函数apache启动失败
apache启动失败 时间:2021-01-11 阅读:()
ApacheSpark2.
4正式发布,重要功能详细介绍美国时间2018年11月08日正式发布了.
一如既往,为了继续实现Spark更快,更轻松,更智能的目标,Spark2.
4带来了许多新功能,如下:添加一种支持屏障模式(barriermode)的调度器,以便与基于MPI的程序更好地集成,例如,分布式深度学习框架;引入了许多内置的高阶函数,以便更容易处理复杂的数据类型(比如数组和map);开始支持Scala2.
12;允许我们对notebooks中的DataFrame进行热切求值(eagerevaluation),以便于调试和排除故障;引入新的内置Avro数据源.
如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop除了这些新功能外,该版本还重点关注可用性,稳定性和优化,解决了超过1000个tickets.
Spark贡献者的其他显着特征包括:消除2GB块大小的限制[SPARK-24296,SPARK-24307]提升PandasUDF[SPARK-22274,SPARK-22239,SPARK-24624]图片模式数据源(Imageschemadatasource)[SPARK-22666]SparkSQL加强[SPARK-23803,SPARK-4502,SPARK-24035,SPARK-24596,SPARK-19355]内置文件源改进[SPARK-23456,SPARK-24576,SPARK-25419,SPARK-23972,SPARK-19018,SPARK-24244]1/5Kubernetes整合加强[SPARK-23984,SPARK-23146]在这篇文章中,我们简要总结了一些更高级别的功能和改进.
有关Spark所有组件和JIRA已解决的主要功能的完整列表,请阅读ApacheSpark2.
4.
0releasenotes.
BarrierExecutionModeBarrierExecutionMode是ProjectHydrogen的一部分,这是ApacheSpark的一项计划,旨在将最先进的大数据和AI技术结合在一起.
它可以将来自AI框架的分布式训练作业正确地嵌入到Spark作业中.
我们通常会像All-Reduce这样来探讨复杂通信模式(complexcommunicationpatterns),因此所有的任务都需要同时运行.
这不符合Spark当前使用的MapReduce模式.
使用这种新的执行模式,Spark同时启动所有训练任务(例如,MPI任务),并在任务失败时重新启动所有任务.
Spark还为屏障(barriertasks)任务引入了一种新的容错机制.
当任何障碍任务在中间失败时,Spark将中止所有任务并重新启动当前stage.
内置高阶函数在Spark2.
4之前,为了直接操作复杂类型(例如数组类型),有两种典型的解决方案:将嵌套结构展开为多行,并应用某些函数,然后再次创建结构;编写用户自定义函数(UDF).
新的内置函数可以直接操作复杂类型,高阶函数可以使用匿名lambda函数直接操作复杂值,类似于UDF,但具有更好的性能.
比如以下两个高阶函数:SELECTarray_distinct(array(1,2,3,null,3));["1","2","3",null]SELECTarray_intersect(array(1,2,3),array(1,3,5));["1","3"]关于内置函数和高阶函数的进一步说明可以参见《ApacheSpark2.
4中解决复杂数据类型的内置函数和高阶函数介绍》和《ApacheSpark2.
4新增内置函数和高阶函数使用介绍》内置Avro数据源ApacheAvro是一种流行的数据序列化格式.
它广泛用于ApacheSpark和ApacheHadoop生态系统,尤其适用于基于Kafka的数据管道.
从ApacheSpark2.
4版本开始,Spark为读取和写入Avro数据提供内置支持.
新的内置spark-avro模块最初来自Databricks2/5的开源项目AvroDataSourceforApacheSpark.
除此之外,它还提供以下功能:新函数from_avro()和to_avro()用于在DataFrame中读取和写入Avro数据,而不仅仅是文件.
支持Avro逻辑类型(logicaltypes),包括Decimal,Timestamp和Date类型.
SparkSQL和Avro的数据类型之间的转换可以参见下面:SparkSQLtypeAvrotypeAvrologicaltypeByteTypeintShortTypeintBinaryTypebytesDateTypeintdateTimestampTypelongtimestamp-microsDecimalTypefixeddecimal2倍读取吞吐量提高和10%写入吞吐量提升.
支持Scala2.
12从Spark2.
4开始,Spark支持Scala2.
12,并分别与Scala2.
11和2.
12进行交叉构建,这两个版本都可以在Maven存储库和下载页面中使用.
现在,用户可以使用Scala2.
12来编写Spark应用程序.
Scala2.
12为Java8带来了更好的互操作性,Java8提供了改进的lambda函数序列化.
它还包括用户期望的新功能和错误修复.
PandasUDF提升PandasUDF是从Spark2.
3开始引入的.
在此版本中,社区收集了用户的反馈,并不断改进PandasUDF.
除了错误修复之外,Spark2.
4中还有2个新功能:SPARK-22239使用PandasUDF来用户自定义窗口函数.
SPARK-22274使用PandasUDF来用户自定义聚合函数.
我们相信这些新功能将进一步改善PandasUDF的使用,我们将在下一版本中不断改进PandasUDF.
ImageDataSource3/5社区从图像/视频/音频处理行业看到了更多案例.
为这些提供Spark内置数据源简化了用户将数据导入ML训练的工作.
在Spark2.
3版本中,图像数据源是通过ImageSchema.
readImages实现的.
Spark2.
4发行版中的SPARK-22666引入了一个新的Spark数据源,它可以作为DataFrame从目录中递归加载图像文件.
现在加载图像非常简单:df=spark.
read.
format("image").
load(".
.
.
")Kubernetes整合增强Spark2.
4包含许多Kubernetes集成的增强功能.
主要包括这三点:首先,此版本支持在Kubernetes上运行容器化PySpark和SparkR应用程序.
Spark为Dockerfiles提供了Python和R绑定,供用户构建基本映像或自定义它以构建自定义映像.
其次,提供了客户端模式.
用户可以在Kubernetes集群中运行的pod里面运行交互式工具(例如,shell或notebooks).
最后,支持挂载以下类型的Kubernetesvolumes:emptyDir,hostPath和persistentVolumeClaim.
灵活的StreamingSink许多外部存储系统已经有批量连接器(batchconnectors),但并非所有外部存储系统都有流式接收器(streamingsinks).
在此版本中,即使存储系统不支持将流式传输作为接收器(streamingasasink).
streamingDF.
writeStream.
foreachBatch(.
.
.
)允许我们在每个微批次(microbatch)的输出中使用batchdatawriters.
例如,过往记忆告诉你可以使用foreachBatch中现有的ApacheCassandra连接器直接将流式查询的输出写入到Cassandra.
具体如下:/***User:过往记忆*Date:2018-11-10*Time:10:24*bolg:https://www.
iteblog.
com*本文地址:https://www.
iteblog.
com/archives/2448*过往记忆博客,专注于Hadoop、Spark、HBase等大数据技术.
*过往记忆博客微信公共帐号:iteblog_hadoop*/streamingDF.
writeStream.
foreachBatch{(iteblogBatchDF:DataFrame,batchId:Long)=>4/5iteblogBatchDF.
write//UseCassandrabatchdatasourcetowritestreamingout.
cassandraFormat(tableName,keyspace).
option("cluster","iteblog_hadoop").
mode("append").
save()}同样,你也可以使用它将每个微批输出(micro-batchoutput)应用于streamingDataFrames中,许多DataFrame/Dataset操作在streamingDataFrames是不支持的,具体使用如下:streamingDF.
writeStream.
foreachBatch{(iteblogBatchDF:DataFrame,batchId:Long)=>iteblogBatchDF.
cache()iteblogBatchDF.
write.
format(.
.
.
).
save(location1iteblogBatchDF.
write.
format(.
.
.
).
save(location2iteblogBatchDF.
uncache()}本博客文章除特别声明,全部都是原创!
转载本文请加上:转载自过往记忆(https://www.
iteblog.
com/)本文链接:【】()PoweredbyTCPDF(www.
tcpdf.
org)5/5
4正式发布,重要功能详细介绍美国时间2018年11月08日正式发布了.
一如既往,为了继续实现Spark更快,更轻松,更智能的目标,Spark2.
4带来了许多新功能,如下:添加一种支持屏障模式(barriermode)的调度器,以便与基于MPI的程序更好地集成,例如,分布式深度学习框架;引入了许多内置的高阶函数,以便更容易处理复杂的数据类型(比如数组和map);开始支持Scala2.
12;允许我们对notebooks中的DataFrame进行热切求值(eagerevaluation),以便于调试和排除故障;引入新的内置Avro数据源.
如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop除了这些新功能外,该版本还重点关注可用性,稳定性和优化,解决了超过1000个tickets.
Spark贡献者的其他显着特征包括:消除2GB块大小的限制[SPARK-24296,SPARK-24307]提升PandasUDF[SPARK-22274,SPARK-22239,SPARK-24624]图片模式数据源(Imageschemadatasource)[SPARK-22666]SparkSQL加强[SPARK-23803,SPARK-4502,SPARK-24035,SPARK-24596,SPARK-19355]内置文件源改进[SPARK-23456,SPARK-24576,SPARK-25419,SPARK-23972,SPARK-19018,SPARK-24244]1/5Kubernetes整合加强[SPARK-23984,SPARK-23146]在这篇文章中,我们简要总结了一些更高级别的功能和改进.
有关Spark所有组件和JIRA已解决的主要功能的完整列表,请阅读ApacheSpark2.
4.
0releasenotes.
BarrierExecutionModeBarrierExecutionMode是ProjectHydrogen的一部分,这是ApacheSpark的一项计划,旨在将最先进的大数据和AI技术结合在一起.
它可以将来自AI框架的分布式训练作业正确地嵌入到Spark作业中.
我们通常会像All-Reduce这样来探讨复杂通信模式(complexcommunicationpatterns),因此所有的任务都需要同时运行.
这不符合Spark当前使用的MapReduce模式.
使用这种新的执行模式,Spark同时启动所有训练任务(例如,MPI任务),并在任务失败时重新启动所有任务.
Spark还为屏障(barriertasks)任务引入了一种新的容错机制.
当任何障碍任务在中间失败时,Spark将中止所有任务并重新启动当前stage.
内置高阶函数在Spark2.
4之前,为了直接操作复杂类型(例如数组类型),有两种典型的解决方案:将嵌套结构展开为多行,并应用某些函数,然后再次创建结构;编写用户自定义函数(UDF).
新的内置函数可以直接操作复杂类型,高阶函数可以使用匿名lambda函数直接操作复杂值,类似于UDF,但具有更好的性能.
比如以下两个高阶函数:SELECTarray_distinct(array(1,2,3,null,3));["1","2","3",null]SELECTarray_intersect(array(1,2,3),array(1,3,5));["1","3"]关于内置函数和高阶函数的进一步说明可以参见《ApacheSpark2.
4中解决复杂数据类型的内置函数和高阶函数介绍》和《ApacheSpark2.
4新增内置函数和高阶函数使用介绍》内置Avro数据源ApacheAvro是一种流行的数据序列化格式.
它广泛用于ApacheSpark和ApacheHadoop生态系统,尤其适用于基于Kafka的数据管道.
从ApacheSpark2.
4版本开始,Spark为读取和写入Avro数据提供内置支持.
新的内置spark-avro模块最初来自Databricks2/5的开源项目AvroDataSourceforApacheSpark.
除此之外,它还提供以下功能:新函数from_avro()和to_avro()用于在DataFrame中读取和写入Avro数据,而不仅仅是文件.
支持Avro逻辑类型(logicaltypes),包括Decimal,Timestamp和Date类型.
SparkSQL和Avro的数据类型之间的转换可以参见下面:SparkSQLtypeAvrotypeAvrologicaltypeByteTypeintShortTypeintBinaryTypebytesDateTypeintdateTimestampTypelongtimestamp-microsDecimalTypefixeddecimal2倍读取吞吐量提高和10%写入吞吐量提升.
支持Scala2.
12从Spark2.
4开始,Spark支持Scala2.
12,并分别与Scala2.
11和2.
12进行交叉构建,这两个版本都可以在Maven存储库和下载页面中使用.
现在,用户可以使用Scala2.
12来编写Spark应用程序.
Scala2.
12为Java8带来了更好的互操作性,Java8提供了改进的lambda函数序列化.
它还包括用户期望的新功能和错误修复.
PandasUDF提升PandasUDF是从Spark2.
3开始引入的.
在此版本中,社区收集了用户的反馈,并不断改进PandasUDF.
除了错误修复之外,Spark2.
4中还有2个新功能:SPARK-22239使用PandasUDF来用户自定义窗口函数.
SPARK-22274使用PandasUDF来用户自定义聚合函数.
我们相信这些新功能将进一步改善PandasUDF的使用,我们将在下一版本中不断改进PandasUDF.
ImageDataSource3/5社区从图像/视频/音频处理行业看到了更多案例.
为这些提供Spark内置数据源简化了用户将数据导入ML训练的工作.
在Spark2.
3版本中,图像数据源是通过ImageSchema.
readImages实现的.
Spark2.
4发行版中的SPARK-22666引入了一个新的Spark数据源,它可以作为DataFrame从目录中递归加载图像文件.
现在加载图像非常简单:df=spark.
read.
format("image").
load(".
.
.
")Kubernetes整合增强Spark2.
4包含许多Kubernetes集成的增强功能.
主要包括这三点:首先,此版本支持在Kubernetes上运行容器化PySpark和SparkR应用程序.
Spark为Dockerfiles提供了Python和R绑定,供用户构建基本映像或自定义它以构建自定义映像.
其次,提供了客户端模式.
用户可以在Kubernetes集群中运行的pod里面运行交互式工具(例如,shell或notebooks).
最后,支持挂载以下类型的Kubernetesvolumes:emptyDir,hostPath和persistentVolumeClaim.
灵活的StreamingSink许多外部存储系统已经有批量连接器(batchconnectors),但并非所有外部存储系统都有流式接收器(streamingsinks).
在此版本中,即使存储系统不支持将流式传输作为接收器(streamingasasink).
streamingDF.
writeStream.
foreachBatch(.
.
.
)允许我们在每个微批次(microbatch)的输出中使用batchdatawriters.
例如,过往记忆告诉你可以使用foreachBatch中现有的ApacheCassandra连接器直接将流式查询的输出写入到Cassandra.
具体如下:/***User:过往记忆*Date:2018-11-10*Time:10:24*bolg:https://www.
iteblog.
com*本文地址:https://www.
iteblog.
com/archives/2448*过往记忆博客,专注于Hadoop、Spark、HBase等大数据技术.
*过往记忆博客微信公共帐号:iteblog_hadoop*/streamingDF.
writeStream.
foreachBatch{(iteblogBatchDF:DataFrame,batchId:Long)=>4/5iteblogBatchDF.
write//UseCassandrabatchdatasourcetowritestreamingout.
cassandraFormat(tableName,keyspace).
option("cluster","iteblog_hadoop").
mode("append").
save()}同样,你也可以使用它将每个微批输出(micro-batchoutput)应用于streamingDataFrames中,许多DataFrame/Dataset操作在streamingDataFrames是不支持的,具体使用如下:streamingDF.
writeStream.
foreachBatch{(iteblogBatchDF:DataFrame,batchId:Long)=>iteblogBatchDF.
cache()iteblogBatchDF.
write.
format(.
.
.
).
save(location1iteblogBatchDF.
write.
format(.
.
.
).
save(location2iteblogBatchDF.
uncache()}本博客文章除特别声明,全部都是原创!
转载本文请加上:转载自过往记忆(https://www.
iteblog.
com/)本文链接:【】()PoweredbyTCPDF(www.
tcpdf.
org)5/5
- 函数apache启动失败相关文档
- 打印服务器apache启动失败
- 安装apache启动失败
- 数据apache启动失败
- discuz!论坛的建立——配置apache及论坛程序的安装
- 录音apache启动失败
- 文件apache启动失败
免费注册宝塔面板账户赠送价值3188礼包适合购买抵扣折扣
对于一般的用户来说,我们使用宝塔面板免费版本功能还是足够的,如果我们有需要付费插件和专业版的功能,且需要的插件比较多,实际上且长期使用的话,还是购买付费专业版或者企业版本划算一些。昨天也有在文章中分享年中促销活动。如今我们是否会发现,我们在安装宝塔面板后是必须强制我们登录账户的,否则一直有弹出登录界面,我们还是注册一个账户比较好。反正免费注册宝塔账户还有代金券赠送。 新注册宝塔账户送代金券我们注册...
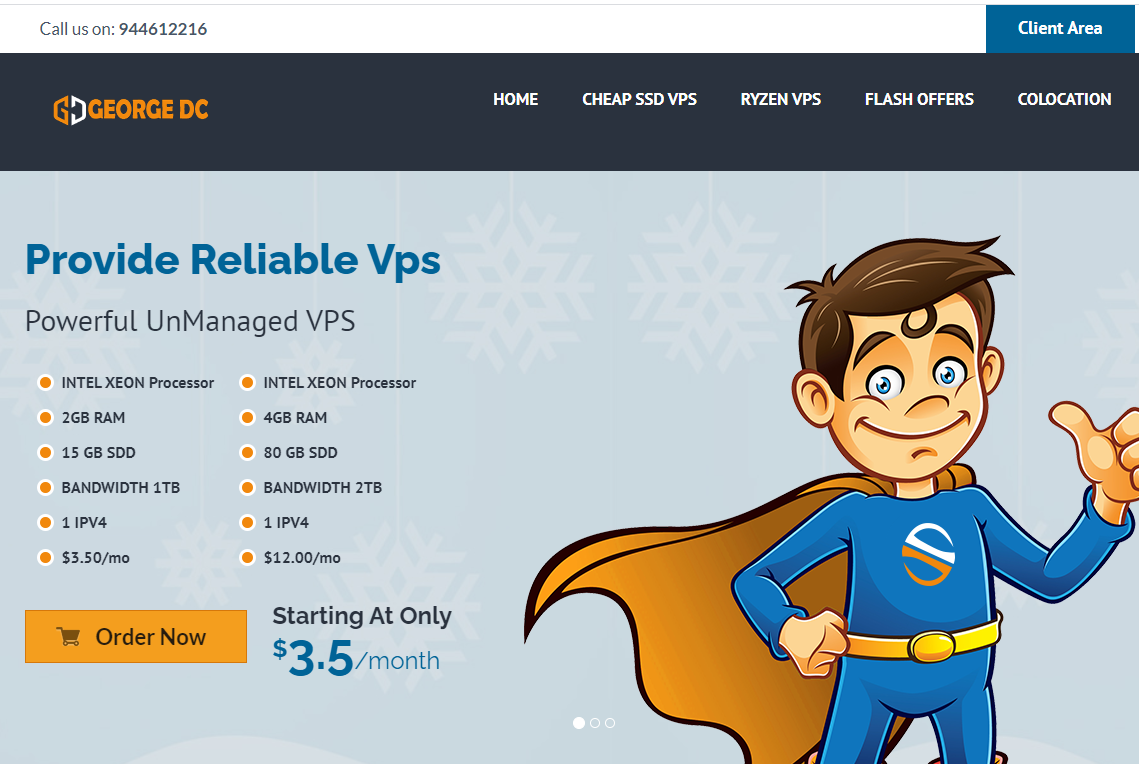
georgedatacenter39美元/月$20/年/洛杉矶独立服务器美国VPS/可选洛杉矶/芝加哥/纽约/达拉斯机房/
georgedatacenter这次其实是两个促销,一是促销一款特价洛杉矶E3-1220 V5独服,性价比其实最高;另外还促销三款特价vps,georgedatacenter是一家成立于2019年的美国VPS商家,主营美国洛杉矶、芝加哥、达拉斯、新泽西、西雅图机房的VPS、邮件服务器和托管独立服务器业务。georgedatacenter的VPS采用KVM和VMware虚拟化,可以选择windows...
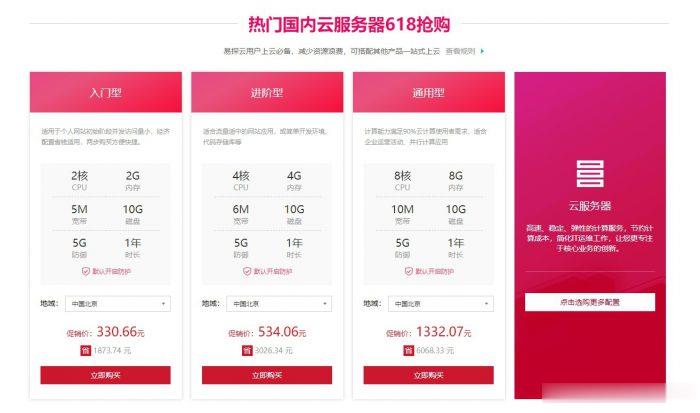
易探云2核2G5M仅330元/年起,国内挂机宝云服务器,独立ip
易探云怎么样?易探云是国内一家云计算服务商家,致力香港服务器、国内外服务器租用及托管等互联网业务,目前主要地区为运作香港BGP、香港CN2、广东、北京、深圳等地区。目前,易探云推出深圳或北京地区的适合挂机和建站的云服务器,国内挂机宝云服务器(可选深圳或北京地区),独立ip;2核2G5M挂机云服务器仅330元/年起!点击进入:易探云官方网站地址易探云国内挂机宝云服务器推荐:1、国内入门型挂机云服务器...
apache启动失败为你推荐
-
美国vps服务器便宜的国外vps都有哪些,能否推荐几个??域名注册公司公司域名注册在哪个网站上注册好网站域名注册怎么做网站?怎么注册域名?网络服务器租用现在网站服务器租赁一年多少钱?网站域名各种网站的域名域名服务商最好的域名服务商是哪一家ip代理地址ip代理有什么用?有图片..ip代理地址代理ip地址是怎么来的?云服务器租用云服务器租用费用是多少深圳网站空间求免费稳定空间网站?