hadoop是什么Hadoop:是什么,如何工作,可以用来做什么
hadoop是什么 时间:2021-08-24 阅读:()
hadoop通俗点说是什么?应该怎么学?有哪些前提的知识条件吗?
展开全部 通俗的说就是 假如说你有一个篮子水果,你想知道苹果和梨的数量是多少,那么只要一个一个数就可以知道有多少了。如果你有一个集装箱水果,这时候就需要很多人同时帮你数了,这相当于多进程或多线程。
如果你很多个集装箱的水果,这时就需要分布式计算了,也就是Hadoop。
Apache Hadoop是入门点,或者我们可以说是进入整个大数据生态系统的基础。
它是大数据生态系统中大多数高级工具,应用程序和框架的基础,但是在学习Apache Hadoop时,还需要事先知道一些事情。
开始学习Apache Hadoop没有严格的先决条件。
?但是,它使事情更容易,如果你想成为和Apache Hadoop的专家,这些是很好的知道的东西。
因此,Apache Hadoop的几个非常基本的先决条件是:Java ? Linux ? SQL
Hadoop是什么?Hadoop工资很高吗?
市场研究机构IDC预测到2016年,Hadoop将实现8.128亿美元的销售额—复合年增长率达到60.2%。SAS期望客户能够借助Hadoop继续将大数据转化为卓越洞察。
对于Hadoop人才的需求量也与日俱增,目前从事Hadoop工作的人员工资已经远超普通技术开发者,初级月薪在2万左右,高级年薪已经达到50万。
什么是hadoop,怎样学习hadoop
Hadoop实现了一个分布式文件系统(Hadoop Distributed File System),简称HDFS。HDFS有高容错性的特点,并且设计用来部署在低廉的(low-cost)硬件上;而且它提供高吞吐量(high throughput)来访问应用程序的数据,适合那些有着超大数据集(large data set)的应用程序。
HDFS放宽了(relax)POSIX的要求,可以以流的形式访问(streaming ess)文件系统中的数据。
Hadoop的框架最核心的设计就是:HDFS和MapReduce。
HDFS为海量的数据提供了存储,则MapReduce为海量的数据提供了计算。
一句话来讲Hadoop就是存储加计算。
Hadoop这个名字不是一个缩写,而是一个虚构的名字。
该项目的创建者,Doug Cutting解释Hadoop的得名 :“这个名字是我孩子给一个棕黄色的大象玩具命名的。
Hadoop是一个能够让用户轻松架构和使用的分布式计算平台。
用户可以轻松地在Hadoop上开发和运行处理海量数据的应用程序。
它主要有以下几个优点: 1、高可靠性Hadoop按位存储和处理数据的能力值得人们信赖。
2、高扩展性Hadoop是在可用的计算机集簇间分配数据并完成计算任务的,这些集簇可以方便地扩展到数以千计的节点中。
3、高效性Hadoop能够在节点之间动态地移动数据,并保证各个节点的动态平衡,因此处理速度非常快。
4、高容错性Hadoop能够自动保存数据的多个副本,并且能够自动将失败的任务重新分配。
5、低成本与一体机、商用数据仓库以及QlikView、Yonghong Z-Suite等数据集市相比,hadoop是开源的,项目的软件成本因此会大大降低。
Hadoop带有用Java语言编写的框架,因此运行在 Linux 生产平台上是非常理想的。
Hadoop 上的应用程序也可以使用其他语言编写,比如 C++。
Hadoop大数据处理的意义 Hadoop得以在大数据处理应用中广泛应用得益于其自身在数据提取、变形和加载(ETL)方面上的天然优势。
Hadoop的分布式架构,将大数据处理引擎尽可能的靠近存储,对例如像ETL这样的批处理操作相对合适,因为类似这样操作的批处理结果可以直接走向存储。
Hadoop的MapReduce功能实现了将单个任务打碎,并将碎片任务(Map)发送到多个节点上,之后再以单个数据集的形式加载(Reduce)到数据仓库里。
Hadoop由以下几个项目构成 1、Hadoop Common :Hadoop体系最底层的一个模块,为Hadoop各子项目提供各种工具,如:配置文件和日志操作等。
2、HDFS:分布式文件系统,提供高吞吐量的应用程序数据访问,对外部客户机而言,HDFS 就像一个传统的分级文件系统。
可以创建、删除、移动或重命名文件,等等。
但是 HDFS 的架构是基于一组特定的节点构建的(参见图 1),这是由它自身的特点决定的。
这些节点包括 NameNode(仅一个),它在 HDFS 内部提供元数据服务;DataNode,它为 HDFS 提供存储块。
由于仅存在一个 NameNode,因此这是 HDFS 的一个缺点(单点失败)。
存储在 HDFS 中的文件被分成块,然后将这些块复制到多个计算机中(DataNode)。
这与传统的 RAID 架构大不相同。
块的大小(通常为 64MB)和复制的块数量在创建文件时由客户机决定。
NameNode 可以控制所有文件操作。
HDFS 内部的所有通信都基于标准的 TCP/IP 协议。
3、MapReduce :一个分布式海量数据处理的软件框架集计算集群。
4、Avro :doug cutting主持的RPC项目,主要负责数据的序列化。
有点类似Google的protobuf和Facebook的thrift。
avro用来做以后hadoop的RPC,使hadoop的RPC模块通信速度更快、数据结构更紧凑。
5、Hive :类似CloudBase,也是基于hadoop分布式计算平台上的提供data warehouse的sql功能的一套软件。
使得存储在hadoop里面的海量数据的汇总,即席查询简单化。
hive提供了一套QL的查询语言,以sql为基础,使用起来很方便。
6、HBase :基于Hadoop Distributed File System,是一个开源的,基于列存储模型的可扩展的分布式数据库,支持大型表的存储结构化数据。
7、Pig :是一个并行计算的高级的数据流语言和执行框架 ,SQL-like语言,是在MapReduce上构建的一种高级查询语言,把一些运算编译进MapReduce模型的Map和Reduce中,并且用户可以定义自己的功能。
8、ZooKeeper :Google的Chubby一个开源的实现。
它是一个针对大型分布式系统的可靠协调系统,提供的功能包括:配置维护、名字服务、分布式同步、组服务等。
ZooKeeper的目标就是封装好复杂易出错的关键服务,将简单易用的接口和性能高效、功能稳定的系统提供给用户。
9、Chukwa :一个管理大型分布式系统的数据采集系统 由yahoo贡献。
10、Cassandra :无单点故障的可扩展的多主数据库 。
11、Mahout :一个可扩展的机器学习和数据挖掘库 。
Hadoop 设计之初的目标就定位于高可靠性、高可拓展性、高容错性和高效性,正是这些设计上与生俱来的优点,才使得Hadoop 一出现就受到众多大公司的青睐,同时也引起了研究界的普遍关注。
到目前为止,Hadoop 技术在互联网领域已经得到了广泛的运用,如Yahoo、Facebook、Adobe、IBM、百度、阿里巴巴、腾讯、华为、中国移动等。
关于怎样学习hadoop,首先要了解并且深刻认识什么是hadoop,它的原理以及作用是什么,包括基本构成是什么,分别有什么作用,当然,在学习之前,至少要掌握一门基础语言,这样在学习起来才会事半功倍,因为目前hadoop在国内发展时间不长,有兴趣的朋友可以先找一些书籍来学习,打好基本功,本站也将持续更新有关hadoop的学习方法以及资料资源共享,希望我们一起努力,有好的方法和建议欢迎交流。
Hadoop:是什么,如何工作,可以用来做什么
Hadoop主要是分布式计算和存储的框架,所以Hadoop工作过程主要依赖于HDFS(Hadoop Distributed File System)分布式存储系统和Mapreduce分布式计算框架。分布式存储系统HDFS中工作主要是一个主节点namenode(master)(hadoop1.x只要一个namenode节点,2.x中可以有多个节点)和若干个从节点Datanode(数据节点)相互配合进行工作,HDFS主要是存储Hadoop中的大量的数据,namenode节点主要负责的是: 1、接收client用户的操作请求,这种用户主要指的是开发工程师的Java代码或者是命令客户端操作。
2、维护文件系统的目录结构,主要就是大量数据的关系以及位置信息等。
3、管理文件系统与block的关系,Hadoop中大量的数据为了方便存储和管理主要是以block块(64M)的形式储存。
一个文件被分成大量的block块存储之后,block块之间都是有顺序关系的,这个文件与block之间的关系以及block属于哪个datanode都是有namenode来管理。
Datanode的主要职责是: 1、存储文件。
2、将数据分成大量的block块。
3、为保证数据的安全,对数据进行备份,一般备份3份。
当其中的一份出现问题时,将由其他的备份来对数据进行恢复。
MapReduce主要也是一个主节点JOPtracker和testtracker组成,主要是负责hadoop中的数据处理过程中的计算问题。
joptracker主要负责接收客户端传来的任务,并且把计算任务交给很多testtracker工作,同时joptracker会不断的监控testtracker的执行情况。
testtracker主要是执行joptracker交给它的任务具体计算,例如给求大量数据的最大值,每个testtracker会计算出自己负责的数据中的最大值,然后交给joptracker。
Hadoop的主要两个框架组合成了分布式的存储和计算,使得hadoop可以很快的处理大量的数据。
- hadoop是什么Hadoop:是什么,如何工作,可以用来做什么相关文档
- hadoop是什么Hadoop是什么?
- hadoop是什么hadoop是什么?是操作系统么
- hadoop是什么hadoop入门,了解什么是hadoop
VPS云服务器GT线路,KVM虚vps消息CloudCone美国洛杉矶便宜年付VPS云服务器补货14美元/年
近日CloudCone发布了最新的补货消息,针对此前新年闪购年付便宜VPS云服务器计划方案进行了少量补货,KVM虚拟架构,美国洛杉矶CN2 GT线路,1Gbps带宽,最低3TB流量,仅需14美元/年,有需要国外便宜美国洛杉矶VPS云服务器的朋友可以尝试一下。CloudCone怎么样?CloudCone服务器好不好?CloudCone值不值得购买?CloudCone是一家成立于2017年的美国服务器...
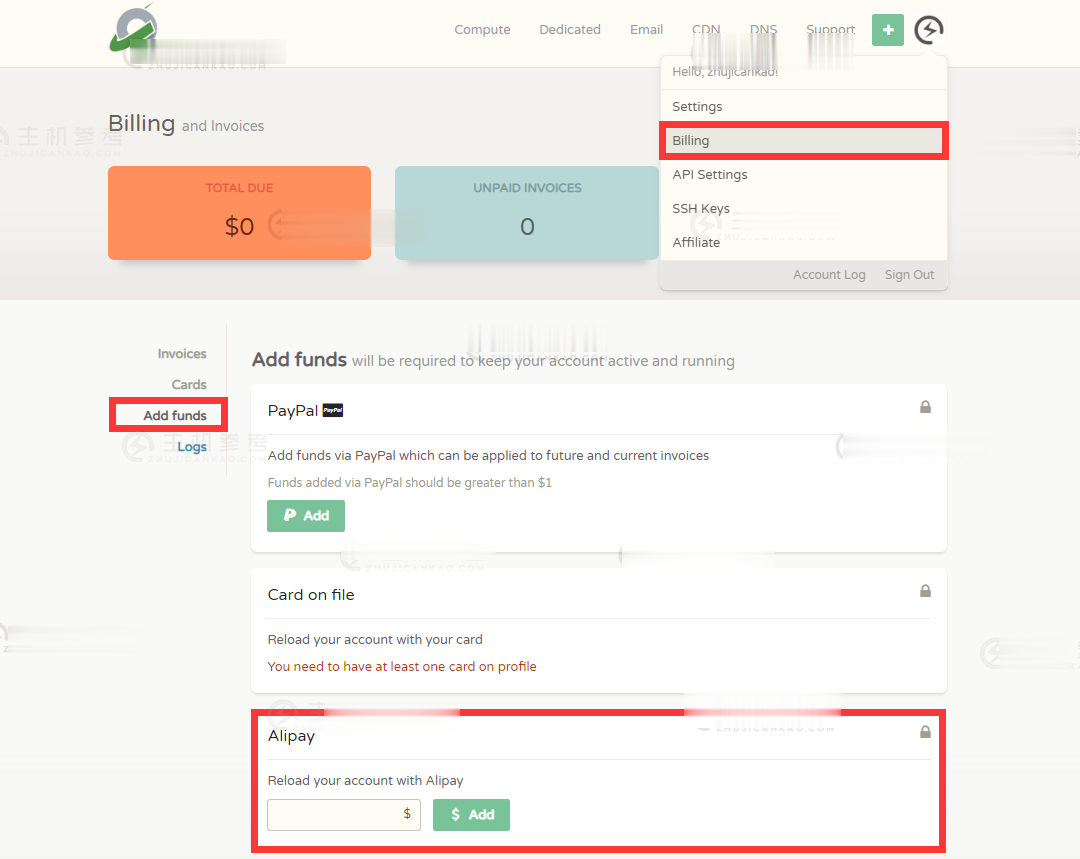
HostKvm($4.25/月)俄罗斯/香港高防VPS
HostKvm又上新了,这次上架了2个线路产品:俄罗斯和香港高防VPS,其中俄罗斯经测试电信CN2线路,而香港高防VPS提供30Gbps攻击防御。HostKvm是一家成立于2013年的国外主机服务商,主要提供基于KVM架构的VPS主机,可选数据中心包括日本、新加坡、韩国、美国、中国香港等多个地区机房,均为国内直连或优化线路,延迟较低,适合建站或者远程办公等。俄罗斯VPSCPU:1core内存:2G...
弘速云(28元/月)香港葵湾2核2G10M云服务器
弘速云怎么样?弘速云是创建于2021年的品牌,运营该品牌的公司HOSU LIMITED(中文名称弘速科技有限公司)公司成立于2021年国内公司注册于2019年。HOSU LIMITED主要从事出售香港vps、美国VPS、香港独立服务器、香港站群服务器等,目前在售VPS线路有CN2+BGP、CN2 GIA,该公司旗下产品均采用KVM虚拟化架构。可联系商家代安装iso系统,目前推出全场vps新开7折,...

hadoop是什么为你推荐
-
公告格式通告格式及有关文字文件保护什么叫文件保护查杀木马怎样手动查杀木马混乱模式拳皇2002李梅的混乱模式出招最好的电脑操作系统主流的电脑操作系统都有哪些?反恐精英维护到几点反恐精英几点维护完物联网公司排名国内物联网卡座公司有排名吗?人工电源网络设备EMC试验等级怎么选择?有选择标准吗?是什么标准?谢谢!垂直型网站垂直型网站和平行型网站的区别什么是无线上网WIFI无线上网是什么意思