计算抢票软件哪个成功率高
集算器创新大数据计算引擎润乾软件出品高性能计算专家(HPC)高性能计算理念软件改变不了硬件的计算性能但软件可以设计一些高效(低复杂度)算法,降低计算规模,从而提升计算性能这类方案通常需要定制化,因地制宜,看菜吃饭集算器使用了诸多高效算法:分组计算关联计算查找定位遍历技术游标与管道并行计算……softwarehardware高效算法举例–分组计算结果集小能够全内存结果集大不能全内存针对分组字段有序针对分组字段无序分组计算无需磁盘交互生成临时缓存·可并行无需磁盘交互生成临时缓存·可并行需要磁盘交互生成临时缓存·无法并行了解了计算和数据特征,就可以选用适合的算法,从而获得高性能集算器性能表现测试结果(时间单位:秒)测试用例IntelX86芯片国产飞腾芯片SPL读文件计算SPL读数据库计算数据库中SQL计算SPL读文件计算SPL读数据库计算连接后并集-3.
8>1小时--连接后交集-3.
9>1小时--多对多连接遍历69103>1小时93268有序分组遍历100647>1小时1022037多步过程计算272848>1小时377>1小时大分组391552573562493大表关联分组111566>1小时1782106批量键值查询15>1小时>1小时15>1小时*数据规模:100亿行;集群数量:4国产飞腾芯片上运行的润乾集算器可以超越Intel芯片上分布式数据库的性能【注】SPL是润乾集算器采用的程序设计语言;SQL是关系数据库采用的程序设计语言轻量级大数据计算引擎23高性能计算技术4应用案例1现状分析目录Contents沉重的大数据计算单机性能不被关注,依靠集群规模框架体系庞大复杂,试图包罗万象避开外存计算困难,指望巨大内存123集群内存框架大数据计算开发难度大大数据平台对SQL查询关注过多性能比拼的主要阵地优化SQL性能几乎无助于降低开发难度大量过程计算的开发难度还很大用SQL很难描述,复杂SQL优化效果不好仍需大量底层的编码,经常编写UDF提高性能本质上是降低开发难度复杂运算的自动优化靠不住,需要快速编写高性能算法难度大集群透明化大数据平台努力实现集群透明化单机与集群一致网络存储系统+自动任务分配透明化提高代码兼容性,降低开发难度透明化难以获得最优性能高性能计算方案因场景而异,可能是矛盾的透明化只能选择最保险的方法,一般是性能较差的那个透明化框架对资源消耗严重透明化轻量级大数据计算引擎23高性能计算技术4应用案例1现状分析目录Contents集算器—技术特征面向过程计算无缝应用集成多样性数据源接口直接文件计算单机优化技术多线程并行无中心集群结构自由数据分布和任务分配集算器—敏捷语法体系思考:按照自然思维怎么做1selectmax(连续日数)2from(selectcount(*)连续日数3from(selectsum(涨跌标志)over(orderby交易日)不涨日数4from(select交易日,5casewhen收盘价>lag(收盘价)over(orderby交易日)6then0else1end涨跌标志7from股价表))8groupby不涨日数)SQLA1=股价表.
sort(交易日)2=03=A1.
max(A2=if(收盘价>收盘价[-1],A2+1,0))集算脚本某支股票最长连续涨了多少交易日语法体系更容易描述人的思路数据模型不限制高效算法实现集算器—面向过程计算完整的循环分支控制天然分步、层次清晰、直接引用单元格名无需定义变量集算器—开发环境执行、调试执行、单步执行设置断点语法简单,符合自然思维,比其他高级开发语言更简单网格结果所见即所得,易于调试;方便引用中间结果系统信息输出,异常随时查看集算器—应用结构应用程序集算器IDE数据计算层集算器脚本(DFX)集算器JDBC数据存储层(RDB、NoSQL、TXT、CSV、JSON、Hadoop)轻量级大数据计算引擎23高性能计算技术4应用案例1现状分析目录Contents分段并行高性能计算技术连接解决集群方案使用索引遍历技术存储格式遍历技术遍历复用聚合理解延迟游标有序游标遍历是大数据计算的基础遍历技术延迟游标游标概念流式读入数据,每次仅计算一小部分延迟计算在游标上定义运算,返回结果仍然是游标,可再定义运算不立即计算,最终一次性遍历和计算AB1=file("data.
txt").
cursor@t()/创建游标2=A1.
select(product=="1")/过滤3=A2.
derive(quantity*price:amount)/计算列4=A3.
sum(amount)/实际计算遍历技术遍历复用外存计算优化方向是减少访问量可复用的遍历减少外存访问量一次遍历可返回多个分组结果A1=file("data.
txt").
cursor()2=channel().
groups(;count(1))配置同步计算3>A1.
push(A2)绑定4=A1.
sortx(key)排序,遍历过程中处理绑定计算5=A2.
result().
#1取出绑定计算的结果,即总记录数6=A4.
skip((A5-1)\2).
fetch@x(2-A5%2).
avg(key)取出中位数记录并计算中位数遍历技术聚合理解从一个集合计算出一个单值或另一个集合都可理解为聚合高复杂度的排序问题转换为低复杂度的遍历问题A1=file("data.
txt").
cursor@t()2=A1.
groups(;top(10,amount))金额在前10名的订单3=A1.
groups(area;top(10,amount))每个地区金额在前10名的订单遍历技术有序游标针对已有序的数据可一次遍历实现大结果集分组运算,减少外存交换A1=file("data.
txt").
cursor@t()2=A1.
groupx@o(uid;count(1),max(login))ABC1=file("user.
dat").
cursor@b()/按用户id排序的源文件2forA1;id…/从游标中循环读入数据,每次读出一组id相同3…/处理计算该组数据复杂处理需要读出到程序内存中再处理有序游标有效减少查找和遍历数量连接解决外键指针化外键序号化区分JOIN有序归并连接计算是结构化数据的最大难点指针化序号化外键维表1:N有序归并同维表1:1有序归并主子表1:N连接解决区分JOIN!
外键需要随机小量频繁访问内存指针查找大幅提高性能A1=file("Products.
txt").
import()读入商品列表2=file("Sales.
txt").
import()读入销售记录3>A2.
switch(productid,A1:id)建立指针式连接,把商品编号转换成指针4=A2.
sum(quantity*productid.
price)计算销售金额,用指针方式引用商品单价Java指针连接Oracle单表无连接0.
57s0.
623s五表外键连接2.
3s5.
1sProductsidnamevendortypepriceSalesseqdateproductidquantity连接解决外键指针化序号化相当于外存指针化不需要再计算Hash值和比较A1=file("Products.
txt").
import()读入商品列表2=file("Sales.
txt").
cursor()根据已序号化的销售记录建立游标3=A2.
switch(productid,A1:#)用序号定位建立连接指针,准备遍历4=A3.
groups(;sum(quantity*productid.
price))计算结果连接解决外键序号化同维表和主子表连接可以先排序后变成有序归并追加数据的再排序也仍然是低成本的归并计算A1=file("Order.
txt").
cursor@t()订单游标,按订单id排序2=file("Detail.
txt").
cursor@t()订单明细游标,也按订单id排序3=joinx(A1:O,id;A2:D,id)有序归并连接,仍返回游标4=A3.
groups(O.
area;sum(D.
amount))按地区分组汇总金额,地区字段在主表中,金额字段在明细子表中连接解决有序归并自由列存序号主键压缩二进制主子合一有效的存储格式是高性能的保证存储格式数据类型已存入,无须解析轻量级压缩减少硬盘空间很少占用CPU时间泛型存储,允许集合数据可追加存储格式压缩二进制自由分配列组行列存统一重复值压缩对上透明访问过滤优化只读取与条件相关的列组组1组2组k列1列2列3列4…1………2…………10231024存储格式自由列存多层序号式主键外存指针式外键,高速引用外存游离记录表示,离散性天然有序,易于查找分组针对外键结果自然对齐有序北京1海淀1,1朝阳1,2…上海2浦东2,1……存储格式序号主键多层复式表层次式有序集合每层均可以有数据结构同维表与主子表统一消除对齐式连接订单客户地区日期…订单明细产品数量单价…存储格式主子合一有序对分查找有序数据提供对分查找,快速定位普通定位索引按键值找到数据两段式索引提高维护性能片状索引连续记录的索引使用索引片状索引普通定位索引有序对分查找CUBE切片索引的困难列存索引太大数据必须实际排序双向逆序索引按D1,…,Dn和Dn,…,D1双倍排序只针对前半部分维度使用片式索引使用索引应用:切片的双向逆序索引数据分段是并行计算的基础倍增分段列存分段文本分段有序/对位分段多路游标分段并行文件线程1线程4线程2线程3并行处理需要将数据文件分段,每个线程处理一段简单按字节分段按行分段去头补尾的字节分段文本并行解析A1=file("data.
txt").
cursor@tm(amount)/定义并行取数的游标(并行)2=A1.
groups(;sum(amount):amount)/遍历游标汇总amount(串行)分段并行文本分段分段数足够大,以适应变化的并行数每段记录数相对平均数据追加时不必重写所有数据,保持连续性AB1=file("data.
bin")2fork4=A1.
cursor@b(amount;A2:4)3=B2.
groups(;sum(amount):a)4=A2.
conj().
sum(a)追加前追加后112324536748…10235121024513…分段并行倍增分段倍增分段方案解决列存并行困难各列同步分段同列连续存储AB1=[1,3].
(file("col"/~/".
bin"))2fork4=A1.
cursor(amount;A2:4)3=B2.
groups(;sum(amount):a)4=A2.
conj().
sum(a)段列1列2…11,…,k1,…,k2k+1,…,2kk+1,…,2k32k+1,…,3k2k+1,…,3k43k+1,…,4k3k+1,…,4k…10231024分段并行列存分段有序数据的分段点要落在组边界上才能分段并行同维表、主子表需同步分段A1=file("userlog.
txt").
cursor@t()原始数据游标2=A1.
sortx(id)按id排序3>file("userlog.
dat").
export@z(A2;id)写成按id分段的文件A1=file("Order.
txt").
cursor@t()2=A1.
sortx(id)按id排序3>file("Order.
dat").
export@z(A2;id)写成按id分段的文件4=file("Detail.
txt").
cursor@t()5=A4.
sortx(id)按id排序6>file("Detail.
dat").
export@z(A2;id,file("Order.
dat"),id)和Order.
dat同步按id分段分段并行有序与对位分段建立多路游标,可继续进行过程计算,会自动并行执行,简化书写难度.
A1=file("Order.
txt").
cursor@tm()建立多路游标,自动并行执行2=A1.
select(month(Date)==10)条件过滤3=A2.
groups(ID;sum(COST*WEIGHT):VALUE)分组汇总分段并行多路游标集群方案集群设计原则确保容错减少网络传输量考虑负载均衡集群计算技术集群维表外存分布内存分布集群方案—无中心设计服务器集群无中心集算器没有框架,没有永久的中心主控节点,程序员用代码控制参与计算的节点无中心不会发生单点失效所有节点地位都等同,不会发生单点失效,某个节点有故障时整个集群仍然可以运行计算任务有主控节点在计算过程中由主控节点临时寻找其它节点参与计算集群方案—负载均衡与容错具备负载均衡能力根据每个节点空闲程度(当前正在运行的线程数量)决定是否分配任务,实现负担和资源的有效平衡具备容错能力某个节点失效导致子任务失败,主控程序还会再次将这个子任务分配给其它有效的节点集算器数据源集群方案—并行逻辑结构sub.
dfxsub.
dfxsub.
dfxORAMSSQL本地文件HDFSmain.
dfx共享式数据计算分布共享数据源方式:计算分布实现,数据共享读取集算器数据源并行节点并行节点并行节点ORAMSSQL本地文件HDFSAB1=4.
("192.
168.
0.
"/(10+~)/":1234")节点机列表,4个2forkto(8);A1到节点机上执行,分成8个任务3=hdfsfile("hdfs:\\192.
168.
0.
1\persons.
txt")HDFS上的文件4=B3.
cursor@t(;A2:8)分段游标5=B4.
select(gender=='M').
groups(;count(1):C)过滤并计数6=A2.
conj().
sum(C)汇总结果冗余式外存分布所有任务都需要用到的公共维表复制存储事务数据分成N个区,根据需要的容错指数循环分区存储利用率约为1/k(允许k-1个节点失效)4X515X123X452X341X23外存分布—数据同步集算器提供节点之间的同区数据同步功能每个节点都是独立的计算机,可以应用内存和外存的计算方法.
1new3new13122外存分布—动态任务分配主控程序分配任务节点程序收到任务本节点是否有所需数据节点程序执行任务有无ABC1=4.
("192.
168.
0.
"/(10+~)/":1234")节点机列表,4个2forkto(8);A1到节点机上执行,分成8个任务3=file("person.
txt",A2)A2为数据区号4if!
B3.
exists()end"datanotfind"找不到返回错误再分配5=B3.
cursor()6=B5.
select(gender=='M').
groups(;count(1):C)计算7=A2.
conj().
sum(C)汇总备胎式内存分布数据分区分别加载进节点内存n个节点(每节点一个分区)+k个备份节点内存利用率n/(n+k)XX5X4X3X2X1X内存分布—静态任务分配预留备份节点(备胎)不加载任何数据分区发现有分区在所有可用节点都找不到时,启动找备份节点执行加载该分区任务直接分配到相应节点,不再动态询问A主程序1=8.
("192.
168.
0.
"/(10+~)/":1234")节点列表,共8个2=hosts(A1,to(4),"init.
dfx")在其中寻找4个节点加载内存数据3=callx@a("sub.
dfx",to(4);A2)调用这些节点上程序计算4=A3.
sum()汇总结果A节点初始化程序init.
dfx1=file("Product.
txt",z).
import()读入第z分区的数据2>env(T,A1)将数据记入环境3>zone(z)登记本节点的分区A节点程序sub.
dfx1=T从环境中取出数据2=A1.
count(gender=='M')过滤并计数3returnA2返回结果MapReduce->ForkReduceMapReduce的问题任务太碎,管理成本过高难以实现关联运算HashShuffle随意性太强ForkReduce批量任务,调度成本低结合对位分段技术实现关联运算Shuffle结果有确定分布方案轻量级大数据计算引擎23高性能计算技术4应用案例1现状分析目录Contents某大型保险公司-存储过程优化【案例背景】定报价风险保费通过informix存储过程计算,运行1小时,效率低下影响使用;初始化车险新规车辆归并,找到上三年保单,数据量大(30天)时,运行将近2小时,急需优化【数据规模】保单表:0.
35亿;保单明细表:1.
23亿【优化效果】【使用的集算器技术】压缩列存:使用集算器组表的列式压缩存储,空间小,并且减少了参与计算的列数(约1/7)有序存储:数据按照保险单号顺序存放,这样可以使用有序关联提升计算效率高效计算:原来需要遍历多次完成多表关联,现在只需遍历一次即可完成多表关联并行技术:集算器提供多线程并行计算,在多核环境下可以加速计算场景优化前优化后提升倍数定报价风险保费3600秒68秒52.
9倍查找上三年保单6672秒1020秒6.
5倍52.
9倍某金融机构–报表优化【案例背景】该金融机构需要维护的报表超过7500张,其中20%查询速度为分钟级,5%的查询速度为小时级,这5%非常慢的查询SQL代码行数有几百行,存储过程更是达到几千行,关联运算多.
用通俗的语言描述报表慢的原因主要是数据量大,业务逻辑复杂.
【数据规模】POS交易情况统计表运行时间为3700秒,4个SQL数据集,涉及6个数据库表的关联运算,其中3个表的数据量为千万级(1708万-4886万).
【优化效果】不改变硬件环境的条件下,报表查询速度从3700秒降到105秒.
【使用的集算器技术】高效关联技术:将原来报表的顺序关联改为更高效的外键指针式关联方式并行计算:将原有串行计算的4个SQL,改为4线程并行加速计算35.
2倍某银行–报表优化【案例背景】随着客户业务数据量级的日益增长,使原有业务报表在查询和导出时的效率明显降低,已经跟不上业务的发展;并且在引入HBase后,仍无法解决批量查询效率问题.
【数据规模】千万级【优化效果】原有回单报表查询一个分行一个月的数据需要18分钟,甚至造成内存溢出,引入集算器后,每页展示2000条数据,首页加载时间为10秒,一个分行一个月的数据全部加载完成缩短至5分钟,并且不会造成内存溢出的问题.
【使用的集算器技术】高性能存储:集算器提供了私有二进制压缩存储,提供保存数据类型、泛型存储、任意分段等机制双线程异步计算:与报表工具结合,将取数计算和数据呈现使用不同的异步线程处理,提升数据展现速度,并降低内存使用率3.
6倍某电信运营商–Excel财务报表优化【案例背景】月财务结算时需要各省市分级按科目上报财务报表,但由于集团下属分子公司使用了不同的财务软件(SAP和用友),上报的数据存在财务账套无法完全匹配,不同科目需要关联替换等业务数据准备工作需要财务人员手工完成,使用Excel进行报表统计十分低效.
buyvm美国大硬盘VPS,1Gbps带宽不限流量
buyvm正式对外开卖第四个数据中心“迈阿密”的块存储服务,和前面拉斯维加斯、纽约、卢森堡一样,依旧是每256G硬盘仅需1.25美元/月,最大支持10T硬盘。配合buyvm自己的VPS,1Gbps带宽、不限流量,在vps上挂载块存储之后就可以用来做数据备份、文件下载、刷BT等一系列工作。官方网站:https://buyvm.net支持信用卡、PayPal、支付宝付款,支付宝付款用的是加元汇率,貌似...
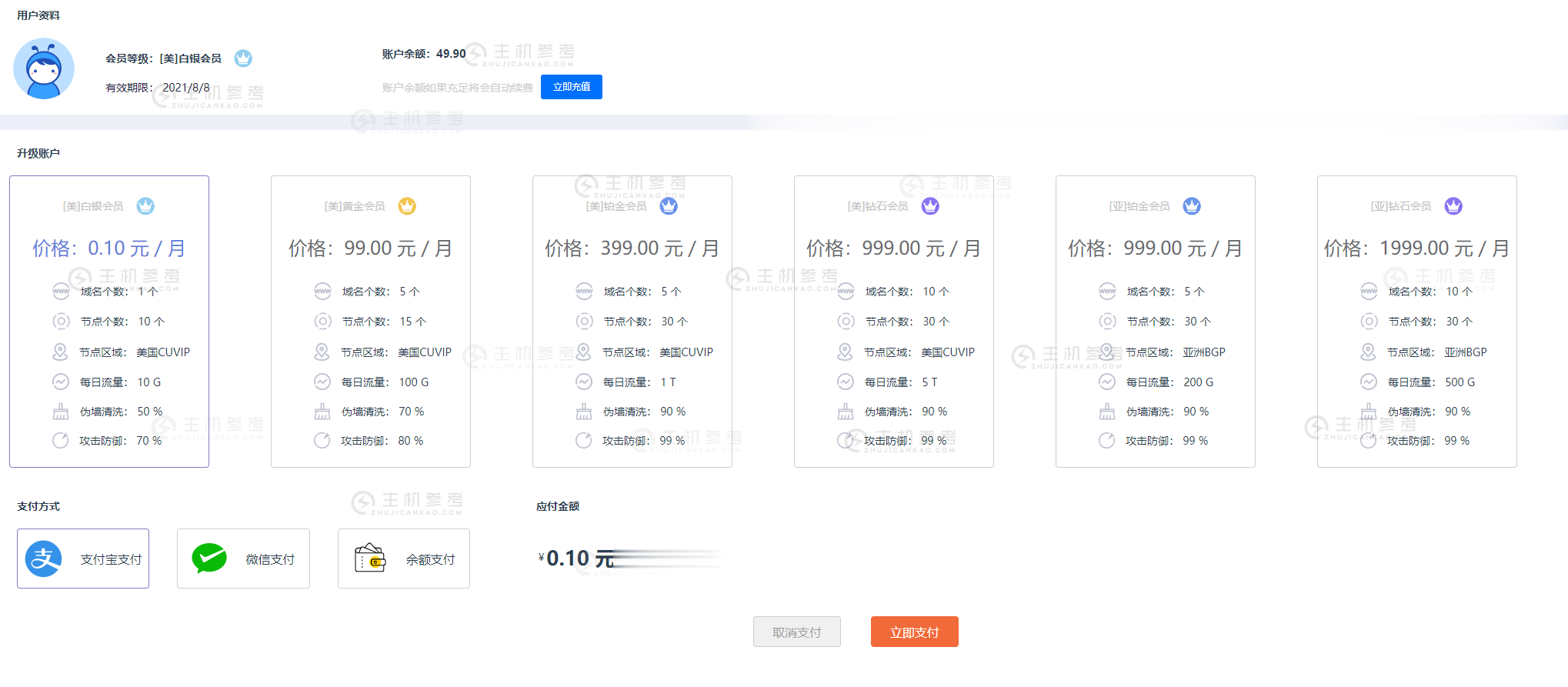
FBICDN,0.1元解决伪墙/假墙攻击,超500 Gbps DDos 防御,每天免费流量高达100G,免费高防网站加速服务
最近很多网站都遭受到了伪墙/假墙攻击,导致网站流量大跌,间歇性打不开网站。这是一种新型的攻击方式,攻击者利用GWF规则漏洞,使用国内服务器绑定host的方式来触发GWF的自动过滤机制,造成GWF暂时性屏蔽你的网站和服务器IP(大概15分钟左右),使你的网站在国内无法打开,如果攻击请求不断,那么你的网站就会是一个一直无法正常访问的状态。常规解决办法:1,快速备案后使用国内服务器,2,使用国内免备案服...
imidc:$88/月,e3-1230/16G内存/512gSSD/30M直连带宽/13个IPv4日本多IP
imidc对日本独立服务器在搞特别促销,原价159美元的机器现在只需要88美元,而且给13个独立IPv4,30Mbps直连带宽,不限制流量。注意,本次促销只有一个链接,有2个不同的优惠码,你用不同的优惠码就对应着不同的配置,价格也不一样。88美元的机器,下单后默认不管就给512G SSD,要指定用HDD那就发工单,如果需要多加一个/28(13个)IPv4,每个月32美元...官方网站:https:...
-
vpsVPS是干嘛用的?英文域名中文域名与英文域名区别美国vps租用如何选择国外vps服务器?台湾vps香港vps和台湾vps哪个好用台湾主机台湾版本的主机好不好?100m网站空间100M的最好的网站空间价格多少?1g虚拟主机想买个1G虚拟主机,不限流量的,但不知道哪个建站网站靠谱,求推荐!上海虚拟主机谁能告诉我杭州哪个公司的虚拟主机最好,机房最好是上海或浙江的.www二级域名请问 www.aaa.bbb.com 是一级域名还是二级域名啊?能否备案?怎么备案?域名网站哪里可以给你免费的域名做个网站