUPDATEofnameONfoodsBEGININSERTINTOlogVALUES('updatedfoods:newname='||NEW.
name);END;BEGIN;UPDATEfoodssetname='JUJYFRUIT'wherename='JujyFruit';40SELECT*FROMlog;ROLLBACK;错误处理定义一个事件的before触发器给了你一个阻止事件发生的机会.
before触发器可以实现新的完整性约束.
SQLite为触发器提供了一个称为RAISE()的特殊SQL函数,可以在触发器体中唤起一个错误.
RAISE如下定义:RAISE(resolution,error_message);使用触发器的外键约束在SQLite中,触发器最有趣的应用之一是实现外键约束.
为了进一步了解触发器,我将用这个想法在foods表和food_types表之间实现外键.
附加(Attaching)数据库SQLite允许你用ATTACH命令将多个数据库"附加"到当前连接上来.
当你附加了一个数据库,它的所有内容在当前数据库文件的全局范围内都是可存取的.
ATTACH的语法为:ATTACH[DATABASE]filenameASdatabase_name;清洁数据库SQLite有两个命令用于数据库清洁——REINDEX和VACUUM.
REINDEX用于重建索引,有两种形式:REINDEXcollation_name;REINDEXtable_name|index_name;第一种形式利用给定的排序法名称重新建立所有的索引.
VACUUM通过重建数据库文件来清除数据库内所有的未用空间.
数据库配置SQLite没有配置文件.
所有这些配置参数都是用pragma来实现.
Pragma以独特的方式工作,有些像变量,又有些像命令.
连接缓冲区大小缓冲区尺寸pragma控制一个连接可以在内存中使用多少个数据库页.
要查看当前缓冲区大小的默认值,执行:sqlite>PRAGMAcache_size;41cache_size2000要改变缓冲区大小,执行:sqlite>PRAGMAcache_size=10000;sqlite>PRAGMAcache_size;cache_size10000获得数据库信息可以使用数据库的schemapragma来获得数据库信息,定义如下:ldatabase_list:Listsinformationaboutallattacheddatabases.
lindex_info:Listsinformationaboutthecolumnswithinanindex.
Ittakesanindexnameasanargument.
lindex_list:Listsinformationabouttheindexesinatable.
Ittakesatablenameasanargument.
ltable_info:Listsinformationaboutallcolumnsinatable.
请看下面示例:sqlite>PRAGMAdatabase_list;seqnamefile0main/tmp/foods.
db2db2/tmp/dbsqlite>CREATEINDEXfoods_name_type_idxONfoods(name,type_id);sqlite>PRAGMAindex_info(foods_name_type_idx);seqncidname02name11type_idsqlite>PRAGMAindex_list(foods);seqnameunique0foods_name_type_idx0sqlite>PRAGMAtable_info(foods);cidnametypenotndfltpk0idinteger011type_idinteger002nametext00页大小、编码和自动排空Thedatabasepagesize,encoding,andautovacuumingmustbesetbeforeadatabaseiscreated.
Thatis,inordertoalterthedefaults,youmustfirstsetthesepragmasbeforecreatinganydatabase42objectsinanewdatabase.
Thedefaultsarea1,024-bytepagesizeandUTF-8encoding.
SQLitesupportspagesizesrangingfrom512to32,786bytes,inpowersof2.
SupportedencodingsareUTF-8,UTF-16le(little-endianUTF-16encoding),andUTF-16be(big-endianUTF-16encoding).
如果使用auto_vacuumpragma,可以使数据库自动维持最小.
一般情况下,当一个事务从数据库中删除了数据并提交后,数据库文件的大小保持不变.
当使用了auto_vacuumpragma后,当删除事务提交时,数据库文件会自动缩小.
系统表sqlite_master表是一个系统表,它包含数据库中所有表、视图、索引和触发器的信息.
例如,foods的当前内容如下:sqlite>SELECTtype,name,rootpageFROMsqlite_master;typenamerootpagetableepisodes2tablefoods3tablefoods_episodes4tablefood_types5indexfoods_name_idx30tablesqlite_sequence50triggerfoods_update_trg0triggerfoods_insert_trg0triggerfoods_delete_trg0有关sqlite_master表的结构请参考第2章的"获得数据库的Schema信息"一节.
sqlite_master包含一个称为sql的字段,存储了创建对象的DDL命令,如:sqlite>SELECTsqlFROMsqlite_masterWHEREname='foods_update_trg';返回:CREATETRIGGERfoods_update_trgBEFOREUPDATEOFtype_idONfoodsBEGINSELECTCASEWHEN(SELECTidFROMfood_typesWHEREid=NEW.
type_id)ISNULLTHENRAISE(ABORT,'ForeignKeyViolation:foods.
type_idisnotinfood_types.
id')END;END查看Query的执行可以用EXPLAIN命令查看SQLite执行一个查询的方法.
EXPLAIN列出一个SQL命令编译后的VDBE程序.
sqlite>.
mcolsqlite>.
honsqlite>.
w41533310343sqlite>EXPLAINSELECT*FROMfoods;addropcodep1p2p3p4p5comment0Trace000001Goto0110002OpenRead0703003Rewind090004Rowid010005Column012006Column023007ResultRow130008Next040019Close0000010Halt0000011Transaction0000012VerifyCookie04000013TableLock070foods0014Goto0200044第5章设计和概念本章为后面的3章打下基础,这几章专注于SQLite编程.
这几章专注于作为程序员,在编码时你所应该了解的有关SQLite的东西.
无论你是用C语言对SQLite进行编程,还是用其它的编程语言,这些内容都是重要的.
它不仅帮助你了解API,还包括部分有关SQLite的体系结构和实现方法的内容.
具备了这些知识,你就可以编出更好的代码,这些代码执行得更快,且不会产生死锁、不可预知错误等问题.
你会看到SQLite如何处理你的代码,你还会变得更加自信,因为你知道自己正前进在解决问题的正确方向上.
你不需要从头到尾地读内部代码才能理解这些内容,你也不必是一个C程序员.
SQLite的设计和概念都是非常直观和容易理解的.
只有一小部分内容你需要知道,本章就介绍这些内容.
1.
明显地,你需要知道API是如何工作的.
于是本章从一个对API概念性的介绍开始,图示了主要的数据结构,API的一般设计和它主要的函数.
还可以看到SQLite的一些主要的子系统,这些子系统在查询的处理过程中起着重要作用.
2.
除了知道什么函数做什么,你还需要从比API高的角度来看问题,看看所有这些函数在事务(transactions)中是如何操作的.
SQLite的所有的工作都是在事务中完成的.
于是,你需要知道在API之下,事务如何按照锁的约束来工作.
如果你不知道锁是如何操作的,这些锁就会导致问题.
当对锁有所了解之后,你不仅可以避免潜在的并发问题,还可以通过编程控制它们来优化你的查询.
3.
最后,你还必须理解如何将这些内容应用于编码.
本章的最后部分会将3个主题结合在一起——API、事务和锁,并且看一看好代码与坏代码的区别.
空注:本章看得还是比较仔细的,翻译的也比较全.
API从功能的角度来区分,SQLite的API可分为两类:核心API的扩充API.
核心API由所有完成基本数据库操作的函数构成,包括:连接数据库、执行SQL和遍历结果集.
它还包括一些功能函数,用来完成字符串格式化、操作控制、调试和错误处理等任务.
扩充API提供不同的方法来扩展SQLite,它使你能够创建自定义的SQL扩展,并与SQLite本身的SQL相集成.
SQLite版本3的新特性在开始之前,我们先讨论一下SQLite版本3的新特色:一、首先,SQLite的API被彻底重新设计了,并具有了许多新特性.
由第二版的15个函数增加到88个函数.
这些函数包括支持UTF-8和UTF-16编码的功能函数.
SQLite3有一个更方便的查询模式,使查询的预处理更容易并且支持新的参数绑定方法.
SQLite3还增加了用户定义的排序序列、CHECK约束、64位的键值和新的查询优化.
二、在后端大大地改进了并发性能.
加锁子系统引进了一种新的锁升级模型,解决了第二版中的写进程饿死的问题.
这种模型保证写进程按照先来先服务的算法得到排它锁(Exclusive45Lock).
甚至,写进程通过把结果写入临时缓冲区(TemporaryBuffer),可以在得到排它锁之前就开始工作.
这对于写要求较高的应用,性能可提高400%.
三、SQLite3包含一个改进了的B-tree模型.
现在对库表使用B+tree,大大提高查询效率,存储大数据字段更有效,并可以从磁盘上删除不用了的字段.
其结果是数据库文件的体积减小了25–35%并改善了全面性能.
B+tree将在第9章介绍.
四、SQLite3最重要的改变是它的存储模型.
由第二版只支持文本模型,扩展到支持5种本地数据类型,如第4章所介绍的,还增强了弱类型和类型亲和性的概念.
每种类型都被优化,以得到更高的查询性能并战用更少的存储空间.
例如,整数和浮点数以二进制的形式存储,而不再是以ASCII形式存储,这样,就不必再对WHERE子句中的值进行转换(像第2版那样).
弱类型使你能够在定义一个字段时选择是否预声明类型.
亲和性确定一个值存储于字段的格式——基于值的表示法和列的亲和性.
类型亲和性与弱类型紧密关联——列的亲和性由其类型的声明确定.
在很多方面,SQLite3是一个与SQLite2完全不同的数据库,并且提供了很多在适应性、特色和性能方面的改进.
主要的数据结构在第1章你看到了很多SQLite组件——分词器、分析器和虚拟机等等.
但是从程序员的角度,最需要知道的是:connection、statements、B-tree和pager.
它们之间的关系如图5-1所示.
这些对象构成了编写优秀代码所必须知道的3个首要内容:API、事务和锁.
图5-1SQLiteCAPI对象模型从技术上来说,B-tree和pager不是API的一部分,但是它们却在事务和锁上起着关键作用.
这里只介绍关联的内容,详细内容将在"事务"一节介绍.
46连接(Connection)和语句(Statement)连接(Connection)和语句(Statement)是执行SQL命令涉及的两个主要数据结构,几乎所有通过API进行的操作都要用到它们.
连接代表在一个独立的事务环境下的一个单独的数据库连接.
每个语句都和一个连接关联,通常表示一个编译过的SQL语句.
在内部,它以VDBE字节码表示.
语句包括执行一个命令所需要一切,包括保存VDBE程序执行状态所需的资源,指向硬盘记录的B-tree游标,以及参数等等.
B-tree和Pager一个连接可以有多个database对象——一个主数据库和附加的数据库.
每一个数据库对象有一个B-tree对象,一个B-tree有一个pager对象(这里的对象不是面向对象的"对象",只是为了说清楚问题).
语句最终都是通过连接的B-tree和pager从数据库读或者写数据,通过B-tree的游标(cursor)遍历存储在页(page)中的记录.
在游标访问页之前,页必须从磁盘加载到内存,而这就是pager的任务.
任何时候,如果B-tree需要页,它都会请求pager从磁盘读取数据,pager把页加载到页缓冲区(pagecache).
之后,B-tree和与之关联的游标就可以访问位于页中的记录了.
如果游标改变了页,为了防止事务回滚,pager必须采取特殊的方式保存原来的页.
总的来说,pager负责读写数据库,管理内存缓存和页,以及管理事务、锁和崩溃恢复(这些在"事务"一节会详细介绍).
总之,关于连接和事务,你必须知道两件事:(1)对数据库的任何操作,一个连接存在于一个事务之下.
(2)一个连接绝不会同时存在于多个事务之下.
无论何时,一个连接在对数据库做任何操作时,都总是在恰好一个事务之下,不会多,也不会少.
核心API核心API主要与执行SQL命令有关.
有两种方法执行SQL语句:预编译查询和封装查询.
预编译查询由三个阶段构成:准备(preparation)、执行(execution)和定案(finalization).
其实封闭装查询只是对预编译查询的三个过程进行了包装而已,最终也会转化为预编译查询来执行.
连接的生命周期(TheConnectionLifecycle)和大多数据库连接相同,其生命周期由三个阶段构成:1.
连接数据库(Connecttothedatabase).
2.
处理事务(Performtransactions):如你所知,任何命令都在事务下执行.
默认情况下,事务自动提交,也就是每一个SQL语句都在一个独立的事务下运行.
当然也可以通过使用BEGIN.
.
COMMIT手动提交事务.
3.
断开连接(Disconnectfromthedatabase):关闭数据库文件.
还要关闭所有附加的数据库文件.
在查询的处理过程中还包括其它一些行为,如处理错误、"忙"句柄和schema改变等,所有47这些都将在utilityfunctions一节中介绍.
连接数据库(Connecttothedatabase):连接数据库不只是打开一个文件.
每个SQLite数据库都存储在单独的操作系统文件中——数据库与文件一一对应.
连接、打开数据库的CAPI为sqlite3_open(),它只是一个简单的系统调用,来打开一个文件,它的实现位于main.
c文件中.
SQLite还可以创建内存数据库.
如果你使用:memory:或一个空字符串做数据库名,数据库将在RAM中创建.
内存数据库将只能被创建它的连接所存取,不能与其它连接共享.
另外,内存数据库只能存活于连接期间,一旦连接关闭,数据库就将从内存中被删除.
当连接一个位于磁盘上的数据库时,如果数据库文件存在,则打开该文件;如果不存在,SQLite会假定你想创建一个新的数据库.
在这种情况下,SQLite不会立即在磁盘上创建一个文件,只有当你向数据库写入数据时才会创建文件,比如:创建表、视图或者其它数据库对象.
如果你打开一个数据库,不做任何事,然后关闭它,SQLite会创建一个文件,但只是一个长度为0的空文件而已.
另外一个不立即创建新文件的原因是,一些数据库的参数,比如:编码,页大小等,只能在数据库创建之前设置.
默认情况下,页大小为1024字节,但是你可以选择512-32768字节之间为2幂数的数字.
有些时候,较大的页能更有效地处理大量的数据.
你可以使用page_sizepragma来设置数据库页大小.
字符编码是数据库的另一个永久设置.
你可以使用encodingpragma来设置字符编码,其值可以是UTF-8、UTF-16、UTF-16le(littleendian)和UTF-16be(bigendian).
执行预处理查询前面提到,预处理查询(PreparedQuery)是SQLite执行所有SQL命令的方式,包括以下三个步聚:(1)准备(preparation):分词器(tokenizer)、分析器(parser)和代码生成器(codegenerator)把SQL语句编译成VDBE字节码,编译器会创建一个语句句柄(sqlite3_stmt),它包括字节码以及其它执行命令和遍历结果集所需的全部资源.
相应的CAPI为sqlite3_prepare(),位于prepare.
c文件中.
(2)执行(execution):虚拟机执行字节码,执行过程是一个步进(stepwise)的过程,每一步(step)由sqlite3_step()启动,并由VDBE执行一段字节码.
当第一次调用sqlite3_step()时,一般会获得一种锁,锁的种类由命令要做什么(读或写)决定.
对于SELECT语句,每次调用sqlite3_step()使用语句句柄的游标移到结果集的下一行.
对于结果集中的每一行,它返回SQLITE_ROW,当到达结果末尾时,返回SQLITE_DONE.
对于其它SQL语句(INSERT、UPDATE、DELETE等),第一次调用sqlite3_step()就导致VDBE执行整个命令.
(3)定案(finalization):VDBE关闭语句,释放资源.
相应的CAPI为sqlite3_finalize(),它导致VDBE结束程序运行并关闭语句句柄.
如果事务是由人工控制开始的,它必须由人工控制进行提交或回卷,否则sqlite3_finalize()会返回一个错误.
当sqlite3_finalize()执行成功,所有与语句对象关联的资源都将被释放.
在自动提交模式下,还会释放关联的数据库锁.
每一步(preparation、execution和finalization)都关联于语句句柄的一种状态(prepared、active和finalized).
Pepared表示所有资源都已分配,语句已经可以执行,但还没有执行.
现在还48没有申请锁,一直到调用sqlite3_step()时才会申请锁.
Active状态开始于对sqlite3_step()的调用,此时语句正在被执行并拥有某种锁.
Finalized意味着语句已经被关闭且所有相关资源已经被释放.
通过图5-2可以更容易地理解该过程:图5-2语句处理下面代码例示了在SQLite上执行一个query的一般过程.
#include#include#include"sqlite3.
h"#include#pragmacomment(lib,"sqlite3.
lib")intmain(intargc,char**argv){intrc,i,ncols;sqlite3*db;sqlite3_stmt*stmt;char*sql;constchar*tail;49//打开数据rc=sqlite3_open("foods.
db",&db);if(rc){fprintf(stderr,"Can'topendatabase:%sn",sqlite3_errmsg(db));sqlite3_close(db);exit(1);}sql="select*fromepisodes";//预处理rc=sqlite3_prepare(db,sql,(int)strlen(sql),&stmt,&tail);if(rc!
=SQLITE_OK){fprintf(stderr,"SQLerror:%sn",sqlite3_errmsg(db));}rc=sqlite3_step(stmt);ncols=sqlite3_column_count(stmt);while(rc==SQLITE_ROW){for(i=0;i#include#include"util.
h"#pragmacomment(lib,"sqlite3.
lib")intmain(intargc,char**argv){sqlite3*db;char*zErr;intrc;char*sql;rc=sqlite3_open("test.
db",&db);if(rc){fprintf(stderr,"Can'topendatabase:%s\n",sqlite3_errmsg(db));sqlite3_close(db);exit(1);}sql="createtableepisodes(idintegerprimarykey,"67"nametext,cidint)";rc=sqlite3_exec(db,sql,NULL,NULL,&zErr);if(rc!
=SQLITE_OK){if(zErr!
=NULL){fprintf(stderr,"SQLerror:%s\n",zErr);sqlite3_free(zErr);}}sql="insertintoepisodes(name,id)values('CinnamonBabka2',1)";rc=sqlite3_exec(db,sql,NULL,NULL,&zErr);if(rc!
=SQLITE_OK){if(zErr!
=NULL){fprintf(stderr,"SQLerror:%s\n",zErr);sqlite3_free(zErr);}}sqlite3_close(db);return0;}处理记录如第5章所述,还是有可能从sqlite3_exec()取得记录的.
sqlite3_exec()包含一个回叫(callback)机制,提供了一种从SELECT语句得到结果的方法.
这个机制由sqlite3_exec()函数的第3和第4个参数实现.
第3个参数是一个指向回叫函数的指针,如果提供了回叫函数,SQLite则会在执行SELECT语句期间在遇到每一条记录时调用回叫函数.
回叫函数的声明如下:typedefint(*sqlite3_callback)(void*,/*Dataprovidedinthe4thargumentofsqlite3_exec()*/int,/*Thenumberofcolumnsinrow*/char**,/*Anarrayofstringsrepresentingfieldsintherow*/char**/*Anarrayofstringsrepresentingcolumnnames*/);函数sqlite3_exec()的第4个参数是一个指向任何应用程序指定的数据的指针,这个数据是你准备提供给回叫函数使用的.
SQLite将把这个数据作为回叫函数的第1个参数传递.
总之,sqlite3_exec()允许你处理一批命令,并且你可以使用回叫函数来收集所有返回的数据.
例如,先向episodes表插入一条记录,再从中查询所有记录,所有这些都在一个sqlite3_exec()调用中完成.
完整的程序代码见列表6-2,它来自exec.
c.
68列表6-2将sqlite3_exec()用于记录处理#include#include#include"util.
h"#pragmacomment(lib,"sqlite3.
lib")intcallback(void*data,intncols,char**values,char**headers);intmain(intargc,char**argv){sqlite3*db;intrc;char*sql;char*zErr;char*data;rc=sqlite3_open("test.
db",&db);if(rc){fprintf(stderr,"Can'topendatabase:%s\n",sqlite3_errmsg(db));sqlite3_close(db);exit(1);}data="Callbackfunctioncalled";sql="insertintoepisodes(name,cid)values('MackinawPeaches',1);""select*fromepisodes;";rc=sqlite3_exec(db,sql,callback,data,&zErr);if(rc!
=SQLITE_OK){if(zErr!
=NULL){fprintf(stderr,"SQLerror:%s\n",zErr);sqlite3_free(zErr);}}sqlite3_close(db);return0;}intcallback(void*data,intncols,char**values,char**headers){inti;69fprintf(stderr,"%s:",(constchar*)data);for(i=0;iintmain(intargc,char**argv){intrc,i,ncols;sqlite3*db;sqlite3_stmt*stmt;char*sql;72constchar*tail;rc=sqlite3_open("test.
db",&db);if(rc){fprintf(stderr,"Can'topendatabase:%s\n",sqlite3_errmsg(db));sqlite3_close(db);exit(1);}sql="select*fromepisodes;";rc=sqlite3_prepare(db,sql,(int)strlen(sql),&stmt,&tail);if(rc!
=SQLITE_OK){fprintf(stderr,"SQLerror:%s\n",sqlite3_errmsg(db));}rc=sqlite3_step(stmt);ncols=sqlite3_column_count(stmt);while(rc==SQLITE_ROW){for(i=0;iintmain(intargc,char**argv){intrc,i,ncols,id,cid;char*name,*sql;sqlite3*db;sqlite3_stmt*stmt;sql="selectid,cid,namefromepisodes";sqlite3_open("test.
db",&db);sqlite3_prepare(db,sql,strlen(sql),&stmt,NULL);ncols=sqlite3_column_count(stmt);rc=sqlite3_step(stmt);/*Printcolumninformation*/for(i=0;iDENIED\n");returnSQLITE_IGNORE;}}下面是INSERT和UPDATE的过滤.
所有的插入被允许.
对x字段的修改被拒绝.
这样不会锁住UPDATE的执行,而是简单地过滤掉对x字段的修改企图.
if(type==SQLITE_INSERT){printf(into%s",a);}if(type==SQLITE_UPDATE){printf(":Updateof%s.
%s",a,b);/*Blockupdatesofcolumnx*/82if(strcmp(b,"x")==0){printf("->DENIED\n");returnSQLITE_IGNORE;}}最后,对DELETE、ATTACH和DETACH进行过滤,在遇到这些事件时只是简单地给出通知.
if(type==SQLITE_DELETE){printf(":Deletefrom%s",a);}if(type==SQLITE_ATTACH){printf(":%s",a);}if(type==SQLITE_DETACH){printf("->%s",a);}下面是主程序,为了介绍的方便,也会分成多个片段.
intmain(intargc,char**argv){sqlite3*db,*db2;char*zErr;intrc;**Setup*//*Connecttotest.
db*/rc=sqlite3_open("test.
db",&db);if(rc){fprintf(stderr,"Can'topendatabase:%s\n",sqlite3_errmsg(db));sqlite3_close(db);exit(1);}**Authorizeandtest*//*Registertheauthorizerfunction*/83sqlite3_set_authorizer(db,auth,NULL);/*Testtransactionsevents*/printf("program:Startingtransaction\n");sqlite3_exec(db,"BEGIN",NULL,NULL,&zErr);printf("program:Committingtransaction\n");sqlite3_exec(db,"COMMIT",NULL,NULL,&zErr);printf("program:Startingtransaction\n");sqlite3_exec(db,"BEGIN",NULL,NULL,&zErr);printf("program:Abortingtransaction\n");sqlite3_exec(db,"ROLLBACK",NULL,NULL,&zErr);//Testtableeventsprintf("program:Creatingtable\n");sqlite3_exec(db,"createtablefoo(xint,yint,zint)",NULL,NULL,&zErr);printf("program:Insertingrecord\n");sqlite3_exec(db,"insertintofoovalues(1,2,3)",NULL,NULL,&zErr);printf("program:Selectingrecord(valueforzshouldbeNULL)\n");print_sql_result(db,"select*fromfoo");printf("program:Updatingrecord(updateofxshouldbedenied)\n");sqlite3_exec(db,"updatefoosetx=4,y=5,z=6",NULL,NULL,&zErr);printf("program:Selectingrecord(noticexwasnotupdated)\n");print_sql_result(db,"select*fromfoo");printf("program:Deletingrecord\n");sqlite3_exec(db,"deletefromfoo",NULL,NULL,&zErr);printf("program:Droppingtable\n");sqlite3_exec(db,"droptablefoo",NULL,NULL,&zErr);Severalthingsaregoingonhere.
Theprogramselectsallrecordsinthetable,oneofwhichiscolumnz.
Weshouldseeintheoutputthatcolumnz'svalueisNULL.
Allotherfieldsshouldcontaindatafromthetable.
Next,theprogramattemptstoupdateallfields,themostimportantofwhichiscolumnx.
Theupdateshouldsucceed,butthevalueincolumnxshouldbeunchanged,astheauthorizerdeniesit.
ThisisconfirmedonthefollowingSELECTstatement,whichshowsthatallcolumnswereupdatedexceptforcolumnx,whichisunchanged.
The84programthendropsthefootable,whichshouldissueaschemachangenotificationfromthepreviousfilter.
//TestATTACH/DETACH//Connecttotest2.
dbrc=sqlite3_open("test2.
db",&db2);if(rc){fprintf(stderr,"Can'topendatabase:%s\n",sqlite3_errmsg(db2));sqlite3_close(db2);exit(1);}//Droptablefoo2intest2ifexistssqlite3_exec(db2,"droptablefoo2",NULL,NULL,&zErr);sqlite3_exec(db2,"createtablefoo2(xint,yint,zint)",NULL,NULL,&zErr);//Attachdatabasetest2.
dbtotest.
dbprintf("program:Attachingdatabasetest2.
db\n");sqlite3_exec(db,"attach'test2.
db'astest2",NULL,NULL,&zErr);//Selectrecordfromtest2.
dbfoo2intest.
dbprintf("program:Selectingrecordfromattacheddatabasetest2.
db\n");sqlite3_exec(db,"select*fromfoo2",NULL,NULL,&zErr);printf("program:Detachingtable\n");sqlite3_exec(db,"detachtest2",NULL,NULL,&zErr);**Cleanup*/sqlite3_close(db);sqlite3_close(db2);return0;}线程如第2章所述,SQLite支持线程.
在多线程环境下使用SQLite时,有一些基本规则需要遵守.
85共享缓冲区模式Figure6-3.
Thesharedcachemodel线程和内存管理共享缓冲区模式的目录是为了节省内在,SQLite中有几个函数是与线程和内存管理有关的.
使用它们可以限制堆的尺寸或手工地发起内存清理.
这些函数包括:voidsqlite3_soft_heap_limit(intN);intsqlite3_release_memory(intN);voidsqlite3_thread_cleanup(void);86第7章扩充CAPI本章介绍SQLite的新技巧.
前一章涉及一般的数据库操作,本章将开始创新.
扩充API提供3种基本方法来扩展(或说定制)SQLite,包括:创建用户自定义函数、聚合和排序序列.
- 数据库recovery教程相关文档
- rebuildrecovery教程
- CUCM的备份和恢复操作通过CLI
- statedrecovery教程
- 画面recovery教程
- Orlandorecovery教程
- 您的recovery教程
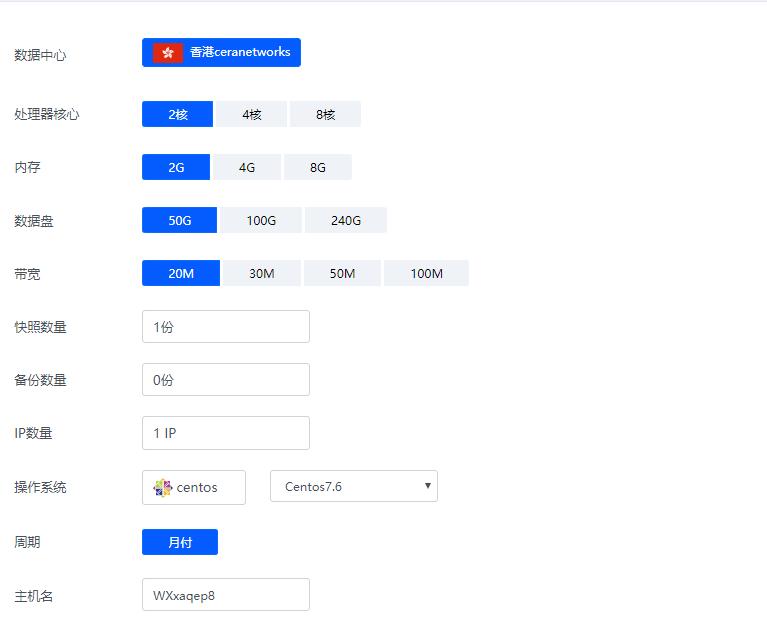
香港ceranetworks(69元/月) 2核2G 50G硬盘 20M 50M 100M 不限流量
香港ceranetworks提速啦是成立于2012年的十分老牌的一个商家这次给大家评测的是 香港ceranetworks 8核16G 100M 这款产品 提速啦老板真的是豪气每次都给高配我测试 不像别的商家每次就给1核1G,废话不多说开始跑脚本。香港ceranetworks 2核2G 50G硬盘20M 69元/月30M 99元/月50M 219元/月100M 519元/月香港ceranetwork...
乌云数据(10/月),香港cera 1核1G 10M带宽/美国cera 8核8G10M
乌云数据主营高性价比国内外云服务器,物理机,本着机器为主服务为辅的运营理念,将客户的体验放在第一位,提供性价比最高的云服务器,帮助各位站长上云,同时我们深知新人站长的不易,特此提供永久免费虚拟主机,已提供两年之久,帮助了上万名站长从零上云官网:https://wuvps.cn迎国庆豪礼一多款机型史上最低价,续费不加价 尽在wuvps.cn香港cera机房,香港沙田机房,超低延迟CN2线路地区CPU...
青果云(590元/年),美国vps洛杉矶CN2 GIA主机测评 1核1G 10M
青果网络QG.NET定位为高效多云管理服务商,已拥有工信部颁发的全网云计算/CDN/IDC/ISP/IP-VPN等多项资质,是CNNIC/APNIC联盟的成员之一,2019年荣获国家高薪技术企业、福建省省级高新技术企业双项荣誉。那么青果网络作为国内主流的IDC厂商之一,那么其旗下美国洛杉矶CN2 GIA线路云服务器到底怎么样?官方网站:https://www.qg.net/CPU内存系统盘流量宽带...

-
阿里云系统安卓系统和阿里云系统比较?那个很好?优点缺点?比较一下,最近想买,不知道选哪个系统的。阿里云系统阿里云系统怎么样网易公开课怎么下载手机上的网易公开课的付费课程怎么下载??????硬盘人什么叫“软盘人”和“硬盘人”?畅想中国20年后中国会变成什么样?--畅想一下未来的中国!!mate8价格手机华为mat8售价多少ios系统iOS系统是什么二层交换机集线器和二层交换机,三层交换机的区别虚拟专用网intranet,extranet,虚拟专用网与internet有什么区别与联系声母是什么声母.韵母有哪些