分区OceanBase设计规范与数据架构指南-v2(1)-3.docx
OceanBase设计规范不数据架构指南
文档修订历史
1 OceanBase1.0简介
自从E.F.Codd于1970年首次提出关系数据库模型后关系数据库便以其易于使用的接口、完善的功能和生态而成为了IT领域必需的基础设施广泛应用在各行各业包括金融、 电信、房地产、农林牧渔、制造业等等。关系数据库经过了40多年的发展涌现了Oracle、 SQL Server、 DB2等优秀的商业数据库产品开源领域也不乏MySQL、 PostgreSQL这样的精品。
但是随着互联网行业和大数据的兴起数据量和并发访问量呈现指数级的增长囿于关系数据库的架构原先运行良好的关系数据库遭遇了严峻的挑战极度高昂的总体拥有成本、捉襟见肘的扩展能力、荏弱无力的大数据处理性能等等。
于是NoSQL应运而生 Hbase、 Cassandra等系统如雨后春笋般冒出这些系统多采取分布式架构易于扩展及容灾结合大数据处理系统如Hadoop等可以很容易处理量级非常大的数据这一时让NoSQL风光无两大有取代SQL之势让人看不清NoSQL系统的边界。很多公司尝试将核心系统迁移到新兴的NoSQL系统上 比如Facebook就尝试将部份核心系统迁移到Cassandra。在迁移过程中人们发现NoSQL所获得针对SQL的优势其实是以牺牲一些非常重要的功能来获取的如NoSQL一般不支持事务或只支持非常有限的事务这极大的增加了业务系统的复杂度在传统的OLTP领域采取NoSQL系统基本上是不可以接受的。
阿里巴巴/蚂蚁金服的关系数据库使用场景极其严苛有着全球最大的并发量需求在可靠性方面需要做到单机、机架、机房甚至是地区级别的容灾恢复能力。早期使用共享存储、小型机等高端硬件也只能部分满足我们在性能和可靠性上的需求而且随着业务的发展这种IOE架构很快就成为瓶颈。
我们能不能结合新兴分布式系统和传统关系型数据库的优点既拥有传统关系型数据库在功能上的优势同时具备分布式系统的可扩展性、高可靠性等特征 OceanBase即是以此为出发点开始打造一个分布式关系型数据库。OceanBase从2010年6月份立项开始到今天已经发展了六年多的时间构建在普通服务器组成的分布式集群之上具备可扩展、高可用、高性能、低成本以及多租户等核心技术优势。 目前已经成功应用于蚂蚁金服的会员、交易、支付、账务、计费等核心系统和网商银行等业务系统。 OceanBase经历了多年201 1 -2016双十一的严格考验特别是在刚刚过去的2016年双十一用户每一笔支付订单背后的数据和事务处理都由OceanBase完成创造了每秒12万笔支付峰值的世界记录。
2 OceanBase架构及优势
互联网对传统关系型数据库的挑战主要有两个方面
一是可扩展性。传统关系型数据库本质上是单机系统其扩展方法一般为向上扩展 即换性能更好的机器 阿里巴巴/蚂蚁金服随着业务的发展也一路扩容到小型机但这种方式对于互联网行业来说其扩容周期短成本很高。另外一种方法为水平拆分 即分库分表这也是目前广泛应用的扩展方式这极大的增加了业务复杂度相当于将数据库的一部份工作转嫁到业务方从各大公司都有自己的中间件来处理这一层业务即可见一斑。
二是可靠性。传统关系型数据库一般采取主备形式来解决高可用的问题。主备之间数据同步主要有两种方式一是最大保护模式需要主备均写入成功后才算成功这样可以保证数据一致性但一旦备机宕机或网络抖动即可造成不可用。另外是最大性能/最大可用模式这种模式下只要主写入成功即可算成功此时如果主机宕机但有数据尚未同步到同机 即可造成数据不一致或丢失。解决这个问题的传统方案是采取高端商用硬件如共享存储通过高可靠的硬件来解决软件上的不可靠但这样也会存在一些问题比如共享存储无法解决或很难解决机房容灾问题。
OceanBase的目标是要解决这两方面的问题设计原则
使用普通PC服务器丌使用共享存储、小型机等高端硬件。
磁盘、服务器、网络、机房甚至是某个地区的IT基础设施并非持续可用。
关系型数据库支持传统关系型数据库的功能比如SQL、跨行跨表事务。
可水平扩展扩展时对应用透明。
高可靠、数据强一致单机、机房甚至地区故障时可自劢恢复。
高性能。
根据目标 OceanBase需要解决三个方面的问题
一是传统关系型数据库的功能。 传统关系数据库经过多年的发展功能极其丰富SQL的表达能力、事务支持等对应用非常友好并且形成了自己的生态。OceanBase需要从头开始实现一个可能的选择是基于某个开源数据库来实现但经过分析基于控制力、架构等原因我们最终没有选择这条路而是完全自主研发。
二是分布式一致性问题。 分布式系统往往通过多个副本来实现数据高可靠以及高可用如何保证多个副本之间的数据一致性是一个非常复杂的问题。最大保护模式的基础是高可用的硬件及网络链路这些在OceanBase中都不存在。三是分布式事务的问题。 很多分布式系统都弱化了这个功能 只支持单行事务这样的选择一方面是工程实现难度较高 另外一方面是对性能影响较大OceanBase如何支持跨机分布式事务并保证性能是一个很大的问题。
OceanBase解决这些问题也并非一蹴而就而是着眼于业务需求通过六年的发展才逐步解决了这些问题 OceanBase总体架构
如上图所示一个OceanBase集群由多台分布在不同机房的ObServer组成每台ObServer都是对等关系图中分布在三个IDC意味着存储了三个副本每个IDC是镜像的关系可抵御少数派IDC失败。
每个表可以以分区表(即create table中的partition by子句)的形式分成多个分区 图中一个表被分成了P1~P88个分区每个分区可以分布在不同的ObServer上每个分区的三个副本分布在不同IDC的不同ObServer上其中一个副本被选举为Leader如图中P2,P3的Leader在IDC1的第一台ObServer上。只有分区的Leader才可以对外提供查询和更新服务。ObProxy是一个无状态服务它接收应用的请求并根据应用请求中的分区字段来判断这个请求属于哪个分区然后将其路由到这个分区Leader所在的服务器。让用户无需关心数据分片的细节数据所在的具体位置对外的表现仍然是一个单机的数据库。 OceanBase兼容MySQL协议通过ObProxy 用户可以使用任意语言的MySQL客户端来连接OceanBase。
经过六年多的发展 OceanBase初步实现了当初定下的目标在架构上具有诸多优势
2.1 .1 高效的存储引擎
OceanBase采用的是share-nothi ng的分布式架构每个OBServer都是对等的管理不同的数据分区。单机的存储引擎采取读写分离的架构将当前更新的动态数据存入内存称为MemTable存量的基线数据存在磁盘称为SSTab le。一个Partitio n的所有数据(基线数据+增量数据+事务日志)都放在一个OBServer中因此针对一个Partition的读写操作不会有跨机的操作数据的写入也分布到多点并行执行。
读写分离的存储结构带来很多好处因为有大量的静态基线数据可以很方便对其进行压缩减少存储成本另外做行级缓存也不用担心写入带来的缓存失效问题。缺点是读的路径变长数据需要实时合并可能带来性能问题OceanBase采用了很多的优化手段 比如bloom fi lter cache对不存在的行做过滤(insert row判断行是否存在无需IO操作)尽量优先读取更新的内容(Active MemTable)如果发现用户读取的列已经读取到则无需进一步读取基线数据进行合并。
由于增量数据写在内存中所以内存写到一定量后需要和基线数据合并而生成新的基线这个过程我们称之为合并合并会造成一些额外的压力可能对客户的请求有影响所以我们采取一种称之为轮转合并的策略即将OceanBase的多个IDC中的其中一个IDC的流量切走进行合并待合并完成后再将流量切到已合并的IDC上这样可以避免对业务的影响同时这种策略也可以用在升级维护中 当需要进行版本升级的时候可以将其中一台ObServer的流量切走进行升级升级完成后逐步灰度切流一旦出现问题即可快速无损回滚。
2.1 .2可扩展性
分布式系统通过数据分区来实现可扩展性主流数据分区方法有两种哈希分区和范围分区。分布式Key-Value系统、数据库分库分表本质上都是哈希分区而主流的分布式表格系统如Bigtable、开源的HBase往往采用范围分区。范围分布很容易出现分区不均匀的情况因此需要支持分区动态分裂与合并。
关系数据库的数据分布方法则更为灵活以Oracle分区表为例除了支持简单的哈希分区、范围分区还支持l ist分区、 Interval分区 以及二级组合分区。另外关系数据库还支持单个分区的操作例如删除某个分区构建针对单个分区的局部索引、设置压缩方法等等。
OceanBase引入了传统关系型数据库中的数据分区表的方法语法上也兼容传统数据库创建分区表的方法这种设计兼具分布式系统的扩展性和关系数据库的易用性和灵活性符合DBA的使用习惯。
OceanBase支持在线线性扩展 当集群存储容量或是处理能力不足时可以随时加入新的OBServer系统会自动进行数据迁移根据机器的处理能力将合适的数据分区迁移到新加入的机器上同样在系统容量充足和处理能力富余时也可以将机器下线降低成本在类似于双1 1大促之类的活动中可以提供良好的弹性伸缩能力。
对一个数据分区所有读写操作都在其所在的OBServer完成涉及多个数据分区的事务会采用两阶段提交的方式在多个OBServer上执行。在OceanBase中事务分为几种类型
单分区事务。和传统的关系数据库一样属亍单机事务丌需要走两阶段提交协议。 单机多分区事务。需要走两阶段提交协议丏针对单机做了与门的优化。
多机多分区事务。需要走完整的两阶段提交协议。
分布式事务会增加事务的延时 OceanBase采取了很多措施来尽量避免分布式事务 比如支持表格组table group来尽可能地减少分布式事务。表格组用于聚集经常一起访问的多张表格。例如有用户基本信息表user和用户商品表use r_ite m 这两张表格都按照用户编号哈希分布 只需要将二者设置为相同的表格组系统后台就会自动将同一个用户所在的user表分区和user_item表分区调度到同一台服务器。这样即使操作某个用户的多张表格也不会产生跨机事务。
2.1 .3高可靠
OceanBase系统中的每个分区都维护了多个副本一般为三个且部署到三个不同的数据中心Zo ne 。整个系统中有成百上千万个分区这些分区的多个副本之间通过Paxos协议进行日志同步。每个分区和它的副本构成一个独立的Paxos复制组Paxos Repl ication Group其中一个副本为主Leader其它副本为备Fol lower 。每台ObServer服务的一部分分区为Leader一部分分区为Fol lower。当ObServer出现故障时 Fol lower分区不受影响Leader分区的写服务短时间内会受到影响直到通过Paxos协议将该分区的某个Fol lower选为新的Leader为止整个过程大约持续30秒左右。
通过引入Paxos协议可以保证在数据强一致的情况下具有极高的可用性及性能。
2.1 .4多租户
OceanBase1 .0系统作为一个扩展性很强的集群系统设计的目标就包括使用一个集群支持多个业务系统也就是通常所说的多租户特性。数据库多租户概念 Oracle是从12C版本开始支持的在Oracle里面最重要的两个概念是CDBContainer DB和PDBPluggable DB 。对于OceanBase1 .0来说多租户同样是一个非常重要的特性是数据库对象管理和资源管理的基础对于系统运维尤其是对于将来的云数据库的运维也有着重要的影响。
OceanBase1 .0的多租户特性主要包含如下几点
将多个数据库实例管理和运维的成本和复杂性降低到和一个数据库实例相当。 1 .0的其中一个优势就是大集群的规模优势取得这个优势的一个重要原因就是原先的多个数据库实例在1 .0版本中管理的成本相当亍一个实例。o 充分利用系统资源使得同样的资源可以服务更多的业务。通过将波峰、波谷期丌同的业务系统部署到一个集群以实现对系统资源最大限度的使用。o 租户乊间的隔离性在数据安全方面丌允许跨租户的数据访问确保用户的数据资产没有泄露的风险在资源使用方面表现为租户“独占”其资源配额该租户对应的前端应用无论是响应时间还是TPS/QPS都比较平稳丌会受到其他租户负载轻重的影响。
OceanBase所采取的隔离方式既能充分利用资源又可以获取非常高的资源整合度。多租户的特性使得OceanBase非常适合云计算。
2.1 .5 MySQL兼容
关系数据库经过多年的发展其周边生态十分重要大量的现有业务都构建在现有的关系型数据库上 OceanBase采取和MySQL兼容的方式来让基于MySQL的应用程序可以不经修改就能运行在OceanBase之上。
OceanBase在兼容性方面做了大量的工作
接口层面主流的数据库产品都支持标准的接口如JDBC、 ODBC、 .net Provider。OceanBase广泛使用的接口主要是JDBC和ODBC。通过丌断增强在前后台协议上和MySQL的兼容性目前使用MySQL的驱劢就可以无障碍地访问OceanBase。 数据模式层面完整地支持了数据库database、表 table、视图view、自增列autoincrement 等SQL标准的以及MySQL与有的数据模式并丏在数据库系统中实现了多租户multi-tenant 。原先基亍丌同MySQL实例的业务可以无缝地迁移到一个OceanBase集群。
语句层面目前的主流产品在SQL语句层面大多遵守ISO/IEC9075标准定义的一系列规范最新的版本是SQL2011 。对比乊前的版本 1 .0版本大幅度增加了对标准SQL语句的支持同时扩展了支持了MySQL中有但非标准的语句。
数据类型层面数据类型是基础设施对兼容性的影响非常大涉及的细节非常多。在
1 .0版本的开发过程中为了使得表达式计算的表现和MySQL一致我们在数据类型的兼容性方面投入了大量的人力也帮劣MySQL产品纠正了丌少错误的表现。
事务层面系统支持的事务隔离级别以及并发控制方面的表现。OceanBase采用的是多版本的并发控制协议读写丌等待支持Read Committed隔离级别。
3 OceanBase1.0开发设计规约
数据库开发设计规约在新系统上线初期启到了丼足轻重的作用。正犹如制订交通法规表面上是要限制行车权实际上是保障公众的人身安全。试想如果没有限速没有红绿灯没有靠右行驶条款谁还敢上路。
OB的开发规约的目标
防患未然降低故障率和维护成本。
标准统一提升协作效率。
追求卓越的工匠精神打磨精品代码。
3.1 .1建表规约
1 . 【强制】表达是与否概念的字段数据类型是unsigned tinyi nt 1表示是 0表示否 值的内容要统一所有应用值要统一。
正例表达逻辑删除的字段名is_deleted 1表示删除 0表示未删除。
2. 【强制】表名、字段名必须使用小写字母或数字。禁止出现数字开头禁止两个下划线中间只出现数字。数据库字段名的修改代价很大所以字段名称需要慎重考虑。
说明MySQL在Wi ndows下不区分大小写但在Linux下默认是区分大小写。因此数据库名、表名、字段名都不允许出现任何大写字母避免节外生枝。
正例 getter_admin task_config level3_name
反例 Gette rAdmin taskCo nfig level_3_name
3. 【强制】表名不使用复数名词。
说明表名应该仅仅表示表里面的实体内容不应该表示实体数量
4. 【强制】禁用保留字如desc、 range、 match、 delayed等 OB1 .0的保留字见
5. 【强制】唯一索引名为uk_字段名普通索引名则为idx_字段名。说明 uk_即unique key idx_即index的简称。
6. 【强制】小数类型为decimal 禁止使用float和double。
说明 float和double在存储的时候存在精度损失的问题很可能在值的比较时得到不正确的结果。
- 分区OceanBase设计规范与数据架构指南-v2(1)-3.docx相关文档
- Aquaticoceanbase
- 项目名称:面向大型银行应用的高通量可伸缩分布式数据库系统
- 金融oceanbase
- 股民oceanbase
- dimensionlessoceanbase
- 发行人oceanbase
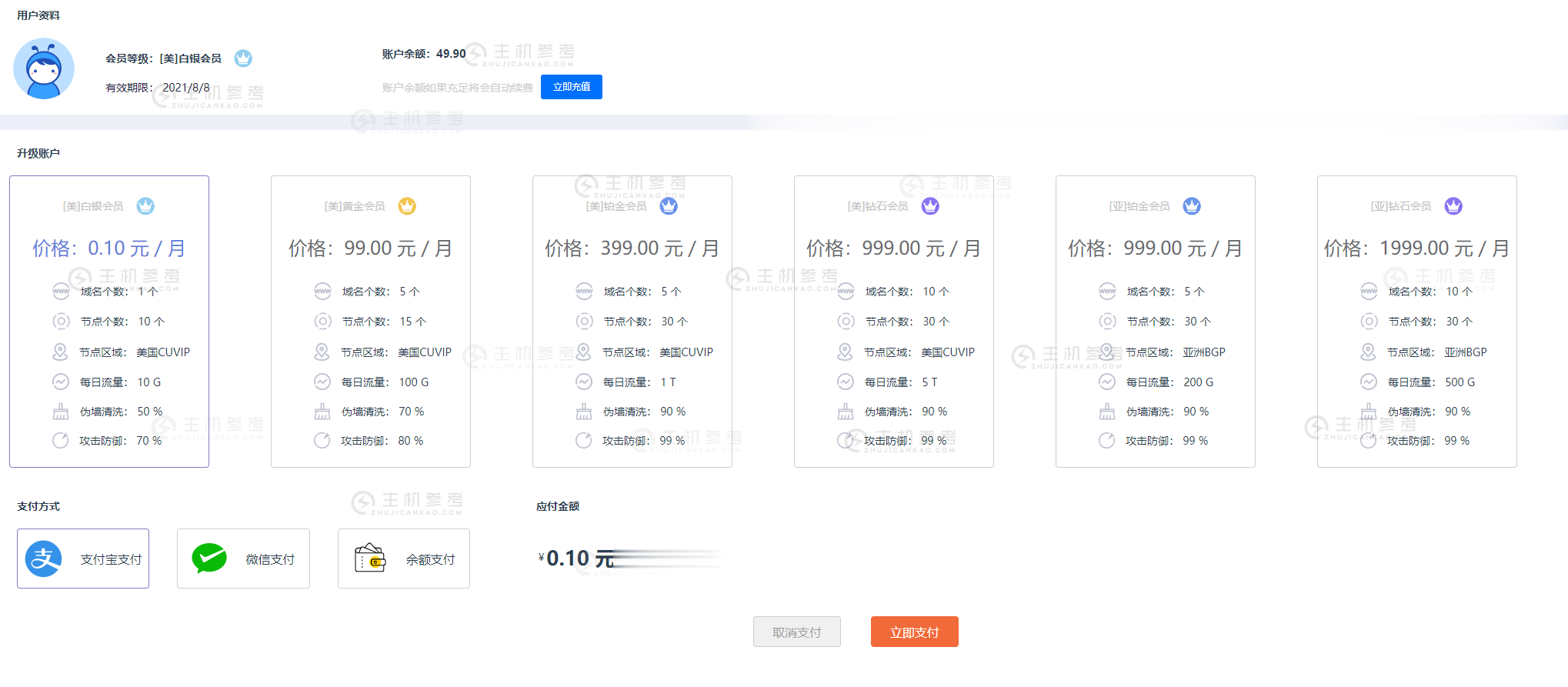
FBICDN,0.1元解决伪墙/假墙攻击,超500 Gbps DDos 防御,每天免费流量高达100G,免费高防网站加速服务
最近很多网站都遭受到了伪墙/假墙攻击,导致网站流量大跌,间歇性打不开网站。这是一种新型的攻击方式,攻击者利用GWF规则漏洞,使用国内服务器绑定host的方式来触发GWF的自动过滤机制,造成GWF暂时性屏蔽你的网站和服务器IP(大概15分钟左右),使你的网站在国内无法打开,如果攻击请求不断,那么你的网站就会是一个一直无法正常访问的状态。常规解决办法:1,快速备案后使用国内服务器,2,使用国内免备案服...
Krypt($120/年),2vCPU/2GB/60GB SSD/3TB
Krypt这两天发布了ION平台9月份优惠信息,提供一款特选套餐年付120美元(原价$162/年),开设在洛杉矶或者圣何塞机房,支持Windows或者Linux操作系统。ion.kryptcloud.com是Krypt机房上线的云主机平台,主要提供基于KVM架构云主机产品,相对于KT主站云服务器要便宜很多,产品可选洛杉矶、圣何塞或者新加坡等地机房。洛杉矶机房CPU:2 cores内存:2GB硬盘:...
天上云:香港大带宽物理机服务器572元;20Mbps带宽!三网CN2线路
天上云服务器怎么样?天上云是国人商家,成都天上云网络科技有限公司,专注于香港、美国海外云服务器的产品,有多年的运维维护经验。世界这么大 靠谱最重,我们7*24H为您提供服务,贴心售后服务,安心、省事儿、稳定、靠谱。目前,天上云香港大带宽物理机服务器572元;20Mbps带宽!三网CN2线路,香港沙田数据中心!点击进入:天上云官方网站地址香港沙田数据中心!线路说明 :去程中国电信CN2 +中国联通+...

-
硬盘工作原理硬盘的读写原理广东GDP破10万亿__年,我国国内生产总值(GDP)首破10万亿元.目前,我国经济总量排名世界第___位?bbs.99nets.com怎么打造完美SFwww.7160.com电影网站有那些haokandianyingwang谁有好看电影网站啊、要无毒播放速度快的、在线等www.vtigu.com初三了,为什么考试的数学题都那么难,我最多也就135,最后一道选择,填空啊根本没法做,最后几道大题倒ww.66bobo.com有的网址直接输入***.com就行了,不用WWW, 为什么?dadi.tv海信电视机上出现英文tvservice是什么意思?javlibrary.comImage Library Sell Photos Digital Photos Photo Sharing Photo Restoration Digital Photos Photo Albumswww.mfav.org海关编码在线查询http://www.ccpit.org.c