Dresdenhttp
http错误403-禁止访问 时间:2021-04-09 阅读:()
GPUTechnologyConference,May14-17,2012McEneryConventionCenter,SanJose,Californiawww.
gputechconf.
comSessionsonComputationalPhysics(subjecttochange)IMPORTANT:Visithttp://www.
gputechconf.
com/page/sessions.
htmlforthemostup-to-dateschedule.
S0268-VirtualProcessEngineering-RealtimeSimulationofMultiphaseSystemsWeiGe(InstituteofProcessEngineering,ChineseAcademyofSciences)Day:Tuesday,05/15|Time:9:00am-9:50amTopicAreas:ComputationalFluidDynamics;MolecularDynamics;ComputationalPhysics;Algorithms&NumericalTechniquesSessionLevel:AdvancedRealtimesimulationandvirtualrealitywithquantitativelycorrectphysicsforindustrialprocesseswithmulti-scaleandmultiphasesystemisoncearemotedreamforprocessengineering,butisbecomingtruenowwithCPU-GPUhybridsupercomputing.
NumericalandvisualizationmethodsforsuchsimulationsonthousandsofGPUswillbereportedwithapplicationsinchemicalandenergyindustries.
S0258-Sailfish:LatticeBoltzmannFluidSimulationswithGPUsandPythonMichalJanuszewski(UniversityofSilesiainKatowice;GoogleSwitzerland)Day:Tuesday,05/15|Time:9:30am-9:55amTopicAreas:ComputationalFluidDynamics;ComputationalPhysics;DevelopmentTools&LibrariesSessionLevel:IntermediateLearnhowRun-TimeCodeGeneration(RTCG)techniquesallowedforfastdevelopmentofalatticeBoltzmann(LB)fluiddynamicssolvercalledSailfish.
Sailfishiscompletelyopensource,supportsawidevarietyofLBmodels(singleandmultiplerelaxationtimes,theentropicmodel;singleandbinaryfluids)andcantakeadvantageofmultipleGPUs.
EventhoughtheprojectiswrittenpredominantlyinPython,noperformancecompromisesaremade.
ThistalkwillintroducethebasicdesignprinciplesofSailfishandillustratehowRTCGallowstoexploitthepowerofGPUswithminimalprogrammereffort.
S0031-UnstructuredGridNumberingSchemesforGPUCoalescingRequirementsAndrewCorrigan(NavalResearchLaboratory),JohannDahm(UniversityofMichigan)Day:Tuesday,05/15|Time:10:00am-10:25amTopicAreas:ComputationalFluidDynamics;Algorithms&NumericalTechniques;ComputationalPhysicsSessionLevel:AdvancedLearnhowtoachievehighperformanceforcomputationalfluiddynamics(CFD)solversoverunstructuredgridsusingnumberingschemestailoredforGPUcoalescingrequirements.
Usingthesetechniques,unstructuredgridCFDsolverscanmakemoreeffectiveuseofmemorybandwidth,whichisanotherwisesignificantperformancebottleneckthathassofarledtorelativelylimitedperformancegainsonGPUsincomparisontostructuredgridCFDsolvers.
PerformancebenchmarkswillbeshownusingtheJetEngineNoiseReduction(JENRE)code.
S0321-GPU-BasedMonteCarloRayTracingSimulationforSolarPowerPlantsClausNilsson(TietronixSoftware,Inc.
),MichelIzygon(TietronixSoftware,Inc.
)Day:Tuesday,05/15|Time:2:00pm-2:25pmTopicAreas:EnergyExploration;ComputationalPhysics;RayTracingSessionLevel:BeginnerLearnaboutrealtimesimulationsofConcentratingThermalSolarPowerusingGPUtechnologytoenableperformanceoptimizationoftheseutilityscaleplants.
ByleveragingthepowerofGPUsandtheparallelaspectofthefieldofthousandssun-trackingmirrors,wehavebeensuccessfulincuttingthecomputationtimebyordersofmagnitudeversusthepreviouslyrequiredminutesandhoursruntime.
WewillpresentanoverviewoftheproblemdomainanddescribehowweusedtheGPUtoderiveaMonteCarlophysicsraytracingmethodtosimulatethefluxreflectedbythemirrorsontothesolarreceiver.
S0046-ApplicationoftheGPUtoaTwo-PartComputationalElectromagneticAlgorithmEricDunn(SAIC)Day:Tuesday,05/15|Time:2:30pm-2:55pmTopicAreas:ComputationalPhysics;Algorithms&NumericalTechniques;RayTracingSessionLevel:BeginnerTheshootingandbouncingray(SBR)methodisonewaytosimulateelectromagneticfieldradiation.
Likeallmethods,therearecertainproblemswhereitdoesnotyieldaccurateresults.
Inthispresentation,wewillexplainonesuchcasethatconsistsofanantennaresonatingbetweentwometalplates.
Wewilldiscusshowweusedthegraphicsprocessingunit(GPU)toseparatetheproblemintotwoparts.
EachpartissimulatedindividuallywithSBRproducinganimprovedresult.
SuchaGPU-accelerated,two-partapproachcanbeappliedtoothermoregeneralhybridsimulations.
S0379-GPU-basedHigh-PerformanceSimulationsforSpintronicsJanJacob(UniversityofHamburg-InstituteofAppliedPhysicsandMicrostructureResearchCenter)Day:Tuesday,05/15|Time:2:30pm-2:55pmTopicAreas:GeneralInterest;ComputationalPhysics;ApplicationDesign&PortingTechniquesSessionLevel:IntermediateThejointutilizationoftheelectron'schargeandspinin"spintronics"representsapromisingtechnologyfordataprocessingandstorageinnanostructures.
Thecomplexquantumeffectslikethespin-Halleffectinthesedevicesrequiredemandingnumericalsimulationsprovidingaconvenientlinkbetweenidealizedanalyticalmodelstooftenverycomplexresultsfrommeasurements.
ThesimulationsinvolvingmultiplicationsandinversionsoflargematricesprovideanidealshowcaseforperformancegainbyemployingGPGPUsintheexecutionofthealgebraicroutinesonthesematricesincomputingenvironmentswithsharedexecutionofalgorithmsonmultiplenodeswithmultipleGPGPUsandCPUcores.
S0036-MultiparticleCollisionDynamicsonGPUsElmarWestphal(ForschungszentrumJuelich)Day:Tuesday,05/15|Time:3:00pm-3:50pmTopicAreas:ComputationalPhysics;ComputationalFluidDynamics;MolecularDynamicsSessionLevel:IntermediateSeehowweemployGPUstosimulatetheinteractionofmillionsofsolventandsoluteparticlesofafluidsystem.
Oftenthedomainoflargeclustersystem,themosttimeconsumingpartofoursimulationscannowbedoneondesktopPCsinreasonabletime.
ThiscontributionshowshowGPUscaneffectivelybeusedtoaccelerateexistingprogramsandhowtechniqueslikestreamingandincreaseddatalocalitysignificantlyenhancecalculationthroughput.
ItalsoshowshowaGPU-optimizedprogramstructureyieldsusuallyexpensiveadditionalfunctionality"almostfree".
Furthermore,awell-scalingsingle-node/multi-GPUimplementationoftheprogramispresented.
S0067-PIConGPU-Bringinglarge-scaleLaserPlasmaSimulationstoGPUSupercomputingMichaelBussmann(Helmholtz-ZentrumDresden-Rossendorf),GuidoJuckeland(CenterforInformationServicesandHighPerformanceComputing,TechnicalUniversityDresden)Day:Tuesday,05/15|Time:3:00pm-3:50pmTopicAreas:ComputationalPhysics;Algorithms&NumericalTechniques;ApplicationDesign&PortingTechniques;SupercomputingSessionLevel:AdvancedWithpowerfullasersbreakingthePetawattbarrier,applicationsforlaser-acceleratedparticlebeamsaregainingmoreinterestthanever.
Ionbeamsacceleratedbyintenselaserpulsesfosternewwaysoftreatingcancerandmakethemavailabletomorepeoplethaneverbefore.
Laser-generatedelectronbeamscandrivenewcompactx-raysourcestocreatesnapshotsofultrafastprocessesinmaterials.
WithPIConGPUlaser-drivenparticleaccelerationcanbecomputedinhourscomparedtoweeksonstandardCPUclusters.
WepresentthetechniquesbehindPIConGPU,detailedperformanceanalysisandthebenefitsofPIConGPUforreal-worldphysicscases.
S0221-1024BitParallelRationalArithmeticOperatorsfortheGPURobertZigon(BeckmanCoulter)Day:Tuesday,05/15|Time:4:00pm-4:50pmTopicAreas:Algorithms&NumericalTechniques;ComputationalPhysicsSessionLevel:IntermediateLearnhowtocreateasetofrationalarithmeticoperatorsthatmanipulate1024bitoperandsonaTeslaC2050.
TheseoperatorsareusedtocreateanumericallystableimplementationforBesselfunctions.
NaiveimplementationsoftheBesselfunctionsproduceunreliableresultswhentheyareusedtosolveMaxwell'sequationsbywayofMietheory.
Maxwell'sequationsareusedtomodelthescatteringoflightbysmallparticles.
LightscatterisusedinParticleCharacterizationtomeasurethequalityofmaterialslikecocoa,cementandpharmaceuticals.
S0245-PortingLegacyPlasmaCodestoGPUPengWang(NVIDIA)Day:Tuesday,05/15|Time:4:00pm-4:25pmTopicAreas:ComputationalPhysics;ComputationalPhysicsSessionLevel:IntermediateLearnhowtoportlegacyFortranplasmacodestoGPU.
ManylegacyplasmacodesarewritteninFortranandhavemanylinesofcodes.
WewilldiscusstechniquesinportingsuchlegacycodeseasilyandefficientlytoCUDAC/C++.
Performanceanalysisofmajoralgorithmicpatternsinplasmacodeswillbediscussed.
ThediscussionwillusetheGTCandGeFiplasmacodeasrealisticexamples.
S0058-AdvancingGPUMolecularDynamics:RigidBodiesinHOOMD-blueJoshuaAnderson(UniversityofMichigan),TrungDacNguyen(UniversityofMichigan)Day:Wednesday,05/16|Time:10:00am-10:50amTopicAreas:MolecularDynamics;ComputationalPhysicsSessionLevel:IntermediateLearnhowrigidbodydynamicsareimplementedinHOOMD-blue.
Previousreleaseswerecapableofexecutingclassicalmoleculardynamics--wherefreeparticlesinteractviasmoothpotentialsandtheirmotionthroughtimeiscomputedusingNewton'slaws.
Thelatestversionallowsparticlestobegroupedintobodiesthatmoveasrigidunits.
Userscannowsimulatematerialsmadeofcubes,rods,bentrods,jacks,plates,patchyparticles,buckyballs,oranyotherarbitraryshapes.
ThistalkcovershowthesealgorithmsareimplementedontheGPU,tunedtoperformwellforbodiesofanysize,anddiscussesseveraluse-casesrelevanttoresearch.
S0125-MemoryEfficientReverseTimeMigrationin3DChrisLeader(StanfordExplorationProject)Day:Wednesday,05/16|Time:10:00am-10:25amTopicAreas:EnergyExploration;ComputationalPhysicsSessionLevel:IntermediateLearnhowwecanimagetheinterioroftheEarthinthreedimensionsusingReverseTimeMigration.
WediscusshowGPUsacceleratethismethodusingparallelwavepropagationkernels,texturememoriesandminimaldevicetohosttransfers.
Furtherwediscusshowtheprogressionto3Dpresentsamultitudeofnewproblems,particularlymemorybased-causingthesystemtobeIOlimited.
Bymanipulatingboundarypositionsandvaluestoapseudo-randomformweshowhowmanyofthesememoryrestrictionscanbediminishedandhowdetailedsubsurfaceimagescanbefullyconstructedusingGPUs.
S0236-AdvancedOptimizationTechniquesOnaCUDAImplementationofConjugateGradientSolversEriRubin(OptiTex)Day:Wednesday,05/16|Time:10:00am-10:25amTopicAreas:Algorithms&NumericalTechniques;Algorithms&NumericalTechniques;ComputationalPhysics;ApplicationDesign&PortingTechniquesSessionLevel:IntermediateLinearsystemsareattheheartofallotofcomputeproblems.
Inlargesparsesystems,thereare2distinctapproaches,thedirectanditerativesolvers.
Aftermanyyearsofresearchingandtestingbothapproaches,onCPUandGPUwehaveimplementedahighlyefficientCGsolverontheGPUusingacombinationofuniquetechniques.
Inthistalkwewillgooverthesetechniquesandtheimprovedperformancetheybring.
S0312-GPUImplementationforRapidIterativeImageReconstructioninNuclearMedicineJakubPietrzak(UniversityofWarsaw)Day:Wednesday,05/16|Time:10:00am-10:25amTopicAreas:MedicalImaging&Visualization;ComputationalPhysics;ComputerGraphicsSessionLevel:IntermediateGPUimplementationcangreatlyaccelerateiterativetechniquesof3Dimagereconstructioninnuclearmedicineimaging.
SinglePhotonEmissionComputedTomography(SPECT)isafunctionalimagingmodalitywidelyusedinclinicaldiagnosis.
Toobtainhighqualityimageswithinreducedscanningtimeshighsensitivitycollimatorsneedtobeusedandtheirresponsefunctionmodeledinthereconstruction.
ThisisingeneralverycomputationallyintensiveandunfeasiblewithCPUandalgorithmimplementations.
Oursoftwareisabletoperformthereconstructionofpatientdatawithinclinicallyacceptabletimesusingrelativelylowcostandwidelyavailablehardware.
S0352-GPU-AcceleratedParallelComputingforSimulationofSeismicWavePropagationTaroOkamoto(DepartmentofEarthandPlanetarySciences,TokyoInstituteofTechnology)Day:Wednesday,05/16|Time:10:30am-10:55amTopicAreas:ComputationalPhysics;GeneralInterestSessionLevel:AdvancedWeadoptedGPUtoacceleratelarge-scale,parallelfinite-difference(FDTD)simulationofseismicwavepropagation.
EffectiveparallelimplementationisneededbecausethesizeofthememoryofasingleGPUistoosmallforrealapplications.
Thuswedescribethememoryoptimization,thethree-dimensionaldomaindecomposition,andoverlappingthecommunicationandcomputationadoptedinourprogram.
Weachievedsofarahighperformance(single-precision)ofabout61TFlopsbyusing1200GPUsofTSUBAME-2.
0,theGPUsupercomputerinTokyoInstituteofTechnology,Japan.
Asanimportantapplication,weshowtheresultsofthesimulationofthe2011Tohoku-Okimega-quake.
S0269-Accelerating3D-RISMCalculationsusingGPUsYutakaMaruyama(InstituteforMolecularScience),FumioHirata(InstituteforMolecularScience)Day:Wednesday,05/16|Time:3:00pm-3:25pmTopicAreas:LifeSciences;Algorithms&NumericalTechniques;ComputationalPhysicsSessionLevel:IntermediateThethree-dimensionalreferenceinteractionsitemodel(3D-RISM)theory,isapowerfultooltoinvestigatebiomolecularprocessesinsolution.
Unfortunately,3D-RISMcalculationsareoftenbothmemoryintensiveandtime-consuming.
WesoughttoacceleratethesecalculationsusingGPUs.
ToworkaroundtheproblemoflimitedmemorysizeinGPUs,wemodifiedthelessmemory-intensiveAndersonmethodforfasterconvergenceof3D-RISMcalculations.
UsingthismethodonC2070,wereducedthecomputationaltimebyafactorofeightcomparedtoIntelXeon(8cores,3.
33GHz)withtheconventionalmethod.
S0055-ParticleDynamicswithMBDandFEAusingCUDAGrahamSanborn(FunctionBay)Day:Wednesday,05/16|Time:4:00pm-4:25pmTopicAreas:ComputationalStructuralMechanics;ComputationalPhysics;ComputationalFluidDynamicsSessionLevel:IntermediateManysphereparticlesaresolvedwithDEM(DiscreteElementMethod)andsimulatedwithGPUtechnology.
Fastalgorithmisappliedtocalculatehertziancontactforcesbetweenmanysphereparticles(from100,000to1,000,000)andNVIDIA'sCUDAisusedtoacceleratethecalculation.
ManysphereparticlesandMBDandFEAentitiesaresimulatedwithincommercialsoftwareRecurDyn.
Manymodelsarebuiltandsimulated;forklifterwithsandmodel,oilinoiltankmodel,oilfilledenginesystemandwaterfilledwashingmachinemodel.
AllmodelsaresimulatedwithNVIDIA'sGPUandtheresultisshown.
S0363-EfficientMolecularDynamicsonHeterogeneousGPUArchitecturesinGROMACSSzilárdPáll(KTHRoyalInstituteofTechnology),BerkHess(KTHRoyalInstituteofTechnology)Day:Wednesday,05/16|Time:4:00pm-4:25pmTopicAreas:MolecularDynamics;ComputationalPhysics;LifeSciencesSessionLevel:IntermediateMolecularDynamicsisanimportantapplicationforGPUacceleration,butmanyalgorithmicoptimizationsandfeaturesstillrelyoncodethatpreferstraditionalCPUs.
ItisonlywiththelatesthardwareandsoftwarewehavebeenabletorealizeaheterogeneousGPU/CPUimplementationandreachperformancesignificantlybeyondthestate-of-the-artofhand-tunedCPUcodeinourGROMACSprogram.
Thesub-milliseconditerationtimeposeschallengesonalllevelsofparallelization.
Comeandlearnaboutournewatom-clusterpairinteractionapproachfornon-bondedforceevaluationthatachieves60%work-efficiencyandotherinnovativesolutionsforheterogeneousGPUsystems.
S0139-GPU-BasedMolecularDynamicsSimulationsofProteinandRNAAssemblySamuelCho(WakeForestUniversity)Day:Wednesday,05/16|Time:5:00pm-5:25pmTopicAreas:MolecularDynamics;ComputationalPhysicsSessionLevel:IntermediateProteinandRNAbiomolecularfoldingandassemblyproblemshaveimportantapplicationsbecausemisfoldingisassociatedwithdiseaseslikeAlzheimer'sandParkinson's.
However,simulatingcomplexbiomoleculesonthesametimescalesasexperimentsisanextraordinarychallengeduetoabottleneckintheforcecalculations.
Toovercomethesehurdles,weperformcoarse-grainedmoleculardynamicssimulationswherebiomoleculesarereducedintosimplercomponents.
Furthermore,ourGPU-basedsimulationshaveasignificantperformanceimprovementoverCPU-basedsimulations,whichislimitedtosystemsof50-150residues/nucleotides.
TheGPU-basedcodecansimulateprotein/RNAsystemsof400-10,000+residues/nucleotides,andwepresentribosomeassemblysimulations.
S0129-AMonteCarloThermalRadiationSolverinGPU/CPUHybridArchitectureGaofengWang(LaboratoireE.
M2.
C,EcoleCentraleParis),OliverGicquel(LaboratoireE.
M2.
C,EcoleCentraleParis)Day:Thursday,05/17|Time:9:00am-9:25amTopicAreas:ComputationalFluidDynamics;ComputationalFluidDynamics;ComputationalPhysics;RayTracingSessionLevel:IntermediateAMonteCarloray-tracingcodeisdevelopedtopredictradiativeheattransferbehaviorsinCFDsimulationofcombustionphenomena.
Usingemission-reciprocalmethod,eachrandomraycastingofeachnodecouldbeindependentlyconductedforparallelcomputations.
ThecodeisefficientlyimplementedinhybridGPU/CPUHPCresourcesusingadedicateddynamicloadbalancingstrategy.
AlinearspeedupscalingofhybridHPCresourceshasbeenshownindemonstratingcalculationofradiativeheattransferofahelicopterengine'scombustionchamber,whileaddingoneGPUinHPCresourcespoolisinsenseofnineCPUcoressupplements.
S0508-FasterFiniteElementsforWavePropagationCodesMaxRietmann(InstituteforComputationalScience/USILugano,Switzerland)Day:Thursday,05/17|Time:10:00am-10:25amTopicAreas:Algorithms&NumericalTechniques;ComputationalPhysicsSessionLevel:IntermediateLearnhowtodevelopfasterandbetterfinite-elementcodesforwavepropagationusingGPUsandMPIcombinedwithoverlappingtechniquestohidethecostofcommunicationsandofhost/devicememorycopies.
Differentoptionsbasedonmeshcoloringoronatomicoperationswillbepresented.
Thedifficultytodefinespeedupwillalsobediscussed(speedupversuswhatusingwhatdefinitionof"cost").
ExampleswillbegivenusingSPECFEM3D,ahighlyoptimizedspectralfinite-elementcodethathaswontheGordonBellSupercomputingawardandtheBULLJosephFourieraward,andthatcanrunonCPUorGPUclusters.
S0039-Data-DrivenGPGPUIdeologyExtensionAlexandrKosenkov(UniversityofGeneva),BelaBauer(MicrosoftResearch)Day:Thursday,05/17|Time:10:00am-10:25amTopicAreas:ApplicationDesign&PortingTechniques;ComputationalPhysics;ParallelProgrammingLanguages&Compilers;DevelopmentTools&LibrariesSessionLevel:AdvancedInthissessionwewilldemonstratehowtheGPGPUideologycanbeextendedsothatitcanbeusedonascaleofInfinibandhybridsystem.
Theapproachthatwearepresentingcombinesdelayedexecution,schedulingtechniquesand,mostimportantly,castsdowntheCPUmulti-coreideologytothestreamingmultiprocessor'soneenforcingfullfledged"GPGPUasaco-processor"wayofprogrammingforlarge-scaleMPIhybridapplications.
StayingcompatiblewithmodernCPU/GPGPUlibrariesitprovidesmorethanafinegrainedcontroloverresources-morethanyouwantedthatis.
S0217-EfficientImplementationofCFDAlgorithmsonGPUAcceleratedSupercomputersAliKhajeh-Saeed(UniversityofMassachusetts,Amherst),BlairPerot(UniversityofMassachusetts,Amherst)Day:Thursday,05/17|Time:10:30am-10:55amTopicAreas:ComputationalFluidDynamics;ComputationalPhysics;Supercomputing;ApplicationDesign&PortingTechniquesSessionLevel:IntermediateThegoalofthissessionistointroducetheconceptsnecessarytoperformlargecomputationalfluiddynamic(CFD)problemsoncollectionsofmanyGPUs.
CommunicationandcomputationoverlappingschemesbecomeevenmorecriticalwhenusingfastcomputeenginessuchasGPUsthatareconnectedviaarelativelyslowinterconnect(suchasMPIonInfiniBand).
ThealgorithmspresentedarevalidatedonunsteadyCFDsimulationsofturbulenceusing192graphicsprocessorstoupdatehalf-a-billionunknownspercomputationaltimestep.
TheperformanceresultsfromthreedifferentGPUacceleratedsupercomputers(Lincoln,Forge,andKeeneland)arecomparedwithalargeCPUbasedsupercomputer(Ranger).
S0378-VASPAcceleratedwithGPUsMaxwellHutchinson(UniversityofChicago)Day:Thursday,05/17|Time:2:00pm-2:50pmTopicAreas:QuantumChemistry;ApplicationDesign&PortingTechniques;ComputationalPhysicsSessionLevel:IntermediateThissessionwilldetailtheperformanceandcapabilitiesofGPU-acceleratedVASP,explaindesigndecisionsmadeinportingVASPtoCUDA,andpresentaroadmapforGPUacceleratedVASPdevelopment.
We'veachievedperformanceimprovementsuptoaround20xonsystemsofaround100ionsandhaveimplementedexact-exchange.
Weareworkingonportsofmoreconventionalfunctionality.
S0071-TheHigh-LevelLinearAlgebraLibraryViennaCLAndItsApplicationsKarlRupp(TUWien)Day:Thursday,05/17|Time:3:00pm-3:50pmTopicAreas:DevelopmentTools&Libraries;Algorithms&NumericalTechniques;ComputationalPhysicsSessionLevel:IntermediateGettoknowViennaCL,anOpenCLhigh-levellinearalgebrasoftware,whichallowstogetthespeedofGPUcomputingattheconvenienceleveloftheC++Boostlibraries.
Decreasethedevelopmentandexecutiontimeofapplicationsbyutilizingourwell-testedandwidelyusedlibrary,insteadofspendingdaysonlearningdetailsofGPUarchitecturesanddebugging.
Weprovideexamplesthatdemonstratenotonlyhowquicklyexistingapplicationsareportedefficientlyfromsingle-threadedexecutiontofullyutilizingmulti-threadedenvironments,butalsohowtoutilizetherichsetoffunctionalitiesrangingfromcommonBLASroutinestoiterativesolvers.
S0087-GPUAccelerationofDenseStellarClustersSimulationBharathPattabiraman(NorthwesternUniversity),StefanUmbreit(NorthwesternUniversity)Day:Thursday,05/17|Time:3:00pm-3:25pmTopicAreas:Astronomy&Astrophysics;ComputationalPhysics;Algorithms&NumericalTechniquesSessionLevel:IntermediateComputingtheinteractionsbetweenstarswithindensestellarclustersisaproblemoffundamentalimportanceintheoreticalastrophysics.
ThispaperpresentstheparallelizationofaMonteCarloalgorithmforsimulatingstellarclusterevolutionusingprogrammableGraphicsProcessingUnits.
Thekernelsofthisalgorithmexhibithighlevelsofdatadependentdecisionmakingandunavoidablenon-contiguousmemoryaccesses.
However,weadoptvariousparallelizationstrategiesandutilizethehighcomputingpoweroftheGPUtoobtainsubstantialnear-linearspeedupswhichcannotbeeasilyachievedonaCPU-basedsystem.
Thisaccelerationallowstoexplorephysicalregimeswhichwereoutofreachofcurrentsimulations.
S0368-UnravelingtheMysteriesofQuarkswithHundredsofGPUsRonaldBabich(NVIDIA)Day:Thursday,05/17|Time:3:00pm-3:50pmTopicAreas:ComputationalPhysics;ApplicationDesign&PortingTechniques;Algorithms&NumericalTechniques;SupercomputingSessionLevel:IntermediateDiveintotheworldofquarksandgluons,andhearhowGPUcomputingisrevolutionizingthewaymanycalculationsinlatticequantumchromodynamics(latticeQCD)areperformed.
Themaincomputationalchallengeinsuchcalculationsistorepeatedlysolvelargesystemsoflinearequationsarisingfromafour-dimensionalfinite-differenceproblem.
Inthissession,we'lldiscussstrategiesforparallelizingsuchasolveracrosshundredsofGPUs.
Theseincludetechniquesandalgorithmsforreducingmemorytrafficandinter-GPUcommunication.
Thenetresultisanimplementationthatachievesbetterthan20Tflopson256GPUs,realizedintheopen-source"QUDA"library.
S0091-SustainableHybridParallelizationofanUnstructuredHydrodynamicCodeRaphalPoncet(Commissariatàl'EnergieAtomiqueetauxEnergiesAlternatives)Day:Thursday,05/17|Time:3:00pm-3:25pmTopicAreas:ApplicationDesign&PortingTechniques;Algorithms&NumericalTechniques;ComputationalFluidDynamics;ComputationalPhysicsSessionLevel:AdvancedThegoalofthispresentationistoshareourmethodologyforportinganumericalcodetohybridsupercomputingarchitecturesusingMPIcoupledwithdirective-basedlanguages(OpenMPformulticoreCPUs,andHMPPforGPUs).
Ourcode,VOLNA,isanunstructuredpartialdifferentialequationhydrodynamicsolverdevelopedforthesimulationoftsunamis.
Ourresultsdemonstratethatusingdirective-basedlanguagessuchasHMPPforGPUprogramming,onecanretaingoodperformance(e.
g.
speedupof15comparedto1CPUcore,3comparedto8CPUcores)withminimalmodificationsoftheoriginalCPUsourcecode(about30linesofdirectivesinourcase).
S0334-TheFastMultipoleMethodonCPUandGPUProcessorsEricDarve(Stanford)Day:Thursday,05/17|Time:3:00pm-3:25pmTopicAreas:ComputationalPhysics;MolecularDynamics;Algorithms&NumericalTechniquesSessionLevel:AdvancedThefastmultipolemethod(FMM)isawidelyusednumericalalgorithmincomputationalengineering.
AcceleratingtheFMMonCUDA-enabledGPUsischallengingbecausetheFMMhasacomplicateddataaccesspattern,mostlyduringtheso-calledmultipole-to-local(M2L)operation.
WehavecreatedseveralschemestooptimizetheM2Landhaveattainedaperformanceofover350(resp.
160)Gflop/sforsingle(double)precisionarithmetic.
TheoptimalalgorithmwasincorporatedintoacompleteFMMcode,whichcanacceptanysmoothkernelasspecifiedbytheuser,makingitveryflexible.
WehavealsodevelopedahighlyefficientCPUversion.
S0282-LeveragingNVIDIAGPUDirectonAPEnet+3DTorusClusterInterconnectDavideRossetti(ItalianNationalInstitueforNuclearPhysics)Day:Thursday,05/17|Time:4:30pm-4:55pmTopicAreas:Supercomputing;ComputationalPhysicsSessionLevel:IntermediateAPEnet+isanovelclusterinterconnect,basedonacustomPCIcardwhichfeaturesaPCIExpressGen2X8linkandare-configurableHWcomponent(FPGA).
Itsupportsa3DTorustopologyandhasspecialaccelerationfeaturesspecificallydevelopedforNVIDIAFermiGPUs.
AnintroductiontothebasicfeaturesandtheprogrammingmodelofAPEnet+willbefollowedbyadescriptionofitsperformanceonsomenumericalsimulations,e.
g.
HighEnergyPhysicssimulations.
S0218-ASIParallelFortran:AGeneral-PurposeFortrantoGPUTranslatorRainaldLohner(GeorgeMasonUniversity)Day:Thursday,05/17|Time:4:30pm-4:55pmTopicAreas:DevelopmentTools&Libraries;ComputationalFluidDynamics;ComputationalPhysics;ParallelProgrammingLanguages&CompilersSessionLevel:AdvancedOverthelast3yearswehavedevelopedageneral-purposeFortrantoGPUtranslator:ASIParallelFortrandoes.
Thetalkwilldetailitspurpose,designlayoutandcapabilities,andshowhowitisusedandimplemented.
TheuseofASIParallelFortranwillbeshownforlarge-scaleCFD/CEMcodesaswellasothergeneralpurposeFortrancodes.
gputechconf.
comSessionsonComputationalPhysics(subjecttochange)IMPORTANT:Visithttp://www.
gputechconf.
com/page/sessions.
htmlforthemostup-to-dateschedule.
S0268-VirtualProcessEngineering-RealtimeSimulationofMultiphaseSystemsWeiGe(InstituteofProcessEngineering,ChineseAcademyofSciences)Day:Tuesday,05/15|Time:9:00am-9:50amTopicAreas:ComputationalFluidDynamics;MolecularDynamics;ComputationalPhysics;Algorithms&NumericalTechniquesSessionLevel:AdvancedRealtimesimulationandvirtualrealitywithquantitativelycorrectphysicsforindustrialprocesseswithmulti-scaleandmultiphasesystemisoncearemotedreamforprocessengineering,butisbecomingtruenowwithCPU-GPUhybridsupercomputing.
NumericalandvisualizationmethodsforsuchsimulationsonthousandsofGPUswillbereportedwithapplicationsinchemicalandenergyindustries.
S0258-Sailfish:LatticeBoltzmannFluidSimulationswithGPUsandPythonMichalJanuszewski(UniversityofSilesiainKatowice;GoogleSwitzerland)Day:Tuesday,05/15|Time:9:30am-9:55amTopicAreas:ComputationalFluidDynamics;ComputationalPhysics;DevelopmentTools&LibrariesSessionLevel:IntermediateLearnhowRun-TimeCodeGeneration(RTCG)techniquesallowedforfastdevelopmentofalatticeBoltzmann(LB)fluiddynamicssolvercalledSailfish.
Sailfishiscompletelyopensource,supportsawidevarietyofLBmodels(singleandmultiplerelaxationtimes,theentropicmodel;singleandbinaryfluids)andcantakeadvantageofmultipleGPUs.
EventhoughtheprojectiswrittenpredominantlyinPython,noperformancecompromisesaremade.
ThistalkwillintroducethebasicdesignprinciplesofSailfishandillustratehowRTCGallowstoexploitthepowerofGPUswithminimalprogrammereffort.
S0031-UnstructuredGridNumberingSchemesforGPUCoalescingRequirementsAndrewCorrigan(NavalResearchLaboratory),JohannDahm(UniversityofMichigan)Day:Tuesday,05/15|Time:10:00am-10:25amTopicAreas:ComputationalFluidDynamics;Algorithms&NumericalTechniques;ComputationalPhysicsSessionLevel:AdvancedLearnhowtoachievehighperformanceforcomputationalfluiddynamics(CFD)solversoverunstructuredgridsusingnumberingschemestailoredforGPUcoalescingrequirements.
Usingthesetechniques,unstructuredgridCFDsolverscanmakemoreeffectiveuseofmemorybandwidth,whichisanotherwisesignificantperformancebottleneckthathassofarledtorelativelylimitedperformancegainsonGPUsincomparisontostructuredgridCFDsolvers.
PerformancebenchmarkswillbeshownusingtheJetEngineNoiseReduction(JENRE)code.
S0321-GPU-BasedMonteCarloRayTracingSimulationforSolarPowerPlantsClausNilsson(TietronixSoftware,Inc.
),MichelIzygon(TietronixSoftware,Inc.
)Day:Tuesday,05/15|Time:2:00pm-2:25pmTopicAreas:EnergyExploration;ComputationalPhysics;RayTracingSessionLevel:BeginnerLearnaboutrealtimesimulationsofConcentratingThermalSolarPowerusingGPUtechnologytoenableperformanceoptimizationoftheseutilityscaleplants.
ByleveragingthepowerofGPUsandtheparallelaspectofthefieldofthousandssun-trackingmirrors,wehavebeensuccessfulincuttingthecomputationtimebyordersofmagnitudeversusthepreviouslyrequiredminutesandhoursruntime.
WewillpresentanoverviewoftheproblemdomainanddescribehowweusedtheGPUtoderiveaMonteCarlophysicsraytracingmethodtosimulatethefluxreflectedbythemirrorsontothesolarreceiver.
S0046-ApplicationoftheGPUtoaTwo-PartComputationalElectromagneticAlgorithmEricDunn(SAIC)Day:Tuesday,05/15|Time:2:30pm-2:55pmTopicAreas:ComputationalPhysics;Algorithms&NumericalTechniques;RayTracingSessionLevel:BeginnerTheshootingandbouncingray(SBR)methodisonewaytosimulateelectromagneticfieldradiation.
Likeallmethods,therearecertainproblemswhereitdoesnotyieldaccurateresults.
Inthispresentation,wewillexplainonesuchcasethatconsistsofanantennaresonatingbetweentwometalplates.
Wewilldiscusshowweusedthegraphicsprocessingunit(GPU)toseparatetheproblemintotwoparts.
EachpartissimulatedindividuallywithSBRproducinganimprovedresult.
SuchaGPU-accelerated,two-partapproachcanbeappliedtoothermoregeneralhybridsimulations.
S0379-GPU-basedHigh-PerformanceSimulationsforSpintronicsJanJacob(UniversityofHamburg-InstituteofAppliedPhysicsandMicrostructureResearchCenter)Day:Tuesday,05/15|Time:2:30pm-2:55pmTopicAreas:GeneralInterest;ComputationalPhysics;ApplicationDesign&PortingTechniquesSessionLevel:IntermediateThejointutilizationoftheelectron'schargeandspinin"spintronics"representsapromisingtechnologyfordataprocessingandstorageinnanostructures.
Thecomplexquantumeffectslikethespin-Halleffectinthesedevicesrequiredemandingnumericalsimulationsprovidingaconvenientlinkbetweenidealizedanalyticalmodelstooftenverycomplexresultsfrommeasurements.
ThesimulationsinvolvingmultiplicationsandinversionsoflargematricesprovideanidealshowcaseforperformancegainbyemployingGPGPUsintheexecutionofthealgebraicroutinesonthesematricesincomputingenvironmentswithsharedexecutionofalgorithmsonmultiplenodeswithmultipleGPGPUsandCPUcores.
S0036-MultiparticleCollisionDynamicsonGPUsElmarWestphal(ForschungszentrumJuelich)Day:Tuesday,05/15|Time:3:00pm-3:50pmTopicAreas:ComputationalPhysics;ComputationalFluidDynamics;MolecularDynamicsSessionLevel:IntermediateSeehowweemployGPUstosimulatetheinteractionofmillionsofsolventandsoluteparticlesofafluidsystem.
Oftenthedomainoflargeclustersystem,themosttimeconsumingpartofoursimulationscannowbedoneondesktopPCsinreasonabletime.
ThiscontributionshowshowGPUscaneffectivelybeusedtoaccelerateexistingprogramsandhowtechniqueslikestreamingandincreaseddatalocalitysignificantlyenhancecalculationthroughput.
ItalsoshowshowaGPU-optimizedprogramstructureyieldsusuallyexpensiveadditionalfunctionality"almostfree".
Furthermore,awell-scalingsingle-node/multi-GPUimplementationoftheprogramispresented.
S0067-PIConGPU-Bringinglarge-scaleLaserPlasmaSimulationstoGPUSupercomputingMichaelBussmann(Helmholtz-ZentrumDresden-Rossendorf),GuidoJuckeland(CenterforInformationServicesandHighPerformanceComputing,TechnicalUniversityDresden)Day:Tuesday,05/15|Time:3:00pm-3:50pmTopicAreas:ComputationalPhysics;Algorithms&NumericalTechniques;ApplicationDesign&PortingTechniques;SupercomputingSessionLevel:AdvancedWithpowerfullasersbreakingthePetawattbarrier,applicationsforlaser-acceleratedparticlebeamsaregainingmoreinterestthanever.
Ionbeamsacceleratedbyintenselaserpulsesfosternewwaysoftreatingcancerandmakethemavailabletomorepeoplethaneverbefore.
Laser-generatedelectronbeamscandrivenewcompactx-raysourcestocreatesnapshotsofultrafastprocessesinmaterials.
WithPIConGPUlaser-drivenparticleaccelerationcanbecomputedinhourscomparedtoweeksonstandardCPUclusters.
WepresentthetechniquesbehindPIConGPU,detailedperformanceanalysisandthebenefitsofPIConGPUforreal-worldphysicscases.
S0221-1024BitParallelRationalArithmeticOperatorsfortheGPURobertZigon(BeckmanCoulter)Day:Tuesday,05/15|Time:4:00pm-4:50pmTopicAreas:Algorithms&NumericalTechniques;ComputationalPhysicsSessionLevel:IntermediateLearnhowtocreateasetofrationalarithmeticoperatorsthatmanipulate1024bitoperandsonaTeslaC2050.
TheseoperatorsareusedtocreateanumericallystableimplementationforBesselfunctions.
NaiveimplementationsoftheBesselfunctionsproduceunreliableresultswhentheyareusedtosolveMaxwell'sequationsbywayofMietheory.
Maxwell'sequationsareusedtomodelthescatteringoflightbysmallparticles.
LightscatterisusedinParticleCharacterizationtomeasurethequalityofmaterialslikecocoa,cementandpharmaceuticals.
S0245-PortingLegacyPlasmaCodestoGPUPengWang(NVIDIA)Day:Tuesday,05/15|Time:4:00pm-4:25pmTopicAreas:ComputationalPhysics;ComputationalPhysicsSessionLevel:IntermediateLearnhowtoportlegacyFortranplasmacodestoGPU.
ManylegacyplasmacodesarewritteninFortranandhavemanylinesofcodes.
WewilldiscusstechniquesinportingsuchlegacycodeseasilyandefficientlytoCUDAC/C++.
Performanceanalysisofmajoralgorithmicpatternsinplasmacodeswillbediscussed.
ThediscussionwillusetheGTCandGeFiplasmacodeasrealisticexamples.
S0058-AdvancingGPUMolecularDynamics:RigidBodiesinHOOMD-blueJoshuaAnderson(UniversityofMichigan),TrungDacNguyen(UniversityofMichigan)Day:Wednesday,05/16|Time:10:00am-10:50amTopicAreas:MolecularDynamics;ComputationalPhysicsSessionLevel:IntermediateLearnhowrigidbodydynamicsareimplementedinHOOMD-blue.
Previousreleaseswerecapableofexecutingclassicalmoleculardynamics--wherefreeparticlesinteractviasmoothpotentialsandtheirmotionthroughtimeiscomputedusingNewton'slaws.
Thelatestversionallowsparticlestobegroupedintobodiesthatmoveasrigidunits.
Userscannowsimulatematerialsmadeofcubes,rods,bentrods,jacks,plates,patchyparticles,buckyballs,oranyotherarbitraryshapes.
ThistalkcovershowthesealgorithmsareimplementedontheGPU,tunedtoperformwellforbodiesofanysize,anddiscussesseveraluse-casesrelevanttoresearch.
S0125-MemoryEfficientReverseTimeMigrationin3DChrisLeader(StanfordExplorationProject)Day:Wednesday,05/16|Time:10:00am-10:25amTopicAreas:EnergyExploration;ComputationalPhysicsSessionLevel:IntermediateLearnhowwecanimagetheinterioroftheEarthinthreedimensionsusingReverseTimeMigration.
WediscusshowGPUsacceleratethismethodusingparallelwavepropagationkernels,texturememoriesandminimaldevicetohosttransfers.
Furtherwediscusshowtheprogressionto3Dpresentsamultitudeofnewproblems,particularlymemorybased-causingthesystemtobeIOlimited.
Bymanipulatingboundarypositionsandvaluestoapseudo-randomformweshowhowmanyofthesememoryrestrictionscanbediminishedandhowdetailedsubsurfaceimagescanbefullyconstructedusingGPUs.
S0236-AdvancedOptimizationTechniquesOnaCUDAImplementationofConjugateGradientSolversEriRubin(OptiTex)Day:Wednesday,05/16|Time:10:00am-10:25amTopicAreas:Algorithms&NumericalTechniques;Algorithms&NumericalTechniques;ComputationalPhysics;ApplicationDesign&PortingTechniquesSessionLevel:IntermediateLinearsystemsareattheheartofallotofcomputeproblems.
Inlargesparsesystems,thereare2distinctapproaches,thedirectanditerativesolvers.
Aftermanyyearsofresearchingandtestingbothapproaches,onCPUandGPUwehaveimplementedahighlyefficientCGsolverontheGPUusingacombinationofuniquetechniques.
Inthistalkwewillgooverthesetechniquesandtheimprovedperformancetheybring.
S0312-GPUImplementationforRapidIterativeImageReconstructioninNuclearMedicineJakubPietrzak(UniversityofWarsaw)Day:Wednesday,05/16|Time:10:00am-10:25amTopicAreas:MedicalImaging&Visualization;ComputationalPhysics;ComputerGraphicsSessionLevel:IntermediateGPUimplementationcangreatlyaccelerateiterativetechniquesof3Dimagereconstructioninnuclearmedicineimaging.
SinglePhotonEmissionComputedTomography(SPECT)isafunctionalimagingmodalitywidelyusedinclinicaldiagnosis.
Toobtainhighqualityimageswithinreducedscanningtimeshighsensitivitycollimatorsneedtobeusedandtheirresponsefunctionmodeledinthereconstruction.
ThisisingeneralverycomputationallyintensiveandunfeasiblewithCPUandalgorithmimplementations.
Oursoftwareisabletoperformthereconstructionofpatientdatawithinclinicallyacceptabletimesusingrelativelylowcostandwidelyavailablehardware.
S0352-GPU-AcceleratedParallelComputingforSimulationofSeismicWavePropagationTaroOkamoto(DepartmentofEarthandPlanetarySciences,TokyoInstituteofTechnology)Day:Wednesday,05/16|Time:10:30am-10:55amTopicAreas:ComputationalPhysics;GeneralInterestSessionLevel:AdvancedWeadoptedGPUtoacceleratelarge-scale,parallelfinite-difference(FDTD)simulationofseismicwavepropagation.
EffectiveparallelimplementationisneededbecausethesizeofthememoryofasingleGPUistoosmallforrealapplications.
Thuswedescribethememoryoptimization,thethree-dimensionaldomaindecomposition,andoverlappingthecommunicationandcomputationadoptedinourprogram.
Weachievedsofarahighperformance(single-precision)ofabout61TFlopsbyusing1200GPUsofTSUBAME-2.
0,theGPUsupercomputerinTokyoInstituteofTechnology,Japan.
Asanimportantapplication,weshowtheresultsofthesimulationofthe2011Tohoku-Okimega-quake.
S0269-Accelerating3D-RISMCalculationsusingGPUsYutakaMaruyama(InstituteforMolecularScience),FumioHirata(InstituteforMolecularScience)Day:Wednesday,05/16|Time:3:00pm-3:25pmTopicAreas:LifeSciences;Algorithms&NumericalTechniques;ComputationalPhysicsSessionLevel:IntermediateThethree-dimensionalreferenceinteractionsitemodel(3D-RISM)theory,isapowerfultooltoinvestigatebiomolecularprocessesinsolution.
Unfortunately,3D-RISMcalculationsareoftenbothmemoryintensiveandtime-consuming.
WesoughttoacceleratethesecalculationsusingGPUs.
ToworkaroundtheproblemoflimitedmemorysizeinGPUs,wemodifiedthelessmemory-intensiveAndersonmethodforfasterconvergenceof3D-RISMcalculations.
UsingthismethodonC2070,wereducedthecomputationaltimebyafactorofeightcomparedtoIntelXeon(8cores,3.
33GHz)withtheconventionalmethod.
S0055-ParticleDynamicswithMBDandFEAusingCUDAGrahamSanborn(FunctionBay)Day:Wednesday,05/16|Time:4:00pm-4:25pmTopicAreas:ComputationalStructuralMechanics;ComputationalPhysics;ComputationalFluidDynamicsSessionLevel:IntermediateManysphereparticlesaresolvedwithDEM(DiscreteElementMethod)andsimulatedwithGPUtechnology.
Fastalgorithmisappliedtocalculatehertziancontactforcesbetweenmanysphereparticles(from100,000to1,000,000)andNVIDIA'sCUDAisusedtoacceleratethecalculation.
ManysphereparticlesandMBDandFEAentitiesaresimulatedwithincommercialsoftwareRecurDyn.
Manymodelsarebuiltandsimulated;forklifterwithsandmodel,oilinoiltankmodel,oilfilledenginesystemandwaterfilledwashingmachinemodel.
AllmodelsaresimulatedwithNVIDIA'sGPUandtheresultisshown.
S0363-EfficientMolecularDynamicsonHeterogeneousGPUArchitecturesinGROMACSSzilárdPáll(KTHRoyalInstituteofTechnology),BerkHess(KTHRoyalInstituteofTechnology)Day:Wednesday,05/16|Time:4:00pm-4:25pmTopicAreas:MolecularDynamics;ComputationalPhysics;LifeSciencesSessionLevel:IntermediateMolecularDynamicsisanimportantapplicationforGPUacceleration,butmanyalgorithmicoptimizationsandfeaturesstillrelyoncodethatpreferstraditionalCPUs.
ItisonlywiththelatesthardwareandsoftwarewehavebeenabletorealizeaheterogeneousGPU/CPUimplementationandreachperformancesignificantlybeyondthestate-of-the-artofhand-tunedCPUcodeinourGROMACSprogram.
Thesub-milliseconditerationtimeposeschallengesonalllevelsofparallelization.
Comeandlearnaboutournewatom-clusterpairinteractionapproachfornon-bondedforceevaluationthatachieves60%work-efficiencyandotherinnovativesolutionsforheterogeneousGPUsystems.
S0139-GPU-BasedMolecularDynamicsSimulationsofProteinandRNAAssemblySamuelCho(WakeForestUniversity)Day:Wednesday,05/16|Time:5:00pm-5:25pmTopicAreas:MolecularDynamics;ComputationalPhysicsSessionLevel:IntermediateProteinandRNAbiomolecularfoldingandassemblyproblemshaveimportantapplicationsbecausemisfoldingisassociatedwithdiseaseslikeAlzheimer'sandParkinson's.
However,simulatingcomplexbiomoleculesonthesametimescalesasexperimentsisanextraordinarychallengeduetoabottleneckintheforcecalculations.
Toovercomethesehurdles,weperformcoarse-grainedmoleculardynamicssimulationswherebiomoleculesarereducedintosimplercomponents.
Furthermore,ourGPU-basedsimulationshaveasignificantperformanceimprovementoverCPU-basedsimulations,whichislimitedtosystemsof50-150residues/nucleotides.
TheGPU-basedcodecansimulateprotein/RNAsystemsof400-10,000+residues/nucleotides,andwepresentribosomeassemblysimulations.
S0129-AMonteCarloThermalRadiationSolverinGPU/CPUHybridArchitectureGaofengWang(LaboratoireE.
M2.
C,EcoleCentraleParis),OliverGicquel(LaboratoireE.
M2.
C,EcoleCentraleParis)Day:Thursday,05/17|Time:9:00am-9:25amTopicAreas:ComputationalFluidDynamics;ComputationalFluidDynamics;ComputationalPhysics;RayTracingSessionLevel:IntermediateAMonteCarloray-tracingcodeisdevelopedtopredictradiativeheattransferbehaviorsinCFDsimulationofcombustionphenomena.
Usingemission-reciprocalmethod,eachrandomraycastingofeachnodecouldbeindependentlyconductedforparallelcomputations.
ThecodeisefficientlyimplementedinhybridGPU/CPUHPCresourcesusingadedicateddynamicloadbalancingstrategy.
AlinearspeedupscalingofhybridHPCresourceshasbeenshownindemonstratingcalculationofradiativeheattransferofahelicopterengine'scombustionchamber,whileaddingoneGPUinHPCresourcespoolisinsenseofnineCPUcoressupplements.
S0508-FasterFiniteElementsforWavePropagationCodesMaxRietmann(InstituteforComputationalScience/USILugano,Switzerland)Day:Thursday,05/17|Time:10:00am-10:25amTopicAreas:Algorithms&NumericalTechniques;ComputationalPhysicsSessionLevel:IntermediateLearnhowtodevelopfasterandbetterfinite-elementcodesforwavepropagationusingGPUsandMPIcombinedwithoverlappingtechniquestohidethecostofcommunicationsandofhost/devicememorycopies.
Differentoptionsbasedonmeshcoloringoronatomicoperationswillbepresented.
Thedifficultytodefinespeedupwillalsobediscussed(speedupversuswhatusingwhatdefinitionof"cost").
ExampleswillbegivenusingSPECFEM3D,ahighlyoptimizedspectralfinite-elementcodethathaswontheGordonBellSupercomputingawardandtheBULLJosephFourieraward,andthatcanrunonCPUorGPUclusters.
S0039-Data-DrivenGPGPUIdeologyExtensionAlexandrKosenkov(UniversityofGeneva),BelaBauer(MicrosoftResearch)Day:Thursday,05/17|Time:10:00am-10:25amTopicAreas:ApplicationDesign&PortingTechniques;ComputationalPhysics;ParallelProgrammingLanguages&Compilers;DevelopmentTools&LibrariesSessionLevel:AdvancedInthissessionwewilldemonstratehowtheGPGPUideologycanbeextendedsothatitcanbeusedonascaleofInfinibandhybridsystem.
Theapproachthatwearepresentingcombinesdelayedexecution,schedulingtechniquesand,mostimportantly,castsdowntheCPUmulti-coreideologytothestreamingmultiprocessor'soneenforcingfullfledged"GPGPUasaco-processor"wayofprogrammingforlarge-scaleMPIhybridapplications.
StayingcompatiblewithmodernCPU/GPGPUlibrariesitprovidesmorethanafinegrainedcontroloverresources-morethanyouwantedthatis.
S0217-EfficientImplementationofCFDAlgorithmsonGPUAcceleratedSupercomputersAliKhajeh-Saeed(UniversityofMassachusetts,Amherst),BlairPerot(UniversityofMassachusetts,Amherst)Day:Thursday,05/17|Time:10:30am-10:55amTopicAreas:ComputationalFluidDynamics;ComputationalPhysics;Supercomputing;ApplicationDesign&PortingTechniquesSessionLevel:IntermediateThegoalofthissessionistointroducetheconceptsnecessarytoperformlargecomputationalfluiddynamic(CFD)problemsoncollectionsofmanyGPUs.
CommunicationandcomputationoverlappingschemesbecomeevenmorecriticalwhenusingfastcomputeenginessuchasGPUsthatareconnectedviaarelativelyslowinterconnect(suchasMPIonInfiniBand).
ThealgorithmspresentedarevalidatedonunsteadyCFDsimulationsofturbulenceusing192graphicsprocessorstoupdatehalf-a-billionunknownspercomputationaltimestep.
TheperformanceresultsfromthreedifferentGPUacceleratedsupercomputers(Lincoln,Forge,andKeeneland)arecomparedwithalargeCPUbasedsupercomputer(Ranger).
S0378-VASPAcceleratedwithGPUsMaxwellHutchinson(UniversityofChicago)Day:Thursday,05/17|Time:2:00pm-2:50pmTopicAreas:QuantumChemistry;ApplicationDesign&PortingTechniques;ComputationalPhysicsSessionLevel:IntermediateThissessionwilldetailtheperformanceandcapabilitiesofGPU-acceleratedVASP,explaindesigndecisionsmadeinportingVASPtoCUDA,andpresentaroadmapforGPUacceleratedVASPdevelopment.
We'veachievedperformanceimprovementsuptoaround20xonsystemsofaround100ionsandhaveimplementedexact-exchange.
Weareworkingonportsofmoreconventionalfunctionality.
S0071-TheHigh-LevelLinearAlgebraLibraryViennaCLAndItsApplicationsKarlRupp(TUWien)Day:Thursday,05/17|Time:3:00pm-3:50pmTopicAreas:DevelopmentTools&Libraries;Algorithms&NumericalTechniques;ComputationalPhysicsSessionLevel:IntermediateGettoknowViennaCL,anOpenCLhigh-levellinearalgebrasoftware,whichallowstogetthespeedofGPUcomputingattheconvenienceleveloftheC++Boostlibraries.
Decreasethedevelopmentandexecutiontimeofapplicationsbyutilizingourwell-testedandwidelyusedlibrary,insteadofspendingdaysonlearningdetailsofGPUarchitecturesanddebugging.
Weprovideexamplesthatdemonstratenotonlyhowquicklyexistingapplicationsareportedefficientlyfromsingle-threadedexecutiontofullyutilizingmulti-threadedenvironments,butalsohowtoutilizetherichsetoffunctionalitiesrangingfromcommonBLASroutinestoiterativesolvers.
S0087-GPUAccelerationofDenseStellarClustersSimulationBharathPattabiraman(NorthwesternUniversity),StefanUmbreit(NorthwesternUniversity)Day:Thursday,05/17|Time:3:00pm-3:25pmTopicAreas:Astronomy&Astrophysics;ComputationalPhysics;Algorithms&NumericalTechniquesSessionLevel:IntermediateComputingtheinteractionsbetweenstarswithindensestellarclustersisaproblemoffundamentalimportanceintheoreticalastrophysics.
ThispaperpresentstheparallelizationofaMonteCarloalgorithmforsimulatingstellarclusterevolutionusingprogrammableGraphicsProcessingUnits.
Thekernelsofthisalgorithmexhibithighlevelsofdatadependentdecisionmakingandunavoidablenon-contiguousmemoryaccesses.
However,weadoptvariousparallelizationstrategiesandutilizethehighcomputingpoweroftheGPUtoobtainsubstantialnear-linearspeedupswhichcannotbeeasilyachievedonaCPU-basedsystem.
Thisaccelerationallowstoexplorephysicalregimeswhichwereoutofreachofcurrentsimulations.
S0368-UnravelingtheMysteriesofQuarkswithHundredsofGPUsRonaldBabich(NVIDIA)Day:Thursday,05/17|Time:3:00pm-3:50pmTopicAreas:ComputationalPhysics;ApplicationDesign&PortingTechniques;Algorithms&NumericalTechniques;SupercomputingSessionLevel:IntermediateDiveintotheworldofquarksandgluons,andhearhowGPUcomputingisrevolutionizingthewaymanycalculationsinlatticequantumchromodynamics(latticeQCD)areperformed.
Themaincomputationalchallengeinsuchcalculationsistorepeatedlysolvelargesystemsoflinearequationsarisingfromafour-dimensionalfinite-differenceproblem.
Inthissession,we'lldiscussstrategiesforparallelizingsuchasolveracrosshundredsofGPUs.
Theseincludetechniquesandalgorithmsforreducingmemorytrafficandinter-GPUcommunication.
Thenetresultisanimplementationthatachievesbetterthan20Tflopson256GPUs,realizedintheopen-source"QUDA"library.
S0091-SustainableHybridParallelizationofanUnstructuredHydrodynamicCodeRaphalPoncet(Commissariatàl'EnergieAtomiqueetauxEnergiesAlternatives)Day:Thursday,05/17|Time:3:00pm-3:25pmTopicAreas:ApplicationDesign&PortingTechniques;Algorithms&NumericalTechniques;ComputationalFluidDynamics;ComputationalPhysicsSessionLevel:AdvancedThegoalofthispresentationistoshareourmethodologyforportinganumericalcodetohybridsupercomputingarchitecturesusingMPIcoupledwithdirective-basedlanguages(OpenMPformulticoreCPUs,andHMPPforGPUs).
Ourcode,VOLNA,isanunstructuredpartialdifferentialequationhydrodynamicsolverdevelopedforthesimulationoftsunamis.
Ourresultsdemonstratethatusingdirective-basedlanguagessuchasHMPPforGPUprogramming,onecanretaingoodperformance(e.
g.
speedupof15comparedto1CPUcore,3comparedto8CPUcores)withminimalmodificationsoftheoriginalCPUsourcecode(about30linesofdirectivesinourcase).
S0334-TheFastMultipoleMethodonCPUandGPUProcessorsEricDarve(Stanford)Day:Thursday,05/17|Time:3:00pm-3:25pmTopicAreas:ComputationalPhysics;MolecularDynamics;Algorithms&NumericalTechniquesSessionLevel:AdvancedThefastmultipolemethod(FMM)isawidelyusednumericalalgorithmincomputationalengineering.
AcceleratingtheFMMonCUDA-enabledGPUsischallengingbecausetheFMMhasacomplicateddataaccesspattern,mostlyduringtheso-calledmultipole-to-local(M2L)operation.
WehavecreatedseveralschemestooptimizetheM2Landhaveattainedaperformanceofover350(resp.
160)Gflop/sforsingle(double)precisionarithmetic.
TheoptimalalgorithmwasincorporatedintoacompleteFMMcode,whichcanacceptanysmoothkernelasspecifiedbytheuser,makingitveryflexible.
WehavealsodevelopedahighlyefficientCPUversion.
S0282-LeveragingNVIDIAGPUDirectonAPEnet+3DTorusClusterInterconnectDavideRossetti(ItalianNationalInstitueforNuclearPhysics)Day:Thursday,05/17|Time:4:30pm-4:55pmTopicAreas:Supercomputing;ComputationalPhysicsSessionLevel:IntermediateAPEnet+isanovelclusterinterconnect,basedonacustomPCIcardwhichfeaturesaPCIExpressGen2X8linkandare-configurableHWcomponent(FPGA).
Itsupportsa3DTorustopologyandhasspecialaccelerationfeaturesspecificallydevelopedforNVIDIAFermiGPUs.
AnintroductiontothebasicfeaturesandtheprogrammingmodelofAPEnet+willbefollowedbyadescriptionofitsperformanceonsomenumericalsimulations,e.
g.
HighEnergyPhysicssimulations.
S0218-ASIParallelFortran:AGeneral-PurposeFortrantoGPUTranslatorRainaldLohner(GeorgeMasonUniversity)Day:Thursday,05/17|Time:4:30pm-4:55pmTopicAreas:DevelopmentTools&Libraries;ComputationalFluidDynamics;ComputationalPhysics;ParallelProgrammingLanguages&CompilersSessionLevel:AdvancedOverthelast3yearswehavedevelopedageneral-purposeFortrantoGPUtranslator:ASIParallelFortrandoes.
Thetalkwilldetailitspurpose,designlayoutandcapabilities,andshowhowitisusedandimplemented.
TheuseofASIParallelFortranwillbeshownforlarge-scaleCFD/CEMcodesaswellasothergeneralpurposeFortrancodes.
- Dresdenhttp相关文档
- 死刑http错误403-禁止访问
- 未成年人http错误403-禁止访问
- 凤凰http错误403-禁止访问
- 本题http错误403-禁止访问
- 记录http错误403-禁止访问
- 本记录包括中文发言的文本和其他语言发言的译文.定本将刊印在《安全理事会正式记录》.更
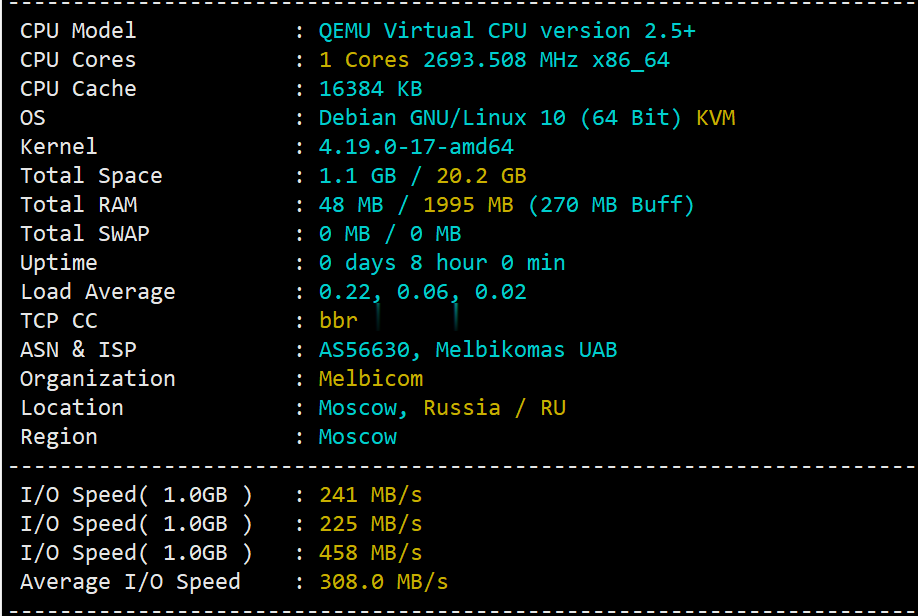
简单测评melbicom俄罗斯莫斯科数据中心的VPS,三网CN2回国,电信双程cn2
melbicom从2015年就开始运作了,在国内也是有一定的粉丝群,站长最早是从2017年开始介绍melbicom。上一次测评melbicom是在2018年,由于期间有不少人持续关注这个品牌,而且站长貌似也听说过路由什么的有变动的迹象。为此,今天重新对莫斯科数据中心的VPS进行一次简单测评,数据仅供参考。官方网站: https://melbicom.net比特币、信用卡、PayPal、支付宝、银联...
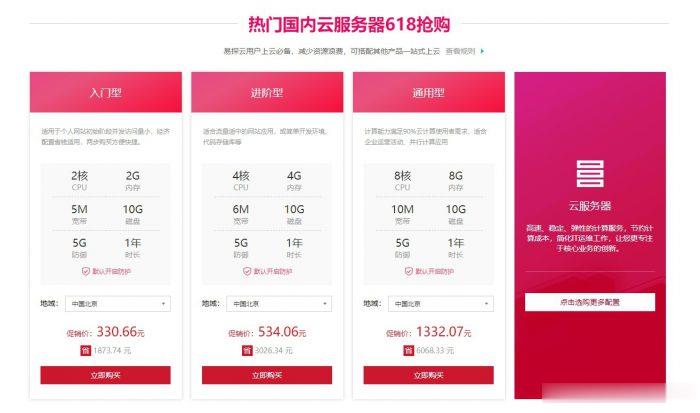
易探云2核2G5M仅330元/年起,国内挂机宝云服务器,独立ip
易探云怎么样?易探云是国内一家云计算服务商家,致力香港服务器、国内外服务器租用及托管等互联网业务,目前主要地区为运作香港BGP、香港CN2、广东、北京、深圳等地区。目前,易探云推出深圳或北京地区的适合挂机和建站的云服务器,国内挂机宝云服务器(可选深圳或北京地区),独立ip;2核2G5M挂机云服务器仅330元/年起!点击进入:易探云官方网站地址易探云国内挂机宝云服务器推荐:1、国内入门型挂机云服务器...
vpsdime7美元/月,美国达拉斯Windows VPS,2核4G/50GB SSD/2TB流量/Hyper-V虚拟化
vpsdime怎么样?vpsdime是2013年成立的国外VPS主机商,以大内存闻名业界,主营基于OpenVZ和KVM虚拟化的Linux套餐,大内存、10Gbps大带宽、大硬盘,有美国西雅图、达拉斯、新泽西、英国、荷兰机房可选。在上个月搞了一款达拉斯Linux系统VPS促销,详情查看:vpsdime夏日促销活动,美国达拉斯vps,2G内存/2核/20gSSD/1T流量,$20/年,此次推出一款Wi...
http错误403-禁止访问为你推荐
-
公司网络被攻击最近公司频繁的受到网络攻击,导致网络瘫痪,又碰到arp攻击,有病毒的,有点崩溃。。。美国互联网瘫痪美国掐断中国互联网怎么办,我们如何解决?是否有后招?中老铁路地铁路是怎么造的?是钻地吗?bbs.99nets.com送点卷的冒险岛私服百度关键词价格查询百度推广关键词怎么扣费?月神谭适合12岁男孩的网名,要非主流的,帮吗找找,谢啦同ip网站同IP网站9个越来越多,为什么?porndao单词prondao的汉语是什么www.119mm.comwww.kb119.com 这个网站你们能打开不?杨丽晓博客杨丽晓是怎么 出道的