算法基于hash和trie树的ipv6高速查找和快速增量更新路由算法设计与实现
设计论文题目基于Hash和Trie树的IPv6高速查找和快速增量更新路由算法设计与实现
姓 名 刘晓青
学 号 20081101420
所属系 信息技术学院
专业年级08级计算机科学与技术
指导教师 何 英
2012年5月
摘要
由于Interne t的速度不断提高、 网络流量不断增加和网络规模不断扩大使得路由器成为制约Interne t性能的主要瓶颈之一。随着路由器技术的发展路由查找速度依然是进一步提高路由器性能的关键要素。本论文首先研究了各种经典的IPv6路由查找算法并分析了各种路由查找算法的复杂度和存在的问题对IPv4向IP v6过度的路由查找算法的存在的问题以及路由查找算法的性能参数和复杂度给出了一种基于hash和trie树高速查找和快速增量更新路由查找算法其次对路由缓存优化策略进行改进并就路由节点进行生物智能化处理使得路由负载平衡得到改善最后通过仿真实验得出该算法优于以往算法。关键字路由查找最长前缀匹配 Hash表 Trie树生物智能
Abstract
With the development of the internet,the increasing of throughput and theexpanding of network,making the router becomes the one of the main bottleneckrestricting the internet performance.With the development of routing technology,thespeed of the routing lookup is still a key element to further improvement of routerperformance.This paper studied various classic IPv6 routing lookup algorithms firstly,then analysis the complexity of the various routing lookup algorithms and someexisting problems,find the exiting problems in routing lookup algorithms from IPv4 toIPv6 and the performance parameters and complexity of routing lookup algorithms,iserved a high speed lookup and fast incremental update routing lookup algorithmsbased on hash and trie tree;Secondly,i have been done for route cache optimizationstrategies improvement and conducted route nodal biological intelligent,make therouting load balancing improving;Finally,via the simulation experiment,i know thatthis algorithm is better than before.
Keywo rds :Route lookup Lo ngest prefix match Hash table Tire Biologicalin te llig e nc e
目录
第一章绪论. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .1
1.1研究背景及现状. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .1
1.2本文研究内容、意义、价值. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .1
第二章相关技术概述. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .2
第三章HT6路由查找算法的实现. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .4
3.1算法设计. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .4
3.1.1 HT6算法基本思想. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .4
3.1.2数据结构设计. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .5
3.1.3 HT6查找设计. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .8
3.1.4路由更新. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .11
3.2算法改进. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .13
3.2.1缓存优化. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .13
3.2.2生物智能节点. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .17
第四章模拟仿真及实验数据分析. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .23
4.1仿真环境搭建. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .23
4.2算法仿真及分析. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .24
第五章总结与展望. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .26
5.1全文总结. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .26
5.2研究展望. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .27
参考文献. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .27
致谢. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .28
第一章绪论
1.1研究背景及现状
互联网在人类生活中扮演着重要的角色。随着互联网规模不断增长用于主干网络互联的核心路由器的接口速率需求已经大大提高这就要求核心路由器在单位时间内能够转发更多的分组分组转发的重要一步就是查找路由表。
目前的互联网是基于IP v4协议随着互联网的网络规模不断扩大 IP v4协议在许多方面己经不能满足人们的需要。 IPv6是由IETF设计的用来替代IP v4的下一代互联网协议。和IPv4相比 IPv6最大的特点是它使用了128位超长IP地址这就使得IP v4中许多性能优异的路由查找算法不能够应用到IP v6中或者是应用到IPv6之后 由于内存访问次数或内存消耗的增加导致算法性能非常低。
1.2本文研究内容、意义、价值
本文主要研究了IPv6路由查找算法提出了一种适用于IP v6路由高速查找和快速增量更新实现思路在此基础上改进了路由缓存将生物智能应用到路由节点的负载平衡中来并搭建了仿真实验平台对其特点和性能进行了定量研究。上述工作的意义和价值主要体现在以下方面第一本文在前人的基础上提出了新的路由查找算法设计思路具有创新性。基于该思路设计的查找算法具有更低的时间复杂度和空间复杂度。第二在此算法的基础上提出了路由缓存优化的策略和基于生物智能的路由节点负载策略对算法的性能进行了大幅度的提升这对以后研究IPv6路由算法具有明显的借鉴价值。第三为了更好地分析和对比各种路由查找算法的性能我们搭建了路由仿真平台。相信第三章算法对学者以及企业级路由应用具有很高的参考价值。
1
第二章相关技术概述
路由器是工作在网络层(IP层)的网络通信设备可以连接不同类型的网络还能够选择数据传送路径并对数据进行转发。路由器主要由下面几部分组成路由引擎、转发引擎、路由表、网络适配器和相关的逻辑电路等。转发引擎负责把从一个网络适配器来的数据包转发到另一个网络适配器出去。 IP协议包括对路由表的查找构成了转发引擎中最主要的部分。由于每个通过路由器并需要其转发的数据包都要对路由表进行查找所以路由表的查找效率如何往往决定了整个路由器的性能。路由引擎则包括了高层协议特别是路由协议它负责对路由表的更新。 由于路由引擎不涉及通过路由器的数据通路可以使用通用的CPU代替。
IPv6核心标准是RFC2460网际协议版本6(IP v6)规范以及描述其辅助协议的文档RFC2461(IPv6邻居发现协议ND)和RFC2463(互联网控制报文协议版本
6 ICMP v6)。 IP v6地址可以分为一下三类单播、任播、多播。单播(unicast)地址是和IPv4相同标准的地址一个单播地址标识一个网络接口任播(anycas t)地址标识一组网络接口但目标为一个任播地址的分组只会被送到那个组中的一个接口中去通常被送到容易到达的接口 多播(multicast)地址也标识一组网络接口 目标为多播地址的分组会被送给那个组中所有的成员IPv6地址的前缀表示类似于IP v4的无类别地址。地址由网络I D和主机I D组成 网络lD称为前缀其比特个数称为前缀长度。前缀通常是在地址后加斜杠斜杠后加前缀长度来表示。
Trie采用一种基于树的数据结构它通过前缀中每一个比特的值来决定树的分支。Trie树结构的查找过程根据目的地址的比特位来进行每个节点左右分支由目的地址所对应比特位的值来决定如果比特位为0则选择左分支否则选右分支。
IPv6算法有基于B-树的IP v6路由查找算法、 TSB算法、基于trie的IP v6路由查找算法、基于哈希表和trie树的快速内容路由查找算法[1]
基于B-树的IPv6路由查找算法用IP地址作为插入和查找的关键字将表项有序的存储在B-树结构中 同时利用B-树基于外存查找。
基于Hash和trie树的路由查找算法是将原来的Hash表按照顶级域名划分成
2
各个小表再利用trie树进行查找。
各算法性能分析与比较如表2.1所示(其中W为地址长度N为路由表前缀数目)
表21 IPv6各算法性能分析比较
在实际开发中路由查找算法需要满足以下要求。
1.)查找速度快2.)存储空间少3.)更新时间短4.)可扩展性5.)实现的灵活性6.)预处理时间短
本章主要对路由技术现状的进行介绍和分析其中重点讲了IPv6路由发展,研究存在的问题及评价标准特别是IPv6的路由研究。这一章介绍的路由技术为作者的研究提供了素材和启迪对HT 6算法的设计以及改进提供了技术支援。
3
第三章HT6路由查找算法的实现
3.1算法设计
我们希望一个好的路由查找算法能够达到:
1.算法实现简单耗费内存较小
2.理想情况下最好只用一次访存就能达到转发端口
3.如果访存次数大于一次那么该算法应该满足访存次数很少或者在任何情况下访存次数能够被限定在一个很小的数值范围内
4.算法更新所耗时间比较小
本文算法基于这几方面提出了HT 6算法。
3.1.1HT6算法基本思想
考虑到分离链接散列表装填因子控制在0.674能够使节点平均查找得到最小的开销和多分支tr ie树检查的比特位数的特点结合IP v6地址结构对IP v6地址的48比特采用多分支Trie树进行查找而剩余的16比特直接采用Hash查找。在路由前缀表项中增加前缀长度压缩算法所需的存储空间采用BitAtlas 二进制位向量来表示连续出现的相同Ne xt-Hop 下一跳信息从而使得每个新出现的Next-Hop信息只需存储一次。对于以001作为高3比特单播路由查找在查找时我们可以忽略这三位对于其它类型的单播路由则只需将H T6算法数据结构的第一层trie树的查找步宽增加到24比特即可。
针对以上分析HT 6算法设计的基本思想主要体现在对于前缀扩展技术不但要有较大幅度的压缩比而且要易于解压缩查找和路由更新。针对以上要求我们设计的前缀扩展技术利用节点构造查找步宽为24-8-4-4-8-16的六层多分支Trie树将具有相同下一跳信息的连续表项组成一个数据块采用BitAtlas记录每个数据块的起始位置(即下一跳信息发生改变的表项位置)对于每个数据块中的下一跳信息只在表中存储一次。
4
3.1.2数据结构设计
数据结构在参考了TrieC[2]算法的基础上提出了HT6算法该算法采用24-8-4-4-8-16的步宽来构建多分支Tile树树中各节点的数据结构如下
·根节点采用HTl56 步宽为24的数据结构(忽略IPv6地址的001域)存储所有长度为[1 24]比特的IP v6地址前缀
·第二层和第五层均采用HT44 步宽为8的数据结构分别存储长度为
[25 32]比特和[41,48]比特的IP v6地址前缀。对于第三层和第四层则采用H T24步宽为4的数据结构分别存储长度为[33 36]比特和[37 40]比特的IP v6地址前缀
·第五层采用Hash数据结构存储长度为[49 64]比特的IP v6地址前缀。
为实现路由表的快速增量更新在Trie树中保存了未进行前缀扩展压缩前的原始前缀长度信息该信息被保存在NHI(Next-Hop Index)数据结构中。NHI长为2个字节NHI[15 16]存储标志(flag)位 flag为“0”表示查找成功这时NHI[14 6]存储了下一跳信息Next-Hop IDNHl[5 0]保存了MCPE压缩前的前缀长度(最长64位) flag为“1”表示需要继续查找下一层Trie树节点这时NHI[140]中存储了指向下一层Trie树节点的指针。NHI的数据结构如表2所示
表3 1 Next-Hop Index
NHIA(Next-hop Information Array)表示若干个NHI被连续存储在一个数组中。和B itAtlas相关的参数有两个 TotalEntrop y表示B itAtlas中被置“1” 的比特数它指示了NHIA数组的大小 Pos itio nEntrop y[K]表示B itAtla s中从比特0至比特K之间被置“1”的比特数表示N HIA数组中第几个元素是比特K所对应的 NHI 其中 0<K<2TotalEntropy-1 。 对所有的 K 总有Po s itio nEntrop y<=Tota lEntrop y。
HTl5/6数据结构如图3.1所示 对于每个HTl56节点包含215个表项(称HTl56 entry)每个表项的大小为16个字节。对于表项[63 0]存储着一个指向NHIA数组的指针。若B itAtlas域的TotalEntrop y小于等于4则HTl5/6_entry[63 0]存储
5
- 算法基于hash和trie树的ipv6高速查找和快速增量更新路由算法设计与实现相关文档
- 项目IPv6项目投资计划书
- 地址L 2003215063_杨新乾_基于IPv6的下一代校园网设计
- 设备基于ipv6的智能家居系统设计
- 地址网络协议IPV6基础知识点集锦(网络技术范文)
- 隧道ipv6校园建设实施计划方案模板
- 地址网络协议IPV6基础知识点(网络技术范文)
简单测评v5.net的美国cn2云服务器:电信双程cn2+联通AS9929+移动直连
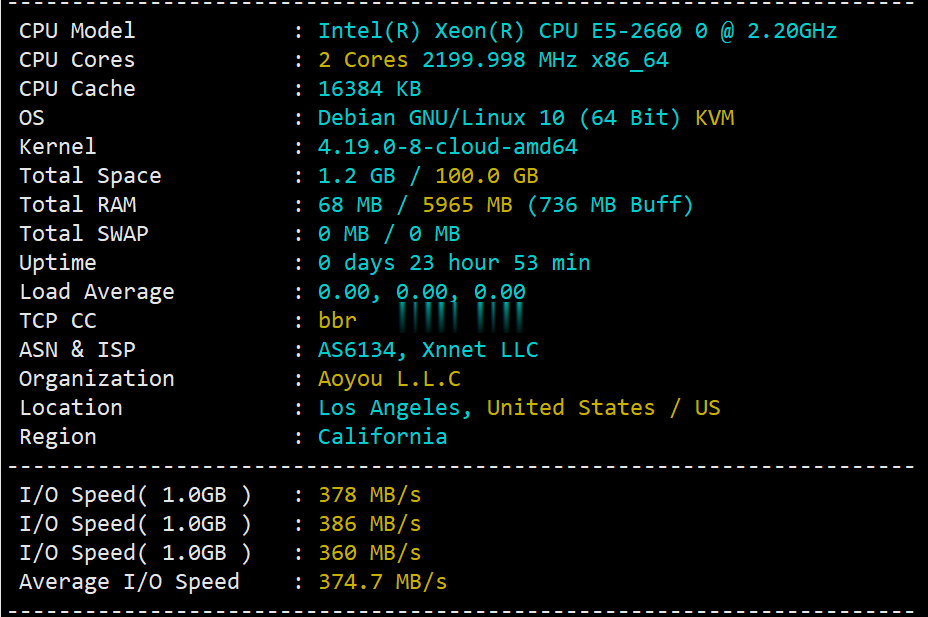
v5.net一直做独立服务器这块儿的,自从推出云服务器(VPS)以来站长一直还没有关注过,在网友的提醒下弄了个6G内存、2核、100G SSD的美国云服务器来写测评,主机测评给大家趟雷,让你知道v5.net的美国云服务器效果怎么样。本次测评数据仅供参考,有兴趣的还是亲自测试吧! 官方网站:https://v5.net/cloud.html 从显示来看CPU是e5-2660(2.2GHz主频),...
两款半月湾 HMBcloud 春节88折日本和美国CN2 VPS主机套餐
春节期间我们很多朋友都在忙着吃好喝好,当然有时候也会偶然的上网看看。对于我们站长用户来说,基本上需要等到初八之后才会开工,现在有空就看看是否有商家的促销。这里看到来自HMBcloud半月湾服务商有提供两款春节机房方案的VPS主机88折促销活动,分别是来自洛杉矶CN2 GIA和日本CN2的方案。八八折优惠码:CNY-GIA第一、洛杉矶CN2 GIA美国原生IP地址、72小时退款保障、三网回程CN2 ...
webhosting24:€28/年,日本NVMe3900X+Webvps
webhosting24决定从7月1日开始对日本机房的VPS进行NVMe和流量大升级,几乎是翻倍了硬盘和流量,当然前提是价格依旧不变。目前来看,国内过去走的是NTT直连,服务器托管机房应该是CDN77*(也就是datapacket.com),加上高性能平台(AMD Ryzen 9 3900X+NVMe),这样的日本VPS还是有相当大的性价比的。官方网站:https://www.webhosting...
-
美国10次啦导航gps卫星导航用的卫星应该是美国的吧?那有限几十颗卫星怎么能同时给地面上如此多的终端提供导航呢?腾讯空间首页怎么才能让自己QQ空间被腾讯推荐在QQ空间首页里面?杰士邦和杜蕾斯哪个好安全套杜蕾丝好还是杰士邦好?手机管家哪个好手机管理软件哪个好用红茶和绿茶哪个好红茶和绿茶哪个更好?雅思和托福哪个好考托福和雅思哪个好考 急。。。。。网络机顶盒哪个好什么牌子的网络机顶盒最好美国国际东西方大学美国新常春藤大学有哪些?qq空间登录电脑求助,怎么登陆电脑版的qq空间360云盘官网是不是一定要注册360帐号才能登陆360云盘?