攻击拒绝服务攻击
拒绝服务攻击 时间:2021-05-08 阅读:()
软件学报ISSN1000-9825,CODENRUXUEWE-mail:jos@iscas.
ac.
cnJournalofSoftware,2011,22(10):24252437[doi:10.
3724/SP.
J.
1001.
2011.
03882]http://www.
jos.
org.
cn中国科学院软件研究所版权所有.
Tel/Fax:+86-10-62562563随机伪造源地址分布式拒绝服务攻击过滤肖军1,2+,云晓春1,张永铮11(中国科学院计算技术研究所,北京100190)2(中国科学院研究生院,北京100049)RandomSpoofedSourceAddressDistributedDenial-of-ServiceAttackTrafficFilterXIAOJun1,2+,YUNXiao-Chun1,ZHANGYong-Zheng11(InstituteofComputingTechnology,TheChineseAcademyofSciences,Beijing100190,China)2(GraduateUniversity,TheChineseAcademyofSciences,Beijing100049,China)+Correspondingauthor:E-mail:xiaojun@software.
ict.
ac.
cnXiaoJ,YunXC,ZhangYZ.
Randomspoofedsourceaddressdistributeddenial-of-serviceattacktrafficfilter.
JournalofSoftware,2011,22(10):24252437.
http://www.
jos.
org.
cn/1000-9825/3882.
htmAbstract:DistributedDenial-of-Service(DDoS)attack,usingrandomspoofedsourceaddresses,ispopularbecauseitcanprotecttheattacker'sanonymity.
Itisverydifficulttodefentagainstthisattackbecauseitisveryhardtodifferentiatebadtrafficfromthenormal.
Inthispaper,basedonthesourceaddressesdistributionstatisticalfeature,aneffectivedefensescheme,whichcandifferentiatevicioustrafficfromnormaltraffic,ispresented.
BasedonanovelExtendedCountingBloomFilter(ECBF)datastructure,thispaperproposesanalgorithmtoidentifynormaladdressesaccurately.
Onceanormaladdressissoughtout,packetsfromitwillbeforwardedwithhighpriority,thus,normaltrafficisprotected.
Thesimulationresultsshowthatthisschemecanidentifylegitimateaddressesaccurately,protectlegitimatetrafficeffectively,andgivebetterprotectiontovaluablelongflows.
BecausethetimecomplexityofthemethodisO(1),anditneedsseveralMBmemoryspace,itcanbeimplementedinedgeroutersornetworksecuredeviceslikefirewallstodefendagainstrandomspoofedsourceaddressDDoSattacks.
Keywords:networksecurity;distributeddenialofservice;BloomFilter;randomspoofedsourceaddress摘要:由于能够有效隐藏攻击者,随机伪造源地址分布式拒绝服务攻击被广泛采用.
抵御这种攻击的难点在于无法有效区分合法流量和攻击流量.
基于此类攻击发生时攻击包源地址的统计特征,提出了能够有效区分合法流量和攻击流量,并保护合法流量的方法.
首先设计了一种用于统计源地址数据包数的高效数据结构ExtendedCountingBloomFilter(ECBF),基于此,提出了随机伪造源地址分布式拒绝服务攻击发生时合法地址识别算法.
通过优先转发来自合法地址的数据包,实现对合法流量的有效保护.
采用真实互联网流量进行模拟,实验结果表明,所提方法能精确识别合法地址,有效地保护合法流量,尤其能够较好地保护有价值的交易会话.
所提方法的时间复杂性为O(1),并且只需数兆字节的内存开销,可嵌入边界路由器或网络安全设备,如防火墙中,实现随机伪造源地址分布式拒绝服务攻击的在线过滤.
关键词:网络安全;分布式拒绝服务攻击;BloomFilter;随机伪造源地址基金项目:国家自然科学基金(60703021,61070185);国家高技术研究发展计划(863)(2007AA010501,2007AA01Z444)收稿时间:2009-10-14;修改时间:2010-03-29;定稿时间:2010-04-272426JournalofSoftware软件学报Vol.
22,No.
10,October2011中图法分类号:TP309文献标识码:A分布式拒绝服务攻击(distributeddenialofservices,简称DDoS)是当前互联网最主要的安全威胁之一,严重影响了民众生活和社会经济,甚至于国家安全.
近年来,DDoS攻击事件频繁发生,比较典型的事件是2009年5月19日的"暴风影音"事件[1],造成的经济损失超过1.
6亿元,其根本原因是暴风影音的域名服务器DNSpod遭到了DDoS攻击.
可见,DDoS攻击的检测、防御和过滤的研究工作具有重要的理论意义和实际价值.
DDoS攻击发送大量数据包到被攻击服务器,可以有效阻止合法用户对资源的访问.
DDoS攻击可分为两类:利用协议弱点的攻击和洪泛攻击.
SYNFlood攻击是最典型的协议弱点攻击.
TCP协议收到一个SYN包,会开辟一段内存空间.
SYNFlood利用这一弱点,通过发送大量的SYN包消耗攻击目标的内存空间.
而洪泛攻击则是通过发送大量的数据包来消耗攻击目标的计算能力或带宽等,如UDPFlood.
从攻击数据包源地址真实性的角度来看,DDoS攻击可以分为采用真实源地址或者伪造源地址.
虽然当前僵尸网络规模庞大,攻击者可以利用大量的僵尸主机发动攻击,但是由于伪造源地址能够有效保护攻击者,隐藏僵尸主机,增加攻击防御难度,因此,采用伪造源地址的DDoS攻击始终是一种重要的攻击方式[2].
从DDoS防御设备部署位置的角度来看,流量过滤可以分为被攻击端过滤(ingressfiltering)、攻击端过滤(egressfiltering)和骨干网路由器过滤(router-basedfiltering).
IngressFiltering是最常见的防御方法,具有易于部署且部署者可以直接受益的优点.
但是,几乎当前所有IngressFiltering方法都无法有效抵御随机伪造源地址DDoS攻击,最大的困难在于无法有效区分合法流量和攻击流量.
基于统计的方法,如Packetscore方法[3]和PCA方法[4],都只是数据包层面上的过滤,无法为合法流量提供流层面上的保护;而Hop-CountFiltering[5]和History-IPFiltering[6]只能保护以前曾出现过的用户,而无法保护新来的用户.
本文关注伪造数据包源地址在整个地址空间(0~232)内随机分布的DDoS攻击.
在此类攻击发生时,对一个伪造数据包而言,每一个IP地址都有相同的概率被其选中作为其源地址,且概率为1/232.
因此,合法地址可能被伪造数据包选中,作为其源地址.
另一方面,合法地址同时也发送了合法数据包到被攻击端.
所以,从统计的角度来看,合法地址对应的数据包数大于伪造地址对应的数据包数.
基于上述统计特征,本文提出一种基于源地址分布特征的随机伪造源地址DDoS过滤方法(filteringbasedonthesourceaddressdistributedfeature,简称FSAD).
该方法部署在被攻击端,能够准确识别合法地址,并保护合法流量.
该方法具有如下优点:1)计算复杂性低,时间复杂性为O(1),只需消耗数兆字节内存,满足在线处理要求,可以嵌入到边界路由器或者防火墙中;2)能够识别出新用户;3)只需对历史流量进行学习,无需建立复杂的模型;4)不依赖于具体的网络协议,适用范围广.
本文第1节从总体上介绍FSAD.
第2节首先介绍用于统计源IP地址对应数据包数的高效数据结构——extendedcountingBloomFilter(ECBF),并基于ECBF提出合法地址识别算法,详细分析识别算法的误报率和漏报率,并提出识别参数的动态调整算法,最后介绍合法流量的保护方法.
第3节采用真实网络流量进行模拟实验,验证FSAD在地址识别和流量过滤这两方面的准确性和高效性.
第4节为相关工作.
第5节对一些相关问题进行讨论.
第6节总结全文.
1FSAD概述通常,DDoS攻击工具采用随机函数产生随机数作为伪造源地址[7,8].
由于随机数的范围受到处理器和操作系统位数的限制,所以伪造源地址常常局限在部分地址空间.
例如,如果操作系统是32位的Linux,则伪造源地址只能分布在0~2311之间.
与伪造地址在整个地址空间(0~232)内分布相比,部分空间分布的伪造方式往往无法最好地发挥攻击效率.
例如,对源地址不在伪造源地址覆盖范围内的数据包,安全设备可以直接允许其通过,这样,肖军等:随机伪造源地址分布式拒绝服务攻击过滤2427被攻击服务器仍然可以为很大一部分用户提供服务.
当前,64位的处理器和操作系统已开始普及,64位平台生成的伪造源地址将会在整个地址空间内分布.
同时,现有其他平台上的DDoS工具也很容易修改,实现伪造源地址在整个地址空间内随机分布.
由于存在以上两个原因,本文关注伪造源地址在整个地址空间内随机分布的DDoS攻击.
FSAD的过滤包含如下3个阶段:检测攻击发生,并根据当前攻击规模、历史流量和源地址识别精度的要求,设定合适的合法地址识别参数;识别出合法源地址,并保存到合法地址表中(legitimateaddresstable,简称LAT);检查数据包是否来自合法地址,根据检查结果按照不同优先级进行转发.
如果数据包转发队列发生溢出,则丢弃数据包.
FSAD的第1步是检测攻击发生.
一些过滤方法[9,10]无论攻击是否发生,都进行伪造数据包识别和过滤.
与这些方法不同,FSAD只有在检测到攻击发生时才开启过滤功能.
本文采用了基于熵的检测方法[11],能够快速检测到攻击发生.
熵能够有效地反映地址分布的聚合情况,同时具有较高的灵敏度.
在随机伪造源地址攻击发生时,与正常情况相比,源地址分布更加均匀,熵值相应地有所增加.
当熵值超过了一个阈值,可以认为随机伪造源地址DDoS攻击发生.
由于篇幅限制,本文不对检测方法作详细介绍,重点介绍合法源地址识别算法和合法流量保护这两方面内容.
2合法地址识别和合法流量保护本节介绍合法地址识别方法以及在合法地址识别后合法流量的保护策略.
首先介绍一个用于统计源地址包数的高效数据结构ExtendedCountingBloomFilter(ECBF),它可以大幅度降低内存开销.
基于ECBF,我们提出了合法地址识别算法,接着分析了识别算法的误报率和漏报率,然后提出了合法地址识别参数动态调整算法,可以保证在不同的攻击规模下满足识别精度的要求,最后介绍了合法流量保护和被保护对象过载控制方法.
2.
1TheExtendedCountingBloomFilter(ECBF)假设待保护地址已经给定,则只需统计源地址的信息.
随机伪造源地址攻击数据包的源地址在0~232之间随机分布,如果记录每个源地址对应的数据包数,则内存开销难以承受,需找到合适的方法节省内存开销,并且此方法能够用来识别合法源地址.
本文借鉴了龚俭等人[12]构建BloomFilter的方法,采用一种ECBF数据结构统计源地址对应包数.
与龚俭等人工作的区别在于:1)使用目的不同,龚俭等人提出的BloomFilter用于异常检测,而本文用于合法地址识别;2)龚俭等人采用了3个哈希函数记录源地址信息,而本文采用了4个哈希函数,能够降低地址识别的误报率;3)龚俭等人提出的方法需要还原IP地址,相应的时间复杂度为O(M),其中,M为216,而采用ECBF可以直接识别合法地址,相应的时间复杂度为O(1).
ECBF包含4个用于统计源地址数据包数的哈希函数和数组,每个数组分别对应于一个哈希函数,其中,A1对应于IPH,A2对应于IPM,A3对应于IPL,A4对应于IPLH,如图1所示.
每个哈希函数和统计过程具体介绍如下:假设收到一个数据包,源地址Saddr为(a.
b.
c.
d),则IPH(Saddr)=256*a+b;IPM(Saddr)=256*b+c;IPL(Saddr)=256*c+d;IPLH(Saddr)=256*d+a.
然后对A1[256*a+b],A2[256*b+c],A3[256*c+d]andA4[256*d+a]分别加1.
容易看出,ECBF的每个元素对应于216个源地址.
例如,A1数组的第257个单元对应源地址为(1.
1.
x.
y)的数据包,其中,x和y是0~255之间的任意一个数.
并且每收到一个数据包,对应于该数据包源地址的4个单元值都会被加1.
2428JournalofSoftware软件学报Vol.
22,No.
10,October2011Fig.
1ExtendedcountingBloomFilter(ECBF)图1扩展的计数BloomFilter结构2.
2合法地址识别算法基于前文提出的ECBF结构,本节给出一种随机伪造源地址DDoS攻击时合法地址的识别算法,如图2所示.
SetidentifyingtimeintervalandthresholdT;while(1)Receiveapacket;Getsourceipaddresssip;Recordsipinecbf;If(everyelement'svalueofsipin4arrays>T)Sipisalegitimateaddress;fi;if(timeintervalisover)Empty4arrays;Startanewtimeinterval;fi;Endwhile;Fig.
2LegitimateaddressidentifyingalgorithmunderrandomspoofedsourceaddressDDoSattacks图2随机伪造源地址DDoS攻击合法地址识别算法算法的第1步是设置合适的识别时隙interval和识别阈值T.
由于时隙和阈值的设定与识别精度要求以及当前的攻击规模相关,如何设置会在对识别算法的误差分析之后加以阐述.
每收到一个数据包,需进行4次哈希操作,由于每个哈希操作的时间复杂性都是O(1),所以算法的时间复杂性是O(1).
本识别算法基于ECBF,采用了4个数组,每个数组共216个元素,若每个元素大小以4B(字节)为例,则本识别算法的内存开销为1MB.
可见,本文提出的合法地址识别算法具有很好的时间复杂性和空间复杂性.
2.
3误报率和漏报率为了深入分析识别算法的准确性,首先将ECBF的元素分为两类:仅记录了伪造包数的元素和同时记录了合法包和伪造包数的元素;接着给出了元素值的分布特性;然后从误报率(falsepositiverate)和漏报率(falsenegativerate)两方面分析识别算法的误差.
IPHIPMIPLHashfunctionPacket(a.
b.
c.
d)A1A2A3.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
IPLHA4256*a+b256*b+c256*c+d256*d+a肖军等:随机伪造源地址分布式拒绝服务攻击过滤24292.
3.
1元素值分布参数X表示一个时隙后,一个元素的伪造攻击包计数.
参数Xi表示,当收到此时隙中第i个攻击包时,该元素的累加值.
显然,Xi=0或者Xi=1.
假设在一个时隙内共有m个伪造数据包到达被攻击端,则1.
miiXX==∑X服从二项分布,不易计算.
但由于伪造攻击数据包较多,二项分布可用泊松分布来近似.
任意一个IP地址被选中的期望值是m/232,每个单元对应216个IP地址,所以每个单元的攻击包计数服从泊松分布,期望值是m/216.
所以,1()e,!
kkTpXTkλλ+∞=+>=∑其中,λ=m/216.
为了验证上述推断,用ECBF记录随机生成的20*64K个伪造源地址.
任意选择ECBF中5000个元素,元素值分布如图3所示,圆点表示实际元素值分布,而曲线为推断的泊松分布曲线.
可见,元素值的分布情况与泊松分布基本接近.
假设一个时隙内一个合法地址的数据包数服从泊松分布.
由于两个泊松分布之和仍然是泊松分布,并且期望值是两者期望值之和,所以元素的合法数据包计数也服从泊松分布,假设其期望值为n.
此元素同时记录了攻击数据包数和正常数据包数,两者均服从泊松分布,期望值分别是m/216和n.
所以,此元素值也服从泊松分布,期望值是m/216+n.
图4显示了两类元素值的分布情况,其中,左边的曲线对应仅记录了伪造包的元素值,右边的曲线对应记录了合法数据包的元素值,两者期望值分别是λ1和λ2.
这里,λ1=m/216,λ2=m/216+n.
Fig.
3Elements'valuesdistributionFig.
4TwokindsofPoissondistribution图3元素值分布图4两类元素值的泊松分布2.
3.
2误报率和漏报率本文通过一个阈值T来区分上文所提及的两类元素,在此基础上分析识别算法的误报率和漏报率.
误报率为一个伪造地址被识别为合法地址的概率.
不失一般性,假设伪造源地址(x.
y.
z.
w)被识别为合法源地址,根据识别算法,它的4个对应元素值需均大于阈值T,所以误报率为p(A1[256*x+y]>T)*p(A2[256*y+z]>T)*p(A3[256*z+w]>T)*p(A4[256*w+x]>T).
p(A1[256*x+y]>T)表示A1[256*x+y]>T的概率,剩下3项的含义与之类似.
p(A1[256*x+y]>T),p(A2[256*y+z]>T),p(A3[256*z+w]>T)和p(A4[256*w+x]>T)的分析相似,为便于分析,用p(X>T)分别代替它们,误报率可表示为p4(X>T).
pa(X>T)表示伪造包计数X大于T的概率,pm(X>T)表示伪造包计数和合法包计数之和X大于T的概率.
如图5所示,区域A表示pa(X>T),区域B表示pm(X>T).
显然,p(X>T)=(1p)*pa(X>T)+p*pm(X>T),其中,p是ECBF任意一个数组中记录了合法包数的元素比率.
假设共有C′个元素记录了合法包,则p=C′/N,其中,N=65536.
所以,误报率为44((11()()amamCCppXTppXTpXTpXTNN′′(1)0.
125101520253035400.
100.
080.
060.
040.
020.
00λ1λ22430JournalofSoftware软件学报Vol.
22,No.
10,October2011从图4可以看出,pm(X>T)>pa(X>T),所以误报率随C′的增加而增加.
通常,同时与一个服务器交互的IP地址不会超过10K,为便于计算,本文用10K代替C′.
相应地,计算出的误报率大于实际误报率.
Fig.
5TwokindsofprobabilityofXgreaterthanT图5两类X大于T的概率分布漏报率是一个合法IP地址未被识别的概率.
根据合法地址识别算法,如果对应的4个元素值中有一个或多个小于阈值T,则这个地址不会被识别.
所以,漏报率为1p4(X>T).
对记录了合法数据包数的元素,p(X>T)即为pm(X>T),则漏报率为41()mpXT>(2)2.
4识别参数调整算法从图5可以看出,pm(X>T)和pa(X>T)都随着阈值T的增加而降低.
由公式(1)和公式(2)可知,随着阈值T的增加,误报率降低而漏报率增加.
基于这一结论,本节提出一种识别参数动态调整算法,以满足在不同攻击规模下识别精度的要求,如图6所示.
M:Thepredictedpacketnumberpersecondwithoutattacks;N:Thecurrentpacketsnumberpersecondunderanattack;Rn,Rp:Thefalsenegativeandfalsepositiverequirementvalues;fn(T,λ):Thefunctionusedtocalculatethefalsenegative,TisthePoissonrandomvariableandλistheaveragerateofsuccess;fp(T,λ):Thefunctionusedtocalculatethefalsepositive,TisthePoissonrandomvariableandλistheaveragerateofsuccess;Δλ3:=min(theexpectedvalueofnormalpacketsarrivalrateinasecond);Δλ1:=(NM)/65536;λ1:=Δλ1;λ3:=Δλ3;interval:=1;while(1)T:=min(T′|fn(T′,λ1)=2000.
90.
80.
70.
60.
50.
40.
30.
20.
10.
051015202530pktcout=200FalsepositiveFalsenegative5Ratio(%)Attacktrafficrate(k/s)43210510152025302434JournalofSoftware软件学报Vol.
22,No.
10,October2011(a)FSADandPacketscore'sfalsepositiverateand(b)FSADpacketpassingratioofaddresswhosecorrespondingfalsenegativerateofnormalpacketspassingpacketsnumberareindifferentranges(a)FSAD和Packetscore合法包识别的错报率和漏报率(b)FSAD方法中,处于不同包数范围合法地址的包通过率(c)Packetscorepacketpassingratioofaddresseswhosecorrespondingpacketsnumberareindifferentranges(c)Packetscore中,处于不同包数范围合法地址的包通过率Fig.
10NormalpacketspassingrationperformanceofFSADandPacketscore图10FSAD和Packetscore合法数据包通过情况4相关工作依据过滤位置的不同,DDoS攻击过滤可以分为被攻击端过滤、攻击端过滤和路由器过滤.
IngressFiltering是一类通过过滤可疑数据包或者非法数据包抵御DDoS攻击的常用方法.
通常只有在一个数据包的源地址在过滤系统许可的范围内,才允许其进入子网或服务器.
Wang等人[5]基于数据包在网络传递过程中网络跳数不易被攻击者伪造这一原理,提出了一种基于跳数过滤(hop-countfiltering,简称HCF)的伪造数据包DDoS攻击过滤方法,基于数据包首部的TTL(time-to-live)值判断数据包是否伪造,从而过滤DDoS攻击.
Tao等人[6]基于以往出现用户还会再次访问这一特点,提出了一种基于历史IP(history-IP)的DDoS防御方法,该方法对未出现在历史IP表中的源地址进行过滤,以实现对DDoS攻击的防御.
IngressFiltering往往需要复杂的离线或者在线学习,并且无法为新到用户提供保护.
IngressFiltering的主要局限性在于攻击者能够利用的网络资源或者计算资源远远大于防御设备拥有的资源,常常超过防御或者过滤设备处理的能力.
EgressFiltering是另一种常用的过滤手段,不同点在于过滤设备部署在源端,如果数据包的源地址属于本地子网,数据包将被允许通过.
这种过滤方法需要路由器开启过滤功能,但由于ISP往往各自为战,因而该方法无法普遍实施.
D-WARD[18]是一种新颖的EgressFiltering方法,通过比较正常流量模型和当前流量来识别是否有pktcout=2001.
2FalsenegativerateAttacktrafficrate(k/s)1.
00.
80.
60.
40.
2051015202530FSAD—FalsepositiveFSAD—FalsenegativePacketscore—FalsepositivePacketscore—Falsenegative0.
15RatioAttacktrafficrate(k/s)0.
120.
090.
060.
030.
0051015202530pktcout=2000.
10FalsenegativerateAttacktrafficrate(k/s)0.
090.
080.
070.
060.
0551015202530肖军等:随机伪造源地址分布式拒绝服务攻击过滤2435攻击发生,比如进出当前子网的数据包比例或者目的地址的连接数等.
如果当前流量状况偏离正常流量模型,则认为攻击发生,进行过滤.
Router-BasedFiltering在骨干网路由器上实现对攻击流量的过滤,可以有效阻止伪造攻击包到达目的地址.
SpoofingPreventionMothod[19]和Passport[20]方法均采取了让数据包携带secretekey的策略,通过secretekey,路由器可以验证数据包源地址的真实性.
DistributedPacketFiltering[21]和SourceAddressValidityEnforcementProtocol(SAVE)[9]均通过数据包进入路由器的接口验证数据包是否伪造,从而实现过滤.
此外,SAVE方法提供了一种发现数据包所进入接口的方法,而BGPAnti-SpoofingExtension[10]则采取让数据包携带表示数据包所进入方向的信息.
Pushback[22,23]是另一类重要的Router-BasedFiltering方法,监测到攻击发生之后,在靠近攻击端的路由器进行流量过滤,可以在攻击流量刚进入骨干网时就实现过滤,可有效降低DDoS攻击危害.
Router-BasedFiltering方法需要消耗路由器的计算资源,并且需要路由器之间的密切协作.
由于Router-BasedFiltering需要ISP的大规模投入,具有较大的实施难度,并且ISP各自为战,因而使得Router-BasedFiltering难以广泛普及.
5讨论前文对合法地址识别和合法流量保护的原理进行了阐述,下面有必要对如下相关问题作进一步的讨论.
5.
1哈希函数选取第2.
1节中提到,龚俭等人的工作采用3个哈希函数,本文所提出的ECBF采用4个哈希函数,能够降低合法地址识别误报率,下面对此作进一步分析.
源地址为(a.
b.
c.
d)的攻击数据包,依据合法地址识别算法,被识别为合法数据包的概率为P=p(A1[256*a+b]>T)*p(A2[256*b+c]>T)*p(A3[256*c+d]>T)*p(A4[256*d+a]>T).
如果采用3个哈希函数,地址识别算法不变,则上述攻击数据包被识别为合法数据包的概率为P′=p(A1[256*a+b]>T)*p(A2[256*b+c]>T)*p(A3[256*c+d]>T).
在同样的合法访问和攻击下,P可见,采用4个哈希函数与采用3个哈希函数相比,能够降低误报率.
下面给出一个误报实例.
采用3个哈希函数记录每个源地址对应的数据包数.
现有两个合法地址(a.
b.
c.
d)和(e.
b.
c.
f),两者对应的单元值均大于阈值T.
此时,源地址为(a.
b.
c.
f)和(e.
b.
c.
d)的攻击包均会被识别为合法数据包.
如图11所示,两个曲线框分别对应(a.
b.
c.
f)和(e.
b.
c.
d)这两个误报地址.
采用4个哈希函数能够有效避免此类误报.
Fig.
11Anormaladdressidentifyingerror图11合法地址识别错误实例5.
2合法地址识别算法在IPV6地址空间的适用性本文所提合法地址识别算法基于如下规律:随机伪造源地址攻击包在整个地址空间内均匀分布,从统计角度来看,每个单元记录的伪造攻击包数相同.
合法地址对应的单元同时记录了伪造包数和合法包数,因而具有比伪造地址更多的数据包数.
在IPV6地址空间下,这一规律保持不变,因而合法地址识别算法在IPV6空间下仍然256*a+b256*b+c256*c+dA1256*e+b256*c+fA2A3…………………2436JournalofSoftware软件学报Vol.
22,No.
10,October2011适用.
由于地址识别准确性与ECBF的哈希个数相关,为了减少误报,需对本文所提出的ECBF结构进行扩充,增加更多的哈希函数.
5.
3局限性由攻击包源地址的真实性角度来看,DDoS攻击可分为采用真实地址和采用伪造地址两类.
伪造地址可以进一步分为伪造固定地址、伪造子网地址、随机伪造源地址3种.
本文所提合法地址识别算法依赖于攻击包源地址在地址空间内的随机分布特性,因而不适用于真实地址、伪造固定地址和伪造子网地址这3类攻击.
随机伪造源地址的分布范围与操作系统、CPU和攻击代码相关,可分为在整个地址空间内分布和在部分地址空间内分布.
虽然本文只关注攻击包源地址在整个地址空间内分布的情况,但由于攻击源地址在部分地址空间范围内分布时,伪造源地址在此范围内仍然服从随机分布,因而本文的合法地址识别算法可识别此范围内的合法地址,但需识别出攻击包源地址的分布范围.
合法地址识别算法利用了攻击包源地址分布的统计特性,而与具体协议无关,即识别算法适用于多种协议的随机伪造源地址DDoS攻击,如SYNFlood攻击、UDPFlood、ICMPFlood或者多种协议的混合攻击.
6结论本文针对随机伪造源地址DDoS攻击,基于其源地址分布的统计特征提出了一种过滤方法,能够有效识别合法地址,为合法流量提供保护.
首先,提出了一个高效的数据包数统计结构ECBF,基于此,提出了合法地址识别算法;然后分析了识别算法的准确性,并提出了一种识别参数调整算法,可以在不同的攻击规模下满足识别精度的要求.
FSAD依据数据包源地址的合法性,给数据包以不同的优先级转发.
采用了真实网络数据进行模拟,结果表明,本文所提方法能够高精度地识别合法地址,有效保护合法流量,并可为有价值的长流提供更好的保护.
本文所提过滤方法无需建立复杂的训练模型,能够为新的合法用户提供流量保护,不依赖于具体协议,实用范围广.
由于对地址的识别和合法地址的查询均采用哈希结构,仅需数兆字节内存开销,且时间复杂性为O(1),可实时在线过滤,或嵌入到边界路由器或者现有的网络安全设备中,如防火墙等,因而具有较好的应用前景.
References:[1]http://net.
chinabyte.
com/519DNS/[2]EhrkenkranzT,LiJ.
OnthestateofIPspoofingdefense.
ACMTrans.
onInternetTechnology,2009,9(2):6(1)6(29).
[3]KimY,LauWC,ChuahMC,ChaoHJ.
Packetscore:Statistic-Basedoverloadcontrolagainstdistributeddenial-of-serviceattacks.
In:Proc.
oftheINFOCOM.
HongKong,2004.
141155.
http://ieeexplore.
ieee.
org/xpl/freeabs_all.
jsparnumber=1354679[doi:10.
1109/INFCOM.
2004.
1354679][4]SunH,ZhaungY,ChaoHJ.
Aprincipalcomponentsanalysis-basedrobustDDoSdefensesystem.
In:Proc.
oftheIEEEInt'lConf.
onCommunications.
Beijing,2008.
16631669.
http://ieeexplore.
ieee.
org/xpl/freeabs_all.
jsparnumber=4533357[doi:10.
1109/ICC.
2008.
321][5]JinC,WangHN,ShinKG.
Hop-Countfiltering:AneffectivedefenseagainstspoofedDdoStraffic.
In:Proc.
ofthe10thACMConf.
onComputerandCommunicationsSecurity.
Washington,2003.
3041.
http://dl.
acm.
org/citation.
cfmid=948116[doi:10.
1145/948109.
948116][6]PengT,LeckieC,RamamohanaraoK.
Protectionfromdistributeddenialofserviceattacksusinghistory-basedIPfiltering.
In:Proc.
oftheIEEEInt'lConf.
onCommunications.
Anchorage,2003.
482486.
http://ieeexplore.
ieee.
org/Xplore/login.
jspurl=http%3A%2F%2Fieeexplore.
ieee.
org%2Fiel5%2F8564%2F27113%2F01204223.
pdf%3Farnumber%3D1204223&authDecision=-203[doi:10.
1109/ICC.
2003.
1204223][7]DittrichD.
http://staff.
washington.
edu/dittrich/misc/tfn.
analysis.
txt.
1999.
[8]BarlowJ.
http://packetstormsecurity.
org/distributed/TFN2k_Analysis-1.
3.
txt.
2000.
[9]LiJ,MirkovicJ,WangMQ,ReiherP,ZhangLX.
SAVE:Sourceaddressvalidityenforcementprotocol.
In:Proc.
oftheINFOCOM.
NewYork,2002.
15571566.
http://ieeexplore.
ieee.
org/xpl/freeabs_all.
jsparnumber=1019407[doi:10.
1109/INFCOM.
2002.
1019407]肖军等:随机伪造源地址分布式拒绝服务攻击过滤2437[10]LeeH,KwonM,HaskerG,PerrigA.
BASE:AnincrementallydeployablemechanismforviableIPspoofingprevention.
In:Proc.
ofthe2ndACMSymp.
onInformation,ComputerandCommunicationSecurity.
Singapore,2007.
2031.
http://dl.
acm.
org/citation.
cfmid=1229293[doi:10.
1145/1229285.
1229293][11]CormenTH,LeiersonCE,RivestRL,SteinC.
IntroductiontoAlgorithms.
2nded.
,Cambridge:MITPressandMcGraw-Hill,2001.
101122.
[12]GongJ,PengYB,YangW,LiuWJ.
ReconstructingtheparameterformassiveabnormalTCPconnectionswithbloomfilter.
JournalofSoftware,2006,17(3):434444(inChinesewithEnglishabstract).
http://www.
jos.
org.
cn/1000-9825/17/434.
htm[doi:10.
1360/jos170434][13]ZouBX,LiuQ.
ARMA-Basedtrafficpredictionandoverloaddetectionofnetwork.
JournalofComputerResearchandDevelopment,2002,39(12):16451652(inChinesewithEnglishabstract).
[14]XuJ,LeeW.
SustainingavailabilityofWebservicesunderdistributeddenialofserviceattacks.
IEEETrans.
onComputers,2003,52(2):195208.
[doi:10.
1109/TC.
2003.
1176986][15]Ben-PoratU,Bremler-BarrA,LevyH.
EvaluatingthevulnerabilityofnetworkmechanismstosophisticatedDDoSattacks.
In:Proc.
oftheINFOCOM.
Phoenix,2008.
22972305.
http://ieeexplore.
ieee.
org/Xplore/login.
jspurl=http%3A%2F%2Fieeexplore.
ieee.
org%2Fiel5%2F4509594%2F4509595%2F04509893.
pdf%3Farnumber%3D4509893&authDecision=-203[doi:10.
1109/INFOCOM.
2008.
298][16]ArlittM,JinT.
Workloadcharacterizationofthe1998WorldCupWebsite.
HPLabsTechnicalReport,1999.
[17]http://mawi.
wide.
ad.
jp/[18]MirkoviJ,PrierG,ReiherP.
AttackingDDoSatthesource.
In:Proc.
oftheIEEEInt'lConf.
onNetworkProtocols.
Paris,2002.
312321.
http://dl.
acm.
org/citation.
cfmid=656169[19]Bremler-BarrA,LevyH.
Spoofingpreventionmethod.
In:Proc.
oftheINFOCOM.
2005.
http://ieeexplore.
ieee.
org/xpl/freeabs_all.
jsparnumber=1497921[doi:10.
1109/INFCOM.
2005.
1497921][20]LiuX,LiA,YangXW,WetherallD.
Passport:Secureandadoptablesourceauthentication.
In:Proc.
oftheUSENIXSymp.
onNetworkedSystemsDesignandImplementation.
2008.
365378.
http://dl.
acm.
org/citation.
cfmid=1387615[21]ParkK,LeeH.
Ontheeffectivenessofrouter-basedpacketfilteringfordistributedDoSattackpreventioninpower-lawInternets.
In:Proc.
oftheACMSIGCOMM.
SanDiego,2001.
1526.
http://dl.
acm.
org/citation.
cfmid=383061[doi:10.
1145/383059.
383061][22]IoannidisJ,BellovinSM.
Implementingpushback:Router-BaseddefenseagainstDDoSattacks.
In:Proc.
oftheNetworkandDistributedSystemSecurity(NDSS).
2002.
[23]YauDKY,LuiJCS,LiangF,YamY.
Defendingagainstdistributeddenial-of-serviceattackswithmax-minfairserver-centricrouterthrottles.
IEEETrans.
onNetworking,2005,13(1):2942.
[doi:10.
1109/TNET.
2004.
842221]附中文参考文献:[12]龚俭,彭艳兵,杨望,刘卫江.
基于BloomFilter的大规模异常TCP连接参数再现方法.
软件学报,2006,17(3):434444.
http://www.
jos.
org.
cn/1000-9825/17/434.
htm[doi:10.
1360/jos170434][13]邹柏贤,刘强.
基于ARMA模型的网络流量预测.
计算机研究与发展,2002,39(12):16451652.
肖军(1979-),男,江苏大丰人,博士生,CCF会员,主要研究领域为DDoS攻击检测,DDoS攻击过滤.
张永铮(1978-),男,博士,副研究员,CCF会员,主要研究领域为网络安全.
云晓春(1971-),男,博士,教授,博士生导师,主要研究领域为网络安全,互联网建模.
ac.
cnJournalofSoftware,2011,22(10):24252437[doi:10.
3724/SP.
J.
1001.
2011.
03882]http://www.
jos.
org.
cn中国科学院软件研究所版权所有.
Tel/Fax:+86-10-62562563随机伪造源地址分布式拒绝服务攻击过滤肖军1,2+,云晓春1,张永铮11(中国科学院计算技术研究所,北京100190)2(中国科学院研究生院,北京100049)RandomSpoofedSourceAddressDistributedDenial-of-ServiceAttackTrafficFilterXIAOJun1,2+,YUNXiao-Chun1,ZHANGYong-Zheng11(InstituteofComputingTechnology,TheChineseAcademyofSciences,Beijing100190,China)2(GraduateUniversity,TheChineseAcademyofSciences,Beijing100049,China)+Correspondingauthor:E-mail:xiaojun@software.
ict.
ac.
cnXiaoJ,YunXC,ZhangYZ.
Randomspoofedsourceaddressdistributeddenial-of-serviceattacktrafficfilter.
JournalofSoftware,2011,22(10):24252437.
http://www.
jos.
org.
cn/1000-9825/3882.
htmAbstract:DistributedDenial-of-Service(DDoS)attack,usingrandomspoofedsourceaddresses,ispopularbecauseitcanprotecttheattacker'sanonymity.
Itisverydifficulttodefentagainstthisattackbecauseitisveryhardtodifferentiatebadtrafficfromthenormal.
Inthispaper,basedonthesourceaddressesdistributionstatisticalfeature,aneffectivedefensescheme,whichcandifferentiatevicioustrafficfromnormaltraffic,ispresented.
BasedonanovelExtendedCountingBloomFilter(ECBF)datastructure,thispaperproposesanalgorithmtoidentifynormaladdressesaccurately.
Onceanormaladdressissoughtout,packetsfromitwillbeforwardedwithhighpriority,thus,normaltrafficisprotected.
Thesimulationresultsshowthatthisschemecanidentifylegitimateaddressesaccurately,protectlegitimatetrafficeffectively,andgivebetterprotectiontovaluablelongflows.
BecausethetimecomplexityofthemethodisO(1),anditneedsseveralMBmemoryspace,itcanbeimplementedinedgeroutersornetworksecuredeviceslikefirewallstodefendagainstrandomspoofedsourceaddressDDoSattacks.
Keywords:networksecurity;distributeddenialofservice;BloomFilter;randomspoofedsourceaddress摘要:由于能够有效隐藏攻击者,随机伪造源地址分布式拒绝服务攻击被广泛采用.
抵御这种攻击的难点在于无法有效区分合法流量和攻击流量.
基于此类攻击发生时攻击包源地址的统计特征,提出了能够有效区分合法流量和攻击流量,并保护合法流量的方法.
首先设计了一种用于统计源地址数据包数的高效数据结构ExtendedCountingBloomFilter(ECBF),基于此,提出了随机伪造源地址分布式拒绝服务攻击发生时合法地址识别算法.
通过优先转发来自合法地址的数据包,实现对合法流量的有效保护.
采用真实互联网流量进行模拟,实验结果表明,所提方法能精确识别合法地址,有效地保护合法流量,尤其能够较好地保护有价值的交易会话.
所提方法的时间复杂性为O(1),并且只需数兆字节的内存开销,可嵌入边界路由器或网络安全设备,如防火墙中,实现随机伪造源地址分布式拒绝服务攻击的在线过滤.
关键词:网络安全;分布式拒绝服务攻击;BloomFilter;随机伪造源地址基金项目:国家自然科学基金(60703021,61070185);国家高技术研究发展计划(863)(2007AA010501,2007AA01Z444)收稿时间:2009-10-14;修改时间:2010-03-29;定稿时间:2010-04-272426JournalofSoftware软件学报Vol.
22,No.
10,October2011中图法分类号:TP309文献标识码:A分布式拒绝服务攻击(distributeddenialofservices,简称DDoS)是当前互联网最主要的安全威胁之一,严重影响了民众生活和社会经济,甚至于国家安全.
近年来,DDoS攻击事件频繁发生,比较典型的事件是2009年5月19日的"暴风影音"事件[1],造成的经济损失超过1.
6亿元,其根本原因是暴风影音的域名服务器DNSpod遭到了DDoS攻击.
可见,DDoS攻击的检测、防御和过滤的研究工作具有重要的理论意义和实际价值.
DDoS攻击发送大量数据包到被攻击服务器,可以有效阻止合法用户对资源的访问.
DDoS攻击可分为两类:利用协议弱点的攻击和洪泛攻击.
SYNFlood攻击是最典型的协议弱点攻击.
TCP协议收到一个SYN包,会开辟一段内存空间.
SYNFlood利用这一弱点,通过发送大量的SYN包消耗攻击目标的内存空间.
而洪泛攻击则是通过发送大量的数据包来消耗攻击目标的计算能力或带宽等,如UDPFlood.
从攻击数据包源地址真实性的角度来看,DDoS攻击可以分为采用真实源地址或者伪造源地址.
虽然当前僵尸网络规模庞大,攻击者可以利用大量的僵尸主机发动攻击,但是由于伪造源地址能够有效保护攻击者,隐藏僵尸主机,增加攻击防御难度,因此,采用伪造源地址的DDoS攻击始终是一种重要的攻击方式[2].
从DDoS防御设备部署位置的角度来看,流量过滤可以分为被攻击端过滤(ingressfiltering)、攻击端过滤(egressfiltering)和骨干网路由器过滤(router-basedfiltering).
IngressFiltering是最常见的防御方法,具有易于部署且部署者可以直接受益的优点.
但是,几乎当前所有IngressFiltering方法都无法有效抵御随机伪造源地址DDoS攻击,最大的困难在于无法有效区分合法流量和攻击流量.
基于统计的方法,如Packetscore方法[3]和PCA方法[4],都只是数据包层面上的过滤,无法为合法流量提供流层面上的保护;而Hop-CountFiltering[5]和History-IPFiltering[6]只能保护以前曾出现过的用户,而无法保护新来的用户.
本文关注伪造数据包源地址在整个地址空间(0~232)内随机分布的DDoS攻击.
在此类攻击发生时,对一个伪造数据包而言,每一个IP地址都有相同的概率被其选中作为其源地址,且概率为1/232.
因此,合法地址可能被伪造数据包选中,作为其源地址.
另一方面,合法地址同时也发送了合法数据包到被攻击端.
所以,从统计的角度来看,合法地址对应的数据包数大于伪造地址对应的数据包数.
基于上述统计特征,本文提出一种基于源地址分布特征的随机伪造源地址DDoS过滤方法(filteringbasedonthesourceaddressdistributedfeature,简称FSAD).
该方法部署在被攻击端,能够准确识别合法地址,并保护合法流量.
该方法具有如下优点:1)计算复杂性低,时间复杂性为O(1),只需消耗数兆字节内存,满足在线处理要求,可以嵌入到边界路由器或者防火墙中;2)能够识别出新用户;3)只需对历史流量进行学习,无需建立复杂的模型;4)不依赖于具体的网络协议,适用范围广.
本文第1节从总体上介绍FSAD.
第2节首先介绍用于统计源IP地址对应数据包数的高效数据结构——extendedcountingBloomFilter(ECBF),并基于ECBF提出合法地址识别算法,详细分析识别算法的误报率和漏报率,并提出识别参数的动态调整算法,最后介绍合法流量的保护方法.
第3节采用真实网络流量进行模拟实验,验证FSAD在地址识别和流量过滤这两方面的准确性和高效性.
第4节为相关工作.
第5节对一些相关问题进行讨论.
第6节总结全文.
1FSAD概述通常,DDoS攻击工具采用随机函数产生随机数作为伪造源地址[7,8].
由于随机数的范围受到处理器和操作系统位数的限制,所以伪造源地址常常局限在部分地址空间.
例如,如果操作系统是32位的Linux,则伪造源地址只能分布在0~2311之间.
与伪造地址在整个地址空间(0~232)内分布相比,部分空间分布的伪造方式往往无法最好地发挥攻击效率.
例如,对源地址不在伪造源地址覆盖范围内的数据包,安全设备可以直接允许其通过,这样,肖军等:随机伪造源地址分布式拒绝服务攻击过滤2427被攻击服务器仍然可以为很大一部分用户提供服务.
当前,64位的处理器和操作系统已开始普及,64位平台生成的伪造源地址将会在整个地址空间内分布.
同时,现有其他平台上的DDoS工具也很容易修改,实现伪造源地址在整个地址空间内随机分布.
由于存在以上两个原因,本文关注伪造源地址在整个地址空间内随机分布的DDoS攻击.
FSAD的过滤包含如下3个阶段:检测攻击发生,并根据当前攻击规模、历史流量和源地址识别精度的要求,设定合适的合法地址识别参数;识别出合法源地址,并保存到合法地址表中(legitimateaddresstable,简称LAT);检查数据包是否来自合法地址,根据检查结果按照不同优先级进行转发.
如果数据包转发队列发生溢出,则丢弃数据包.
FSAD的第1步是检测攻击发生.
一些过滤方法[9,10]无论攻击是否发生,都进行伪造数据包识别和过滤.
与这些方法不同,FSAD只有在检测到攻击发生时才开启过滤功能.
本文采用了基于熵的检测方法[11],能够快速检测到攻击发生.
熵能够有效地反映地址分布的聚合情况,同时具有较高的灵敏度.
在随机伪造源地址攻击发生时,与正常情况相比,源地址分布更加均匀,熵值相应地有所增加.
当熵值超过了一个阈值,可以认为随机伪造源地址DDoS攻击发生.
由于篇幅限制,本文不对检测方法作详细介绍,重点介绍合法源地址识别算法和合法流量保护这两方面内容.
2合法地址识别和合法流量保护本节介绍合法地址识别方法以及在合法地址识别后合法流量的保护策略.
首先介绍一个用于统计源地址包数的高效数据结构ExtendedCountingBloomFilter(ECBF),它可以大幅度降低内存开销.
基于ECBF,我们提出了合法地址识别算法,接着分析了识别算法的误报率和漏报率,然后提出了合法地址识别参数动态调整算法,可以保证在不同的攻击规模下满足识别精度的要求,最后介绍了合法流量保护和被保护对象过载控制方法.
2.
1TheExtendedCountingBloomFilter(ECBF)假设待保护地址已经给定,则只需统计源地址的信息.
随机伪造源地址攻击数据包的源地址在0~232之间随机分布,如果记录每个源地址对应的数据包数,则内存开销难以承受,需找到合适的方法节省内存开销,并且此方法能够用来识别合法源地址.
本文借鉴了龚俭等人[12]构建BloomFilter的方法,采用一种ECBF数据结构统计源地址对应包数.
与龚俭等人工作的区别在于:1)使用目的不同,龚俭等人提出的BloomFilter用于异常检测,而本文用于合法地址识别;2)龚俭等人采用了3个哈希函数记录源地址信息,而本文采用了4个哈希函数,能够降低地址识别的误报率;3)龚俭等人提出的方法需要还原IP地址,相应的时间复杂度为O(M),其中,M为216,而采用ECBF可以直接识别合法地址,相应的时间复杂度为O(1).
ECBF包含4个用于统计源地址数据包数的哈希函数和数组,每个数组分别对应于一个哈希函数,其中,A1对应于IPH,A2对应于IPM,A3对应于IPL,A4对应于IPLH,如图1所示.
每个哈希函数和统计过程具体介绍如下:假设收到一个数据包,源地址Saddr为(a.
b.
c.
d),则IPH(Saddr)=256*a+b;IPM(Saddr)=256*b+c;IPL(Saddr)=256*c+d;IPLH(Saddr)=256*d+a.
然后对A1[256*a+b],A2[256*b+c],A3[256*c+d]andA4[256*d+a]分别加1.
容易看出,ECBF的每个元素对应于216个源地址.
例如,A1数组的第257个单元对应源地址为(1.
1.
x.
y)的数据包,其中,x和y是0~255之间的任意一个数.
并且每收到一个数据包,对应于该数据包源地址的4个单元值都会被加1.
2428JournalofSoftware软件学报Vol.
22,No.
10,October2011Fig.
1ExtendedcountingBloomFilter(ECBF)图1扩展的计数BloomFilter结构2.
2合法地址识别算法基于前文提出的ECBF结构,本节给出一种随机伪造源地址DDoS攻击时合法地址的识别算法,如图2所示.
SetidentifyingtimeintervalandthresholdT;while(1)Receiveapacket;Getsourceipaddresssip;Recordsipinecbf;If(everyelement'svalueofsipin4arrays>T)Sipisalegitimateaddress;fi;if(timeintervalisover)Empty4arrays;Startanewtimeinterval;fi;Endwhile;Fig.
2LegitimateaddressidentifyingalgorithmunderrandomspoofedsourceaddressDDoSattacks图2随机伪造源地址DDoS攻击合法地址识别算法算法的第1步是设置合适的识别时隙interval和识别阈值T.
由于时隙和阈值的设定与识别精度要求以及当前的攻击规模相关,如何设置会在对识别算法的误差分析之后加以阐述.
每收到一个数据包,需进行4次哈希操作,由于每个哈希操作的时间复杂性都是O(1),所以算法的时间复杂性是O(1).
本识别算法基于ECBF,采用了4个数组,每个数组共216个元素,若每个元素大小以4B(字节)为例,则本识别算法的内存开销为1MB.
可见,本文提出的合法地址识别算法具有很好的时间复杂性和空间复杂性.
2.
3误报率和漏报率为了深入分析识别算法的准确性,首先将ECBF的元素分为两类:仅记录了伪造包数的元素和同时记录了合法包和伪造包数的元素;接着给出了元素值的分布特性;然后从误报率(falsepositiverate)和漏报率(falsenegativerate)两方面分析识别算法的误差.
IPHIPMIPLHashfunctionPacket(a.
b.
c.
d)A1A2A3.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
IPLHA4256*a+b256*b+c256*c+d256*d+a肖军等:随机伪造源地址分布式拒绝服务攻击过滤24292.
3.
1元素值分布参数X表示一个时隙后,一个元素的伪造攻击包计数.
参数Xi表示,当收到此时隙中第i个攻击包时,该元素的累加值.
显然,Xi=0或者Xi=1.
假设在一个时隙内共有m个伪造数据包到达被攻击端,则1.
miiXX==∑X服从二项分布,不易计算.
但由于伪造攻击数据包较多,二项分布可用泊松分布来近似.
任意一个IP地址被选中的期望值是m/232,每个单元对应216个IP地址,所以每个单元的攻击包计数服从泊松分布,期望值是m/216.
所以,1()e,!
kkTpXTkλλ+∞=+>=∑其中,λ=m/216.
为了验证上述推断,用ECBF记录随机生成的20*64K个伪造源地址.
任意选择ECBF中5000个元素,元素值分布如图3所示,圆点表示实际元素值分布,而曲线为推断的泊松分布曲线.
可见,元素值的分布情况与泊松分布基本接近.
假设一个时隙内一个合法地址的数据包数服从泊松分布.
由于两个泊松分布之和仍然是泊松分布,并且期望值是两者期望值之和,所以元素的合法数据包计数也服从泊松分布,假设其期望值为n.
此元素同时记录了攻击数据包数和正常数据包数,两者均服从泊松分布,期望值分别是m/216和n.
所以,此元素值也服从泊松分布,期望值是m/216+n.
图4显示了两类元素值的分布情况,其中,左边的曲线对应仅记录了伪造包的元素值,右边的曲线对应记录了合法数据包的元素值,两者期望值分别是λ1和λ2.
这里,λ1=m/216,λ2=m/216+n.
Fig.
3Elements'valuesdistributionFig.
4TwokindsofPoissondistribution图3元素值分布图4两类元素值的泊松分布2.
3.
2误报率和漏报率本文通过一个阈值T来区分上文所提及的两类元素,在此基础上分析识别算法的误报率和漏报率.
误报率为一个伪造地址被识别为合法地址的概率.
不失一般性,假设伪造源地址(x.
y.
z.
w)被识别为合法源地址,根据识别算法,它的4个对应元素值需均大于阈值T,所以误报率为p(A1[256*x+y]>T)*p(A2[256*y+z]>T)*p(A3[256*z+w]>T)*p(A4[256*w+x]>T).
p(A1[256*x+y]>T)表示A1[256*x+y]>T的概率,剩下3项的含义与之类似.
p(A1[256*x+y]>T),p(A2[256*y+z]>T),p(A3[256*z+w]>T)和p(A4[256*w+x]>T)的分析相似,为便于分析,用p(X>T)分别代替它们,误报率可表示为p4(X>T).
pa(X>T)表示伪造包计数X大于T的概率,pm(X>T)表示伪造包计数和合法包计数之和X大于T的概率.
如图5所示,区域A表示pa(X>T),区域B表示pm(X>T).
显然,p(X>T)=(1p)*pa(X>T)+p*pm(X>T),其中,p是ECBF任意一个数组中记录了合法包数的元素比率.
假设共有C′个元素记录了合法包,则p=C′/N,其中,N=65536.
所以,误报率为44((11()()amamCCppXTppXTpXTpXTNN′′(1)0.
125101520253035400.
100.
080.
060.
040.
020.
00λ1λ22430JournalofSoftware软件学报Vol.
22,No.
10,October2011从图4可以看出,pm(X>T)>pa(X>T),所以误报率随C′的增加而增加.
通常,同时与一个服务器交互的IP地址不会超过10K,为便于计算,本文用10K代替C′.
相应地,计算出的误报率大于实际误报率.
Fig.
5TwokindsofprobabilityofXgreaterthanT图5两类X大于T的概率分布漏报率是一个合法IP地址未被识别的概率.
根据合法地址识别算法,如果对应的4个元素值中有一个或多个小于阈值T,则这个地址不会被识别.
所以,漏报率为1p4(X>T).
对记录了合法数据包数的元素,p(X>T)即为pm(X>T),则漏报率为41()mpXT>(2)2.
4识别参数调整算法从图5可以看出,pm(X>T)和pa(X>T)都随着阈值T的增加而降低.
由公式(1)和公式(2)可知,随着阈值T的增加,误报率降低而漏报率增加.
基于这一结论,本节提出一种识别参数动态调整算法,以满足在不同攻击规模下识别精度的要求,如图6所示.
M:Thepredictedpacketnumberpersecondwithoutattacks;N:Thecurrentpacketsnumberpersecondunderanattack;Rn,Rp:Thefalsenegativeandfalsepositiverequirementvalues;fn(T,λ):Thefunctionusedtocalculatethefalsenegative,TisthePoissonrandomvariableandλistheaveragerateofsuccess;fp(T,λ):Thefunctionusedtocalculatethefalsepositive,TisthePoissonrandomvariableandλistheaveragerateofsuccess;Δλ3:=min(theexpectedvalueofnormalpacketsarrivalrateinasecond);Δλ1:=(NM)/65536;λ1:=Δλ1;λ3:=Δλ3;interval:=1;while(1)T:=min(T′|fn(T′,λ1)=2000.
90.
80.
70.
60.
50.
40.
30.
20.
10.
051015202530pktcout=200FalsepositiveFalsenegative5Ratio(%)Attacktrafficrate(k/s)43210510152025302434JournalofSoftware软件学报Vol.
22,No.
10,October2011(a)FSADandPacketscore'sfalsepositiverateand(b)FSADpacketpassingratioofaddresswhosecorrespondingfalsenegativerateofnormalpacketspassingpacketsnumberareindifferentranges(a)FSAD和Packetscore合法包识别的错报率和漏报率(b)FSAD方法中,处于不同包数范围合法地址的包通过率(c)Packetscorepacketpassingratioofaddresseswhosecorrespondingpacketsnumberareindifferentranges(c)Packetscore中,处于不同包数范围合法地址的包通过率Fig.
10NormalpacketspassingrationperformanceofFSADandPacketscore图10FSAD和Packetscore合法数据包通过情况4相关工作依据过滤位置的不同,DDoS攻击过滤可以分为被攻击端过滤、攻击端过滤和路由器过滤.
IngressFiltering是一类通过过滤可疑数据包或者非法数据包抵御DDoS攻击的常用方法.
通常只有在一个数据包的源地址在过滤系统许可的范围内,才允许其进入子网或服务器.
Wang等人[5]基于数据包在网络传递过程中网络跳数不易被攻击者伪造这一原理,提出了一种基于跳数过滤(hop-countfiltering,简称HCF)的伪造数据包DDoS攻击过滤方法,基于数据包首部的TTL(time-to-live)值判断数据包是否伪造,从而过滤DDoS攻击.
Tao等人[6]基于以往出现用户还会再次访问这一特点,提出了一种基于历史IP(history-IP)的DDoS防御方法,该方法对未出现在历史IP表中的源地址进行过滤,以实现对DDoS攻击的防御.
IngressFiltering往往需要复杂的离线或者在线学习,并且无法为新到用户提供保护.
IngressFiltering的主要局限性在于攻击者能够利用的网络资源或者计算资源远远大于防御设备拥有的资源,常常超过防御或者过滤设备处理的能力.
EgressFiltering是另一种常用的过滤手段,不同点在于过滤设备部署在源端,如果数据包的源地址属于本地子网,数据包将被允许通过.
这种过滤方法需要路由器开启过滤功能,但由于ISP往往各自为战,因而该方法无法普遍实施.
D-WARD[18]是一种新颖的EgressFiltering方法,通过比较正常流量模型和当前流量来识别是否有pktcout=2001.
2FalsenegativerateAttacktrafficrate(k/s)1.
00.
80.
60.
40.
2051015202530FSAD—FalsepositiveFSAD—FalsenegativePacketscore—FalsepositivePacketscore—Falsenegative0.
15RatioAttacktrafficrate(k/s)0.
120.
090.
060.
030.
0051015202530pktcout=2000.
10FalsenegativerateAttacktrafficrate(k/s)0.
090.
080.
070.
060.
0551015202530肖军等:随机伪造源地址分布式拒绝服务攻击过滤2435攻击发生,比如进出当前子网的数据包比例或者目的地址的连接数等.
如果当前流量状况偏离正常流量模型,则认为攻击发生,进行过滤.
Router-BasedFiltering在骨干网路由器上实现对攻击流量的过滤,可以有效阻止伪造攻击包到达目的地址.
SpoofingPreventionMothod[19]和Passport[20]方法均采取了让数据包携带secretekey的策略,通过secretekey,路由器可以验证数据包源地址的真实性.
DistributedPacketFiltering[21]和SourceAddressValidityEnforcementProtocol(SAVE)[9]均通过数据包进入路由器的接口验证数据包是否伪造,从而实现过滤.
此外,SAVE方法提供了一种发现数据包所进入接口的方法,而BGPAnti-SpoofingExtension[10]则采取让数据包携带表示数据包所进入方向的信息.
Pushback[22,23]是另一类重要的Router-BasedFiltering方法,监测到攻击发生之后,在靠近攻击端的路由器进行流量过滤,可以在攻击流量刚进入骨干网时就实现过滤,可有效降低DDoS攻击危害.
Router-BasedFiltering方法需要消耗路由器的计算资源,并且需要路由器之间的密切协作.
由于Router-BasedFiltering需要ISP的大规模投入,具有较大的实施难度,并且ISP各自为战,因而使得Router-BasedFiltering难以广泛普及.
5讨论前文对合法地址识别和合法流量保护的原理进行了阐述,下面有必要对如下相关问题作进一步的讨论.
5.
1哈希函数选取第2.
1节中提到,龚俭等人的工作采用3个哈希函数,本文所提出的ECBF采用4个哈希函数,能够降低合法地址识别误报率,下面对此作进一步分析.
源地址为(a.
b.
c.
d)的攻击数据包,依据合法地址识别算法,被识别为合法数据包的概率为P=p(A1[256*a+b]>T)*p(A2[256*b+c]>T)*p(A3[256*c+d]>T)*p(A4[256*d+a]>T).
如果采用3个哈希函数,地址识别算法不变,则上述攻击数据包被识别为合法数据包的概率为P′=p(A1[256*a+b]>T)*p(A2[256*b+c]>T)*p(A3[256*c+d]>T).
在同样的合法访问和攻击下,P
下面给出一个误报实例.
采用3个哈希函数记录每个源地址对应的数据包数.
现有两个合法地址(a.
b.
c.
d)和(e.
b.
c.
f),两者对应的单元值均大于阈值T.
此时,源地址为(a.
b.
c.
f)和(e.
b.
c.
d)的攻击包均会被识别为合法数据包.
如图11所示,两个曲线框分别对应(a.
b.
c.
f)和(e.
b.
c.
d)这两个误报地址.
采用4个哈希函数能够有效避免此类误报.
Fig.
11Anormaladdressidentifyingerror图11合法地址识别错误实例5.
2合法地址识别算法在IPV6地址空间的适用性本文所提合法地址识别算法基于如下规律:随机伪造源地址攻击包在整个地址空间内均匀分布,从统计角度来看,每个单元记录的伪造攻击包数相同.
合法地址对应的单元同时记录了伪造包数和合法包数,因而具有比伪造地址更多的数据包数.
在IPV6地址空间下,这一规律保持不变,因而合法地址识别算法在IPV6空间下仍然256*a+b256*b+c256*c+dA1256*e+b256*c+fA2A3…………………2436JournalofSoftware软件学报Vol.
22,No.
10,October2011适用.
由于地址识别准确性与ECBF的哈希个数相关,为了减少误报,需对本文所提出的ECBF结构进行扩充,增加更多的哈希函数.
5.
3局限性由攻击包源地址的真实性角度来看,DDoS攻击可分为采用真实地址和采用伪造地址两类.
伪造地址可以进一步分为伪造固定地址、伪造子网地址、随机伪造源地址3种.
本文所提合法地址识别算法依赖于攻击包源地址在地址空间内的随机分布特性,因而不适用于真实地址、伪造固定地址和伪造子网地址这3类攻击.
随机伪造源地址的分布范围与操作系统、CPU和攻击代码相关,可分为在整个地址空间内分布和在部分地址空间内分布.
虽然本文只关注攻击包源地址在整个地址空间内分布的情况,但由于攻击源地址在部分地址空间范围内分布时,伪造源地址在此范围内仍然服从随机分布,因而本文的合法地址识别算法可识别此范围内的合法地址,但需识别出攻击包源地址的分布范围.
合法地址识别算法利用了攻击包源地址分布的统计特性,而与具体协议无关,即识别算法适用于多种协议的随机伪造源地址DDoS攻击,如SYNFlood攻击、UDPFlood、ICMPFlood或者多种协议的混合攻击.
6结论本文针对随机伪造源地址DDoS攻击,基于其源地址分布的统计特征提出了一种过滤方法,能够有效识别合法地址,为合法流量提供保护.
首先,提出了一个高效的数据包数统计结构ECBF,基于此,提出了合法地址识别算法;然后分析了识别算法的准确性,并提出了一种识别参数调整算法,可以在不同的攻击规模下满足识别精度的要求.
FSAD依据数据包源地址的合法性,给数据包以不同的优先级转发.
采用了真实网络数据进行模拟,结果表明,本文所提方法能够高精度地识别合法地址,有效保护合法流量,并可为有价值的长流提供更好的保护.
本文所提过滤方法无需建立复杂的训练模型,能够为新的合法用户提供流量保护,不依赖于具体协议,实用范围广.
由于对地址的识别和合法地址的查询均采用哈希结构,仅需数兆字节内存开销,且时间复杂性为O(1),可实时在线过滤,或嵌入到边界路由器或者现有的网络安全设备中,如防火墙等,因而具有较好的应用前景.
References:[1]http://net.
chinabyte.
com/519DNS/[2]EhrkenkranzT,LiJ.
OnthestateofIPspoofingdefense.
ACMTrans.
onInternetTechnology,2009,9(2):6(1)6(29).
[3]KimY,LauWC,ChuahMC,ChaoHJ.
Packetscore:Statistic-Basedoverloadcontrolagainstdistributeddenial-of-serviceattacks.
In:Proc.
oftheINFOCOM.
HongKong,2004.
141155.
http://ieeexplore.
ieee.
org/xpl/freeabs_all.
jsparnumber=1354679[doi:10.
1109/INFCOM.
2004.
1354679][4]SunH,ZhaungY,ChaoHJ.
Aprincipalcomponentsanalysis-basedrobustDDoSdefensesystem.
In:Proc.
oftheIEEEInt'lConf.
onCommunications.
Beijing,2008.
16631669.
http://ieeexplore.
ieee.
org/xpl/freeabs_all.
jsparnumber=4533357[doi:10.
1109/ICC.
2008.
321][5]JinC,WangHN,ShinKG.
Hop-Countfiltering:AneffectivedefenseagainstspoofedDdoStraffic.
In:Proc.
ofthe10thACMConf.
onComputerandCommunicationsSecurity.
Washington,2003.
3041.
http://dl.
acm.
org/citation.
cfmid=948116[doi:10.
1145/948109.
948116][6]PengT,LeckieC,RamamohanaraoK.
Protectionfromdistributeddenialofserviceattacksusinghistory-basedIPfiltering.
In:Proc.
oftheIEEEInt'lConf.
onCommunications.
Anchorage,2003.
482486.
http://ieeexplore.
ieee.
org/Xplore/login.
jspurl=http%3A%2F%2Fieeexplore.
ieee.
org%2Fiel5%2F8564%2F27113%2F01204223.
pdf%3Farnumber%3D1204223&authDecision=-203[doi:10.
1109/ICC.
2003.
1204223][7]DittrichD.
http://staff.
washington.
edu/dittrich/misc/tfn.
analysis.
txt.
1999.
[8]BarlowJ.
http://packetstormsecurity.
org/distributed/TFN2k_Analysis-1.
3.
txt.
2000.
[9]LiJ,MirkovicJ,WangMQ,ReiherP,ZhangLX.
SAVE:Sourceaddressvalidityenforcementprotocol.
In:Proc.
oftheINFOCOM.
NewYork,2002.
15571566.
http://ieeexplore.
ieee.
org/xpl/freeabs_all.
jsparnumber=1019407[doi:10.
1109/INFCOM.
2002.
1019407]肖军等:随机伪造源地址分布式拒绝服务攻击过滤2437[10]LeeH,KwonM,HaskerG,PerrigA.
BASE:AnincrementallydeployablemechanismforviableIPspoofingprevention.
In:Proc.
ofthe2ndACMSymp.
onInformation,ComputerandCommunicationSecurity.
Singapore,2007.
2031.
http://dl.
acm.
org/citation.
cfmid=1229293[doi:10.
1145/1229285.
1229293][11]CormenTH,LeiersonCE,RivestRL,SteinC.
IntroductiontoAlgorithms.
2nded.
,Cambridge:MITPressandMcGraw-Hill,2001.
101122.
[12]GongJ,PengYB,YangW,LiuWJ.
ReconstructingtheparameterformassiveabnormalTCPconnectionswithbloomfilter.
JournalofSoftware,2006,17(3):434444(inChinesewithEnglishabstract).
http://www.
jos.
org.
cn/1000-9825/17/434.
htm[doi:10.
1360/jos170434][13]ZouBX,LiuQ.
ARMA-Basedtrafficpredictionandoverloaddetectionofnetwork.
JournalofComputerResearchandDevelopment,2002,39(12):16451652(inChinesewithEnglishabstract).
[14]XuJ,LeeW.
SustainingavailabilityofWebservicesunderdistributeddenialofserviceattacks.
IEEETrans.
onComputers,2003,52(2):195208.
[doi:10.
1109/TC.
2003.
1176986][15]Ben-PoratU,Bremler-BarrA,LevyH.
EvaluatingthevulnerabilityofnetworkmechanismstosophisticatedDDoSattacks.
In:Proc.
oftheINFOCOM.
Phoenix,2008.
22972305.
http://ieeexplore.
ieee.
org/Xplore/login.
jspurl=http%3A%2F%2Fieeexplore.
ieee.
org%2Fiel5%2F4509594%2F4509595%2F04509893.
pdf%3Farnumber%3D4509893&authDecision=-203[doi:10.
1109/INFOCOM.
2008.
298][16]ArlittM,JinT.
Workloadcharacterizationofthe1998WorldCupWebsite.
HPLabsTechnicalReport,1999.
[17]http://mawi.
wide.
ad.
jp/[18]MirkoviJ,PrierG,ReiherP.
AttackingDDoSatthesource.
In:Proc.
oftheIEEEInt'lConf.
onNetworkProtocols.
Paris,2002.
312321.
http://dl.
acm.
org/citation.
cfmid=656169[19]Bremler-BarrA,LevyH.
Spoofingpreventionmethod.
In:Proc.
oftheINFOCOM.
2005.
http://ieeexplore.
ieee.
org/xpl/freeabs_all.
jsparnumber=1497921[doi:10.
1109/INFCOM.
2005.
1497921][20]LiuX,LiA,YangXW,WetherallD.
Passport:Secureandadoptablesourceauthentication.
In:Proc.
oftheUSENIXSymp.
onNetworkedSystemsDesignandImplementation.
2008.
365378.
http://dl.
acm.
org/citation.
cfmid=1387615[21]ParkK,LeeH.
Ontheeffectivenessofrouter-basedpacketfilteringfordistributedDoSattackpreventioninpower-lawInternets.
In:Proc.
oftheACMSIGCOMM.
SanDiego,2001.
1526.
http://dl.
acm.
org/citation.
cfmid=383061[doi:10.
1145/383059.
383061][22]IoannidisJ,BellovinSM.
Implementingpushback:Router-BaseddefenseagainstDDoSattacks.
In:Proc.
oftheNetworkandDistributedSystemSecurity(NDSS).
2002.
[23]YauDKY,LuiJCS,LiangF,YamY.
Defendingagainstdistributeddenial-of-serviceattackswithmax-minfairserver-centricrouterthrottles.
IEEETrans.
onNetworking,2005,13(1):2942.
[doi:10.
1109/TNET.
2004.
842221]附中文参考文献:[12]龚俭,彭艳兵,杨望,刘卫江.
基于BloomFilter的大规模异常TCP连接参数再现方法.
软件学报,2006,17(3):434444.
http://www.
jos.
org.
cn/1000-9825/17/434.
htm[doi:10.
1360/jos170434][13]邹柏贤,刘强.
基于ARMA模型的网络流量预测.
计算机研究与发展,2002,39(12):16451652.
肖军(1979-),男,江苏大丰人,博士生,CCF会员,主要研究领域为DDoS攻击检测,DDoS攻击过滤.
张永铮(1978-),男,博士,副研究员,CCF会员,主要研究领域为网络安全.
云晓春(1971-),男,博士,教授,博士生导师,主要研究领域为网络安全,互联网建模.
UCloud优刻得,新增1核1G内存AMD快杰云机型,服务器2元/首月,47元/年
UCloud优刻得近日针对全球大促活动进行了一次改版,这次改版更加优惠了,要比之前的优惠价格还要低一些,并且新增了1核心1G内存的快杰云服务器,2元/首年,47元/年,这个价格应该是目前市面上最低最便宜的云服务器产品了,有需要国内外便宜VPS云服务器的朋友可以关注一下。UCloud好不好,UCloud服务器怎么样?UCloud服务器值不值得购买UCloud是优刻得科技股份有限公司旗下拥有的云计算服...
LOCVPS-2021年6月香港便宜vps宽带升级,充值就送代金券,其它八折优惠!
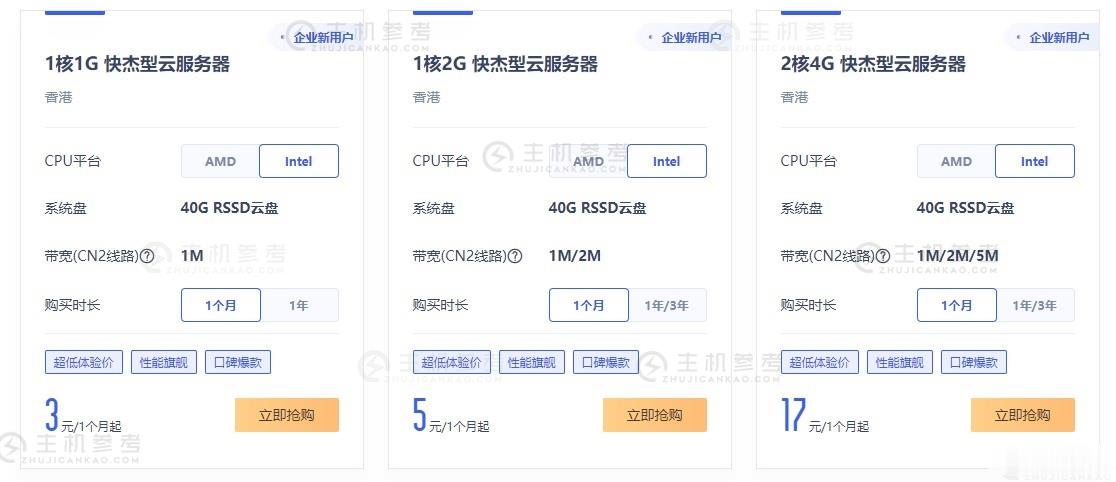
LOCVPS怎么样?LOCVPS是一家成立于2011年的稳定老牌国人商家,目前提供中国香港、韩国、美国、日本、新加坡、德国、荷兰等区域VPS服务器,所有机房Ping延迟低,国内速度优秀,非常适合建站和远程办公,所有机房Ping延迟低,国内速度优秀,非常适合做站。XEN架构产品的特点是小带宽无限流量、不超售!KVM架构是目前比较流行的虚拟化技术,大带宽,生态发展比较全面!所有大家可以根据自己业务需求...
legionbox:美国、德国和瑞士独立服务器,E5/16GB/1Gbps月流量10TB起/$69/月起
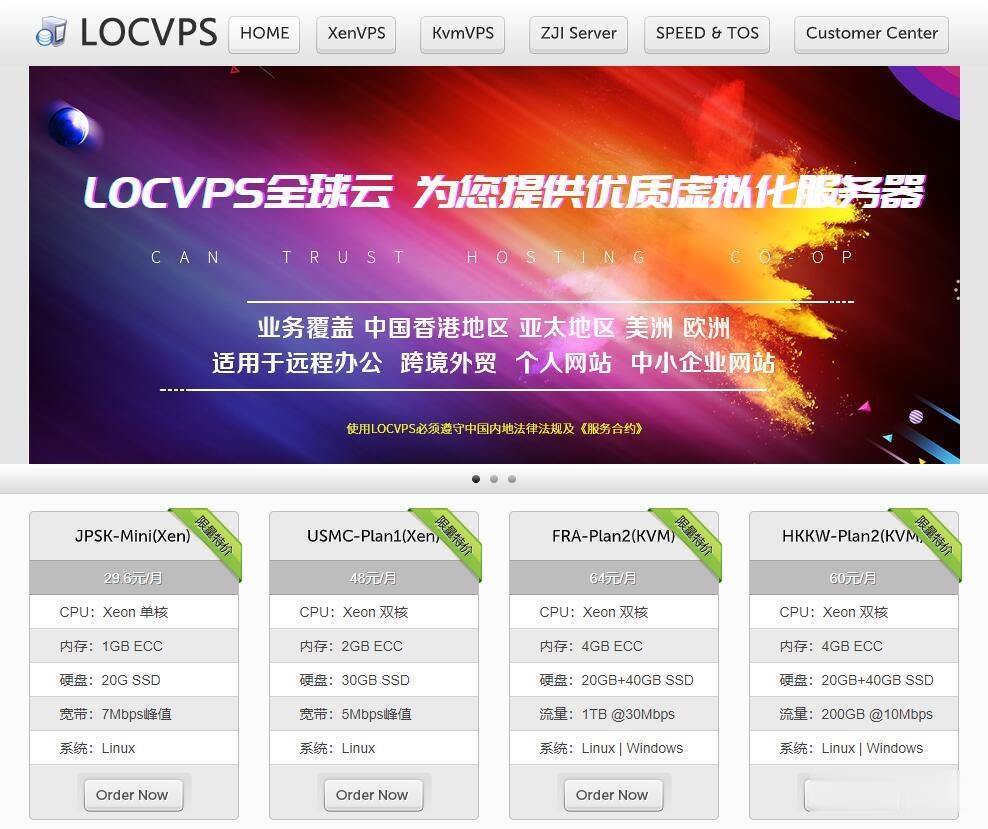
legionbox怎么样?legionbox是一家来自于澳大利亚的主机销售商,成立时间在2014年,属于比较老牌商家。主要提供VPS和独立服务器产品,数据中心包括美国洛杉矶、瑞士、德国和俄罗斯。其中VPS采用KVM和Xen架构虚拟技术,硬盘分机械硬盘和固态硬盘,系统支持Windows。当前商家有几款大硬盘的独立服务器,可选美国、德国和瑞士机房,有兴趣的可以看一下,付款方式有PAYPAL、BTC等。...
拒绝服务攻击为你推荐
-
aspweb服务器如何搭建简易Asp Web服务器企业信息查询系统官网怎么查企业信息是否在网上公示过ym.163.comfoxmail设置163免费企业邮箱sqlserver数据库如何登陆sql server中的数据库sqlserver2000挂起安装sqlserver2000时总提示有挂起操作!重庆杨家坪猪肉摊主杀人重庆忠县的猪肉市场应该好好整顿一下了。6月份我买到了母猪肉。今天好不容易才下定决心去买农贸市场买肉。重庆杨家坪猪肉摊主杀人重庆九龙坡区治安好么flashfxp下载怎么用flashFXP下载空间内容ipad代理如何贷款买IPAD抢米网什么意思抢小米手机