mapreduce编程hadoop上运行mapreduce程序是在什么模式下
mapreduce编程 时间:2021-07-14 阅读:()
将之前mapreduce生成的文件作为新一次mapreduce的输入文件,怎么划分字段
你第一个job应该使用的是TextOutputFormat,所以输出默认是key-value形式的文本文档,当作为输入之后默认是使用TextOutputFormat,读入的key是每行的偏移量而非上一个job输出时的key,这是需要显示设置第二个job的输入格式为KeyValueInputFormat。什么是MapReduce?
概念"Map(映射)"和"Reduce(化简)",和他们的主要思想,都是从函数式编程语言里借来的,还有从矢量编程语言里借来的特性。他极大地方便了编程人员在不会分布式并行编程的情况下,将自己的程序运行在分布式系统上。
当前的软件实现是指定一个Map(映射)函数,用来把一组键值对映射成一组新的键值对,指定并发的Reduce(化简)函数,用来保证所有映射的键值对中的每一个共享相同的键组。
映射和化简 简单说来,一个映射函数就是对一些独立元素组成的概念上的列表(例如,一个测试成绩的列表)的每一个元素进行指定的操作(比如前面的例子里,有人发现所有学生的成绩都被高估了一分,他可以定义一个“减一”的映射函数,用来修正这个错误。
)。
事实上,每个元素都是被独立操作的,而原始列表没有被更改,因为这里创建了一个新的列表来保存新的答案。
这就是说,Map操作是可以高度并行的,这对高性能要求的应用以及并行计算领域的需求非常有用。
而化简操作指的是对一个列表的元素进行适当的合并(继续看前面的例子,如果有人想知道班级的平均分该怎么做?他可以定义一个化简函数,通过让列表中的元素跟自己的相邻的元素相加的方式把列表减半,如此递归运算直到列表只剩下一个元素,然后用这个元素除以人数,就得到了平均分。
)。
虽然他不如映射函数那么并行,但是因为化简总是有一个简单的答案,大规模的运算相对独立,所以化简函数在高度并行环境下也很有用。
编辑本段分布和可靠性 MapReduce通过把对数据集的大规模操作分发给网络上的每个节点实现可靠性;每个节点会周期性的把完成的工作和状态的更新报告回来。
如果一个节点保持沉默超过一个预设的时间间隔,主节点(类同Google File System中的主服务器)记录下这个节点状态为死亡,并把分配给这个节点的数据发到别的节点。
每个操作使用命名文件的原子操作以确保不会发生并行线程间的冲突;当文件被改名的时候,系统可能会把他们复制到任务名以外的另一个名字上去。
(避免副作用)。
化简操作工作方式很类似,但是由于化简操作在并行能力较差,主节点会尽量把化简操作调度在一个节点上,或者离需要操作的数据尽可能近的节点上了;这个特性可以满足Google的需求,因为他们有足够的带宽,他们的内部网络没有那么多的机器。
用途 在Google,MapReduce用在非常广泛的应用程序中,包括“分布grep,分布排序,web连接图反转,每台机器的词矢量,web访问日志分析,反向索引构建,文档聚类,机器学习,基于统计的机器翻译...”值得注意的是,MapReduce实现以后,它被用来重新生成Google的整个索引,并取代老的ad hoc程序去更新索引。
MapReduce会生成大量的临时文件,为了提高效率,它利用Google文件系统来管理和访问这些文件。
mapreduce,spark和yarn的区别是什么?
Hadoop 它是一个分布式系统基础架构,由Apache基金会所开发。用户可以在不了解分布式底层细节的情况下,开发分布式程序。
充分利用集群的威力进行高速运算和存储。
Hadoop的框架最核心的设计就是:HDFS和MapReduce.HDFS为海量的数据提供了存储,则MapReduce为海量的数据提供了计算。
Yarn 它是Hadoop2.0的升级版。
Yarn 的优点: 这个设计大大减小了 JobTracker(也就是现在的 ResourceManager)的资源消耗,并且让监测每一个 Job 子任务 (tasks) 状态的程序分布式化了,更安全、更优美。
在新的 Yarn 中,ApplicationMaster 是一个可变更的部分,用户可以对不同的编程模型写自己的 AppMst,让更多类型的编程模型能够跑在 Hadoop 集群中,可以参考 hadoop Yarn 官方配置模板中的 mapred-site.xml 配置。
对于资源的表示以内存为单位 ( 在目前版本的 Yarn 中,没有考虑 cpu 的占用 ),比之前以剩余 slot 数目更合理。
老的框架中,JobTracker 一个很大的负担就是监控 job 下的 tasks 的运行状况,现在,这个部分就扔给 ApplicationMaster 做了,而 ResourceManager 中有一个模块叫做 ApplicationsMasters( 注意不是 ApplicationMaster),它是监测 ApplicationMaster 的运行状况,如果出问题,会将其在其他机器上重启。
Container 是 Yarn 为了将来作资源隔离而提出的一个框架。
这一点应该借鉴了 Mesos 的工作,目前是一个框架,仅仅提供 java 虚拟机内存的隔离 ,hadoop 团队的设计思路应该后续能支持更多的资源调度和控制 , 既然资源表示成内存量,那就没有了之前的 map slot/reduce slot 分开造成集群资源闲置的尴尬情况。
Spark Spark是UC Berkeley AMP lab所开源的类Hadoop MapReduce的通用的并行计算框架,Spark基于map reduce算法实现的分布式计算,拥有Hadoop MapReduce所具有的优点;但不同于MapReduce的是Job中间输出结果可以保存在内存中,从而不再需要读写HDFS,因此Spark能更好地适用于数据挖掘与机器学习等需要迭代的map reduce的算法。
他们三个其实也可以说Hadoop发展的几个阶段,目前Spark非常火,是用Scala语言写的。
如何用mapreduce解决实际问题
MapReduce从出现以来,已经成为Apache Hadoop计算范式的扛鼎之作。它对于符合其设计的各项工作堪称完美:大规模日志处理,ETL批处理操作等。
随着Hadoop使用范围的不断扩大,人们已经清楚知道MapReduce不是所e68a8462616964757a686964616f31333363363434有计算的最佳框架。
Hadoop 2将资源管理器YARN作为自己的顶级组件,为其他计算引擎的接入提供了可能性。
如Impala等非MapReduce架构的引入,使平台具备了支持交互式SQL的能力。
今天,Apache Spark是另一种这样的替代,并且被称为是超越MapReduce的通用计算范例。
也许您会好奇:MapReduce一直以来已经这么有用了,怎么能突然被取代看毕竟,还有很多ETL这样的工作需要在Hadoop上进行,即使该平台目前也已经拥有其他实时功能。
值得庆幸的是,在Spark上重新实现MapReduce一样的计算是完全可能的。
它们可以被更简单的维护,而且在某些情况下更快速,这要归功于Spark优化了刷写数据到磁盘的过程。
Spark重新实现MapReduce编程范式不过是回归本源。
Spark模仿了Scala的函数式编程风格和API。
而MapReduce的想法来自于函数式编程语言LISP。
尽管Spark的主要抽象是RDD(弹性分布式数据集),实现了Map,reduce等操作,但这些都不是Hadoop的Mapper或Reducer API的直接模拟。
这些转变也往往成为开发者从Mapper和Reducer类平行迁移到Spark的绊脚石。
与Scala或Spark中经典函数语言实现的map和reduce函数相比,原有Hadoop提供的Mapper和Reducer API 更灵活也更复杂。
这些区别对于习惯了MapReduce的开发者而言也许并不明显,下列行为是针对Hadoop的实现而不是MapReduce的抽象概念: · Mapper和Reducer总是使用键值对作为输入输出。
· 每个Reducer按照Key对Value进行reduce。
· 每个Mapper和Reducer对于每组输入可能产生0个,1个或多个键值对。
· Mapper和Reducer可能产生任意的keys和values,而不局限于输入的子集和变换。
Mapper和Reducer对象的生命周期可能横跨多个map和reduce操作。
它们支持setup和cleanup方法,在批量记录处理开始之前和结束之后被调用。
本文将简要展示怎样在Spark中重现以上过程,您将发现不需要逐字翻译Mapper和Reducer! 作为元组的键值对 假定我们需要计算大文本中每一行的长度,并且报告每个长度的行数。
在HadoopMapReduce中,我们首先使用一个Mapper,生成为以行的长度作为key,1作为value的键值对。
public class LineLengthMapper extends Mapper<LongWritable, Text, IntWritable, IntWritable> { @Override protected void map(LongWritable lineNumber, Text line, Context context) throws IOException, InterruptedException { context.write(new IntWritable(line.getLength()), new IntWritable(1)); } } 值得注意的是Mappers和Reducers只对键值对进行操作。
所以由TextInputFormat提供输入给LineLengthMapper,实际上也是以文本中位置为key(很少这么用,但是总是需要有东西作为Key),文本行为值的键值对。
与之对应的Spark实现: lines.map(line => (line.length, 1)) Spark中,输入只是String构成的RDD,而不是key-value键值对。
Spark中对key-value键值对的表示是一个Scala的元组,用(A,B)这样的语法来创建。
上面的map操作的结果是(Int,Int)元组的RDD。
当一个RDD包含很多元组,它获得了多个方法,如reduceByKey,这对再现MapReduce行为将是至关重要的。
Reduce reduce()与reduceBykey() 统计行的长度的键值对,需要在Reducer中对每种长度作为key,计算其行数的总和作为value。
public class LineLengthReducer extends Reducer<IntWritable, IntWritable, IntWritable, IntWritable> { @Override protected void reduce(IntWritable length, Iterable<IntWritable> counts, Context context) throws IOException, InterruptedException { int sum = 0; for (IntWritable count : counts) { sum += count.get(); } context.write(length, new IntWritable(sum)); } } Spark中与上述Mapper,Reducer对应的实现只要一行代码: val lengthCounts = lines.map(line => (line.length, 1)).reduceByKey(_ + _) Spark的RDD API有个reduce方法,但是它会将所有key-value键值对reduce为单个value。
这并不是Hadoop MapReduce的行为,Spark中与之对应的是ReduceByKey。
另外,Reducer的Reduce方法接收多值流,并产生0,1或多个结果。
而reduceByKey,它接受的是一个将两个值转化为一个值的函数,在这里,就是把两个数字映射到它们的和的简单加法函数。
此关联函数可以被调用者用来reduce多个值到一个值。
与Reducer方法相比,他是一个根据Key来Reduce Value的更简单而更精确的API。
Mapper map() 与 flatMap() 现在,考虑一个统计以大写字母开头的单词的个数的算法。
对于每行输入文本,Mapper可能产生0个,1个或多个键值对。
public class CountUppercaseMapper extends Mapper<LongWritable, Text, Text, IntWritable> { @Override protected void map(LongWritable lineNumber, Text line, Context context) throws IOException, InterruptedException { for (String word : line.toString().split(" ")) { if (Character.isUpperCase(word.charAt(0))) { context.write(new Text(word), new IntWritable(1)); } } } } Spark对应的写法: lines.flatMap( _.split(" ").filter(word => Character.isUpperCase(word(0))).map(word => (word,1)) ) 简单的Spark map函数不适用于这种场景,因为map对于每个输入只能产生单个输出,但这个例子中一行需要产生多个输出。
所以,和MapperAPI支持的相比,Spark的map函数语义更简单,应用范围更窄。
Spark的解决方案是首先将每行映射为一组输出值,这组值可能为空值或多值。
随后会通过flatMap函数被扁平化。
数组中的词会被过滤并被转化为函数中的元组。
这个例子中,真正模仿Mapper行为的是flatMap,而不是map。
groupByKey() 写一个统计次数的reducer是简单的,在Spark中,reduceByKey可以被用来统计每个单词的总数。
比如出于某种原因要求输出文件中每个单词都要显示为大写字母和其数量,在MapReduce中,实现如下: public class CountUppercaseReducer extends Reducer<Text, IntWritable, Text, IntWritable> { @Override protected void reduce(Text word, Iterable<IntWritable> counts, Context context) throws IOException, InterruptedException { int sum = 0; for (IntWritable count : counts) { sum += count.get(); } context .write(new Text(word.toString().toUpperCase()), new IntWritable(sum)); } } 但是redeceByKey不能单独在Spark中工作,因为他保留了原来的key。
为了在Spark中模拟,我们需要一些更像Reducer API的操作。
我们知道Reducer的reduce方法接受一个key和一组值,然后完成一组转换。
groupByKey和一个连续的map操作能够达到这样的目标: groupByKey().map { case (word,ones) => (word.toUpperCase, ones.sum) } groupByKey只是将某一个key的所有值收集在一起,并且不提供reduce功能。
以此为基础,任何转换都可以作用在key和一系列值上。
此处,将key转变为大写字母,将values直接求和。
setup()和cleanup() 在MapReduce中,Mapper和Reducer可以声明一个setup方法,在处理输入之前执行,来进行分配数据库连接等昂贵资源,同时可以用cleanup函数可以释放资源。
public class SetupCleanupMapper extends Mapper<LongWritable, Text, Text, IntWritable> { private Connection dbConnection; @Override protected void setup(Context context) { dbConnection = ...; } ... @Override protected void cleanup(Context context) { dbConnection.close(); } } Spark中的map和flatMap方法每次只能在一个input上操作,而且没有提供在转换大批值前后执行代码的方法,看起来,似乎可以直接将setup和cleanup代码放在Sparkmap函数调用之前和之后: val dbConnection = ... lines.map(... dbConnection.createStatement(...) ...) dbConnection.close() // Wrong! 然而这种方法却不可行,原因在于: · 它将对象dbConnection放在map函数的闭包中,这需要他是可序列化的(比如,通过java.io.Serializable实现)。
而数据库连接这种对象一般不能被序列化。
· map是一种转换,而不是操作,并且拖延执行。
连接对象不能被及时关闭。
· 即便如此,它也只能关闭driver上的连接,而不是释放被序列化拷贝版本分配的资源连接。
事实上,map和flatMap都不是Spark中Mapper的最接近的对应函数,Spark中Mapper的最接近的对应函数是十分重要的mapPartitions()方法,这个方法能够不仅完成单值对单值的映射,也能完成一组值对另一组值的映射,很像一个批映射(bulkmap)方法。
这意味着mapPartitions()方法能够在开始时从本地分配资源,并在批映射结束时释放资源。
添加setup方法是简单的,添加cleanup会更困难,这是由于检测转换完成仍然是困难的。
例如,这样是能工作的: lines.mapPartitions { valueIterator => val dbConnection = ... // OK val transformedIterator = valueIterator.map(... dbConnection ...) dbConnection.close() // Still wrong! May not have evaluated iterator transformedIterator } 一个完整的范式应该看起来类似于: lines.mapPartitions { valueIterator => if (valueIterator.isEmpty) { Iterator[...]() } else { val dbConnection = ... valueIterator.map { item => val transformedItem = ... if (!valueIterator.hasNext) { dbConnection.close() } transformedItem } } } 虽然后者代码翻译注定不如前者优雅,但它确实能够完成工作。
flatMapPartitions方法并不存在,然而,可以通过调用mapPartitions,后面跟一个flatMap(a= > a)的调用达到同样效果。
带有setup和cleanup的Reducer对应只需仿照上述代码使用groupByKey后面跟一个mapPartition函数。
别急,等一下,还有更多 MapReduce的开发者会指出,还有更多的还没有被提及的API: · MapReduce支持一种特殊类型的Reducer,也称为Combiner,可以从Mapper中减少洗牌(shuffled)数据大小。
· 它还支持同通过Partitioner实现的自定义分区,和通过分组Comparator实现的自定义分组。
· Context对象授予Counter API的访问权限以及它的累积统计。
· Reducer在其生命周期内一直能看到已排序好的key 。
· MapReduce有自己的Writable序列化方案。
· Mapper和Reducer可以一次发射多组输出。
· MapReduce有几十个调优参数。
有很多方法可以在Spark中实现这些方案,使用类似umulator的API,类似groupBy和在不同的这些方法中加入partitioner参数的方法,Java或Kryo序列化,缓存和更多。
由于篇幅限制,在这篇文章中就不再累赘介绍了。
需要指出的是,MapReduce的概念仍然有用。
只不过现在有了一个更强大的实现,并利用函数式语言,更好地匹配其功能性。
理解Spark RDD API和原来的Mapper和ReducerAPI之间的差异,可以帮助开发者更好地理解所有这些函数的工作原理,以及理解如何利用Spark发挥其优势。
hadoop上运行mapreduce程序是在什么模式下
1、什么模式?这个问的有点不明不白 2、hadoop只有两种模式,即一般模式和安全模式。一般模式就是任何hadoop的东西都可以正常的执行,包括读写的任何操作。
安全模式:对hadoop的任何东西,都只有读的权限,不能进行任何的写。
- mapreduce编程hadoop上运行mapreduce程序是在什么模式下相关文档
- mapreduce编程MapReduce 与 HBase 的关系?
- mapreduce编程如何在Hadoop上编写MapReduce程序
- mapreduce编程简述Hadoop的MapReduce与Googl的MapReducc 之间的关系
- mapreduce编程mapreduce编程接口有哪些
- mapreduce编程学MapReduce先学什么好
美国cera机房 2核4G 19.9元/月 宿主机 E5 2696v2x2 512G
美国特价云服务器 2核4G 19.9元杭州王小玉网络科技有限公司成立于2020是拥有IDC ISP资质的正规公司,这次推荐的美国云服务器也是商家主打产品,有点在于稳定 速度 数据安全。企业级数据安全保障,支持异地灾备,数据安全系数达到了100%安全级别,是国内唯一一家美国云服务器拥有这个安全级别的商家。E5 2696v2x2 2核 4G内存 20G系统盘 10G数据盘 20M带宽 100G流量 1...
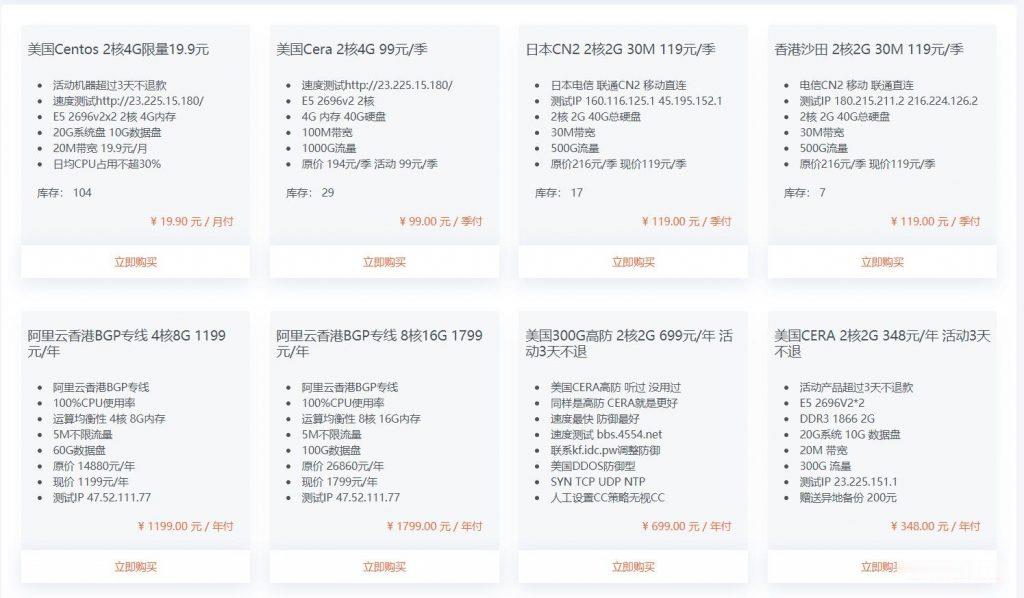
[黑五]ProfitServer新加坡/德国/荷兰/西班牙VPS五折,不限流量KVM月付2.88美元起
ProfitServer已开启了黑色星期五的促销活动,一直到本月底,商家新加坡、荷兰、德国和西班牙机房VPS直接5折,无码直购最低每月2.88美元起,不限制流量,提供IPv4+IPv6。这是一家始于2003年的俄罗斯主机商,提供虚拟主机、VPS、独立服务器、SSL证书、域名等产品,可选数据中心包括俄罗斯、法国、荷兰、美国、新加坡、拉脱维亚、捷克、保加利亚等多个国家和地区。我们随便以一个数据中心为例...
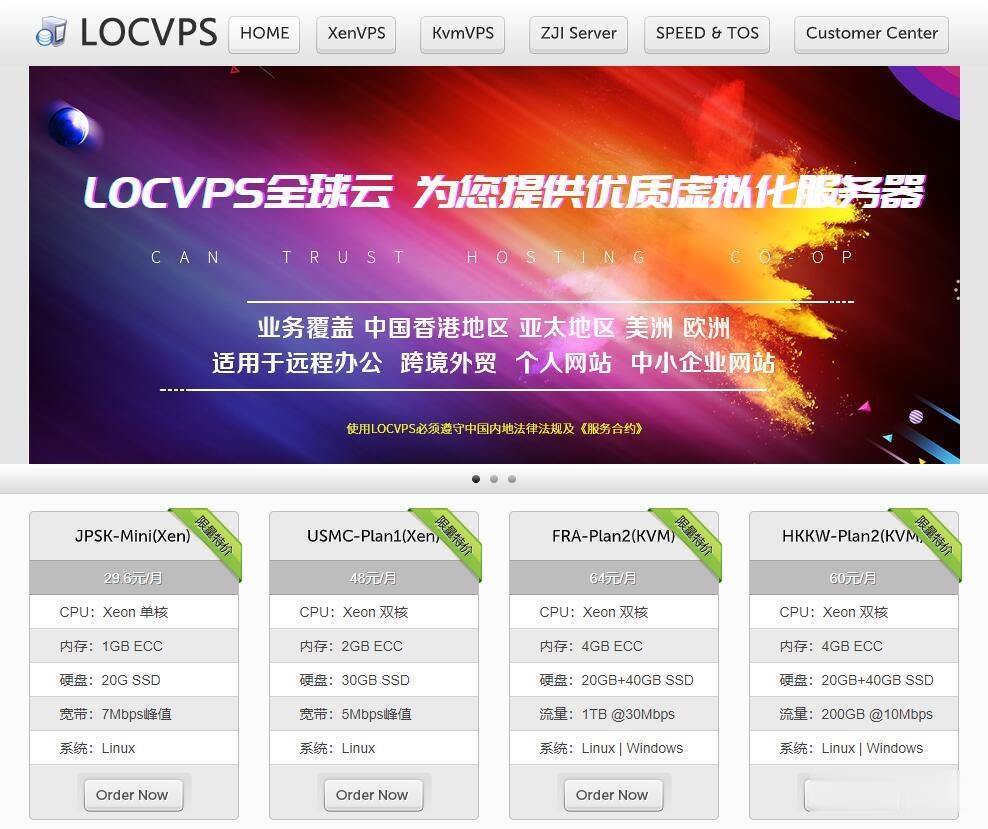
LOCVPS-2021年6月香港便宜vps宽带升级,充值就送代金券,其它八折优惠!
LOCVPS怎么样?LOCVPS是一家成立于2011年的稳定老牌国人商家,目前提供中国香港、韩国、美国、日本、新加坡、德国、荷兰等区域VPS服务器,所有机房Ping延迟低,国内速度优秀,非常适合建站和远程办公,所有机房Ping延迟低,国内速度优秀,非常适合做站。XEN架构产品的特点是小带宽无限流量、不超售!KVM架构是目前比较流行的虚拟化技术,大带宽,生态发展比较全面!所有大家可以根据自己业务需求...
mapreduce编程为你推荐
-
最开放的浏览器用的最多的三个浏览器是?网关和路由器的区别网关和路由器的区别和联系在bindserviceservice在手机程序中起什么作用拓扑关系什么是空间数据的拓扑关系jdk6JDK6和JDK7两个版本有什么区别,初学者选那个好?jdk6我是win7的系统,安装了JDK6,环境配置都正确了。但是安装完没有应用程序啊~php论坛用php写一个论坛,重点是什么?还有具体的功能,谢谢有b吗34B的胸围有多大?色库赤峰中色库博红烨锌业有限公司就是冶炼厂在 赤峰的 什么地方,一 人知道吗???系统论坛怎么进论坛