模糊聚类分析请问层次聚类法与模糊聚类法有什么区别与联系?
模糊聚类分析 时间:2021-08-26 阅读:()
如何利用matlab模糊聚类分析
function Z=hecheng(X,X) [m,m]=size(X);z=zeros(m,m);p4=zeros(1,m); for i=1:m for j=1:m for k=1:m p4(1,k)=min(X(i,k),Y(k,j)); end Z(i,j)=max(p4); end end 应该能用!模糊聚类算法为什么要求 模糊相似矩阵
模糊聚类分析一般是指根据研究对象本身的属性来构造模糊矩阵,并在此基础上根据一定的隶属度来确定聚类关系,即用模糊数学的方法把样本之间的模糊关系定量的确定,从而客观且准确地进行聚类。聚类就是将数据集分成多个类或簇,使得各个类之间的数据差别应尽可能大,类内之间的数据差别应尽可能小,即为“最小化类间相似性,最大化类内相似性”原则
模糊聚类分析法的优点
聚类分析如果按照隶属度的取值范围可以分为两类,一类叫硬聚类算法,另一类就是模糊聚类算法。隶属度的概念是从模糊集理论里引申出来的。
传统硬聚类算法隶属...
模糊聚类分析的常用分类方法
数据分类中,常用的分类方法有多元统计中的系统聚类法、模糊聚类分析等.在模糊聚类分析中,首先要计算模糊相似矩阵,而不同的模糊相似矩阵会产生不同的分类结果;即使采用相同的模糊相似矩阵,不同的阈值也会产生不同的分类结果.“如何确定这些分类的有效性”便成为模糊聚类的要点。识别研究中的一个重要问题.文献,把有效性不满意的原因归结于数据集几何结构的不理想.但笔者认为,不同的几何结构是对实际需要的反映,我们不能排除实际需要而追求所谓的“理想几何结构”,不理想的分类不应归因于数据集的几何结构.针对同一模糊相似矩阵,文献建立了确定模糊聚类有效性的方法.用固定的显著性水平,在不同分类的F一统计量和F检验临界值的差中选最大者,即为有效分类.但是,当显著性水平变化时,此方法的结果也会变化.文献引进了一种模糊划分嫡来评价模糊聚类的有效性,并人为规定当两类的嫡大于一数时,此两类可合并,通过逐次合并,最终得到有效分类.此方法人为干预较多,当这个规定数不同时,也会得到不同的结果.另外这两种方法也未比较不同模糊相似矩阵的分类结果. 系统聚类法是基于模糊等价关系的模糊聚类分析法。
在经典的聚类分析方法中可用经典等价关系对样本集X进行聚类。
设R是 X上的经典等价关系。
对X中的两个元素x和y,若xRy或(x,y)∈R,则将x和y并为一类,否则x和y不属于同一类。
相应地,可用X上的模糊等价关系对样本集X进行模糊聚类。
设慒是X上的模糊等价关系,是慒 的隶属函数。
对于任何α∈【0,1】,定义慒 的α截关系 Sα是X上的经典等价关系。
根据Sα得到X 的一种聚类,称为在α水平上的聚类。
应用这种方法,分类的结果与α的取值大小有关。
α取值越大,分的类数越多。
α小到某一值时,X中的所有样本归并为一类。
这种方法的优点在于可按实际需要选取α的值,以便得到恰当的分类。
系统聚类法的步骤如下: ①用数字描述样本的特征。
设被聚类的样本集为 X={x1,…,xn}。
每个样本均有p种特征,记作xi=(xi1,…,xip);i=1,2,…,n;xip表示描述样本xi的第p个特征的数。
②规定样本之间的相似系数rij(0≤rij≤1;i,j=1,…,n)。
rij描述样本xi与xj之间的差异或相似的程度。
rij 越接近于1,表明样本xi与xj之间的差异越小;rij 越接近于0,表明xi与xj之间的差异越大。
rij可用主观评定或集体评分的方法规定,也可用公式计算,如采用夹角余弦法、最小最大法、算术平均最小法等。
因为rii=1(xi与自身没有差异),rij=rji(xi与xj之间的差异等同于xj与xi之间的差异),所以由rij(i,j=1,…,n)可得X上的模糊相似关系。
一般,R不具备可传递性,因而R不一定是 X上的模糊等价关系。
③运用合成运算R=R?R(或R=R?R等)求出最接近相似关系R的模糊等价关系S=R(或R等)。
若R已是模糊等价关系,则取S=R。
④选取适当水平α(0≤α≤1),得到X 的一种聚类。
逐步聚类法是一种基于模糊划分的模糊聚类分析法。
它是预先确定好待分类的样本应分成几类,然后按最优化原则进行再分类,经多次迭代直到分类比较合理为止。
在分类过程中可认为某个样本以某一隶属度隶属于某一类,又以另一隶属度隶属于另一类。
这样,样本就不是明确地属于或不属于某一类。
若样本集有 n个样本要分成c类,则它的模糊划分矩阵为此c×n模糊划分矩阵有下列特性:①uij∈【0,1】;i=1,…,c;j=1,…,n。
②即每一样本属于各类的隶属度之和为1。
③即每一类模糊子集都不是空集。
模糊聚类分析与模糊综合评价的关系
模糊聚类主要是模糊相似矩阵通过截集聚类,模糊综合评判主要是通过模糊变换关系矩阵,他们都用到模糊关系矩阵,他们都属于模糊数学的经典方法 不是属于关系,模糊聚类分析不是综合评价方法的一种请问层次聚类法与模糊聚类法有什么区别与联系?
你的应用背景我不了解。但是感觉你好像要把样本分成三类,如果是这样的话,最好不要用层次聚类算法。
层次聚类算法是不能自己指定聚类个数的,你需要用划分的聚类算法。
聚类算法粗略分为两类:基于“层次的”与基于“划分”的。
你说的模糊聚类算法也分很多种,最著名的也是最常用的就是模糊c均值聚类算法,它是基于“划分”的,个人感觉它应该适用于你的问题。
你不需要把“层次”聚类与“划分”的或者“模糊”聚类进行结合。
模糊c均值聚类本身就可以人为指定聚类个数,如果结合聚类有效性指标,也可以自动确定聚类个数。
聚类有效性指标以及模糊c均值你可以查文献,上中国知网搜索,很多的,要想看具体的介绍可以搜索相关博士或者硕士论文,在里面都会介绍具体细节。
模糊c均值的改进算法主要是可能性聚类算法,希望对你有帮助。
- 模糊聚类分析请问层次聚类法与模糊聚类法有什么区别与联系?相关文档
- 模糊聚类分析在matlab2014a中怎样查找模糊聚类
- 模糊聚类分析简单的一句话说模糊聚类分析是什么
- 模糊聚类分析模糊聚类的基本思想是什么?
NameCheap域名转入优惠再次来袭 搜罗今年到期域名续费
在上个月的时候也有记录到 NameCheap 域名注册商有发布域名转入促销活动的,那时候我也有帮助自己和公司的客户通过域名转入到NC服务商这样可以实现省钱续费的目的。上个月续费转入的时候是选择9月和10月份到期的域名,这不还有几个域名年底到期的,正好看到NameCheap商家再次发布转入优惠,所以打算把剩下的还有几个看看一并转入进来。活动截止到9月20日,如果我们需要转入域名的话可以准备起来。 N...
buyvm美国大硬盘VPS,1Gbps带宽不限流量
buyvm正式对外开卖第四个数据中心“迈阿密”的块存储服务,和前面拉斯维加斯、纽约、卢森堡一样,依旧是每256G硬盘仅需1.25美元/月,最大支持10T硬盘。配合buyvm自己的VPS,1Gbps带宽、不限流量,在vps上挂载块存储之后就可以用来做数据备份、文件下载、刷BT等一系列工作。官方网站:https://buyvm.net支持信用卡、PayPal、支付宝付款,支付宝付款用的是加元汇率,貌似...
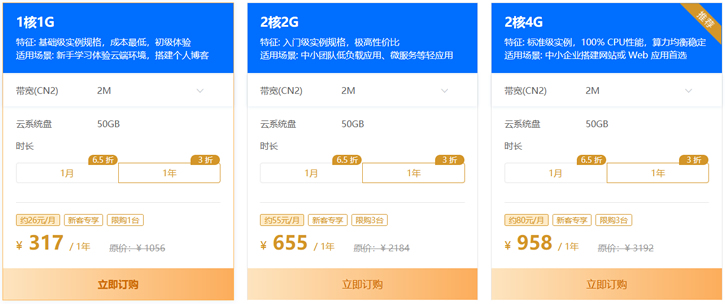
恒创新客(317元)香港云服务器 2M带宽 三网CN2线路直连
恒创科技也有暑期的活动,其中香港服务器也有一定折扣,当然是针对新用户的,如果我们还没有注册过或者可以有办法注册到新用户的,可以买他们家的香港服务器活动价格,2M带宽香港云服务器317元。对于一般用途还是够用的。 活动链接:恒创暑期活动爆款活动均是针对新用户的。1、云服务器仅限首次购买恒创科技产品的新用户。1 核 1G 实例规格,单个账户限购 1台;其他活动机型,单个账户限购 3 台(必须在一个订单...
模糊聚类分析为你推荐
-
方便快捷方便快捷的食物做法网不易上网的好处和坏处色空间求图像处理中颜色空间的介绍,越详细越好安卓手机用什么安全软件好现在的安卓手机用哪个应用下载软件好用?2017双112017年双11有哪些值得购买的商品垂直型网站垂直型网站和平行型网站的区别wps表格数据恢复WPS表格如果变成这样怎么恢复公司注册如何办理我想注册个小公司,具体怎么做。。。hadoop大数据平台大数据与Hadoop之间是什么关系本地连接断开本地连接老是断开怎么解决