爬虫ie脚本错误
ie脚本错误 时间:2021-02-25 阅读:()
第2章使用C#开发网络爬虫52152采购人员需要找到提供产品的有竞争力的厂家和价格,金融交易人员需要找到有潜力的投资公司,出版行业人士需要找到迅速变热的话题.
这些都可以使用网络爬虫帮忙实现.
网络爬虫从互联网源源不断地抓取海量信息,搜索引擎结果中的信息都来源于此.
如果把互联网比喻成一个覆盖地球的蜘蛛网,那么抓取程序就是在网上爬来爬去的蜘蛛.
在抓取信息时,应当首先关注一些高质量的网页信息.
高质量的网页是指网民投票选择出来的网页,这里是访问量高的网站中的一些热门网页.
但是尺有所短,寸有所长,很多访问量一般的网站包括了更多问题的答案.
有点类似长尾效益.
Alexa(http://www.
alexa.
com)专门统计网站访问量并发布网站世界排名.
如果使用FireFox浏览器,可以通过alexa插件查看到当前访问的网站是否还有很多人在访问.
如果使用IE浏览器,可以通过alexa工具条查看到当前访问网站的访问量排名.
有些文档的时效性很强,如新闻或者财经信息.
大部分人想要知道的是当天股票市场的报道,只有很少人关心昨天的市场发生了什么.
本章专门介绍如何抓取即时信息.
网络爬虫需要实现的基本功能包括下载网页以及对URL地址的遍历.
为了高效、快速地遍历网站,还需要应用专门的数据结构来优化.
爬虫很消耗带宽资源,设计爬虫时需要仔细地考虑如何节省网络带宽.
2.
1网络爬虫抓取原理既然所有的网页都可能链接到其他的网站,那么从一个网站开始,跟踪所有网页上的所有链接,就可能遍历整个互联网.
为了更快地抓取想要的信息,网页抓取首先从一个已知的URL地址列表开始遍历,对垂直搜索来说,一般是积累的行业内的网站.
有人可能会奇怪,像Google或百度这样的搜索门户怎么设置这个初始的URL地址列表.
一般来说,网站拥有者把网站提交给分类目录,如dmoz(http://www.
dmoz.
org/),爬虫则可以从开放式分类目录dmoz抓取.
抓取下来的网页中包含了想要的信息,一般存放在数据库或索引库这样的专门的存储系统中,如图2-1所示.
图2-1网络爬虫基本结构在搜索引擎中,爬虫程序是从一系列种子链接把这些初始的网页中的URL提取出来,放入URL工作队列(Todo队列,也叫Frontier),然后遍历所有工作队列中的URL,下载网页并把其中新发现的URL再次放入工作队列.
为了判断一个URL是否已经遍历过,可以5353第2章使用C#开发网络爬虫把所有遍历过的URL放入历史表(Visited表).
爬虫抓取的基本过程如图2-2所示.
图2-2网页遍历流程图抓取的主要流程代码如下:classCrawler{staticListtodo=newList();//要访问的链接staticListvisited=newList();//已经访问过的链接staticstringstartPointAddress="http://www.
lietu.
com";publicvoidCrawler(){//爬虫的开始点RequestSite(startPointAddress);//访问种子站点while(todo.
Count>0){//如果有需要遍历的链接,则逐个遍历StringcurrentURL=todo[0];RequestSite(currentURL);//访问链接todo.
RemoveAt(currentURL);//从todo表中删除visited.
Add(currentURL);}}voidRequestSite(stringurl){WebRequestreq=(WebRequest.
Create(url));HttpWebResponseres=(HttpWebResponse)(req.
GetResponse());Streamst=res.
GetResponseStream();StreamReaderrdr=newStreamReader(st);strings=rdr.
ReadToEnd();todo.
AddRange(GetLinks(s));//增加链接到队列的尾部}ListGetLinks(stringhtmlPage){//通过正则表达式提取链接Regexregx=newRegex("http://([\\w+\\.
\\w+])+([a-zA-Z0-9\\~RegexOptions.
IgnoreCase);MatchCollectionmactches=regx.
Matches(htmlPage);Listresults=newList();foreach(Matchmatchinmatches){if(!
visited.
Contains(match.
Value))54154results.
Add(mattch.
Value);}returnresults;}}如果采用Queue来实现todo,则对每个增加到todo的元素都需要用对象封装.
ArrayDeque允许在末端增加或删除元素.
因为ArrayDeque底层采用数组实现,所以增加到ArrayDeque的元素不需要用对象封装.
ArrayDeque性能比Queue更好.
所以用ArrayDeque来实现todo队列.
Wintellect.
PowerCollections中包含一个ArrayDeque的实现.
有个URLSeen存储.
这里的visited就是URLSeen存储.
如果visited是全局唯一的,那就需要同步了.
服务器的名称通过DNS服务器转换成对应的IP地址,也就是说,通过DNS取得该URL域名的IP地址.
需要选择一个好的DNS服务器.
在Windows下DNS解析的问题可以用nslookup命令来分析,例如:C:\Users\Administrator>nslookupwww.
lietu.
com服务器:linedns.
bta.
net.
cnAddress:202.
106.
196.
115非权威应答:名称:www.
lietu.
comAddress:211.
147.
214.
145根据服务器名称取得IP地址的代码如下:Stringhostname="www.
lietu.
com";//如果是"www.
baidu.
com",则会返回多项IPIPHostEntryhost=Dns.
GetHostEntry(hostname);Console.
WriteLine("GetHostEntry({0})returns:",hostname);foreach(IPAddressipinhost.
AddressList){Console.
WriteLine("{0}",ip);}2.
2爬虫架构本节首先介绍爬虫的基本架构,然后介绍可以在多台服务器上运行的分布式爬虫架构.
2.
2.
1基本架构一般的爬虫软件,通常都包含以下几个模块.
(1)保存种子URL和待抓取的URL的数据结构.
(2)保存已经抓取过的URL的数据结构,防止重复抓取.
(3)页面获取模块.
5555第2章使用C#开发网络爬虫(4)对已经获取页面内容的各个部分进行抽取的模块,如抽取HTML、JavaScript等.
其他可选的模块包括:负责连接前处理模块;负责连接后处理模块;过滤器模块;负责多线程的模块;负责分布式的模块.
各模块详细介绍如下.
1.
保存种子和抓取出来的URL的数据结构农民会把有生长潜力的籽用作种子,这里把一些活跃的网页用作种子URL,如网站的首页或者列表页,因为在这些页面经常会发现新的链接.
通常,爬虫都是从一系列的种子URL开始抓取,一般从数据库表或者配置文件中读取这些种子URL.
种子URL描述表如表2-1所示.
表2-1最佳优先遍历过程表字段名字段类型说明IdNumber(12)唯一标识urlVarchar(128)网站URLsourceVarchar(128)网站来源描述rankNUmber(12)网站PageRank值但是保存待抓取的URL的数据结构确因系统的规模、功能不同而可能采用不同的策略.
一个比较小的示例爬虫程序,可能就使用内存中的一个队列,或者是优先级队列进行存储.
一个中等规模的爬虫程序,可能使用BerkeleyDB这种内存数据库来存储,如果内存中存放不下,还可以序列化到磁盘上.
但是,真正的大规模爬虫系统,是通过服务器集群来存储已经抓取出来的URL的.
并且,还会在存储URL的表中附带一些其他信息,如PageRank值等,供之后的计算用.
2.
保存已经抓取过的URL的数据结构已经抓取过的URL的规模和待抓取的URL的规模是一个相当大的量级.
正如前面介绍的Todo表和Visited表.
但是,它们唯一的不同是,Visited表会经常被查询,以便确定发现的URL是否已经处理过.
因此,Visited表数据结构如果是一个内存数据结构的话,可以采用散列表(HashMap或者HashSet)来存储,如果保存在数据库中,可以对URL列建立索引.
3.
页面获取模块当从种子URL队列或者抓取出来的URL队列中获得URL后,便要根据这个URL来获得当前页面的内容,获得的方法非常简单,就是普通的IO操作.
在这个模块中,仅仅是把URL所指的内容按照二进制的格式读出来,而不对内容做任何处理.
4.
提取已经获取的网页内容中的有效信息从页面获取模块的结果是一个表示HTML源代码的字符串.
从这个字符串中抽取各种56156相关的内容,是爬虫软件的目的.
因此,这个模块就显得非常重要.
通常,在一个网页中,除了包含有文本内容外还有图片、超链接等.
对于文本内容,首先把HTML源代码的字符串保存成HTML文件即可.
关于超链接提取,可以根据HTML语法,使用正则表达式来提取,并且把提取的超链接加入到Todo表中;也可以使用专门的HTML文档解析工具.
在网页中,超链接不光指向HTML页面,还会指向各种文件,对于除了HTML页面的超链接之外,其他内容的链接不能放入Todo表中,而要直接下载.
因此,在这个模块中,还必须包含提取图片、JavaScript、PDF、DOC等内容的部分.
并且,在提取过程中,还要针对HTTP协议来处理返回的状态码.
本章主要研究网页的架构问题,在下一章详细研究从各种文件格式提取有效信息.
5.
负责连接前处理模块、后处理模块和过滤器模块如果只抓取某个网站的网页,则可以对URL按域名过滤.
6.
多线程模块爬虫主要消耗3种资源,即网络带宽、中央处理器和磁盘.
三者中任何一者都有可能成为瓶颈,其中网络带宽一般是租用,所以价格相对昂贵.
为了提高爬虫效率,最直接的方法就是使用多线程的方式进行处理.
在爬虫系统中,将要处理的URL队列往往是唯一的,多个线程顺序地从队列中取得URL,之后各自进行处理(处理阶段是并发进行的).
通常,可以利用线程池来管理线程.
程序中可以使用的最多线程数是可以配置的.
7.
分布式处理分布式是当今计算的主流.
这项技术也可以同时用在网络爬虫上面.
下节介绍多台机器并行采集的方法.
2.
2.
2分布式爬虫架构把抓取任务分布到不同的节点主要是为了可扩展性,也可以使用物理分布的爬虫系统,让每个爬虫节点抓取靠近它的网站.
例如,北京的爬虫节点抓取北京的网站,上海的爬虫节点抓取上海的网站.
还比如,电信网络中的爬虫节点抓取托管在电信的网站,联通网络中的爬虫节点抓取托管在联通的网站.
图2-3所示为一种没有中央服务器的分布式爬虫结构.
要点在于按域名分配采集任务.
每台机器扫描到的网址,不属于它自己的会交换给属于它的机器.
例如,专门有一台机器抓取s开头的网站http://www.
sina.
com.
cn和http://www.
sohu.
com,而另外一台机器抓取l开头的网站http://www.
lietu.
com.
垂直信息分布式抓取的基本设计如下.
(1)按要处理的信息的首字母做散列,让不同的机器抓取不同的信息.
(2)每台机器通过配置文件读取自己要处理的字母.
每台机器抓取完一条结果后把该结果写入到统一的一个数据库中.
比如说有26台机器,第一台机器抓取字母a开头的公司,5757第2章使用C#开发网络爬虫第二台机器抓取字母b开头的公司,依次类推.
(3)如果某一台机器抓取速度太慢,则把该任务拆分到其他的机器.
图2-3分布式爬虫结构2.
2.
3垂直爬虫架构垂直爬虫往往抓取指定网站的新闻或论坛等信息.
可以指定初始抓取的首页或者列表页,然后提取相关的详细页中的有效信息存入数据库,总体结构如图2-4所示.
图2-4垂直爬虫结构垂直爬虫涉及的功能有以下几个.
从首页提取不同栏目的列表页.
网页分类.
把网页分类成列表页或详细页或者未知类型.
列表页链接提取.
从列表页提取同一个栏目下的列表页,这些页面往往用"下一页"或"尾页"等信息描述.
详细页面内容提取.
从详细页提取网页标题、主要内容、发布时间等信息.
可以每个网站用一个线程抓取,这样方便控制对被抓网站的访问频率.
最好有通用的58158信息提取方式来解析网页,这样可以减少人工维护成本.
同时,也可以采用专门的提取类来处理数据量大的网站,这样可以提高抓取效率.
2.
3下载网页例如,想要获得每个城市地区对应的街道.
在网址http://bj.
cityhouse.
cn/street/hd/onedistlist.
html包含一些这样的信息.
先用网页浏览器打开这个网页,下载网页和浏览器根据网址打开网页的道理是一样的.
"打开"网页的过程其实就是浏览器作为一个浏览的"客户端",向服务器端发送了一次请求,把服务器端的文件"抓"到本地,再进行解释、展现.
更进一步,可以通过浏览器端查看"下载"过来的文件源代码.
选择"查看"→"源文件"菜单命令,就会出现从服务器上面"下载"下来的文件源代码.
上面的例子中,在浏览器的地址栏中输入的字符串叫作URL.
那么,什么是URL呢直观地讲,URL就是在浏览器端输入的http://bj.
cityhouse.
cn/street/hd/onedistlist.
html这个字符串.
用URL来代表一个网页.
URL是HTTP协议的一部分.
首先了解下载网页的HTTP协议.
2.
3.
1HTTP协议网络资源一般是Web服务器上的一些各种格式的文件.
一般通过HTTP协议和Web服务器打交道,这样的Web服务器也叫HTTP服务器.
HTTP服务器存储了互联网上的数据,并且根据HTTP客户端的请求提供数据.
网络爬虫也是一种HTTP客户端.
更常见的HTTP客户端是Web浏览器.
客户端发起一个到服务器上指定端口(默认端口为80)的HTTP请求,服务器端按指定格式返回网页或者其他网络资源,如图2-5所示.
图2-5HTTP协议URI包括URL和URN.
但是URN没有流行起来,只需要知道URL是URI的一种就可以了.
URL是UniformResourceLocator的缩写,译为"统一资源定位符".
通俗地说,URL是Internet上描述信息资源的字符串,主要用在各种WWW客户程序和服务器程序上.
采用URL可以用一种统一的格式来描述各种信息资源,包括文件、服务器的地址和目录等.
URL由协议名、主机名和资源路径3个部分组成,一个具体的例子如图2-6所示.
URL中的协议也称为服务方式.
如果你能记住的话,URL中的主机名也可以用主机IP地址代替.
有时也包括端口号,5959第2章使用C#开发网络爬虫如果这个端口号访问者也能记住的话.
图2-6URL的3个部分URL中的资源路径是指主机资源的具体地址,如目录和文件名等.
协议名和主机名之间用"://"符号隔开,主机名和资源路径用"/"符号隔开.
协议名和主机名是不可缺少的,资源路径有时可以省略,如果正好是访问根路径下的默认资源.
例如,http://bj.
cityhouse.
cn/street/hd/onedistlist.
html,其主机域名为bj.
cityhouse.
cn,超级文本文件(文件类型为.
html)是在目录street/hd下的onedistlist.
html.
网页抓取就是把URL地址中指定的网络资源从网络流中读取出来,保存到本地.
类似于使用程序模拟网页浏览器的功能,把URL作为HTTP请求的内容发送到服务器端,然后读取服务器端的响应资源.
客户端向服务器发送的请求头包含请求的方法、URL、协议版本以及包含请求修饰符、客户信息和内容.
服务器以一个状态行作为响应,相应的内容包括消息协议的版本,成功或者错误编码加上包含服务器信息、实体元信息以及可能的实体内容.
HTTP请求格式如下:[]在HTTP请求中,第一行必须是一个请求行(requestline),用来说明请求类型、要访问的资源以及使用的HTTP版本.
紧接着是头信息(headers),用来说明服务器要使用的附加信息.
在头信息之后是一个空行,之后可以添加任意的其他数据,这些附加的数据称为主体(body).
HTTP规范定义了8种可能的请求方法.
网络爬虫经常用到GET、HEAD和POST3种方法,分别说明如下.
(1)GET:检索URI中标识资源的一个简单请求,如爬虫发送请求GET/index.
htmlHTTP/1.
1.
(2)HEAD:与GET方法相同,服务器只返回状态行和头标,并不返回请求文档,如用HEAD请求检查网页更新时间.
(3)POST:服务器接受被写入客户端输出流中的数据请求.
可以用POST方法来提交表单参数.
例如,请求头:Accept:text/plain,text/html60160客户端说明了可以接收文本类型的信息,最好不要发送音频格式的数据.
Referer:http://www.
w3.
org/hypertext/DataSources/Overview.
html代表从这个网页知道正在请求的网页.
Accept-Charset:GB2312,utf-8;q=0.
7每个语言后包括一个q-value,表示用户对这种语言的偏好估计.
默认值是1.
0,1.
0也是最大值.
Keep-alive:115Connection:keep-aliveKeep-alive是指在同一个连接中发出和接收多次HTTP请求,单位是毫秒.
介绍完客户端向服务器的请求消息后,然后再了解服务器向客户端返回的响应消息.
这种类型的消息也是由一个起始行、一个或者多个头信息、一个指示头信息结束的空行和可选的消息体组成.
HTTP的头信息包括通用头、请求头、响应头和实体头4个部分.
每个头信息由一个域名、冒号(:)和域值3部分组成.
域名是大小写无关的,域值前可以添加任何数量的空格符,头信息可以被扩展为多行,在每行开始处,使用至少一个空格或制表符.
例如,爬虫程序发出GET请求:GET/index.
htmlHTTP/1.
1服务器返回响应:HTTP/1.
1200OKDate:Apr11201615:32:08GMTServer:Apache/2.
0.
46(win32)Content-Length:119Content-Type:text/htmlGET请求的头显示类似下面的信息:GET/HTTP/1.
0Host:www.
lietu.
comConnection:Keep-Alive响应头显示类似以下信息:HTTP/1.
0200OKDate:Sun,19Mar201619:39:05GMTContent-Length:657306161第2章使用C#开发网络爬虫Content-Type:text/htmlExpires:Sun,19Mar201619:40:05GMTCache-Control:max-age=60,privateConnection:keep-aliveProxy-Connection:keep-aliveServer:ApacheLast-Modified:Sun,19Mar201619:38:58GMTVary:Accept-Encoding,User-AgentVia:1.
1webcache(NetCacheNetApp/6.
0.
1P3)在提交表单的时候,如果不指定方法,则默认为GET请求,表单中提交的数据将会附加在URL之后,以与URL分开.
字母数字字符原样发送,但空格转换为"+"号,其他符号转换为%**,其中**为该符号以十六进制表示的ASCII值.
GET请求将提交的数据放置在HTTP协议头中,而POST提交的数据则放在实体数据中.
GET方式提交的数据最多只能有1024B,而POST则没有此限制.
例如,程序发出HEAD请求:HEAD/index.
jspHTTP/1.
0服务器返回响应:HTTP/1.
1200OKServer:Apache-Coyote/1.
1Content-Type:text/html;charset=UTF-8Content-Length:5367Date:Fri,08Apr201111:08:24GMTConnection:close2.
3.
2下载静态网页下载网页的基本原理是和Web服务器端建立Socket连接.
但一般不直接使用原始的Socket类,可以用TcpClient来简化Socket编程,如图2-7所示.
图2-7使用System.
Net.
Sockets.
TcpClient使用TcpClient建立连接的例子:62162System.
Net.
TcpClientclient=newTcpClient("www.
lietu.
com",80);Console.
Write("连接上了");完整的下载网页例子的代码如下:TcpClientclient=newTcpClient();StringhostName="www.
lietu.
com";//主机名intportNumber=80;//端口号try{client.
Connect(hostName,portNumber);//建立连接Console.
Write("连接上了");//NetworkStream对象专门用于对网络流数据进行处理NetworkStreamclientStream=client.
GetStream();StreamWriterwriteStream=newStreamWriter(clientStream);writeStream.
Write("GET/HTTP/1.
1\r\n"//发送GET请求+"User-Agent:crawlerrequest!
\r\n"+"Host:www.
lietu.
com\r\n"+"Connection:Close\r\n"+"\r\n");writeStream.
Flush();Stringtext="";byte[]buffer=newbyte[1024];while(clientStream.
Read(buffer,0,1024)>0){//把数据读入到缓存text=text+Encoding.
UTF8.
GetString(buffer);//假设网页是UTF-8编码方式}Console.
WriteLine(text);}catch(SocketExceptionex){System.
Console.
WriteLine(ex.
Message);}finally{client.
Close();}利用WebRequest类可以很轻易地根据给定URL地址下载网页:WebRequestrequest=System.
Net.
WebRequest.
Create("http://www.
lietu.
com");WebRequest能够通过传入的URL对象,创建基于不同协议的Web请求.
从原理上来说,使用了设计模式中的工厂方法支持各种协议.
WebRequest的子类HttpWebRequest类代表要给某个URL发送的HTTP请求.
通过HttpWebRequest.
GetResponse()得到HttpWebResponse类的一个实例.
HttpWebResponse类代表服务器返回的HTTP响应数据,其中包括了网页源代码.
HttpWebResponse.
GetResponseStream()得到输出流.
StringurlDownLoad="http://www.
lietu.
com";//需要获取网页内容的URL地址6363第2章使用C#开发网络爬虫//因为URL地址是HTTP协议的,所以返回一个HttpWebRequest对象HttpWebRequestrequest=(HttpWebRequest)System.
Net.
WebRequest.
Create(urlDownLoad);HttpWebResponseresponse=(HttpWebResponse)request.
GetResponse();Encodingencode=Encoding.
GetEncoding("gb2312");//如果是乱码就改成utf-8TextReadertr=newStreamReader(response.
GetResponseStream(),encode);StringhtmlContent=tr.
ReadToEnd();//保存在字符串中,也可以保存在文件中response.
Close();除了网页源代码,还可以打印返回的头信息,代码如下:WebHeaderCollectionwhc=response.
Headers;for(inti=0;iB>C>A>E>F>I>H,则整个遍历过程如表2-3所示:表2-3最佳优先遍历过程表Todo优先级队Visited集合AnullB,C,D,E,FAB,C,E,FA,DC,E,FA,B,DE,FA,B,C,DF,HA,B,C,D,EH,GA,B,C,D,E,FHA,B,C,D,E,F,GIA,B,C,D,E,F,H,GnullA,B,C,D,E,F,H,I2.
6网站地图为了方便爬虫遍历和更新网站内容,网站可以设置Sitemap.
xml.
Sitemap.
xml也就是网站地图,不过这个网站地图是用XML编写的.
例如,http://www.
10010.
com/Sitemap.
xml,在其中列出网站中的网址以及关于每个网址的其他元数据(上次更新的时间、更改的频率以及相对于网站上其他网址的重要程度等),以便搜索引擎抓取网站.
完整格式如下:http://shop.
10010.
com2011-07-17daily1.
078178http://shop.
10010.
com/iphonesale/getAllIphone.
action2011-07-17weekly0.
9…其中的XML标签的含义说明如下.
loc:页面永久链接地址.
lastmod:页面最后修改时间.
changefreq:页面内容更新频率.
priority:相对于其他页面的优先权.
对于有网站地图的网站,爬虫可以利用这个网站地图遍历和增量抓取.
2.
7连接池当一个新的连接请求进来的时候,连接池管理器检查连接池中是否包含任何没用的连接,如果有的话,就返回一个.
如果连接池中所有的连接都忙,并且最大的连接池数量没有达到,就创建新的连接并且增加到连接池.
当连接池中在用的连接达到最大值时,所有的新连接请求进入队列,直到一个连接可用或者连接请求超时.
连接池包含以下参数.
(1)连接超时.
控制请求一个新连接的等待时间,如果超时,将会抛出一个异常.
(2)最大连接数.
声明连接池的最大值.
默认是100.
(3)最小连接数.
连接池创建时的初始连接数量.
程序一开始初始化创建若干数量的长链接.
给它们设置一个标识位,这个标识位表示该链接是否空闲的状态.
当需要发送数据的时候,系统给它分配一个当前空闲的链接.
同时,将得到的链接设置为"忙",当数据发送完毕后,把链接标识位设置为"闲",让系统可以分配给下个用户,这样使两种方式的优点都充分发挥出来了.
ConnectionPool是连接池的管理器.
用以下方法使用ConnectionPool:ConnectionPool.
InitializeConnectionPool(hostIPAddress,hostPortNumber,minConnections,maxConnections);//初始化连接池try{//取得套接字CustomSocket=ConnectionPool.
GetSocket();//下载网页7979第2章使用C#开发网络爬虫//返回套接字ConnectionPool.
PutSocket();}catch(Exception){ConnectionPool.
PopulateSocketError();}CustomSocket表示一个简单的TCPClient,代码如下:publicclassCustomSocket:TcpClient{privateDateTime_TimeCreated;publicDateTimeTimeCreated{get{return_TimeCreated;}set{_TimeCreated=value;}}publicCustomSocket(stringhost,intport):base(host,port){_TimeCreated=DateTime.
Now;}}2.
8URL地址查新在发表科技论文时,为了避免重复研究和抄袭,需要到专门的科技情报所做论文查新.
为了避免重复抓取,URL地址也需要查新.
判断解析出的URL是否已经遍历过,也叫URLSeen测试.
URLSeen测试对爬虫性能有重要的影响.
本节介绍两种实现快速URLSeen测试的方法.
在介绍爬虫架构的时候,讲解了Frontier组件的作用.
它作为一个基础的组件,为爬虫提供URL.
因此,在Frontier中有一个数据结构来存储URL.
在一些小的爬虫程序中,使用内存队列(ArrayList、HashMap或Queue)或者优先级队列来存储URL,但内存是有限的.
在通常商业应用中,URL地址数据量非常大.
早期的爬虫经常把URL地址放在数据库表中,但数据库对于这种简单的结构化存储来说效率太低.
因此,考虑使用嵌入式数据库来存储.
这里的嵌入式的意思和硬件无关,是嵌入在程序中的意思.
2.
8.
1嵌入式数据库提到嵌入式数据库,首先想到的是最广泛应用的BerkeleyDB(简称BDB).
BDB中的一个数据库只能存储一些键/值对,也就是键和值两列.
BDBC#API打包在BDB源代码里,最新代码可从http://www.
oracle.
com/technology/software/products/berkeley-db/index.
html下载.
下载的db-5.
1.
25.
zip不包括已经编译好的动态链接库,需要根据C和C#源代码编译出相关的动态链接库.
编译BDBC#API本身需要BDBC的动态库.
在BDB的源代码中,C#API的解决方案已包含了BDBC工程,因此,编译该解决方案,无须另外编译和指定BDBC动态库.
80180进入BDB主目录\下的build_windows目录,打开该目录下的C#API的解决方案BDB_dotNet.
sln.
BDBC#API解决方案已配置好所有BDBC#动态库所需的库及环境.
因此,在配置管理器中选择平台(Win32或者x64)和编译模式(Debug或者Release)后,编译该解决方案,便可生成相应的BDBC动态库libdb51.
dll、C#动态库libdb_csharp51.
dll和libdb_dotnet51.
dll以及所有实例的可执行文件.
使用BDBC#API进行基于数据库应用程序的开发,需要3个动态链接库,即libdb51.
dll、libdb_csharp51.
dll和libdb_dotnet51.
dll.
首先,在开发的工程中添加libdb_dotnet51.
dll的引用,由于libdb_dotnet51.
dll需要调用libdb51.
dll和libdb_csharp51.
dll.
因此,libdb51.
dll和libdb_csharp51.
dll应放在本工程路径或者环境变量中,以便运行时加载.
libdb_dotnet51.
dll包含几个基本的类.
其中,DatabaseConfig类表示数据库的配置参数.
DatabaseConfig的子类BTreeDatabaseConfig专门用来配置B树数据库.
BtreeDatabase类表示B树格式存储的数据库,也就是一个排好序的平衡树结构.
DatabaseEntry表示一个数据项.
使用BDBC#API完整的示例代码如下:BTreeDatabaseConfigbtreeDBConfig=newBTreeDatabaseConfig();btreeDBConfig.
Creation=CreatePolicy.
IF_NEEDED;//如果不存在数据库就创建btreeDBConfig.
PageSize=512;//页大小btreeDBConfig.
CacheSize=newCacheInfo(0,64*1024,1);//缓存大小BTreeDatabasebtreeDB=BTreeDatabase.
Open("bdb.
db",btreeDBConfig);Stringurl="www.
lietu.
com";DatabaseEntryk=newDatabaseEntry(ASCIIEncoding.
ASCII.
GetBytes(url));DatabaseEntryv=newDatabaseEntry(BitConverter.
GetBytes((int)1));btreeDB.
Put(k,v);//放入数据KeyValuePairpair=btreeDB.
Get(k);//取得数据System.
Console.
WriteLine(ASCIIEncoding.
ASCII.
GetString(pair.
Key.
Data));btreeDB.
Close();//关闭数据库因为BDB的C#版本要调用C语言的实现,所以部署起来麻烦一点.
Perst是一个全部用C#实现的面向对象的嵌入式数据库系统.
像其他嵌入式数据库一样,Perst没有管理上的代价,但不同的是,Perst直接将对象以C#对象的形式进行存储.
因此,不需要在对象的内部表现形式和C#表现形式之间转换.
项目中直接引用Perst.
NET.
dll.
Perst中操作数据库的代码如下://得到storage的实例Storagedb=StorageFactory.
Instance.
CreateStorage();intpagePoolSize=32*1024*1024;//打开数据库db.
Open("urlSeen.
dbs",pagePoolSize);//操作数据库db.
Close();//关闭数据库需要一个Root对象,代码如下:8181第2章使用C#开发网络爬虫root=(Root)db.
Root;if(root==null){//Root没有定义,也就是storage没有初始化root=newRoot();//创建root对象root.
strIndex=db.
CreateIndex(typeof(String),true);db.
Root=root;}使用Perst实现的URL地址查新方法的代码如下:publicclassRecord:Persistent{publicstringstrKey;}publicclassRoot:Persistent{publicIndexstrIndex;}publicclassUrlSeenDetector{privateStoragedb=null;privateRootroot;privateIndexstrIndex;publicUrlSeenDetector(stringdbName){//初始化数据库db=StorageFactory.
Instance.
CreateStorage();intpagePoolSize=32*1024*1024;db.
Open(dbName,pagePoolSize);root=(Root)db.
Root;if(root==null){root=newRoot();root.
strIndex=db.
CreateIndex(typeof(String),true);db.
Root=root;}strIndex=root.
strIndex;}//如果输入的URL已经见过,则返回truepublicbooldetect(StringnewUrl){Recordrec2=(Record)strIndex[newUrl];//查询if(rec2!
=null){returntrue;}Recordrec=newRecord();rec.
strKey=newUrl;strIndex[rec.
strKey]=rec;returnfalse;82182}publicvoidClose(){if(db!
=null)db.
Close();}}2.
8.
2布隆过滤器判断URL地址是否已经抓取过还可以借助布隆过滤器(BloomFilter).
布隆过滤器的实现方法是:利用内存中的一个长度是m的位数组B,对其中所有位都置0,如图2-13所示.
图2-13位数组B的初始状态然后对每个遍历过的URL根据k个不同的散列函数执行散列,每次散列的结果都是不大于m的一个整数a.
根据散列得到的数在位数组B对应的位上置1,也就是让B[a]=1.
图2-14显示了放入3个URL后位数组B的状态,这里k=3.
图2-14放入数据后位数组B的状态每次插入一个URL,也执行k次散列,只有当全部位都已经置1才认为这个URL已经遍历过.
BloomFilter(http://bloomfilter.
codeplex.
com/)实现了布隆过滤器.
下面是使用布隆过滤器(Filter)的一个例子,其代码如下://创建一个布隆过滤器,优化成包含10000个项目intcapacity=10000;//we'llactuallyaddonlyoneitemfloaterrorRate=0.
0001F;//0.
01%//最后一个值是空,表示使用默认的散列函数FilterurlSeen=newFilter(capacity,errorRate,null);//增加内容到布隆过滤器urlSeen.
add("www.
lietu.
com");urlSeen.
add("www.
sina.
com");urlSeen.
add("www.
qq.
com");urlSeen.
add("www.
sohu.
com");//测试布隆过滤器是否记得这个项目if(urlSeen.
Contains("www.
lietu.
com")){8383第2章使用C#开发网络爬虫System.
Console.
WriteLine("可能已经存在");}else{System.
Console.
WriteLine("一定不存在");}布隆过滤器如果返回不包含某个项目,那肯定就是没往里面增加过这个项目,如果返回包含某个项目,但其实可能没有增加过这个项目,所以有误判的可能.
对爬虫来说,使用布隆过滤器的后果是可能导致漏抓网页.
如果想知道需要使用多少位才能降低错误概率,可以从表2-4所列的存储项目和位数比率估计布隆过滤器的误判率.
表2-4布隆过滤器误判率表比率(items:bits)误判率1∶10.
632120558828561∶20.
399576400893731∶40.
146891597660381∶80.
021577141463221∶160.
000465573033721∶320.
000000211673401∶640.
00000000000004为每个URL分配两个字节就可以达到千分之几的冲突.
例如,一个比较保守的实现,为每个URL分配了4个字节,项目和位数比是1∶32,误判率是0.
00000021167340.
对于5000万数量级的URL,布隆过滤器只占用了200MB的空间,并且排重速度超快,一遍下来不到两分钟.
Filter类中实现的把对象映射到位集合的方法的代码如下://////增加一个新项目到布隆过滤器.
不能再删除这个项目//////publicvoidAdd(Titem){//开始为每个项目的散列位翻转位intprimaryHash=item.
GetHashCode();intsecondaryHash=getHashSecondary(item);for(inti=0;i///检查项目是否在布隆过滤器中84184/////////publicboolContains(Titem){intprimaryHash=item.
GetHashCode();intsecondaryHash=getHashSecondary(item);for(inti=0;i_rssItems=newCollection();}首先看一下其中的GetFeed()方法.
这个方法返回一个Rss.
Items的集合.
这个类使用XMLReader读入XML.
XMLDocument表示一个XML文档.
尽管XmlReader只是一个抽象类,有一些XmlReader类的具体实现,如XmlTextReader、XmlNodeReader和XmlValidatingReader类,但是建议使用Create方法创建XmlReader实例.
其代码如下://检索远程的Feed并解析它publicCollectionGetFeed(){//开始解析过程using(XmlReaderreader=XmlReader.
Create(Url)){8585第2章使用C#开发网络爬虫XmlDocumentxmlDoc=newXmlDocument();xmlDoc.
Load(reader);//解析Feed的项目ParseDocElements(xmlDoc.
SelectSingleNode("//channel"),"title",ref_feedTitle);ParseDocElements(xmlDoc.
SelectSingleNode("//channel"),"description",ref_feedDescription);ParseRssItems(xmlDoc);//返回Feed项目return_rssItems;}}用ParseDocElements方法创建一个新的Rss.
Items集合对象,然后解析返回的XML,增加集合中的项目.
其代码如下://为了检索RSS项目,解析xml文档privatevoidParseRssItems(XmlDocumentxmlDoc){_rssItems.
Clear();XmlNodeListnodes=xmlDoc.
SelectNodes("rss/channel/item");foreach(XmlNodenodeinnodes){Rss.
Itemsitem=newRss.
Items();ParseDocElements(node,"title",refitem.
Title);ParseDocElements(node,"description",refitem.
Description);ParseDocElements(node,"link",refitem.
Link);stringdate=null;ParseDocElements(node,"pubDate",refdate);DateTime.
TryParse(date,outitem.
Date);_rssItems.
Add(item);}}ParseDocElements方法调用ParseDocElements,这里检查每个XmlNode,看它是否包含Feed的属性,其代码如下.
//用指定的Xpath查询解析XmlNode//并分配值给property参数privatevoidParseDocElements(XmlNodeparent,stringxPath,refstringproperty){XmlNodenode=parent.
SelectSingleNode(xPath);if(node!
=null)property=node.
InnerText;elseproperty="Unresolvable";}86186Rss.
Items是一个结构,用来保存Feed中的项目,其代码如下:publicclassRss{///保存RSS的Feed项目的结构[Serializable]publicstructItems{//发布日期publicDateTimeDate;//feed的标题publicstringTitle;//内容的描述publicstringDescription;//Feed的链接publicstringLink;}}2.
10解析相对地址在Windows的控制台窗口中,可以根据当前路径的相对路径转移到一个路径,如cd.
.
转移到当前路径的上级路径.
在HTML网页中也经常使用相对URL.
绝对URL就是不依赖其他的URL路径,如http://www.
lietu.
com/index.
jsp.
在一定的上下文环境下可以使用相对URL.
网页中的URL地址可能是相对地址,如.
/index.
html.
可以在和标签中使用相对URL.
例如:可以根据所在网页的绝对URL地址,把相对地址转换成绝对地址.
为了灵活地引用网站内部资源,相对路径在网页中很常见.
爬虫为了后续处理方便,需要把相对地址转化为绝对地址.
在C#中,可以用System.
Uri类表示一个URL地址.
下面的代码把相对地址转换成绝对地址:UribaseUri=newUri("http://my.
server.
com/folder/directory/sample");//把第二个参数中的相对地址转换成绝对地址UriabsoluteUri=newUri(baseUri,".
.
/.
.
/other/path");2.
11网页更新经常有人会问:"有没有什么新消息"这说明人的大脑是增量获取信息的,对爬虫来说也是如此.
网站中的内容经常会变化,这些变化经常在网站首页或者目录页有反映.
为了提高采集效率,往往考虑增量采集网页.
可以把这个问题看成是被采集的Web服务器8787第2章使用C#开发网络爬虫和存储库同步的问题.
更新网页内容的基本原理是:下载网页时,记录网页下载的时间,增量采集这个网页时,判断URL地址对应的网页是否有更新.
HTTP1.
1声明支持一种特殊类型的HTTPGet,叫做HTTP条件Get.
如果文件在某个条件下没有修改,则HTTP条件Get不下载这个网页.
判断网页是否修改的方法包括If-Modified-Since、If-Unmodified-Since、If-Match、If-None-Match或者If-Range头信息.
爬虫发送条件GET请求的情况如下:GET/HTTP/1.
1Host:www.
lietu.
com.
cn:80If-Modified-Since:Thu,4Feb201020:39:13GMTConnection:Close当没有更新时服务器的响应如下:HTTP/1.
0304NotModifiedDate:Thu,04Feb201012:38:41GMTContent-Type:text/htmlExpires:Thu,04Feb201012:39:41GMTLast-Modified:Thu,04Feb201012:29:04GMTAge:28Connection:close如果服务器网页已经更新,就会把客户端的请求当作一个普通的Get请求发送网页内容:HTTP/1.
0200OKDate:Thu,04Feb201012:49:46GMTServer:ApacheLast-Modified:Thu,04Feb201012:49:05GMTAccept-Ranges:bytesCache-Control:max-age=60Expires:Thu,04Feb201012:50:46GMTVary:Accept-EncodingX-UA-Compatible:IE=EmulateIE7Content-Length:452785Content-Type:text/htmlAge:11Connection:close网页内容.
条件下载命令可以根据时间条件下载网页.
再次请求已经抓取过的页面时,爬虫往Web服务器发送If-Modified-Since请求头,其中包含的时间是先前服务器端发过来的Last-Modified最后修改时间戳.
这样让Web服务器端进行验证,通过这个时间戳判断爬虫上次抓过的页面是否有修改.
如果有修改,则返回HTTP状态码200和新的内容.
如果没有变化,则只返回HTTP状态码304,告诉爬虫页面没有变化.
这样可以大大减少在网络上传输的数据,同时也减轻了被抓取的服务器的负担.
看一下HTTP的Get代码例子.
存储HttpWebRequest的GetResponse方法返回的88188HttpWebResponse对象中的ETag和最后修改日期,其代码如下:HttpWebRequestrequest=(HttpWebRequest)HttpWebRequest.
Create(Uri);request.
Method="GET";HttpWebResponseresponse=(HttpWebResponse)request.
GetResponse();//存储要在HTTP的条件GET中使用的ETag和网页的最后修改日期stringeTag=response.
Headers[HttpResponseHeader.
ETag];stringifModifiedSince=response.
Headers[HttpResponseHeader.
LastModified];注意:对最后修改时间,最好存储原字符串.
因为不同的Web服务器用的日期字符串格式可能不一样.
看一下HTTP条件Get的代码例子,在取得HTTP响应前,它使用Etag去设置If-None-Match头域信息,并且使用最后修改时间去设置If-Modified-Since头域信息.
如果网页没有修改,HttpWebReponse类会抛出一个System.
Net.
WebException异常并且设置StatusCode成NotModified,因此要捕获这个异常并且检查StatusCode.
其代码如下:try{HttpWebRequestrequest=(HttpWebRequest)HttpWebRequest.
Create(Uri);request.
Method="GET";//使用刚保存的ETag设置IfNoneMatchrequest.
Headers[HttpRequestHeader.
IfNoneMatch]=eTag;//使用刚保存的最后修改日期设置IfModifiedSincerequest.
IfModifiedSince=ifModifiedSince;request.
Credentials=newNetworkCredential(userName,password);HttpWebResponseresponse=(HttpWebResponse)request.
GetResponse();//下载Streamstrm=response.
GetResponseStream();//Inputstream//OutputstreamFileStreamfs=newFileStream(outputFile,FileMode.
Create,FileAccess.
Write,FileShare.
None);constintArrSize=10000;Byte[]barr=newByte[ArrSize];while(true){intResult=strm.
Read(barr,0,ArrSize);if(Result==-1||Result==0)break;fs.
Write(barr,0,Result);}fs.
Flush();fs.
Close();strm.
Close();response.
Close();//下载结束}catch(System.
Net.
WebExceptionex){8989第2章使用C#开发网络爬虫if(ex.
Response!
=null){using(HttpWebResponseresponse=ex.
ResponseasHttpWebResponse){if(response.
StatusCode==HttpStatusCode.
NotModified){Console.
WriteLine("文件没有更新");return;}elseConsole.
WriteLine(string.
Format("返回意外的状态码{0}",response.
StatusCode));}}}可以用Range条件下载部分网页.
比如:某网页的大小是1000B,爬虫请求这个网页时用"Range:bytes=0-500",那么Web服务器应该把这个网页开头的501B发回给爬虫.
2.
12信息过滤有时候可能需要按一个关键词列表来过滤信息,如过滤黄色或其他非法信息.
调用indexOf方法来查找关键词集合效率不高,Aho-Corasick算法可以用来在文本中搜索多个关键词.
当有一个关键词的集合,想发现文本中的所有出现关键词的位置,或者检查是否有关键词集合中的任何关键词出现在文本中时,这个实现代码是有用的.
有很多不经常改变的关键词时,可以使用Aho-Corasick算法.
其运行时间是输入文本的长度加上匹配关键词数目的线性和.
Aho-Corasick算法用发明人AlfredV.
Aho和MargaretJ.
Corasick名字命名的.
Aho-Corasick把所有要查找的关键词构建成一个Trie树.
Trie树包含像后缀树一样的链接集合,从代表字符串的每个节点(如abc)到最长的后缀(例如,如果词典中存在bc,则链接到bc,否则如果词典中存在c,则链接到c,否则链接到根节点).
每个节点的失败(failure)匹配属性存储这个最长后缀节点.
也就是说,还包含一个从每个节点到存在于词典中的最长后缀节点链接.
假设词典中存在a、ab、bc、bca、c、caa词,这6个词组成如图2-15所示的Trie树结构.
由指定的字典构造的Aho-Corasick算法的数据结构如表2-5所列,表里面的每一行代表树中的一个节点,表里的列路径用从根到节点的唯一字符序列说明.
每取一个待匹配的字符后,当前的节点通过寻找它的孩子来匹配,如果孩子不存在,也就是匹配失败,则试图匹配该节点后缀的孩子,如果这样也没有匹配上,则匹配该节点后缀的后缀的孩子,最后如果什么也没有匹配上,就在根节点结束.
分析输入字符串"abccab"的匹配过程如表2-6所示.
90190图2-15Trie树结构表2-5Trie树的结构路径是否在字典里后缀链接词典后缀链接()否(a)是()(ab)是(b)(b)否()(bc)是(c)(c)(bca)是(ca)(a)(c)是()(ca)否(a)(a)(caa)是(a)(a)表2-6Aho-Corasick算法匹配过程节点剩余的字符串输出:结束位置跳转输出()abccab从根节点开始(a)bccaba:1从根节点()转移到孩子节点(a)当前节点(ab)ccabab:2节点(a)转移到孩子节点(ab)当前节点(bc)cabbc:3,c:3节点(ab)转到后缀(b),再跳转到孩子节点(bc)当前节点,词典后缀节点9191第2章使用C#开发网络爬虫续表节点剩余的字符串输出:结束位置跳转输出(c)abc:4节点(bc)转到后缀节点(c),再跳转到根节点(),再跳转到孩子节点(c)当前节点(ca)ba:5节点(c)跳转到孩子节点(ca)词典后缀节点(ab)ab:6节点(ca)跳转到后缀节点(a),再跳转到孩子节点(ab)当前节点首先定义Trie树节点类,其代码如下://////表示字符和它的转换和失败方法的树节点///classTreeNode{#region构造&方法//////使用特定的字符初始化树节点//////父亲节点///字符publicTreeNode(TreeNodeparent,charc){_char=c;_parent=parent;_results=newArrayList();_resultsAr=newstring[]{};_transitionsAr=newTreeNode[]{};_transHash=newHashtable();}//////增加在这个节点结束的模式//////模式publicvoidAddResult(stringresult){if(_results.
Contains(result))return;_results.
Add(result);_resultsAr=(string[])_results.
ToArray(typeof(string));}//////增加转换节点//////NodepublicvoidAddTransition(TreeNodenode){92192_transHash.
Add(node.
Char,node);TreeNode[]ar=newTreeNode[_transHash.
Values.
Count];_transHash.
Values.
CopyTo(ar,0);_transitionsAr=ar;}//////返回到给定字符的转换(如果存在的话)//////字符///返回TreeNode或者nullpublicTreeNodeGetTransition(charc){return(TreeNode)_transHash[c];}//////如果节点包括到指定字符的转换,则返回true//////Character///如果转换存在则返回TruepublicboolContainsTransition(charc){returnGetTransition(c)!
=null;}#endregion#regionPropertiesprivatechar_char;privateTreeNode_parent;privateTreeNode_failure;privateArrayList_results;privateTreeNode[]_transitionsAr;privatestring[]_resultsAr;privateHashtable_transHash;//////分隔字符///publiccharChar{get{return_char;}}//////父亲树节点///9393第2章使用C#开发网络爬虫publicTreeNodeParent{get{return_parent;}}//////失败方法–后代节点///publicTreeNodeFailure{get{return_failure;}set{_failure=value;}}//////转换方法–后代节点的列表///publicTreeNode[]Transitions{get{return_transitionsAr;}}//////返回一个以这个字符结束的模式的数组///publicstring[]Results{get{return_resultsAr;}}#endregion}查找输入文本是否包含关键词集合中的任何词,其代码如下://////查询传入的字符串,如果包含任何关键词,则返回true//////Texttosearch///当字符串包含任何关键词,则返回truepublicboolContainsAny(stringtext){TreeNodeptr=_root;intindex=0;while(index0)returntrue;index++;}returnfalse;}2.
13垂直行业抓取从首页提取类别信息,然后按类别信息找到目录页.
通过翻页遍历所有的目录页,提取详细页.
从详细页面提取商品信息.
把商品信息存入数据库.
以新浪新闻为例,同一个目录下的URL是:http://roll.
news.
sina.
com.
cn/news/gjxw/hqqw/index.
shtmlhttp://roll.
news.
sina.
com.
cn/news/gjxw/hqqw/index_2.
shtmlhttp://roll.
news.
sina.
com.
cn/news/gjxw/hqqw/index_3.
shtml以购物网站为例,同一个目录下的URL是:http://www.
mcmelectronics.
com/browse/Cameras/0000000002http://www.
mcmelectronics.
com/browse/Cameras/0000000002/p/2http://www.
mcmelectronics.
com/browse/Cameras/0000000002/p/3http://www.
mcmelectronics.
com/browse/Cameras/0000000002/p/4不断增加翻页参数,一直到找不到新的商品为止.
很多网页的下一页链接是由JavaScript函数生成的,比如:2需要用WebBrowser控件提取其中的链接.
2.
14抓取限制应对方法对爬虫不友好的网站有各种各样的限制抓取的方法,所以爬虫应对的方法也不同.
从原理上来说,只要浏览器可以访问,爬虫应该也可以访问.
2.
14.
1更换IP地址有些网站对于同一个IP地址在一段时间内的访问次数有限制.
可以使用Socket代理来更改请求的IP地址.
这时可以通过大量不同的Socket代理循环访问网站.
WebRequest中可以指定代理服务器,代码如下:WebProxyproxyObject=newWebProxy("http://proxyserver:80/",true);WebRequestreq=WebRequest.
Create("http://www.
lietu.
com");req.
Proxy=proxyObject;9595第2章使用C#开发网络爬虫去某网站上抓取数据时,每隔几分钟换不同代理访问该网站.
每次抓的时候看一下当前代理开始启用的时间有没有过期.
如果已经过期就换新的代理,同时记录新的时间,其代码如下:privatestaticDateTimeLastCheckTime=DateTime.
Now;//记录下当前代理开始启用的时间WebProxyproxyObject=newWebProxy("http://currentIP:80/",true);//如果超过10分钟就换IPif(LastCheckTime.
AddMinutes(10)-1){//登录成功Console.
WriteLine("断开登录成功");}else{Console.
WriteLine("断开登录失败");}}}使用办公区的机器抓取数据后,可以把数据提交到统一的存储服务器.
这样抓取数据的机器对于存储服务器来说就是客户端,而存储的机器一般位于机房,是服务器端.
这些都可以使用网络爬虫帮忙实现.
网络爬虫从互联网源源不断地抓取海量信息,搜索引擎结果中的信息都来源于此.
如果把互联网比喻成一个覆盖地球的蜘蛛网,那么抓取程序就是在网上爬来爬去的蜘蛛.
在抓取信息时,应当首先关注一些高质量的网页信息.
高质量的网页是指网民投票选择出来的网页,这里是访问量高的网站中的一些热门网页.
但是尺有所短,寸有所长,很多访问量一般的网站包括了更多问题的答案.
有点类似长尾效益.
Alexa(http://www.
alexa.
com)专门统计网站访问量并发布网站世界排名.
如果使用FireFox浏览器,可以通过alexa插件查看到当前访问的网站是否还有很多人在访问.
如果使用IE浏览器,可以通过alexa工具条查看到当前访问网站的访问量排名.
有些文档的时效性很强,如新闻或者财经信息.
大部分人想要知道的是当天股票市场的报道,只有很少人关心昨天的市场发生了什么.
本章专门介绍如何抓取即时信息.
网络爬虫需要实现的基本功能包括下载网页以及对URL地址的遍历.
为了高效、快速地遍历网站,还需要应用专门的数据结构来优化.
爬虫很消耗带宽资源,设计爬虫时需要仔细地考虑如何节省网络带宽.
2.
1网络爬虫抓取原理既然所有的网页都可能链接到其他的网站,那么从一个网站开始,跟踪所有网页上的所有链接,就可能遍历整个互联网.
为了更快地抓取想要的信息,网页抓取首先从一个已知的URL地址列表开始遍历,对垂直搜索来说,一般是积累的行业内的网站.
有人可能会奇怪,像Google或百度这样的搜索门户怎么设置这个初始的URL地址列表.
一般来说,网站拥有者把网站提交给分类目录,如dmoz(http://www.
dmoz.
org/),爬虫则可以从开放式分类目录dmoz抓取.
抓取下来的网页中包含了想要的信息,一般存放在数据库或索引库这样的专门的存储系统中,如图2-1所示.
图2-1网络爬虫基本结构在搜索引擎中,爬虫程序是从一系列种子链接把这些初始的网页中的URL提取出来,放入URL工作队列(Todo队列,也叫Frontier),然后遍历所有工作队列中的URL,下载网页并把其中新发现的URL再次放入工作队列.
为了判断一个URL是否已经遍历过,可以5353第2章使用C#开发网络爬虫把所有遍历过的URL放入历史表(Visited表).
爬虫抓取的基本过程如图2-2所示.
图2-2网页遍历流程图抓取的主要流程代码如下:classCrawler{staticListtodo=newList();//要访问的链接staticListvisited=newList();//已经访问过的链接staticstringstartPointAddress="http://www.
lietu.
com";publicvoidCrawler(){//爬虫的开始点RequestSite(startPointAddress);//访问种子站点while(todo.
Count>0){//如果有需要遍历的链接,则逐个遍历StringcurrentURL=todo[0];RequestSite(currentURL);//访问链接todo.
RemoveAt(currentURL);//从todo表中删除visited.
Add(currentURL);}}voidRequestSite(stringurl){WebRequestreq=(WebRequest.
Create(url));HttpWebResponseres=(HttpWebResponse)(req.
GetResponse());Streamst=res.
GetResponseStream();StreamReaderrdr=newStreamReader(st);strings=rdr.
ReadToEnd();todo.
AddRange(GetLinks(s));//增加链接到队列的尾部}ListGetLinks(stringhtmlPage){//通过正则表达式提取链接Regexregx=newRegex("http://([\\w+\\.
\\w+])+([a-zA-Z0-9\\~RegexOptions.
IgnoreCase);MatchCollectionmactches=regx.
Matches(htmlPage);Listresults=newList();foreach(Matchmatchinmatches){if(!
visited.
Contains(match.
Value))54154results.
Add(mattch.
Value);}returnresults;}}如果采用Queue来实现todo,则对每个增加到todo的元素都需要用对象封装.
ArrayDeque允许在末端增加或删除元素.
因为ArrayDeque底层采用数组实现,所以增加到ArrayDeque的元素不需要用对象封装.
ArrayDeque性能比Queue更好.
所以用ArrayDeque来实现todo队列.
Wintellect.
PowerCollections中包含一个ArrayDeque的实现.
有个URLSeen存储.
这里的visited就是URLSeen存储.
如果visited是全局唯一的,那就需要同步了.
服务器的名称通过DNS服务器转换成对应的IP地址,也就是说,通过DNS取得该URL域名的IP地址.
需要选择一个好的DNS服务器.
在Windows下DNS解析的问题可以用nslookup命令来分析,例如:C:\Users\Administrator>nslookupwww.
lietu.
com服务器:linedns.
bta.
net.
cnAddress:202.
106.
196.
115非权威应答:名称:www.
lietu.
comAddress:211.
147.
214.
145根据服务器名称取得IP地址的代码如下:Stringhostname="www.
lietu.
com";//如果是"www.
baidu.
com",则会返回多项IPIPHostEntryhost=Dns.
GetHostEntry(hostname);Console.
WriteLine("GetHostEntry({0})returns:",hostname);foreach(IPAddressipinhost.
AddressList){Console.
WriteLine("{0}",ip);}2.
2爬虫架构本节首先介绍爬虫的基本架构,然后介绍可以在多台服务器上运行的分布式爬虫架构.
2.
2.
1基本架构一般的爬虫软件,通常都包含以下几个模块.
(1)保存种子URL和待抓取的URL的数据结构.
(2)保存已经抓取过的URL的数据结构,防止重复抓取.
(3)页面获取模块.
5555第2章使用C#开发网络爬虫(4)对已经获取页面内容的各个部分进行抽取的模块,如抽取HTML、JavaScript等.
其他可选的模块包括:负责连接前处理模块;负责连接后处理模块;过滤器模块;负责多线程的模块;负责分布式的模块.
各模块详细介绍如下.
1.
保存种子和抓取出来的URL的数据结构农民会把有生长潜力的籽用作种子,这里把一些活跃的网页用作种子URL,如网站的首页或者列表页,因为在这些页面经常会发现新的链接.
通常,爬虫都是从一系列的种子URL开始抓取,一般从数据库表或者配置文件中读取这些种子URL.
种子URL描述表如表2-1所示.
表2-1最佳优先遍历过程表字段名字段类型说明IdNumber(12)唯一标识urlVarchar(128)网站URLsourceVarchar(128)网站来源描述rankNUmber(12)网站PageRank值但是保存待抓取的URL的数据结构确因系统的规模、功能不同而可能采用不同的策略.
一个比较小的示例爬虫程序,可能就使用内存中的一个队列,或者是优先级队列进行存储.
一个中等规模的爬虫程序,可能使用BerkeleyDB这种内存数据库来存储,如果内存中存放不下,还可以序列化到磁盘上.
但是,真正的大规模爬虫系统,是通过服务器集群来存储已经抓取出来的URL的.
并且,还会在存储URL的表中附带一些其他信息,如PageRank值等,供之后的计算用.
2.
保存已经抓取过的URL的数据结构已经抓取过的URL的规模和待抓取的URL的规模是一个相当大的量级.
正如前面介绍的Todo表和Visited表.
但是,它们唯一的不同是,Visited表会经常被查询,以便确定发现的URL是否已经处理过.
因此,Visited表数据结构如果是一个内存数据结构的话,可以采用散列表(HashMap或者HashSet)来存储,如果保存在数据库中,可以对URL列建立索引.
3.
页面获取模块当从种子URL队列或者抓取出来的URL队列中获得URL后,便要根据这个URL来获得当前页面的内容,获得的方法非常简单,就是普通的IO操作.
在这个模块中,仅仅是把URL所指的内容按照二进制的格式读出来,而不对内容做任何处理.
4.
提取已经获取的网页内容中的有效信息从页面获取模块的结果是一个表示HTML源代码的字符串.
从这个字符串中抽取各种56156相关的内容,是爬虫软件的目的.
因此,这个模块就显得非常重要.
通常,在一个网页中,除了包含有文本内容外还有图片、超链接等.
对于文本内容,首先把HTML源代码的字符串保存成HTML文件即可.
关于超链接提取,可以根据HTML语法,使用正则表达式来提取,并且把提取的超链接加入到Todo表中;也可以使用专门的HTML文档解析工具.
在网页中,超链接不光指向HTML页面,还会指向各种文件,对于除了HTML页面的超链接之外,其他内容的链接不能放入Todo表中,而要直接下载.
因此,在这个模块中,还必须包含提取图片、JavaScript、PDF、DOC等内容的部分.
并且,在提取过程中,还要针对HTTP协议来处理返回的状态码.
本章主要研究网页的架构问题,在下一章详细研究从各种文件格式提取有效信息.
5.
负责连接前处理模块、后处理模块和过滤器模块如果只抓取某个网站的网页,则可以对URL按域名过滤.
6.
多线程模块爬虫主要消耗3种资源,即网络带宽、中央处理器和磁盘.
三者中任何一者都有可能成为瓶颈,其中网络带宽一般是租用,所以价格相对昂贵.
为了提高爬虫效率,最直接的方法就是使用多线程的方式进行处理.
在爬虫系统中,将要处理的URL队列往往是唯一的,多个线程顺序地从队列中取得URL,之后各自进行处理(处理阶段是并发进行的).
通常,可以利用线程池来管理线程.
程序中可以使用的最多线程数是可以配置的.
7.
分布式处理分布式是当今计算的主流.
这项技术也可以同时用在网络爬虫上面.
下节介绍多台机器并行采集的方法.
2.
2.
2分布式爬虫架构把抓取任务分布到不同的节点主要是为了可扩展性,也可以使用物理分布的爬虫系统,让每个爬虫节点抓取靠近它的网站.
例如,北京的爬虫节点抓取北京的网站,上海的爬虫节点抓取上海的网站.
还比如,电信网络中的爬虫节点抓取托管在电信的网站,联通网络中的爬虫节点抓取托管在联通的网站.
图2-3所示为一种没有中央服务器的分布式爬虫结构.
要点在于按域名分配采集任务.
每台机器扫描到的网址,不属于它自己的会交换给属于它的机器.
例如,专门有一台机器抓取s开头的网站http://www.
sina.
com.
cn和http://www.
sohu.
com,而另外一台机器抓取l开头的网站http://www.
lietu.
com.
垂直信息分布式抓取的基本设计如下.
(1)按要处理的信息的首字母做散列,让不同的机器抓取不同的信息.
(2)每台机器通过配置文件读取自己要处理的字母.
每台机器抓取完一条结果后把该结果写入到统一的一个数据库中.
比如说有26台机器,第一台机器抓取字母a开头的公司,5757第2章使用C#开发网络爬虫第二台机器抓取字母b开头的公司,依次类推.
(3)如果某一台机器抓取速度太慢,则把该任务拆分到其他的机器.
图2-3分布式爬虫结构2.
2.
3垂直爬虫架构垂直爬虫往往抓取指定网站的新闻或论坛等信息.
可以指定初始抓取的首页或者列表页,然后提取相关的详细页中的有效信息存入数据库,总体结构如图2-4所示.
图2-4垂直爬虫结构垂直爬虫涉及的功能有以下几个.
从首页提取不同栏目的列表页.
网页分类.
把网页分类成列表页或详细页或者未知类型.
列表页链接提取.
从列表页提取同一个栏目下的列表页,这些页面往往用"下一页"或"尾页"等信息描述.
详细页面内容提取.
从详细页提取网页标题、主要内容、发布时间等信息.
可以每个网站用一个线程抓取,这样方便控制对被抓网站的访问频率.
最好有通用的58158信息提取方式来解析网页,这样可以减少人工维护成本.
同时,也可以采用专门的提取类来处理数据量大的网站,这样可以提高抓取效率.
2.
3下载网页例如,想要获得每个城市地区对应的街道.
在网址http://bj.
cityhouse.
cn/street/hd/onedistlist.
html包含一些这样的信息.
先用网页浏览器打开这个网页,下载网页和浏览器根据网址打开网页的道理是一样的.
"打开"网页的过程其实就是浏览器作为一个浏览的"客户端",向服务器端发送了一次请求,把服务器端的文件"抓"到本地,再进行解释、展现.
更进一步,可以通过浏览器端查看"下载"过来的文件源代码.
选择"查看"→"源文件"菜单命令,就会出现从服务器上面"下载"下来的文件源代码.
上面的例子中,在浏览器的地址栏中输入的字符串叫作URL.
那么,什么是URL呢直观地讲,URL就是在浏览器端输入的http://bj.
cityhouse.
cn/street/hd/onedistlist.
html这个字符串.
用URL来代表一个网页.
URL是HTTP协议的一部分.
首先了解下载网页的HTTP协议.
2.
3.
1HTTP协议网络资源一般是Web服务器上的一些各种格式的文件.
一般通过HTTP协议和Web服务器打交道,这样的Web服务器也叫HTTP服务器.
HTTP服务器存储了互联网上的数据,并且根据HTTP客户端的请求提供数据.
网络爬虫也是一种HTTP客户端.
更常见的HTTP客户端是Web浏览器.
客户端发起一个到服务器上指定端口(默认端口为80)的HTTP请求,服务器端按指定格式返回网页或者其他网络资源,如图2-5所示.
图2-5HTTP协议URI包括URL和URN.
但是URN没有流行起来,只需要知道URL是URI的一种就可以了.
URL是UniformResourceLocator的缩写,译为"统一资源定位符".
通俗地说,URL是Internet上描述信息资源的字符串,主要用在各种WWW客户程序和服务器程序上.
采用URL可以用一种统一的格式来描述各种信息资源,包括文件、服务器的地址和目录等.
URL由协议名、主机名和资源路径3个部分组成,一个具体的例子如图2-6所示.
URL中的协议也称为服务方式.
如果你能记住的话,URL中的主机名也可以用主机IP地址代替.
有时也包括端口号,5959第2章使用C#开发网络爬虫如果这个端口号访问者也能记住的话.
图2-6URL的3个部分URL中的资源路径是指主机资源的具体地址,如目录和文件名等.
协议名和主机名之间用"://"符号隔开,主机名和资源路径用"/"符号隔开.
协议名和主机名是不可缺少的,资源路径有时可以省略,如果正好是访问根路径下的默认资源.
例如,http://bj.
cityhouse.
cn/street/hd/onedistlist.
html,其主机域名为bj.
cityhouse.
cn,超级文本文件(文件类型为.
html)是在目录street/hd下的onedistlist.
html.
网页抓取就是把URL地址中指定的网络资源从网络流中读取出来,保存到本地.
类似于使用程序模拟网页浏览器的功能,把URL作为HTTP请求的内容发送到服务器端,然后读取服务器端的响应资源.
客户端向服务器发送的请求头包含请求的方法、URL、协议版本以及包含请求修饰符、客户信息和内容.
服务器以一个状态行作为响应,相应的内容包括消息协议的版本,成功或者错误编码加上包含服务器信息、实体元信息以及可能的实体内容.
HTTP请求格式如下:[]在HTTP请求中,第一行必须是一个请求行(requestline),用来说明请求类型、要访问的资源以及使用的HTTP版本.
紧接着是头信息(headers),用来说明服务器要使用的附加信息.
在头信息之后是一个空行,之后可以添加任意的其他数据,这些附加的数据称为主体(body).
HTTP规范定义了8种可能的请求方法.
网络爬虫经常用到GET、HEAD和POST3种方法,分别说明如下.
(1)GET:检索URI中标识资源的一个简单请求,如爬虫发送请求GET/index.
htmlHTTP/1.
1.
(2)HEAD:与GET方法相同,服务器只返回状态行和头标,并不返回请求文档,如用HEAD请求检查网页更新时间.
(3)POST:服务器接受被写入客户端输出流中的数据请求.
可以用POST方法来提交表单参数.
例如,请求头:Accept:text/plain,text/html60160客户端说明了可以接收文本类型的信息,最好不要发送音频格式的数据.
Referer:http://www.
w3.
org/hypertext/DataSources/Overview.
html代表从这个网页知道正在请求的网页.
Accept-Charset:GB2312,utf-8;q=0.
7每个语言后包括一个q-value,表示用户对这种语言的偏好估计.
默认值是1.
0,1.
0也是最大值.
Keep-alive:115Connection:keep-aliveKeep-alive是指在同一个连接中发出和接收多次HTTP请求,单位是毫秒.
介绍完客户端向服务器的请求消息后,然后再了解服务器向客户端返回的响应消息.
这种类型的消息也是由一个起始行、一个或者多个头信息、一个指示头信息结束的空行和可选的消息体组成.
HTTP的头信息包括通用头、请求头、响应头和实体头4个部分.
每个头信息由一个域名、冒号(:)和域值3部分组成.
域名是大小写无关的,域值前可以添加任何数量的空格符,头信息可以被扩展为多行,在每行开始处,使用至少一个空格或制表符.
例如,爬虫程序发出GET请求:GET/index.
htmlHTTP/1.
1服务器返回响应:HTTP/1.
1200OKDate:Apr11201615:32:08GMTServer:Apache/2.
0.
46(win32)Content-Length:119Content-Type:text/htmlGET请求的头显示类似下面的信息:GET/HTTP/1.
0Host:www.
lietu.
comConnection:Keep-Alive响应头显示类似以下信息:HTTP/1.
0200OKDate:Sun,19Mar201619:39:05GMTContent-Length:657306161第2章使用C#开发网络爬虫Content-Type:text/htmlExpires:Sun,19Mar201619:40:05GMTCache-Control:max-age=60,privateConnection:keep-aliveProxy-Connection:keep-aliveServer:ApacheLast-Modified:Sun,19Mar201619:38:58GMTVary:Accept-Encoding,User-AgentVia:1.
1webcache(NetCacheNetApp/6.
0.
1P3)在提交表单的时候,如果不指定方法,则默认为GET请求,表单中提交的数据将会附加在URL之后,以与URL分开.
字母数字字符原样发送,但空格转换为"+"号,其他符号转换为%**,其中**为该符号以十六进制表示的ASCII值.
GET请求将提交的数据放置在HTTP协议头中,而POST提交的数据则放在实体数据中.
GET方式提交的数据最多只能有1024B,而POST则没有此限制.
例如,程序发出HEAD请求:HEAD/index.
jspHTTP/1.
0服务器返回响应:HTTP/1.
1200OKServer:Apache-Coyote/1.
1Content-Type:text/html;charset=UTF-8Content-Length:5367Date:Fri,08Apr201111:08:24GMTConnection:close2.
3.
2下载静态网页下载网页的基本原理是和Web服务器端建立Socket连接.
但一般不直接使用原始的Socket类,可以用TcpClient来简化Socket编程,如图2-7所示.
图2-7使用System.
Net.
Sockets.
TcpClient使用TcpClient建立连接的例子:62162System.
Net.
TcpClientclient=newTcpClient("www.
lietu.
com",80);Console.
Write("连接上了");完整的下载网页例子的代码如下:TcpClientclient=newTcpClient();StringhostName="www.
lietu.
com";//主机名intportNumber=80;//端口号try{client.
Connect(hostName,portNumber);//建立连接Console.
Write("连接上了");//NetworkStream对象专门用于对网络流数据进行处理NetworkStreamclientStream=client.
GetStream();StreamWriterwriteStream=newStreamWriter(clientStream);writeStream.
Write("GET/HTTP/1.
1\r\n"//发送GET请求+"User-Agent:crawlerrequest!
\r\n"+"Host:www.
lietu.
com\r\n"+"Connection:Close\r\n"+"\r\n");writeStream.
Flush();Stringtext="";byte[]buffer=newbyte[1024];while(clientStream.
Read(buffer,0,1024)>0){//把数据读入到缓存text=text+Encoding.
UTF8.
GetString(buffer);//假设网页是UTF-8编码方式}Console.
WriteLine(text);}catch(SocketExceptionex){System.
Console.
WriteLine(ex.
Message);}finally{client.
Close();}利用WebRequest类可以很轻易地根据给定URL地址下载网页:WebRequestrequest=System.
Net.
WebRequest.
Create("http://www.
lietu.
com");WebRequest能够通过传入的URL对象,创建基于不同协议的Web请求.
从原理上来说,使用了设计模式中的工厂方法支持各种协议.
WebRequest的子类HttpWebRequest类代表要给某个URL发送的HTTP请求.
通过HttpWebRequest.
GetResponse()得到HttpWebResponse类的一个实例.
HttpWebResponse类代表服务器返回的HTTP响应数据,其中包括了网页源代码.
HttpWebResponse.
GetResponseStream()得到输出流.
StringurlDownLoad="http://www.
lietu.
com";//需要获取网页内容的URL地址6363第2章使用C#开发网络爬虫//因为URL地址是HTTP协议的,所以返回一个HttpWebRequest对象HttpWebRequestrequest=(HttpWebRequest)System.
Net.
WebRequest.
Create(urlDownLoad);HttpWebResponseresponse=(HttpWebResponse)request.
GetResponse();Encodingencode=Encoding.
GetEncoding("gb2312");//如果是乱码就改成utf-8TextReadertr=newStreamReader(response.
GetResponseStream(),encode);StringhtmlContent=tr.
ReadToEnd();//保存在字符串中,也可以保存在文件中response.
Close();除了网页源代码,还可以打印返回的头信息,代码如下:WebHeaderCollectionwhc=response.
Headers;for(inti=0;iB>C>A>E>F>I>H,则整个遍历过程如表2-3所示:表2-3最佳优先遍历过程表Todo优先级队Visited集合AnullB,C,D,E,FAB,C,E,FA,DC,E,FA,B,DE,FA,B,C,DF,HA,B,C,D,EH,GA,B,C,D,E,FHA,B,C,D,E,F,GIA,B,C,D,E,F,H,GnullA,B,C,D,E,F,H,I2.
6网站地图为了方便爬虫遍历和更新网站内容,网站可以设置Sitemap.
xml.
Sitemap.
xml也就是网站地图,不过这个网站地图是用XML编写的.
例如,http://www.
10010.
com/Sitemap.
xml,在其中列出网站中的网址以及关于每个网址的其他元数据(上次更新的时间、更改的频率以及相对于网站上其他网址的重要程度等),以便搜索引擎抓取网站.
完整格式如下:http://shop.
10010.
com2011-07-17daily1.
078178http://shop.
10010.
com/iphonesale/getAllIphone.
action2011-07-17weekly0.
9…其中的XML标签的含义说明如下.
loc:页面永久链接地址.
lastmod:页面最后修改时间.
changefreq:页面内容更新频率.
priority:相对于其他页面的优先权.
对于有网站地图的网站,爬虫可以利用这个网站地图遍历和增量抓取.
2.
7连接池当一个新的连接请求进来的时候,连接池管理器检查连接池中是否包含任何没用的连接,如果有的话,就返回一个.
如果连接池中所有的连接都忙,并且最大的连接池数量没有达到,就创建新的连接并且增加到连接池.
当连接池中在用的连接达到最大值时,所有的新连接请求进入队列,直到一个连接可用或者连接请求超时.
连接池包含以下参数.
(1)连接超时.
控制请求一个新连接的等待时间,如果超时,将会抛出一个异常.
(2)最大连接数.
声明连接池的最大值.
默认是100.
(3)最小连接数.
连接池创建时的初始连接数量.
程序一开始初始化创建若干数量的长链接.
给它们设置一个标识位,这个标识位表示该链接是否空闲的状态.
当需要发送数据的时候,系统给它分配一个当前空闲的链接.
同时,将得到的链接设置为"忙",当数据发送完毕后,把链接标识位设置为"闲",让系统可以分配给下个用户,这样使两种方式的优点都充分发挥出来了.
ConnectionPool是连接池的管理器.
用以下方法使用ConnectionPool:ConnectionPool.
InitializeConnectionPool(hostIPAddress,hostPortNumber,minConnections,maxConnections);//初始化连接池try{//取得套接字CustomSocket=ConnectionPool.
GetSocket();//下载网页7979第2章使用C#开发网络爬虫//返回套接字ConnectionPool.
PutSocket();}catch(Exception){ConnectionPool.
PopulateSocketError();}CustomSocket表示一个简单的TCPClient,代码如下:publicclassCustomSocket:TcpClient{privateDateTime_TimeCreated;publicDateTimeTimeCreated{get{return_TimeCreated;}set{_TimeCreated=value;}}publicCustomSocket(stringhost,intport):base(host,port){_TimeCreated=DateTime.
Now;}}2.
8URL地址查新在发表科技论文时,为了避免重复研究和抄袭,需要到专门的科技情报所做论文查新.
为了避免重复抓取,URL地址也需要查新.
判断解析出的URL是否已经遍历过,也叫URLSeen测试.
URLSeen测试对爬虫性能有重要的影响.
本节介绍两种实现快速URLSeen测试的方法.
在介绍爬虫架构的时候,讲解了Frontier组件的作用.
它作为一个基础的组件,为爬虫提供URL.
因此,在Frontier中有一个数据结构来存储URL.
在一些小的爬虫程序中,使用内存队列(ArrayList、HashMap或Queue)或者优先级队列来存储URL,但内存是有限的.
在通常商业应用中,URL地址数据量非常大.
早期的爬虫经常把URL地址放在数据库表中,但数据库对于这种简单的结构化存储来说效率太低.
因此,考虑使用嵌入式数据库来存储.
这里的嵌入式的意思和硬件无关,是嵌入在程序中的意思.
2.
8.
1嵌入式数据库提到嵌入式数据库,首先想到的是最广泛应用的BerkeleyDB(简称BDB).
BDB中的一个数据库只能存储一些键/值对,也就是键和值两列.
BDBC#API打包在BDB源代码里,最新代码可从http://www.
oracle.
com/technology/software/products/berkeley-db/index.
html下载.
下载的db-5.
1.
25.
zip不包括已经编译好的动态链接库,需要根据C和C#源代码编译出相关的动态链接库.
编译BDBC#API本身需要BDBC的动态库.
在BDB的源代码中,C#API的解决方案已包含了BDBC工程,因此,编译该解决方案,无须另外编译和指定BDBC动态库.
80180进入BDB主目录\下的build_windows目录,打开该目录下的C#API的解决方案BDB_dotNet.
sln.
BDBC#API解决方案已配置好所有BDBC#动态库所需的库及环境.
因此,在配置管理器中选择平台(Win32或者x64)和编译模式(Debug或者Release)后,编译该解决方案,便可生成相应的BDBC动态库libdb51.
dll、C#动态库libdb_csharp51.
dll和libdb_dotnet51.
dll以及所有实例的可执行文件.
使用BDBC#API进行基于数据库应用程序的开发,需要3个动态链接库,即libdb51.
dll、libdb_csharp51.
dll和libdb_dotnet51.
dll.
首先,在开发的工程中添加libdb_dotnet51.
dll的引用,由于libdb_dotnet51.
dll需要调用libdb51.
dll和libdb_csharp51.
dll.
因此,libdb51.
dll和libdb_csharp51.
dll应放在本工程路径或者环境变量中,以便运行时加载.
libdb_dotnet51.
dll包含几个基本的类.
其中,DatabaseConfig类表示数据库的配置参数.
DatabaseConfig的子类BTreeDatabaseConfig专门用来配置B树数据库.
BtreeDatabase类表示B树格式存储的数据库,也就是一个排好序的平衡树结构.
DatabaseEntry表示一个数据项.
使用BDBC#API完整的示例代码如下:BTreeDatabaseConfigbtreeDBConfig=newBTreeDatabaseConfig();btreeDBConfig.
Creation=CreatePolicy.
IF_NEEDED;//如果不存在数据库就创建btreeDBConfig.
PageSize=512;//页大小btreeDBConfig.
CacheSize=newCacheInfo(0,64*1024,1);//缓存大小BTreeDatabasebtreeDB=BTreeDatabase.
Open("bdb.
db",btreeDBConfig);Stringurl="www.
lietu.
com";DatabaseEntryk=newDatabaseEntry(ASCIIEncoding.
ASCII.
GetBytes(url));DatabaseEntryv=newDatabaseEntry(BitConverter.
GetBytes((int)1));btreeDB.
Put(k,v);//放入数据KeyValuePairpair=btreeDB.
Get(k);//取得数据System.
Console.
WriteLine(ASCIIEncoding.
ASCII.
GetString(pair.
Key.
Data));btreeDB.
Close();//关闭数据库因为BDB的C#版本要调用C语言的实现,所以部署起来麻烦一点.
Perst是一个全部用C#实现的面向对象的嵌入式数据库系统.
像其他嵌入式数据库一样,Perst没有管理上的代价,但不同的是,Perst直接将对象以C#对象的形式进行存储.
因此,不需要在对象的内部表现形式和C#表现形式之间转换.
项目中直接引用Perst.
NET.
dll.
Perst中操作数据库的代码如下://得到storage的实例Storagedb=StorageFactory.
Instance.
CreateStorage();intpagePoolSize=32*1024*1024;//打开数据库db.
Open("urlSeen.
dbs",pagePoolSize);//操作数据库db.
Close();//关闭数据库需要一个Root对象,代码如下:8181第2章使用C#开发网络爬虫root=(Root)db.
Root;if(root==null){//Root没有定义,也就是storage没有初始化root=newRoot();//创建root对象root.
strIndex=db.
CreateIndex(typeof(String),true);db.
Root=root;}使用Perst实现的URL地址查新方法的代码如下:publicclassRecord:Persistent{publicstringstrKey;}publicclassRoot:Persistent{publicIndexstrIndex;}publicclassUrlSeenDetector{privateStoragedb=null;privateRootroot;privateIndexstrIndex;publicUrlSeenDetector(stringdbName){//初始化数据库db=StorageFactory.
Instance.
CreateStorage();intpagePoolSize=32*1024*1024;db.
Open(dbName,pagePoolSize);root=(Root)db.
Root;if(root==null){root=newRoot();root.
strIndex=db.
CreateIndex(typeof(String),true);db.
Root=root;}strIndex=root.
strIndex;}//如果输入的URL已经见过,则返回truepublicbooldetect(StringnewUrl){Recordrec2=(Record)strIndex[newUrl];//查询if(rec2!
=null){returntrue;}Recordrec=newRecord();rec.
strKey=newUrl;strIndex[rec.
strKey]=rec;returnfalse;82182}publicvoidClose(){if(db!
=null)db.
Close();}}2.
8.
2布隆过滤器判断URL地址是否已经抓取过还可以借助布隆过滤器(BloomFilter).
布隆过滤器的实现方法是:利用内存中的一个长度是m的位数组B,对其中所有位都置0,如图2-13所示.
图2-13位数组B的初始状态然后对每个遍历过的URL根据k个不同的散列函数执行散列,每次散列的结果都是不大于m的一个整数a.
根据散列得到的数在位数组B对应的位上置1,也就是让B[a]=1.
图2-14显示了放入3个URL后位数组B的状态,这里k=3.
图2-14放入数据后位数组B的状态每次插入一个URL,也执行k次散列,只有当全部位都已经置1才认为这个URL已经遍历过.
BloomFilter(http://bloomfilter.
codeplex.
com/)实现了布隆过滤器.
下面是使用布隆过滤器(Filter)的一个例子,其代码如下://创建一个布隆过滤器,优化成包含10000个项目intcapacity=10000;//we'llactuallyaddonlyoneitemfloaterrorRate=0.
0001F;//0.
01%//最后一个值是空,表示使用默认的散列函数FilterurlSeen=newFilter(capacity,errorRate,null);//增加内容到布隆过滤器urlSeen.
add("www.
lietu.
com");urlSeen.
add("www.
sina.
com");urlSeen.
add("www.
qq.
com");urlSeen.
add("www.
sohu.
com");//测试布隆过滤器是否记得这个项目if(urlSeen.
Contains("www.
lietu.
com")){8383第2章使用C#开发网络爬虫System.
Console.
WriteLine("可能已经存在");}else{System.
Console.
WriteLine("一定不存在");}布隆过滤器如果返回不包含某个项目,那肯定就是没往里面增加过这个项目,如果返回包含某个项目,但其实可能没有增加过这个项目,所以有误判的可能.
对爬虫来说,使用布隆过滤器的后果是可能导致漏抓网页.
如果想知道需要使用多少位才能降低错误概率,可以从表2-4所列的存储项目和位数比率估计布隆过滤器的误判率.
表2-4布隆过滤器误判率表比率(items:bits)误判率1∶10.
632120558828561∶20.
399576400893731∶40.
146891597660381∶80.
021577141463221∶160.
000465573033721∶320.
000000211673401∶640.
00000000000004为每个URL分配两个字节就可以达到千分之几的冲突.
例如,一个比较保守的实现,为每个URL分配了4个字节,项目和位数比是1∶32,误判率是0.
00000021167340.
对于5000万数量级的URL,布隆过滤器只占用了200MB的空间,并且排重速度超快,一遍下来不到两分钟.
Filter类中实现的把对象映射到位集合的方法的代码如下://////增加一个新项目到布隆过滤器.
不能再删除这个项目//////publicvoidAdd(Titem){//开始为每个项目的散列位翻转位intprimaryHash=item.
GetHashCode();intsecondaryHash=getHashSecondary(item);for(inti=0;i///检查项目是否在布隆过滤器中84184/////////publicboolContains(Titem){intprimaryHash=item.
GetHashCode();intsecondaryHash=getHashSecondary(item);for(inti=0;i_rssItems=newCollection();}首先看一下其中的GetFeed()方法.
这个方法返回一个Rss.
Items的集合.
这个类使用XMLReader读入XML.
XMLDocument表示一个XML文档.
尽管XmlReader只是一个抽象类,有一些XmlReader类的具体实现,如XmlTextReader、XmlNodeReader和XmlValidatingReader类,但是建议使用Create方法创建XmlReader实例.
其代码如下://检索远程的Feed并解析它publicCollectionGetFeed(){//开始解析过程using(XmlReaderreader=XmlReader.
Create(Url)){8585第2章使用C#开发网络爬虫XmlDocumentxmlDoc=newXmlDocument();xmlDoc.
Load(reader);//解析Feed的项目ParseDocElements(xmlDoc.
SelectSingleNode("//channel"),"title",ref_feedTitle);ParseDocElements(xmlDoc.
SelectSingleNode("//channel"),"description",ref_feedDescription);ParseRssItems(xmlDoc);//返回Feed项目return_rssItems;}}用ParseDocElements方法创建一个新的Rss.
Items集合对象,然后解析返回的XML,增加集合中的项目.
其代码如下://为了检索RSS项目,解析xml文档privatevoidParseRssItems(XmlDocumentxmlDoc){_rssItems.
Clear();XmlNodeListnodes=xmlDoc.
SelectNodes("rss/channel/item");foreach(XmlNodenodeinnodes){Rss.
Itemsitem=newRss.
Items();ParseDocElements(node,"title",refitem.
Title);ParseDocElements(node,"description",refitem.
Description);ParseDocElements(node,"link",refitem.
Link);stringdate=null;ParseDocElements(node,"pubDate",refdate);DateTime.
TryParse(date,outitem.
Date);_rssItems.
Add(item);}}ParseDocElements方法调用ParseDocElements,这里检查每个XmlNode,看它是否包含Feed的属性,其代码如下.
//用指定的Xpath查询解析XmlNode//并分配值给property参数privatevoidParseDocElements(XmlNodeparent,stringxPath,refstringproperty){XmlNodenode=parent.
SelectSingleNode(xPath);if(node!
=null)property=node.
InnerText;elseproperty="Unresolvable";}86186Rss.
Items是一个结构,用来保存Feed中的项目,其代码如下:publicclassRss{///保存RSS的Feed项目的结构[Serializable]publicstructItems{//发布日期publicDateTimeDate;//feed的标题publicstringTitle;//内容的描述publicstringDescription;//Feed的链接publicstringLink;}}2.
10解析相对地址在Windows的控制台窗口中,可以根据当前路径的相对路径转移到一个路径,如cd.
.
转移到当前路径的上级路径.
在HTML网页中也经常使用相对URL.
绝对URL就是不依赖其他的URL路径,如http://www.
lietu.
com/index.
jsp.
在一定的上下文环境下可以使用相对URL.
网页中的URL地址可能是相对地址,如.
/index.
html.
可以在和标签中使用相对URL.
例如:可以根据所在网页的绝对URL地址,把相对地址转换成绝对地址.
为了灵活地引用网站内部资源,相对路径在网页中很常见.
爬虫为了后续处理方便,需要把相对地址转化为绝对地址.
在C#中,可以用System.
Uri类表示一个URL地址.
下面的代码把相对地址转换成绝对地址:UribaseUri=newUri("http://my.
server.
com/folder/directory/sample");//把第二个参数中的相对地址转换成绝对地址UriabsoluteUri=newUri(baseUri,".
.
/.
.
/other/path");2.
11网页更新经常有人会问:"有没有什么新消息"这说明人的大脑是增量获取信息的,对爬虫来说也是如此.
网站中的内容经常会变化,这些变化经常在网站首页或者目录页有反映.
为了提高采集效率,往往考虑增量采集网页.
可以把这个问题看成是被采集的Web服务器8787第2章使用C#开发网络爬虫和存储库同步的问题.
更新网页内容的基本原理是:下载网页时,记录网页下载的时间,增量采集这个网页时,判断URL地址对应的网页是否有更新.
HTTP1.
1声明支持一种特殊类型的HTTPGet,叫做HTTP条件Get.
如果文件在某个条件下没有修改,则HTTP条件Get不下载这个网页.
判断网页是否修改的方法包括If-Modified-Since、If-Unmodified-Since、If-Match、If-None-Match或者If-Range头信息.
爬虫发送条件GET请求的情况如下:GET/HTTP/1.
1Host:www.
lietu.
com.
cn:80If-Modified-Since:Thu,4Feb201020:39:13GMTConnection:Close当没有更新时服务器的响应如下:HTTP/1.
0304NotModifiedDate:Thu,04Feb201012:38:41GMTContent-Type:text/htmlExpires:Thu,04Feb201012:39:41GMTLast-Modified:Thu,04Feb201012:29:04GMTAge:28Connection:close如果服务器网页已经更新,就会把客户端的请求当作一个普通的Get请求发送网页内容:HTTP/1.
0200OKDate:Thu,04Feb201012:49:46GMTServer:ApacheLast-Modified:Thu,04Feb201012:49:05GMTAccept-Ranges:bytesCache-Control:max-age=60Expires:Thu,04Feb201012:50:46GMTVary:Accept-EncodingX-UA-Compatible:IE=EmulateIE7Content-Length:452785Content-Type:text/htmlAge:11Connection:close网页内容.
条件下载命令可以根据时间条件下载网页.
再次请求已经抓取过的页面时,爬虫往Web服务器发送If-Modified-Since请求头,其中包含的时间是先前服务器端发过来的Last-Modified最后修改时间戳.
这样让Web服务器端进行验证,通过这个时间戳判断爬虫上次抓过的页面是否有修改.
如果有修改,则返回HTTP状态码200和新的内容.
如果没有变化,则只返回HTTP状态码304,告诉爬虫页面没有变化.
这样可以大大减少在网络上传输的数据,同时也减轻了被抓取的服务器的负担.
看一下HTTP的Get代码例子.
存储HttpWebRequest的GetResponse方法返回的88188HttpWebResponse对象中的ETag和最后修改日期,其代码如下:HttpWebRequestrequest=(HttpWebRequest)HttpWebRequest.
Create(Uri);request.
Method="GET";HttpWebResponseresponse=(HttpWebResponse)request.
GetResponse();//存储要在HTTP的条件GET中使用的ETag和网页的最后修改日期stringeTag=response.
Headers[HttpResponseHeader.
ETag];stringifModifiedSince=response.
Headers[HttpResponseHeader.
LastModified];注意:对最后修改时间,最好存储原字符串.
因为不同的Web服务器用的日期字符串格式可能不一样.
看一下HTTP条件Get的代码例子,在取得HTTP响应前,它使用Etag去设置If-None-Match头域信息,并且使用最后修改时间去设置If-Modified-Since头域信息.
如果网页没有修改,HttpWebReponse类会抛出一个System.
Net.
WebException异常并且设置StatusCode成NotModified,因此要捕获这个异常并且检查StatusCode.
其代码如下:try{HttpWebRequestrequest=(HttpWebRequest)HttpWebRequest.
Create(Uri);request.
Method="GET";//使用刚保存的ETag设置IfNoneMatchrequest.
Headers[HttpRequestHeader.
IfNoneMatch]=eTag;//使用刚保存的最后修改日期设置IfModifiedSincerequest.
IfModifiedSince=ifModifiedSince;request.
Credentials=newNetworkCredential(userName,password);HttpWebResponseresponse=(HttpWebResponse)request.
GetResponse();//下载Streamstrm=response.
GetResponseStream();//Inputstream//OutputstreamFileStreamfs=newFileStream(outputFile,FileMode.
Create,FileAccess.
Write,FileShare.
None);constintArrSize=10000;Byte[]barr=newByte[ArrSize];while(true){intResult=strm.
Read(barr,0,ArrSize);if(Result==-1||Result==0)break;fs.
Write(barr,0,Result);}fs.
Flush();fs.
Close();strm.
Close();response.
Close();//下载结束}catch(System.
Net.
WebExceptionex){8989第2章使用C#开发网络爬虫if(ex.
Response!
=null){using(HttpWebResponseresponse=ex.
ResponseasHttpWebResponse){if(response.
StatusCode==HttpStatusCode.
NotModified){Console.
WriteLine("文件没有更新");return;}elseConsole.
WriteLine(string.
Format("返回意外的状态码{0}",response.
StatusCode));}}}可以用Range条件下载部分网页.
比如:某网页的大小是1000B,爬虫请求这个网页时用"Range:bytes=0-500",那么Web服务器应该把这个网页开头的501B发回给爬虫.
2.
12信息过滤有时候可能需要按一个关键词列表来过滤信息,如过滤黄色或其他非法信息.
调用indexOf方法来查找关键词集合效率不高,Aho-Corasick算法可以用来在文本中搜索多个关键词.
当有一个关键词的集合,想发现文本中的所有出现关键词的位置,或者检查是否有关键词集合中的任何关键词出现在文本中时,这个实现代码是有用的.
有很多不经常改变的关键词时,可以使用Aho-Corasick算法.
其运行时间是输入文本的长度加上匹配关键词数目的线性和.
Aho-Corasick算法用发明人AlfredV.
Aho和MargaretJ.
Corasick名字命名的.
Aho-Corasick把所有要查找的关键词构建成一个Trie树.
Trie树包含像后缀树一样的链接集合,从代表字符串的每个节点(如abc)到最长的后缀(例如,如果词典中存在bc,则链接到bc,否则如果词典中存在c,则链接到c,否则链接到根节点).
每个节点的失败(failure)匹配属性存储这个最长后缀节点.
也就是说,还包含一个从每个节点到存在于词典中的最长后缀节点链接.
假设词典中存在a、ab、bc、bca、c、caa词,这6个词组成如图2-15所示的Trie树结构.
由指定的字典构造的Aho-Corasick算法的数据结构如表2-5所列,表里面的每一行代表树中的一个节点,表里的列路径用从根到节点的唯一字符序列说明.
每取一个待匹配的字符后,当前的节点通过寻找它的孩子来匹配,如果孩子不存在,也就是匹配失败,则试图匹配该节点后缀的孩子,如果这样也没有匹配上,则匹配该节点后缀的后缀的孩子,最后如果什么也没有匹配上,就在根节点结束.
分析输入字符串"abccab"的匹配过程如表2-6所示.
90190图2-15Trie树结构表2-5Trie树的结构路径是否在字典里后缀链接词典后缀链接()否(a)是()(ab)是(b)(b)否()(bc)是(c)(c)(bca)是(ca)(a)(c)是()(ca)否(a)(a)(caa)是(a)(a)表2-6Aho-Corasick算法匹配过程节点剩余的字符串输出:结束位置跳转输出()abccab从根节点开始(a)bccaba:1从根节点()转移到孩子节点(a)当前节点(ab)ccabab:2节点(a)转移到孩子节点(ab)当前节点(bc)cabbc:3,c:3节点(ab)转到后缀(b),再跳转到孩子节点(bc)当前节点,词典后缀节点9191第2章使用C#开发网络爬虫续表节点剩余的字符串输出:结束位置跳转输出(c)abc:4节点(bc)转到后缀节点(c),再跳转到根节点(),再跳转到孩子节点(c)当前节点(ca)ba:5节点(c)跳转到孩子节点(ca)词典后缀节点(ab)ab:6节点(ca)跳转到后缀节点(a),再跳转到孩子节点(ab)当前节点首先定义Trie树节点类,其代码如下://////表示字符和它的转换和失败方法的树节点///classTreeNode{#region构造&方法//////使用特定的字符初始化树节点//////父亲节点///字符publicTreeNode(TreeNodeparent,charc){_char=c;_parent=parent;_results=newArrayList();_resultsAr=newstring[]{};_transitionsAr=newTreeNode[]{};_transHash=newHashtable();}//////增加在这个节点结束的模式//////模式publicvoidAddResult(stringresult){if(_results.
Contains(result))return;_results.
Add(result);_resultsAr=(string[])_results.
ToArray(typeof(string));}//////增加转换节点//////NodepublicvoidAddTransition(TreeNodenode){92192_transHash.
Add(node.
Char,node);TreeNode[]ar=newTreeNode[_transHash.
Values.
Count];_transHash.
Values.
CopyTo(ar,0);_transitionsAr=ar;}//////返回到给定字符的转换(如果存在的话)//////字符///返回TreeNode或者nullpublicTreeNodeGetTransition(charc){return(TreeNode)_transHash[c];}//////如果节点包括到指定字符的转换,则返回true//////Character///如果转换存在则返回TruepublicboolContainsTransition(charc){returnGetTransition(c)!
=null;}#endregion#regionPropertiesprivatechar_char;privateTreeNode_parent;privateTreeNode_failure;privateArrayList_results;privateTreeNode[]_transitionsAr;privatestring[]_resultsAr;privateHashtable_transHash;//////分隔字符///publiccharChar{get{return_char;}}//////父亲树节点///9393第2章使用C#开发网络爬虫publicTreeNodeParent{get{return_parent;}}//////失败方法–后代节点///publicTreeNodeFailure{get{return_failure;}set{_failure=value;}}//////转换方法–后代节点的列表///publicTreeNode[]Transitions{get{return_transitionsAr;}}//////返回一个以这个字符结束的模式的数组///publicstring[]Results{get{return_resultsAr;}}#endregion}查找输入文本是否包含关键词集合中的任何词,其代码如下://////查询传入的字符串,如果包含任何关键词,则返回true//////Texttosearch///当字符串包含任何关键词,则返回truepublicboolContainsAny(stringtext){TreeNodeptr=_root;intindex=0;while(index0)returntrue;index++;}returnfalse;}2.
13垂直行业抓取从首页提取类别信息,然后按类别信息找到目录页.
通过翻页遍历所有的目录页,提取详细页.
从详细页面提取商品信息.
把商品信息存入数据库.
以新浪新闻为例,同一个目录下的URL是:http://roll.
news.
sina.
com.
cn/news/gjxw/hqqw/index.
shtmlhttp://roll.
news.
sina.
com.
cn/news/gjxw/hqqw/index_2.
shtmlhttp://roll.
news.
sina.
com.
cn/news/gjxw/hqqw/index_3.
shtml以购物网站为例,同一个目录下的URL是:http://www.
mcmelectronics.
com/browse/Cameras/0000000002http://www.
mcmelectronics.
com/browse/Cameras/0000000002/p/2http://www.
mcmelectronics.
com/browse/Cameras/0000000002/p/3http://www.
mcmelectronics.
com/browse/Cameras/0000000002/p/4不断增加翻页参数,一直到找不到新的商品为止.
很多网页的下一页链接是由JavaScript函数生成的,比如:2需要用WebBrowser控件提取其中的链接.
2.
14抓取限制应对方法对爬虫不友好的网站有各种各样的限制抓取的方法,所以爬虫应对的方法也不同.
从原理上来说,只要浏览器可以访问,爬虫应该也可以访问.
2.
14.
1更换IP地址有些网站对于同一个IP地址在一段时间内的访问次数有限制.
可以使用Socket代理来更改请求的IP地址.
这时可以通过大量不同的Socket代理循环访问网站.
WebRequest中可以指定代理服务器,代码如下:WebProxyproxyObject=newWebProxy("http://proxyserver:80/",true);WebRequestreq=WebRequest.
Create("http://www.
lietu.
com");req.
Proxy=proxyObject;9595第2章使用C#开发网络爬虫去某网站上抓取数据时,每隔几分钟换不同代理访问该网站.
每次抓的时候看一下当前代理开始启用的时间有没有过期.
如果已经过期就换新的代理,同时记录新的时间,其代码如下:privatestaticDateTimeLastCheckTime=DateTime.
Now;//记录下当前代理开始启用的时间WebProxyproxyObject=newWebProxy("http://currentIP:80/",true);//如果超过10分钟就换IPif(LastCheckTime.
AddMinutes(10)-1){//登录成功Console.
WriteLine("断开登录成功");}else{Console.
WriteLine("断开登录失败");}}}使用办公区的机器抓取数据后,可以把数据提交到统一的存储服务器.
这样抓取数据的机器对于存储服务器来说就是客户端,而存储的机器一般位于机房,是服务器端.
- 爬虫ie脚本错误相关文档
- "辽宁省网上税务局—网上申报缴税模块常见问题汇总",,,
- 上杭县政府网站信息公开及政务服务平台专栏
- 希赛网(www.educity.cn),专注软考、PMP、通信考试
- 点击ie脚本错误
- 证书ie脚本错误
- 申报ie脚本错误
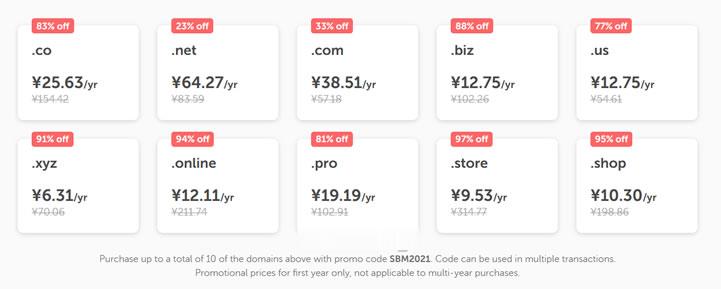
NameCheap优惠活动 新注册域名38元
今天上午有网友在群里聊到是不是有新注册域名的海外域名商家的优惠活动。如果我们并非一定要在国外注册域名的话,最近年中促销期间,国内的服务商优惠力度还是比较大的,以前我们可能较多选择海外域名商家注册域名在于海外商家便宜,如今这几年国内的商家价格也不贵的。比如在前一段时间有分享到几个商家的年中活动:1、DNSPOD域名欢购活动 - 提供域名抢购活动、DNS解析折扣、SSL证书活动2、难得再次关注新网商家...
恒创新客(317元)香港云服务器 2M带宽 三网CN2线路直连
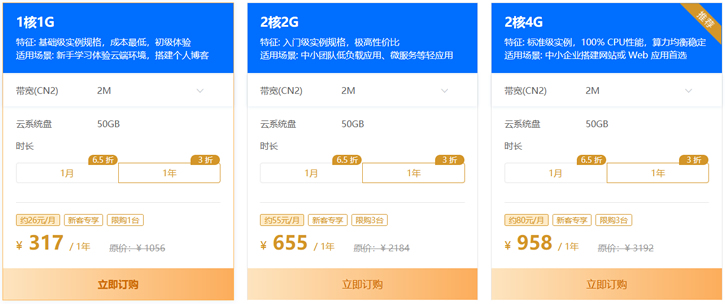
恒创科技也有暑期的活动,其中香港服务器也有一定折扣,当然是针对新用户的,如果我们还没有注册过或者可以有办法注册到新用户的,可以买他们家的香港服务器活动价格,2M带宽香港云服务器317元。对于一般用途还是够用的。 活动链接:恒创暑期活动爆款活动均是针对新用户的。1、云服务器仅限首次购买恒创科技产品的新用户。1 核 1G 实例规格,单个账户限购 1台;其他活动机型,单个账户限购 3 台(必须在一个订单...
Webhosting24:$1.48/月起,日本东京NTT直连/AMD Ryzen 高性能VPS/美国洛杉矶5950X平台大流量VPS/1Gbps端口/
Webhosting24宣布自7月1日起开始对日本机房的VPS进行NVMe和流量大升级,几乎是翻倍了硬盘和流量,价格依旧不变。目前来看,日本VPS国内过去走的是NTT直连,服务器托管机房应该是CDN77*(也就是datapacket.com),加上高性能平台(AMD Ryzen 9 3900X+NVMe),还是有相当大的性价比的。此外在6月30日,又新增了洛杉矶机房,CPU为AMD Ryzen 9...

ie脚本错误为你推荐
-
百度k站百度k站的原因是什么cornerradiusUG后处理可以输出自定义刀具描述吗?flash导航条如何制作flash导航条微信如何建群微信可以建立两个人的群吗?有一个是自己安卓应用平台哪个手机应用平台的软件比较正版,安全?硬盘人电脑对人有多大辐射?人人逛街为什么女人都喜欢逛街?谢谢了,大神帮忙啊免费免费建站电脑上有真正免费的网站吗??idc前线穿越火线河北的服务器好卡 有人知道怎么回事嘛 知道的速回iphone6上市时间苹果6什么时候出?