dedecms自动采集织梦CMS系统的采集功能不知道怎么采集软件。
dedecms自动采集 时间:2021-03-16 阅读:()
DEDE自动采集软件有什么副作用?缺点?
Dede采集功能目前还没有完善。自动采集插件也是存有bug 经本人用了。
发现采集的文章自动重复发到其他栏目。
也可以说是乱发情况。
其他倒没什么。
可能要等一阵子,给点时间来完善吧! dede还是很不错的!
DEDECMS的采集
节点基本信息 --} {dede:item name='U28网' imgurl='/upimg' imgdir='../upimg' language='gb2312' isref='no' refurl='' exptime='10' typeid='1' matchtype='string'} {/dede:item} {!-- 采集列表获取规则 --} {dede:list source='var' sourcetype='list' varstart='1' varend='3'} {dede:url value='/web-art/htmlbase/HTML/list_33_[var:分页] .html'}{/dede:url} {dede:need}{/dede:need} {dede:cannot}{/dede:cannot} {dede:linkarea} <!--新闻列表--> <div class="newslist"> <dl>[var:区域]<!--分页--> <div class="pages"> <div class="plist"> <a href='#'>首页</a>{/dede:linkarea} {/dede:list} {!-- 网页内容获取规则 --} {dede:art} {dede:sppage sptype='none'}{/dede:sppage} {dede:note field='dede_archives.sortrank' value='[var:内容]'ment='排序级别' isunit='' isdown=''} {dede:match}{/dede:match} {dede:function}@me = time();{/dede:function} {/dede:note} {dede:note field='dede_archives.pubdate' value='[var:内容]'ment='发布时间' isunit='' isdown=''} {dede:match}{/dede:match} {dede:function}@me = ( @me!="" ? GetMkTime(@me) : time());{/dede:function} {/dede:note} {dede:note field='dede_archives.litpic' value='[var:内容]'ment='缩略图' isunit='' isdown=''} {dede:match}{/dede:match} {dede:function}@me = @litpic;{/dede:function} {/dede:note} {dede:note field='dede_archives.title' value='[var:内容]'ment='文章标题' isunit='' isdown=''} {dede:match}<title>[var:内容]</title>{/dede:match} {dede:trim} 织梦内容管理系统{/dede:trim} {dede:function}{/dede:function} {/dede:note} {dede:note field='dede_archives.writer' value='[var:内容]'ment='文章作者' isunit='' isdown=''} {dede:match}<STRONG>作者:</STRONG>[var:内容]<STRONG>时间:</STRONG>{/dede:match}dedecms织梦 怎么采集整个页面
这就简单多了,不用什么规则, 直接找到中间部分的容器名称,以它为开始,以尾部容器名称为结束就行了。如果说不会找这些的话,咳,,,这就不好说了。
,
谁会dedecms的采集功能
在网站建设初期,若CMS系统没有一个采集功能,那更新文章的工作量是可想而知的,使用采集功能可以方便地在网站中加入丰富的内容。在左侧的面板列表中依次选择“采集管理”→“采集节点管理”,接着点击“添加新节点”按钮进入采集规则编写页面(如图6)。
在编写采集规则时,是用“[Var:内容]”标记来表示所有的变量,例如编写文章标题的采集规则,通过查看采集页面源文件发现其代码如下:
<span style="font-size:12pt"><b>快速上手 企业建站DedeCms一马当先”</b></span>
那么“文章标题”中的采集规则就可写为<span style="font-size:12pt"><b>[Var:内容]</b></span>,非常的简单。
dedecms采集规则
|
织梦CMS系统的采集功能不知道怎么采集软件。
可以到管理后台的文件夹中找到 empletsco_add_step0.htm 这个文件后,用dreamweaver 打开编辑找到如下代码:$dsql->SetQuery("Select id,typename From `#@__channeltype` where id in(1,2) order by id asc ");将其修改为:$dsql->SetQuery("Select id,typename From `#@__channeltype` where id in(1,2,3) order by id asc "); 就可以了!
- dedecms自动采集织梦CMS系统的采集功能不知道怎么采集软件。相关文档
- 中航dedecms自动采集
- 力创科技产品系列之-------EDA9011D
- 投标人dedecms自动采集
- 采集dedecms自动采集
- 采集dedecms自动采集
- 投标人dedecms自动采集
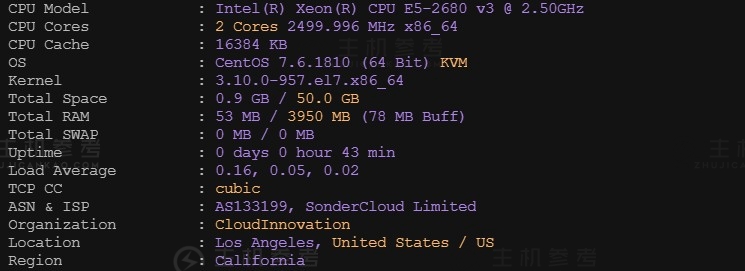
恒创科技SonderCloud,美国VPS综合性能测评报告,美国洛杉矶机房,CN2+BGP优质线路,2核4G内存10Mbps带宽,适用于稳定建站业务需求
最近主机参考拿到了一台恒创科技的美国VPS云服务器测试机器,那具体恒创科技美国云服务器性能到底怎么样呢?主机参考进行了一番VPS测评,大家可以参考一下,总体来说还是非常不错的,是值得购买的。非常适用于稳定建站业务需求。恒创科技服务器怎么样?恒创科技服务器好不好?henghost怎么样?henghost值不值得购买?SonderCloud服务器好不好?恒创科技henghost值不值得购买?恒创科技是...
pacificrack:超级秒杀,VPS低至$7.2/年,美国洛杉矶VPS,1Gbps带宽
pacificrack又追加了3款特价便宜vps搞促销,而且是直接7折优惠(一次性),低至年付7.2美元。这是本月第3波便宜vps了。熟悉pacificrack的知道机房是QN的洛杉矶,接入1Gbps带宽,KVM虚拟,纯SSD RAID10,自带一个IPv4。官方网站:https://pacificrack.com支持PayPal、支付宝等方式付款7折秒杀优惠码:R3UWUYF01T内存CPUSS...
CloudCone(20美元/年)大硬盘VPS云服务器,KVM虚拟架构,1核心1G内存1Gbps带宽
近日CloudCone商家对旗下的大硬盘VPS云服务器进行了少量库存补货,也是悄悄推送了一批便宜VPS云服务器产品,此前较受欢迎的特价20美元/年、1核心1G内存1Gbps带宽的VPS云服务器也有少量库存,有需要美国便宜大硬盘VPS云服务器的朋友可以关注一下。CloudCone怎么样?CloudCone服务器好不好?CloudCone值不值得购买?CloudCone是一家成立于2017年的美国服务...
dedecms自动采集为你推荐
-
目录盐城市第八届人大常委会第五次会议纪要thinksns请问除了discuz、ThinkSNS、wordpress、phpwind之外,还有什么类似这样的开波音737起飞爆胎客机起飞的时候时速是多少?重庆400年老树穿楼生长重庆轻轨穿过居民楼在哪里,从解放碑怎么去pintang深圳御品堂怎么才能保证他们卖的东西都是有机食品?网络u盘你们谁知道网络硬盘怎么用站点管理工行网点现场管理人员主要职责是什么powerbydedecms如何去掉织梦网站底部的powered by dedecms方法店铺统计淘宝店运营每天需要统计哪些数据,我要做个表格joomla教程如何获得 Joomla,2.5中 itemid 的值