检索相关搜索
相关搜索 时间:2021-02-22 阅读:()
第58卷第15期2014年8月基于特征项的文献共现网络在学术信息检索中的应用丁洁王曰芬[摘要]在综合国内学术信息检索服务的现状和现有理论方法研究的基础上,以检索词推荐为研究对象,构建基于文献特征项共现网络的学术信息检索词推荐模型.
模型包括基础文献存储模块、文献特征项抽取模块、文献特征项共现网络预处理模块、基于特征项的文献检索模块及检索词服务前端5个部分.
利用实验验证基于特征项的共现网络用于检索词推荐的可行性,结果表明推荐模型结果与各检索项的检索词更具有相关性,推荐质量较好.
[关键词]检索词推荐推荐模型共现分析学术信息检索科技文献[分类号]G350DOI:10.
13266/j.
issn.
0252-3116.
2014.
15.
020本文系国家自然科学基金资助项目"新研究领域科学文献传播网络成长及对传播效果影响研究"(项目编号:71373124)研究成果之一.
[作者简介]丁洁,南京理工大学经济管理学院硕士研究生;王曰芬,南京理工大学经济管理学院教授,博士生导师,通讯作者,Email:yuefen163@163.
com.
收稿日期:2014-05-19修回日期:2014-07-06本文起止页码:135-141本文责任编辑:徐健1引言在以超海量信息有序存储和组织为特征的学术信息检索环境中,"信息过载"、"知识泛滥"、"知识迷航"等问题不断出现.
一方面,自然语言和计算机系统在解析语意上存在着巨大差异,人机交互过程中可能会出现不可避免的语义偏差;另一方面,在学术信息检索环境中,用户往往需要获取当前检索项相关的其他研究信息,进一步拓展和完善检索需求[1].
因此,近年来对于提高学术信息检索词推荐效率的研究越来越受到重视,相关学者从检索文档库及检索日志入手,利用同义词识别、本体构建、共现分析、关联规则及协同过滤等不断提出及修正各种检索词推荐的方法.
目前主流的学术信息检索途径包括数字图书馆、商业数据库及开放存取等.
本文采用典型调查法,以国内较为常用的9个学术信息检索网站(分别为国家数字图书馆、国家科技图书文献中心、中国高等教育数字图书馆、中国科技论文在线、中国知网CNKI、万方数据知识服务平台、中国科学院文献情报中心、中国社会科学院系统数字图书馆、维普仓储式在线出版平台.
其中后三者不提供检索词推荐服务)为调查对象,对其提供的检索词推荐服务进行统计,结果显示仅有66.
7%的学术检索网站提供聚类浏览导航和"相关搜索"推荐来帮助用户进行检索词拓展及优化.
那么,如何更好地利用用户实时的检索信息及文献特征项的语义关联共现,为用户提供更为学术性和专业性的检索词推荐服务将具有重要的研究价值.
在对国内学术信息检索服务的现状和现有的理论方法进行研究的基础上,本文以检索词推荐的"相关搜索"推荐服务为研究对象,探索构建基于文献特征项共现网络的学术信息检索词推荐模型,并以实验验证模型应用于检索词推荐的可行性.
2国内学术信息检索词推荐服务现状由于目前学术信息检索的数据还大多来自CNKI、万方、维普等商业数据库,且仅有商业数据库提供较为完善的检索词推荐服务,故表1中具体以CNKI及万方中的"相关检索"推荐服务为研究对象(维普暂不提供),分别以较为常用且一般可作为单独检索项的主题、篇名、关键词、作者、单位、期刊、ISSN、CN、摘要、全文及参考文献为检索入口,以"知识构建"、"姜永常"等检索词为例,对CNKI及万方提供的检索词推荐内容汇总如下:(1)从CNKI提供的推荐结果来看,其主要分为3种类型:主题相关性的检索词推荐(主题、篇名、关键词、摘要、全文、参考文献入口)、文本相似性的检索词推荐(作者、ISSN、CN、中图分类号入口)及混合方式的检索词推荐(单位、期刊、基金入口).
从检索入口类别区分,具体体现在以下3个方面:通过主题、篇名、关键词、摘要、全文及参考文531丁洁,王曰芬.
基于特征项的文献共现网络在学术信息检索中的应用献特征项进行检索时,检索推荐项内容完全相同,且系统主要基于与检索词的主题相关性来进行推荐.
表1CNKI及万方检索推荐结果统计TOP10检索入口检索词CNKI检索推荐结果万方检索推荐结果主题知识构建构建知识/政策构建/组织构建/法律构建/构建措施/信息构建/知识管理/知识共享/知识组织/知识管理知识构建/知识服务/图书馆/信息构建/知识管理/数字图书馆/知识/知识节点/知识生态/过程模型篇名知识构建同上知识构建/知识服务/信息构建/图书馆/知识/数字图书馆/本体/知识网络/知识管理/知识结构关键词知识构建同上知识构建/知识服务/信息构建/数字图书馆/知识管理/图书馆/知识元/大学英语/知识空间/知识网络摘要知识构建同上知识构建/知识服务/图书馆/信息构建/知识管理/数字图书馆/知识/知识网络/过程模型/知识生态全文知识构建同上知识构建/知识服务/图书馆/知识管理/信息构建/数字图书馆/知识网络/知识/网站建设/知识创新参考文献知识构建同上没有此检索项作者姜永常姜片/白姜/菜姜/加姜/姜酒/姜末/姜尚/姜属/姜西/山姜知识构建/知识服务/图书馆/知识网络/知识管理/知识元/知识创新/知识产业/知识经济/知识网格ISSN0252-3116没有推荐结果没有该检索项CN11-1541/G2没有推荐结果没有该检索项中图分类号G350350/350MW/350兆频率/350MHz警用/350MW机组/Φ350/P350/H.
350/R-350/350兆没有该检索项单位哈尔滨商业大学图书馆自然科学版/学术研讨会/开发与利用/经济发展/高校图书馆/高层论坛/地方经济/~~/总目次/综合性学术期刊图书馆/知识管理/高校图书馆/知识服务/知识构建/数字图书馆/知识网络/知识元/创新/知识空间期刊图书情报工作图书馆学情报学/中国科学院文献情报中心/中国图书馆学会/图书情报学/数字图书馆/专业图书馆/图书情报事业/中国科学院/科学图书馆/图书情报没有返回结果基金国家自然科学基金国家顶研基金/国家军标基金/国家天元基金/国家社科部基金/国家白然科学基金/资助项目/基础研究/面上项目/国家自然科学基金委员会/重点项目没有该检索项注:万方提供的检索推荐项基于当前页的高频关键词统计,以上为相关性排序的第一页推荐;中图分类号为《中国图书馆分类法》分类号之简称.
通过作者、ISSN、CN及中图分类号特征项进行检索时,系统主要基于文本的相似程度进行推荐.
如在作者特征项检索"姜永常"时,系统提供的推荐检索结果为文本相似的"姜片"、"白姜"等;通过单位、期刊及基金特征项进行检索时,系统推荐结果中主题相似项及文本相似项均存在,本文界定为混合方式的检索词推荐.
如在基金特征项检索"国家自然科学基金"时,会出现"国家社科部基金"、"资助项目"等主题相关推荐项,也出现了"国家白然科学基金"等文本相似性推荐项.
(2)从万方提供的推荐结果来看,推荐检索词均为主题相关性的检索词推荐,是对当前返回结果的高频关键词统计.
从检索入口类别区分,具体体现在以下2个方面:通过主题、篇名、关键词、摘要、全文及参考文献特征项进行检索时,返回结果与检索词的主题具有较强的相关性,推荐结果的准确性很高.
通过作者、单位、期刊特征项进行检索时,返回结果仍为检索文献的高频关键词统计,无法与当前入口的检索特征项类别对应,推荐结果的准确性较低.
3有关学术信息检索词推荐方法的研究推荐所依据的基本原理是数据挖掘理论[2].
目前检索词推荐最广泛的应用是在电子商务及搜索引擎领域.
学术信息检索词推荐的实现方法可分为基于检索文档库及基于检索日志两种方式.
3.
1基于检索文档库的检索词推荐目前主要利用同义词或相关词识别、本体及共现网络3种方式实现.
同义词或相关词识别主要基于句法结构[3]、模式匹配[4]或采用词典语料(如wikipedia[5])实现,自动识别和挖掘与检索词相关联的其他关键词,但是由于知识表示方式的复杂性,其适用性受到一定的限制.
基于本体的检索词推荐主要利用本体的推理机制实现[6-7],准确率较高,但由于本体一般是在领域专家的帮助下人工构建,适用性也受到了一定的限制.
基于共现网络的检索词推荐利用词对的共现关系描述词与词之间的相关性[8-9],推荐词来源于文献本身,推荐结果更具专业性,相比检索日志推荐更适用于以知识性及学术性为重要特征的学术信息检索环境,但也存在着计算复631第58卷第15期2014年8月杂、反应慢以及文献格式限定的缺陷.
3.
2基于检索日志的检索词推荐目前主要应用于搜索引擎及电子商务领域的推荐系统,更侧重用户的搜索行为本身,具体包括基于内容、关联规则及协同过滤3种方式.
基于内容的过滤方式主要依据信息与用户在过去选择项目特点的相似性来进行推荐[10],内容提取能力有限.
基于关联规则的过滤主要依据传统及改进的关联规则算法(如Apriori[11]、AprioriTid[12]等)、挖掘项集(itemset)中的强关联规则建立推荐模型,再依据推荐模型和用户的操作行为向用户产生推荐[13].
协同过滤推荐技术在个性化推荐系统中应用最广,包括基于用户及基于项目两类过滤方式[14].
众多研究人员也提出了基于传统的协同过滤算法改进,具体体现在与聚类、关联规则、贝叶斯、云模型、神经网络/免疫系统、维数简化以及对等网技术的结合[15].
通过综合检索词推荐服务现状和现有的理论方法研究可以发现,目前国内学术信息检索在作者、单位、期刊、中图分类号及基金等非主题相关性特征项的检索词推荐服务中,无法获取与检索入口匹配、与检索词直接相关的检索词推荐结果;同时,基于共现网络的检索词推荐大多还局限于关键词或主题词数据,需要继续拓展到其他能够表征文献特性的数据中.
因此,本文尝试进一步拓展及完善现有的检索词推荐方法体系,改进传统的基于共现网络的推荐方法,构建能够实现推荐词类别与检索特征项类别的一致性且具有高推荐效率的检索词推荐模型.
4基于文献特征项共现网络的学术信息检索词推荐模型4.
1文献特征项元素集合数字化学术资源中的文献检索是基于对文献内容特征项及外部特征项的详细标引的.
本文参考文献[16]中的文献特征项类别,同时借鉴现有学术信息检索中提供的检索项及统计项,对文献的特征项元素进行总结,如表2所示:表2文献特征项元素集合主体特征项类别特征项元素文献与相关性有关的内容特征项题名(TI)、摘要(AB)、关键词(KW)、学科类别(SC)、全文(FT)、参考文献(RF)与权威性有关的外部特征项作者(AU)、作者所属单位(IN)、来源期刊(PU、ISSN、CN)、发表时间(TM)、基金资助情况(FU)、研究层次(LE)、中图分类号(CLC)、被引频次(CI)、下载频次(DL)如果将一篇科学文献的内容特征与外部特征提取出来,可以发现科学文献是由一系列特征要素构成的集合.
本文假设该集合可以表达为:F(i)={TIia,ABib,KWic,SXi,FTid,RFic,AUif,INif,PUi,ISSNi,CNi,TMi,LEi,CLCi,CIi,DLi}(1)目前可提供检索的常用特征项包括主题(TI+AB+KW)、篇名(TI)、关键词(KW)、作者(AU)、单位(IN)、期刊(PU)、ISSN、CN、期、基金(FU)、摘要(AB)、全文(FT)、参考文献(RF)和中图分类号(CLC)等.
当用户使用ISSN和CN特征项进行检索时,可以先预置换为期刊,再进行检索推荐;用户一般不使用期及基金作为第一检索特征项;且使用参考文献作为检索项时,推荐内容一般基于检索词进行主题推荐.
因此,本文进一步简化F(i)表达式,略去ISSN、CN、期及参考文献特征项,F′(i)具体表达如下:F′(i)={TIia,ABib,KWic,FTid,AUif,INif,PUi,CLCi}(2)4.
2基于特征项的文献共现网络的形成4.
2.
1TI、AB及FT共现网络篇名(TI)、摘要(AB)及全文(FT)经由数据预切分处理后,可获取一系列表达文献主题的知识元项.
知识元项共同在篇名、摘要及全文中出现在一定程度上可表征知识元之间主题相关.
由于TI、AB,尤其是FT简单切分后的知识元及知识元共现频次较高,且可能存在很多文本主题不相关的高频词语,因此本文借鉴文献[17]基于向量空间模型和TFIDF方法对TI、AB及FT信息预先进行分词、权重计算及知识元抽取,并统计抽取后的各知识元出现频次及关联度.
本文假定基于TI、AB及FT的共现网络,分别以TI、AB及FT中预处理后的知识元为节点,以各知识元共现的关联度作为描述共现联系紧密性的指标.
4.
2.
2KW、AU、IN及CLC共现网络关键词(KW)、作者(AU)、单位(IN)及中图分类号(CLC)的共同特征是由一系列表达文献内外部特征的知识元以"合作"关系构成.
文献中关键词之间往往存在主题相关性,多作者合作及多单位合作能够在一定程度上表明作者及单位之间研究领域的相似性,共同标引文献的分类号之间也存在研究主题的交叉.
本文假定基于KW、AU、IN及CLC的共现网络,分别以其中共现"合作"知识元为节点,以各知识元共现的关联度作为描述共现联系紧密性的指标.
4.
2.
3PU共现网络期刊(PU)的特征是单篇文献中不存在共现合作项,可依据期刊之间的主题相似性731丁洁,王曰芬.
基于特征项的文献共现网络在学术信息检索中的应用构建PU共现网络.
假定期刊A及期刊B的高频主题词依次为A={Ai|i=1,2,3…N}、B={Bj|j=1,2,3…N}.
由4.
2.
1及4.
2.
2,将文献篇名、关键词及摘要进行汇总,可构建基于主题的共现网络.
则期刊A与B的主题相关程度表示如下:QAB=Nj=1Ni=1Sim(Ai,Bj)(3)其中:Sim(Ai,Bj)为Ai主题词与Bj主题词在主题共现网络中的相关程度,主要基于改进的知网语义相似度算法实现[18].
本文假定基于PU的共现网络,以期刊知识元为节点,以期刊高频主题词累计相关程度数值QAB作为描述连线紧密的指标.
4.
3学术信息检索词推荐模型检索词推荐模型由基础文献存储模块、文献特征项抽取模块、文献特征项共现网络预处理模块、基于特征项的文献检索模块及检索词推荐服务前端5个部分组成,具体如图1所示:图1基于文献特征项共现网络的学术信息检索词推荐模型4.
3.
1基础文献存储模块基础文献存储模块主要实现原始文献数据的基础信息存储.
存储字段包括文献ID、TI、AB、FT、AU、IN、CLC及PU信息,可利用学术信息检索平台中现有的文献数据进行存储.
基础文献存储模块是整个模型的原始数据来源,它的稳定和可靠是整个模型正确实施的保证.
4.
3.
2文献特征项抽取模块文献特征项抽取模块主要实现基础文献数据中特征项的单独抽取、分离(或分词)及存储,并分别构建TI、KW等特征项数据库.
其中,TI库、AB库及FT库存储字段包括文献ID及分词后的各知识元;KW库、AU库、IN库及CLC库存储字段包括文献ID及分离合作关系后的各知识元;PU库存储字段包括文献ID及该篇文献所属PU.
文献特征项抽取模块是整个模型的重要组成部分,文献特征项的抽取、分离(或分词)及存储是后期特征项共现网络构建的基础.
这里尤其需要注意的是,依据基础文献数据的特征项进行抽取、分离(或分词)的过程中,TI、KW及AB数据中存在着大量的形如"研究"、"应用"等没有实际语义的噪音词.
因此,本文借鉴齐普夫定律、卢恩假设及帕欧公式[19],依次对各特征项数据库中的分离(或分词)知识元进行词频统计.
依据帕欧公式及必要的人工核查构建基于各特征项的高频无实际语义的噪音词词表,并在各特征项数据库中删除噪音词字段,以获取更为准确的特征项数据.
4.
3.
3文献特征项共现网络预处理模块文献特征项共现网络预处理模块是整个模型的核心部分,在特征项数据库基础上,实现各文献特征项共现网络的构建,同时获取各特征项中知识元的出现频次及关联度.
目前词汇关联度的主要测度方式有Dice指数、余弦指数、Jaccard指数及ChenHsinchun提出的共现算法[20].
其中Jaccard指数能够根据词的共现频率直接反映两个词之间的相似度并且消除部分无意义高频词的消极影响,因此它被广泛用作代表ci和cj两词之间的标准化相关系数,公式如下:Jaccardcoefficient=cijci+cj-cij(4)其中cij是知识元i和知识元j的共现频次,ci、cj分别是词i和词j在数据集中的全部出现频次.
Jaccard指数的取值越高,表明知识元之间的关联度越高.
因此,模型在构建基于各文献特征项知识网络的基础上,利用Jaccard指数测度知识元项的关联度,为基于文献特征项的检索模块提供数据支撑.
4.
3.
4基于特征项的文献检索模块基于特征项的文献检索模块主要实现依据用户检索入口类别差异,在对应特征项共现网络中查询并返回关联度较高的推荐结果.
模块中的匹配推荐算法直接决定推荐词模型的查准率和查全率.
由于在共现网络预处理模块中已实现各知识元项的关联度测度,本模型直接利用当前用户的检索词,在对应类别的特征项共现网络预处理数据中进行查询及处理操作,并输出与当前检索词关831第58卷第15期2014年8月联度较高的知识元作为检索推荐词语.
4.
3.
5检索词推荐服务前端检索词检索服务前端在模型中直接与用户进行交互,主要实现用户的不同特征项入口检索及推荐检索词的返回显示.
用户在初步明确检索需求后,在特定文献特征项的检索入口输入检索词,并等待后台查询及返回与当前检索词相关的词项.
5实验和讨论为了评估上述基于文献特征项共现网络的学术信息检索词推荐模型的可行性,本文利用样本文献数据对检索推荐模型进行验证,并与现有的检索词推荐结果进行对比分析.
5.
1数据来源和处理本文以CNKI、万方及维普为数据来源,剔除部分相同文献数据,共获取1186篇"知识构建"主题的样本文献.
样本文献信息中具体包括文献篇名、摘要、关键词、作者、单位、期刊及中图分类号(由于时间限制,全文FT处理信息量较大,本次实验暂未考虑).
本文按照获取时间顺序,将样本文献数据依次编号1-1186.
由上文,样本文献信息中篇名TI及摘要AB项进行预分词处理,获取相应具体的知识元项.
本文通过Eclipse调用国内中文词切分效果较好的ICTCLA提供的java接口,实现TI及AB项的词语切分,利用哈尔滨工业大学停用词表实现了"的"、"通过"及标题符号等词语的过滤.
并依据CNKI文献分类目录分层抽样,共获取各学科领域9600条文献篇名、关键词及摘要数据,借鉴齐普夫定律、卢恩假设及帕欧公式,实现TI、KW及AB数据中"研究"、"应用"、"影响"、"过程"等噪音词的过滤.
由于ICTCLA仍无法实现基于语义切分,切分效率有限,因此实验在机器切分基础上添加用户词典,并进行了部分数据的人工修正.
目前国内外文献信息共现关系分析的应用软件包括Citespace、NetworkWorkbenchTool、Pajek及Bibexcel等.
对比实验需求及使用难度,本文主要采用Bibexcel软件实现知识共现网络的构建,具体可实现不同文献特征项内各知识元出现的频次统计及Jaccard指数计算.
本文以KW共现网络为例,以表格形式表征,结果见表3.
利用Ucinet软件实现共现网络的可视化,见图2.
其中知识元节点大小及颜色表征该知识元出现频次大小,节点间联系粗细表征知识元之间的Jaccard指数高低.
表3KW知识共现网络表格形式表示(TOP10)KW知识元出现频次KW知识元AKW知识元BJaccard指数知识构建234知识服务知识构建0.
063025知识管理28信息构建知识构建0.
046414建构主义27知识构建知识管理0.
043825本体23课程标准知识构建0.
038462课堂教学21数字图书馆知识构建0.
033613知识服务19教学过程知识构建0.
029289教学模式18课堂教学知识构建0.
028226教师16地理环境知识构建0.
025641教学15学生知识构建0.
024793信息构建14知识构建知识组织0.
021277图2KW知识共现网络的可视化931丁洁,王曰芬.
基于特征项的文献共现网络在学术信息检索中的应用在图2中,KW共现网络中以检索关键词"知识构建"为中心节点,周圈关键词与中间节点及周圈关键词之间均存在不同程度的主题关联,呈现网状交错的共现网络结构.
由于Jaccard指数直接表征知识元项之间的关联度,与"知识构建"之间具有高Jaccard指数的"知识服务"、"信息构建"等将被作为KW项检索推荐结果,其他特征项共现网络亦然.
5.
2结果分析本文仍以表1中涉及的检索入口及相应检索词为例,忽略实验中未加入考虑的FT、RF、ISSN、CN及期等检索项入口,利用本文构建的检索词推荐模型进行检索推荐,推荐结果具体如表4所示:表4基于检索词推荐模型的检索推荐结果TOP10检索入口检索词模型检索推荐结果主题知识构建知识服务/课程标准/信息构建/知识管理/学习能力/数字图书馆/教学过程/新课程/教学方法/实践能力篇名知识构建知识服务/学生/图书馆/信息构建/数字图书馆/高职/本体/知识管理/学科知识体系/初中学段关键词知识构建知识服务/信息构建/知识管理/课程标准/数字图书馆/教学过程/课堂教学/地理环境/学生/知识组织摘要知识构建教学模式/技能/知识服务/课程标准/学习能力/兴趣/教学方法/素质教育/新课程/情境作者姜永常张静/金岩中图分类号G350G20/F270单位哈尔滨商业大学图书馆东北林业大学图书馆期刊图书情报工作图书情报技术/图书馆论坛/情报理论与实践/档案管理/图书馆学研究/图书馆/河南图书馆学刊/情报杂志/情报学报/情报探索将目前数字化学术资源检索提供的检索词推荐结果(见表1)及本文构建的检索词推荐模型结果(见表4)进行对比,发现:(1)通过主题、篇名、关键词及摘要特征项进行检索时,表1中CNKI及万方提供的推荐检索词主题相关度高,但检索入口类别特征无法体现.
表4中的检索推荐结果在保证推荐词主题相关的基础上,充分考虑上述特征项的类别差异性,提供与特征项入口类别一致性的推荐结果.
(2)通过作者、中图分类号、单位及期刊特征项进行检索时,表1中CNKI及万方提供的推荐检索词仍无法体现入口类别特征,且CNKI部分推荐结果依据文本相似性推荐,存在"姜片"、"白姜"等无意义推荐结果.
表4中的检索推荐结果来源于文献特征项的主题或合作共现,能够完全排除出现无意义推荐结果的可能性,更具合理性和可行性.
6结语本文以学术信息检索词推荐为研究对象,通过总结国内学术信息检索服务的现状及现有的理论研究现状,尝试进一步拓展及完善现有的检索词推荐方法体系,构建基于文献特征项共现网络的学术信息检索词推荐模型,最后利用实验验证文献特征项共现网络应用于检索词推荐的可行性.
可得到以下几点结论:(1)国内学术信息检索词推荐服务有待继续改善.
从目前检索词推荐服务存在的问题来看,国内的学术信息检索词推荐服务与国内外检索词推荐理论方法研究之间还存在一定差距.
(2)基于共现网络的检索词推荐不局限于在关键词或主题词数据,其他能够表征文献特性的数据同样适用.
除关键词和主题词之外,篇名知识元、摘要知识元、作者、中图分类号、单位及期刊数据的共现信息同样具有主题相关性,可以充分挖掘其中隐含的关联信息并应用于实践.
(3)实现推荐词类别与检索特征项入口类别的一致性具有重要意义.
特别当用户从作者、分类号、单位及期刊检索项入口进行检索时,在当前类别内语义相关的推荐结果更能够满足用户进一步拓展检索的需求.
基于文献特征项共现网络的检索词推荐模型在提高推荐效果的同时,在模型构建中还存在部分难点尚待解决.
模型中只对部分检索推荐进行了研究,以参考文献、基金等其他特征项作为检索入口的搜索推荐研究尚未开展;基于文献特征项网络的检索词推荐模型还仅限于特征项的单元共现,能够排除部分完全无意义的推荐结果,但特征项之间的多元语义共现还没有得到体现.
以上问题是检索词推荐服务领域研究人员所面临的重大挑战,检索词推荐模型有待进一步修正和完善.
参考文献:[1]张铧予,李广建.
基于文献的语义资源库建设及其在NSTL中的应用[J].
图书情报工作,2012,56(9):18-23.
[2]边鹏,苏玉召.
基于检索日志的检索词推荐研究[J].
图书情报工作,2012,56(9):31-36,41.
041第58卷第15期2014年8月[3]于娟,尹积栋,费庶.
基于句法结构分析的同义词识别方法研究[J].
现代图书情报技术,2013,29(9):35-40.
[4]陆勇,侯汉清.
基于模式匹配的汉语同义词自动识别[J].
情报学报,2006,25(6):720-724.
[5]YangXu,GarethJFJ,WangBin.
Querydependentpseudo-relevancefeedbackbasedonwikipedia[C]//Proceedingsofthe32ndinternationalACMSIGIRconferenceonResearchanddevelopmentininformationretrieval.
NewYork:ACM,2009:59-66.
[6]汪英姿.
基于本体的个性化图书推荐方法研究[J].
现代图书情报技术,2012,(12):72-78.
[7]唐晓玲.
基于本体和协同过滤技术的推荐系统研究[J].
情报科学,2013,31(12):90-94.
[8]黄媛.
基于论文主题词和关键词关系网的检索词拓展研究[J].
科技广场,2011,(1):24-27.
[9]陆伟,张晓娟.
基于主题与用户偏好分析的查询推荐研究[J].
情报学报,2012,31(12):1252-1258.
[10]JiShihao,ZhouKe,LiaoCiya,etal.
Globalrankingbyexploitinguserclicks[C]//Proceedingsofthe32ndinternationalACMSIGIRconferenceonResearchanddevelopmentininformationretrieval.
NewYork:ACM,2009:35-42.
[11]SanjeevR,PriyankaG.
ImplementingimprovedalgorithmoverAPRIORIdaataminingassociationrulealgorithm[J].
InternationalJournalofComputerScienceandTechology,2012,3(1):489-493.
[12]KomalK,SimpleS.
Analysisofassociationrulesminingalgorithms[J].
InternationalJournalofScientificandResearchPublications,2013,3(5):1-4.
[13]刘旭东,葛俊杰.
基于关联规则的个性化推荐在数字图书馆中的应用研究[J].
德州学院学报,2010,26(2):72-75.
[14]边鹏,赵妍,苏玉召.
一种适合检索词推荐的Kmeans算法最佳聚类数确定方法[J].
图书情报工作,2012,56(4):107-111.
[15]奉国和.
协同过滤推荐研究综述[J].
图书情报工作,2011,55(16):126-130.
[16]曹艺.
面向学术影响力评价的网络学术交流中文献的下载与引用研究[D].
南京:南京理工大学,2012.
[17]许文海,温有奎.
一种基于TFIDF方法的中文关键词抽取算法[J].
情报理论与实践,2008(2):298-302.
[18]基于知网的词汇语义相似度计算方法研究[J].
计算机应用研究,2010,27(9):3329-3333.
[19]邱均平.
信息计量学[M].
武汉:武汉大学出版社,2007:132-152.
[20]HsinchunC,AndreaLH,RobinRS.
Internetbrowsingandsearching:Userevaluationsofcategorymapandconceptspacetechniques[J].
JournaloftheAmericanSocietyforInformationScience,1998,49(7):582-603.
TechnologiesandApplicationsofLiteratureCooccurrenceNetworkBasedonCharacteristicTermsinAcademicInformationRetrievalDingJieWangYuefenSchoolofEconomicsandManagement,NanjingUniversityofScience&Technology,Nanjing210094[Abstract]Afteranalyzingthepresentsituationofthedomesticacademicinformationretrievalservicesandresearchstatusathomeandabroad,adigitalacademicinformationquerysuggestionrecommendationmodelbasedoncooccurrenceanalysiswasdeveloped,whichincludesthebasicliteraturesstoragemodule,theliteraturesfeatureitemextractionmodule,theliteraturesfeaturecooccurrencenetworkpreprocessingmodule,theliteraturesearchmodulebasedonfeatureitemandthefrontendofsearchtermservices.
Anexperimentwasdonetoverifythemodel.
Theresearchshowedthattheacademicinformationquerysuggestionrecommendationmodelbasedoncooccurrenceanalysisofliteraturecharacteristictermsachievedbetterrecommendationquality.
[Keywords]querysuggestionrecommendationmodelcooccurrenceanalysisacademicinformationretrieval檶檶檶檶檶檶檶檶檶檶檶檶檶檶檶檶檶檶檶檶檶檶檶檶檶檶檶檶檶檶檶檶檶檶檶檶檶檶檶檶檶檶檶檶檶檶檶檶檶檶檶檶檶檶檶檶檶檶檶檶檶檶檶檶檶檶檶檶檶檶檶檶檶檶檶檶檶檶檶檶檶檶檶檶檶檶檶檶檶檶檶檶檶檶檶檶檶檶檶檶檶檶檶檶檶檶檶檶檶檶殞殞殞殞scientificliterature2014中国机构知识库学术研讨会征文通知机构知识库是促进科技信息开放共享的重要力量,已经被学术界广泛接受并形成普遍共识.
在成功举办第一届中国机构知识库学术研讨会的基础上,为持续交流和共享全国机构知识库的创新发展,中国机构知识库推进工作组联合中国图书馆学会专业图书馆分会、中国图书馆学会高校图书馆分会,定于2014年11月3-6日在福建厦门召开"2014中国机构知识库学术研讨会".
主题是:机构知识库的创新发展.
会议将围绕中文机构知识库的服务、政策、技术等方面的内容进行研究交流与讨论,欢迎各界踊跃投稿.
请登陆以下网址了解详细信息:http://www.
csla.
org.
cn/.
141
模型包括基础文献存储模块、文献特征项抽取模块、文献特征项共现网络预处理模块、基于特征项的文献检索模块及检索词服务前端5个部分.
利用实验验证基于特征项的共现网络用于检索词推荐的可行性,结果表明推荐模型结果与各检索项的检索词更具有相关性,推荐质量较好.
[关键词]检索词推荐推荐模型共现分析学术信息检索科技文献[分类号]G350DOI:10.
13266/j.
issn.
0252-3116.
2014.
15.
020本文系国家自然科学基金资助项目"新研究领域科学文献传播网络成长及对传播效果影响研究"(项目编号:71373124)研究成果之一.
[作者简介]丁洁,南京理工大学经济管理学院硕士研究生;王曰芬,南京理工大学经济管理学院教授,博士生导师,通讯作者,Email:yuefen163@163.
com.
收稿日期:2014-05-19修回日期:2014-07-06本文起止页码:135-141本文责任编辑:徐健1引言在以超海量信息有序存储和组织为特征的学术信息检索环境中,"信息过载"、"知识泛滥"、"知识迷航"等问题不断出现.
一方面,自然语言和计算机系统在解析语意上存在着巨大差异,人机交互过程中可能会出现不可避免的语义偏差;另一方面,在学术信息检索环境中,用户往往需要获取当前检索项相关的其他研究信息,进一步拓展和完善检索需求[1].
因此,近年来对于提高学术信息检索词推荐效率的研究越来越受到重视,相关学者从检索文档库及检索日志入手,利用同义词识别、本体构建、共现分析、关联规则及协同过滤等不断提出及修正各种检索词推荐的方法.
目前主流的学术信息检索途径包括数字图书馆、商业数据库及开放存取等.
本文采用典型调查法,以国内较为常用的9个学术信息检索网站(分别为国家数字图书馆、国家科技图书文献中心、中国高等教育数字图书馆、中国科技论文在线、中国知网CNKI、万方数据知识服务平台、中国科学院文献情报中心、中国社会科学院系统数字图书馆、维普仓储式在线出版平台.
其中后三者不提供检索词推荐服务)为调查对象,对其提供的检索词推荐服务进行统计,结果显示仅有66.
7%的学术检索网站提供聚类浏览导航和"相关搜索"推荐来帮助用户进行检索词拓展及优化.
那么,如何更好地利用用户实时的检索信息及文献特征项的语义关联共现,为用户提供更为学术性和专业性的检索词推荐服务将具有重要的研究价值.
在对国内学术信息检索服务的现状和现有的理论方法进行研究的基础上,本文以检索词推荐的"相关搜索"推荐服务为研究对象,探索构建基于文献特征项共现网络的学术信息检索词推荐模型,并以实验验证模型应用于检索词推荐的可行性.
2国内学术信息检索词推荐服务现状由于目前学术信息检索的数据还大多来自CNKI、万方、维普等商业数据库,且仅有商业数据库提供较为完善的检索词推荐服务,故表1中具体以CNKI及万方中的"相关检索"推荐服务为研究对象(维普暂不提供),分别以较为常用且一般可作为单独检索项的主题、篇名、关键词、作者、单位、期刊、ISSN、CN、摘要、全文及参考文献为检索入口,以"知识构建"、"姜永常"等检索词为例,对CNKI及万方提供的检索词推荐内容汇总如下:(1)从CNKI提供的推荐结果来看,其主要分为3种类型:主题相关性的检索词推荐(主题、篇名、关键词、摘要、全文、参考文献入口)、文本相似性的检索词推荐(作者、ISSN、CN、中图分类号入口)及混合方式的检索词推荐(单位、期刊、基金入口).
从检索入口类别区分,具体体现在以下3个方面:通过主题、篇名、关键词、摘要、全文及参考文531丁洁,王曰芬.
基于特征项的文献共现网络在学术信息检索中的应用献特征项进行检索时,检索推荐项内容完全相同,且系统主要基于与检索词的主题相关性来进行推荐.
表1CNKI及万方检索推荐结果统计TOP10检索入口检索词CNKI检索推荐结果万方检索推荐结果主题知识构建构建知识/政策构建/组织构建/法律构建/构建措施/信息构建/知识管理/知识共享/知识组织/知识管理知识构建/知识服务/图书馆/信息构建/知识管理/数字图书馆/知识/知识节点/知识生态/过程模型篇名知识构建同上知识构建/知识服务/信息构建/图书馆/知识/数字图书馆/本体/知识网络/知识管理/知识结构关键词知识构建同上知识构建/知识服务/信息构建/数字图书馆/知识管理/图书馆/知识元/大学英语/知识空间/知识网络摘要知识构建同上知识构建/知识服务/图书馆/信息构建/知识管理/数字图书馆/知识/知识网络/过程模型/知识生态全文知识构建同上知识构建/知识服务/图书馆/知识管理/信息构建/数字图书馆/知识网络/知识/网站建设/知识创新参考文献知识构建同上没有此检索项作者姜永常姜片/白姜/菜姜/加姜/姜酒/姜末/姜尚/姜属/姜西/山姜知识构建/知识服务/图书馆/知识网络/知识管理/知识元/知识创新/知识产业/知识经济/知识网格ISSN0252-3116没有推荐结果没有该检索项CN11-1541/G2没有推荐结果没有该检索项中图分类号G350350/350MW/350兆频率/350MHz警用/350MW机组/Φ350/P350/H.
350/R-350/350兆没有该检索项单位哈尔滨商业大学图书馆自然科学版/学术研讨会/开发与利用/经济发展/高校图书馆/高层论坛/地方经济/~~/总目次/综合性学术期刊图书馆/知识管理/高校图书馆/知识服务/知识构建/数字图书馆/知识网络/知识元/创新/知识空间期刊图书情报工作图书馆学情报学/中国科学院文献情报中心/中国图书馆学会/图书情报学/数字图书馆/专业图书馆/图书情报事业/中国科学院/科学图书馆/图书情报没有返回结果基金国家自然科学基金国家顶研基金/国家军标基金/国家天元基金/国家社科部基金/国家白然科学基金/资助项目/基础研究/面上项目/国家自然科学基金委员会/重点项目没有该检索项注:万方提供的检索推荐项基于当前页的高频关键词统计,以上为相关性排序的第一页推荐;中图分类号为《中国图书馆分类法》分类号之简称.
通过作者、ISSN、CN及中图分类号特征项进行检索时,系统主要基于文本的相似程度进行推荐.
如在作者特征项检索"姜永常"时,系统提供的推荐检索结果为文本相似的"姜片"、"白姜"等;通过单位、期刊及基金特征项进行检索时,系统推荐结果中主题相似项及文本相似项均存在,本文界定为混合方式的检索词推荐.
如在基金特征项检索"国家自然科学基金"时,会出现"国家社科部基金"、"资助项目"等主题相关推荐项,也出现了"国家白然科学基金"等文本相似性推荐项.
(2)从万方提供的推荐结果来看,推荐检索词均为主题相关性的检索词推荐,是对当前返回结果的高频关键词统计.
从检索入口类别区分,具体体现在以下2个方面:通过主题、篇名、关键词、摘要、全文及参考文献特征项进行检索时,返回结果与检索词的主题具有较强的相关性,推荐结果的准确性很高.
通过作者、单位、期刊特征项进行检索时,返回结果仍为检索文献的高频关键词统计,无法与当前入口的检索特征项类别对应,推荐结果的准确性较低.
3有关学术信息检索词推荐方法的研究推荐所依据的基本原理是数据挖掘理论[2].
目前检索词推荐最广泛的应用是在电子商务及搜索引擎领域.
学术信息检索词推荐的实现方法可分为基于检索文档库及基于检索日志两种方式.
3.
1基于检索文档库的检索词推荐目前主要利用同义词或相关词识别、本体及共现网络3种方式实现.
同义词或相关词识别主要基于句法结构[3]、模式匹配[4]或采用词典语料(如wikipedia[5])实现,自动识别和挖掘与检索词相关联的其他关键词,但是由于知识表示方式的复杂性,其适用性受到一定的限制.
基于本体的检索词推荐主要利用本体的推理机制实现[6-7],准确率较高,但由于本体一般是在领域专家的帮助下人工构建,适用性也受到了一定的限制.
基于共现网络的检索词推荐利用词对的共现关系描述词与词之间的相关性[8-9],推荐词来源于文献本身,推荐结果更具专业性,相比检索日志推荐更适用于以知识性及学术性为重要特征的学术信息检索环境,但也存在着计算复631第58卷第15期2014年8月杂、反应慢以及文献格式限定的缺陷.
3.
2基于检索日志的检索词推荐目前主要应用于搜索引擎及电子商务领域的推荐系统,更侧重用户的搜索行为本身,具体包括基于内容、关联规则及协同过滤3种方式.
基于内容的过滤方式主要依据信息与用户在过去选择项目特点的相似性来进行推荐[10],内容提取能力有限.
基于关联规则的过滤主要依据传统及改进的关联规则算法(如Apriori[11]、AprioriTid[12]等)、挖掘项集(itemset)中的强关联规则建立推荐模型,再依据推荐模型和用户的操作行为向用户产生推荐[13].
协同过滤推荐技术在个性化推荐系统中应用最广,包括基于用户及基于项目两类过滤方式[14].
众多研究人员也提出了基于传统的协同过滤算法改进,具体体现在与聚类、关联规则、贝叶斯、云模型、神经网络/免疫系统、维数简化以及对等网技术的结合[15].
通过综合检索词推荐服务现状和现有的理论方法研究可以发现,目前国内学术信息检索在作者、单位、期刊、中图分类号及基金等非主题相关性特征项的检索词推荐服务中,无法获取与检索入口匹配、与检索词直接相关的检索词推荐结果;同时,基于共现网络的检索词推荐大多还局限于关键词或主题词数据,需要继续拓展到其他能够表征文献特性的数据中.
因此,本文尝试进一步拓展及完善现有的检索词推荐方法体系,改进传统的基于共现网络的推荐方法,构建能够实现推荐词类别与检索特征项类别的一致性且具有高推荐效率的检索词推荐模型.
4基于文献特征项共现网络的学术信息检索词推荐模型4.
1文献特征项元素集合数字化学术资源中的文献检索是基于对文献内容特征项及外部特征项的详细标引的.
本文参考文献[16]中的文献特征项类别,同时借鉴现有学术信息检索中提供的检索项及统计项,对文献的特征项元素进行总结,如表2所示:表2文献特征项元素集合主体特征项类别特征项元素文献与相关性有关的内容特征项题名(TI)、摘要(AB)、关键词(KW)、学科类别(SC)、全文(FT)、参考文献(RF)与权威性有关的外部特征项作者(AU)、作者所属单位(IN)、来源期刊(PU、ISSN、CN)、发表时间(TM)、基金资助情况(FU)、研究层次(LE)、中图分类号(CLC)、被引频次(CI)、下载频次(DL)如果将一篇科学文献的内容特征与外部特征提取出来,可以发现科学文献是由一系列特征要素构成的集合.
本文假设该集合可以表达为:F(i)={TIia,ABib,KWic,SXi,FTid,RFic,AUif,INif,PUi,ISSNi,CNi,TMi,LEi,CLCi,CIi,DLi}(1)目前可提供检索的常用特征项包括主题(TI+AB+KW)、篇名(TI)、关键词(KW)、作者(AU)、单位(IN)、期刊(PU)、ISSN、CN、期、基金(FU)、摘要(AB)、全文(FT)、参考文献(RF)和中图分类号(CLC)等.
当用户使用ISSN和CN特征项进行检索时,可以先预置换为期刊,再进行检索推荐;用户一般不使用期及基金作为第一检索特征项;且使用参考文献作为检索项时,推荐内容一般基于检索词进行主题推荐.
因此,本文进一步简化F(i)表达式,略去ISSN、CN、期及参考文献特征项,F′(i)具体表达如下:F′(i)={TIia,ABib,KWic,FTid,AUif,INif,PUi,CLCi}(2)4.
2基于特征项的文献共现网络的形成4.
2.
1TI、AB及FT共现网络篇名(TI)、摘要(AB)及全文(FT)经由数据预切分处理后,可获取一系列表达文献主题的知识元项.
知识元项共同在篇名、摘要及全文中出现在一定程度上可表征知识元之间主题相关.
由于TI、AB,尤其是FT简单切分后的知识元及知识元共现频次较高,且可能存在很多文本主题不相关的高频词语,因此本文借鉴文献[17]基于向量空间模型和TFIDF方法对TI、AB及FT信息预先进行分词、权重计算及知识元抽取,并统计抽取后的各知识元出现频次及关联度.
本文假定基于TI、AB及FT的共现网络,分别以TI、AB及FT中预处理后的知识元为节点,以各知识元共现的关联度作为描述共现联系紧密性的指标.
4.
2.
2KW、AU、IN及CLC共现网络关键词(KW)、作者(AU)、单位(IN)及中图分类号(CLC)的共同特征是由一系列表达文献内外部特征的知识元以"合作"关系构成.
文献中关键词之间往往存在主题相关性,多作者合作及多单位合作能够在一定程度上表明作者及单位之间研究领域的相似性,共同标引文献的分类号之间也存在研究主题的交叉.
本文假定基于KW、AU、IN及CLC的共现网络,分别以其中共现"合作"知识元为节点,以各知识元共现的关联度作为描述共现联系紧密性的指标.
4.
2.
3PU共现网络期刊(PU)的特征是单篇文献中不存在共现合作项,可依据期刊之间的主题相似性731丁洁,王曰芬.
基于特征项的文献共现网络在学术信息检索中的应用构建PU共现网络.
假定期刊A及期刊B的高频主题词依次为A={Ai|i=1,2,3…N}、B={Bj|j=1,2,3…N}.
由4.
2.
1及4.
2.
2,将文献篇名、关键词及摘要进行汇总,可构建基于主题的共现网络.
则期刊A与B的主题相关程度表示如下:QAB=Nj=1Ni=1Sim(Ai,Bj)(3)其中:Sim(Ai,Bj)为Ai主题词与Bj主题词在主题共现网络中的相关程度,主要基于改进的知网语义相似度算法实现[18].
本文假定基于PU的共现网络,以期刊知识元为节点,以期刊高频主题词累计相关程度数值QAB作为描述连线紧密的指标.
4.
3学术信息检索词推荐模型检索词推荐模型由基础文献存储模块、文献特征项抽取模块、文献特征项共现网络预处理模块、基于特征项的文献检索模块及检索词推荐服务前端5个部分组成,具体如图1所示:图1基于文献特征项共现网络的学术信息检索词推荐模型4.
3.
1基础文献存储模块基础文献存储模块主要实现原始文献数据的基础信息存储.
存储字段包括文献ID、TI、AB、FT、AU、IN、CLC及PU信息,可利用学术信息检索平台中现有的文献数据进行存储.
基础文献存储模块是整个模型的原始数据来源,它的稳定和可靠是整个模型正确实施的保证.
4.
3.
2文献特征项抽取模块文献特征项抽取模块主要实现基础文献数据中特征项的单独抽取、分离(或分词)及存储,并分别构建TI、KW等特征项数据库.
其中,TI库、AB库及FT库存储字段包括文献ID及分词后的各知识元;KW库、AU库、IN库及CLC库存储字段包括文献ID及分离合作关系后的各知识元;PU库存储字段包括文献ID及该篇文献所属PU.
文献特征项抽取模块是整个模型的重要组成部分,文献特征项的抽取、分离(或分词)及存储是后期特征项共现网络构建的基础.
这里尤其需要注意的是,依据基础文献数据的特征项进行抽取、分离(或分词)的过程中,TI、KW及AB数据中存在着大量的形如"研究"、"应用"等没有实际语义的噪音词.
因此,本文借鉴齐普夫定律、卢恩假设及帕欧公式[19],依次对各特征项数据库中的分离(或分词)知识元进行词频统计.
依据帕欧公式及必要的人工核查构建基于各特征项的高频无实际语义的噪音词词表,并在各特征项数据库中删除噪音词字段,以获取更为准确的特征项数据.
4.
3.
3文献特征项共现网络预处理模块文献特征项共现网络预处理模块是整个模型的核心部分,在特征项数据库基础上,实现各文献特征项共现网络的构建,同时获取各特征项中知识元的出现频次及关联度.
目前词汇关联度的主要测度方式有Dice指数、余弦指数、Jaccard指数及ChenHsinchun提出的共现算法[20].
其中Jaccard指数能够根据词的共现频率直接反映两个词之间的相似度并且消除部分无意义高频词的消极影响,因此它被广泛用作代表ci和cj两词之间的标准化相关系数,公式如下:Jaccardcoefficient=cijci+cj-cij(4)其中cij是知识元i和知识元j的共现频次,ci、cj分别是词i和词j在数据集中的全部出现频次.
Jaccard指数的取值越高,表明知识元之间的关联度越高.
因此,模型在构建基于各文献特征项知识网络的基础上,利用Jaccard指数测度知识元项的关联度,为基于文献特征项的检索模块提供数据支撑.
4.
3.
4基于特征项的文献检索模块基于特征项的文献检索模块主要实现依据用户检索入口类别差异,在对应特征项共现网络中查询并返回关联度较高的推荐结果.
模块中的匹配推荐算法直接决定推荐词模型的查准率和查全率.
由于在共现网络预处理模块中已实现各知识元项的关联度测度,本模型直接利用当前用户的检索词,在对应类别的特征项共现网络预处理数据中进行查询及处理操作,并输出与当前检索词关831第58卷第15期2014年8月联度较高的知识元作为检索推荐词语.
4.
3.
5检索词推荐服务前端检索词检索服务前端在模型中直接与用户进行交互,主要实现用户的不同特征项入口检索及推荐检索词的返回显示.
用户在初步明确检索需求后,在特定文献特征项的检索入口输入检索词,并等待后台查询及返回与当前检索词相关的词项.
5实验和讨论为了评估上述基于文献特征项共现网络的学术信息检索词推荐模型的可行性,本文利用样本文献数据对检索推荐模型进行验证,并与现有的检索词推荐结果进行对比分析.
5.
1数据来源和处理本文以CNKI、万方及维普为数据来源,剔除部分相同文献数据,共获取1186篇"知识构建"主题的样本文献.
样本文献信息中具体包括文献篇名、摘要、关键词、作者、单位、期刊及中图分类号(由于时间限制,全文FT处理信息量较大,本次实验暂未考虑).
本文按照获取时间顺序,将样本文献数据依次编号1-1186.
由上文,样本文献信息中篇名TI及摘要AB项进行预分词处理,获取相应具体的知识元项.
本文通过Eclipse调用国内中文词切分效果较好的ICTCLA提供的java接口,实现TI及AB项的词语切分,利用哈尔滨工业大学停用词表实现了"的"、"通过"及标题符号等词语的过滤.
并依据CNKI文献分类目录分层抽样,共获取各学科领域9600条文献篇名、关键词及摘要数据,借鉴齐普夫定律、卢恩假设及帕欧公式,实现TI、KW及AB数据中"研究"、"应用"、"影响"、"过程"等噪音词的过滤.
由于ICTCLA仍无法实现基于语义切分,切分效率有限,因此实验在机器切分基础上添加用户词典,并进行了部分数据的人工修正.
目前国内外文献信息共现关系分析的应用软件包括Citespace、NetworkWorkbenchTool、Pajek及Bibexcel等.
对比实验需求及使用难度,本文主要采用Bibexcel软件实现知识共现网络的构建,具体可实现不同文献特征项内各知识元出现的频次统计及Jaccard指数计算.
本文以KW共现网络为例,以表格形式表征,结果见表3.
利用Ucinet软件实现共现网络的可视化,见图2.
其中知识元节点大小及颜色表征该知识元出现频次大小,节点间联系粗细表征知识元之间的Jaccard指数高低.
表3KW知识共现网络表格形式表示(TOP10)KW知识元出现频次KW知识元AKW知识元BJaccard指数知识构建234知识服务知识构建0.
063025知识管理28信息构建知识构建0.
046414建构主义27知识构建知识管理0.
043825本体23课程标准知识构建0.
038462课堂教学21数字图书馆知识构建0.
033613知识服务19教学过程知识构建0.
029289教学模式18课堂教学知识构建0.
028226教师16地理环境知识构建0.
025641教学15学生知识构建0.
024793信息构建14知识构建知识组织0.
021277图2KW知识共现网络的可视化931丁洁,王曰芬.
基于特征项的文献共现网络在学术信息检索中的应用在图2中,KW共现网络中以检索关键词"知识构建"为中心节点,周圈关键词与中间节点及周圈关键词之间均存在不同程度的主题关联,呈现网状交错的共现网络结构.
由于Jaccard指数直接表征知识元项之间的关联度,与"知识构建"之间具有高Jaccard指数的"知识服务"、"信息构建"等将被作为KW项检索推荐结果,其他特征项共现网络亦然.
5.
2结果分析本文仍以表1中涉及的检索入口及相应检索词为例,忽略实验中未加入考虑的FT、RF、ISSN、CN及期等检索项入口,利用本文构建的检索词推荐模型进行检索推荐,推荐结果具体如表4所示:表4基于检索词推荐模型的检索推荐结果TOP10检索入口检索词模型检索推荐结果主题知识构建知识服务/课程标准/信息构建/知识管理/学习能力/数字图书馆/教学过程/新课程/教学方法/实践能力篇名知识构建知识服务/学生/图书馆/信息构建/数字图书馆/高职/本体/知识管理/学科知识体系/初中学段关键词知识构建知识服务/信息构建/知识管理/课程标准/数字图书馆/教学过程/课堂教学/地理环境/学生/知识组织摘要知识构建教学模式/技能/知识服务/课程标准/学习能力/兴趣/教学方法/素质教育/新课程/情境作者姜永常张静/金岩中图分类号G350G20/F270单位哈尔滨商业大学图书馆东北林业大学图书馆期刊图书情报工作图书情报技术/图书馆论坛/情报理论与实践/档案管理/图书馆学研究/图书馆/河南图书馆学刊/情报杂志/情报学报/情报探索将目前数字化学术资源检索提供的检索词推荐结果(见表1)及本文构建的检索词推荐模型结果(见表4)进行对比,发现:(1)通过主题、篇名、关键词及摘要特征项进行检索时,表1中CNKI及万方提供的推荐检索词主题相关度高,但检索入口类别特征无法体现.
表4中的检索推荐结果在保证推荐词主题相关的基础上,充分考虑上述特征项的类别差异性,提供与特征项入口类别一致性的推荐结果.
(2)通过作者、中图分类号、单位及期刊特征项进行检索时,表1中CNKI及万方提供的推荐检索词仍无法体现入口类别特征,且CNKI部分推荐结果依据文本相似性推荐,存在"姜片"、"白姜"等无意义推荐结果.
表4中的检索推荐结果来源于文献特征项的主题或合作共现,能够完全排除出现无意义推荐结果的可能性,更具合理性和可行性.
6结语本文以学术信息检索词推荐为研究对象,通过总结国内学术信息检索服务的现状及现有的理论研究现状,尝试进一步拓展及完善现有的检索词推荐方法体系,构建基于文献特征项共现网络的学术信息检索词推荐模型,最后利用实验验证文献特征项共现网络应用于检索词推荐的可行性.
可得到以下几点结论:(1)国内学术信息检索词推荐服务有待继续改善.
从目前检索词推荐服务存在的问题来看,国内的学术信息检索词推荐服务与国内外检索词推荐理论方法研究之间还存在一定差距.
(2)基于共现网络的检索词推荐不局限于在关键词或主题词数据,其他能够表征文献特性的数据同样适用.
除关键词和主题词之外,篇名知识元、摘要知识元、作者、中图分类号、单位及期刊数据的共现信息同样具有主题相关性,可以充分挖掘其中隐含的关联信息并应用于实践.
(3)实现推荐词类别与检索特征项入口类别的一致性具有重要意义.
特别当用户从作者、分类号、单位及期刊检索项入口进行检索时,在当前类别内语义相关的推荐结果更能够满足用户进一步拓展检索的需求.
基于文献特征项共现网络的检索词推荐模型在提高推荐效果的同时,在模型构建中还存在部分难点尚待解决.
模型中只对部分检索推荐进行了研究,以参考文献、基金等其他特征项作为检索入口的搜索推荐研究尚未开展;基于文献特征项网络的检索词推荐模型还仅限于特征项的单元共现,能够排除部分完全无意义的推荐结果,但特征项之间的多元语义共现还没有得到体现.
以上问题是检索词推荐服务领域研究人员所面临的重大挑战,检索词推荐模型有待进一步修正和完善.
参考文献:[1]张铧予,李广建.
基于文献的语义资源库建设及其在NSTL中的应用[J].
图书情报工作,2012,56(9):18-23.
[2]边鹏,苏玉召.
基于检索日志的检索词推荐研究[J].
图书情报工作,2012,56(9):31-36,41.
041第58卷第15期2014年8月[3]于娟,尹积栋,费庶.
基于句法结构分析的同义词识别方法研究[J].
现代图书情报技术,2013,29(9):35-40.
[4]陆勇,侯汉清.
基于模式匹配的汉语同义词自动识别[J].
情报学报,2006,25(6):720-724.
[5]YangXu,GarethJFJ,WangBin.
Querydependentpseudo-relevancefeedbackbasedonwikipedia[C]//Proceedingsofthe32ndinternationalACMSIGIRconferenceonResearchanddevelopmentininformationretrieval.
NewYork:ACM,2009:59-66.
[6]汪英姿.
基于本体的个性化图书推荐方法研究[J].
现代图书情报技术,2012,(12):72-78.
[7]唐晓玲.
基于本体和协同过滤技术的推荐系统研究[J].
情报科学,2013,31(12):90-94.
[8]黄媛.
基于论文主题词和关键词关系网的检索词拓展研究[J].
科技广场,2011,(1):24-27.
[9]陆伟,张晓娟.
基于主题与用户偏好分析的查询推荐研究[J].
情报学报,2012,31(12):1252-1258.
[10]JiShihao,ZhouKe,LiaoCiya,etal.
Globalrankingbyexploitinguserclicks[C]//Proceedingsofthe32ndinternationalACMSIGIRconferenceonResearchanddevelopmentininformationretrieval.
NewYork:ACM,2009:35-42.
[11]SanjeevR,PriyankaG.
ImplementingimprovedalgorithmoverAPRIORIdaataminingassociationrulealgorithm[J].
InternationalJournalofComputerScienceandTechology,2012,3(1):489-493.
[12]KomalK,SimpleS.
Analysisofassociationrulesminingalgorithms[J].
InternationalJournalofScientificandResearchPublications,2013,3(5):1-4.
[13]刘旭东,葛俊杰.
基于关联规则的个性化推荐在数字图书馆中的应用研究[J].
德州学院学报,2010,26(2):72-75.
[14]边鹏,赵妍,苏玉召.
一种适合检索词推荐的Kmeans算法最佳聚类数确定方法[J].
图书情报工作,2012,56(4):107-111.
[15]奉国和.
协同过滤推荐研究综述[J].
图书情报工作,2011,55(16):126-130.
[16]曹艺.
面向学术影响力评价的网络学术交流中文献的下载与引用研究[D].
南京:南京理工大学,2012.
[17]许文海,温有奎.
一种基于TFIDF方法的中文关键词抽取算法[J].
情报理论与实践,2008(2):298-302.
[18]基于知网的词汇语义相似度计算方法研究[J].
计算机应用研究,2010,27(9):3329-3333.
[19]邱均平.
信息计量学[M].
武汉:武汉大学出版社,2007:132-152.
[20]HsinchunC,AndreaLH,RobinRS.
Internetbrowsingandsearching:Userevaluationsofcategorymapandconceptspacetechniques[J].
JournaloftheAmericanSocietyforInformationScience,1998,49(7):582-603.
TechnologiesandApplicationsofLiteratureCooccurrenceNetworkBasedonCharacteristicTermsinAcademicInformationRetrievalDingJieWangYuefenSchoolofEconomicsandManagement,NanjingUniversityofScience&Technology,Nanjing210094[Abstract]Afteranalyzingthepresentsituationofthedomesticacademicinformationretrievalservicesandresearchstatusathomeandabroad,adigitalacademicinformationquerysuggestionrecommendationmodelbasedoncooccurrenceanalysiswasdeveloped,whichincludesthebasicliteraturesstoragemodule,theliteraturesfeatureitemextractionmodule,theliteraturesfeaturecooccurrencenetworkpreprocessingmodule,theliteraturesearchmodulebasedonfeatureitemandthefrontendofsearchtermservices.
Anexperimentwasdonetoverifythemodel.
Theresearchshowedthattheacademicinformationquerysuggestionrecommendationmodelbasedoncooccurrenceanalysisofliteraturecharacteristictermsachievedbetterrecommendationquality.
[Keywords]querysuggestionrecommendationmodelcooccurrenceanalysisacademicinformationretrieval檶檶檶檶檶檶檶檶檶檶檶檶檶檶檶檶檶檶檶檶檶檶檶檶檶檶檶檶檶檶檶檶檶檶檶檶檶檶檶檶檶檶檶檶檶檶檶檶檶檶檶檶檶檶檶檶檶檶檶檶檶檶檶檶檶檶檶檶檶檶檶檶檶檶檶檶檶檶檶檶檶檶檶檶檶檶檶檶檶檶檶檶檶檶檶檶檶檶檶檶檶檶檶檶檶檶檶檶檶檶殞殞殞殞scientificliterature2014中国机构知识库学术研讨会征文通知机构知识库是促进科技信息开放共享的重要力量,已经被学术界广泛接受并形成普遍共识.
在成功举办第一届中国机构知识库学术研讨会的基础上,为持续交流和共享全国机构知识库的创新发展,中国机构知识库推进工作组联合中国图书馆学会专业图书馆分会、中国图书馆学会高校图书馆分会,定于2014年11月3-6日在福建厦门召开"2014中国机构知识库学术研讨会".
主题是:机构知识库的创新发展.
会议将围绕中文机构知识库的服务、政策、技术等方面的内容进行研究交流与讨论,欢迎各界踊跃投稿.
请登陆以下网址了解详细信息:http://www.
csla.
org.
cn/.
141
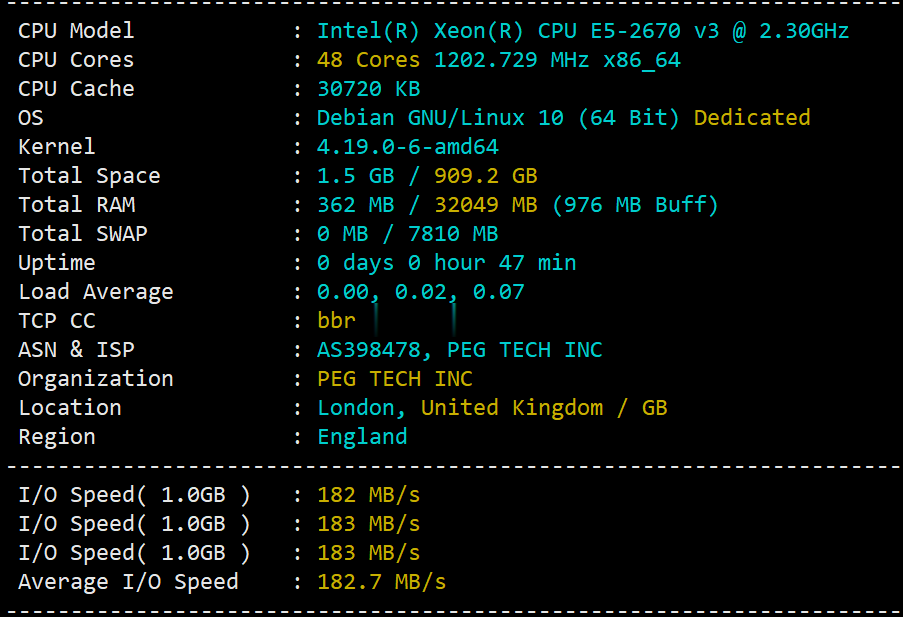
raksmart:香港机房服务器实测评数据分享,告诉你raksmart服务器怎么样
raksmart作为一家老牌美国机房总是被很多人问到raksmart香港服务器怎么样、raksmart好不好?其实,这也好理解。香港服务器离大陆最近、理论上是不需要备案的服务器里面速度最快的,被过多关注也就在情理之中了。本着为大家趟雷就是本站的光荣这一理念,拿了一台raksmart的香港独立服务器,简单做个测评,分享下实测的数据,仅供参考!官方网站:https://www.raksmart.com...
ZJI-全场八折优惠,香港服务器 600元起,还有日本/美国/韩国服务器
ZJI怎么样?ZJI是一家成立于2011年的商家,原名维翔主机,主要从事独立服务器产品销售,目前主打中国香港、日本、美国独立服务器产品,是一个稳定、靠谱的老牌商家。详情如下:月付/年付优惠码:zji??下物理服务器/VDS/虚拟主机空间订单八折终身优惠(长期有效)一、ZJI官网点击直达香港葵湾特惠B型 CPU:E5-2650L核心:6核12线程内存:16GB硬盘:480GB SSD带宽:5Mbps...

香港CN2云服务器 1核 2G 35元/月 妮妮云
妮妮云的来历妮妮云是 789 陈总 张总 三方共同投资建立的网站 本着“良心 便宜 稳定”的初衷 为小白用户避免被坑妮妮云的市场定位妮妮云主要代理市场稳定速度的云服务器产品,避免新手购买云服务器的时候众多商家不知道如何选择,妮妮云就帮你选择好了产品,无需承担购买风险,不用担心出现被跑路 被诈骗的情况。妮妮云的售后保证妮妮云退款 通过于合作商的友好协商,云服务器提供2天内全额退款到网站余额,超过2天...
相关搜索为你推荐
-
万网核心代理哪里可以注册免费代理?arm开发板ARM开发板具体有什么作用?有什么商业价值?网易公开课怎么下载哪位高手指导一下,如何下载网易公开课啊?qq怎么发邮件如何通过QQ发送邮件雅虎天盾有没有用用雅虎天盾的啊?rewritebasehttp怎么做自动跳转https去鼠标加速度去鼠标加速到底有什么好处.......黑龙江计算机等级考试网计算机2级考试成绩怎么查?msn与qqMSN与QQ的区别?12580拨打12580有什么作用?