抽取网址构建器
网址构建器 时间:2021-05-13 阅读:()
54基于网页结构树的Web信息抽取方法陈琼苏文健华南理工大学计算机科学与工程学院广州510640摘要提出了网页结构树提取算法及基于网页结构树的Web信息抽取方法抽取信息时在网页结构树中定位模式库中的待抽取信息用模式库中的待抽取信息和网页结构树的叶结点对应的网页信息进行匹配因而对网页信息的抽取可以转化为对网页结构树的树叶结点信息的查找实验证明该方法具有较强的网页信息抽取能力关键词信息抽取半结构网页结构树模式WebInformationExtractionBasedonWebStructureTreeCHENQiong,SUWenjian(SchoolofComputerScienceandEngineering,SouthChinaUniversityofTechnology,Guangzhou510640)AbstractThispaperproposesanalgorithmthatisusedtoconstructtheWebstructuretreeandaWebinformationextractionmethodbasedonWebpagestructuretree.
Whileextractinginformation,itlocatestheinformationthatshouldbeextractedintheWebpagestructuretreeandmatchesthepatterninformationwiththeterminalinformationinWebpagestructuretree.
TheWebinformationextractionistheterminalinformationextractioninWebpagestructuretree.
ThismethodcanefficientlyextractinformationfromWebpages.
KeywordsInformationextraction;Semi-structure;Webpagestructuretree;Pattern计算机工程ComputerEngineering第31卷第20期Vol.
31202005年10月October2005基金项目论文文章编号10003428(2005)20005402文献标识码A中图分类号TP301.
6网页信息抽取技术包括基于归纳学习的信息抽取基于HTML结构解析的信息抽取基于Web查询的信息抽取基于自然语言处理的信息抽取基于模型的信息抽取和基于本体的信息抽取[1]其中基于HTML结构解析的信息抽取的特点是将Web文档转换成反映HTML文件层次结构的解析树通过自动或半自动的方式产生抽取规则典型的系统有W4F[2]RoadRunner[3]XWRAP[4]等本文提出的基于网页结构树的Web信息抽取方法利用网页结构树提取算法构造网页结构树使得页结点包含网页内容信息抽取信息时在网页结构树中定位模式库中的待抽取信息用模式库中的待抽取信息和网页结构树的叶结点对应的网页信息进行匹配因而对网页信息的抽取可以转化为对网页结构树的树叶结点信息的查找1网页结构树的构造1.
1HTML文档特点目前Web上的数据大部分是以HTML的形式出现的HTML文档由标记(TAG)和元素组成HTML标记确定了浏览器所显示文档元素的格式大多数HTML标记是成对出现的它们分别用作开始标记和结束标记HTML的结束标记与开始标记的唯一区别是多了个斜杠/HTML标记放在尖括号里如是位于HTML文档中的第一个条目HTML文档由标题和主体两部分组成标题部分包含文档的标题主题部分包含文档的内容为标明HTML文档标题部分的起始和结束可以使用标记和同样可以使用标记和标明文档主体部分的开始和结束和用于显示WEB页面的标题是表格起始和结束标记是表头起始和结束标记是表行起始和结束标记是表格内容起始和结束标记等1.
2网页结构树的构造算法利用HTML的TAG的特征采用标记匹配和回溯相结合的方法构造Web文档结构树大多数HTML标记是成对出现的在起始标记和结束标记之间包括网页描述属性信息和网页内容信息如型号在起始标记和结束标记之间的width="33%">是属性信息型号是网页内容信息在构造网页文档结构树时忽略属性描述信息因此只需对部分TAG标记进行分析如果主要是对表格内容的抽取则需要考虑的HTML标记主要有,,,,,,,,,,,,对于其它的HTML标记可视为无用HTML标记在程序处理中将忽略对这些标记的处理网页文档结构树的每个结点对应一个Tag标记因此构建TagNode树的前提条件是正确地读取标记分析开始标记结束标记和没有得到匹配的标记结点对应的Tag开始与结束标记之间的内容存在TagNode类成员data中网页结构树构造算法TagNode如下如果读取的文件没有到文件尾作以下操作如果获取标记成功基金项目国家自然科学基金资助项目60003019广东省自然科学基金资助项目990582广东省科技攻关资助项目项目C10201作者简介陈琼1966女副教授主研方向机器学习智能信息计算苏文健硕士生收稿日期2004-10-04E-mailqiongchen66@yahoo.
comhttp://www.
paper.
edu.
cn中国科技论文在线55如果为开始标记且根结点为空创建根结点使当前结点为根结点如果为开始标记且根结点不为空如果获取的标记为"img"根据获取标记创建新结点使之成为当前结点的儿子标记该新创建的结点为匹配结点如果获取的标记和当前结点不同根据获取标记创建新结点使之成为当前结点的儿子使新创建的结点为当前结点获取当前结点的内容如果获取的标记和当前结点相同根据获取标记创建新结点使之成为当前结点的儿子标记当前结点为匹配结点并使新创建的结点为当前结点获取当前结点的内容如果为结束标记如果为当前结点标记的匹配结束标记标记该结点为匹配结点使当前结点为其父结点如果没有找到和该结束标记匹配的结点作以下操作回溯到当前结点的第一个未匹配的前辈结点如果是和结束标记匹配的结点标记该前辈结点为匹配结点使其父结点为当前结点通过输入一个网页例如图1所示的网页图1输入网页TagNode算法可以自动地对网页结构进行分析构造其TagNode树如图2所示图2网页结构树部分图2只是网页结构树的一部分网页的内容信息都对应在树结点上叶结点对应网页的最小内容信息单元TagNode算法构建的网页结构树虽然没有反映网页的全部信息但通过网页结构树用户可以了解网页的结构还可以查看网页中他们感兴趣的信息从而对网页进行信息抽取2网页信息的抽取2.
1网页信息抽取算法利用TagNode算法构造的网页结构树可以把网页信息的抽取映射为在网页结构树中信息的查找这里设计了抽取手机信息的网页信息抽取器通过对不同网站的手机信息网页的分析发现具有这样的规律要抽取的手机型号和手机价格通常在同一个table中并且手机型号和手机价格间存在一对一或一对多的关系因而可采用如下启发式规则进行网页信息抽取启发式规则为待抽取的信息的各部分通常在同一个table中并且它们之间存在一对一或一对多的关系在进行信息抽取前首先建立模式库模式库包含待抽取信息的表述特征项等抽取信息时在网页结构树中定位模式库中的待抽取信息用模式库中的待抽取信息和网页结构树的叶结点对应的网页信息进行匹配如果匹配成功则找到了一部分要抽取的信息利用上述启发式规则其他待抽取信息对应的结点和这个已匹配的叶结点在同一个table中因此模式库中的待抽取信息或特征项只需和已匹配的树叶结点的兄弟结点对应的网页信息比较通常就可匹配成功完成信息的抽取网页信息抽取算法如下如果要处理的网页结构树结点的儿子为NULL及该结点标记的字符串的前两个字符为td"如果dataKind的值为UnKnown或Cost根据学习的模式修改regularText匹配待抽取信息如果匹配成功matchString记录下匹配的信息找出含匹配信息的结点所在的最底层的table父结点matchLocation赋值为对该table父结点的引用dataKind赋值为Kind如果dataKind的值为Kind匹配其他待抽取信息如果匹配成功如果含有匹配信息的结点所处的最底层的table父结点与matchLocation相同抽取信息并存入数据库此算法中要注意几个全局变量的意义dataKind记录抽取数据时的当前数据类型matchLocation用于指示抽取数据时所抽取树结点所处于的最底层的"table"父结点matchString用于存储抽取数据时所抽取的信息regularText用于抽取手机数据的正则表达式字符串2.
2抽取器模式学习算法通过使用网页信息抽取器可以对输入的网页进行信息抽取固定不变的模式库将限制网页信息抽取器的灵活性抽取器必须具有学习能力能够通过不断地学习去抽取模式丰富模式才能抽取更多的信息具有更广泛的用途考虑到模式学习的需要设计了人工学习和自动学习的两种方式补充和丰富网页信息抽取器的模式库从而提高抽取器的灵活性(下转第140页)140关并进行了对比测试有4组数据(1)IPv4局域网中两台IPv4主机直接通信表示为v4-v4(2)IPv6局域网中两台IPv6主机直接通信表示为v6-v6(3)IPv4局中两台IPv4主机通过Windows2000中的路由转发功能进行通信表示为转发(4)一台IPv6主机和一台IPv4主机通过转换网关进行通信表示为网关3.
1时延测试时延测试使用Ping命令实现Ping包的大小为1024B然后取100个Ping包的平均时延测试结果如图3所示从图中可以看出转换网关的时延只比Windows2000的路由转发多花了大约25ms表明转换网关的时延是非常低的图3时延测试3.
2带宽测试图4带宽测试带宽测试使用ttcpw程序分别在10Mbps和100Mbps网络中发送100MB数据测试的结果如图4所示从图4中可以看出对于10Mbps网络4种测试环境的的带宽基本是一样的对100Mbps网络转换网关和路由转发的带宽都有一定的下降但还是能包达到9000kbps比较转换网关和路由转发的带宽转换网关的带宽略有下降大约为50kbps3.
3应用程序测试我们对转换网关进行了FTP协议HTTP协议Telnet协议和DNS的测试转换网关顺利地通过了这些测试并取得了良好的测试效果4结论本文提出了一个基于Windows操作系统的全功能转换网关架构并进行了代码实现然后对转换网关进行了时延带宽和应用程序测试取得了满意的测试结果表明这是一个优秀的转换网关解决方案本系统虽然是基于Windows操作系统提出的但对其他的系统也具有很大的借鉴意义参考文献1SrisureshT,EgevangK.
TraditionalIPNetworkAddressTranslator(TraditionalNAT)[S].
RFC3022,1995-122MordmarkE.
StatelessIP/ICMPTranslationAlgorithm(SIIT)[S].
RFC2765,2001-013TsirtsisG,SrisureshT.
NetworkAddressTranslation—ProtocolTranslation(NAT-PT)[S].
RFC2766,2000-024ThomsonS,HuitemaC.
DNSExtensionstoSupportIPVersion6[S].
RFC1886,2000-025SrisureshT,TsirtsisG.
DNSExtensionstoNetworkAddressTranslators(DNS_ALG)[S].
RFC2694,1999-096美国微软公司.
Windows2000驱动程序开发大全(第1卷设计指南)[M].
北京:机械工业出版社,2001-08(上接第55页)(1)人工方式打开一个网页后用户尝试抽取网页中的信息但是用户需要的模式并不存在此时用户可以选择要抽取的信息并把它添加到模式库中这样日后用户再碰到同类的信息后网页信息抽取器就可以实现对该类信息的自动抽取可以采用选中网页结构树中的某个结点或选择文本框的字符加入模式库(2)自动方式当用户需要的模式不存在的时候用户可以输入大量的样本网页让抽取器进行学习通过对大量网页样例的学习把原来模式中没有的待抽取信息表述通过学习而添加到模式字符串中这样抽取器就可以通过不断的学习而抽取不同的网页了3结果分析及未来的工作使用网页信息抽取器对十多个手机网站的网页进行分析网页信息抽取器能够为每个网页构造结构树对于特定网站的所有具有相似结构的网页信息都可以正确抽取对于不同结构的网页通过模式学习可以正确抽取用户感兴趣的的信息这里的网页结构树构造算法主要处理的是表格标记可以推广到处理LiOlUlHx等标记考虑属性信息可以构造更全面反映网页结构及特征的网页结构树另外通过模式的学习本网页信息抽取器的应用领域可以推广到其他领域对于其它领域的信息通过模式的学习可以把领域知识存入模式库从而使信息抽取器具有更强的灵活性参考文献1LaenderHF,Ribeiro-NetoBA,ASdaSilva,etal.
ABriefSurveyofWebDataExtractionTools.
SIGMODRecord,2002,31(2):84-932SahuguetA,AzavanF.
BuildingIntelligentWebApplicationsUsingLightweightWrappers.
DataandKnowledgeEngineering,2001,36(3),283-3163CrescenziV,MeccaG,MerialdoP.
RoadRunner:TowardsAutomaticDataExtractionfromLargeWebSites.
Rome,Italy:In:Proceedingofthe26thInternationalConferenceonVeryLargeDatabaseSystems,2001:109-1184LiuL,PuC,HanW.
XWRAP:AnXML-enableWrapperConstructionSystemforWebInformationSources.
SanDiego,California:In:Proceedingsofthe16thIEEEInternationalConferenceonDataEngineering,2000:611-6215李晶陈恩红.
Web信息抽取.
计算机科学,2003,30(6):78-81020040060080010001200v4-v4v6-v6转发网关时延(ms)020004000600080001000012000v4-v4v6-v6转发网关速度(kbps)10M100M
Whileextractinginformation,itlocatestheinformationthatshouldbeextractedintheWebpagestructuretreeandmatchesthepatterninformationwiththeterminalinformationinWebpagestructuretree.
TheWebinformationextractionistheterminalinformationextractioninWebpagestructuretree.
ThismethodcanefficientlyextractinformationfromWebpages.
KeywordsInformationextraction;Semi-structure;Webpagestructuretree;Pattern计算机工程ComputerEngineering第31卷第20期Vol.
31202005年10月October2005基金项目论文文章编号10003428(2005)20005402文献标识码A中图分类号TP301.
6网页信息抽取技术包括基于归纳学习的信息抽取基于HTML结构解析的信息抽取基于Web查询的信息抽取基于自然语言处理的信息抽取基于模型的信息抽取和基于本体的信息抽取[1]其中基于HTML结构解析的信息抽取的特点是将Web文档转换成反映HTML文件层次结构的解析树通过自动或半自动的方式产生抽取规则典型的系统有W4F[2]RoadRunner[3]XWRAP[4]等本文提出的基于网页结构树的Web信息抽取方法利用网页结构树提取算法构造网页结构树使得页结点包含网页内容信息抽取信息时在网页结构树中定位模式库中的待抽取信息用模式库中的待抽取信息和网页结构树的叶结点对应的网页信息进行匹配因而对网页信息的抽取可以转化为对网页结构树的树叶结点信息的查找1网页结构树的构造1.
1HTML文档特点目前Web上的数据大部分是以HTML的形式出现的HTML文档由标记(TAG)和元素组成HTML标记确定了浏览器所显示文档元素的格式大多数HTML标记是成对出现的它们分别用作开始标记和结束标记HTML的结束标记与开始标记的唯一区别是多了个斜杠/HTML标记放在尖括号里如是位于HTML文档中的第一个条目HTML文档由标题和主体两部分组成标题部分包含文档的标题主题部分包含文档的内容为标明HTML文档标题部分的起始和结束可以使用标记和同样可以使用标记和标明文档主体部分的开始和结束和用于显示WEB页面的标题是表格起始和结束标记是表头起始和结束标记是表行起始和结束标记是表格内容起始和结束标记等1.
2网页结构树的构造算法利用HTML的TAG的特征采用标记匹配和回溯相结合的方法构造Web文档结构树大多数HTML标记是成对出现的在起始标记和结束标记之间包括网页描述属性信息和网页内容信息如型号在起始标记和结束标记之间的width="33%">是属性信息型号是网页内容信息在构造网页文档结构树时忽略属性描述信息因此只需对部分TAG标记进行分析如果主要是对表格内容的抽取则需要考虑的HTML标记主要有,,,,,,,,,,,,对于其它的HTML标记可视为无用HTML标记在程序处理中将忽略对这些标记的处理网页文档结构树的每个结点对应一个Tag标记因此构建TagNode树的前提条件是正确地读取标记分析开始标记结束标记和没有得到匹配的标记结点对应的Tag开始与结束标记之间的内容存在TagNode类成员data中网页结构树构造算法TagNode如下如果读取的文件没有到文件尾作以下操作如果获取标记成功基金项目国家自然科学基金资助项目60003019广东省自然科学基金资助项目990582广东省科技攻关资助项目项目C10201作者简介陈琼1966女副教授主研方向机器学习智能信息计算苏文健硕士生收稿日期2004-10-04E-mailqiongchen66@yahoo.
comhttp://www.
paper.
edu.
cn中国科技论文在线55如果为开始标记且根结点为空创建根结点使当前结点为根结点如果为开始标记且根结点不为空如果获取的标记为"img"根据获取标记创建新结点使之成为当前结点的儿子标记该新创建的结点为匹配结点如果获取的标记和当前结点不同根据获取标记创建新结点使之成为当前结点的儿子使新创建的结点为当前结点获取当前结点的内容如果获取的标记和当前结点相同根据获取标记创建新结点使之成为当前结点的儿子标记当前结点为匹配结点并使新创建的结点为当前结点获取当前结点的内容如果为结束标记如果为当前结点标记的匹配结束标记标记该结点为匹配结点使当前结点为其父结点如果没有找到和该结束标记匹配的结点作以下操作回溯到当前结点的第一个未匹配的前辈结点如果是和结束标记匹配的结点标记该前辈结点为匹配结点使其父结点为当前结点通过输入一个网页例如图1所示的网页图1输入网页TagNode算法可以自动地对网页结构进行分析构造其TagNode树如图2所示图2网页结构树部分图2只是网页结构树的一部分网页的内容信息都对应在树结点上叶结点对应网页的最小内容信息单元TagNode算法构建的网页结构树虽然没有反映网页的全部信息但通过网页结构树用户可以了解网页的结构还可以查看网页中他们感兴趣的信息从而对网页进行信息抽取2网页信息的抽取2.
1网页信息抽取算法利用TagNode算法构造的网页结构树可以把网页信息的抽取映射为在网页结构树中信息的查找这里设计了抽取手机信息的网页信息抽取器通过对不同网站的手机信息网页的分析发现具有这样的规律要抽取的手机型号和手机价格通常在同一个table中并且手机型号和手机价格间存在一对一或一对多的关系因而可采用如下启发式规则进行网页信息抽取启发式规则为待抽取的信息的各部分通常在同一个table中并且它们之间存在一对一或一对多的关系在进行信息抽取前首先建立模式库模式库包含待抽取信息的表述特征项等抽取信息时在网页结构树中定位模式库中的待抽取信息用模式库中的待抽取信息和网页结构树的叶结点对应的网页信息进行匹配如果匹配成功则找到了一部分要抽取的信息利用上述启发式规则其他待抽取信息对应的结点和这个已匹配的叶结点在同一个table中因此模式库中的待抽取信息或特征项只需和已匹配的树叶结点的兄弟结点对应的网页信息比较通常就可匹配成功完成信息的抽取网页信息抽取算法如下如果要处理的网页结构树结点的儿子为NULL及该结点标记的字符串的前两个字符为td"如果dataKind的值为UnKnown或Cost根据学习的模式修改regularText匹配待抽取信息如果匹配成功matchString记录下匹配的信息找出含匹配信息的结点所在的最底层的table父结点matchLocation赋值为对该table父结点的引用dataKind赋值为Kind如果dataKind的值为Kind匹配其他待抽取信息如果匹配成功如果含有匹配信息的结点所处的最底层的table父结点与matchLocation相同抽取信息并存入数据库此算法中要注意几个全局变量的意义dataKind记录抽取数据时的当前数据类型matchLocation用于指示抽取数据时所抽取树结点所处于的最底层的"table"父结点matchString用于存储抽取数据时所抽取的信息regularText用于抽取手机数据的正则表达式字符串2.
2抽取器模式学习算法通过使用网页信息抽取器可以对输入的网页进行信息抽取固定不变的模式库将限制网页信息抽取器的灵活性抽取器必须具有学习能力能够通过不断地学习去抽取模式丰富模式才能抽取更多的信息具有更广泛的用途考虑到模式学习的需要设计了人工学习和自动学习的两种方式补充和丰富网页信息抽取器的模式库从而提高抽取器的灵活性(下转第140页)140关并进行了对比测试有4组数据(1)IPv4局域网中两台IPv4主机直接通信表示为v4-v4(2)IPv6局域网中两台IPv6主机直接通信表示为v6-v6(3)IPv4局中两台IPv4主机通过Windows2000中的路由转发功能进行通信表示为转发(4)一台IPv6主机和一台IPv4主机通过转换网关进行通信表示为网关3.
1时延测试时延测试使用Ping命令实现Ping包的大小为1024B然后取100个Ping包的平均时延测试结果如图3所示从图中可以看出转换网关的时延只比Windows2000的路由转发多花了大约25ms表明转换网关的时延是非常低的图3时延测试3.
2带宽测试图4带宽测试带宽测试使用ttcpw程序分别在10Mbps和100Mbps网络中发送100MB数据测试的结果如图4所示从图4中可以看出对于10Mbps网络4种测试环境的的带宽基本是一样的对100Mbps网络转换网关和路由转发的带宽都有一定的下降但还是能包达到9000kbps比较转换网关和路由转发的带宽转换网关的带宽略有下降大约为50kbps3.
3应用程序测试我们对转换网关进行了FTP协议HTTP协议Telnet协议和DNS的测试转换网关顺利地通过了这些测试并取得了良好的测试效果4结论本文提出了一个基于Windows操作系统的全功能转换网关架构并进行了代码实现然后对转换网关进行了时延带宽和应用程序测试取得了满意的测试结果表明这是一个优秀的转换网关解决方案本系统虽然是基于Windows操作系统提出的但对其他的系统也具有很大的借鉴意义参考文献1SrisureshT,EgevangK.
TraditionalIPNetworkAddressTranslator(TraditionalNAT)[S].
RFC3022,1995-122MordmarkE.
StatelessIP/ICMPTranslationAlgorithm(SIIT)[S].
RFC2765,2001-013TsirtsisG,SrisureshT.
NetworkAddressTranslation—ProtocolTranslation(NAT-PT)[S].
RFC2766,2000-024ThomsonS,HuitemaC.
DNSExtensionstoSupportIPVersion6[S].
RFC1886,2000-025SrisureshT,TsirtsisG.
DNSExtensionstoNetworkAddressTranslators(DNS_ALG)[S].
RFC2694,1999-096美国微软公司.
Windows2000驱动程序开发大全(第1卷设计指南)[M].
北京:机械工业出版社,2001-08(上接第55页)(1)人工方式打开一个网页后用户尝试抽取网页中的信息但是用户需要的模式并不存在此时用户可以选择要抽取的信息并把它添加到模式库中这样日后用户再碰到同类的信息后网页信息抽取器就可以实现对该类信息的自动抽取可以采用选中网页结构树中的某个结点或选择文本框的字符加入模式库(2)自动方式当用户需要的模式不存在的时候用户可以输入大量的样本网页让抽取器进行学习通过对大量网页样例的学习把原来模式中没有的待抽取信息表述通过学习而添加到模式字符串中这样抽取器就可以通过不断的学习而抽取不同的网页了3结果分析及未来的工作使用网页信息抽取器对十多个手机网站的网页进行分析网页信息抽取器能够为每个网页构造结构树对于特定网站的所有具有相似结构的网页信息都可以正确抽取对于不同结构的网页通过模式学习可以正确抽取用户感兴趣的的信息这里的网页结构树构造算法主要处理的是表格标记可以推广到处理LiOlUlHx等标记考虑属性信息可以构造更全面反映网页结构及特征的网页结构树另外通过模式的学习本网页信息抽取器的应用领域可以推广到其他领域对于其它领域的信息通过模式的学习可以把领域知识存入模式库从而使信息抽取器具有更强的灵活性参考文献1LaenderHF,Ribeiro-NetoBA,ASdaSilva,etal.
ABriefSurveyofWebDataExtractionTools.
SIGMODRecord,2002,31(2):84-932SahuguetA,AzavanF.
BuildingIntelligentWebApplicationsUsingLightweightWrappers.
DataandKnowledgeEngineering,2001,36(3),283-3163CrescenziV,MeccaG,MerialdoP.
RoadRunner:TowardsAutomaticDataExtractionfromLargeWebSites.
Rome,Italy:In:Proceedingofthe26thInternationalConferenceonVeryLargeDatabaseSystems,2001:109-1184LiuL,PuC,HanW.
XWRAP:AnXML-enableWrapperConstructionSystemforWebInformationSources.
SanDiego,California:In:Proceedingsofthe16thIEEEInternationalConferenceonDataEngineering,2000:611-6215李晶陈恩红.
Web信息抽取.
计算机科学,2003,30(6):78-81020040060080010001200v4-v4v6-v6转发网关时延(ms)020004000600080001000012000v4-v4v6-v6转发网关速度(kbps)10M100M
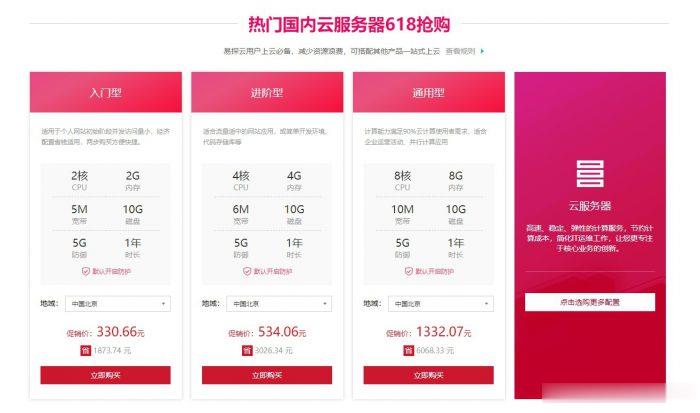
易探云2核2G5M仅330元/年起,国内挂机宝云服务器,独立ip
易探云怎么样?易探云是国内一家云计算服务商家,致力香港服务器、国内外服务器租用及托管等互联网业务,目前主要地区为运作香港BGP、香港CN2、广东、北京、深圳等地区。目前,易探云推出深圳或北京地区的适合挂机和建站的云服务器,国内挂机宝云服务器(可选深圳或北京地区),独立ip;2核2G5M挂机云服务器仅330元/年起!点击进入:易探云官方网站地址易探云国内挂机宝云服务器推荐:1、国内入门型挂机云服务器...
DiyVM:香港VPS五折月付50元起,2核/2G内存/50G硬盘/2M带宽/CN2线路
diyvm怎么样?diyvm这是一家低调国人VPS主机商,成立于2009年,提供的产品包括VPS主机和独立服务器租用等,数据中心包括香港沙田、美国洛杉矶、日本大阪等,VPS主机基于XEN架构,均为国内直连线路,主机支持异地备份与自定义镜像,可提供内网IP。最近,DiyVM商家对香港机房VPS提供5折优惠码,最低2GB内存起优惠后仅需50元/月。点击进入:diyvm官方网站地址DiyVM香港机房CN...

Digital-vm80美元,1-10Gbps带宽日本/新加坡独立服务器
Digital-vm是一家成立于2019年的国外主机商,商家提供VPS和独立服务器租用业务,其中VPS基于KVM架构,提供1-10Gbps带宽,数据中心可选包括美国洛杉矶、日本、新加坡、挪威、西班牙、丹麦、荷兰、英国等8个地区机房;除了VPS主机外,商家还提供日本、新加坡独立服务器,同样可选1-10Gbps带宽,最低每月仅80美元起。下面列出两款独立服务器配置信息。配置一 $80/月CPU:E3-...

网址构建器为你推荐
-
支持ipadwin10445端口win的22端口和23端口作用分别是什么 ?itunes备份itunes 里面的资料如何备份?win7如何关闭445端口如何彻底永久取消win7粘滞键功能联通iphone4联通iphone4好用吗micromediamacromedia的中文名迅雷雷鸟100+怒放手机是迅雷做的么?迅雷之前不是出了一款雷鸟手机么?chrome18谷歌浏览器,你正在用哪个版本呢??android5.1安卓系统5.1好吗winrar5.0win7 64位在运行winrar安装程序时,提示winrar停止工作。