集群渲染云渲染和渲染农场有什么区别
渲染农场是什么?
关于RenderfarmRenderfarm(渲染农场)其实是一种通俗的叫法,实际上我们应该叫他“分布式并行集群计算系统”,这是一种利用现成的CPU、以太网和操作系统构建的超级计算机,它使用主流的商业计算机硬件设备达到或接近超级计算机的计算能力。
集群(cluster)指的是一组计算机通过通信协议连接在一起的计算机群,它们能够将工作负载从一个超载的计算机迁移到集群中的其他计算机上,这一特性称为负载均衡(load balancing),它的目标是使用主流的硬件设备组成网格计算能力,达到、甚至超过天价的超级计算机的计算性能。
典型的超级计算机生产厂商包括IBM、SGI,以及其他一些大学、科研组织,以IBM Blue Pacific超级计算机为例,它拥有5800 个处理器来计算核反应的物理模拟过程,这样的计算机价格对于绝大部分商业用户是很难承受的,而且要面临很多的技术和维护问题,并且换代成本也很高,升级能力差。
因此,发展了利用通信技术连接其他计算机,组成一个网格计算系统,可以分配负载的工作给其他计算机的CPU进行处理的解决方法来模拟超级计算机的能力。
目前很多超级计算机也是通过集群技术得到的,特别是近年,名列世界Top500的超级计算机多数指集群系统,集群计算已经是比较成熟技术,但它仍在继续发展着。
昂贵的SGI Altix超级计算机
目前的集群技术绝大多数都具有负载平衡的特性,他们主要应用与科学计算,包括航天航空、石油、科研、网络等行业,这种技术应用于电影电视、CG行业时,因为主要用来解决长时间的图像渲染问题,所以被称为“Renderfarm(渲染农场)”,最近的几部大片的制作都依赖Renderfarm系统来进行快速渲染,比如Weta制作的《魔戒》,如果没有Renderfarm(渲染农场)平台,而是使用高性能计算机的话,我们不知需要多少年以后才能看到这部电影,或者导演根本就不可能考虑制作这样视觉效果的电影。
负载均衡的工作原理
分布式并行计算分为空间上的并行和奔渖系牟⑿小?span href="tag.php?name=%BF%D5%BC%E4" onclick="tagshow(event)" class="t_tag">空间上的并行是指用多个?砥鞑⒎⒌闹葱屑扑悖 热镗entalray渲染器就支持单帧画面分割渲染,时间上的并行就是指流水线技术,比如使用强氧Renderfarm提交渲染电影序列。
现在的集群计算系统的前沿科学研究主要是空间并行方面的,时间上的流式并行计算已经得到广泛应用。
以电影制作为例,一段电影图像序列需要很长时间的渲染,(通常2K分辨率所需要的渲染时间能被大家接受的大概是在每帧1小时左右),管理节点将序列图像分割为若干单元通过Web分配给其他节点,这个过程是动态的,集群软件会检查每个节点的当前负载,如果某个计算节点硬件配置比较高,很快完成了第一次分配的渲染工作,那么管理节点继续会将剩余工作分割为若干单元然后再发送给这个已完成渲染的空闲计算节点,直到渲染工作完成。
目前用于CG渲染的商业RenderFarm软件的核心功能其实就是动态分配渲染进程、网络监控和数据管理。
负载均衡系统使计算负载可以在计算机集群中尽可能平均分摊处理。
负载一般是需要应用程序处理,这样的系统适合于运行同一组应用程序的大量用户,比如用于Maya渲染的工作组,每个节点都可以处理一部分工作,并且可以在集群节点之间动态分配负载,以实现平衡。
集群计算管理需要涉及网络流量和流量管理。
负载均衡应用服务要求集群软件检查每个节点的当前负载,并确定哪些节点可以接受新的作业,这最适合运行如数据分析等串行和批处理作业,所以很容易允许具有批渲染能力的应用软件加载集群功能,一些集群软件被开发出来,它们通过TCP/IP 进行流量管理,并且针对特定的应用程序的API或Script接口编写批处理命令,如Muster,并且这些集群软件还可以配置成关注某特定节点的硬件或操作系统功能(受应用软件制约),这样,群集中的节点就没有必要是一致的,硬件和系统异构也就很容易实现。
实现负载均衡的方式可以分为软件负载均衡和硬件负载均衡两种方式,由于硬件负载均衡的实现非常昂贵,很多集群系统都采用了软件负载均衡,强氧集群系统就是使用软件均衡。
并行计算的问题
并行原理是将整个数据分割成N个模块分配给N个CPU计算,在每一个CPU中启动计算进程,由主进程调度各CPU的计算。
并行集群计算有一个效率发挥的问题,理论上CPU数量和渲染时间与实际会有差异,而且不同系统的实际时间也不尽相同。
理论上说CPU数量越大,渲染时间越短,它们成反比关系。
例如,一个任务由N颗CPU来完成,假设1颗CPU(N = 1)完成此任务所需要的时间T为1, 则n颗CPU的效率是1颗CPU效率的N倍,也即
然而事实上,动画渲染花费的时间和CPU的数量并非成线性反比。
当计算节点到某个数量级别的时候,简单地增加CPU数量或者计算节点根本无法有效地提高渲染的效率,这时的计算方式为:
CPU个数达到一定数量后系统效率不但不增加,还有可能减少。
造成这种问题的瓶颈主要在于通信(不止网络通信,还包括PC内部CPU、内存和硬盘之间的通信)和软件的算法,系统中使用多少个节点计算机(基于CPU的数量)也是需要考虑的问题。
这就需要一个拥有优秀算法的集群渲染管理软件进行调度并发挥每个CPU的效能并且使用性能优异的硬件配置。
Renderfarm特性
Renderfarm是基于软件和硬件应用的完美结合,采用基于微软Windows的Render farm,最新的网络管理方式,是用于管理复杂的和跨平台的高级3D和2D网络渲染解决方案,在渲染效率、稳定性、灵活性方面具有强有力的优势!
Renderfarm独特的“蜂群”构架消除了对集中“管理器“的需求――就像程序一样。
1)基于1U平台解决方案
在标准的42U机轨上轻松部署160颗处理器运算节点,提供业内独一无二的高性能--它带有众多创新性的选项:多核处理器、NVIDIA Quadro FX 图形处理和高性能千兆以太网。
2)强劲的处理器支持
支持最新的双核心处理器,在1U平台上集成四颗物理核心处理器,提供超过普通双处理器平台双倍的运算效率!
3)64位系统构架
采用64位系统架构,良好兼容32位运算,平滑过渡到64位系统!
4)友善的用户界面
针对广大用户的反馈,Renderfarm对自身做出了相应的改进:没有了缓慢的页面、晦涩难懂的术语和运行怪异的多平台用户界面窗口部件,取而代之的是一个单一完整的Monitor用户界面。
5)对当前各种渲染包的完美支持
除了能够支持所有标准命令行渲染工具,Renderfarm带有针对Maya,3ds max,Digital Fusion, Lightwave, Softimage XSI 和AfterEffects等软件的自定义编写窗口,通过专门的应用软件脚本或者插件,以实现高效率及可配置性。
广泛的应用程序支持包括:
3dsmax After Effects Combustion Digital Fusion Gelato Lightwave Maya Shake Softimage XSI
基于RIB渲染引擎3Delight、AIR、BMRT、Entropy、PRMan、Pixie、RenderDotC 脚本和C++SDK插件 ,支持渲染引擎的脚本,SDK提供强大灵活的特性。
整合RPManager
6)多个工作时间表选项
数字显示的工作优先级、机器资源、指定的并发事件限制群以及特定工作黑名单使您既可以处理有限证件插件和渲染包,也能够准确地在多部门间控制渲染资源的分配。
7)管理和审查
管理特性可选择密码保护。
任何对工作、任务及从属项目更改都可被记录并跟踪。
整合的远程管理功能,如:设备统计报告(CPU、磁盘空间、存储器、操作系统及修补包)、远程启动/停止/重启从属程序和设备、在远程设备上执行任意命令行。
远程错误报告直接向Frantic Films Software报告渲染错误和一般应用程序错误可以缩短停工期并加快问题的解决。
9)良好的系统兼容性
Renderfarm可以良好的运行于Microsoft Windows 2000,Microsoft Windows Server 2000和Microsoft Windows XP和运行在Microsoft .NET 1.1平台的顶层,他通过向一个Windows共享的文件夹读写文件实现网络渲染,没有必要在贮藏库主机上安装客户端软件。
对少于11台机器的Render farm,任意Windows 2000 或 Windows Xp机器都能作为贮藏库主机使用,而对多于11台机器的较大Render farm,推荐下面任意一种配置:
Microsoft Windows 2000 Server,
Microsoft Windows 2000 Advanced Server,
Microsoft Windows 2003 Server
如果没有从微软另购买用户访问证件,标准配置的Microsoft Windows 2000 和Windows XP不允许多于10个接入连接。
大场景可视化应用越来越广,intel最新推出D5400XS主板,该主板将45纳米酷睿技术,nvidia的SLI技术,FBD800高速内存,eSATA高速阵列,静音等最新技术融为一体,广泛用于海量数据处理可视化,动画渲染,虚拟现实仿真,视频处理,该配置适合工程设计研究室,个人工作室,做到真正高速运算静音工作完美地步。
请问GPU渲染是否可以完全取代CPU渲染
展开全部 不是作用不大 对于效果图的渲染,GPU根本不起任何作用!! 渲染 有两种 时时渲染,和最终渲染 显卡的工作,换句话说 显卡的职责,显卡最初的设计理论,当初为什么要设计,发明显卡 是为了解决3D时时加速的。在当时的应用就是游戏,和3D应用。
显卡的工作就是多边形生成和纹理贴图。
在3DMAX中间 4个透视窗口中我们建立模型是依靠显卡GPU进行运算的,时时计算3D加速 支持OPENGL或者D3D 这些都是时时渲染加速,不支持复杂的光照运算。
之所以显卡不支持复杂光照运算是由于显卡的构造而决定了。
我举个例子 画笔和图案印章 。
同样画图 很显然图案印章的效率明显比画笔快,压以下一个图案,但是印章的局限就是图案简单,也就是说它只能画出GPU本身所支持的算发,也就是几个简单的加减乘除,和函数计算(GPU只继承了这些算法) GPU就是图案印章。
画笔 我不说你也应该知道它就是CPU了 虽然画画速度慢 但是他想画什么就能画什么,只要软件支持。
因为CPU的指令集非常丰富,能进行软件所支持的任何计算,无论是加减乘除还是复杂的函数运算,根号运算都支持。
而这个就是渲染最终效果图所需要的。
即使现在的游戏,光影都是由CPU负责的, 显卡的工作就是多边形生成 和文理贴图, 不具备光影处理能力。
现在的游戏中 光影都是假光影,物体的反射都是材质贴图,也就是说镜子所反射的不是周围的物体 而是制作了一个周围物体的贴图给了镜子。
从D3D9以后 显卡能够多一点的分担CPU的负担 集成的更多的指令集和函数流水线,但是他毕竟是用来加速时时3D的 所以流处理器的个数才是最重要的。
1个流处理器就是一个CPU 只不过指令集和功能比CPU少的可怜。
无论是专业显卡还是中等的图形工作站 显卡都不参与效果图渲染。
即使以后显卡能够渲染效果图了,我们也不会使用显卡渲染 因为CPU体积比显卡小多了,大型服务器 超级计算机 图形渲染集群都是成千上万的CPU组成的 一般一部服务器 安装了500 600个CPU,如果换成显卡,那体积不得了。
而且用途也不广泛,CPU是万能的。
专业显卡和游戏显卡 本身没有区别,也就是说显卡硬件GPU没有区别。
区别在于驱动。
在GPU中间有一个OPENGL硬件开关,出厂的时候就已经设定好的,NV显卡无法修改ATI显卡可以破解。
游戏显卡注重速度,而不注重质量,只对D3D支持和基础OPENGL 不支持专业OPENGL 专业显卡注重质量,抗锯齿模式丰富,并且支持线框抗锯齿。
游戏中,只有物体边缘有矩尺,而专业做图,由于线筐多,一个屏幕复杂的要几万条线条,所以抗矩尺很重要 和游戏显卡不同 专业显卡对于3D模型的内部显示做优化,游戏中的汽车,只显示汽车外表,而专业作图不仅显示外表 还要显示汽车内部结构。
显示的内容都是不一样的
预算10W左右,要配个渲染集群,兄弟们帮忙看看
从专业角度讲不太建议用ASUS,建议您用超微或者泰安的 主板:Tyan S7002G2NRF CPU : Xeon E5620 * 2 硬盘: WD 1TB 黑盘 内存: 2G ECC DDR3 1333 * 2 机电: 塔式 + 新巨600W 总价:10800 有疑问我们可以及时沟通予以解决,QQ:1187520094 TEL:15989429629,期待您的来电。maya渲染技巧 无规则多帧批量渲染
你可以设置自己的机器为渲染服务器,然后用集群渲染的方法把所有的渲染队列发送到服务器上,也就是自己的机器上,然后他就会按照顺序挨个渲染了
集群渲染设置 ↓
参考资料:/link?url=p3Rfq-SFu2cDaKQ7QeZSF3IUjGVqL4s1qMOttxb68ypPLc0pyoIxmeSSAS4s7jmeuKhJ9fpLTJ1LMGnG4vB4z7D4bkT4o_ifVyJVAnGcecy
请问集群渲染仅限于二三维动画吗?设计能否用到?
你得详细地说出到底是设计什么,集群就是渲染速度快,如果是平面设计的话,根本不需要集群呀,只有像三维动画这样巨大的工程才需要集群。这只是个需不需要的问题,而不是一个能否的问题
云渲染和渲染农场有什么区别
简单点说,云渲染就是你把作品通过网络发到远方的超级计算机集群中,由它们帮你完成渲染后再发回到你的电脑中。渲染农场相当于一个超级计算机,也可以完成渲染工作。
现在一些云渲染农场,其实就是运用了云渲染技术,不了解的话可以看一下德国的REBUSfarm渲染农场的工作原理,它们就是采用了云渲染技术。
中文网址:
- 集群渲染云渲染和渲染农场有什么区别相关文档
- 集群渲染maya 批量渲染 第一百多帧后与单帧渲染的不一样了 求解
- 集群渲染渲染农场和云渲染有什么区别
- 集群渲染云渲染和渲染农场有什么区别
- 集群渲染CPU渲染和GPU渲染出来的图为什么差别那么大
CloudCone:$17.99/年KVM-1GB/50GB/1TB/洛杉矶MC机房
CloudCone在月初发了个邮件,表示上新了一个系列VPS主机,采用SSD缓存磁盘,支持下单购买额外的CPU、内存和硬盘资源,最低年付17.99美元起。CloudCone成立于2017年,提供VPS和独立服务器租用,深耕洛杉矶MC机房,最初提供按小时计费随时退回,给自己弄回一大堆中国不能访问的IP,现在已经取消了随时删除了,不过他的VPS主机价格不贵,支持购买额外IP,还支持购买高防IP。下面列...
hostyun评测香港原生IPVPS
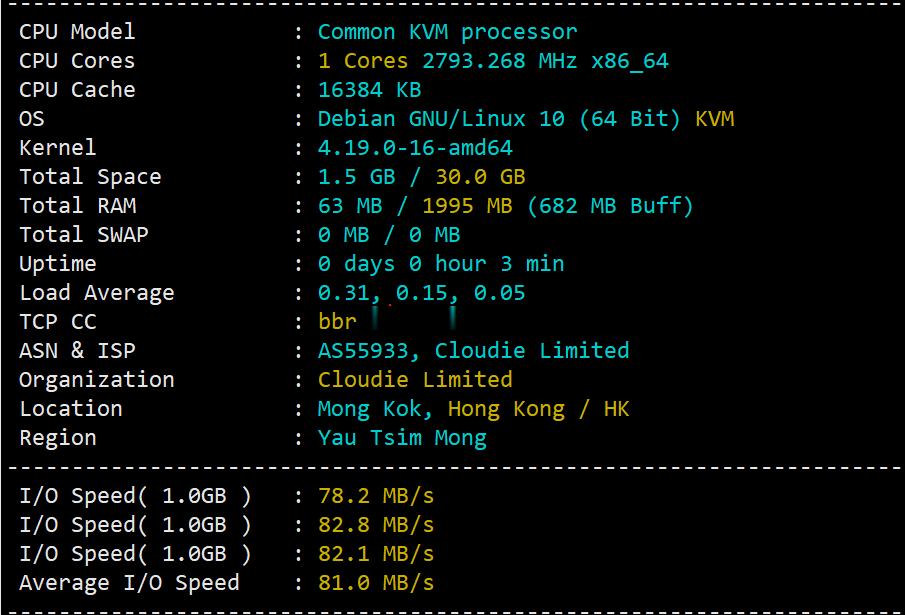
hostyun新上了香港cloudie机房的香港原生IP的VPS,写的是默认接入200Mbps带宽(共享),基于KVM虚拟,纯SSD RAID10,三网直连,混合超售的CN2网络,商家对VPS的I/O有大致100MB/S的限制。由于是原生香港IP,所以这个VPS还是有一定的看头的,这里给大家弄个测评,数据仅供参考!9折优惠码:hostyun,循环优惠内存CPUSSD流量带宽价格购买1G1核10G3...
小白云 (80元/月),四川德阳 4核2G,山东枣庄 4核2G,美国VPS20元/月起三网CN2
小白云是一家国人自营的企业IDC,主营国内外VPS,致力于让每一个用户都能轻松、快速、经济地享受高端的服务,成立于2019年,拥有国内大带宽高防御的特点,专注于DDoS/CC等攻击的防护;海外线路精选纯CN2线路,以确保用户体验的首选线路,商家线上多名客服一对一解决处理用户的问题,提供7*24无人全自动化服务。商家承诺绝不超开,以用户体验为中心为用提供服务,一直坚持主打以产品质量用户体验性以及高效...

-
商品管理怎样管理好经营好一个商场?权限表用户,权限,角色表怎么设计组或资源的状态不是执行请求操作的正确状态无法启动承载网络,组或资源状态下不是执行请求操作的正确状态!文件保护文件被写保护,怎么解除/反恐精英维护到几点今天反恐精英几点维护完?企业电子邮箱注册电子邮箱怎么注册网络黑科技华为有哪些黑科技?小时代发布会完整版在《小时代》发布会上看到有主演穿COCOON(可可尼)的衣服耶,COCOON(可可尼)有赞助这部电视剧吗?hadoop大数据平台大数据分析与应用平台 是什么样的系统hadoop大数据平台大数据集群?