sql distinctsql distinct语句的用法【在线等】
求SQL语句 distinct的用法
select distinct GoodsName from table order by GoodsName desc菜鸟求助sql语句distinct用法
select distinct score.sid,student.sid from score,student 其实我很奇怪,你这俩表没任何联系的吗? 这样数据会重复的。 所以我觉得以上用distinct 还不一定真正能达到你要求。 因为这样的distinct只会筛选掉两条一模一样的数据。也就是说这两条数据要所有东西一样,才会筛选掉。 而和字段没关系。SQL数据库DISTINCT是什么意思
SQL数据库中,?DISTINCT表示去掉重复的行,针对包含重复值的数据表,用于返回唯一不同的值。语法是SELECT DISTINCT 列名称 FROM 表名称。如果指定了 SELECT DISTINCT,那么 ORDER BY 子句中的项就必须出现在选择列表中,否则会出现错误。 扩展资料: ?DISTINCT虽然是用来过滤重复记录。但往往在使用时,只用它来返回不重复记录的条数,而不是用它来返回不重记录的所有值。其原因是?DISTINCT只有用二重循环查询来解决,而这样对于一个数据量非常大的站来说,无疑是会直接影响到效率的。 此外,对于?DISTINCT关键字,如果后面有多个字段,则代表着是多条件去重,只有当这几个条件都相同时才算是重复记录。SQL 语言DISTINCT怎么用?
Distinct 是消除字段中的重复值. 你判断字段为空这样方法不好.可能就出在这的问题 我一直用 isnull(字段)SQL中DISTINCT的位置
您好,知很高兴为您解答! 1. distinct 一般是放在select之后; 2. 如果是所有查询出来的道都要distinct,直接在select后加版distinct 关键词就可以; 3. 如果是单列,可以用distinct(col)函数权 希望我的回答对您有用!SQL语句,distinct的关键字使用。
distinct是会影响后面的列的, Select distinct amount,payee FROM checks 表示的是,查找checks表中,(amount,payee)这样一个组合不同 的记录。就是查两列不全相同的。请问一个SQL中distinct函数的问题?
b 正确 distinct是去掉重复的值sqlserver中的distinct的具体作用是什么?
我们在使用SQL语句对数据库表中的数据进行查询的时候,结果中可能会包含多条重复的记录,而关键字distinct的作用就是将重复的记录进行合并,相同的记录只显示一条。请问sql语句“Select Distinct”是什么意思?可不可以讲一下它的用法
Distinct的是作用是过滤结果集中的重复值。 比如订单信息表中有3条信息: 货品编码 数量 001 10 001 20 002 10 如果用第一个SQL语句查询的话,会返回 货品编码 数量 001 10 001 20 002 10 而用第二个则返回 货品编码 001 002 所以如果仅仅需要知道订单信息中的所有货品编码就用第二个SQL语句。SQL里的DISTINCT什么意思
distinct就是去掉重复值的意思,比如你这里,DISTINCT(Sno)如果sno出现两次但是只显示一次,所以在做count的时候就不一样了。Sql Distinct知多少
加上这个就是以distinct后面的字段为准,不要重复,将结果返回; 如select distinct a.dm,a.mc from test a; 表示查询a表dm不重复的记录;SQL中的DISTINCT有什么作用
假如 SNAME 字段有2个aaa, 当用DISTINCT会排除重复的而输出一个aaa 不用的时候输出2个aaadistinct用法 SQL用法
对整个select 来说的话.前面加一个distinct表示把重复的记录去掉的意思 id name 1 张三 2 王三 3 李四 4 张三 2 王三 select distinct id,name from t1 id name 1 张三 2 王三 3 李四 4 张三 select distinct name from t1 name 张三 王三 李四sql语句中DISTINCT是什么意思
DISTINCT 这个关键词的意思是用于返回唯一不同的值。 在表中,可能会包含重复值。这并不成问题,不过,有时您也许希望仅仅列出不同(distinct)的值。SELECT DISTINCT 表示查询结果中,去掉了重复的行;Distinct表示去掉重复的行。 扩展资料: sql语句中使用DISTINCT的注意事项: 如果指定了 SELECT DISTINCT,那么 ORDER BY 子句中的项就必须出现在选择列表中,否则会出现错误。 比如SQL语句:SELECT DISTINCT?Company?FROM Orders order by?Company?ASC是可以正常执行的。 但是如果SQL语句是:SELECT DISTINCT?Company?FROM Orders order by?Num?ASC是不能正确执行的,在ASP中会提示“ORDER BY 子句与 (Num) DISTINCT 冲突”错误。 SQL语句修改成:SELECT DISTINCT?Company,Num?FROM Orders order by?Num?ASC可以正常执行 参考资料:搜狗百科-DISTINCTSQL 语句提问 distinct的用法
select distinct max(z.id),z.djbm,z.sname from sj_dj z group by z.djbm, z.sname distinct 在这里没有什么作用,去掉后结果一样SQL ,distinct
你的要求很有意思!! 你要求longitude,latitude完全不重复的行,也就是说要剔除longitude中重复的列和latitude重复的列??? 不知道是不是这个意思,这个SQL语句是可以实现的 select longitude,latitude,currenttime from aa where longitude in (select longitude from aa group by longitude having count(longitude)=1) and latitude in (select latitude from aa group by latitudehaving count(latitude)=1) order by currenttime 上面的语句实现的是longitude中不重复的行,latitude中不重复的行的所有组合SQL语句中的 Distinct 和 Group by 有什么不同,用那个好?
我不给你转摘枯燥难读的文章,给你用例子说明: 不过,首先我要说:它俩的作用完全不同,如果你只把group by当做去掉重复记录的工具,就太小看它了, 善于使用它,将会为你的工作带来极大的便利,而且能够制作出非常科学高效的报表! group by主要是用来分组的,怎么个分组呢? 以下用两个例子说明两个使用方面,1是合理的返回合计值(防止笛卡尔积现象),2是用分组来找出重复的记录 ==================================================================== ★★★例子1:假如有这么一个表:tab_1,它有两个字段:xm、gzlb、je(姓名、工资类别、金额),具体数据如下: xm```````gzlb`````````je ----------------------------------------- 张三`````养老金`````1000 张三`````护理费`````200 张三`````其他```````50 ............. 李四`````养老金`````800 李四`````其他```````50 ............. 王五`````养老金`````900 王五`````其他```````35 可以看出每个人的工资都是按类别存放的,如果要返回合计的数据,如: 张三``````1250 李四``````850 王五``````935 该怎么写SQL呢?初学者往往会这么写:select xm, sum(je) from tab_1;但结果会是什么样呢?结果将是: 张三``````1250 张三``````850 张三``````935 李四``````1250 李四``````850 李四``````935 王五``````1250 王五``````850 王五``````935 这是将全部字段都进行了所有的排列组合,即:笛卡尔积!要防止这个情况的发生,我们就可以用到group by(分组)了! select xm, sum(je) from tab_1 group by xm; 上面的SQL指定了用xm字段分组,这样一来就返回出正确的结果了: 张三``````1250 李四``````850 王五``````935 ==================================================================== ★★★例子2:假设又有这么一个表:tab_2,有这些字段:bh, xm, dah,……(编号、姓名、档案号、……), 比如有这样的情况:向该表录入数据的人员非常不认真,重复录入了不少数据,如: bh``````xm```````dah ------------------------ 1```````张三`````10001 2```````李四`````10002 3```````王五`````10003 ……………… 84``````张三`````10001 85``````赵六`````10004 ……………… 126`````王五`````10003 可以看出张三、王五各重复了一次,假设这个表有几万条数据,那么要查出究竟有多少重复的,该怎么查呢? select bh, xm, dah from tab_2 group by xm, sfzh having count(*) >= 2; 返回值为: bh``````xm```````dah ------------------------ 1```````张三`````10001 84``````张三`````10001 3```````王五`````10003 126`````王五`````10003 解释一下刚才的SQL:是从tab_2表中检索编号、姓名、档案号,怎么检索呢?是用姓名、档案号做为分组,分组的条件是记录数大于等于2的。 这个比喻很形象:having count()语句相对于group by语句,就相当于where语句相对于select语句 ==================================================================== 所以,group by 这个分组语句是非常有用的一个好东西,还是那句话:善于使用它将会为你的工作带来极大的便利,而且能够制作出非常科学高效的报表!sql distinct 多字段
表结构
去除重复 distinct
只去掉了 A列和B列完全重复的数据
如果 去掉A列重复 并且去掉B列重复 可能会出现 A列 3条数据 B列5条数据的情况
所以 能同时去掉两列重复
如果一定要 同时去除 可以写两条查询分别去除重复 后插入临时表 然后查询
datediff datepart distinct SQL语句的使用方法
DateDiff 函数 返回两个日期之间的时间间隔。 DateDiff(interval, date1, date2 [,firstdayofweek[, firstweekofyear]]) DateDiff 函数的语法有以下参数: 参数 interval 必选项。String expression 表示用于计算 date1 和 date2 之间的时间间隔。有关数值,请参阅“设置”部分。 date1, date2 必选项。日期表达式。用于计算的两个日期。 Firstdayofweek 可选项。指定星期中第一天的常数。如果没有指定,则默认为星期日。有关数值,请参阅“设置”部分。 Firstweekofyear 可选项。指定一年中第一周的常数。如果没有指定,则默认为 1 月 1 日所在的星期。有关数值,请参阅“设置”部分。 设置 interval 参数可以有以下值: 设置 描述 yyyy 年 q 季度 m 月 y 一年的日数 d 日 w 一周的日数 ww 周 h 小时 n 分钟 s 秒 firstdayofweek 参数可以有以下值: 常数 值 描述 vbUseSystem 0 使用区域语言支持 (NLS) API 设置。 vbSunday 1 星期日(默认) vbMonday 2 星期一 vbTuesday 3 星期二 vbWednesday 4 星期三 vbThursday 5 星期四 vbFriday 6 星期五 vbSaturday 7 星期六 firstweekofyear 参数可以有以下值: 常数 值 描述 vbUseSystem 0 使用区域语言支持 (NLS) API 设置。 vbFirstJan1 1 由 1 月 1 日所在的星期开始(默认)。 vbFirstFourDays 2 由在新年中至少有四天的第一周开始。 vbFirstFullWeek 3 由在新的一年中第一个完整的周开始。 说明 DateDiff 函数用于判断在两个日期之间存在的指定时间间隔的数目。例如可以使用 DateDiff 计算两个日期相差的天数,或者当天到当年最后一天之间的星期数。 要计算 date1 和 date2 相差的天数,可以使用“一年的日数”(“y”)或“日”(“d”)。当 interval 为“一周的日数”(“w”)时,DateDiff 返回两个日期之间的星期数。如果 date1 是星期一,则 DateDiff 计算到 date2 之前星期一的数目。此结果包含 date2 而不包含 date1。如果 interval 是“周”(“ww”),则 DateDiff 函数返回日历表中两个日期之间的星期数。函数计算 date1 和 date2 之间星期日的数目。如果 date2 是星期日,DateDiff 将计算 date2,但即使 date1 是星期日,也不会计算 date1。 如果 date1 晚于 date2,则 DateDiff 函数返回负数。 firstdayofweek 参数会对使用“w”和“ww”间隔符号的计算产生影响。 如果 date1 或 date2 是日期文字,则指定的年度会成为日期的固定部分。但是如果 date1 或 date2 被包括在引号 (" ") 中并且省略年份,则在代码中每次计算 date1 或 date2 表达式时,将插入当前年份。这样就可以编写适用于不同年份的程序代码。 在 interval 为“年”(“yyyy”)时,比较 12 月 31 日和来年的 1 月 1 日,虽然实际上只相差一天,DateDiff 返回 1 表示相差一个年份。 下面的示例利用 DateDiff 函数显示今天与给定日期之间间隔天数: Function DiffADate(theDate) DiffADate = "从当天开始的天数:" & DateDiff("d", Now, theDate) End Functionsql 语名中怎样使用 distinct?
你需要的是消除结果集中的重复行吧. 比如在SQL SERVER2005中标准的格式是这样的SELECT DISTINCT column_name[,column_name...] 意思是只需要在SELECT后面,要显示的自段前面加入DISTINCT就可以了. 所以修改你的SQL语句:select distinct * from [user] where (" & translate(keyword,"xuexiao") & ") order by userid desc即可 给我看看你的结果,我不知道你具体有什么列也不是很清楚你要达到什么目的~打个比方 名字"黎明" 36岁 名字"黎明" 38岁 如果你"SELECT DISTINCT 名字,年龄 FROM A" 他会显示出两行~ 大意.把你程序中的*改成你要去的重复列.改成name 要是显示别的列.看格式[]加.我这台机器没有SQL没法验证.应该是下面的样子大致 修改:select distinct name from [user] where (" & translate(keyword,"xuexiao") & ") order by userid desc 去掉排列顺序BY USERID DESE.你想如果由名字显示.并不会有一个因为名字的升降序 这两天比较忙没时间上来看.SQL忘差不多了问了问朋友select distinct * from [user] where (" & translate(keyword,"xuexiao") & ") order by userid desc应该没有问题的。你在看看你表的结构是不是别的地方不对了sql distinct语句的用法【在线等】
select distinct 记账,结账, 销售单号 ,客户姓名 from zuzhuang
- sql distinctsql distinct语句的用法【在线等】相关文档
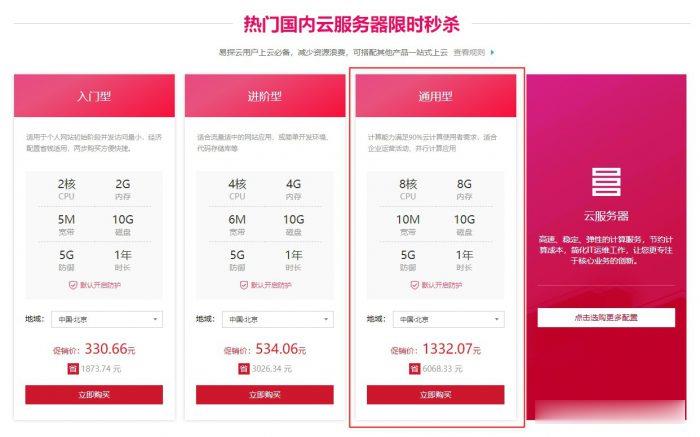
易探云(QQ音乐绿钻)北京/深圳云服务器8核8G10M带宽低至1332.07元/年起
易探云怎么样?易探云香港云服务器比较有优势,他家香港BGP+CN2口碑不错,速度也很稳定。尤其是今年他们动作很大,推出的香港云服务器有4个可用区价格低至18元起,试用过一个月的用户基本会续费,如果年付的话还可以享受8.5折或秒杀价格。今天,云服务器网(yuntue.com)小编推荐一下易探云国内云服务器优惠活动,北京和深圳这二个机房的云服务器2核2G5M带宽低至330.66元/年,还有高配云服务器...
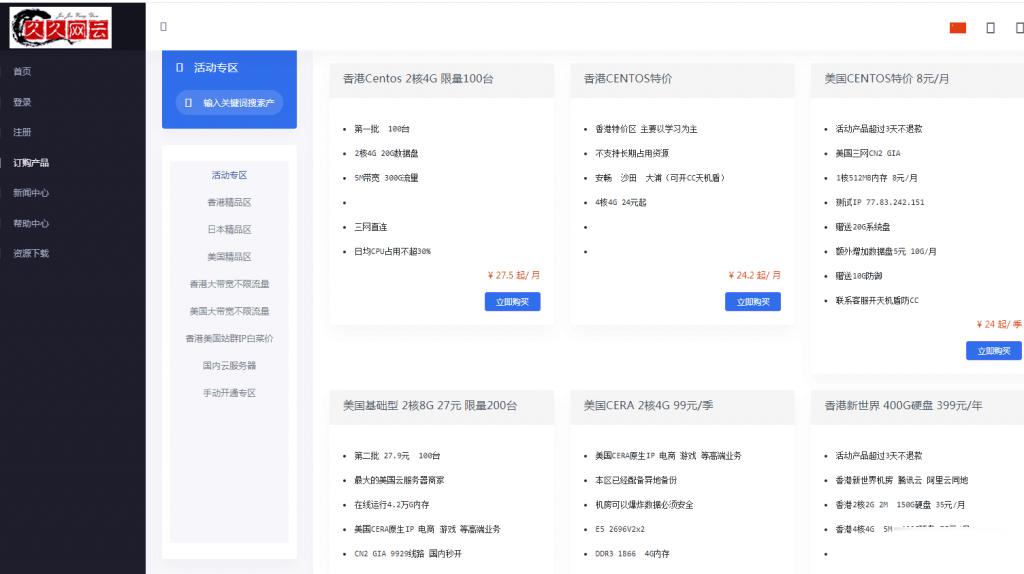
久久网云-目前最便宜的国内,香港,美国,日本VPS云服务器19.9元/月起,三网CN2,2天内不满意可以更换其他机房机器,IP免费更换!。
久久网云怎么样?久久网云好不好?久久网云是一家成立于2017年的主机服务商,致力于为用户提供高性价比稳定快速的主机托管服务,久久网云目前提供有美国免费主机、香港主机、韩国服务器、香港服务器、美国云服务器,香港荃湾CN2弹性云服务器。专注为个人开发者用户,中小型,大型企业用户提供一站式核心网络云端服务部署,促使用户云端部署化简为零,轻松快捷运用云计算!多年云计算领域服务经验,遍布亚太地区的海量节点为...
SugarHosts糖果主机,(67元/年)云服务器/虚拟主机低至半价
SugarHosts 糖果主机商也算是比较老牌的主机商,从2009年开始推出虚拟主机以来,目前当然还是以虚拟主机为主,也有新增云服务器和独立服务器。早年很多网友也比较争议他们家是不是国人商家,其实这些不是特别重要,我们很多国人商家或者国外商家主要还是看重的是品质和服务。一晃十二年过去,有看到SugarHosts糖果主机商12周年的促销活动。如果我们有需要香港、美国、德国虚拟主机的可以选择,他们家的...

-
腾讯无线腾讯全民wifi多少钱word2003公式编辑器word2003里的公式编辑器怎么用啊?网龙吧刘谦吧 百度贴吧java学习思维导图如何一步一步学习java 知乎安卓系统软件删除安卓手机怎么卸载已经安装的各类软件?人脸检测综述人脸检测方法创业好项目论坛我想创业,有没有什么好的项目,福州创业QQ群有吗?或者是创业论坛?云图好看吗云图这部电影好看吗慕课网址慕课网是什么?Costco茅台被抢光Costco在中国大陆第一家店开业首日被挤爆,为什么人们都特别青睐洋货?