污点内存卡读不出来怎么办
软件学报ISSN1000-9825,CODENRUXUEWE-mail:jos@iscas.
ac.
cnJournalofSoftware,2017,28(8):20642079[doi:10.
13328/j.
cnki.
jos.
005126]http://www.
jos.
org.
cn中国科学院软件研究所版权所有.
Tel:+86-10-62562563基于即时编译的动态污点跟踪优化吴泽智1,2,陈性元1,2,杨智1,3,杜学绘1,31(解放军信息工程大学三院,河南郑州450001)2(密码科学技术国家重点实验室(北京信息科学技术研究院),北京100094)3(河南省信息安全重点实验室(解放军信息工程大学),河南郑州450001)通讯作者:陈性元,E-mail:chxy302@vip.
sina.
com摘要:动态污点跟踪技术展现了在移动隐私保护方面的强大功能,但存在系统性能较低问题.
提出了一种基于即时编译的动态污点传播优化方法.
首先,将程序逻辑精确抽象为污点传播逻辑,简化污点传播分析复杂性;然后,提出了一个污点传播框架,并证明了在该框架下污点传播分析的正确性和有效性;最后,采用消除、替换和移动等方法将冗余低效的污点传播代码转化为高效等价的污点传播代码.
实验结果表明,经过优化后,单条热路径的污点传播代码节省了38%的内存占用和指令执行时间,系统整体性能平均提升了6.
8%.
关键词:安卓;隐私安全;动态污点跟踪;即时编译器;污点传播优化中图法分类号:TP311中文引用格式:吴泽智,陈性元,杨智,杜学绘.
基于即时编译的动态污点跟踪优化.
软件学报,2017,28(8):20642079.
http://www.
jos.
org.
cn/1000-9825/5126.
htm英文引用格式:WuZZ,ChenXY,YangZ,DuXH.
Dynamictainttrackingoptimizationonjust-in-timecompilation.
RuanJianXueBao/JournalofSoftware,2017,28(8):20642079(inChinese).
http://www.
jos.
org.
cn/1000-9825/5126.
htmDynamicTaintTrackingOptimizationonJust-in-TimeCompilationWUZe-Zhi1,2,CHENXing-Yuan1,2,YANGZhi1,3,DUXue-Hui1,31(ThirdCollege,PLAInformationEngineeringUniversity,Zhengzhou450001,China)2(StateKeyLaboratoryofCryptology(BeijingAcademyofInformationScienceandTechnology),Beijing100094,China)3(He'nanProvinceKeyLaboratoryofInformationSecurity(PLAInformationEngineeringUniversity),Zhengzhou450001,China)Abstract:Despitethedemonstratedusefulnessofdynamictainttrackingtechniquesinmobileprivacysecurity,poorperformanceattainedbyprototypesisabigproblem.
Anoveloptimizationmethodologyfordynamictainttrackingbasedonjust-in-timecompilationispresented.
First,thetaintpropagationlogicisseparatedfromtheprogramlogicpreciselytosimplifyingthecomplexityofthetaintpropagationanalysis.
Then,ataintpropagationframeworkisproposedandthecorrectnessofthetaintpropagationanalysisisproved.
.
Finally,redundantandinefficienttaintpropagationcodesaretransferredtoefficientandequivalentcodesbyadoptingthemethodsofeliminating,replacingandmoving.
Experimentalresultsshowthat38%ofmemoryusageandthetimeofexecutionoftainttrackinginstructionsaresavedforeverysinglehottrace,andonaveragetheperformanceofdynamictainttrackingsystemisimproved6.
8%.
Keywords:Android;privacysecurity;dynamictainttracking;just-in-timecompiler;taintpropagationoptimization飞速发展的移动互联网和快速普及的智能终端,使得人们的生活水平和生活方式得到了极大的提高和改基金项目:国家自然科学基金(61402437);国家高技术研究发展计划(863)(2015AA016006,2012AA012704)Foundationitem:NationalNaturalScienceFoundationofChina(61402437);NationalHigh-TechR&DProgramofChina(863)(2015AA016006,2012AA012704)收稿时间:2015-05-07;修改时间:2015-12-22,2016-07-15;采用时间:2016-08-10;jos在线出版时间:2016-10-11CNKI网络优先出版:2016-10-1216:26:36,http://www.
cnki.
net/kcms/detail/11.
2560.
TP.
20161012.
1626.
005.
html吴泽智等:基于即时编译的动态污点跟踪优化2065变.
然而,在人们享受它们带来的繁荣与便利的同时,存储在智能终端上的隐私数据安全受到了前所未有的挑战[1].
在众多隐私保护技术中,动态污点跟踪技术可有效地、实时地、细粒度地保护用户隐私数据,但在应用了动态污点跟踪技术后,系统实时执行效率都将严重下降.
例如,在虚拟机实时运行层引入污点跟踪技术后,对于每一条可能传播污点的虚拟机指令,都将插入多条本地指令以完成污点跟踪.
这些指令不但降低了系统的实时执行效率,而且通过即时编译后产生的冗余代码占用了更多的系统内存.
因此,如何有效地解决动态污点跟踪效率问题,是制约其能否广泛应用与形成产品的关键.
本文将动态污点跟踪技术与即时编译优化技术相结合,并应用于安卓系统上的隐私信息流控制与保护,实现了正确和有效的污点跟踪优化,提高了动态污点跟踪系统的效率.
1相关工作动态污点跟踪[2]又可称为动态信息流跟踪或动态数据流跟踪,是指在程序执行过程中跟踪所感兴趣的数据流集合.
按其应用领域分类,主要包括软件漏洞挖掘[3]、隐私数据流保护、数据生命周期分析[4]、软件配置诊断和输入过滤[5]等.
按其实现方法分类,主要包括全系统模拟、中间虚拟机实现[6]、动态二进制插装、源码到源码转换、基于编译的污点跟踪[7]和基于硬件污点跟踪等.
基于动态二进制插装实现污点跟踪系统一般依赖于插装平台.
按跟踪粒度,又可分为细粒度和粗粒度跟踪.
上述工作均属于细粒度跟踪,细粒度跟踪还包括基于语言的信息流控制[8,9]工作.
粗粒度的污点跟踪主要体现在操作系统进程级别的信息流跟踪,如Asbestos[10],Flume[11]和GPTM[12].
以上研究普遍存在系统效率较低的问题,例如,TaintCheck对系统应用执行速度将减缓20倍~30倍.
污点跟踪优化相关研究工作从5个方面尝试解决以上问题.
第一,增加额外硬件资源,例如增加处理器、寄存器和内存或者将工作传输给远程主机[13,14].
此种优化又有两个研究方向:其一,污点跟踪代码仍然嵌入到程序代码中,采用并行化[15]思想将混杂的代码分配到不同CPU处理,从而提高系统运行效率;其二,将污点跟踪代码从程序中解耦合[16].
ShadowReplica[17]将污点跟踪代码分配到不同的CPU处理,不同CPU间采用相应通信机制传递污点警报.
这类方法的缺点是需要多核硬件支持,不适应本文情况.
但利用此种解耦合方法,本文在MIR(middleintermediaterepresentation)编译为LIR(low-levelintermediaterepresentation)过程中插入的污点跟踪代码,并使用LIR数据结构中相应标志位将程序代码和污点跟踪代码区分开来,便于优化时依据污点跟踪代码特性进行针对性的优化.
第二,将部分动态污点跟踪工作转化到静态分析时完成,主要思想是:通过静态组件将程序源码或二进制文件统一转化为中间代码,并插入相应的污点跟踪指令,最终形成可直接执行并包含污点跟踪的程序代码.
文献[18]将污点跟踪过程抽象成污点传播代数,并使用DAG(directacyclicgraph)进行复写传播和公共子表达式删除等优化.
文献[19]结合静态与动态分析,在静态分析时通过编译器保守地完成信息流跟踪代码插入,有效地减少了动态运行时实施信息流跟踪的负荷.
以上的研究缺点在于静态分析缺乏运行时profile信息,从而导致优化效果较差,而且缺乏对操作系统和高级语言的支持.
第三,依据需求动态关闭或开启污点跟踪功能[20,21],这类研究工作的缺点在于动态开启或关闭的时机难以确定,且存在开启或关闭时的性能损耗.
非专业用户在关闭污点跟踪时可能存在隐私泄漏情况.
第四,依据用户或者系统需求,仅对程序部分代码进行污点跟踪[22,23],而对一些非重要代码不进行污点跟踪.
这类研究工作的缺点在于,无法严格确定哪些程序代码需要进行跟踪,而且容易产生漏报,导致跟踪精确性较差.
第五,依赖于插装平台在即时编译时进行代码优化.
以valgrind为例,其即时编译过程如下:首先将机器码转化为treeIR,然后通过复写和常量传播、常量折叠、死代码删除、公共子表达式删除和循环展开等优化方法将treeIR转化为flatIR,然后向flatIR中插装,并再次进行常量折叠和死代码消除优化,最后将flatIR转化为本地代码.
因而在使用valgrind进行指令级别代码插装时,可对形成的flatIR再次进行针对性优化.
Lift[24]实现了Fast-Path,MergedCheck和FastSwitch优化.
但已有研究工作如libdft[25]2066JournalofSoftware软件学报Vol.
28,No.
8,August2017都未针对污点传播代码的特性进行优化,而是使用一般优化方法,如方法内联、活跃变量分析和分支预测等.
本文有以下4个方面的优势.
其一,相对于低级语言虚拟机,高级语言虚拟机指令含有丰富的高层语义,更利于程序逻辑向污点传播逻辑转化.
其二,插装平台为污点传播所建立的污点影子内存使用1bit的污点值,难以进行彩色污点跟踪.
Dalvik虚拟机污点值采用32bit表示,拓宽污点值域,更利于建立一个污点传播分析的框架.
其三,dalvik虚拟机具备解释器和即时编译器,解释器可为即时编译器提供足够的运行时profile信息,可自适应地对热点路径进行污点跟踪优化.
其原因在于:第一,若冷路径污点跟踪优化算法所占用的时间长于运行代码的执行时间,则显然是入不敷出的,因而不宜进行优化;第二,即使污点跟踪优化算法所占有的时间长于运行代码的执行时间,但由于该热点路径反复执行,即以1次优化的代价换取多次执行的开销是值得的.
其四,基于dalvik虚拟机实现的污点跟踪和安卓手机操作系统是完美结合的,不需要插装平台的支持和较高专业知识水平用户,具有良好的易用性和用户透明性.
安卓上动态信息流分析代表性工作是TaintDroid[26],通过在操作系统源码关键处插入钩子,实现自动对个人隐私数据打上污点标记和检测是否存在带有污点标记的数据通过网络等路径离开系统;通过消息级别、程序变量级别、程序方法级别和文件级别的动态污点跟踪,实现了污点在程序运行过程中的准确传播和污点永久记忆.
但TaintDroid对可能发生污点传播的指令都进行跟踪,而未针对污点跟踪代码进行优化工作.
目前没有面向安卓的动态污点跟踪优化相关工作,与dalvik虚拟机性能优化相关的研究主要包括:文献[27]提出了一种基于文件的动态即时编译代码共享方法,有效提高了虚拟机内存使用效率和热路径重编译负荷;文献[28]改进了dalvik虚拟机自适应编译系统,提出了一种基于结果反馈的动态自适应阈值重置策略,有效提高了循环、分支跳转和派发指令的执行效率.
关于java虚拟机性能优化相关工作主要包括基于编译策略优化技术、基于性能监控优化技术、基于证据的优化技术和基于语言特性优化技术.
本文工作结合基于中间虚拟机实现方法和基于编译的污点跟踪实现方法,针对虚拟机基于热路径的即时编译特征和污点传播特性,依据程序运行的热点原理,即,程序的大部分(80%)运行时间是耗费在小部分(20%)代码上,结合已有优化技术,提出了一种动态污点编译优化方法,对单条热路径进行局部性污点传播优化,有效提高污点传播技术应用后虚拟机实时执行效率.
2污点传播优化基础在虚拟机指令级别引入污点传播机制后,如果简单地对每一条虚拟机指令都插入若干条污点传播指令以完成污点跟踪,则会带来相当大的运行时开销.
因此,需要将插入的污点传播指令进行优化,即在目标指令中消除不必要的污点传播指令,或将污点传播指令移动位置,或将污点传播指令序列替换为可完成同样污点传播功能但执行速度更快的指令序列.
将此定义污点传播优化.
要实现污点传播优化,需要解决以下4个关键问题:第一是污点传播代码与程序代码语义的一致性,也可称为正确性,正确性要求程序代码执行时发生污点传播时要准确跟踪,未发生污点传播时不能错误跟踪;第二是污点传播代码优化后的高效性,即要求跟踪代码优化后在运行时间和空间都能优化于未优化的代码;第三是优化算法合算性,优化算法代价是能够换取程序执行污点传播时所需的时间和空间的性能开销;第四是优化算法精确性,即在正确性基础上确保优化后代码是精确的,优化算法精确性主要依赖于污点传播分析算法精确性,可有效防止污点传播假阳性和假阴性.
本节通过分析污点传播语义的特性,提出了污点传播逻辑.
在此基础上进一步提出了污点传播框架,从理论方面有效解决了前3个问题.
第4个问题依赖于全局的污点传播分析和控制流分析,有待后续进一步深入研究.
2.
1污点传播逻辑污点传播的过程可看作是对程序内部整个污染状态的一系列转换过程,程序污染状态由各变量的污点值组成,同时还可能包括运行时刻栈帧和寄存器所存储的各变量污点值.
程序执行时,每一条污点传播语句都将一吴泽智等:基于即时编译的动态污点跟踪优化2067个输入污染状态转化为一个新的输出污染状态.
在整个污点传播分析过程中,仅分析与污点传播相关的数据流信息.
将复杂的数据类型和数值计算逻辑抽象成独立的污点传播逻辑,也可以理解为将程序逻辑中污点传播语句转化为污点传播逻辑中污点传播表示式(不包含控制流引起污点传播).
结合Dalvik即时编译时虚拟机指令向SSA(staticsingle-assignment)表示的MIR转化的特点,引入以下相关概念.
定义1(污染点(T)).
变量var的污染点是MIR所处位置,执行该指令后,变量var污点值会发生改变.
变量污染点分析需针对不同虚拟机指令类型.
例如,OP_MOVEvA,vB是vA的污染点,同理,该类型指令还包括数值转换指令(如OP_INT_TO_LONGvA,vB)、数值计算(如OP_ADD_INTvAA,vBB,vCC)、逻辑运算(如OP_AND_INTvAA,vBB,vCC)等.
特别地,对于OP_MIR_PHI指令,也认为是vA的污染点.
定义2(传播点(P)).
变量var的传播点是语句MIR所处位置,执行该语句后变量var的污点值会影响其他变量的污点值.
变量传播点分析也需针对不同虚拟机指令类型.
例如,指令OP_MOVEvA,vB是vA的污染点,同时也是vB的传播点.
指令OP_ADD_INTvAA,vBB,vCC是vA的污染点,同时也是vB和vC的传播点.
同理,该类型虚拟机指令还包括逻辑运算如OP_AND_INTvAA,vBB,vCC等等.
特别地,对于OP_RETURN指令,认为是vA的传播点.
由以上定义,对于指令OP_ADD_INTvAA,vBB,vCC,其污点传播可表达为TaintA=TaintB|TaintC.
同理,可将所有MIR指令统一抽象为污点传播逻辑(taintpropagationlogic,简称TPL),其语义如图1所示.
Fig.
1Taintpropagationlogic图1污点传播逻辑Const代表污染的基本颜色种类的集合.
clean表示数据未被污染,color1到color32表示数据已被相应的颜色污染.
考虑dalvik虚拟机使用寄存器大小为32位,以32位无符号整数2n表示某种颜色.
例如,红色代表短信类隐私信息,以0x00000001表示;黄色代表联系人类隐私信息,以0x00000002表示.
污点标记变量var记录当前数据(变量、对象)污染状态,由任意不同种的基本颜色colori组成,数据被何种污点标记是不确定的.
例如,某数据包含短信类信息和联系人类隐私信息,其污点可用0x00000003(0x00000001|0x00000002)表示.
Binary-op将程序逻辑中发生污点传播的指令统一抽象成二元或操作符"|",在污点传播框架内可理解为集合并操作,在系统实现部分是逻辑或操作.
例如,加法指令x+y与减法指令xy在程序数值运算结果虽然不同,但在污点传播逻辑下运算结果都是x|y.
同时,对于不会引起污点传播指令则直接约减.
内存读写指令load与store表示污点在内存与寄存器间读写操作,写入内存确保污点跟踪正确性.
表达式exp定义是递归的,元表达式由两个污点变量和一个或操作符运算组成.
语句stat语义上完整表达的污点传播过程,即表达式运算后污点值由赋值运算符将污点值赋予变量var.
2.
2污点传播框架2.
2.
1污点传播值域在污点传播逻辑下,将每条污点传播语句和一个污点值关联起来,污点值是指在某处可观察到所有污染状态集合的抽象表示.
所有可能的污点值的集合称为污点传播值域,以整体的的方式抽象地研究污点传播,污点值域是一个乘积格,每个污点变量对应的格如图2所示(ci代表colori).
对于任意值x属于值集V,交汇运算∧取集合并集∪,有:(1)x∧x=x,满足等幂性;(2)x∧y=y∧x,满足可交换性;(3)x∧(y∧z)=(x∧y)∧z,满足可结合性.
其顶元素是空集,表示为T,对于V中的所有x,有T∧x=x;底元素是全集U,表示为⊥,对于V中所有x,有⊥∧x=⊥.
2068JournalofSoftware软件学报Vol.
28,No.
8,August2017交汇运算符定义了污点值域上的一个偏序(记为≤),污点值域即各个污点变量到格中某个值的映射,记污点变量v在映射m中的值为g(v).
因此,g≤g′当且仅当对于所有污点变量v,都有g(v)≤g′(v).
也可以表达为m∧m′=m″.
当且仅当对于所有污点变量v,g(v)∧g′(v)=g″(v).
偏序集(V,≤)上的一个上升链是一个满足x1
.
.
.
.
.
{ci}{}{c32}{c2,c3,.
.
.
,c32}{c1,ci,.
.
.
,c31}{c1,ci,.
.
.
,c32}{c1,ci,.
.
.
,c32}Fig.
2Latticeoftaintpropagationrange图2污点传播值域的格2.
2.
2传递函数族F在污点传播逻辑中,每个语句Stat对应一个传递函数fs,包含多个语句的程序块的传递函数可通过将各个语句对应的传递函数组合起来而构造得到.
函数集合F由一组传递函数fs组成,其输入是污点变量到格中元素的映射IN[S],输入则是发生污点传播后一个新的映射OUT[S].
在前向污点传播分析中,传递函数fs以语句之前IN[S]作为输入,并输出语句之后的OUT[S];传递函数F对于组合运算是封闭的,即对于F中的任意函数f和g,存在h(x)=g(f(x))的函数h也在F中.
传递函数族F中存在一个单元函数I,接受一个映射作为输入并输出返回的相同的映射,即:对于V中的所有x,有I(x)=x.
2.
2.
3框架的单调性单调性在格中定义为:①对于所有F中的f以及所有V中的x和y,f(x∧y)≤f(x)∧f(y).
单调性也可等价定义为:②对于所有F中的f以及所有V中的x和y,x≤y蕴含f(x)≤f(y).
现证明两种定义是等价的.
证明:先证明单调性②可推导出单调性①:由于x∧y是x和y的最大下界,则x∧y≤x且x∧y≤y,由单调性②可知,f(x∧y)≤f(x)且f(x∧y)≤f(y);同时,f(x∧y)是f(x)和f(y)的最大下界,单调性①得证.
然后证明单调性①可推导出单调性②:假设x≤y,由单调性①可知,f(x∧y)≤f(x)∧f(y),根据定义有x∧y=x.
因此有f(x)≤f(x)∧f(y).
因为f(x∧y)是f(x)和f(y)的最大下界,得到f(x)∧f(y)≤f(y).
从而f(x)≤f(x)∧f(y)≤f(y),即f(x)≤f(y),单调性②得证.
如图2所示的格显然满足单调性②定义,因为对于任意集合X和Y,X属于X∪Y.
2.
2.
4框架下污点传播分析为了便于理解和直观形象地分析污点传播,以如下dalvik指令代码为例进行分析.
.
methodpublicloop()Vconst/16v3,0x3e8:goto_0add-int/2addrv0,v1add-int/2addrv1,v0add-int/lit8v2,v2,0x1if-ltv2,v3,:goto_0return-void.
endmethod示例代码程序逻辑是将a=a+b与b=b+a计算1000次.
现着重分析每条语句在污点传播框架下表达式及其污点操作的实现.
对于Dalvik指令const/16v3,0x3e8,在污点传播逻辑下表达为3vTaintclean=.
对该虚拟机指令进行污点跟踪,需要额外完成以下3步:首先,通过SET_TAINT_FP(r1)保存变量污点的内存地址存入寄存器;然后,通过SET_TAINT_CLEAR(r2)设置初始污点值;最后,通过SET_VREG_TAINT(r2,r3,r1)将该污点值存入内存.
对吴泽智等:基于即时编译的动态污点跟踪优化2069于Dalvik指令add-int/2addrv0,v1,在污点传播逻辑下表达为001|vvvTaintTaintTaint=,其传递函数fs将污点变量v0从输入状态[100…0]转化为[110…0].
对该虚拟机指令进行污点跟踪,需要额外完成以下4步:首先,通过SET_TAINT_FP(r10)保存变量污点的内存地址存入寄存器;然后,通过GET_VREG_TAINT(r3,r3,r10)与GET_VREG_TAINT(r2,r2,r10)获取变量污点值;然后,通过orrr2,r3,r2计算更新后污点值;最后,通过SET_VREG_TAINT(r2,r9,r10)将该污点值存入内存.
对于Dalivk指令add-int/lit8v2,v2,0x1,在污点传播逻辑下表达为22|vvTaintTaintclean=.
其传递函数fs将污点变量v2从输入状态[001…0]转化为[001…0].
对于由该3条语句组成的循环体,其传递函数fs将污点变量v0从输入状态[100…0]转化为[110…0],将污点变量v1从输入状态[010…0]转化为[110…0],将污点变量v2从输入状态[001…0]转化为[001…0].
3污点传播优化方法通过上述污点传播分析,污点跟踪代码有如下特征.
其一,在程序逻辑向污点传播逻辑转化后,污点传播逻辑对应的本地指令集变小.
最主要包含以下4种:setTaintClear(*cUnit,rlDest)方法和setTaintClearWide(*cUnit,rlDest)方法编译为mov指令;loadTaintDirect(*cUnit,rlSrc,reg1)方法和loadTaintDirectWide(*cUnit,rlSrc,reg1)方法编译为ldr指令;storeTaintDirect(*cUnit,rlDest,reg1)方法和storeTaintDirectWide(*cUnit,rlDest,reg1)方法编译为str指令;opRegRegReg(cUnit,kOpOr,taint1,taint1,taint2)方法编译为orr指令.
因此,污点传播本地指令集主要包括ldr,str,mov和orr指令.
相对arm指令集是非常小的一个子集.
其二,程序逻辑向污点传播逻辑转化后,污点传播代码具备了一些新的特征.
例如,a=a+b和a=ab虽然在程序逻辑下计算出的a数值不一样,但在污点传播逻辑下,a的污点值是一样的.
又如for(i=0;i<100;i++)a=a+b,在循环执行时,a的数值是一直变化的,但在污点传播逻辑下,a的污点值是不变的.
其三,在插入的污点跟踪代码中,存在许多内存和寄存器之间存取数据的指令.
比如,要完成a=a+b,就需要在内存中取a的污点值,取b的污点值;同时,完成运算后,还要将a的污点值保存到内存.
针对污点传播代码的特征(上述3种特征),对经典流数据流算法进行改进,提出了3种适应污点传播代码特性、针对性更强、效率更高的优化算法.
主要改进体现在如下两个方面.
其一,指令数据结构的改进.
在dalvik即时编译过程中,程序指令一般被组织为一条双向链表.
而本文将程序指令和污点传播指令组织为一条双向链表,污点传播指令又组织为另一条双向链表,其开销只是在指令数据结构中加入*TAINT_PRE和*TAINT_NEXT.
其二,数据流算法的改进,由于污点传播指令单独组织,优化算法只需遍历插入的污点传播代码,无需遍历所有的程序指令.
从而算法效率更高.
对于每一种优化算法,都是依据上述污点传播代码的特征进行优化的.
同时,考虑在即时编译器下以最快速度进行污点跟踪优化,优化算法在污点传播分析的同时进行污点跟踪优化,而不像传统编译器将数据流分析和代码优化算法分开.
3.
1冗余污点存取消除冗余污点存取消除是指消除冗余的污点在寄存器和内存之间移动.
以虚拟机指令add-int/2addrv0,v1和add-int/2addrv1,v0为例.
Dalvik即时编译器将其转化为表1第1列所示LIR(已将内存读指令集中并前置),其中,r5表示栈针位置,内存数据偏移量以字节为单位.
对于第1条虚拟机指令add-int/2addrv0,v1,首先,由于污点值交叉保存在内存,将变量v0和v1从偏移位置0和8处读入寄存器r1和r2,并将其污点值从偏移位置4和12处读入寄存器r0和r3.
然后,将操作数及其污点进行数值运算addsr1,r1,r2和污点传播运算orrr0,r0,r3.
最后,将数值和污点值写回内存.
同理,对于第2条指令完成相同动作.
由于即时编译器仅简单地将虚拟指令翻译为LIR指令,因此产生的代码较为庞大和冗余.
通过对虚拟机指令的污点传播分析,可得出第1条指令和第2条指令变量值及其污点值在内存中位置一致,此时,第2条指令不需要再次读取操作数及其污点,且第1条指令不需要立即将2070JournalofSoftware软件学报Vol.
28,No.
8,August2017数值运算结果和污点传播运算结果保存到内存,可在第2条指令执行完成后再保存相应数据值及其污点值.
删除冗余的污点存取代码后优化结果见表1第2列.
Table1Exampleofredundanttaintload-storeelimination表1冗余污点存取消除示例TaintwithoutoptimizationTaintwithoptimization(0x0010):ldrr1,[r5,#0](0x0010):ldrr1,[r5,#0](0x0012):ldrr0,[r5,#4](0x0012):ldrr0,[r5,#4](0x0014):ldrr3,[r5,#12](0x0014):ldrr3,[r5,#12](0x0016):ldrr2,[r5,#8](0x0016):ldrr2,[r5,#8](0x0018):ldrr4,[r5,#12](0x001a):addsr1,r1,r2(0x0018):addsr1,r1,r2(0x001c):ldrr0,[r5,#4](0x001e):ldrr3,[r5,#12](0x0020):orrr0,r0,r3(0x001a):orrr0,r0,r3(0x0022):movsr1,r1(0x0024):strr1,[r5,#0](0x0026):strr0,[r5,#4](0x0028):addsr2,r2,r1(0x001c):addsr2,r2,r1(0x002a):ldrr4,[r5,#12](0x002c):ldrr7,[r5,#4](0x002e):movsr7,r0(0x0030):orrr4,r4,r7(0x001e):orrr3,r3,r0(0x0032):movsr2,r2(0x0034):strr2,[r5,#8](0x0036):strr4,[r5,#12](0x0038):strr4,[r5,#12](0x0020):strr3,[r5,#12](0x0040):strr2,[r5,#8](0x0022):strr2,[r5,#8](0x004a):strr0,[r5,#4](0x0024):strr0,[r5,#4](0x004c):strr1,[r5,#0](0x0026):strr1,[r5,#0]污点存取冗余是由于在污点传播代码中有大量无用的内存存取指令(数量几乎占插入代码的70%),通过分析污点在内存与寄存器之间移动的特性,可实现冗余污点存取消除.
在区分必然别名和寄存器值不被破坏的情况下,对于污点存取指令,分以下4种情况讨论.
(1)读后读(readafterread,简称RAR):数据污点值读取后又再次读取.
对于此种情况,如果污点数值在第1次读取内存与第2次读取内存之间不存在对该污点值的写入指令,则可以删除后一条读取内存指令.
(2)写后写(writeafterwrite,简称WRW):数据污点值写入内存后又再次写入内存.
对于此种情况,如果污点数值在第1次写入内存与第2次写入内存之间对该污点值的读入指令,则可以删除前一条污点值的写入指令.
(3)读后写(readafterwrite,简称RAW):数据污点值在读取后写入内存.
对于此种情况,如果在读取和写入内存之间不存在该数据污点值的传播点和污染点,则可将读取和写入内存指令删除;如果在读取和写入内存之间存在对该数据污点值的传播点但不存在污染点,则可将写入内存指令删除.
(4)写后读(writeafterread,简称WRA):数据污点值写入内存后读取.
对于此情况,则可将读取指令删除.
其具体算法如算法1所示.
算法1.
冗余污点存取代码消除.
输入:编译单元*cUnit,路径污点跟踪首指令*headLIR,路径污点跟踪尾指令*tailLIR.
输出:编译单元*cUnit.
1.
for(currentLIR=TAINT_PREV_LIR(t_tailLIR);currentLIR!
=t_headLIR;currentLIR=TAINT_PREV_LIR(currentLIR))2.
{if(!
(EncodingMap[currentLIR→opcode].
flags&(IS_LOAD|IS_STORE)))continue;3.
//判断当前污点传播指令类型是否为内存存取类型,若否,则继续循环4.
for(moveLIR=TAINT_PREV_LIR(currentLIR);吴泽智等:基于即时编译的动态污点跟踪优化2071moveLIR!
=t_headLIR;moveLIR=TAINT_PREV_LIR(moveLIR))5.
{if(!
(EncodingMap[moveLIR→opcode].
flags&(IS_LOAD|IS_STORE)))continue;6.
//判断当前污点传播指令类型为内存存取类型,若否,则继续循环7.
if(moveLIR→operands[0]==currentLIR→operands[0]&&moveLIR→aliasInfo==currentLIR→aliasInfo)8.
//互为别名,操作数本地寄存器一致且未被破坏9.
{if((isCurrentLIRLoad&&isMoveLIRLoad)||(!
isCurrentLIRLoad&&isMoveLIRLoad))10.
{moveLIR→flags.
isNop=true;}11.
//将后一读取指令删除12.
elseif(!
isThisLIRLoad&&!
isCheckLIRLoad)13.
{CurrentLIR→flags.
isNop=true;}14.
//将前一污点写入指令删除15.
elseif(isThisLIRLoad&&!
isCheckLIRLoad)16.
{if(currntTaintMask==moveTaintMask)17.
moveLIR→flags.
isNop=true;}18.
//将后一污点写入指令删除}19.
}endif20.
}//endfor21.
}//endfor3.
2污点重复计算消除污点重复计算消除是指消除污点值的重复计算.
同样以虚拟机指令add-int/2addrv0,v1与add-int/2addrv1,v0为例,执行第1条Dalvik指令后,v0污点值更新为10|;vvTaintTaint执行第2条Dalvik指令后,v1污点更新为10|.
vvTaintTaint由污点传播分析可知,两条虚拟机指令的污点运算值是相等的.
可将表1第2列编号为0x001e的指令orrr0,r0,r3替换成movsr3,r0,以提高指令执行速度.
对于污点重复计算消除,由于其程序逻辑中复杂的数值计算都将转化为污点传播逻辑中的或运算,因而会产生大量重复的计算表达式.
针对这种污点传播代码的特性,通过分析此种污点计算代码的特性,给出污点重复计算消除算法.
其实现的基本思想是:对于给定形如orrr0,r0,r1和orrr1,r1,r0表达式,若其间不存在其他对r0与r1的污染点,则可将后一表达式替换为执行速度更快的指令movr1,r0.
其具体算法如算法2所示.
算法2.
污点重复计算消除.
输入:编译单元*cUnit,路径污染跟踪首指令*headLIR,路径污点跟踪尾指令*tailLIR.
输出:编译单元*cUnit.
1.
for(currentLIR=TAINT_PREV_LIR(tailLIR);currentLIR!
=t_headLIR;currentLIR=TAINT_PREV_LIR(currentLIR))2.
{if(!
(EncodingMap[currentLIR→opcode].
flags&(IS_ORR)))continue;3.
//判断当前污点传播指令类型是否为ORR类型4.
for(moveLIR=TAINT_PREV_LIR(currentLIR);moveLIR!
=t_headLIR;moveLIR=PREV_LIR(moveLIR))5.
{if(!
(EncodingMap[moveLIR→opcode].
flags&(IS_ORR)))continue;6.
//判断当前污点传播指令类型是否为ORR类型7.
if(moveLIR→operands[0]==currentLIR→operands[0]&&moveLIR→operands[2]==currentLIR→operands[2])8.
//操作数本地寄存器一致2072JournalofSoftware软件学报Vol.
28,No.
8,August20179.
{newLIR=dvmCompilerRegCopyNoInsert(cUnit,moveLIR→operands[0],moveLIR→operands[2]);10.
dvmCompilerInsertLIRAfter(moveLIR,newLIR);11.
moveLIR→flags.
isNop=true;}12.
//产生一条mov复制指令并插入,同时,将后一orr运算指令删除13.
elseif(moveLIR→operands[0]==currentLIR→operands[0]||moveLIR→operands[0]==currentLIR→operands[2])14.
break;15.
//操作数在该处污染,结束当前循环,在外循环中检查下一条currentLIR16.
}//endfor17.
}//endfor3.
3循环不变污点传播代码外提循环是程序中不可缺少的一种控制结构,因为循环中的代码要重复执行,所以对循环代码的污点优化效果十分明显.
循环不变污点传播代码外提,是指将循环体中反复进行污点值运算但污点值不变的代码提取到循环体必经后置基本块.
仍然以第2节的dalvik代码为例,即时编译器探测到此循环并选择add-int/2addrv0,v1和add-int/lit8v2,v2,0x1和if-ltv2,v3,:goto_0为热点路径,并将其编译为7个基本块,其中,关键基本块CodeBlock与NormalChainingCell代码见表2第2列.
在程序逻辑下,变量a的数值是循环变化的.
但污点传播逻辑下,变量a的污点值是循环不变的.
同理,对于循环归纳变量,其污点值也是不变的.
因此,可将ldrr0,[r5,#4],ldrr3,[r5,#12],ldrr7,[r5,#28],orrr0,r0,r3等污点操作指令提取到循环必经后置节点,见表2第3列.
Table2Exampleofloopinvarianttaintpropagationcodemotion表2循环不变污点传播代码外提示例TaintwithoutoptimizationTaintwithoptimizationCodeblock(0x0010):ldrr1,[r5,#0](0x0010):ldrr1,[r5,#0](0x0012):ldrr0,[r5,#4](0x0014):ldrr3,[r5,#12](0x0016):ldrr2,[r5,#8](0x0012):ldrr2,[r5,#8](0x0018):ldrr4,[r5,#24](0x0014):ldrr4,[r5,#24](0x001a):addsr1,r1,r2(0x0016):addsr1,r1,r2(0x001c):ldrr7,[r5,#28](0x001e):ldrbr8,[r6,#50](0x0018):ldrbr8,[r6,#50](0x0022):orrr0,r0,r3(0x0026):addsr4,r4,#1(0x001a):addsr4,r4,#1(0x0028):cmpr8,#0[0](0x001c):cmpr8,#0[0](0x002c):strr7,[r5,#28](0x002e):strr4,[r5,#24](0x001e):strr4,[r5,#24](0x0030):strr0,[r5,#4](0x0032):ldrr9,[r5,#32](0x0020):ldrr9,[r5,#32](0x0036):strr1,[r5,#0](0x0024):strr1,[r5,#0](0x0038):bnePCReconstruction(0x0026):bnePCReconstruction(0x003a):cmpr4,r9(0x0028):cmpr4,r9(0x003c):blt0x0010(0x002a):blt0x0010(0x0040):b0x004c(0x002e):b0x003aNormalchainingcell(0x004c):b0x0050(0x003a):b0x003e(0x004e):orrsr0,r0(0x003c):orrsr0,r0(0x003e):ldrr0,[r5,#4](0x0040):ldrr3,[r5,#12](0x0042):orrr0,r0,r3(0x0046):strr0,[r5,#4](0x0050):ldrr0,[r6,#100](0x0048):ldrr0,[r6,#100](0x0052):blxr0(0x004a):blxr0(0x0054):data0xe7d6(59350)(0x004e):data0xe7d6(59350)(0x0056):data0x4a2c(18988)(0x0050):data0x4a2c(18988)吴泽智等:基于即时编译的动态污点跟踪优化2073实现循环不变污点传播代码外提,关键在于找到循环污点不变量,分以下两种情况讨论.
第1是循环归纳变量,循环归纳变量较容易分析,其污染点和传播点都在PHI节点处,且其数值加减某一常数.
如示例代码add-int/lit8v2,v2,0x1,当中v2是归纳变量,其污点值在循环过程中不变.
第2是非归纳不变量,非归纳不变量分析较为复杂.
第1种情况是某变量污染点和传播点都在一处且传播点位于该处的其他变量在循环体内不存在污染点,如示例代码add-int/2addrv0,v1满足此类情况,v0寄存器的污染点和传播点都在该指令处,且v1寄存器在循环其他处不存在污染点;第2种情况是某变量污染点和传播点都在一处且传播点位于该处的其他变量是循环污点不变量,如示例代码add-int/2addrv0,v1与add-int/2addrv1,v0中,v0和v1的污点值均是循环不变量.
第2种情况需要使用迭代算法,由于污点传播框架中污点值域格具有有穷的高度,且是单调的,可证明迭代算法是收敛的.
其证明过程可参见编译原理中数据流分析算法敛散性证明[29].
因而,循环不变污点传播代码外提算法如算法3所示.
算法3.
循环不变污点传播代码外提算法.
输入:编译单元*cUnit,循环体污点传播首指令*headLIR,循环体污点传播尾指令*tailLIR.
输出:编译单元*cUnit.
1.
for(currentLIR=t_headLIR;currentLIR!
=t_tailLIR;currentLIR=TAINT_NEXT_LIR(currentLIR))2.
{if(!
(EncodingMap[currentLIR→opcode].
flags&(IS_ORR))continue;3.
//判断当前污点传播指令类型是否ORR类型4.
findLIV=1;5.
for(moveLIR=TAINT_NEXT_LIR(currentLIR);moveLIR!
=t_tailLIR;moveLIR=TAINT_NEXT_LIR(moveLIR))6.
{if(moveLIR→operands[0]==currentLIR→operands[0]&&!
((moveLIR→operands[2]==const||isLIV(moveLIR→operands[2]))))7.
findLIV=0;8.
break;}9.
if(findLIV=1)10.
{newLIR=dvmCompilerCopyLIR(cUnit,moveLIR);11.
dvmCompilerInsertLIRAfter(chainingcellLIR,newLIR);12.
moveLIR→flags.
isNop=true;}13.
//将循环不变污点传播代码外提14.
}//endfor15.
}//endfor4系统实现框架与测试4.
1系统实现框架在Dalvik即时编译器基础上实现了污点传播编译优化技术,其整体框架如图3所示.
(1)在解释器进行热点路径探测,若该路径入口指令执行次数达到阈值threshold(40),则编译该路径并进行污点传播优化;否则,不进行污点传播优化(冷路径优化代价过大).
(2)创建编译线程,完成MIR到SSA转换和基本的方法内联优化,并填充MIR相应污点数据结构.
(3)将MIR转换成LIR:首先,依据程序逻辑向污点传播逻辑转化特点,完成MIR指令污染点和传播点分析,并将插入的污点跟踪指令组织为双向链表;填充LIR相应污点数据结构(Taint_map),并完成路径流图分析.
若该路径是循环,则需完成循环信息分析.
(4)通过以上3种污点传播优化算法,完成对以双向链表组织的污点跟踪指令的LIR进行污点传播优化.
2074JournalofSoftware软件学报Vol.
28,No.
8,August2017最后,将LIR转化成机器码,并返回路径将入口内存地址.
DALVIK虚拟机解释器路径调度器路径缓存哈希表路径本地指令缓存是否达到热路径门限值路径是否已编译缓存启动编译线程污染点标记污点传播分析污点传播优化传播点标记.
.
.
循环识别冗余污点存取消除污点重复计算消除循环不变污点传播代码外提污点传播分析和优化否是No是基本方法内联优化Fig.
3Frameworkoftaintpropagationoptimization图3污点传播优化整体框架4.
2系统功能与性能测试本文所有测试均在模拟器上进行,操作系统环境为os/Ubuntu-12.
04,cpu/2.
27GHZ,RAM/4GB,version/Android-4.
1.
1.
启动模拟器关键参数如下:emulator–kernelqumu-armv7–ramdiskramdisk.
img–datauserdata.
img–sdcardsdcard.
img–partition-size500–memory512(本文原型系统OFCDroid和对比系统FCDroid可从http://pan.
baidu.
com/s/1pJC63uN处下载).
4.
2.
1系统功能测试功能测试的目的在于测试污点优化正确性,即在应用污点传播优化算法后,与未优化前系统隐私泄露报告是否一致.
测试用例使用系统应用和自制应用wzztest.
apk,测试用例包括了不同类型Dalvik指令OP_MOVE,OP_RETURN,OP_CONST,OP_AGET,OP_APUT,OP_IGET,OP_IPUT,OP_SGET,OP_SPUT,OP_INVOKE,OP_INT_TO_LONG,OP_ADD_INT和OP_OR_INT.
测试的隐私数据类型包括string,char,byte,int,long,float,doube和array.
以自带短信程序在通过系统调用接口读取联系人息时,短信程序与安卓系统间通信方法writeString()所含的路径将被编译为热点路径,其测试结果如图4所示.
其中,路径中包含的Dalvik指令如下.
const-stringv1,"*"new-instancev3,Ljava/lang/StringBuilderinvoke-virtual{v3,v1},Ljava/lang/StringBuilder;→append(Ljava/lang/String;)Ljava/lang/StringBuilder;move-result-objectv4其次,使用污点跟踪测试床DroidBench[30]测试系统污点跟踪的正确性.
DroidBench是专门针对安卓平台开发的污点跟踪测试工具,可测试系统在数组污点跟踪、方法污点跟踪、指令污点跟踪、应用内部和外部通信污点跟踪和隐式污点跟踪等方面污点跟踪的正确性,测试结果见表3.
在所选取的51个小测试中,OFCDroid检测到其中36个隐私泄漏并发出警告,15个未发出警告,7个误报.
未发出警告是由于未跟踪隐式信息流,误报是由于数组和字符串污点跟踪过于粗糙.
OFCDroid与FCDroid各项测试结果均一致,表明经过污点传播优化后,污点跟踪仍然是正确的.
吴泽智等:基于即时编译的动态污点跟踪优化2075Fig.
4Notificationofprivacyleak图4隐私泄露通知Table3TestresultsofDroidBench表3DroidBench测试结果正确警告数量a错误警告数量b未警告数量c准确率a/(a+b)(%)漏报率c/(a+c)(%)FCDroid3671583.
729.
4OFCDroid3671583.
729.
44.
2.
2系统性能测试首先测试污点传播优化算法对单条热路径的优化效果和优化代价,优化效果主要通过编译后代码的大小来衡量,代码越小,其执行速度越快,内存占用越少,故优化效果更佳.
优化代价主要通过编译每条热路径耗费时间长短来衡量,编译时间越短,优化代价就越低.
选择安卓操作系统最常被编译为热点路径所属的方法作为测试对象,其测试结果见表4.
Table4Effectsandcostsofthehottraceoptimization表4热路径优化效果与代价热路径所在方法名AndroidFCDroidOFCDroid路径大小(byte)编译时间(μs)路径大小(byte)编译时间(μs)路径大小(byte)编译时间(μs)Ljava/io/File;fixSlashes116264581402797312831196Ljava/util/ArryList$ArraylistIterator;next761732576184437620912Llibcore/util/collectionUtils$1$1;computenext96200911122205410425503Llibcore/util/collectionUtils$1$1;hasnext681562980186997220875Ljava/lang/caseMapper;toUpperCase188317402443387222835280Ljava/lang/character;isHighSurrogate641685472179477218465Ljava/lang/String;hashcode7620448112222639626283LAndroid/os/systemproperties;getint136362151803920116443314对于方法Ljava/io/File;fixSlashes,Android系统通过即时编译器编译后代码占用116字节内存空间,编译耗时26458μs;加入污点传播机制后,FCDroid系统通过即时编译器编译后代码占用140字节内存空间,编译耗时27973μs;引入污点传播优化机制后,OFCDroid系统通过即时编译器编译后代码占用128字节内存空间,编译耗时31196μs.
编译器以11.
5%的编译时间代价获取了8.
5%的运行速度和内存占用的优化效果.
对于方法Ljava/lang/String;hashcode,优化效果最佳达到14.
2%,但优化代价也最大.
对于方法Ljava/lang/character;isHighSurrogate,其优化代价最小为2.
8%,但优化效果最差.
2076JournalofSoftware软件学报Vol.
28,No.
8,August2017Android系统平均每条热路径占用102字节,平均编译时间为23095μs;FCDroid系统平均每条热路径占用127字节,平均编译时间为25056μs;OFCDroid系统平均每条热路径占用117字节,平均编译时间为27728μs.
实验结果表明,经过优化后,每条路径平均少占用10字节,相对于整条热路径指令,污点跟踪优化算法的平均优化率为7.
8%.
相对于插入的污点跟踪指令,污点跟踪优化算法平均优化率为38%.
然后,测试各污点传播优化算法对于单条热路径的优化性能.
优化性能主要通过各污点传播优化算法执行时间的长短来衡量,执行时间越长,算法相对性能就越差.
同样选择上述表4热点路径作作为测试对象,其测试结果见表5.
Table5Performanceoftaintpropagationoptimizationalgorithms表5污点传播优化算法性能热路径所在方法名冗余污点存取优化时间(μs)污点重复计算优化时间(μs)循环不变污点代码外提优化时间(μs)总优化时间(μs)Ljava/io/File;fixSlashes8272227431859Ljava/util/ArryList$ArraylistIterator;next7631450933Llibcore/util/collectionUtils$1$1;computenext8211250971Llibcore/util/collectionUtils$1$1;hasnext132210197Ljava/lang/caseMapper;toUpperCase7582150994Ljava/lang/character;isHighSurrogate1391860344Ljava/lang/String;hashCode63513713352126LAndroid/os/systemproperties;getint11693101217对于优化算法冗余污点存取消除,平均优化时间1180μs,方法LAndroid/os/systemproperties;getint耗时最长为2169μs.
对于优化算法污点重复计算消除,平均优化时间135μs,方法Ljava/io/File;fixSlashes耗时最长为222μs.
对于优化算法循环不变污点传播代码外提,方法Ljava/io/File;fixSlashes和Ljava/lang/String;hashCode中路径包含循环,平均优化时间1936μs.
由于其他路径不属于循环,故其用时为0us.
其次,选择常见系统应用并测试其使用性能.
选择见表6第1列所示的安卓应用程序作为测试对象,每个应用分别进行20次使用测试,并记录其平均执行时间和方差,经过优化后的执行时间越短,表明优化效果越好.
系统优化效率的计算方法为(TimeFCDroidTimeOFCDroid)/TimeFCDroid*100%.
Table6Optimizationeffectofvariousapplicationunderprototypesystem表6不同应用在原型系统下的优化效果应用程序名AndroidFCDroidOFCDroid优化效果(%)平均耗时(ms)方差平均耗时(ms)方差平均耗时(ms)方差短信720.
5860.
5781.
29.
3美图秀秀74534.
294437.
588035.
56.
7联系人891.
31111.
71013.
39.
0电话1222.
21383.
21294.
66.
5图片浏览34410.
538112.
735714.
36.
2微信25515.
429817.
327517.
27.
7uc浏览器172366.
0200168.
3187477.
36.
3ZArchiver压缩153457.
4175646.
5170053.
43.
1对于发送短信,测试点击信息发送直至发送成功所需时间,Android系统耗时72ms;加入污点传播机制后,FCDroid系统耗时86ms;经过优化后,OFCDroid系统耗时78ms.
污点跟踪优化后,系统效率提高了9.
3%.
对于拨打电话,测试按下拨打键至系统硬件产生回应所需时间,其优化效率为6.
5%.
对于拍摄照片,测试按下拍摄键至保存照片完成(照片大小约在546KB左右)所需时间,其优化效率为6.
8%.
对于微信聊天,测试按下发送键至信息发送完成所需时间,其优化效率为7.
7%.
吴泽智等:基于即时编译的动态污点跟踪优化2077对于浏览网页,测试按下前进键至网页完成显示所需时间,其优化效率为6.
3%.
对于读取联系人信息和浏览照片,其优化效率分别为9.
0%和6.
2%.
对于压缩文件,选择1M大小的单个txt文件,测试开始压缩至压缩完成所需时间,其优化效率为3.
1%.
相对来说优化效率偏低,可能是由于压缩算法主要实现在.
so文件中,而本文工作是基于即时编译的污点跟踪优化,是在将dalvik字节码编译转化为本地指令码过程中进行的污点传播优化.
整体上,通过优化后,系统效率平均提高了6.
8%.
最后,采用caffeineMark3.
0测试OFCDroid系统整体性能,其测试结果如图5所示.
对于caffeineMark测试结果,在float得分与logic得分上,OFCDroid与FCDroid差别并不明显,由于其得分高低主要与硬件性能相关;而在loop得分,OFCDroid比FCDroid多出26%.
这是由于循环代码执行次数多,容易被探测为热点路径且被编译为本地代码.
以方法Ljava/lang/String;hashCode为例,设其循环执行次数为n,每条指令执行时间为mμs,其优化后节省指令数为8,则对于该方法执行一次可节省8nmμs.
循环次数越多,优化效果就越明显.
Fig.
5TestresultsofcaffeineMark图5CaffeineMark测试结果5结束语本文针对污点跟踪技术在移动隐私保护方面存在效率较低的问题,提出了一种基于即时编译的动态污点传播优化方法.
首先,将程序逻辑精确抽象为污点传播逻辑,简化污点传播分析复杂性;然后,提出了一个污点传播框架,证明该框架下污点传播分析算法的正确性和有效性,给出了污点传播代码优化算法的实现及算法的性能测试结果.
实验结果表明,该优化方法有效提高了动态污点跟踪系统的性能.
由于污点传播优化精确性问题依赖于全局的污点传播分析和控制流分析,还有待后续进一步的深入研究.
References:[1]WanZY,JiangX.
DissectingAndroidmalware:Characterizationandevolution.
In:Proc.
oftheIEEESymp.
onSecurityandPrivacy.
Oakland:IEEE,2012.
95109.
[doi:10.
1109/SP.
2012.
16][2]SchwartzEJ,AvgerinosT,BrumleyD.
Allyoueverwantedtoknowaboutdynamictaintanalysisandforwardsymbolicexecution(butmighthavebeenafraidtoask).
In:Proc.
oftheIEEESymp.
onSecurityandPrivacy.
Oakland:IEEE,2010.
317331.
[doi:10.
1109/SP.
2010.
26][3]SunH,LiHP,ZengQK.
StaticallydetectandRun-timecheckinteger-basedvulnerabilitieswithinformationflow.
RuanJianXueBao/JournalofSoftware,2013,24(12):27672781(inChinesewithEnglishabstract).
http://www.
jos.
org.
cn/1000-9825/4385.
htm[doi:10.
3724/SP.
J.
1001.
2013.
04385][4]ChowJ,PfaffB,GarfinkelT,ChristpherK,RosenblumM.
Understandingdatalifetimeviawholesystemsimulation.
In:Proc.
oftheUSENIXSecuritySymp.
Berkeley:USENIX,2004.
321336.
[5]AttariyanM,FlinnJ.
Automatingconfigurationtroubleshootingwithdynamicinformationflowanalysis.
In:Proc.
ofthe9thOSDI.
Berkeley:USENIX,2010.
237250.
2078JournalofSoftware软件学报Vol.
28,No.
8,August2017[6]NairSK,SimpsonPND,CrispoB,TanenbaumAS.
Avirtualmachinebasedinformationflowcontrolsystemforpolicyenforcement.
ElectronicNotesinTheoreticalComputerScience,2008,197(1):316.
[doi:10.
1016/j.
entcs.
2007.
10.
010][7]LamLC,ChiuehT.
Ageneraldynamicinformationflowtrackingframeworkforsecurityapplications.
In:Proc.
ofthe22ndAnnualComputerSecurityApplicationsConf.
(ACSAC2006).
IEEE,2006.
463472.
[doi:10.
1109/ACSAC.
2006.
6][8]MyersAC,LiskovB.
Protectingprivacyusingthedecentralizedlabelmodel.
ACMTrans.
onSoftwareEngineeringandMethodology,2000,9(4):410442.
[doi:10.
1145/363516.
363526][9]HedinD,SabelfeldA.
Information-FlowsecurityforacoreofjavaScript.
In:Proc.
oftheIEEE25thComputerSecurityFoundationsSymp.
(CSF).
Cambridge:IEEE,2012.
318.
[doi:10.
1109/CSF.
2012.
19][10]EfstathopoulosP,KrohnM,VanDeBogartS,FreyC,ZieglerD.
LabelsandeventprocessesintheAsbestosoperatingsystem.
In:Proc.
oftheSOSP.
Brighton:ACMPress,2005.
1730.
[doi:10.
1145/1095810.
1095813][11]KrohnM,YipA,BrodskyM,ClifferN,KaashoekMF,KolherE.
InformationflowcontrolforstandardOSabstractions.
In:Proc.
oftheACMSIGOPSOperatingSystemsReview.
NewYork:ACMPress,2007.
321334.
[doi:10.
1145/1294261.
1294293][12]YangZ,YinLH,DuanMY,WuJY,JinSY,GuoL.
Generalizedtaintpropagationmodelforaccesscontrolinoperationsystems.
RuanJianXueBao/JournalofSoftware,2012,23(6):16021619(inChinesewithEnglishabstract).
http://www.
jos.
org.
cn/1000-9825/4083.
htm[doi:10.
3724/SP.
J.
1001.
2012.
04083][13]PortokalidisG,HomburgP,AnagnostakisK,BosH.
ParanoidAndroid:Versatileprotectionforsmartphones.
In:Proc.
ofthe26thAnnualComputerSecurityApplicationsConf.
ACMPress,2010.
347356.
[doi:10.
1145/1920261.
1920313][14]ChenS,KozuchM,StrigkosT,RyanM,GibbonsPB.
Flexiblehardwareaccelerationforinstruction-grainprogrammonitoring.
ACMSIGARCHComputerArchitectureNews,2008,36(3):377388.
[doi:10.
1145/1394608.
1382153][15]RuwaseO,GibbonsPB,MowryTC,RamachandranV,ChenS,KozuchM.
Parallelizingdynamicinformationflowtracking.
In:Proc.
ofthe20thAnnualSymp.
onParallelisminAlgorithmsandArchitectures.
ACMPress,2008.
3545.
[doi:10.
1145/1378533.
1378538][16]ChowJ,GarfinkelT,ChenPM.
Decouplingdynamicprogramanalysisfromexecutioninvirtualenvironments.
In:Proc.
oftheUSENIX2008AnnualTechnicalConf.
Berkeley:USENIX,2008.
114.
[17]JeeK,KemerlisVP,KeromytisAD,PortokalidisG.
ShadowReplica:Efficientparallelizationofdynamicdataflowtracking.
In:Proc.
ofthe2013ACMSIGSACConf.
onComputer&CommunicationsSecurity.
ACMPress,2013.
235246.
[doi:10.
1145/2508859.
2516704][18]JeeK,PortokalidisG,KemerlisVP,GhoshS,AugustDI.
Ageneralapproachforefficientlyacceleratingsoftware-baseddynamicdataflowtrackingoncommodityhardware.
In:Proc.
ofthe19thNDSS.
SanDiego:InternetSociety,2012.
324335.
[19]ChangW,StreiffB,LinC.
Efficientandextensiblesecurityenforcementusingdynamicdataflowanalysis.
In:Proc.
ofthe15thACMConf.
onComputerandCommunicationsSecurity.
Alexandria:ACMPress,2008.
3950.
[doi:10.
1145/1455770.
1455778][20]HoA,FettermanM,ClarkC,WarfieldA,HandS.
Practicaltaint-basedprotectionusingdemandemulation.
ACMSIGOPSOperatingSystemsReview,2006,40(4):2941.
[doi:10.
1145/1218063.
1217939][21]PortokalidisG,BosH.
Eudaemon:Involuntaryandon-demandemulationagainstzero-dayexploits.
In:Proc.
ofthe2008EuroSys.
ACMPress,2008.
287299.
[doi:10.
1145/1352592.
1352622][22]SaxenaP,SekarR,PuranikV.
Efficientfine-grainedbinaryinstrumentationwithapplicationstotaint-tracking.
In:Proc.
ofthe6thCGO.
ACMPress,2008.
7483.
[23]KimHC,KeromytisAD.
Onthedeploymentofdynamictaintanalysisforapplicationcommunities.
IEICETrans.
onInformation&Systems,2009,92(3):548551.
[24]QinF,WangC,LiZ,KimH,ZhouY.
Lift:Alow-overheadpracticalinformationflowtrackingsystemfordetectingsecurityattacks.
In:Proc.
ofthe39thAnnualIEEE/ACMInt'lSymp.
onMicroarchitecture.
IEEE,2006.
135148.
[doi:10.
1109/MICRO.
2006.
29][25]KemerlisVP,PortokalidisG,JeeK,KeromytisAD.
libdft:Practicaldynamicdataflowtrackingforcommoditysystems.
ACMSIGPLANNotices,2012,47(7):121132.
[doi:10.
1145/2365864.
2151042][26]EnckW,GilbertP,HanS,Tendulkar,ChunBG.
TaintDroid:Aninformation-flowtrackingsystemforrealtimeprivacymontoringonsmartphones.
In:Proc.
oftheOSDI.
Berkeley:USENIX,2010.
255270.
[doi:10.
1145/2494522]吴泽智等:基于即时编译的动态污点跟踪优化2079[27]HuangY,ChenY,YangW,ShannJJ.
File-BasedsharingfordynamicallycompiledcodeonDalvikvirtualmachine.
In:Proc.
oftheInt'lComputerSymp.
IEEE,2010.
489494.
[doi:10.
1109/COMPSYM.
2010.
5685462][28]LingM,WuJP,FengKH.
Anadaptivecompilationsystembasedonthedalvikvirtualmachine.
ActaElectronicaSinica,2013,41(8):16221627(inChinesewithEnglishabstract).
[doi:10.
3969/j.
issn.
0372-2112.
2013.
08.
027][29]AhoAV,SethiR,UllmanJD.
Compilers,Principles,Techniques.
2nded.
,AddisonWesleyPublishingCompany,1986.
688703.
[30]FritzC,ArztS,RasthoferS,BoddenE,BartelA.
Highlyprecisetaintanalysisforandroidapplication.
TechnicalReport,TUD-CS-2013-0113,2013.
http://www.
bodden.
de/pubs/TUD-CS-2013-0113.
pdf附中文参考文献:[3]孙浩,李会朋,曾庆凯.
基于信息流的整数漏洞插装和验证.
软件学报,2013,24(12):27672781.
http://www.
jos.
org.
cn/1000-9825/4385.
htm[doi:10.
3724/SP.
J.
1001.
2013.
04385][12]杨智,殷丽华,段洣毅,吴金宇,金舒原,郭莉.
基于广义污点传播模型的操作系统访问控制.
软件学报,2012,23(6):16021619.
IonSwitch:$1.75/月KVM-1GB/10G SSD/1TB/爱达荷州
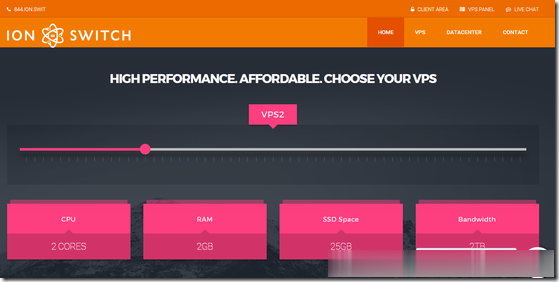
IonSwitch是一家2016年成立的国外VPS主机商,部落上一次分享的信息还停留在2019年,主机商提供基于KVM架构的VPS产品,数据中心之前在美国西雅图,目前是美国爱达荷州科德阿伦(美国西北部,西接华盛顿州和俄勒冈州),为新建的自营数据中心。商家针对新数据中心运行及4号独立日提供了一个5折优惠码,优惠后最低1GB内存套餐每月仅1.75美元起。下面列出部分套餐配置信息。CPU:1core内存...
捷锐数据399/年、60元/季 ,香港CN2云服务器 4H4G10M
捷锐数据官网商家介绍捷锐数据怎么样?捷锐数据好不好?捷锐数据是成立于2018年一家国人IDC商家,早期其主营虚拟主机CDN,现在主要有香港云服、国内物理机、腾讯轻量云代理、阿里轻量云代理,自营香港为CN2+BGP线路,采用KVM虚拟化而且单IP提供10G流量清洗并且免费配备天机盾可达到屏蔽UDP以及无视CC效果。这次捷锐数据给大家带来的活动是香港云促销,总共放量40台点击进入捷锐数据官网优惠活动内...

Megalayer(159元 )年付CN2优化带宽VPS
Megalayer 商家我们还算是比较熟悉的,商家主要业务方向是CN2优化带宽、国际BGP和全向带宽的独立服务器和站群服务器,且后来也有增加云服务器(VPS主机)业务。这次中秋节促销活动期间,有发布促销活动,这次活动力度认为还是比较大的,有提供香港、美国、菲律宾的年付VPS主机,CN2优化方案线路的低至年付159元。这次活动截止到10月30日,如果我们有需要的话可以选择。第一、特价限量年付VPS主...
-
租用主机哪个平台可以租电脑美国主机空间买空间网的美国主机咋样?租服务器我想租服务器,请问会提供哪些服务?中文域名注册查询哪里有可以查询中文域名是否被注册的地方?查询ip怎么查询IP地址台湾vps香港vps和台湾vps哪个好用100m虚拟主机万网和新网虚拟主机有100M的吗新加坡虚拟主机如何购买godaddy的新加坡主机?域名解析域名解析怎么弄?二级域名什么叫一级 二级域名