yarnyarn是什么意思及反义词
yarn 时间:2021-07-28 阅读:()
Hadoop,MapReduce,YARN和Spark的区别与联系
(1) Hadoop 1.0 第一代Hadoop,由分布式存储系统HDFS和分布式计算框架MapReduce组成,其中,HDFS由一个NameNode和多个DataNode组成,MapReduce由一个JobTracker和多个TaskTracker组成,对应Hadoop版本为Hadoop 1.x和0.21.X,0.22.x。(2) Hadoop 2.0 第二代Hadoop,为克服Hadoop 1.0中HDFS和MapReduce存在的各种问题而提出的。
针对Hadoop 1.0中的单NameNode制约HDFS的扩展性问题,提出了HDFS Federation,它让多个NameNode分管不同的目录进而实现访问隔离和横向扩展;针对Hadoop 1.0中的MapReduce在扩展性和多框架支持方面的不足,提出了全新的资源管理框架YARN(Yet Another Resource Negotiator),它将JobTracker中的资源管理和作业控制功能分开,分别由组件ResourceManager和ApplicationMaster实现,其中,ResourceManager负责所有应用程序的资源分配,而ApplicationMaster仅负责管理一个应用程序。
对应Hadoop版本为Hadoop 0.23.x和2.x。
(3) MapReduce 1.0或者MRv1(MapReduceversion 1) 第一代MapReduce计算框架,它由两部分组成:编程模型(programming model)和运行时环境(runtime environment)。
它的基本编程模型是将问题抽象成Map和Reduce两个阶段,其中Map阶段将输入数据解析成key/value,迭代调用map()函数处理后,再以key/value的形式输出到本地目录,而Reduce阶段则将key相同的value进行规约处理,并将最终结果写到HDFS上。
它的运行时环境由两类服务组成:JobTracker和TaskTracker,其中,JobTracker负责资源管理和所有作业的控制,而TaskTracker负责接收来自JobTracker的命令并执行它。
(4)MapReduce 2.0或者MRv2(MapReduce version 2)或者NextGen MapReduc MapReduce 2.0或者MRv2具有与MRv1相同的编程模型,唯一不同的是运行时环境。
MRv2是在MRv1基础上经加工之后,运行于资源管理框架YARN之上的MRv1,它不再由JobTracker和TaskTracker组成,而是变为一个作业控制进程ApplicationMaster,且ApplicationMaster仅负责一个作业的管理,至于资源的管理,则由YARN完成。
简而言之,MRv1是一个独立的离线计算框架,而MRv2则是运行于YARN之上的MRv1。
(5)Hadoop-MapReduce(一个离线计算框架) Hadoop是google分布式计算框架MapReduce与分布式存储系统GFS的开源实现,由分布式计算框架MapReduce和分布式存储系统HDFS(Hadoop Distributed File System)组成,具有高容错性,高扩展性和编程接口简单等特点,现已被大部分互联网公司采用。
(6)Hadoop-YARN(Hadoop 2.0的一个分支,实际上是一个资源管理系统) YARN是Hadoop的一个子项目(与MapReduce并列),它实际上是一个资源统一管理系统,可以在上面运行各种计算框架(包括MapReduce、Spark、Storm、MPI等)。
当前Hadoop版本比较混乱,让很多用户不知所措。
实际上,当前Hadoop只有两个版本:Hadoop 1.0和Hadoop 2.0,其中,Hadoop 1.0由一个分布式文件系统HDFS和一个离线计算框架MapReduce组成,而Hadoop 2.0则包含一个支持NameNode横向扩展的HDFS,一个资源管理系统YARN和一个运行在YARN上的离线计算框架MapReduce。
相比于Hadoop 1.0,Hadoop 2.0功能更加强大,且具有更好的扩展性、性能,并支持多种计算框架。
/YARN/Mesos/Torca/Corona一类系统可以为公司构建一个内部的生态系统,所有应用程序和服务可以“和平而友好”地运行在该生态系统上。
有了这类系统之后,你不必忧愁使用Hadoop的哪个版本,是Hadoop 0.20.2还是 Hadoop 1.0,你也不必为选择何种计算模型而苦恼,因此各种软件版本,各种计算模型可以一起运行在一台“超级计算机”上了。
从开源角度看,YARN的提出,从一定程度上弱化了多计算框架的优劣之争。
YARN是在Hadoop MapReduce基础上演化而来的,在MapReduce时代,很多人批评MapReduce不适合迭代计算和流失计算,于是出现了Spark和Storm等计算框架,而这些系统的开发者则在自己的网站上或者论文里与MapReduce对比,鼓吹自己的系统多么先进高效,而出现了YARN之后,则形势变得明朗:MapReduce只是运行在YARN之上的一类应用程序抽象,Spark和Storm本质上也是,他们只是针对不同类型的应用开发的,没有优劣之别,各有所长,合并共处,而且,今后所有计算框架的开发,不出意外的话,也应是在YARN之上。
这样,一个以YARN为底层资源管理平台,多种计算框架运行于其上的生态系统诞生了。
目前spark是一个非常流行的内存计算(或者迭代式计算,DAG计算)框架,在MapReduce因效率低下而被广为诟病的今天,spark的出现不禁让大家眼前一亮。
从架构和应用角度上看,spark是一个仅包含计算逻辑的开发库(尽管它提供个独立运行的master/slave服务,但考虑到稳定后以及与其他类型作业的继承性,通常不会被采用),而不包含任何资源管理和调度相关的实现,这使得spark可以灵活运行在目前比较主流的资源管理系统上,典型的代表是mesos和yarn,我们称之为“spark on mesos”和“spark on yarn”。
将spark运行在资源管理系统上将带来非常多的收益,包括:与其他计算框架共享集群资源;资源按需分配,进而提高集群资源利用率等。
FrameWork On YARN 运行在YARN上的框架,包括MapReduce-On-YARN, Spark-On-YARN, Storm-On-YARN和Tez-On-YARN。
(1)MapReduce-On-YARN:YARN上的离线计算; (2)Spark-On-YARN:YARN上的内存计算; (3)Storm-On-YARN:YARN上的实时/流式计算; (4)Tez-On-YARN:YARN上的DAG计算
hadoop 1.0 yarn 和 hadoop 2.0 yarn有什么区别
1. Hadoop 1.0中的资源管理方案 Hadoop 1.0指的是版本为Apache Hadoop 0.20.x、1.x或者CDH3系列的Hadoop,内核主要由HDFS和MapReduce两个系统组成,其中,MapReduce是一个离线处理框架,由编程模型(新旧API)、运行时环境(JobTracker和TaskTracker)和数据处理引擎(MapTask和ReduceTask)三部分组成。Hadoop 1.0资源管理由两部分组成:资源表示模型和资源分配模型,其中,资源表示模型用于描述资源的组织方式,Hadoop 1.0采用“槽位”(slot)组织各节点上的资源,而资源分配模型则决定如何将资源分配给各个作业/任务,在Hadoop中,这一部分由一个插拔式的调度器完成。
Hadoop引入了“slot”概念表示各个节点上的计算资源。
为了简化资源管理,Hadoop将各个节点上的资源(CPU、内存和磁盘等)等量切分成若干份,每一份用一个slot表示,同时规定一个task可根据实际需要占用多个slot 。
通过引入“slot“这一概念,Hadoop将多维度资源抽象简化成一种资源(即slot),从而大大简化了资源管理问题。
更进一步说,slot相当于任务运行“许可证”,一个任务只有得到该“许可证”后,才能够获得运行的机会,这也意味着,每个节点上的slot数目决定了该节点上的最大允许的任务并发度。
为了区分Map Task和Reduce Task所用资源量的差异,slot又被分为Map slot和Reduce slot两种,它们分别只能被Map Task和Reduce Task使用。
Hadoop集群管理员可根据各个节点硬件配置和应用特点为它们分配不同的map slot数(由参数mapred.tasktracker.map.tasks.maximum指定)和reduce slot数(由参数mapred.tasktrackerreduce.tasks.maximum指定)。
Hadoop 1.0中的资源管理存在以下几个缺点: (1)静态资源配置。
采用了静态资源设置策略,即每个节点实现配置好可用的slot总数,这些slot数目一旦启动后无法再动态修改。
(2)资源无法共享。
Hadoop 1.0将slot分为Map slot和Reduce slot两种,且不允许共享。
对于一个作业,刚开始运行时,Map slot资源紧缺而Reduce slot空闲,当Map Task全部运行完成后,Reduce slot紧缺而Map slot空闲。
很明显,这种区分slot类别的资源管理方案在一定程度上降低了slot的利用率。
(3) 资源划分粒度过大。
这种基于无类别slot的资源划分方法的划分粒度仍过于粗糙,往往会造成节点资源利用率过高或者过低 ,比如,管理员事先规划好一个slot代表2GB内存和1个CPU,如果一个应用程序的任务只需要1GB内存,则会产生“资源碎片”,从而降低集群资源的利用率,同样,如果一个应用程序的任务需要3GB内存,则会隐式地抢占其他任务的资源,从而产生资源抢占现象,可能导致集群利用率过高。
(4) 没引入有效的资源隔离机制。
Hadoop 1.0仅采用了基于jvm的资源隔离机制,这种方式仍过于粗糙,很多资源,比如CPU,无法进行隔离,这会造成同一个节点上的任务之间干扰严重。
该部分具体展开讲解可阅读我的新书《Hadoop技术内幕:深入解析MapReduce架构设计与实现原理》 中“第6章 JobTracker内部实现剖析” 中的“6.7 Hadoop资源管理”。
2. Hadoop 2.0中的资源管理方案 Hadoop 2.0指的是版本为Apache Hadoop 0.23.x、2.x或者CDH4系列的Hadoop,内核主要由HDFS、MapReduce和YARN三个系统组成,其中,YARN是一个资源管理系统,负责集群资源管理和调度,MapReduce则是运行在YARN上离线处理框架,它与Hadoop 1.0中的MapReduce在编程模型(新旧API)和数据处理引擎(MapTask和ReduceTask)两个方面是相同的。
让我们回归到资源分配的本质,即根据任务资源需求为其分配系统中的各类资源。
在实际系统中,资源本身是多维度的,包括CPU、内存、网络I/O和磁盘I/O等,因此,如果想精确控制资源分配,不能再有slot的概念,最直接的方法是让任务直接向调度器申请自己需要的资源(比如某个任务可申请1.5GB 内存和1个CPU),而调度器则按照任务实际需求为其精细地分配对应的资源量,不再简单的将一个Slot分配给它,Hadoop 2.0正式采用了这种基于真实资源量的资源分配方案。
Hadoop 2.0(YARN)允许每个节点(NodeManager)配置可用的CPU和内存资源总量,而中央调度器则会根据这些资源总量分配给应用程序。
节点(NodeManager)配置参数如下: (1)yarn.nodemanager.resource.memory-mb 可分配的物理内存总量,默认是8*1024,即8GB。
(2)yarn.nodemanager.vmem-pmem-ratio 任务使用单位物理内存量对应最多可使用的虚拟内存量,默认值是2.1,表示每使用1MB的物理内存,最多可以使用2.1MB的虚拟内存总量。
(3)yarn.nodemanager.resource.cpu-vcore 可分配的虚拟CPU个数,默认是8。
为了更细粒度的划分CPU资源和考虑到CPU性能异构性,YARN允许管理员根据实际需要和CPU性能将每个物理CPU划分成若干个虚拟CPU,而每管理员可为每个节点单独配置可用的虚拟CPU个数,且用户提交应用程序时,也可指定每个任务需要的虚拟CPU个数。
比如node1节点上有8个CPU,node2上有16个CPU,且node1 CPU性能是node2的2倍,那么可为这两个节点配置相同数目的虚拟CPU个数,比如均为32,由于用户设置虚拟CPU个数必须是整数,每个任务至少使用node2 的半个CPU(不能更少了)。
此外,Hadoop 2.0还引入了基于cgroups的轻量级资源隔离方案,这大大降低了同节点上任务间的相互干扰,而Hadoop 1.0仅采用了基于JVM的资源隔离,粒度非常粗糙。
yarn是什么意思及反义词
yarn 英 [jɑ?n] 美 [jɑ?rn] n.纱;线;<口>故事 v.讲故事 只有近义词没有反义词: 【近义词】 story故事 tale故事 thread线 anecdote轶事 wool羊毛 spiel滔滔不绝的讲话... narrative故事 ount账户 tall story夸大的故事(鬼话)... tall tale荒诞不经的故事... shaggy-dog story冗长杂乱的故事... fish story吹牛
- yarnyarn是什么意思及反义词相关文档
- yarnyarnboss是什么牌子_yarnboss是什么牌子_YARNBOSS 特价_热门YARNBOSS
选择Vultr VPS主机不支持支付宝付款的解决方案
在刚才更新Vultr 新年福利文章的时候突然想到前几天有网友问到自己有在Vultr 注册账户的时候无法用支付宝付款的问题,当时有帮助他给予解决,这里正好顺带一并介绍整理出来。毕竟对于来说,虽然使用的服务器不多,但是至少是见过世面的,大大小小商家的一些特性特征还是比较清楚的。在这篇文章中,和大家分享如果我们有在Vultr新注册账户或者充值购买云服务器的时候,不支持支付宝付款的原因。毕竟我们是知道的,...

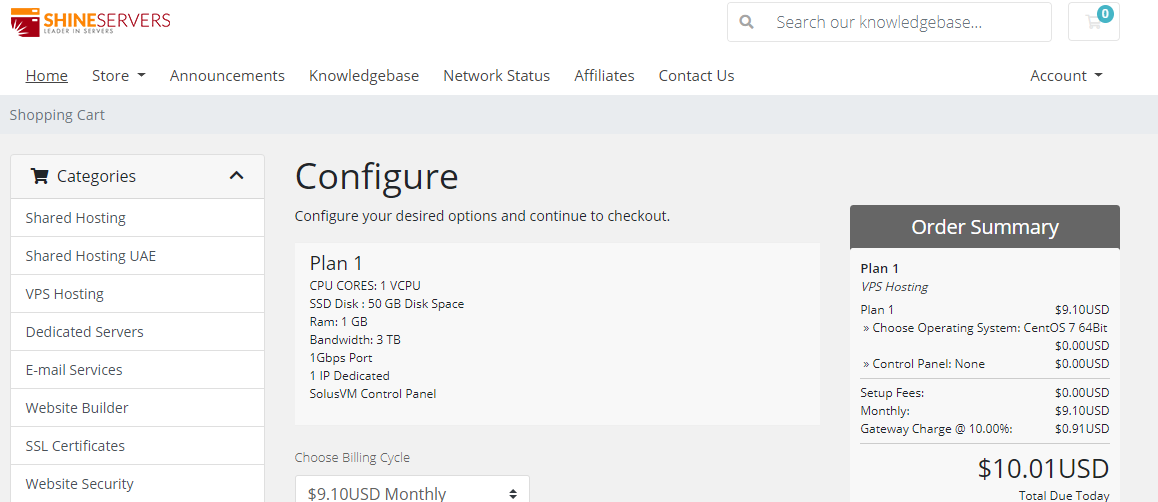
ShineServers(5美元/月)荷兰VPS、阿联酋VPS首月五折/1核1G/50GB硬盘/3TB流量/1Gbps带宽
优惠码50SSDOFF 首月5折50WHTSSD 年付5折15OFF 85折优惠,可循环使用荷兰VPSCPU内存SSD带宽IPv4价格购买1核1G50G1Gbps/3TB1个$ 9.10/月链接2核2G80G1Gbps/5TB1个$ 12.70/月链接2核3G100G1Gbps/7TB1个$ 16.30/月链接3核4G150G1Gbps/10TB1个$ 18.10/月链接阿联酋VPSCPU内存SS...
蓝速数据(58/年)秒杀服务器独立1核2G 1M
蓝速数据金秋上云季2G58/年怎么样?蓝速数据物理机拼团0元购劲爆?蓝速数据服务器秒杀爆产品好不好?蓝速数据是广州五联科技信息有限公司旗下品牌云计算平台、采用国内首选Zkeys公有云建设多种开通方式、具有IDC、ISP从业资格证IDC运营商新老用户值得信赖的商家。我司主要从事内地的枣庄、宿迁、深圳、绍兴、成都(市、县)。待开放地区:北京、广州、十堰、西安、镇江(市、县)。等地区数据中心业务,均KV...
yarn为你推荐
-
android半透明如何实现Android透明导航栏百度预测世界杯预测2018年世界杯哪两个国家会打入决赛?圣诞节网页制作我想在接下来的圣诞、元旦设计一个网站的宣传页面,哪里有好的公司帮我呢?iphone12或支持北斗导航苹果12几个版本人脸检测综述人脸检测技术的来源linux操作系统好吗linux好用不?金山铁路最新时刻表上海铁路时间表魔兽世界密保卡魔兽世界密保卡绑定罗振宇2017跨年演讲罗胖的 “侠爷泼妖” 是什么梗,跨年演讲时提到的~音响解码CD锁了怎么解