缓冲区怎样设置虚拟内存
第二部分端节点算法学端节点算法学端节点算法学:网络算法学在端节点(尤其是服务器)上的运用,是建立高速服务器的一组系统性技术随着网络功能虚拟化的提出,将来数据中心中绝大部分的网络设备都会在通用服务器上实现端节点算法学研究如何减少以下开销:数据拷贝(chapter5)控制转移(chapter6)定时器(chapter7)解复用(chapter8)其它一般性协议处理任务(chapter9)第五章拷贝数据消除不必要的拷贝(P1)网络报文在收发和处理的过程中,通常会被拷贝多次计算机中的数据拷贝消耗两个宝贵的资源:内存带宽:如果处理一个报文涉及k次拷贝,系统吞吐量可能降至1/k内存:如果一个报文在内存中被保存k份,有效内存容量降至1/k本章关注如何消除不必要的拷贝:一个拷贝如果不是由硬件要求的,该拷贝是不必要的本章还将讨论其它需要对数据包载荷进行的操作5.
1为什么要拷贝数据应用场景:用户向web服务器请求一个静态文件服务器从磁盘读出文件,发送到网络上两个内核子系统:文件子系统网络子系统一个简单的故事直观上,这是一个简单的故事:web应用程序通过一个系统调用(读文件),将文件从磁盘读入到它的缓冲区中构造一个HTTP响应头,通过一个系统调用(写套接字),将响应头和缓冲区内容交给网络子系统网络子系统将数据划分成适当大小的块,加上各层协议头,交给网络驱动程序一个真实的故事Copy1:硬盘文件缓冲区(内核空间)Copy2:文件缓冲区应用缓冲区(用户空间)Copy3:应用缓冲区套接字缓冲区(内核空间)Copy4:套接字缓冲区网卡TCP程序还需要扫描一遍数据,计算TCP检查和资源消耗情况拷贝和TCP检查和计算:每个字需要穿过内存总线7~9次!
不同内存区域之间的拷贝(copy2,copy3):每个字都要通过内存总线读一次和写一次计算TCP检查和:每个字都要通过内存总线读一次涉及外设的拷贝(copy1,copy4):如果由CPU做拷贝(PIO):每个字都要通过内存总线读一次和写一次如果由设备做拷贝(DMA):每个字只需通过内存总线读一次或写一次涉及外设的拷贝都需要消耗I/O总线带宽对服务器吞吐量的影响在上面的例子中:Web服务器吞吐量不超过T/7,T为内存速度和内存总线速度中的较小值有效的文件缓冲区大小仅为总容量的1/3多余的拷贝在两个方面损害了服务器的性能:由于使用了过多的总线和内存带宽,服务器的运行速度远远低于总线速度由于使用了过多的内存,服务器不得不更多地从磁盘而不是主存读文件如果请求动态内容,还要增加一次拷贝(CGI程序web服务器)请求动态内容Step6:CGI程序将构造好的网页文件,通过进程间通信机制传给web服务器程序,涉及一次拷贝5.
2消除copy4为什么需要copy4简单的解释:适配器内存和内核存储空间不在同一个硬件上但是,这个理由并不充分!
消除Copy4在一个内存映射的体系结构中,设备寄存器被映射到一块内存区域,CPU通过读写这块内存区域与设备通信理论上,内存可以位于总线上的任何地方,包括在适配器中消除copy4的解决方案:利用网络适配器中已有的存储空间(P4,利用系统组件),以及内核存储空间放置的自由度(P13,利用自由度),将套接字缓冲区放在网络适配器中应用缓冲区的内容直接拷贝到网络适配器的内存中如何计算TCP检查和如何计算检查和Witless方法(P2c,共享开销):CPU执行拷贝,当读入每个字时,捎带计算检查和致命的问题:接收的时候,当发现检查和出错时数据包已被写入应用缓冲区,与TCP语义不符(所以该方法从未被实施)Afterburner适配器(TCPoffloadingengine):数据传输由网卡通过DMA完成,检查和也由网卡计算TCP连接的管理(建立、关闭等)仍由主CPU完成,仅将建立好的TCP连接移交给网络适配器问题:网络适配器需要很大的内存空间和较强的处理器来支持大量的TCP连接,网卡成本可能较高5.
3消除Copy3为什么需要copy3应用和内核使用不同的虚拟地址空间(不是必要的)应用和内核之间需要通过数据拷贝解除耦合(必要的)如果拷贝不能避免,那么能够减小拷贝的开销吗写时拷贝(copy-on-write)当应用程序对内核执行一个写时拷贝时,OS将内核缓冲区映射到应用缓冲区的物理内存页上当应用程序试图修改其缓冲区时,内核进行真正的拷贝有些操作系统提供写时拷贝,很多情况下可以避免真正的拷贝写时拷贝的实现举例:假定进程P1的虚拟页X映射到物理页L上,需要复制X的内容到进程P2的虚拟页Y当P1对X进行写时拷贝时:内核修改页表,令Y指向物理页L将X表项的COW保护位置位当P1试图写页X时:硬件读X的COW位,发现置位,产生一个异常操作系统将物理页L拷贝到物理页L',清除X的COW位,令X指向L',Y继续指向L写时拷贝的实现(续)对于不提供写时拷贝功能的操作系统(如UNIX和Windows),也可以基于虚拟内存实现类似的功能:可以通过修改页表避免物理拷贝需要找到一种替代COW位的保护机制5.
4优化页面重映射对页面重映射过于简单的看法:只需修改P2的页表(一次写操作),令VP8指向存放包的物理页,所有工作就结束了(X)页面重映射的开销修改多级页表:实际映射可能要求修改多级页表,当页表不在内存中时要调入,并修改目录页要求锁操作:修改页表前后要有请求锁和释放锁的开销刷新TLB:新的地址映射写入页表时,相关TLB表项要清除或修正在目标域中分配虚拟内存:系统要在目标进程中找到一个空闲的页表表项锁住物理页:为防止页被换出,必须锁住物理页以上开销在多处理器系统中会被放大页面重映射虽然只需常数时间,但这个常数因子非常大结论:如果只是简单地使用页表重映射来避免拷贝,结果可能不像预期的那么好Fbufs(fastbuffers)基本观察:如果一个应用正在发送大量的数据包,那么一个包缓冲区可能会被重用多次方法一:提前分配好需要的包缓冲区,并计算好所有的页面映射信息(P2a),发送时重复使用这些包缓冲区方法二:数据传输开始时分配包缓冲区并计算页面映射,然后将其缓存起来(P11a),消除后续包的页面映射开销基本思想:映射一次,重复使用为应用分配一组固定的物理页为避免内核空间和用户空间之间的拷贝,将一组物理页P1、P2、……、Pk同时映射给内核和应用来使用数据包经过的一系列处理程序构成一个有序的安全域序列,定义为一条路径为每一条路径预留固定的一组物理页,数据包到达时立即确定其所属的路径(提前解复用)在路径上传递包缓冲区描述符对于每条路径,适配器有一个空闲缓冲区链表:适配器把数据包写入一个空闲缓冲区,将缓冲区描述符传给接收路径上的下一个进程最后一个进程将用完的缓冲区交还给第一个进程,缓冲区重新回到空闲缓冲区链表实现单向路径有序的安全域序列是一条单向路径:规定第一个进程是writer,其余进程是reader(为了提供一定的保护级别)给第一个进程的页表表项设置写允许位,给其它进程的页表表项设置只读位映射到同一个物理页的虚拟页号应相同在进程间传递缓冲区描述符的问题:理论上,各个进程映射到同一个物理页上的虚拟页号可能不同解决方法:规定:映射到同一个物理页的虚拟页号必须相同实现:所有进程的虚拟内存中一定数量的起始页预留为fbuf页收包处理过程P1从freefbufs队列取一个空闲缓冲区,写入数据包,将缓冲区的描述符写入writtenfbufs队列P2从writtenfbufs队列取包缓冲区描述符,读相应的包缓冲区P2将释放的包缓冲区描述符写回freefbufs队列如何添加包头在发送路径上,每一个安全域都要给数据包加上一个包头然而,为了实现保护,每条路径只允许一个writer,其余为reader问题:怎么允许其它安全域添加包头呢定义数据包为聚合数据结构将数据包定义为一个带有指针的聚合数据结构,每个指针指向一个fbuf给数据包添加包头,就是将一个fbuf添加到聚合数据结构中Fbufs总结Fbufs运用了虚拟内存映射的思想,通过在大量数据包之间分摊页面映射开销而做得更高效:包缓冲区映射一次,重复使用很多次消除了一般情形中的页表更新有人扩展了Fbufs思想,并实现在SunSolaris操作系统中IntelDPDK也运用了"一次映射,重复使用"的思想应用如何使用Fbufs大量已有的应用软件是根据拷贝语义的socketAPI写的:应用执行了write()系统调用后,就可以重用包缓冲区,甚至释放包缓冲区了采用fbufs后:在包缓冲区被其它进程使用完之前,应用不允许写或释放包缓冲区解决方案:修改应用API解决方法:API不再保持拷贝语义应用在写缓冲区之前必须进行判断安全的实现方法:当一个fbuf从应用传递到内核后,内核翻转一个写允许比特,归还fbuf时再重新设置该位若应用在不允许写的情况下做写操作,会产生一个异常,应用崩溃,但不影响其它进程已有的网络应用软件必须重写吗方法一:给已有的API增加新的系统调用,要求高性能的应用使用新的系统调用进行重写方法二:用新的扩展实现一个公共的I/O库,链接到该库的应用不需要修改,就可以得到性能提升实践表明,将应用移植到类fbuf的API,对应用所做的修改不大,且是局部的5.
5使用RDMA避免拷贝在web服务器的例子中:Web服务器接收请求,将文件传输到网络上Web服务器作为接收端并不需要保存请求消息现考虑在两个计算机之间传输一个大文件,接收端采用以下方式之一收包:采用fbufs采用TOE网卡采用fbufs收包包到达网卡后,被拷贝到一个包缓冲区中包缓冲区描述符在路径上传递,各安全域处理包应用程序将包数据拷贝到应用缓冲区,释放包缓冲区采用TOE网卡收包包到达网卡后,被送入套接字缓冲区进行协议处理和重组DMA控制器将数据送入应用缓冲区,向CPU发出中断驱动程序处理中断,通知内核模块接收数据,交给应用应用拷贝数据到文件缓冲区,应用缓冲区返回给网卡直接内存访问(DMA)在上述两种方法中,CPU要参与数据传输,且数据到达目的计算机的内存后还要拷贝一次使用DMA在外设和内存之间传输数据,不需要CPU的参与:CPU设置DMA(给出数据的存放地址、长度等)DMA控制器完成数据传输DMA控制器通过中断通知CPU传输完成受DMA的启发,能否在两台计算机的内存之间直接传输数据,而不需要CPU参与远程直接内存访问(RDMA)RDMA的愿景:数据在两台计算机的主存之间直接传输,不需要CPU参与到数据传输的过程中两个网络适配器协作地从一个主存读数据,然后写入另一个主存RDMA需要解决的问题除了需要网卡执行TCP/IP协议外,RDMA还需解决两个问题:接收端适配器如何知道应将数据放在哪儿(不能求助CPU)如何保证安全(发送进程不能随意写目标终端的内存)VAX集群的RDMARDMA在VAX集群中已经被使用,VAX集群为可伸缩应用(如数据库应用)提供计算平台:系统核心是一个140Mb/s的网络(称ComputerInterconnect,CL),使用一个以太网风格的协议用户可以将许多VAX计算机和网络硬盘连接到CLRDMA的需求背景:在远程硬盘和VAX机的内存之间有效传输大量数据要求包含文件数据的包在进入目的适配器之后,直接到达它的存放位置传统网络的接收端接收端应用提前将一些映射好的页放入一个队列,交给网络适配器使用到达网卡的数据包被依次放入这些页中(数据包可能乱序到达)接收完数据包后,CPU做一个重映射(使得在应用看来,数据按顺序存放在一个地址连续的缓冲区中).
若文件很大,重映射的开销很大.
VAX的RDMA解决方案接收端应用锁住一些物理页,用作文件传输的目标存储区域(其呈现出来的逻辑视图是由地址连续的虚拟页组成的一个缓冲区),缓冲区ID被发送给发送端应用发送端应用将缓冲区ID及包存放的偏移量,随同数据包一起发送到接收端接收端适配器根据缓冲区ID和偏移量,将数据包内容存放到指定的位置(不需要页面重映射)如何保证安全允许将一个携带缓冲区ID的网络包直接写入内存,是一个明显的安全隐患为降低安全风险,缓冲区ID中包含一个难以猜测的随机串(防止伪造)VAX集群只在本集群内部可信的计算机之间使用RDMA传递数据RDMA的应用存储区域网(StorageAreaNetwork,SAN):一种后端网络,将大量计算机和网络硬盘连接在一起目前有好几种这样的技术,都使用了RDMA的思想,如FiberChannel(FC)、iSCSI、Infiniband等数据中心支持高性能分布式计算:大数据分析(MapReduce框架)深度学习(TensorFlow、Caffe等)5.
6把避免拷贝技术扩展到文件系统为提高响应速度,Copy1是必要的考虑消除copy25.
6.
1共享内存方法类UNIX操作系统提供一个系统调用mmap(),允许应用(如web服务器)将一个文件映射到自己的虚拟地址空间.
概念上,当一个文件被映射到一个应用的地址空间,这个应用就好像在自己的内存中缓存了这份文件.
当然,这个缓存的文件只是一组映射.
如果Web程序将文件映射到自己的地址空间,则它和文件cache访问的是同一组物理页(免除了拷贝).
FlashWeb服务器Web应用程序将经常用到的文件映射到自己的内存空间受到可分配给文件页的物理页数量及页表映射的限制,FlashWeb服务器只能缓存和映射最近常用的文件事实上,FlashWeb服务器只是缓存了一些文件分片(通常是文件的头几个分片),并使用LRU策略将最近一段时间未用的文件unmap尚未解决的问题FlashWeb不能避免web服务器与CGI进程之间的拷贝文件缓存只能缓存静态内容,动态网页要由CGI程序生成CGI程序生成的动态内容通过UNIX管道传给web服务器;典型地,管道要在两个地址空间之间拷贝内容到目前为止,我们的方案都没有涉及TCP检查和一个被访问多次的文件,文件分片都相同,但TCP检查和未被缓存需要一个从包内容映射到检查和的高速缓存,即数组,a为包内容,f(a)为检查和;由于a太大,采用传统缓存方案很低效由fbufs和mmap()想到的问题fbufs可以消除copy3mmap()可以消除copy2Q:能否将fbufs和mmap()结合起来使用,同时消除copy2和copy3可以结合fbufs和mmap吗如果采用fbufs:所有进程的虚拟内存中一定数量的起始页预留为fbuf页应用进程的应用缓冲区不能被映射到这些物理页上如果应用将文件映射到其虚拟地址空间的一个缓冲区:这个缓冲区不能用fbuf发送,必须要有一次物理拷贝!
当消除copy2时,copy3不能避免!
5.
6.
2IO-LiteIO-Lite将fbufs推广至包含文件系统,从而不必使用mmapIO-Lite可以一揽子解决前面所有的问题:同时消除copy2和copy3消除CGI程序和web服务器之间的拷贝缓存传送过的数据包的检查和IO-Lite的主要思想IO-Lite借用了fbufs的主要思想:为同一条路径上的进程映射相同的物理页,实现只读共享推迟创建路径的缓冲区使用缓冲区聚合以允许添加包头IO-Lite响应Get请求IO-Lite响应Get请求的步骤当文件第一次从磁盘读入文件系统的高速缓存时,文件页被保存为IO-Litebuffer当应用通过一个系统调用读文件时,创建一个缓冲区聚合体,指针指向IO-Litebuffer当应用发送文件给TCP时,网络子系统得到一个指向相同IO-Lite页的指针应用将常用文件的HTTP响应头维护在一个高速缓存中IO-Lite给每个缓冲区分配一个编号,TCP模块维护一个以缓冲区编号为索引的检查和高速缓存实现零拷贝的管道IO-Lite也可以用来实现一个消除了拷贝的改良型管道程序(传递IO-Litebuffer的指针而不是拷贝)将改良后的管道应用到CGI程序和web服务器之间,可以消除冗余的拷贝实现IO-LiteIO-Lite必须处理复杂的共享模式:应用程序、TCP程序和文件服务器等均可能有指向IO-Litebuffer的缓冲区IO-Lite必须实现一个复杂的替换策略:IO-Lite页既可能是虚拟内存页又可能是文件页需将标准的页替换规则和文件缓存替换策略集成在一起找到一种干净的方法将IO-Lite集成到OS中IO-Lite已经在UNIX中实现了5.
6.
3使用I/O拼接避免文件系统拷贝I/O拼接的基本思想:引入一个新的系统调用sendfile(),允许内核将读文件的调用和向网络发送消息的调用合并文件到socket传输的传统方法需两次系统调用:read(file,tem_buf,len);write(socket,tmp_buf,len);使用sendfile()传输文件到socket:sendfile(socket,file,len);内核2.
1版本的sendfile实现调用sendfile()时:文件数据先被拷贝到内核中的文件缓冲区(copy1)然后从文件缓冲区拷贝到内核中的socket缓冲区(合并copy2和copy3)最后从socket缓冲区拷贝到适配器(copy4)与read/write方式相比,减少了一次拷贝内核版本2.
4之后的sendfile实现调用sendfile()时:文件数据先被拷贝到内核中的文件缓冲区(copy1)将记录数据位置和长度的信息保存到socket缓冲区数据通过DMA通道直接发送到适配器(copy4)消除了copy2和copy3基于sendfile的机制不能推广到与CGI程序通信Sendfile()已用于Apache、Nginx、Lighttpd等web服务器中5.
7扩展到拷贝之外除数据拷贝外,其它涉及所有数据的操作也是高开销操作,如检查和计算、格式转换等:需要CPU参与需要使用内存总线计算开销与数据长度成正比将拷贝循环扩展到包括检查和计算:利用load和store之间的空周期做累加计算不增加任何额外的开销IntegratedLayerProcessing(ILP)除检查和之外,其它数据密集的操作能否都集成到拷贝循环中整合层次处理(ILP)的主要思想:对同一个数据包进行多种数据操作时,将这些操作整合在一个循环中,避免对包中的数据进行多次的读和写(P1).
整合层次处理会有什么问题ILP面临的问题问题一:不同操作需要的信息一般来自不同的层次,将不同层次的代码整合在一起而不牺牲模块化特性极其困难问题二:不同操作可能需要在不同长度的数据块上以及数据包的不同部位进行问题三:有些操作可能是相互依赖的.
比如,如果数据包的TCP检查和验证失败,就不应当对包进行解密操作ILP面临的问题(续)问题四:过分提高整合度可能降低代码的局部性,增大指令cache的miss率,反而产生不良的后果结论:ILP很难实现(问题1~问题3)ILP可能性能不佳(问题4)ILP可能完全没有必要(若包数据需要被处理几次,则数据很可能驻留在cache中)目前只有检查和计算被整合在数据拷贝过程中5.
8扩展到数据操作之外消除数据拷贝和整合数据操作,其技术共同点都是避免冗余的读/写操作,以减少对内存总线的压力还有哪些因素会影响内存总线的使用呢Cache的使用效率DMA或PIO的选择5.
8.
1有效使用I-cache处理器包含一个或多个数据cache,以及一个或多个指令cache:一般而言,包数据几乎不能从d-cache获得好处处理数据包需要的状态可以从d-cache获益处理数据包的程序代码可以从I-cache获益代码和状态都可能竞争内存带宽,相比而言,代码对内存带宽的竞争更严重:处理一个包需要的状态一般较小,比如一个连接表项协议栈处理的代码大得多,而I-cache的容量一般很小高效地利用I-cache是提高性能的一个关键I-Cache的实现特点(1)大多数处理器使用直接映射的I-cache:内存地址的低位比特用来检索I-cache条目如果高位比特匹配,直接从I-cache返回内容若不匹配,进行一个主存访问,用新的内容替换原来的条目问题:被映射到I-cache同一位置的代码会被轮流替换出去,即使它们都是经常使用的代码.
I-Cache的实现特点(2)每一条I-cache包含多条指令:当取一条指令时,同一个代码块中的全部指令都会被读入(基于空间局部性假设做的优化)问题:不常用的代码会被读入I-cache,如果它与常用代码在一个块中.
举例许多网络代码包含错误检查,比如:iferrorEdoX,elsedoZ虽然Z几乎从不被执行,但是编译器通常会将Z的代码紧跟在X的后面如果X和Z位于同一个指令块中,取经常使用的代码X,会把不经常使用的代码Z也取进来,浪费了内存带宽和cache空间问题与解决方案指令cache没有很好地反映时间局部性:经常使用的代码不一定在cache中:由一个不完美的映射函数引起不常使用的代码可能被经常调入cache:由cache对空间局部性的优化引起如何解决以上问题重新组织代码,将经常使用的代码连续放置重新组织代码如果工作集超过了I-cache的大小,第一个问题仍会出现,但会减少,而第二个问题能够得到很大程度的缓解代码布局的基本思想:通过优化代码在内存中的位置,使得经常使用的代码驻留在I-cache中新的问题处理包的协议代码肯定无法全部装入指令cache:I-cache的容量非常有限计算机上的所有程序都要竞争I-cache问题:如果每处理一个包,就要将全部的协议代码装入I-cache一次,效率太低!
!
拷贝数据包的开销和将代码装入I-cache的开销比起来,简直就是微不足道!
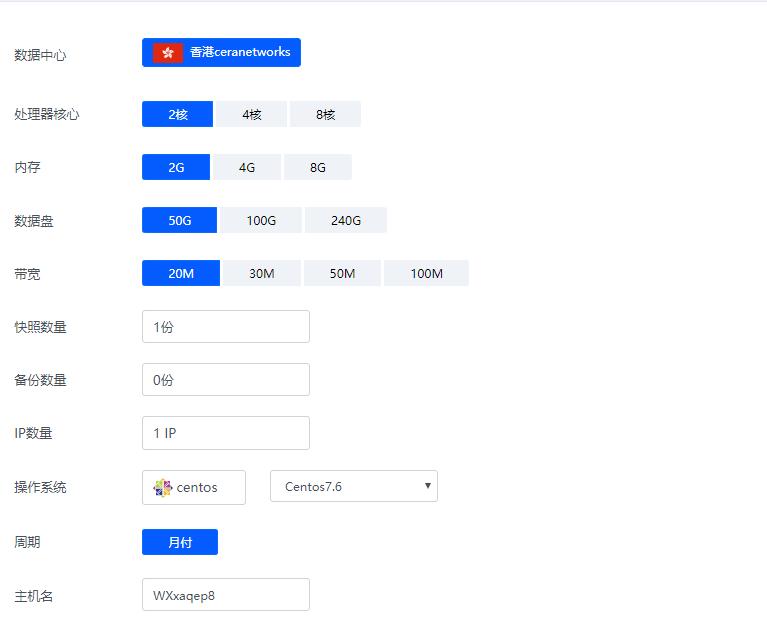
香港ceranetworks(69元/月) 2核2G 50G硬盘 20M 50M 100M 不限流量
香港ceranetworks提速啦是成立于2012年的十分老牌的一个商家这次给大家评测的是 香港ceranetworks 8核16G 100M 这款产品 提速啦老板真的是豪气每次都给高配我测试 不像别的商家每次就给1核1G,废话不多说开始跑脚本。香港ceranetworks 2核2G 50G硬盘20M 69元/月30M 99元/月50M 219元/月100M 519元/月香港ceranetwork...
易速互联月付299元,美国独立服务器促销,加州地区,BGP直连线路,10G防御
易速互联怎么样?易速互联是国人老牌主机商家,至今已经成立9年,商家销售虚拟主机、VPS及独立服务器,目前商家针对美国加州萨克拉门托RH数据中心进行促销,线路采用BGP直连线路,自带10G防御,美国加州地区,100M带宽不限流量,月付299元起,有需要美国不限流量独立服务器的朋友可以看看。点击进入:易速互联官方网站美国独立服务器优惠套餐:RH数据中心位于美国加州、配置丰富性价比高、10G DDOS免...
百星数据(60元/月,600元/年)日本/韩国/香港cn2 gia云服务器,2核2G/40G/5M带宽
百星数据(baixidc),2012年开始运作至今,主要提供境外自营云服务器和独立服务器出租业务,根据网络线路的不同划分为:美国cera 9929、美国cn2 gia、香港cn2 gia、韩国cn2 gia、日本cn2 gia等云服务器及物理服务器业务。目前,百星数据 推出的日本、韩国、香港cn2 gia云服务器,2核2G/40G/5M带宽低至60元/月,600元/年。百星数据优惠码:优惠码:30...

-
全能虚拟主机那家虚拟主机服务商比较不错,比较有名?域名代理怎样通过卖域名赚钱?国外主机空间2个国外主机空间,都放了BLOG,看看哪个更快?jsp虚拟空间jsp虚拟主机有支持的吗1g虚拟主机我要做一个下载资料类网站,刚买了一个虚拟主机1G的,提供商说一次,只能上传一个小于10M的文件山东虚拟主机400电话哪家代理商办理得比较好天津虚拟主机天津哪个是新网互联代理呢,我打算购买邮局?美国免费虚拟主机哪有便宜的美国虚拟主机?246数据美国虚拟主机一年才40元http://246idc.com/host/美国虚拟主机购买美国虚拟主机如何购买jsp虚拟主机java虚拟主机空间怎么选择,国内jsp虚拟主机比较稳定,现在java项目做好后需要推荐一下吧