bitscn163
cn163 net 时间:2021-03-02 阅读:()
Bi-RealNet:EnhancingthePerformanceof1-bitCNNsWithImprovedRepresentationalCapabilityandAdvancedTrainingAlgorithmZechunLiu1,BaoyuanWu2,WenhanLuo2,XinYang3,WeiLiu2,andKwang-TingCheng11HongKongUniversityofScienceandTechnology2TencentAIlab3HuazhongUniversityofScienceandTechnologyzliubq@connect.
ust.
hk,{wubaoyuan1987,whluo.
china}@gmail.
com,xinyang2014@hust.
edu.
cn,wliu@ee.
columbia.
edu,timcheng@ust.
hkAbstract.
Inthiswork,westudythe1-bitconvolutionalneuralnet-works(CNNs),ofwhichboththeweightsandactivationsarebinary.
Whilebeingecient,theclassicationaccuracyofthecurrent1-bitCNNsismuchworsecomparedtotheircounterpartreal-valuedCNNmodelsonthelarge-scaledataset,likeImageNet.
Tominimizetheper-formancegapbetweenthe1-bitandreal-valuedCNNmodels,weproposeanovelmodel,dubbedBi-Realnet,whichconnectstherealactivations(afterthe1-bitconvolutionand/orBatchNormlayer,beforethesignfunction)toactivationsoftheconsecutiveblock,throughanidentityshortcut.
Consequently,comparedtothestandard1-bitCNN,therep-resentationalcapabilityoftheBi-Realnetissignicantlyenhancedandtheadditionalcostoncomputationisnegligible.
Moreover,wedevelopaspecictrainingalgorithmincludingthreetechnicalnoveltiesfor1-bitCNNs.
Firstly,wederiveatightapproximationtothederivativeofthenon-dierentiablesignfunctionwithrespecttoactivation.
Secondly,weproposeamagnitude-awaregradientwithrespecttotheweightforupdatingtheweightparameters.
Thirdly,wepre-trainthereal-valuedCNNmodelwithaclipfunction,ratherthantheReLUfunction,tobet-terinitializetheBi-Realnet.
ExperimentsonImageNetshowthattheBi-Realnetwiththeproposedtrainingalgorithmachieves56.
4%and62.
2%top-1accuracywith18layersand34layers,respectively.
Com-paredtothestate-of-the-arts(e.
g.
,XNORNet),Bi-Realnetachievesupto10%highertop-1accuracywithmorememorysavingandlowercomputationalcost.
1IntroductionDeepConvolutionalNeuralNetworks(CNNs)haveachievedsubstantialad-vancesinawiderangeofvisiontasks,suchasobjectdetectionandrecognition[12,23,25,5,3,20],depthperception[2,16],visualrelationdetection[29,30],faceCorrespondingauthor.
2ZechunLiuetal.
trackingandalignment[24,32,34,28,27],objecttracking[17],etc.
However,thesuperiorperformanceofCNNsusuallyrequirespowerfulhardwarewithabun-dantcomputingandmemoryresources.
Forexample,high-endGraphicsProcess-ingUnits(GPUs).
Meanwhile,therearegrowingdemandstorunvisiontasks,suchasaugmentedrealityandintelligentnavigation,onmobilehand-heldde-vicesandsmalldrones.
MostmobiledevicesarenotequippedwithapowerfulGPUneitheranadequateamountofmemorytorunandstoretheexpensiveCNNmodel.
Consequently,thehighdemandforcomputationandmemorybe-comesthebottleneckofdeployingthepowerfulCNNsonmostmobiledevices.
Ingeneral,therearethreemajorapproachestoalleviatethislimitation.
Therstistoreducethenumberofweights,suchasSparseCNN[15].
Thesecondistoquantizetheweights(e.
g.
,QNN[8]andDoReFaNet[33]).
Thethirdistoquantizebothweightsandactivations,withtheextremecaseofbothweightsandactivationsbeingbinary.
Inthiswork,westudytheextremecaseofthethirdapproach,i.
e.
,thebinaryCNNs.
Itisalsocalled1-bitCNNs,aseachweightparameterandactivationcanberepresentedby1-bit.
Asdemonstratedin[19],upto32*memorysavingand58*speeduponCPUshavebeenachievedfora1-bitconvolutionlayer,inwhichthecomputationallyheavymatrixmultiplicationoperationsbecomelight-weightedbitwiseXNORoperationsandbit-countoperations.
Thecurrentbinarizationmethodachievescomparableaccuracytoreal-valuednetworksonsmalldatasets(e.
g.
,CIFAR-10andMNIST).
Howeveronthelarge-scaledatasets(e.
g.
,ImageNet),thebinarizationmethodbasedonAlexNetin[7]encounterssevereaccuracydegradation,i.
e.
,from56.
6%to27.
9%[19].
Itrevealsthatthecapabilityofconventional1-bitCNNsisnotsucienttocovergreatdiversityinlarge-scaledatasetslikeImageNet.
AnotherbinarynetworkcalledXNOR-Net[19]wasproposedtoenhancetheperformanceof1-bitCNNs,byutilizingtheabsolutemeanofweightsandactivations.
Theobjectiveofthisstudyistofurtherimprove1-bitCNNs,aswebelieveitspotentialhasnotbeenfullyexplored.
Oneimportantobservationisthatduringtheinferenceprocess,1-bitconvolutionlayergeneratesintegeroutputs,duetothebit-countoperations.
TheintegeroutputswillbecomerealvaluesifthereisaBatchNorm[10]layer.
Butthesereal-valuedactivationsarethenbinarizedto1or+1throughtheconsecutivesignfunction,asshowninFig.
1(a).
Obvi-ously,comparedtobinaryactivations,theseintegersorrealactivationscontainmoreinformation,whichislostintheconventional1-bitCNNs[7].
Inspiredbythisobservation,weproposetokeeptheserealactivationsviaaddingasimpleyeteectiveshortcut,dubbedBi-Realnet.
AsshowninFig.
1(b),theshortcutconnectstherealactivationstoanadditionoperatorwiththereal-valuedac-tivationsofthenextblock.
Bydoingso,therepresentationalcapabilityoftheproposedmodelismuchhigherthanthatoftheoriginal1-bitCNNs,withonlyanegligiblecomputationalcostincurredbytheextraelement-wiseadditionandwithoutanyadditionalmemorycost.
Moreover,wefurtherproposeanoveltrainingalgorithmfor1-bitCNNsin-cludingthreetechnicalnovelties:Bi-RealNet:EnhancingthePerformanceof1-bitCNNs3Fig.
1.
Networkwithintermediatefeaturevisualization,yellowlinesdenotevalueprop-agatedinsidethepathbeingrealwhilebluelinesdenotebinaryvalues.
(a)1-bitCNNwithoutshortcut(b)proposedBi-Realnetwithshortcutpropagatingthereal-valuedfeatures.
–Approximationtothederivativeofthesignfunctionwithre-specttoactivations.
Asthesignfunctionbinarizingtheactivationisnon-dierentiable,weproposetoapproximateitsderivativebyapiecewiselinearfunctioninthebackwardpass,derivedfromthepiecewisepolyno-mialfunctionthatisasecond-orderapproximationofthesignfunction.
Incontrast,theapproximatedderivativeusingastepfunction(i.
e.
,1|x|Net[7],thereal-valuedweightisrstupdatedusinggradientdescent,andthenewbinaryweightisthenobtainedthroughtakingthesignoftheupdatedrealweight.
However,wendthatthegradientwithrespecttotherealweightisonlyrelatedtothesignofthecurrentrealweight,whileindependentofitsmagnitude.
Toderiveamoreeectivegradient,weproposetouseamagnitude-awaresignfunctionduringtraining,thenthegradientwithrespecttotherealweightdependsonboththesignandthemagnitudeofthecurrentrealweight.
Afterconvergence,thebinaryweight(i.
e.
,-1or+1)isobtainedthroughthesignfunctionofthenalrealweightforinference.
–Initialization.
Asahighlynon-convexoptimizationproblem,thetrainingof1-bitCNNsislikelytobesensitivetoinitialization.
In[17],the1-bitCNNmodelisinitializedusingthereal-valuedCNNmodelwiththeReLUfunctionpre-trainedonImageNet.
WeproposetoreplaceReLUbytheclipfunctioninpre-training,astheactivationoftheclipfunctionisclosertothebinaryactivationthanthatofReLU.
4ZechunLiuetal.
ExperimentsonImageNetshowthattheabovethreeideasareusefultotrain1-bitCNNs,includingbothBi-Realnetandothernetworkstructures.
Specically,theirrespectivecontributionstotheimprovementsoftop-1accuracyareupto12%,23%and13%fora18-layerBi-Realnet.
Withthededicatedly-designedshortcutandtheproposedoptimizationtechniques,ourBi-Realnet,withonlybinaryweightsandactivationsinsideeach1-bitconvolutionlayer,achieves56.
4%and62.
2%top-1accuracywith18-layerand34-layerstructures,respectively,withupto16.
0*memorysavingand19.
0*computationalcostreductioncomparedtothefull-precisionCNN.
Comparingtothestate-of-the-artmodel(e.
g.
,XNOR-Net),Bi-Realnetachieves10%highertop-1accuracyonthe18-layernetwork.
2RelatedWorkReducingthenumberofparameters.
Severalmethodshavebeenproposedtocompressneuralnetworksbyreducingthenumberofparametersandneuralconnections.
Forinstance,Heetal.
[5]proposedabottleneckstructurewhichconsistsofthreeconvolutionlayersofltersize1*1,3*3and1*1withashort-cutconnectionasapreliminarybuildingblocktoreducethenumberofparam-etersandtospeeduptraining.
InSqueezeNet[9],some3*3convolutionsarereplacedwith1*1convolutions,resultingina50*reductioninthenumberofparameters.
FitNets[21]imitatesthesoftoutputofalargeteachernetworkus-ingathinanddeepstudentnetwork,andinturnyields10.
4*fewerparametersandsimilaraccuracytoalargeteachernetworkontheCIFAR-10dataset.
InSparseCNN[15],asparsematrixmultiplicationoperationisemployedtozerooutmorethan90%ofparameterstoacceleratethelearningprocess.
MotivatedbytheSparseCNN,Hanetal.
proposedDeepCompression[4]whichemploysconnectionpruning,quantizationwithretrainingandHumancodingtoreducethenumberofneuralconnections,thus,inturn,reducesthememoryusage.
Parameterquantization.
Thepreviousstudy[13]demonstratedthatreal-valueddeepneuralnetworkssuchasAlexNet[12],GoogLeNet[25]andVGG-16[23]onlyencountermarginalaccuracydegradationwhenquantizing32-bitpa-rametersto8-bit.
InIncrementalNetworkQuantization,Zhouetal.
[31]quan-tizetheparameterincrementallyandshowthatitisevenpossibletofurtherreducetheweightprecisionto2-5bitswithslightlyhigheraccuracythanafull-precisionnetworkontheImageNetdataset.
InBinaryConnect[1],Courbariauxetal.
employ1-bitprecisionweights(1and-1)whilemaintainingsucientlyhighaccuracyontheMNIST,CIFAR10andSVHNdatasets.
Quantizingweightsproperlycanachieveconsiderablememorysavingswithlittleaccuracydegradation.
However,accelerationviaweightquantizationislimitedduetothereal-valuedactivations(i.
e.
,theinputtoconvolutionlayers).
Severalrecentstudieshavebeenconductedtoexplorenewnetworkstruc-turesand/ortrainingtechniquesforquantizingbothweightsandactivationswhileminimizingaccuracydegradation.
SuccessfulattemptsincludeDoReFa-Net[33]andQNN[8],whichexploreneuralnetworkstrainedwith1-bitweightsBi-RealNet:EnhancingthePerformanceof1-bitCNNs5Fig.
2.
Themechanismofxnoroperationandbit-countinginsidethe1-bitCNNspre-sentedin[19].
and2-bitactivations,andtheaccuracydropsby6.
1%and4.
9%respectivelyontheImageNetdatasetcomparedtothereal-valuedAlexNet.
Additionally,Bina-ryNet[7]usesonly1-bitweightsand1-bitactivationsinaneuralnetworkandachievescomparableaccuracyasfull-precisionneuralnetworksontheMNISTandCIFAR-10datasets.
InXNOR-Net[19],Rastegarietal.
furtherimproveBinaryNetbymultiplyingtheabsolutemeanoftheweightlterandactivationwiththe1-bitweightandactivationtoimprovetheaccuracy.
ABC-Net[14]proposestoenhancetheaccuracybyusingmoreweightbasesandactivationbases.
Theresultsofthesestudiesareencouraging,butadmittedly,duetothelossofprecisioninweightsandactivations,thenumberofltersinthenetwork(thusthealgorithmcomplexity)growsinordertomaintainhighaccuracy,whichosetsthememorysavingandspeedupofbinarizingthenetwork.
Inthisstudy,weaimtodesign1-bitCNNsaidedwithareal-valuedshortcuttocompensatefortheaccuracylossofbinarization.
Optimizationstrategiesforovercomingthegradientdismatchproblemanddiscreteoptimizationdicultiesin1-bitCNNs,alongwithacustomizedinitializationmethod,areproposedtofullyexplorethepotentialof1-bitCNNswithitslimitedresolution.
3Methodology3.
1Standard1-bitCNNsandItsRepresentationalCapability1-bitconvolutionalneuralnetworks(CNNs)refertotheCNNmodelswithbi-naryweightparametersandbinaryactivationsinintermediateconvolutionlay-ers.
Specically,thebinaryactivationandweightareobtainedthroughasignfunction,ab=Sign(ar)=1ifarNet.
Webelievethatthepoorperformanceof1-bitCNNsiscausedbyitslowrepresentationalcapacity.
WedenoteR(x)astherepresentationalcapabilityofx,i.
e.
,thenumberofallpossiblecongurationsofx,wherexcouldbeascalar,vector,matrixortensor.
Forexample,therepresentationalcapabilityof32channelsofabinary14*14featuremapAisR(A)=214*14*32=26272.
Givena3*3*32binaryweightkernelW,eachentryofAW(i.
e.
,thebitwiseconvolutionoutput)canchoosetheevenvaluesfrom(-288to288),asshowninFig3.
Thus,R(AW)=2896272.
NotethatsincetheBatchNormlayerisauniquemapping,itwillnotincreasethenumberofdierentchoicesbutscalethe(-288,288)toaparticularvalue.
Ifaddingthe1-bitconvolutionlayerbehindtheoutput,eachentryinthefeaturemapisbinarized,andtherepresentationalcapabilityshrinksto26272again.
3.
2Bi-RealNetModelandItsRepresentationalCapabilityWeproposetopreservetherealactivationsbeforethesignfunctiontoincreasetherepresentationalcapabilityofthe1-bitCNN,throughasimpleshortcut.
Specically,asshowninFig.
3(b),oneblockindicatesthestructurethat"Sign→1-bitconvolution→batchnormalization→additionoperator".
TheshortcutBi-RealNet:EnhancingthePerformanceof1-bitCNNs7Fig.
4.
Agraphicalillustrationofthetrainingprocessofthe1-bitCNNs,withAbeingtheactivation,Wbeingtheweight,andthesuperscriptldenotingthelthblockconsist-ingwithSign,1-bitConvolution,andBatchNorm.
Thesubscriptrdenotesrealvalue,bdenotesbinaryvalue,andmdenotestheintermediateoutputbeforetheBatchNormlayer.
connectstheinputactivationstothesignfunctioninthecurrentblocktotheoutputactivationsafterthebatchnormalizationinthesameblock,andthesetwoactivationsareaddedthroughanadditionoperator,andthenthecombinedactivationsareinputtedtothesignfunctioninthenextblock.
Therepresenta-tionalcapabilityofeachentryintheaddedactivationsis2892.
Consequently,therepresentationalcapabilityofeachblockinthe1-bitCNNwiththeaboveshortcutbecomes(2892)6272.
Asbothrealandbinaryactivationsarekept,wecalltheproposedmodelasBi-Realnet.
Therepresentationalcapabilityofeachblockinthe1-bitCNNissignicantlyenhancedduetothesimpleidentityshortcut.
Theonlyadditionalcostofcompu-tationistheadditionoperationoftworealactivations,astheserealactivationsalreadyexistinthestandard1-bitCNN(i.
e.
,withoutshortcuts).
Moreover,astheactivationsarecomputedonthey,noadditionalmemoryisneeded.
3.
3TrainingBi-RealNetAsbothactivationsandweightparametersarebinary,thecontinuousopti-mizationmethod,i.
e.
,thestochasticgradientdescent(SGD),cannotbedirectlyadoptedtotrainthe1-bitCNN.
Therearetwomajorchallenges.
Oneishowtocomputethegradientofthesignfunctiononactivations,whichisnon-dierentiable.
Theotheristhatthegradientofthelosswithrespecttothebinaryweightistoosmalltochangetheweight'ssign.
Theauthorsof[7]pro-posedtoadjustthestandardSGDalgorithmtoapproximatelytrainthe1-bitCNN.
Specically,thegradientofthesignfunctiononactivationsisapproxi-matedbythegradientofthepiecewiselinearfunction,asshowninFig.
5(b).
Totacklethesecondchallenge,themethodproposedin[7]updatesthereal-valuedweightsbythegradientcomputedwithregardtothebinaryweightandobtainsthebinaryweightbytakingthesignoftherealweights.
Astheidentityshortcutwillnotadddicultyfortraining,thetrainingalgorithmproposedin[7]canalsobeadoptedtotraintheBi-Realnetmodel.
However,weproposeanoveltrainingalgorithmtotackletheabovetwomajorchallenges,whichismoresuitablefor8ZechunLiuetal.
Fig.
5.
(a)Signfunctionanditsderivative,(b)Clipfunctionanditsderivativeforapproximatingthederivativeofthesignfunction,proposedin[7],(c)Proposeddier-entiablepiecewisepolynomialfunctionanditstriangle-shapedderivativeforapproxi-matingthederivativeofthesignfunctioningradientscomputation.
theBi-Realnetmodelaswellasother1-bitCNNs.
Besides,wealsoproposeanovelinitializationmethod.
WepresentagraphicalillustrationofthetrainingofBi-RealnetinFig.
4.
Theidentityshortcutisomittedinthegraphforclarity,asitwillnotchangethemainpartofthetrainingalgorithm.
Approximationtothederivativeofthesignfunctionwithrespecttoactivations.
AsshowninFig.
5(a),thederivativeofthesignfunctionisanimpulsefunction,whichcannotbeutilizedintraining.
LAl,tr=LAl,tbAl,tbAl,tr=LAl,tbSign(Al,tr)Al,tr≈LAl,trF(Al,tr)Al,tr,(2)whereF(Al,tr)isadierentiableapproximationofthenon-dierentiableSign(Al,tr).
In[7],F(Al,tr)issetastheclipfunction,leadingtothederivativeasastep-function(see5(b)).
Inthiswork,weutilizeapiecewisepolynomialfunction(see5(c))astheapproximationfunction,asEq.
(3)left.
F(ar)=1ifarNet:EnhancingthePerformanceof1-bitCNNs9Thestandardgradientdescentalgorithmcannotbedirectlyappliedasthegradientisnotlargeenoughtochangethebinaryweights.
Totacklethisprob-lem,themethodof[7]introducedarealweightWlrandasignfunctionduringtraining.
Hencethebinaryweightparametercanbeseenastheoutputtothesignfunction,i.
e.
,Wlb=Sign(Wlr),asshownintheuppersub-gureinFig.
4.
Consequently,Wlrisupdatedusinggradientdescentinthebackwardpass,asfollowsWl,t+1r=Wl,trηLWl,tr=Wl,trηLWl,tbWl,tbWl,tr.
(4)NotethatWl,tbWl,trindicatestheelement-wisederivative.
In[7],Wl,tb(i,j)Wl,tr(i,j)issetto1ifWl,tr(i,j)∈[1,1],otherwise0.
ThederivativeLWl,tbisderivedfromthechainrule,asfollowsLWl,tb=LAl+1,trAl+1,trAl,tmAl,tmWl,tb=LAl+1,trθl,tAlb,(5)whereθl,t=Al+1,trAl,tmdenotesthederivativeoftheBatchNormlayer(seeFig.
4)andhasanegativecorrelationtoWl,tb.
AsWl,tb∈{1,+1},thegradientLWl,trisonlyrelatedtothesignofWl,tr,whileisindependentofitsmagnitude.
Basedonthisobservation,weproposetoreplacetheabovesignfunctionbyamagnitude-awarefunction,asfollows:Wl,tb=Wl,tr1,1|Wl,tr|Sign(Wl,tr),(6)where|Wl,tr|denotesthenumberofentriesinWl,tr.
Consequently,theupdateofWlrbecomesWl,t+1r=Wl,trηLWl,tbWl,tbWl,tr=Wl,trηLAl+1,trθl,tAlbWl,tbWl,tr,(7)whereWl,tbWl,tr≈Wl,tr1,1|Wl,tr|·Sign(Wl,tr)Wl,tr≈Wl,tr1,1|Wl,tr|·1|Wl,tr|Net.
However,theactivationofReLUisnon-negative,whilethatofSignis1or+1.
Due10ZechunLiuetal.
tothisdierence,therealCNNswithReLUmaynotprovideasuitableinitialpointfortrainingthe1-bitCNNs.
Instead,weproposetoreplaceReLUwithclip(1,x,1)topre-trainthereal-valuedCNNmodel,astheactivationoftheclipfunctionisclosertothesignfunctionthanReLU.
Theecacyofthisnewinitializationwillbeevaluatedinexperiments.
4ExperimentsInthissection,werstlyintroducethedatasetforexperimentsandimplementa-tiondetailsinSec4.
1.
ThenweconductablationstudyinSec.
4.
2toinvestigatetheeectivenessoftheproposedtechniques.
ThispartisfollowedbycomparingourBi-Realnetwithotherstate-of-the-artbinarynetworksregardingaccuracyinSec4.
3.
Sec.
4.
4reportsmemoryusageandcomputationcostincomparisonwithothernetworks.
4.
1DatasetandImplementationDetailsTheexperimentsarecarriedoutontheILSVRC12ImageNetclassicationdataset[22].
ImageNetisalarge-scaledatasetwith1000classesand1.
2milliontrainingimagesand50kvalidationimages.
ComparedtootherdatasetslikeCIFAR-10[11]orMNIST[18],ImageNetismorechallengingduetoitslargescaleandgreatdiversity.
ThestudyonthisdatasetwillvalidatethesuperiorityoftheproposedBi-Realnetworkstructureandtheeectivenessofthreetrainingmethodsfor1-bitCNNs.
Inourcomparison,wereportboththetop-1andtop-5accuracies.
ForeachimageintheImageNetdataset,thesmallerdimensionoftheimageisrescaledto256whilekeepingtheaspectratiointact.
Fortraining,arandomcropofsize224*224isselected.
Notethat,incontrasttoXNOR-Netandthefull-precisionResNet,wedonotusetheoperationofrandomresize,whichmightimprovetheperformancefurther.
Forinference,weemploythe224*224centercropfromimages.
Training:WetraintwoinstancesoftheBi-Realnet,includingan18-layerBi-Realnetanda34-layerBi-Realnet.
Thetrainingofthemconsistsoftwosteps:trainingthe1-bitconvolutionlayerandretrainingtheBatchNorm.
Intherststep,theweightsinthe1-bitconvolutionlayerarebinarizedtothesignofreal-valuedweightsmultiplyingtheabsolutemeanofeachkernel.
WeusetheSGDsolverwiththemomentumof0.
9andsettheweight-decayto0,whichmeanswenolongerencouragetheweightstobecloseto0.
Forthe18-layerBi-Realnet,werunthetrainingalgorithmfor20epochswithabatchsizeof128.
Thelearningratestartsfrom0.
01andisdecayedtwicebymultiplying0.
1atthe10thandthe15thepoch.
Forthe34-layerBi-Realnet,thetrainingprocessincludes40epochsandthebatchsizeissetto1024.
Thelearningratestartsfrom0.
08andismultipliedby0.
1atthe20thandthe30thepoch,respectively.
Inthesecondstep,weconstrainttheweightsto-1and1,andsetthelearningrateinallconvolutionlayersto0andretraintheBatchNormlayerfor1epochtoabsorbthescalingfactor.
Bi-RealNet:EnhancingthePerformanceof1-bitCNNs11Fig.
6.
Threedierentnetworksdierintheshortcutdesignofconnectingtheblocksshownin(a)conjointlayersofSign,1-bitConvolution,andtheBatchNorm.
(b)Bi-Realnetwithshortcutbypassingeveryblock(c)Res-Netwithshortcutbypassingtwoblocks,whichcorrespondstotheReLU-onlypre-activationproposedin[6]and(d)Plain-Netwithouttheshortcut.
Thesethreestructuresshownin(b),(c)and(d)havethesamenumberofweights.
Inference:weusethetrainedmodelwithbinaryweightsandbinaryactivationsinthe1-bitconvolutionlayersforinference.
4.
2AblationStudyThreebuildingblocks.
TheshortcutinourBi-Realnettransfersreal-valuedrepresentationwithoutadditionalmemorycost,whichplaysanimportantroleinimprovingitscapability.
Toverifyitsimportance,weimplementedaPlain-NetstructurewithoutshortcutasshowninFig.
6(d)forcomparison.
Atthesametime,asournetworkstructureemploysthesamenumberofweightltersandlayersasthestandardResNet,wealsomakeacomparisonwiththestandardResNetshowninFig.
6(c).
Forafaircomparison,weadopttheReLU-onlypre-activationResNetstructurein[6],whichdiersfromBi-Realnetonlyinthestructureoftwolayersperblockinsteadofonelayerperblock.
ThelayerorderandshortcutdesigninFig.
6(c)arealsoapplicablefor1-bitCNN.
ThecomparisoncanjustifythebenetofimplementingourBi-Realnetbyspecicallyreplacingthe2-conv-layer-per-blockRes-Netstructurewithtwo1-conv-layer-per-blockBi-Realstructure.
AsdiscussedinSec.
3,weproposedtoovercometheoptimizationchallengesinducedbydiscreteweightsandactivationsby1)approximationtothederiva-tiveofthesignfunctionwithrespecttoactivations,2)magnitude-awaregradientwithrespecttoweightsand3)clipinitialization.
Tostudyhowtheseproposalsbenetthe1-bitCNNsindividuallyandcollectively,wetrainthe18-layerstruc-tureandthe34-layerstructurewithacombinationofthesetechniquesontheImageNetdataset.
Thuswederive2*3*2*2*2=48pairsofvaluesoftop-1andtop-5accuracy,whicharepresentedinTable1.
BasedonTable1,wecanevaluateeachtechnique'sindividualcontributionandcollectivecontributionofeachuniquecombinationofthesetechniquesto-wardsthenalaccuracy.
1)Comparingthe4th7thcolumnswiththe8th9thcolumns,boththeproposedBi-RealnetandthebinarizedstandardResNetoutperformtheirplain12ZechunLiuetal.
Table1.
Top-1andtop-5accuracies(inpercentage)ofdierentcombinationsofthethreeproposedtechniquesonthreedierentnetworkstructures,Bi-Realnet,ResNetandPlainNet,showninFig.
6.
Initiali-WeightActivationBi-Real-18Res-18Plain-18Bi-Real-34Res-34Plain-34zationupdatebackwardtop-1top-5top-1top-5top-1top-5top-1top-5top-1top-5top-1top-5ReLUOriginalOriginal32.
956.
727.
850.
53.
39.
553.
176.
927.
549.
91.
44.
8Proposed36.
860.
832.
256.
04.
713.
758.
081.
033.
957.
91.
65.
3ProposedOriginal40.
565.
133.
958.
14.
312.
259.
982.
033.
657.
91.
86.
1Proposed47.
571.
941.
666.
48.
521.
561.
483.
347.
572.
02.
16.
8Real-valuedNet68.
588.
367.
887.
867.
587.
570.
489.
369.
188.
366.
886.
8ClipOriginalOriginal37.
462.
432.
856.
73.
29.
455.
979.
135.
059.
22.
26.
9Proposed38.
162.
734.
358.
44.
914.
358.
181.
038.
262.
62.
37.
5ProposedOriginal53.
677.
542.
467.
36.
717.
160.
882.
943.
968.
72.
57.
9Proposed56.
479.
545.
770.
312.
127.
762.
283.
949.
073.
62.
68.
3Real-valuedNet68.
088.
167.
587.
664.
285.
369.
789.
167.
987.
857.
179.
9Full-precisionoriginalResNet[5]69.
389.
273.
391.
3counterpartswithasignicantmargin,whichvalidatestheeectivenessofshort-cutandthedisadvantageofdirectlyconcatenatingthe1-bitconvolutionlayers.
AsPlain-18hasathinanddeepstructure,whichhasthesameweightltersbutnoshortcut,binarizingitresultsinverylimitednetworkrepresentationalcapac-ityinthelastconvolutionlayer,andthuscanhardlyachievegoodaccuracy.
2)Comparingthe4th5thand6th7thcolumns,the18-layerBi-RealnetstructureimprovestheaccuracyofthebinarizedstandardResNet-18byabout18%.
ThisvalidatestheconjecturethattheBi-Realnetstructurewithmoreshortcutsfurtherenhancesthenetworkcapacitycomparedtothestan-dardResNetstructure.
Replacingthe2-conv-layer-per-blockstructureemployedinRes-Netwithtwo1-conv-layer-per-blockstructure,adoptedbyBi-Realnet,couldevenbenetareal-valuednetwork.
3)Allproposedtechniquesforinitialization,weightupdateandactivationbackwardimprovetheaccuracyatvariousdegrees.
Forthe18-layerBi-Realnetstructure,theimprovementfromtheweight(about23%,bycomparingthe2ndand4throws)isgreaterthantheimprovementfromtheactivation(about12%,bycomparingthe2ndand4throws)andtheimprovementfromreplacingReLUwithClipforinitialization(about13%,bycomparingthe2ndand7throws).
Thesethreeproposedtrainingmechanismsareindependentandcanfunctioncollaborativelytowardsenhancingthenalaccuracy.
4)Theproposedtrainingmethodscanimprovethenalaccuracyforallthreenetworksincomparisonwiththeoriginaltrainingmethod,whichimpliestheseproposedthreetrainingmethodsareuniversallysuitableforvariousnetworks.
5)ThetwoimplementedBi-Realnets(i.
e.
the18-layerand34-layerstruc-tures)togetherwiththeproposedtrainingmethods,achieveapproximately83%and89%oftheaccuracyleveloftheircorrespondingfull-precisionnetworks,butwithahugeamountofspeedupandcomputationcostsaving.
Bi-RealNet:EnhancingthePerformanceof1-bitCNNs13Table2.
Thistablecomparesboththetop-1andtop-5accuraciesofourBi-realnetwithotherstate-of-the-artbinarizationmethods:BinaryNet[7],XNOR-Net[19],ABC-Net[14]onboththeRes-18andRes-34[5].
TheBi-Realnetoutperformsothermethodsbyaconsiderablemargin.
Bi-RealnetBinaryNetABC-NetXNOR-NetFull-precision18-layerTop-156.
4%42.
2%42.
7%51.
2%69.
3%Top-579.
5%67.
1%67.
6%73.
2%89.
2%34-layerTop-162.
2%–52.
4%–73.
3%Top-583.
9%–76.
5%–91.
3%Inshort,theshortcutenhancesthenetworkrepresentationalcapability,andtheproposedtrainingmethodshelpthenetworktoapproachtheaccuracyupperbound.
4.
3AccuracyComparisonWithState-of-The-ArtWhiletheablationstudydemonstratestheeectivenessofour1-layer-per-blockstructureandtheproposedtechniquesforoptimaltraining,itisalsonecessarytocomparewithotherstate-of-the-artmethodstoevaluateBi-Realnet'soverallperformance.
Tothisend,wecarryoutacomparativestudywiththreemethods:BinaryNet[7],XNOR-Net[19]andABC-Net[14].
ThesethreenetworksarerepresentativemethodsofbinarizingbothweightsandactivationsforCNNsandachievethestate-of-the-artresults.
Notethat,forafaircomparison,ourBi-RealnetcontainsthesameamountofweightltersasthecorrespondingResNetthatthesemethodsattempttobinarize,dieringonlyintheshortcutdesign.
Table2showstheresults.
Theresultsofthethreenetworksarequoteddi-rectlyfromthecorrespondingreferences,exceptthattheresultofBinaryNetisquotedfromABC-Net[14].
ThecomparisonclearlyindicatesthattheproposedBi-Realnetoutperformsthethreenetworksbyaconsiderablemarginintermsofboththetop-1andtop-5accuracies.
Specically,the18-layerBi-Realnetout-performsits18-layercounterpartsBinaryNetandABC-Netwithrelative33%advantage,andachievesaroughly10%relativeimprovementovertheXNOR-Net.
Similarimprovementscanbeobservedfor34-layerBi-Realnet.
Inshort,ourBi-Realnetismorecompetitivethanthestate-of-the-artbinarynetworks.
4.
4EciencyandMemoryUsageAnalysisInthissection,weanalyzethesavingofmemoryusageandspeedupincomputa-tionofBi-RealnetbycomparingwiththeXNOR-Net[19]andthefull-precisionnetworkindividually.
Thememoryusageiscomputedasthesummationof32bittimesthenum-berofreal-valuedparametersand1bittimesthenumberofbinaryparametersinthenetwork.
Foreciencycomparison,weuseFLOPstomeasurethetotal14ZechunLiuetal.
Table3.
MemoryusageandFLOPscalculationinBi-Realnet.
MemoryusageMemorysavingFLOPsSpeedup18-layerBi-Realnet33.
6Mbit11.
14*1.
63*10811.
06*XNOR-Net33.
7Mbit11.
10*1.
67*10810.
86*Full-precisionRes-Net374.
1Mbit–1.
81*109–34-layerBi-Realnet43.
7Mbit15.
97*1.
93*10818.
99*XNOR-Net43.
9Mbit15.
88*1.
98*10818.
47*Full-precisionRes-Net697.
3Mbit–3.
66*109–real-valuedmultiplicationcomputationintheBi-Realnet,followingthecalcu-lationmethodin[5].
AsthebitwiseXNORoperationandbit-countingcanbeperformedinaparallelof64bythecurrentgenerationofCPUs,theFLOPsiscalculatedastheamountofreal-valuedoatingpointmultiplicationplus1/64oftheamountof1-bitmultiplication.
WefollowthesuggestioninXNOR-Net[19],tokeeptheweightsandactiva-tionsintherstconvolutionandthelastfully-connectedlayerstobereal-valued.
Wealsoadoptthesamereal-valued1x1convolutioninTypeBshort-cut[5]asimplementedinXNOR-Net.
Notethatthis1x1convolutionisforthetransitionbetweentwostagesofResNetandthusallinformationshouldbepreserved.
Asthenumberofweightsinthosethreekindsoflayersaccountsforonlyaverysmallproportionofthetotalnumberofweights,thelimitedmemorysavingforbinarizingthemdoesnotjustifytheperformancedegradationcausedbytheinformationloss.
Forboththe18-layerandthe34-layernetworks,theproposedBi-Realnetreducesthememoryusageby11.
1timesand16.
0timesindividually,andachievescomputationreductionofabout11.
1timesand19.
0times,incomparisonwiththefull-precisionnetwork.
Withoutusingreal-valuedweightsandactivationsforscalingbinaryonesduringinferencetime,ourBi-RealnetrequiresfewerFLOPsanduseslessmemorythanXNOR-Netandisalsomucheasiertoimplement.
5ConclusionInthiswork,wehaveproposedanovel1-bitCNNmodel,dubbedBi-Realnet.
Comparedwiththestandard1-bitCNNs,Bi-Realnetutilizesasimpleshort-cuttosignicantlyenhancetherepresentationalcapability.
Further,anadvancedtrainingalgorithmisspecicallydesignedfortraining1-bitCNNs(includingBi-Realnet),includingatighterapproximationofthederivativeofthesignfunctionwithrespecttheactivation,themagnitude-awaregradientwithrespecttotheweight,aswellasanovelinitialization.
ExtensiveexperimentalresultsdemonstratethattheproposedBi-Realnetandthenoveltrainingalgorithmshowsuperiorityoverthestate-of-the-artmethods.
Infuture,wewillexploreotheradvancedintegerprogrammingalgorithms(e.
g.
,Lp-BoxADMM[26])totrainBi-RealNet.
Bi-RealNet:EnhancingthePerformanceof1-bitCNNs15References1.
Courbariaux,M.
,Bengio,Y.
,David,J.
P.
:Binaryconnect:Trainingdeepneuralnet-workswithbinaryweightsduringpropagations.
In:Advancesinneuralinformationprocessingsystems.
pp.
3123–3131(2015)2.
Garg,R.
,BG,V.
K.
,Carneiro,G.
,Reid,I.
:Unsupervisedcnnforsingleviewdepthestimation:Geometrytotherescue.
In:EuropeanConferenceonComputerVision.
pp.
740–756.
Springer(2016)3.
Girshick,R.
,Donahue,J.
,Darrell,T.
,Malik,J.
:Richfeaturehierarchiesforac-curateobjectdetectionandsemanticsegmentation.
In:ProceedingsoftheIEEEconferenceoncomputervisionandpatternrecognition.
pp.
580–587(2014)4.
Han,S.
,Mao,H.
,Dally,W.
J.
:Deepcompression:Compressingdeepneuralnet-workswithpruning,trainedquantizationandhumancoding.
arXivpreprintarXiv:1510.
00149(2015)5.
He,K.
,Zhang,X.
,Ren,S.
,Sun,J.
:Deepresiduallearningforimagerecognition.
In:ProceedingsoftheIEEEconferenceoncomputervisionandpatternrecognition.
pp.
770–778(2016)6.
He,K.
,Zhang,X.
,Ren,S.
,Sun,J.
:Identitymappingsindeepresidualnetworks.
In:Europeanconferenceoncomputervision.
pp.
630–645.
Springer(2016)7.
Hubara,I.
,Courbariaux,M.
,Soudry,D.
,El-Yaniv,R.
,Bengio,Y.
:Binarizedneuralnetworks.
In:Lee,D.
D.
,Sugiyama,M.
,Luxburg,U.
V.
,Guyon,I.
,Gar-nett,R.
(eds.
)AdvancesinNeuralInformationProcessingSystems29,pp.
4107–4115.
CurranAssociates,Inc.
(2016),http://papers.
nips.
cc/paper/6573-binarized-neural-networks.
pdf8.
Hubara,I.
,Courbariaux,M.
,Soudry,D.
,El-Yaniv,R.
,Bengio,Y.
:Quantizedneu-ralnetworks:Trainingneuralnetworkswithlowprecisionweightsandactivations(2016)9.
Iandola,F.
N.
,Han,S.
,Moskewicz,M.
W.
,Ashraf,K.
,Dally,W.
J.
,Keutzer,K.
:Squeezenet:Alexnet-levelaccuracywith50xfewerparametersand0.
5mbmodelsize.
arXivpreprintarXiv:1602.
07360(2016)10.
Ioe,S.
,Szegedy,C.
:Batchnormalization:Acceleratingdeepnetworktrainingbyreducinginternalcovariateshift.
arXivpreprintarXiv:1502.
03167(2015)11.
Krizhevsky,A.
,Hinton,G.
:Learningmultiplelayersoffeaturesfromtinyimages.
Tech.
rep.
,Citeseer(2009)12.
Krizhevsky,A.
,Sutskever,I.
,Hinton,G.
E.
:Imagenetclassicationwithdeepcon-volutionalneuralnetworks.
In:Advancesinneuralinformationprocessingsystems.
pp.
1097–1105(2012)13.
Lai,L.
,Suda,N.
,Chandra,V.
:Deepconvolutionalneuralnetworkinferencewithoating-pointweightsandxed-pointactivations.
arXivpreprintarXiv:1703.
03073(2017)14.
Lin,X.
,Zhao,C.
,Pan,W.
:Towardsaccuratebinaryconvolutionalneuralnetwork.
In:AdvancesinNeuralInformationProcessingSystems.
pp.
345–353(2017)15.
Liu,B.
,Wang,M.
,Foroosh,H.
,Tappen,M.
,Pensky,M.
:Sparseconvolutionalneuralnetworks.
In:ProceedingsoftheIEEEConferenceonComputerVisionandPatternRecognition.
pp.
806–814(2015)16.
Liu,F.
,Shen,C.
,Lin,G.
,Reid,I.
D.
:Learningdepthfromsinglemonocularimagesusingdeepconvolutionalneuralelds.
IEEETrans.
PatternAnal.
Mach.
Intell.
38(10),2024–2039(2016)17.
Luo,W.
,Sun,P.
,Zhong,F.
,Liu,W.
,Zhang,T.
,Wang,Y.
:End-to-endactiveobjecttrackingviareinforcementlearning.
ICML(2018)16ZechunLiuetal.
18.
Netzer,Y.
,Wang,T.
,Coates,A.
,Bissacco,A.
,Wu,B.
,Ng,A.
Y.
:Readingdigitsinnaturalimageswithunsupervisedfeaturelearning.
In:NIPSworkshopondeeplearningandunsupervisedfeaturelearning.
vol.
2011,p.
5(2011)19.
Rastegari,M.
,Ordonez,V.
,Redmon,J.
,Farhadi,A.
:Xnor-net:Imagenetclassi-cationusingbinaryconvolutionalneuralnetworks.
In:EuropeanConferenceonComputerVision.
pp.
525–542.
Springer(2016)20.
Ren,S.
,He,K.
,Girshick,R.
,Sun,J.
:Fasterr-cnn:Towardsreal-timeobjectdetec-tionwithregionproposalnetworks.
In:Advancesinneuralinformationprocessingsystems.
pp.
91–99(2015)21.
Romero,A.
,Ballas,N.
,Kahou,S.
E.
,Chassang,A.
,Gatta,C.
,Bengio,Y.
:Fitnets:Hintsforthindeepnets.
arXivpreprintarXiv:1412.
6550(2014)22.
Russakovsky,O.
,Deng,J.
,Su,H.
,Krause,J.
,Satheesh,S.
,Ma,S.
,Huang,Z.
,Karpathy,A.
,Khosla,A.
,Bernstein,M.
,etal.
:Imagenetlargescalevisualrecog-nitionchallenge.
InternationalJournalofComputerVision115(3),211–252(2015)23.
Simonyan,K.
,Zisserman,A.
:Verydeepconvolutionalnetworksforlarge-scaleimagerecognition.
arXivpreprintarXiv:1409.
1556(2014)24.
Sun,Y.
,Wang,X.
,Tang,X.
:Deepconvolutionalnetworkcascadeforfacialpointdetection.
In:ProceedingsoftheIEEEconferenceoncomputervisionandpatternrecognition.
pp.
3476–3483(2013)25.
Szegedy,C.
,Liu,W.
,Jia,Y.
,Sermanet,P.
,Reed,S.
,Anguelov,D.
,Erhan,D.
,Vanhoucke,V.
,Rabinovich,A.
:Goingdeeperwithconvolutions.
In:ProceedingsoftheIEEEconferenceoncomputervisionandpatternrecognition.
pp.
1–9(2015)26.
Wu,B.
,Ghanem,B.
:lp-boxadmm:Aversatileframeworkforintegerprogramming.
IEEETransactionsonPatternAnalysisandMachineIntelligence(2018)27.
Wu,B.
,Hu,B.
G.
,Ji,Q.
:Acoupledhiddenmarkovrandomeldmodelforsimul-taneousfaceclusteringandtrackinginvideos.
PatternRecognition64,361–373(2017)28.
Wu,B.
,Lyu,S.
,Hu,B.
G.
,Ji,Q.
:Simultaneousclusteringandtrackletlinkingformulti-facetrackinginvideos.
In:ProceedingsoftheIEEEInternationalConferenceonComputerVision.
pp.
2856–2863(2013)29.
Zhang,H.
,Kyaw,Z.
,Chang,S.
F.
,Chua,T.
S.
:Visualtranslationembeddingnet-workforvisualrelationdetection.
In:CVPR.
vol.
1,p.
5(2017)30.
Zhang,H.
,Kyaw,Z.
,Yu,J.
,Chang,S.
F.
:Ppr-fcn:Weaklysupervisedvisualrela-tiondetectionviaparallelpairwiser-fcn.
arXivpreprintarXiv:1708.
01956(2017)31.
Zhou,A.
,Yao,A.
,Guo,Y.
,Xu,L.
,Chen,Y.
:Incrementalnetworkquantization:Towardslosslesscnnswithlow-precisionweights.
arXivpreprintarXiv:1702.
03044(2017)32.
Zhou,E.
,Fan,H.
,Cao,Z.
,Jiang,Y.
,Yin,Q.
:Extensivefaciallandmarklocaliza-tionwithcoarse-to-neconvolutionalnetworkcascade.
In:ProceedingsoftheIEEEInternationalConferenceonComputerVisionWorkshops.
pp.
386–391(2013)33.
Zhou,S.
,Wu,Y.
,Ni,Z.
,Zhou,X.
,Wen,H.
,Zou,Y.
:Dorefa-net:Traininglowbitwidthconvolutionalneuralnetworkswithlowbitwidthgradients.
arXivpreprintarXiv:1606.
06160(2016)34.
Zhu,X.
,Lei,Z.
,Liu,X.
,Shi,H.
,Li,S.
Z.
:Facealignmentacrosslargeposes:A3dsolution.
In:ProceedingsoftheIEEEconferenceoncomputervisionandpatternrecognition.
pp.
146–155(2016)
ust.
hk,{wubaoyuan1987,whluo.
china}@gmail.
com,xinyang2014@hust.
edu.
cn,wliu@ee.
columbia.
edu,timcheng@ust.
hkAbstract.
Inthiswork,westudythe1-bitconvolutionalneuralnet-works(CNNs),ofwhichboththeweightsandactivationsarebinary.
Whilebeingecient,theclassicationaccuracyofthecurrent1-bitCNNsismuchworsecomparedtotheircounterpartreal-valuedCNNmodelsonthelarge-scaledataset,likeImageNet.
Tominimizetheper-formancegapbetweenthe1-bitandreal-valuedCNNmodels,weproposeanovelmodel,dubbedBi-Realnet,whichconnectstherealactivations(afterthe1-bitconvolutionand/orBatchNormlayer,beforethesignfunction)toactivationsoftheconsecutiveblock,throughanidentityshortcut.
Consequently,comparedtothestandard1-bitCNN,therep-resentationalcapabilityoftheBi-Realnetissignicantlyenhancedandtheadditionalcostoncomputationisnegligible.
Moreover,wedevelopaspecictrainingalgorithmincludingthreetechnicalnoveltiesfor1-bitCNNs.
Firstly,wederiveatightapproximationtothederivativeofthenon-dierentiablesignfunctionwithrespecttoactivation.
Secondly,weproposeamagnitude-awaregradientwithrespecttotheweightforupdatingtheweightparameters.
Thirdly,wepre-trainthereal-valuedCNNmodelwithaclipfunction,ratherthantheReLUfunction,tobet-terinitializetheBi-Realnet.
ExperimentsonImageNetshowthattheBi-Realnetwiththeproposedtrainingalgorithmachieves56.
4%and62.
2%top-1accuracywith18layersand34layers,respectively.
Com-paredtothestate-of-the-arts(e.
g.
,XNORNet),Bi-Realnetachievesupto10%highertop-1accuracywithmorememorysavingandlowercomputationalcost.
1IntroductionDeepConvolutionalNeuralNetworks(CNNs)haveachievedsubstantialad-vancesinawiderangeofvisiontasks,suchasobjectdetectionandrecognition[12,23,25,5,3,20],depthperception[2,16],visualrelationdetection[29,30],faceCorrespondingauthor.
2ZechunLiuetal.
trackingandalignment[24,32,34,28,27],objecttracking[17],etc.
However,thesuperiorperformanceofCNNsusuallyrequirespowerfulhardwarewithabun-dantcomputingandmemoryresources.
Forexample,high-endGraphicsProcess-ingUnits(GPUs).
Meanwhile,therearegrowingdemandstorunvisiontasks,suchasaugmentedrealityandintelligentnavigation,onmobilehand-heldde-vicesandsmalldrones.
MostmobiledevicesarenotequippedwithapowerfulGPUneitheranadequateamountofmemorytorunandstoretheexpensiveCNNmodel.
Consequently,thehighdemandforcomputationandmemorybe-comesthebottleneckofdeployingthepowerfulCNNsonmostmobiledevices.
Ingeneral,therearethreemajorapproachestoalleviatethislimitation.
Therstistoreducethenumberofweights,suchasSparseCNN[15].
Thesecondistoquantizetheweights(e.
g.
,QNN[8]andDoReFaNet[33]).
Thethirdistoquantizebothweightsandactivations,withtheextremecaseofbothweightsandactivationsbeingbinary.
Inthiswork,westudytheextremecaseofthethirdapproach,i.
e.
,thebinaryCNNs.
Itisalsocalled1-bitCNNs,aseachweightparameterandactivationcanberepresentedby1-bit.
Asdemonstratedin[19],upto32*memorysavingand58*speeduponCPUshavebeenachievedfora1-bitconvolutionlayer,inwhichthecomputationallyheavymatrixmultiplicationoperationsbecomelight-weightedbitwiseXNORoperationsandbit-countoperations.
Thecurrentbinarizationmethodachievescomparableaccuracytoreal-valuednetworksonsmalldatasets(e.
g.
,CIFAR-10andMNIST).
Howeveronthelarge-scaledatasets(e.
g.
,ImageNet),thebinarizationmethodbasedonAlexNetin[7]encounterssevereaccuracydegradation,i.
e.
,from56.
6%to27.
9%[19].
Itrevealsthatthecapabilityofconventional1-bitCNNsisnotsucienttocovergreatdiversityinlarge-scaledatasetslikeImageNet.
AnotherbinarynetworkcalledXNOR-Net[19]wasproposedtoenhancetheperformanceof1-bitCNNs,byutilizingtheabsolutemeanofweightsandactivations.
Theobjectiveofthisstudyistofurtherimprove1-bitCNNs,aswebelieveitspotentialhasnotbeenfullyexplored.
Oneimportantobservationisthatduringtheinferenceprocess,1-bitconvolutionlayergeneratesintegeroutputs,duetothebit-countoperations.
TheintegeroutputswillbecomerealvaluesifthereisaBatchNorm[10]layer.
Butthesereal-valuedactivationsarethenbinarizedto1or+1throughtheconsecutivesignfunction,asshowninFig.
1(a).
Obvi-ously,comparedtobinaryactivations,theseintegersorrealactivationscontainmoreinformation,whichislostintheconventional1-bitCNNs[7].
Inspiredbythisobservation,weproposetokeeptheserealactivationsviaaddingasimpleyeteectiveshortcut,dubbedBi-Realnet.
AsshowninFig.
1(b),theshortcutconnectstherealactivationstoanadditionoperatorwiththereal-valuedac-tivationsofthenextblock.
Bydoingso,therepresentationalcapabilityoftheproposedmodelismuchhigherthanthatoftheoriginal1-bitCNNs,withonlyanegligiblecomputationalcostincurredbytheextraelement-wiseadditionandwithoutanyadditionalmemorycost.
Moreover,wefurtherproposeanoveltrainingalgorithmfor1-bitCNNsin-cludingthreetechnicalnovelties:Bi-RealNet:EnhancingthePerformanceof1-bitCNNs3Fig.
1.
Networkwithintermediatefeaturevisualization,yellowlinesdenotevalueprop-agatedinsidethepathbeingrealwhilebluelinesdenotebinaryvalues.
(a)1-bitCNNwithoutshortcut(b)proposedBi-Realnetwithshortcutpropagatingthereal-valuedfeatures.
–Approximationtothederivativeofthesignfunctionwithre-specttoactivations.
Asthesignfunctionbinarizingtheactivationisnon-dierentiable,weproposetoapproximateitsderivativebyapiecewiselinearfunctioninthebackwardpass,derivedfromthepiecewisepolyno-mialfunctionthatisasecond-orderapproximationofthesignfunction.
Incontrast,theapproximatedderivativeusingastepfunction(i.
e.
,1|x|Net[7],thereal-valuedweightisrstupdatedusinggradientdescent,andthenewbinaryweightisthenobtainedthroughtakingthesignoftheupdatedrealweight.
However,wendthatthegradientwithrespecttotherealweightisonlyrelatedtothesignofthecurrentrealweight,whileindependentofitsmagnitude.
Toderiveamoreeectivegradient,weproposetouseamagnitude-awaresignfunctionduringtraining,thenthegradientwithrespecttotherealweightdependsonboththesignandthemagnitudeofthecurrentrealweight.
Afterconvergence,thebinaryweight(i.
e.
,-1or+1)isobtainedthroughthesignfunctionofthenalrealweightforinference.
–Initialization.
Asahighlynon-convexoptimizationproblem,thetrainingof1-bitCNNsislikelytobesensitivetoinitialization.
In[17],the1-bitCNNmodelisinitializedusingthereal-valuedCNNmodelwiththeReLUfunctionpre-trainedonImageNet.
WeproposetoreplaceReLUbytheclipfunctioninpre-training,astheactivationoftheclipfunctionisclosertothebinaryactivationthanthatofReLU.
4ZechunLiuetal.
ExperimentsonImageNetshowthattheabovethreeideasareusefultotrain1-bitCNNs,includingbothBi-Realnetandothernetworkstructures.
Specically,theirrespectivecontributionstotheimprovementsoftop-1accuracyareupto12%,23%and13%fora18-layerBi-Realnet.
Withthededicatedly-designedshortcutandtheproposedoptimizationtechniques,ourBi-Realnet,withonlybinaryweightsandactivationsinsideeach1-bitconvolutionlayer,achieves56.
4%and62.
2%top-1accuracywith18-layerand34-layerstructures,respectively,withupto16.
0*memorysavingand19.
0*computationalcostreductioncomparedtothefull-precisionCNN.
Comparingtothestate-of-the-artmodel(e.
g.
,XNOR-Net),Bi-Realnetachieves10%highertop-1accuracyonthe18-layernetwork.
2RelatedWorkReducingthenumberofparameters.
Severalmethodshavebeenproposedtocompressneuralnetworksbyreducingthenumberofparametersandneuralconnections.
Forinstance,Heetal.
[5]proposedabottleneckstructurewhichconsistsofthreeconvolutionlayersofltersize1*1,3*3and1*1withashort-cutconnectionasapreliminarybuildingblocktoreducethenumberofparam-etersandtospeeduptraining.
InSqueezeNet[9],some3*3convolutionsarereplacedwith1*1convolutions,resultingina50*reductioninthenumberofparameters.
FitNets[21]imitatesthesoftoutputofalargeteachernetworkus-ingathinanddeepstudentnetwork,andinturnyields10.
4*fewerparametersandsimilaraccuracytoalargeteachernetworkontheCIFAR-10dataset.
InSparseCNN[15],asparsematrixmultiplicationoperationisemployedtozerooutmorethan90%ofparameterstoacceleratethelearningprocess.
MotivatedbytheSparseCNN,Hanetal.
proposedDeepCompression[4]whichemploysconnectionpruning,quantizationwithretrainingandHumancodingtoreducethenumberofneuralconnections,thus,inturn,reducesthememoryusage.
Parameterquantization.
Thepreviousstudy[13]demonstratedthatreal-valueddeepneuralnetworkssuchasAlexNet[12],GoogLeNet[25]andVGG-16[23]onlyencountermarginalaccuracydegradationwhenquantizing32-bitpa-rametersto8-bit.
InIncrementalNetworkQuantization,Zhouetal.
[31]quan-tizetheparameterincrementallyandshowthatitisevenpossibletofurtherreducetheweightprecisionto2-5bitswithslightlyhigheraccuracythanafull-precisionnetworkontheImageNetdataset.
InBinaryConnect[1],Courbariauxetal.
employ1-bitprecisionweights(1and-1)whilemaintainingsucientlyhighaccuracyontheMNIST,CIFAR10andSVHNdatasets.
Quantizingweightsproperlycanachieveconsiderablememorysavingswithlittleaccuracydegradation.
However,accelerationviaweightquantizationislimitedduetothereal-valuedactivations(i.
e.
,theinputtoconvolutionlayers).
Severalrecentstudieshavebeenconductedtoexplorenewnetworkstruc-turesand/ortrainingtechniquesforquantizingbothweightsandactivationswhileminimizingaccuracydegradation.
SuccessfulattemptsincludeDoReFa-Net[33]andQNN[8],whichexploreneuralnetworkstrainedwith1-bitweightsBi-RealNet:EnhancingthePerformanceof1-bitCNNs5Fig.
2.
Themechanismofxnoroperationandbit-countinginsidethe1-bitCNNspre-sentedin[19].
and2-bitactivations,andtheaccuracydropsby6.
1%and4.
9%respectivelyontheImageNetdatasetcomparedtothereal-valuedAlexNet.
Additionally,Bina-ryNet[7]usesonly1-bitweightsand1-bitactivationsinaneuralnetworkandachievescomparableaccuracyasfull-precisionneuralnetworksontheMNISTandCIFAR-10datasets.
InXNOR-Net[19],Rastegarietal.
furtherimproveBinaryNetbymultiplyingtheabsolutemeanoftheweightlterandactivationwiththe1-bitweightandactivationtoimprovetheaccuracy.
ABC-Net[14]proposestoenhancetheaccuracybyusingmoreweightbasesandactivationbases.
Theresultsofthesestudiesareencouraging,butadmittedly,duetothelossofprecisioninweightsandactivations,thenumberofltersinthenetwork(thusthealgorithmcomplexity)growsinordertomaintainhighaccuracy,whichosetsthememorysavingandspeedupofbinarizingthenetwork.
Inthisstudy,weaimtodesign1-bitCNNsaidedwithareal-valuedshortcuttocompensatefortheaccuracylossofbinarization.
Optimizationstrategiesforovercomingthegradientdismatchproblemanddiscreteoptimizationdicultiesin1-bitCNNs,alongwithacustomizedinitializationmethod,areproposedtofullyexplorethepotentialof1-bitCNNswithitslimitedresolution.
3Methodology3.
1Standard1-bitCNNsandItsRepresentationalCapability1-bitconvolutionalneuralnetworks(CNNs)refertotheCNNmodelswithbi-naryweightparametersandbinaryactivationsinintermediateconvolutionlay-ers.
Specically,thebinaryactivationandweightareobtainedthroughasignfunction,ab=Sign(ar)=1ifarNet.
Webelievethatthepoorperformanceof1-bitCNNsiscausedbyitslowrepresentationalcapacity.
WedenoteR(x)astherepresentationalcapabilityofx,i.
e.
,thenumberofallpossiblecongurationsofx,wherexcouldbeascalar,vector,matrixortensor.
Forexample,therepresentationalcapabilityof32channelsofabinary14*14featuremapAisR(A)=214*14*32=26272.
Givena3*3*32binaryweightkernelW,eachentryofAW(i.
e.
,thebitwiseconvolutionoutput)canchoosetheevenvaluesfrom(-288to288),asshowninFig3.
Thus,R(AW)=2896272.
NotethatsincetheBatchNormlayerisauniquemapping,itwillnotincreasethenumberofdierentchoicesbutscalethe(-288,288)toaparticularvalue.
Ifaddingthe1-bitconvolutionlayerbehindtheoutput,eachentryinthefeaturemapisbinarized,andtherepresentationalcapabilityshrinksto26272again.
3.
2Bi-RealNetModelandItsRepresentationalCapabilityWeproposetopreservetherealactivationsbeforethesignfunctiontoincreasetherepresentationalcapabilityofthe1-bitCNN,throughasimpleshortcut.
Specically,asshowninFig.
3(b),oneblockindicatesthestructurethat"Sign→1-bitconvolution→batchnormalization→additionoperator".
TheshortcutBi-RealNet:EnhancingthePerformanceof1-bitCNNs7Fig.
4.
Agraphicalillustrationofthetrainingprocessofthe1-bitCNNs,withAbeingtheactivation,Wbeingtheweight,andthesuperscriptldenotingthelthblockconsist-ingwithSign,1-bitConvolution,andBatchNorm.
Thesubscriptrdenotesrealvalue,bdenotesbinaryvalue,andmdenotestheintermediateoutputbeforetheBatchNormlayer.
connectstheinputactivationstothesignfunctioninthecurrentblocktotheoutputactivationsafterthebatchnormalizationinthesameblock,andthesetwoactivationsareaddedthroughanadditionoperator,andthenthecombinedactivationsareinputtedtothesignfunctioninthenextblock.
Therepresenta-tionalcapabilityofeachentryintheaddedactivationsis2892.
Consequently,therepresentationalcapabilityofeachblockinthe1-bitCNNwiththeaboveshortcutbecomes(2892)6272.
Asbothrealandbinaryactivationsarekept,wecalltheproposedmodelasBi-Realnet.
Therepresentationalcapabilityofeachblockinthe1-bitCNNissignicantlyenhancedduetothesimpleidentityshortcut.
Theonlyadditionalcostofcompu-tationistheadditionoperationoftworealactivations,astheserealactivationsalreadyexistinthestandard1-bitCNN(i.
e.
,withoutshortcuts).
Moreover,astheactivationsarecomputedonthey,noadditionalmemoryisneeded.
3.
3TrainingBi-RealNetAsbothactivationsandweightparametersarebinary,thecontinuousopti-mizationmethod,i.
e.
,thestochasticgradientdescent(SGD),cannotbedirectlyadoptedtotrainthe1-bitCNN.
Therearetwomajorchallenges.
Oneishowtocomputethegradientofthesignfunctiononactivations,whichisnon-dierentiable.
Theotheristhatthegradientofthelosswithrespecttothebinaryweightistoosmalltochangetheweight'ssign.
Theauthorsof[7]pro-posedtoadjustthestandardSGDalgorithmtoapproximatelytrainthe1-bitCNN.
Specically,thegradientofthesignfunctiononactivationsisapproxi-matedbythegradientofthepiecewiselinearfunction,asshowninFig.
5(b).
Totacklethesecondchallenge,themethodproposedin[7]updatesthereal-valuedweightsbythegradientcomputedwithregardtothebinaryweightandobtainsthebinaryweightbytakingthesignoftherealweights.
Astheidentityshortcutwillnotadddicultyfortraining,thetrainingalgorithmproposedin[7]canalsobeadoptedtotraintheBi-Realnetmodel.
However,weproposeanoveltrainingalgorithmtotackletheabovetwomajorchallenges,whichismoresuitablefor8ZechunLiuetal.
Fig.
5.
(a)Signfunctionanditsderivative,(b)Clipfunctionanditsderivativeforapproximatingthederivativeofthesignfunction,proposedin[7],(c)Proposeddier-entiablepiecewisepolynomialfunctionanditstriangle-shapedderivativeforapproxi-matingthederivativeofthesignfunctioningradientscomputation.
theBi-Realnetmodelaswellasother1-bitCNNs.
Besides,wealsoproposeanovelinitializationmethod.
WepresentagraphicalillustrationofthetrainingofBi-RealnetinFig.
4.
Theidentityshortcutisomittedinthegraphforclarity,asitwillnotchangethemainpartofthetrainingalgorithm.
Approximationtothederivativeofthesignfunctionwithrespecttoactivations.
AsshowninFig.
5(a),thederivativeofthesignfunctionisanimpulsefunction,whichcannotbeutilizedintraining.
LAl,tr=LAl,tbAl,tbAl,tr=LAl,tbSign(Al,tr)Al,tr≈LAl,trF(Al,tr)Al,tr,(2)whereF(Al,tr)isadierentiableapproximationofthenon-dierentiableSign(Al,tr).
In[7],F(Al,tr)issetastheclipfunction,leadingtothederivativeasastep-function(see5(b)).
Inthiswork,weutilizeapiecewisepolynomialfunction(see5(c))astheapproximationfunction,asEq.
(3)left.
F(ar)=1ifarNet:EnhancingthePerformanceof1-bitCNNs9Thestandardgradientdescentalgorithmcannotbedirectlyappliedasthegradientisnotlargeenoughtochangethebinaryweights.
Totacklethisprob-lem,themethodof[7]introducedarealweightWlrandasignfunctionduringtraining.
Hencethebinaryweightparametercanbeseenastheoutputtothesignfunction,i.
e.
,Wlb=Sign(Wlr),asshownintheuppersub-gureinFig.
4.
Consequently,Wlrisupdatedusinggradientdescentinthebackwardpass,asfollowsWl,t+1r=Wl,trηLWl,tr=Wl,trηLWl,tbWl,tbWl,tr.
(4)NotethatWl,tbWl,trindicatestheelement-wisederivative.
In[7],Wl,tb(i,j)Wl,tr(i,j)issetto1ifWl,tr(i,j)∈[1,1],otherwise0.
ThederivativeLWl,tbisderivedfromthechainrule,asfollowsLWl,tb=LAl+1,trAl+1,trAl,tmAl,tmWl,tb=LAl+1,trθl,tAlb,(5)whereθl,t=Al+1,trAl,tmdenotesthederivativeoftheBatchNormlayer(seeFig.
4)andhasanegativecorrelationtoWl,tb.
AsWl,tb∈{1,+1},thegradientLWl,trisonlyrelatedtothesignofWl,tr,whileisindependentofitsmagnitude.
Basedonthisobservation,weproposetoreplacetheabovesignfunctionbyamagnitude-awarefunction,asfollows:Wl,tb=Wl,tr1,1|Wl,tr|Sign(Wl,tr),(6)where|Wl,tr|denotesthenumberofentriesinWl,tr.
Consequently,theupdateofWlrbecomesWl,t+1r=Wl,trηLWl,tbWl,tbWl,tr=Wl,trηLAl+1,trθl,tAlbWl,tbWl,tr,(7)whereWl,tbWl,tr≈Wl,tr1,1|Wl,tr|·Sign(Wl,tr)Wl,tr≈Wl,tr1,1|Wl,tr|·1|Wl,tr|Net.
However,theactivationofReLUisnon-negative,whilethatofSignis1or+1.
Due10ZechunLiuetal.
tothisdierence,therealCNNswithReLUmaynotprovideasuitableinitialpointfortrainingthe1-bitCNNs.
Instead,weproposetoreplaceReLUwithclip(1,x,1)topre-trainthereal-valuedCNNmodel,astheactivationoftheclipfunctionisclosertothesignfunctionthanReLU.
Theecacyofthisnewinitializationwillbeevaluatedinexperiments.
4ExperimentsInthissection,werstlyintroducethedatasetforexperimentsandimplementa-tiondetailsinSec4.
1.
ThenweconductablationstudyinSec.
4.
2toinvestigatetheeectivenessoftheproposedtechniques.
ThispartisfollowedbycomparingourBi-Realnetwithotherstate-of-the-artbinarynetworksregardingaccuracyinSec4.
3.
Sec.
4.
4reportsmemoryusageandcomputationcostincomparisonwithothernetworks.
4.
1DatasetandImplementationDetailsTheexperimentsarecarriedoutontheILSVRC12ImageNetclassicationdataset[22].
ImageNetisalarge-scaledatasetwith1000classesand1.
2milliontrainingimagesand50kvalidationimages.
ComparedtootherdatasetslikeCIFAR-10[11]orMNIST[18],ImageNetismorechallengingduetoitslargescaleandgreatdiversity.
ThestudyonthisdatasetwillvalidatethesuperiorityoftheproposedBi-Realnetworkstructureandtheeectivenessofthreetrainingmethodsfor1-bitCNNs.
Inourcomparison,wereportboththetop-1andtop-5accuracies.
ForeachimageintheImageNetdataset,thesmallerdimensionoftheimageisrescaledto256whilekeepingtheaspectratiointact.
Fortraining,arandomcropofsize224*224isselected.
Notethat,incontrasttoXNOR-Netandthefull-precisionResNet,wedonotusetheoperationofrandomresize,whichmightimprovetheperformancefurther.
Forinference,weemploythe224*224centercropfromimages.
Training:WetraintwoinstancesoftheBi-Realnet,includingan18-layerBi-Realnetanda34-layerBi-Realnet.
Thetrainingofthemconsistsoftwosteps:trainingthe1-bitconvolutionlayerandretrainingtheBatchNorm.
Intherststep,theweightsinthe1-bitconvolutionlayerarebinarizedtothesignofreal-valuedweightsmultiplyingtheabsolutemeanofeachkernel.
WeusetheSGDsolverwiththemomentumof0.
9andsettheweight-decayto0,whichmeanswenolongerencouragetheweightstobecloseto0.
Forthe18-layerBi-Realnet,werunthetrainingalgorithmfor20epochswithabatchsizeof128.
Thelearningratestartsfrom0.
01andisdecayedtwicebymultiplying0.
1atthe10thandthe15thepoch.
Forthe34-layerBi-Realnet,thetrainingprocessincludes40epochsandthebatchsizeissetto1024.
Thelearningratestartsfrom0.
08andismultipliedby0.
1atthe20thandthe30thepoch,respectively.
Inthesecondstep,weconstrainttheweightsto-1and1,andsetthelearningrateinallconvolutionlayersto0andretraintheBatchNormlayerfor1epochtoabsorbthescalingfactor.
Bi-RealNet:EnhancingthePerformanceof1-bitCNNs11Fig.
6.
Threedierentnetworksdierintheshortcutdesignofconnectingtheblocksshownin(a)conjointlayersofSign,1-bitConvolution,andtheBatchNorm.
(b)Bi-Realnetwithshortcutbypassingeveryblock(c)Res-Netwithshortcutbypassingtwoblocks,whichcorrespondstotheReLU-onlypre-activationproposedin[6]and(d)Plain-Netwithouttheshortcut.
Thesethreestructuresshownin(b),(c)and(d)havethesamenumberofweights.
Inference:weusethetrainedmodelwithbinaryweightsandbinaryactivationsinthe1-bitconvolutionlayersforinference.
4.
2AblationStudyThreebuildingblocks.
TheshortcutinourBi-Realnettransfersreal-valuedrepresentationwithoutadditionalmemorycost,whichplaysanimportantroleinimprovingitscapability.
Toverifyitsimportance,weimplementedaPlain-NetstructurewithoutshortcutasshowninFig.
6(d)forcomparison.
Atthesametime,asournetworkstructureemploysthesamenumberofweightltersandlayersasthestandardResNet,wealsomakeacomparisonwiththestandardResNetshowninFig.
6(c).
Forafaircomparison,weadopttheReLU-onlypre-activationResNetstructurein[6],whichdiersfromBi-Realnetonlyinthestructureoftwolayersperblockinsteadofonelayerperblock.
ThelayerorderandshortcutdesigninFig.
6(c)arealsoapplicablefor1-bitCNN.
ThecomparisoncanjustifythebenetofimplementingourBi-Realnetbyspecicallyreplacingthe2-conv-layer-per-blockRes-Netstructurewithtwo1-conv-layer-per-blockBi-Realstructure.
AsdiscussedinSec.
3,weproposedtoovercometheoptimizationchallengesinducedbydiscreteweightsandactivationsby1)approximationtothederiva-tiveofthesignfunctionwithrespecttoactivations,2)magnitude-awaregradientwithrespecttoweightsand3)clipinitialization.
Tostudyhowtheseproposalsbenetthe1-bitCNNsindividuallyandcollectively,wetrainthe18-layerstruc-tureandthe34-layerstructurewithacombinationofthesetechniquesontheImageNetdataset.
Thuswederive2*3*2*2*2=48pairsofvaluesoftop-1andtop-5accuracy,whicharepresentedinTable1.
BasedonTable1,wecanevaluateeachtechnique'sindividualcontributionandcollectivecontributionofeachuniquecombinationofthesetechniquesto-wardsthenalaccuracy.
1)Comparingthe4th7thcolumnswiththe8th9thcolumns,boththeproposedBi-RealnetandthebinarizedstandardResNetoutperformtheirplain12ZechunLiuetal.
Table1.
Top-1andtop-5accuracies(inpercentage)ofdierentcombinationsofthethreeproposedtechniquesonthreedierentnetworkstructures,Bi-Realnet,ResNetandPlainNet,showninFig.
6.
Initiali-WeightActivationBi-Real-18Res-18Plain-18Bi-Real-34Res-34Plain-34zationupdatebackwardtop-1top-5top-1top-5top-1top-5top-1top-5top-1top-5top-1top-5ReLUOriginalOriginal32.
956.
727.
850.
53.
39.
553.
176.
927.
549.
91.
44.
8Proposed36.
860.
832.
256.
04.
713.
758.
081.
033.
957.
91.
65.
3ProposedOriginal40.
565.
133.
958.
14.
312.
259.
982.
033.
657.
91.
86.
1Proposed47.
571.
941.
666.
48.
521.
561.
483.
347.
572.
02.
16.
8Real-valuedNet68.
588.
367.
887.
867.
587.
570.
489.
369.
188.
366.
886.
8ClipOriginalOriginal37.
462.
432.
856.
73.
29.
455.
979.
135.
059.
22.
26.
9Proposed38.
162.
734.
358.
44.
914.
358.
181.
038.
262.
62.
37.
5ProposedOriginal53.
677.
542.
467.
36.
717.
160.
882.
943.
968.
72.
57.
9Proposed56.
479.
545.
770.
312.
127.
762.
283.
949.
073.
62.
68.
3Real-valuedNet68.
088.
167.
587.
664.
285.
369.
789.
167.
987.
857.
179.
9Full-precisionoriginalResNet[5]69.
389.
273.
391.
3counterpartswithasignicantmargin,whichvalidatestheeectivenessofshort-cutandthedisadvantageofdirectlyconcatenatingthe1-bitconvolutionlayers.
AsPlain-18hasathinanddeepstructure,whichhasthesameweightltersbutnoshortcut,binarizingitresultsinverylimitednetworkrepresentationalcapac-ityinthelastconvolutionlayer,andthuscanhardlyachievegoodaccuracy.
2)Comparingthe4th5thand6th7thcolumns,the18-layerBi-RealnetstructureimprovestheaccuracyofthebinarizedstandardResNet-18byabout18%.
ThisvalidatestheconjecturethattheBi-Realnetstructurewithmoreshortcutsfurtherenhancesthenetworkcapacitycomparedtothestan-dardResNetstructure.
Replacingthe2-conv-layer-per-blockstructureemployedinRes-Netwithtwo1-conv-layer-per-blockstructure,adoptedbyBi-Realnet,couldevenbenetareal-valuednetwork.
3)Allproposedtechniquesforinitialization,weightupdateandactivationbackwardimprovetheaccuracyatvariousdegrees.
Forthe18-layerBi-Realnetstructure,theimprovementfromtheweight(about23%,bycomparingthe2ndand4throws)isgreaterthantheimprovementfromtheactivation(about12%,bycomparingthe2ndand4throws)andtheimprovementfromreplacingReLUwithClipforinitialization(about13%,bycomparingthe2ndand7throws).
Thesethreeproposedtrainingmechanismsareindependentandcanfunctioncollaborativelytowardsenhancingthenalaccuracy.
4)Theproposedtrainingmethodscanimprovethenalaccuracyforallthreenetworksincomparisonwiththeoriginaltrainingmethod,whichimpliestheseproposedthreetrainingmethodsareuniversallysuitableforvariousnetworks.
5)ThetwoimplementedBi-Realnets(i.
e.
the18-layerand34-layerstruc-tures)togetherwiththeproposedtrainingmethods,achieveapproximately83%and89%oftheaccuracyleveloftheircorrespondingfull-precisionnetworks,butwithahugeamountofspeedupandcomputationcostsaving.
Bi-RealNet:EnhancingthePerformanceof1-bitCNNs13Table2.
Thistablecomparesboththetop-1andtop-5accuraciesofourBi-realnetwithotherstate-of-the-artbinarizationmethods:BinaryNet[7],XNOR-Net[19],ABC-Net[14]onboththeRes-18andRes-34[5].
TheBi-Realnetoutperformsothermethodsbyaconsiderablemargin.
Bi-RealnetBinaryNetABC-NetXNOR-NetFull-precision18-layerTop-156.
4%42.
2%42.
7%51.
2%69.
3%Top-579.
5%67.
1%67.
6%73.
2%89.
2%34-layerTop-162.
2%–52.
4%–73.
3%Top-583.
9%–76.
5%–91.
3%Inshort,theshortcutenhancesthenetworkrepresentationalcapability,andtheproposedtrainingmethodshelpthenetworktoapproachtheaccuracyupperbound.
4.
3AccuracyComparisonWithState-of-The-ArtWhiletheablationstudydemonstratestheeectivenessofour1-layer-per-blockstructureandtheproposedtechniquesforoptimaltraining,itisalsonecessarytocomparewithotherstate-of-the-artmethodstoevaluateBi-Realnet'soverallperformance.
Tothisend,wecarryoutacomparativestudywiththreemethods:BinaryNet[7],XNOR-Net[19]andABC-Net[14].
ThesethreenetworksarerepresentativemethodsofbinarizingbothweightsandactivationsforCNNsandachievethestate-of-the-artresults.
Notethat,forafaircomparison,ourBi-RealnetcontainsthesameamountofweightltersasthecorrespondingResNetthatthesemethodsattempttobinarize,dieringonlyintheshortcutdesign.
Table2showstheresults.
Theresultsofthethreenetworksarequoteddi-rectlyfromthecorrespondingreferences,exceptthattheresultofBinaryNetisquotedfromABC-Net[14].
ThecomparisonclearlyindicatesthattheproposedBi-Realnetoutperformsthethreenetworksbyaconsiderablemarginintermsofboththetop-1andtop-5accuracies.
Specically,the18-layerBi-Realnetout-performsits18-layercounterpartsBinaryNetandABC-Netwithrelative33%advantage,andachievesaroughly10%relativeimprovementovertheXNOR-Net.
Similarimprovementscanbeobservedfor34-layerBi-Realnet.
Inshort,ourBi-Realnetismorecompetitivethanthestate-of-the-artbinarynetworks.
4.
4EciencyandMemoryUsageAnalysisInthissection,weanalyzethesavingofmemoryusageandspeedupincomputa-tionofBi-RealnetbycomparingwiththeXNOR-Net[19]andthefull-precisionnetworkindividually.
Thememoryusageiscomputedasthesummationof32bittimesthenum-berofreal-valuedparametersand1bittimesthenumberofbinaryparametersinthenetwork.
Foreciencycomparison,weuseFLOPstomeasurethetotal14ZechunLiuetal.
Table3.
MemoryusageandFLOPscalculationinBi-Realnet.
MemoryusageMemorysavingFLOPsSpeedup18-layerBi-Realnet33.
6Mbit11.
14*1.
63*10811.
06*XNOR-Net33.
7Mbit11.
10*1.
67*10810.
86*Full-precisionRes-Net374.
1Mbit–1.
81*109–34-layerBi-Realnet43.
7Mbit15.
97*1.
93*10818.
99*XNOR-Net43.
9Mbit15.
88*1.
98*10818.
47*Full-precisionRes-Net697.
3Mbit–3.
66*109–real-valuedmultiplicationcomputationintheBi-Realnet,followingthecalcu-lationmethodin[5].
AsthebitwiseXNORoperationandbit-countingcanbeperformedinaparallelof64bythecurrentgenerationofCPUs,theFLOPsiscalculatedastheamountofreal-valuedoatingpointmultiplicationplus1/64oftheamountof1-bitmultiplication.
WefollowthesuggestioninXNOR-Net[19],tokeeptheweightsandactiva-tionsintherstconvolutionandthelastfully-connectedlayerstobereal-valued.
Wealsoadoptthesamereal-valued1x1convolutioninTypeBshort-cut[5]asimplementedinXNOR-Net.
Notethatthis1x1convolutionisforthetransitionbetweentwostagesofResNetandthusallinformationshouldbepreserved.
Asthenumberofweightsinthosethreekindsoflayersaccountsforonlyaverysmallproportionofthetotalnumberofweights,thelimitedmemorysavingforbinarizingthemdoesnotjustifytheperformancedegradationcausedbytheinformationloss.
Forboththe18-layerandthe34-layernetworks,theproposedBi-Realnetreducesthememoryusageby11.
1timesand16.
0timesindividually,andachievescomputationreductionofabout11.
1timesand19.
0times,incomparisonwiththefull-precisionnetwork.
Withoutusingreal-valuedweightsandactivationsforscalingbinaryonesduringinferencetime,ourBi-RealnetrequiresfewerFLOPsanduseslessmemorythanXNOR-Netandisalsomucheasiertoimplement.
5ConclusionInthiswork,wehaveproposedanovel1-bitCNNmodel,dubbedBi-Realnet.
Comparedwiththestandard1-bitCNNs,Bi-Realnetutilizesasimpleshort-cuttosignicantlyenhancetherepresentationalcapability.
Further,anadvancedtrainingalgorithmisspecicallydesignedfortraining1-bitCNNs(includingBi-Realnet),includingatighterapproximationofthederivativeofthesignfunctionwithrespecttheactivation,themagnitude-awaregradientwithrespecttotheweight,aswellasanovelinitialization.
ExtensiveexperimentalresultsdemonstratethattheproposedBi-Realnetandthenoveltrainingalgorithmshowsuperiorityoverthestate-of-the-artmethods.
Infuture,wewillexploreotheradvancedintegerprogrammingalgorithms(e.
g.
,Lp-BoxADMM[26])totrainBi-RealNet.
Bi-RealNet:EnhancingthePerformanceof1-bitCNNs15References1.
Courbariaux,M.
,Bengio,Y.
,David,J.
P.
:Binaryconnect:Trainingdeepneuralnet-workswithbinaryweightsduringpropagations.
In:Advancesinneuralinformationprocessingsystems.
pp.
3123–3131(2015)2.
Garg,R.
,BG,V.
K.
,Carneiro,G.
,Reid,I.
:Unsupervisedcnnforsingleviewdepthestimation:Geometrytotherescue.
In:EuropeanConferenceonComputerVision.
pp.
740–756.
Springer(2016)3.
Girshick,R.
,Donahue,J.
,Darrell,T.
,Malik,J.
:Richfeaturehierarchiesforac-curateobjectdetectionandsemanticsegmentation.
In:ProceedingsoftheIEEEconferenceoncomputervisionandpatternrecognition.
pp.
580–587(2014)4.
Han,S.
,Mao,H.
,Dally,W.
J.
:Deepcompression:Compressingdeepneuralnet-workswithpruning,trainedquantizationandhumancoding.
arXivpreprintarXiv:1510.
00149(2015)5.
He,K.
,Zhang,X.
,Ren,S.
,Sun,J.
:Deepresiduallearningforimagerecognition.
In:ProceedingsoftheIEEEconferenceoncomputervisionandpatternrecognition.
pp.
770–778(2016)6.
He,K.
,Zhang,X.
,Ren,S.
,Sun,J.
:Identitymappingsindeepresidualnetworks.
In:Europeanconferenceoncomputervision.
pp.
630–645.
Springer(2016)7.
Hubara,I.
,Courbariaux,M.
,Soudry,D.
,El-Yaniv,R.
,Bengio,Y.
:Binarizedneuralnetworks.
In:Lee,D.
D.
,Sugiyama,M.
,Luxburg,U.
V.
,Guyon,I.
,Gar-nett,R.
(eds.
)AdvancesinNeuralInformationProcessingSystems29,pp.
4107–4115.
CurranAssociates,Inc.
(2016),http://papers.
nips.
cc/paper/6573-binarized-neural-networks.
pdf8.
Hubara,I.
,Courbariaux,M.
,Soudry,D.
,El-Yaniv,R.
,Bengio,Y.
:Quantizedneu-ralnetworks:Trainingneuralnetworkswithlowprecisionweightsandactivations(2016)9.
Iandola,F.
N.
,Han,S.
,Moskewicz,M.
W.
,Ashraf,K.
,Dally,W.
J.
,Keutzer,K.
:Squeezenet:Alexnet-levelaccuracywith50xfewerparametersand0.
5mbmodelsize.
arXivpreprintarXiv:1602.
07360(2016)10.
Ioe,S.
,Szegedy,C.
:Batchnormalization:Acceleratingdeepnetworktrainingbyreducinginternalcovariateshift.
arXivpreprintarXiv:1502.
03167(2015)11.
Krizhevsky,A.
,Hinton,G.
:Learningmultiplelayersoffeaturesfromtinyimages.
Tech.
rep.
,Citeseer(2009)12.
Krizhevsky,A.
,Sutskever,I.
,Hinton,G.
E.
:Imagenetclassicationwithdeepcon-volutionalneuralnetworks.
In:Advancesinneuralinformationprocessingsystems.
pp.
1097–1105(2012)13.
Lai,L.
,Suda,N.
,Chandra,V.
:Deepconvolutionalneuralnetworkinferencewithoating-pointweightsandxed-pointactivations.
arXivpreprintarXiv:1703.
03073(2017)14.
Lin,X.
,Zhao,C.
,Pan,W.
:Towardsaccuratebinaryconvolutionalneuralnetwork.
In:AdvancesinNeuralInformationProcessingSystems.
pp.
345–353(2017)15.
Liu,B.
,Wang,M.
,Foroosh,H.
,Tappen,M.
,Pensky,M.
:Sparseconvolutionalneuralnetworks.
In:ProceedingsoftheIEEEConferenceonComputerVisionandPatternRecognition.
pp.
806–814(2015)16.
Liu,F.
,Shen,C.
,Lin,G.
,Reid,I.
D.
:Learningdepthfromsinglemonocularimagesusingdeepconvolutionalneuralelds.
IEEETrans.
PatternAnal.
Mach.
Intell.
38(10),2024–2039(2016)17.
Luo,W.
,Sun,P.
,Zhong,F.
,Liu,W.
,Zhang,T.
,Wang,Y.
:End-to-endactiveobjecttrackingviareinforcementlearning.
ICML(2018)16ZechunLiuetal.
18.
Netzer,Y.
,Wang,T.
,Coates,A.
,Bissacco,A.
,Wu,B.
,Ng,A.
Y.
:Readingdigitsinnaturalimageswithunsupervisedfeaturelearning.
In:NIPSworkshopondeeplearningandunsupervisedfeaturelearning.
vol.
2011,p.
5(2011)19.
Rastegari,M.
,Ordonez,V.
,Redmon,J.
,Farhadi,A.
:Xnor-net:Imagenetclassi-cationusingbinaryconvolutionalneuralnetworks.
In:EuropeanConferenceonComputerVision.
pp.
525–542.
Springer(2016)20.
Ren,S.
,He,K.
,Girshick,R.
,Sun,J.
:Fasterr-cnn:Towardsreal-timeobjectdetec-tionwithregionproposalnetworks.
In:Advancesinneuralinformationprocessingsystems.
pp.
91–99(2015)21.
Romero,A.
,Ballas,N.
,Kahou,S.
E.
,Chassang,A.
,Gatta,C.
,Bengio,Y.
:Fitnets:Hintsforthindeepnets.
arXivpreprintarXiv:1412.
6550(2014)22.
Russakovsky,O.
,Deng,J.
,Su,H.
,Krause,J.
,Satheesh,S.
,Ma,S.
,Huang,Z.
,Karpathy,A.
,Khosla,A.
,Bernstein,M.
,etal.
:Imagenetlargescalevisualrecog-nitionchallenge.
InternationalJournalofComputerVision115(3),211–252(2015)23.
Simonyan,K.
,Zisserman,A.
:Verydeepconvolutionalnetworksforlarge-scaleimagerecognition.
arXivpreprintarXiv:1409.
1556(2014)24.
Sun,Y.
,Wang,X.
,Tang,X.
:Deepconvolutionalnetworkcascadeforfacialpointdetection.
In:ProceedingsoftheIEEEconferenceoncomputervisionandpatternrecognition.
pp.
3476–3483(2013)25.
Szegedy,C.
,Liu,W.
,Jia,Y.
,Sermanet,P.
,Reed,S.
,Anguelov,D.
,Erhan,D.
,Vanhoucke,V.
,Rabinovich,A.
:Goingdeeperwithconvolutions.
In:ProceedingsoftheIEEEconferenceoncomputervisionandpatternrecognition.
pp.
1–9(2015)26.
Wu,B.
,Ghanem,B.
:lp-boxadmm:Aversatileframeworkforintegerprogramming.
IEEETransactionsonPatternAnalysisandMachineIntelligence(2018)27.
Wu,B.
,Hu,B.
G.
,Ji,Q.
:Acoupledhiddenmarkovrandomeldmodelforsimul-taneousfaceclusteringandtrackinginvideos.
PatternRecognition64,361–373(2017)28.
Wu,B.
,Lyu,S.
,Hu,B.
G.
,Ji,Q.
:Simultaneousclusteringandtrackletlinkingformulti-facetrackinginvideos.
In:ProceedingsoftheIEEEInternationalConferenceonComputerVision.
pp.
2856–2863(2013)29.
Zhang,H.
,Kyaw,Z.
,Chang,S.
F.
,Chua,T.
S.
:Visualtranslationembeddingnet-workforvisualrelationdetection.
In:CVPR.
vol.
1,p.
5(2017)30.
Zhang,H.
,Kyaw,Z.
,Yu,J.
,Chang,S.
F.
:Ppr-fcn:Weaklysupervisedvisualrela-tiondetectionviaparallelpairwiser-fcn.
arXivpreprintarXiv:1708.
01956(2017)31.
Zhou,A.
,Yao,A.
,Guo,Y.
,Xu,L.
,Chen,Y.
:Incrementalnetworkquantization:Towardslosslesscnnswithlow-precisionweights.
arXivpreprintarXiv:1702.
03044(2017)32.
Zhou,E.
,Fan,H.
,Cao,Z.
,Jiang,Y.
,Yin,Q.
:Extensivefaciallandmarklocaliza-tionwithcoarse-to-neconvolutionalnetworkcascade.
In:ProceedingsoftheIEEEInternationalConferenceonComputerVisionWorkshops.
pp.
386–391(2013)33.
Zhou,S.
,Wu,Y.
,Ni,Z.
,Zhou,X.
,Wen,H.
,Zou,Y.
:Dorefa-net:Traininglowbitwidthconvolutionalneuralnetworkswithlowbitwidthgradients.
arXivpreprintarXiv:1606.
06160(2016)34.
Zhu,X.
,Lei,Z.
,Liu,X.
,Shi,H.
,Li,S.
Z.
:Facealignmentacrosslargeposes:A3dsolution.
In:ProceedingsoftheIEEEconferenceoncomputervisionandpatternrecognition.
pp.
146–155(2016)
pia云低至20/月,七折美国服务器
Pia云是一家2018的开办的国人商家,原名叫哔哔云,目前整合到了魔方云平台上,商家主要销售VPS服务,采用KVM虚拟架构 ,机房有美国洛杉矶、中国香港和深圳地区,洛杉矶为crea机房,三网回程CN2 GIA,带20G防御,常看我测评的朋友应该知道,一般带防御去程都是骨干线路,香港的线路也是CN2直连大陆,目前商家重新开业,价格非常美丽,性价比较非常高,有需要的朋友可以关注一下。活动方案...
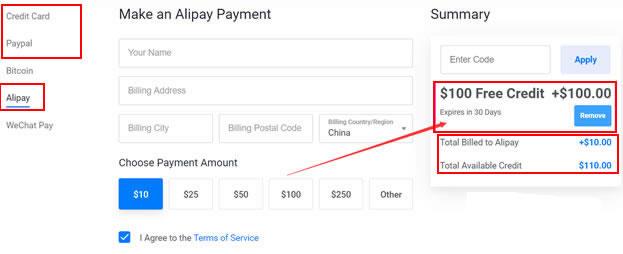
Vultr新注册赠送100美元活动截止月底 需要可免费享30天福利
昨天晚上有收到VULTR服务商的邮件,如果我们有清楚的朋友应该知道VULTR对于新注册用户已经这两年的促销活动是有赠送100美元最高余额,不过这个余额有效期是30天,如果我们到期未使用完的话也会失效的。但是对于我们一般用户来说,这个活动还是不错的,只需要注册新账户充值10美金激活账户就可以。而且我们自己充值的余额还是可以继续使用且无有效期的。如果我们有需要申请的话可以参考"2021年最新可用Vul...
A400互联(49元/月)洛杉矶CN2 GIA+BGP、1Gbps带宽,全场独服永久5折优惠
a400互联是一家成立于2020年商家,主营美国机房的产品,包括BGP线路、CN2 GIA线路的云服务器、独立服务器、高防服务器,接入线路优质,延迟低,稳定性高,额外也还有香港云服务器业务。当前,全场服务器5折,香港VPS7折,洛杉矶VPS5折,限时促销!A400互联官网:https://a400.net/优惠活动全场独服永久5折优惠(续费同价):0722香港VPS七折优惠:0711洛杉矶VPS五...
cn163 net为你推荐
-
bbsxpbbsxp 2008 无法创建数据库支付宝查询余额怎样查支付宝余额自助建站自助建站哪个平台最好?伪静态什么是伪静态网站?伪静态网站有什么优势1433端口如何打开1433端口如何建立自己的网站如何建立自己的网站安装迅雷看看播放器迅雷看看播放器下了安装不了2012年正月十五农历2012年正月15早上9点多生的!命里缺什么!是什么命相linux虚拟机怎么样在Linux下安装虚拟机bluestack安卓模拟器bluestacks怎么用?