WebWandererHow Is My Web Community Developing Monitoring Trends In Web…
How Is MyWeb Community Developing?Monitoring Trends In Web Service
Provision
Brian Kelly,UK Web Focus and Ian Peacock,WebWatch
UK Office for Library and Information Networking,University of Bath,Bath,BA27AY,UK
E-mail: b.kelly@ukoln.ac.uk i.peacock@ukoln.ac.uk
Phone: +441225323943 +441225323570
F ax:+441225826838
Abstract
As the World Wide Web continues its tremendous rate of development,providers ofservices on the Web have dificult decisions to make regarding the deployment of newtechnologies:should they begin deployment of technologies such as HTML 4.0,CSS 2,Java,Dublin Core metadata, etc.,or should they wait until the technologies mature. Thispaper describes the use of a web auditing/profiling robot utility known as Web Watchwhich can help serviceproviders byproviding information on the uptake of technologieswithin particular communities.A description of use of the WebWatch software within theUK Higher Education community is given, together with a discussion of thefindings.Introduction
The Beleaguered Webmaster
In the early days of the web life was easy for the webmaster, to use the popular, ifpolitically-incorrect term.A simple text editor(typically vi or emacs for the Unix user orNotepad for the Windows users)or simple HTML authoring tool would suffice forcreating web pages.Add a graphical tool for creating and editing images,and thewebmaster could create a website which could make use of most of the web technologieswhich were widely deployed in around 1994.
These days,however, life is much more difficult. Competition between the browsersoftware vendors has hastened the development of a wide range ofweb technologies,much o f which, sadly,appears to suffer from interoperab ility prob lems. The webstandards community,principally the World Wide Web Consortium,has developed arange of new or updated web protocols (see article by Brian Kelly elsewhere in thisedition of the Journal ofDocumentation)although,again, there are reports ofimp lementation prob lems.
HowIsMyWebCommunityDeveloping?MonitoringTrends InWeb ServiceProvision 1
As the web becomes increasingly used to support core business functions, rather thansimply as a noticeboard managed by enthusiasts in the IT department, the webmasterfaces pressures to begin deployment of new technologies.He,and the webmaster is oftenmale, is often not in a position to say no and point out deployment and interoperabilityprob lems.
Web Monitoring Tools
Web auditing and monitoring tools can assist the beleaguered webmaster by providinginformation on the uptake of web technologies. Such tools can provide evidence on howwidely deployed particular technologies are and how they are used. This information is,of course,of use to a number of communities such as policy-makers, funders, softwaredeve lopers,e tc.
In this paper the authors describe the use of a web monitoring tool based on web robotsoftware which can be used freely on the Web without any special authorisation.Adescription of the robot software which has been developed by the authors is given. Thepaper then reports on the use of the tools within one particular community–UK HigherEducation–and interprets the results. The paper concludes by describing other ways inwhich web monitoring tools can be used.
Robot Software
Background
How big is the Web?C learly in order to answer this question automated software mustbe used.
In 1993 the first attempt to answer the question was made. The World Wide WebWanderer(WWWW)web robot wa s deve loped a s an automate d too l to automaticallyfollow links on web pages in order to count the total number of resources to be found onthe Web. In June 1993 the robot detected 130 web sites,which had grown to over 10,000by December 1994 and 100,000 by January 1996[1].
Since this initial survey was started,a number of other trawls have been carried out,although,due to the current size of the web, trawls of the entire Web tend nowadays to becarried out by large organisations which have the required disk and server capacity. TheOpen Text Corporation’s trawl reported by Tim Bray at the WWW 5 conference[2]indicated that by November 1995 there were over 11 million unique URLs and over223,000 unique web servers.
Robot Software
The World Wide Web Wanderer and the Open Text Spider are examples of web robots.A web robot can be regarded as an automated browser,which will sequentially retrieve
HowIsMyWebCommunityDeveloping?MonitoringTrends InWeb ServiceProvision 2
web resources.Unlike a browser,however,a robot is not designed to retrieve resourcesfor viewing.Robots typically retrieve web resources for auditing purposes,as describedabove, for indexing or for checking(such as robot software to detect broken links).The current generation of web crawlers is large.A glance at the Web Robots Pages [3]reveals a list ofover 160 well-known robots. These robots are used for a variety ofpurposes including auditing and statistics (such as the Tcl W3 Robot [4]and the RBSESpider[5]), indexing(the NWI Robot [6]and Harvest [7]),maintenance(Checkbot [8]and LinkWalker [9])and mirroring(Temp leton[10]).
Robot so ftware can b e regarded as automated web browsers.A potential problem withrobot software is the danger of causing server or network overload by requesting toomany resources in a short space of time. In order to overcome this problem the RobotExclusion Protocol [11]has been developed. This is a method that allows webadministrators to indicate to robots which parts of their site the robots should not visit.The WebWatch Project
Background
The WebWatch project is funded by the BLRIC(the British Library Research andInnovation Centre). The project is based at UKOLN,University of Bath. The aims ofthe WebWatch project are:
To develop robot software to gather information on usage of web technologieswithin a number of communities within the UK.
To use the so ftware to collect the data.
To develop(if appropriate)and use analysis tools to provide statistical analyses ofthe data.
To produce reports explaining the analyses.
To make recommendations to appropriate bodies on the information collected.
To publicise reports to relevant communities.
The WebWatch project began in August 1997.
WebWatch RobotSoftware
Following an initial survey of robot software it was decided to make use of the Harvestsoftware.Harvest [12] is a software suite which is widely used within the worldwideresearch distributed indexing community.A slightly modified version o f the so ftware
HowIsMyWebCommunityDeveloping?MonitoringTrends InWeb ServiceProvision 3
was used in the initial WebWatch trawl carried out in October 1997 across UK publiclibrary web s ites [13].
Once the data for this community and a number of other small trawls had been collectedand analysed it became apparent that Harvest was very limited as an auditing robot.As ithad been designed for indexing web resources, it did not allow non-textual resources,such as images, to be downloaded.Also as it processed the file suffix for web resources,rather than Internet MIME types, it was not possible to analyse resources by MIME types.In the light of these limitations and the difficulties found in extending Harvest it wasdesigned to write our own WebWatch robot which would be designed for auditingpurposes.
The current version of the WebWatch robot is written in perl5 and builds on previousvers ions.
Survey of UK Higher Education Entry Pages
In October 1997 a WebWatch trawl of UK University entry pages was carried out. Thetrawl was repeated on 31 July 1998(which terminated on 2 August). The initial resultshave been published elsewhere[14]. In this paper we give a brief summary ofthe originalsurvey,a more detailed report ofthe second trawl and a comparison between the twotraw l s.
Initial Trawl of UK Universities
The initial trawl of UK University entry pages began on the evening ofFriday 24thOctober 1997. The WebWatch robot analysed the institutional web entry point for UKUniversities and Colleges as defined in the HESA list [15]. This list contained the entrypoints for 164 institutions.The WebWatch robot successfully trawled 158 institutions.Six institutional home pages could not be accessed,due to server problems,networkproblems or errors in the input data file.
Second Trawl of UK Universities
The second trawl of UK University entry points was initiated on the evening ofFriday 31July 1998. This time the NISS list of Higher Education Universities and Colleges [17]was used for initial trawl. This file contains 170 institutions.The WebWatch robotsuccessfully trawled 149 institutions.Twenty-one institutional home pages could not beaccessed,due to server problems,network problems, restrictions imposed by the robotexclusion protocols or errors in the input data file.
A total of59 sites had robots.txt files.Of these, two sites (Edinburgh andLiverpool universities)prohibited access to most robots.As these sites were not trawledthey are excluded from most of the summaries.However details about the serverconfiguration is included in the summaries.
HowIsMyWebCommunityDeveloping?MonitoringTrends InWeb ServiceProvision 4
Note that when manually analysing outliers in the data it was sometimes found thatinformation could be obtained which was not available in the data collected by the robot.A brief summary of the findings is given below.More detailed commentary is given laterin this article.
Table 1 Table of Server Usage
HowIsMyWebCommunityDeveloping?MonitoringTrends InWeb ServiceProvision 5
As can be seen from Table 1 the Apache server has grown in popularity. This has beenmainly at the expense of the NCSA and CERN servers,which are now very dated and nolonger being developed. In addition a number of servers appear to be no longer in usewithin the community(e.g.Purveyor and WebS ite).Microsoft’s server has also grown inpopularity.
The popularity of Apache is also shown in the August 1998 Netcraft Web Server Survey
[16],which finds Apache to be the most widely used server followed by Microsoft-IISand Netscape-Enterprise.The Netcraft surveys are taken over a wider community thanthe academic sites looked at in this paper.The community surveyed by Netcraft is likelyto consist of more diverse platforms (such as PCs)whereas academic sites show a biastowards Unix systems.This may explain the differences in the results of the next mostpopular servers.
Table 2 shows a profile of HTTP headers.
Table 2 HTTP Headers
Note that this information was not collected for the first trawl due to limitations in therobot so ftware.
In Table 2 a resource is defined as cachable if:
It contains an Expi res header showing that the resource has not expired
It contains a La s t-Modif i ed header with a modification date greater than 1day prior to the robot trawl.
Itcontains the Cache-control: public header
A resource is defined as not cachable if:
It contains an Expi res header showing that the resource has expired
It contains a La s t-Modif i ed header with a modification date coinciding withthe day ofthe robot trawl
HowIsMyWebCommunityDeveloping?MonitoringTrends InWeb ServiceProvision 6
Itcontains the Cache-control: no-cache orCache-control: no-s t or e headers
It contains the Pragma: nocache header
The cachability of resources was not determined if the resource used the E t ag HTTP/1.1header, since this would require additional testing at the time of the trawl which was notcarried out.
Figure 1 gives a histogram of the total size of the institutional entry point.
1 1 1 1 1 1 1 1 1 1
Total size of entry point (Kb)
Figure 1 Size of Entry Point
As shown in Figure 1, four institutions appear to have an institutional web page which isless than 5Kbytes. The mean size is 41 Kb,with a mode of 10-20 Kb. The largest entrypoint is 193 Kbyes.
Note that this information is based on the size of the HTML file,any framed or refreshHTML pages, inline images and embedded Java applets.
HowIsMyWebCommunityDeveloping?MonitoringTrends InWeb ServiceProvision 7
It does not include any background images, since the current version ofthe robot does notparse the<BODY>element for the BACKGROUND attribute. Subsequent analysis showedthat 56 institutions used the BACKGROUND attribute in the<BODY>element.Althoughthis would increase the file size, it is unlikely to do so significantly as backgroundelements are typically small files.
The histogram also does not include any linked style sheet files. The WebWatch robotdoes not parse the HTML document for linked style sheets. In this the robot can beregarded as emulating a Netscape 3 browser.
Figure 2 gives a histogram for the number of images on the institutional entry point.Asmentioned previously this does not include any background images.
Figure 2 Numbers of Images
Figure 3 gives a histogram for the number of hypertext links from institutional entryp o ints.
HowIsMyWebCommunityDeveloping?MonitoringTrends InWeb ServiceProvision 8
#Hyperl ink elements per page
Figure 3 Link Profiles.
Note that F igure 3 gives the total number o f links which were found. This include s<A>elements and client-side image map s.Note that typically links in client-side maps areduplicated using the<A>element.No attempt has been made in this report to count thenumb er o f unique links.
Discussion of Findings
In this section we discuss the findings of the trawls.
The discussion covers the accessibility of the pages and the technologies used. In theaccessibility discussion we consider factors relevant to users accessing the pages,including the files sizes (which affects download times),whether the pages can be cached(which also affects download times)and the usage of hyperlinks (which can affect theusability). In the technology discussion we consider the technologies used, such as serverhardware and software,and web technologies such as use ofJavaScript and Java,metadata and styleshe ets.
HowIsMyWebCommunityDeveloping?MonitoringTrends InWeb ServiceProvision 9
- WebWandererHow Is My Web Community Developing Monitoring Trends In Web…相关文档
- periodPERIODIC TABLE TRENDS - SCHOOLinSITES Web hosting …元素周期表的趋势schoolinsites网页寄存…
- PCTechnological Trends of Distance Learning From Web-Based to WAP-Based
- 网页Mobile Web Design Trends and Best Practices
- higherPeriodic Trends Worksheet - Faculty Access for the Web
- specificInventory- likely to be underestimated three interesting web design trends
- demonstrateGrowing Trends article - NYSTA Web Site
提速啦 韩国服务器 E3 16G 3IP 450元/月 韩国站群服务器 E3 16G 253IP 1100元/月
提速啦(www.tisula.com)是赣州王成璟网络科技有限公司旗下云服务器品牌,目前拥有在籍员工40人左右,社保在籍员工30人+,是正规的国内拥有IDC ICP ISP CDN 云牌照资质商家,2018-2021年连续4年获得CTG机房顶级金牌代理商荣誉 2021年赣州市于都县创业大赛三等奖,2020年于都电子商务示范企业,2021年于都县电子商务融合推广大使。资源优势介绍:Ceranetwo...
极光KVM(限时16元),洛杉矶三网CN2,cera机房,香港cn2
极光KVM创立于2018年,主要经营美国洛杉矶CN2机房、CeRaNetworks机房、中国香港CeraNetworks机房、香港CMI机房等产品。其中,洛杉矶提供CN2 GIA、CN2 GT以及常规BGP直连线路接入。从名字也可以看到,VPS产品全部是基于KVM架构的。极光KVM也有明确的更换IP政策,下单时选择“IP保险计划”多支付10块钱,可以在服务周期内免费更换一次IP,当然也可以不选择,...
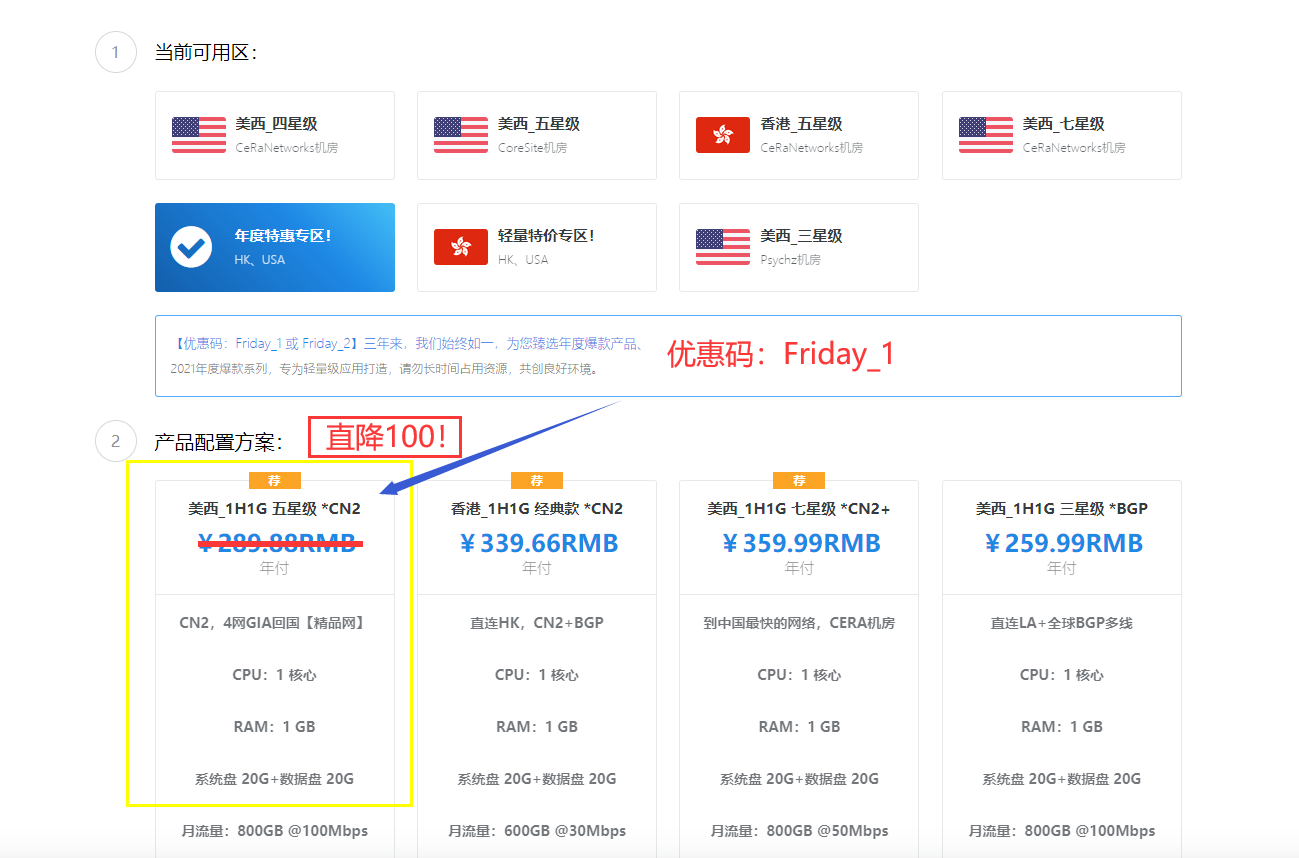
OneTechCloud(31元),美国CN2 GIA高防VPS月
OneTechCloud发布了本月促销信息,全场VPS主机月付9折,季付8折,优惠后香港VPS月付25.2元起,美国CN2 GIA线路高防VPS月付31.5元起。这是一家2019年成立的国人主机商,提供VPS主机和独立服务器租用,产品数据中心包括美国洛杉矶和中国香港,Cera的机器,VPS基于KVM架构,采用SSD硬盘,其中美国洛杉矶回程CN2 GIA,可选高防。下面列出部分套餐配置信息。美国CN...

-
qq空间首页QQ空间的主页免费阅读小说app哪个好想看小说有什么好用的app推荐?帕萨特和迈腾哪个好迈腾和帕萨特哪个好音乐播放器哪个好音乐播放器哪个最好用音乐播放器哪个好音乐播放器哪个好用浮动利率和固定利率哪个好房贷利率是固定的还是浮动的好?手机音乐播放器哪个好手机音乐播放器音质好的APP是那款杰士邦和杜蕾斯哪个好杜蕾斯好用还是杰士邦好要?手机管家哪个好最好的手机管家辽宁联通营业厅辽宁移动网上营业厅进入办法