浮点M—DSP中高性能浮点乘加器的设计与实现
M—DSP中高性能浮点乘加器的设计与实现目录
M-DSP总体结构设计如图1所示
2. 1浮点乘加单元指令集设计
2. 2高性能浮点MAC单元的体系结构设计
1流水线第一站设计实现
2流水线第二站设计实现
3流水线第三站设计实现
4流水线第四站设计实现
5流水线第五站设计实现
6流水线第六站设计实现
2. 3浮点MAC单元关键模块设计
27×16位乘法器采用两级流水实现
a Shift_Bit≥0时b Shift_Bit<0且Shift_Bit≥-50时c Shift_Bit<-50且Shift_Bit≥-98时d Shift_Bit≤-98时
3. 1FMAC验证
M-DSP中浮点MAC的验证主要从模拟验证和形式验证两方面来完成[12]
正文
0引言
数字信号处理器Digital Signal Processor DSP从专用信号处理器开始发展到今天的超长指令字Very Long Itruction WordVLIW阵列处理器其应用领域已经从最初的语音、声纳等低频信号的处理发展到今天雷达、 图像等视频大数据量的信号处理。 由于浮点运算和并行处理技术的应用信号处理能力已得到极大的提高。随着数字信号处理器在处理速度和运算精度两个方向的发展体系结构中
数据流结构甚至人工神经网络结构等将可能成为下一代数字信号处理器的基本结构模式。近些年从传统DSP结构中已不能有效地提高DSP处理器的性能许多新的提高DSP性能的方法被提出[1] 。其中提高频率的方法已达到瓶颈阶段最有效的途径是提高并行性。数字信号处理领域的核心算法根据运算类型可以分为两大类一类是以密集的浮点乘加运算为典型的信号处理算法包括快速傅里叶变换FastFourier Traformation FFT [2-3] 、有限冲激响应FiniteImpulse Respoe FIR和离散傅里叶变换Discrete FourierTraf orm DFT等算法另一类是以密集的复数矩阵操作为主的算法包括信道估计和多输入多输出Multiple-Input Multiple-Output MIMO均衡[4]等算法。这两类算法均需要DSP处理器提供较高的浮点乘加运算的计算性能。第一类算法主要是进行乘加运算
a*b+c 第二类算法主要进行大量的复数矩阵乘和矩阵求逆等运算而在这些运算中都存在密集的乘后加运算a*c+c*d 。浮点乘累加器Floating-point Multiply ACcumulate FMAC已经成为提高并行计算以减少计算延时的有效方法其运算能力已经成为衡量数字信号处理器DSP性能的一个重要特征。
浮点乘加结构已被研究多年 IBM学者Montoye和Hokenek于1990年最先提出了融合乘加的概念[5] 即将乘法和加法融合成一条指令执行并将加法操作融合在乘法的部分积压缩阵列中从而减少硬件开销和延时这种乘加结构的主要缺点是求和尾数长且结果尾数舍入延时长。 Lang等[6]于2004年提出了低延时融合乘加结构这种结构采用前导零预测Leading Zero Anticipation LZA 将尾数舍入和
加法合并并在尾数加法之前进行规格化移位。 目前大多数处理器中的浮点乘加设计实现均采用这种技术为进一步提高浮点融合乘加结构的并行度以提升浮点乘加器的性能 Lang等[7]于2005年设计了双通路浮点融合乘加结构该乘加结构主要优点是延时更低、处理性能得到进一步提高但该乘加结构逻辑设计复杂硬件资源消耗大。国防科技大学研制的FT-XDSP中设计了多功能快速浮点融合乘加运算单元[8] 但该设计硬件资源消耗太多功耗过大。
本文基于高性能计算的应用需求 以M型数字信号处理器M-DSP为研究背景深入研究FMAC的各功能模块和流水线结构对已有浮点融合乘加结构[9]的关键模块和算法进行了研究与优化设计了6级流水线结构的FMA C单元可支持双精度和单精度浮点乘法、乘累加、乘累减、单精度点积和复数运算。对所设计的FM A C单元的寄存器传送语言Register Trafer Language RTL代码实现进行了仿真测试并基于45nm工艺采用Synopsys公司的DC Design Compiler对硬件实现进行了综合运行频率可达1 GH z。
1M-DSP处理器体系结构
M-DSP总体结构设计如图1所示。 M-DSP是自主研发的一款具有自主知识产权的高性能DSP 目标频率1GHz。 内核采用新型的哈佛结构采用可变长的11发射超长指令字结构可以同时并行取指和派发11条指令。 M-DSP中内核结构主要包括一级程序Cache、取指单元
Itruction Fetch IF 、指令派发单元DisPatch DP 、 向量运算部件Vector Process Unit VPU 、标量运算部件Scale
Process Unit SPU和向量阵列存储器Array Memory AM等。其中运算部件是DSP内核中最重要的单元之一约80%以上的指令来自于运算部件。标量运算单元Scale Process Element SPE包括两个乘加部件和一个定点执行单元。两个同构的乘加部件由共享54×32位乘法器结构的定点MAC单元与浮点MAC单元以及浮点算数逻辑单元
Arithmetic Logical Unit ALU组成三个单元独立运算但共用乘累加Mu l t i p ly-AC cumulate MAC单元的写端口写回到寄存器三个单元共用同一套寄存器端口。
向量运算单元Vector Process Element VPE 内数据通路如图2所示它包含64个局部通用寄存器三个同构的MAC部件由定点乘加Integer Multiply Accumulate IMAC 、浮点MAC和浮点ALU单元三个单元构成其中FMAC和IMAC复用了一个54×32乘法器。 向量运算部件均包含有16个相同结构的向量运算单元VPE与标量运算类似每一个向量运算单元由三个向量乘加部件Vector MultiplyACcumul ate VMAC及一个向量定点执行单元组成。每一个单元内部的部件组成及数据写回方式与标量的处理方式相同。 VPE之间通过混洗网络和规约树网络进行数据交互。混洗网络可以根据混洗粒度和混洗模式的不同对VPE之间的数据进行混洗操作归约网络将多个VPE中的数据通过多宽度规约方式规约到一个或者多个VPE中多宽度归约操作将所有的16个VPE进行分组每个分组归约操作并行执行分组只支持平均分组分组大小为2的整数次幂。
2 FMAC单元的结构设计与实现
2. 1浮点乘加单元指令集设计
浮点MAC单元共设计实现9条指令如表1所示 包括双精度乘法Double Floating-point MULtiply DFMUL 、单精度乘法
Single Floating-point MULtiply SFMUL 、双精度乘加
Double Floating-point MULtiply-Adder DFMULA 、单精度乘加
Single Floating-point MULtiply-Adder SFMULA 、双精度乘减
Double Floating-point MULtiply-Subtration DFMULS 、单精度乘减Single Floating-point MULtiply-Subtration
SFMULS 、浮点复数实部乘法Floating-point Complexmultiplication REAL FCREAL 、浮点复数虚部乘法Floating-point Complex multiplication IMAGinary FCIMAG和
浮点点积Floating-point DOT product FDOT指令。 由于寄存器端口的限制双精度指令和4操作数单精度指令需要读取两拍双精度结果写回需要两拍。
2.2高性能浮点MAC单元的体系结构设计
浮点MAC单元其总体结构设计实现如图3所示。基于经典低延时浮点乘加结构根据M-DSP的体系结构设计要求设计实现了双精度浮点乘加运算通路在此基础上复用部分硬件实现单精度指令的相关运算通路包括单精度浮点乘法/乘加、点积和复数操作。为提高性能、降低逻辑设计复杂度基于传统浮点乘加结构将单、双精度指令计算分开处理设计了一套单、双精度通路分离[10]的浮点乘加结构。所设
计的浮点MAC单元包括54×32共享乘法器、指数计算、源操作数例外判断、尾数对阶移位、尾数加法、乘法结果输出、结果符号计算、结果尾数规格化移位、结果舍入和结果选择写回等模块单/双精度浮点操作均需要用到上述模块。根据逻辑复用的设计思想将对阶移位、尾数加法和前导零等模块进行优化使得硬件逻辑在支持单/双精度浮点乘加的同时支持单精度浮点乘法后加法操作。各流水线设计如下
1流水线第一站设计实现。流水线第一站主要由源操作数读取、源操作数例外判断、指数计算和对阶移位量计算等运算模块构成乘法器模块单独设计 其中乘法器的相关模块与定点MAC单元共用为了减少乘法器面积和提高逻辑复用的能力采用4个27×16的乘法器实现54×32的乘法操作双精度乘法需要两次乘法操作才能计算出结果。
2流水线第二站设计实现。流水线第二站主要包括部分积压缩第3级、 27×16乘法结果的S um与C arry的加法和乘法/乘加指令的尾数对阶移位等运算模块。第3级部分级压缩将乘法器中前两级压缩的结果采用进位保留加法器Carry-Save Adder CSA进一步压缩在得到单精度乘法的部分积和阵列的Sum和C arry后采用43位加法器对Sum和Car ry进行全加操作得到高位部分的单精度浮点乘法结果尾数。
3流水线第三站设计实现。流水线第三站包括乘加/乘后加指令的尾数加法等运算模块。在第三站中在单精度乘法操作完成后双精
度乘法的中间结果S um和Carry也已计算出来采用2个全加器用来计算浮点尾数求和前导零LZA逻辑有部分逻辑在第三站进行。
4流水线第四站设计实现。第四流水站主要包括前导零预测LZA第二部分、乘加结果尾数舍入进位处理、乘法结果溢出、例外判断和乘法结果选择写回等运算模块在乘法结果旁路写回模块中单精度乘法执行4拍写回双精度乘法由于读、写都要多一拍需要6拍写回结果。
5流水线第五站设计实现。流水线第五站主要包括规格化移位、尾数舍入处理、结果符号计算和结果指数修正。在第五级流水线中浮点MAC除乘法类的各条指令的规格化移位都使用128位对数移位器对结果尾数进行规格化移位。根据舍入模式以及粘接位的值舍入模块判断是否对最后结果尾数进行加1操作。根据规格化移位的结果尾数和移位量利用指数修正模块可以计算出正确的结果指数根据尾数加法的最后结果采用符号计算逻辑判断结果符号。
6流水线第六站设计实现。第六级流水线主要包括结果尾数的例外判断、溢出判断以及结果选择写回处理。结果尾数选择写回时先根据浮点控制寄存器中各标志位进行结果处理待结果尾数确定后选择写回写回时双精度指令要写两拍。
2.3浮点MAC单元关键模块设计
传统的定点和浮点运算部件都有单独的乘法器单元。特别是处于同一流水线上的定、浮点单元这样的设计会导致硬件资源浪费。因此
在M-DSP中采用定点乘加部件与浮点乘加部件复用同一个乘法器这样可以在满足功能要求的前提条件下提高硬件利用率减少芯片面积。按照指令设计需求定点MAC单元中有32×32和单指令多数据
Single Itruction Multiple Data SIMD的16×16定点乘法浮点MAC单元有54×54和24×24的浮点乘法。 由于寄存器文件端口个数和位宽的限制浮点乘加的读操作数与写结果均需要两拍实现无法实现全流水操作。通过优化逻辑结构 因此将乘法器设计为54×32位乘法器采用4个27×16的子乘法器搭建而成复用的乘法器共三级流水其中定点MAC单元使用前面的两级流水站浮点MAC单元使用三级流水站。 由于乘法器面积在定、浮点乘加部件面积中比重较大共享同一个乘法器的设计可以大幅度减少MAC单元的面积。
27×16位乘法器采用两级流水实现其实现结构如图4所示其中基2Booth编码[11] 、第一级压缩与第二级压缩为第一站第三级压缩和S um与Carry的加法为第二站。这样的流水设计满足功能要求和时序要求并且可以提高乘法器速度。对所设计的27×16位与54×32位乘法器进行模块级验证后使用综合工具DC在40 nm工艺下对所设计的乘法器进行了逻辑综合 27×16位乘法器关键路径340ps单元面积6758.707μ m2单元总功耗6.0817mW 54×32位乘法器关键路径390p s单元面积27438. 196μ m2单元总功耗17.4217mW。
定、浮点MAC单元共享乘法器结构如图5所示其中PP0PP8表示9个部分积Part of the Product PP 乘法器内部有单独的源操作数预处理模块根据派发的定、浮点指令对读取的源操作数进
- 浮点M—DSP中高性能浮点乘加器的设计与实现相关文档
- 信号北理工电子技术课程设计浮点频率计
- 小数PLC(FX2N)小数点(浮点)运算编程研究讲义
- 数据eeprom浮点存取方法
- 小数定点转浮点的Qn定义及计算公式方法
- 小数点将浮点型数据转换为字符串
- 数据串口通信中整型和浮点型数据的处理和发送
极光KVM美国美国洛杉矶元/极光kvmCN7月促销,美国CN2 GIA大带宽vps,洛杉矶联通CUVIP,14元/月起
极光KVM怎么样?极光KVM本月主打产品:美西CN2双向,1H1G100M,189/年!在美西CN2资源“一兆难求”的大环境下,CN2+大带宽 是很多用户的福音,也是商家实力的象征。目前,极光KVM在7月份的促销,7月促销,美国CN2 GIA大带宽vps,洛杉矶联通cuvip,14元/月起;香港CN2+BGP仅19元/月起,这次补货,机会,不要错过了。点击进入:极光KVM官方网站地址极光KVM七月...
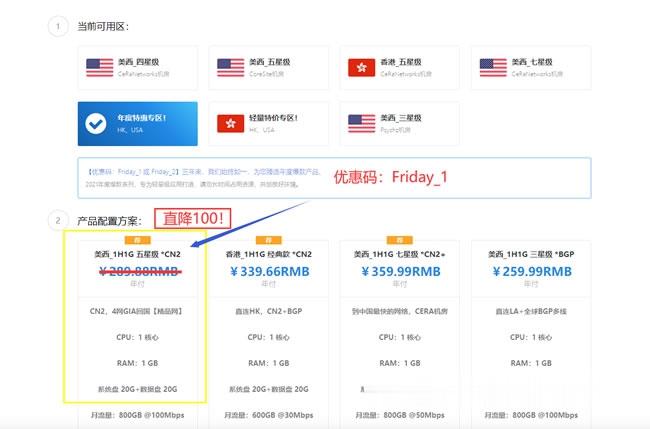
Friendhosting,美国迈阿密机房新上线,全场45折特价优惠,100Mbps带宽不限流量,美国/荷兰/波兰/乌兰克/瑞士等可选,7.18欧元/半年
近日Friendhosting发布了最新的消息,新上线了美国迈阿密的云产品,之前的夏季优惠活动还在进行中,全场一次性45折优惠,最高可购买半年,超过半年优惠力度就不高了,Friendhosting商家的优势就是100Mbps带宽不限流量,有需要的朋友可以尝试一下。Friendhosting怎么样?Friendhosting服务器好不好?Friendhosting服务器值不值得购买?Friendho...
ZJI(月付450元),香港华为云线路服务器、E3服务器起
ZJI发布了9月份促销信息,针对香港华为云线路物理服务器华为一型提供立减300元优惠码,优惠后香港华为一型月付仅450元起。ZJI是原来Wordpress圈知名主机商家:维翔主机,成立于2011年,2018年9月更名为ZJI,提供中国香港、台湾、日本、美国独立服务器(自营/数据中心直营)租用及VDS、虚拟主机空间、域名注册等业务,商家所选数据中心均为国内访问质量高的机房和线路,比如香港阿里云、华为...
-
软银赛富李念老公是谁美国10次啦导航GPS的四大导航百度空间首页如何上百度空间首页录音软件哪个好好用的录音软件! 急!!杰士邦和杜蕾斯哪个好安全套杜蕾丝好还是杰士邦好?oppo和vivo哪个好Vivo和OPPO哪个好点啊?51空间登录怎样登51个人空间群空间登录群空间怎么进去?飞信空间登录怎样在网上登陆飞信YunOSyunOS是手机里的什么软件系统啊?