direction尼坤letitrain
尼坤letitrain 时间:2021-01-15 阅读:()
WhatIsItYouReallyWantofMeGeneralizedRewardLearningwithBiasedBeliefsaboutDomainDynamicsZeGongandYuZhangSchoolofComputing,Informatics,andDecisionSystemsEngineeringArizonaStateUniversity,Tempe,AZ85281USA{zgong11,yzhan442}@asu.
eduAbstractRewardlearningasamethodforinferringhumanintentandpreferenceshasbeenstudiedextensively.
Priorapproachesmakeanimplicitassumptionthatthehumanmaintainsacor-rectbeliefabouttherobot'sdomaindynamics.
However,thismaynotalwaysholdsincethehuman'sbeliefmaybebiased,whichcanultimatelyleadtoamisguidedestimationofthehuman'sintentandpreferences,whichisoftenderivedfromhumanfeedbackontherobot'sbehaviors.
Inthispaper,weremovethisrestrictiveassumptionbyconsideringthatthehu-manmayhaveaninaccurateunderstandingoftherobot.
WeproposeamethodcalledGeneralizedRewardLearningwithbiasedbeliefsaboutdomaindynamics(GeReL)toinferboththerewardfunctionandhuman'sbeliefabouttherobotinaBayesiansettingbasedonhumanratings.
Duetothecom-plexformsoftheposteriors,weformulateitasavariationalinferenceproblemtoinfertheposteriorsoftheparametersthatgoverntherewardfunctionandhuman'sbeliefabouttherobotsimultaneously.
Weevaluateourmethodinasimulateddomainandwithauserstudywheretheuserhasabiasbasedontherobot'sappearances.
Theresultsshowthatourmethodcanrecoverthetruehumanpreferenceswhilesubjecttosuchbiasedbeliefs,incontrasttopriorapproachesthatcouldhavemisinterpretedthemcompletely.
IntroductionWiththerapidadvancementinAIandrobotics,intelli-gentagentsbegintoplayanimportantroleinourlivesinmanydifferentareas.
Robotswillsoonbeexpectedtonotonlyachievetasksalone,butalsoengageintasksthatre-quireclosecollaborationwiththeirhumanteammates.
Insuchsituations,theabilityoftherobottounderstandthehuman'sintentandpreferencesbecomesadeterminantforachievingeffectivehuman-robotteaming.
Theproblemofinferringhuman'sintentandpreferenceshasbeenstud-iedextensivelybefore.
Someresearchers(NgandRussell2000)formulatedthisproblemasanInverseReinforcementLearning(IRL)problem(Russell1998).
Therewardfunc-tionisrecoveredfromoptimalpoliciesorbehaviorsdemon-stratedbyhumanexperts.
Suchexpertdemonstrations,how-ever,areoftendifculttoobtaininreal-worldtasks.
Toad-Copyrightc2020,AssociationfortheAdvancementofArticialIntelligence(www.
aaai.
org).
Allrightsreserved.
dressthisproblem,learningmethodsbasedonnon-expertuserratingsoftherobot'sbehaviors(Danieletal.
2014;DorsaSadigh,Sastry,andSeshia2017;CuiandNiekum2018)aredeveloped.
Acommonassumptionmadeimplic-itlyinallthesepriorworksisthatthehumanalwaysmain-tainsacorrectunderstandingoftherobot'sdomaindynam-ics.
This,however,maynotbethecaseinmanyscenarioses-peciallywithnon-expertusers.
Havingabiasedbeliefabouttherobotcouldleadtobiased(notjustnoisy)ratingsfortherobot'sbehaviors,resultinginaninaccurateestimationofthehuman'srewardfunction.
Considerarobotvacuumcleanerthatistaskedtocleantheoorsinahouse.
Supposethattherobotvacuumisde-signedtocleanmostoortypesexceptforhardwoodsinceitistooslipperyfortherobottograsponto(soitmaybestuckinaroomwithahardwoodooronceentered).
Considerauserwhoisaskedtoratetherobot'sbehaviors.
Givenasetoftrajectoriesoftherobotcleaner(withmostoftheareascoveredexceptforthelivingroomwithahardwoodoor),therobotmaygetlowratingseventhoughitshouldhavereceivedhighratingshadtheuserknownabouttherobot'scapabilities(whichareexpressedintermsofdomaindynam-ics).
Ontheotherhand,therobotmayreceivehighratings(eventhoughitshouldnothave)whenitstays(stuck)inthelivingroombutsomehowmanagestocleanit(albeitmuchlessefciently),iftheuserhadthebeliefthattherobotwasdesignedtocleanonlyoneroomatatime.
Inthispaper,weremovetherestrictiveassumptionthathumanshaveacorrectbeliefabouttherobot'sdomaindy-namics.
Ourgoalistorecoverthetruerewardfunctionunderbiasedbeliefs.
WerefertothisproblemasGeneralizedRe-wardLearning(GRL)andproposeamethodcalledGener-alizedRewardLearningwithbiasedbeliefsaboutdomaindynamics(GeReL)thatinfersthelatentvariablesgovern-ingboththerewardfunctionandhuman'sbelieftogetherinaBayesiansettingbasedonhumanratingsoftherobot'sbehaviors.
Duetothecomplexformsoftheposteriors,theproblemisformulatedinavariationalinferenceframework(Jordanetal.
1999;Bishop2006).
Thevariationalposte-riordistributionofthelatentvariablesforestimatingthetrueposteriorisoptimizedusingablack-boxoptimizationmethod(Ranganath,Gerrish,andBlei2014).
ToreducethevarianceofMonteCarloestimatesofthevariationalgradi-ents,wefactorizetheupdatingrulesaccordingtotheinde-pendenceofthelatentvariablesandapplycontrolvariatetomaketheoptimizationconvergefaster.
Byinferringthere-wardfunctionandthehuman'sbeliefabouttherobotsimul-taneouslyinthisway,ourlearningmethodisabletorecoverthetruehumanpreferenceswhileatthesametimemain-tainanestimateofthehuman'sbiasedbelief.
Assuch,ourmethodaddressesakeylimitationoftheexistingmethodsandhencehasbroadimpactsonimprovingtheapplicabilityandsafetyofroboticsystemsthatworkcloselywithhumans.
Toevaluateourmethod,weperformexperimentsinasim-ulatednavigationdomainandwithauserstudyintheCoffeeRobotdomain(Boutilier,Dearden,andGoldszmidt2000;SigaudandBuffet2013)wherebiasesareintroducedbyvaryingtherobot'sappearances.
WecompareGeReLwithavariantofSimultaneousEstimationofRewardsandDy-namics(SERD)(Hermanetal.
2016),MaximumEntropyIRL(MaxEnt-IRL)(Ziebartetal.
2008),andanotherbase-lineapproachthatusesourinferencemethodbutmaintainsthesameassumptionasinMaxEnt-IRL(thatthehuman'sunderstandingoftherobotiscorrect).
Inthelattertwometh-ods,thetruedomaindynamicsisusedandheldxedduringlearning.
ResultsshowthatGeReLcanbetterrecoverthetruerewardfunctionundersuchbiasedbeliefswhencom-paredtotheseothermethods.
Furthermore,whenbiasesarepresent,thelearnedpreferencescouldbecompletelyoppo-sitetothegroundtruth,suggestingthatsuchamethodisin-deedvaluableforaddressingbiasesinroboticapplications.
RelatedWorkResearchershaveformulatedtheproblemofinferringthehuman'sintentandpreferencesasanIRLproblem(Rus-sell1998)wherethegoalistorecoverthehuman'spref-erencesasarewardfunction.
IRLisoftensolvedusingvariousoptimizationtechniqueswithexpertdemonstrationsastheinput(NgandRussell2000).
IRLhasalsobeenappliedtoapprenticeshiplearning(AbbeelandNg2004)todirectlyapproximatetheexpert'spolicy.
Inordertodealwithnoiseinthedemonstrations,(Ziebartetal.
2008;Boularias,Kober,andPeters2011)proposedaprobabilisticapproachbasedontheprincipleofmaximumentropy.
Fur-thermore,BayesianIRL(RamachandranandAmir2007)isintroducedthatincorporatespriorknowledge.
However,expertdemonstrations(withorwithoutnoise)areoftendifculttoobtaininreal-worldtasks.
Morere-cently,researchersstartfocusingonlearningwithnon-expertfeedbackonthequeriesoftherobot'sbehaviors,of-tenintheformsofratings(Danieletal.
2014),comparisons(DorsaSadigh,Sastry,andSeshia2017),orcritiques(CuiandNiekum2018;ZhangandDragan2019).
Allthesepriorworksrelyonanimplicitassumptionthatthenon-expertusermaintainsacorrectunderstandingoftherobot'sdomaindynamics.
However,whentheuserisbiased,whichislikelyundersuchanon-expertsetting,itmayleadtolearningawrongrewardfunction.
Thereexistspriorworkthatconsidersdifferencesbe-tweenthehumanandrobotintheformsofdifferencesindo-maindynamics(Zhangetal.
2016;2017;Chakrabortietal.
Figure1:WorkowofGeReL.
Usingtherobot'struetransi-tionmodelTR,therobotrandomlygeneratesasetofdemon-strationsZwhichareevaluatedbythehuman.
ThehumanisassumedtoprovidehisratingγH∈ΓHforeachinstanceζ∈ZaccordingtotherewardfunctionRHandhisbe-liefThRabouttherobot'sdomaindynamics.
TheratingswillbeusedtoupdatetheestimatedrewardfunctionRH(gov-ernedbytheparametersw)andhuman'sunderstandingoftherobotThR(governedbytheparametersΘ).
Graycirclesdenotethelatentvariableswhiletheobservedareinwhite.
2017)aswellasrewardfunctions(Arnold,Kasenberg,andScheutz2017;Russell,Dewey,andTegmark2015),wheretherstdirectionisparticularlyrelevanttoourwork.
(Zhangetal.
2016;2017;Zakershahraketal.
2018)approximatethehuman'sunderstandingoftherobot'sbehaviorsusingalearningapproachandintegrateitintotaskplanningtogenerateexplicableplanstobridgethedifferencesindo-maindynamics.
Researchershavealsoinvestigateddirectlylearningthehuman'sunderstandingofthedomaindynam-icsusingmodellearning.
(UnhelkarandShah2019)lever-ageafactoredmodelofbehaviorsandpartialspecicationstorecovertheagent'struegenerativemodelofbehaviors.
(Reddy,Dragan,andLevine2018)learnthehuman'sbeliefaboutthedomaindynamicsviainversesoftQ-learninggiventhehuman'srewardfunction.
Inthispaper,weconsiderthehuman'sbiasedbeliefabouttherobotinrewardlearning.
Weusethehuman'sratingsoftherobot'sbehaviorstoinferboththerewardfunctionandhuman'sbeliefwithoutassum-ingeitherisavailable.
Althoughsimultaneouslylearningtherewardsanddomaindynamicshasbeenstudiedbefore(Her-manetal.
2016),itisnotapplicabletoourproblemsettingwherenon-experthumanratingsareused.
Comparedtoop-timizingthelikelihoodofexpertdemonstrationsbycomput-ingthederivativesdirectly,theposteriorsforourmethodas-sumemorecomplexforms.
Furthermore,ourmethoddoesnotrequirethevaluefunctionstotakecertainforms(e.
g.
,usingsoftBellmanequation)toperformwellandhenceitismoregeneralandeffective.
Thereby,thesmoothingeffectofentropyregularizedrewardfunctioncausedbysoftBellmanequationisavoided,aswewillshow.
GeReLTheworkowofGeReLispresentedinFigure1.
Therobotwillrstrandomlygenerateasetofdemonstrationsforqueryingthehumanforratings.
Then,theratingsofthedemonstrationswillbeusedtoinferboththehuman'sre-wardfunctionandhisbelief.
Thesystemterminateswhenitmeetstheconvergencecriterion.
Similartopriorworkonre-wardlearning,weassumethatthehumanistoalwaysmax-imizetherewards(NgandRussell2000;AbbeelandNg2004),sothathisratingscanbeestimatedgiventherewardfunctionandhisbeliefofthedomaindynamics.
ProblemFormulationMorespecically,givenarobot'sdemonstrationζ,weas-sumethatthehumanwouldrateitaccordingtotwofactors,therewardfunctionRHandhisbeliefabouttherobot'sdo-maindynamicsThR.
Whenthehuman'sbeliefisdifferentfromthetruerobot'sdomaindynamics,theratingmaybebiasedandcouldthenleadtoawronginterpretationofthehuman'spreference.
ThissettingintroducestheGeneralizedRewardLearning(GRL)problemasfollows:Given:Robot'sdemonstrationsZ;Human'sratingsΓHforeachinstanceinZ.
Todetermine:Human'struerewardfunctionRH;Human'sbeliefThRaboutrobot'sdomaindynamics.
Tosolvethisproblem,weformulatetheenvironmentasaMarkovDecisionProcesses(MDP).
AnMDPisdenedbyatuple(S,A,R,T,λ)whereSisanitesetofstates,Aisanitesetofactions,andR:S→Ristherewardfunctionthatmapseachstatetoautilityvalue.
T:S*A*S→[0,1]isthetransitionfunctionthatspeciestheprobabilityoftransitioningtothenextstatewhenyoutakeanactioninthecurrentstate.
λisthediscountfactorthatdetermineshowtheagentfavorscurrentrewardsoverfuturerewards.
Similartopriorworkonrewardlearning(NgandRus-sell2000;AbbeelandNg2004),weformulatetherewardfunctionRHforastatesasfollows:RH(s)=w·Φ(s)whereΦ=[φ0,φ1,φk]Tdenotesasetofpredenedfeaturesforstatesandw=[w0,w1,wk]Tdenotesasetofweightsforthefeatures.
Therobot'sdomaindynam-ics(i.
e.
,thetruedomaindynamics)iscapturedbyatransi-tionfunctionandassumedtobegiven.
Likewise,thehu-man'sbeliefabouttherobot'sdomaindynamicsismod-eledalsoasatransitionfunctionThR,whichishidden.
ThRisassumedtofollowasetofprobabilitydistributionsΘ=[θ1,θ2,θ|S|*|A|]whereθi=p(s|s,a)isadistributionforaxedsanda.
Thesedistributionscapturethehuman'spriorbeliefabouttherobot.
Toratearobot'sbehaviorζ,weassumethatthehumanwillrstgeneratehisexpectationoftherobot'sbehaviorasanoptimalpolicygeneratedusinghisrewardfunctionRHandbeliefabouttherobotThR.
ThenthebehavioroftherobotiscomparedwiththeoptimalpolicytogeneratearatingγH.
Hence,ourlearningtaskinthispaperbecomestolearntheweightswandtransitionprobabilitydistributionsΘ.
MethodologyTheinferenceproblemaboveisoftensolvedbyoptimiz-ingtheposteriorprobabilitywithrespecttothelatentvari-ables.
However,duetothecomplexformsoftheposteriors,weformulatetheprobleminavariationalinferenceframe-work(Jordanetal.
1999;Bishop2006).
Ourgoalistoap-proximatetheposteriordistributionp(w,Θ|ΓH,Z),whereΓH,Zaretheobservationsandw,Θthelatentvariables.
WeassumethatwfollowsamultivariateGaussiandistri-butionN(,Σ).
Forsimplicity,weassumethatΣisgivenapriori.
ForΘ,weneedtoselectapriorforeachθiasaprobabilitydistribution.
WeassumethateachθifollowsaDirichletdistributionDIR(αi),whichencodesadistribu-tionoverdistributions.
LetA=[α1,α2,α|S|*|A|],andthereby,andAaretheparametersweneedtolearn.
Asaresult,ourvariationalposteriordistributionbecomesq(w,Θ|,A),whichistheposteriorofthelatentvariablesthatcorrespondtotherewardfunctionandhuman'sbeliefabouttherobot'sdomaindynamicsgovernedbyandA.
ItthustransformstheproblemofinferringRHandThRintoaproblemofndingandAtomakeq(w,Θ|,A)tobeclosetop(w,Θ|ΓH,Z).
Asavariationalinferenceproblem,weoptimizetheEvi-denceLowerBOund(ELBO):L(q)=Eq(w,Θ)[logp(ΓH,Z,w,Θ)logq(w,Θ)]wherep(ΓH,Z,w,Θ)isthejointprobabilityoftheobser-vationsΓH,Zandlatentvariablesw,Θ.
Inordertomakeitcomputableinourtask,weapplyblack-boxvariationalinference(Ranganath,Gerrish,andBlei2014)tomaximizeELBOviastochasticoptimization:,A=,A+ρ·,AL(q)wherethelearningrateρfollowstheRobbins-Monrorules(RobbinsandMonro1951).
WecomputethegradientofELBOwithrespecttothefreeparametersandAand,AL(q)isderivedasfollows:,AL(q)=Eq(w,Θ)[,Alogq(w,Θ|,A)·(logp(ΓH,Z,w,Θ)logq(w,Θ|,A))](1)FromEquation(1),wecanseethatthegradientofELBOistheexpectationofthemultiplicationofthescorefunction(HinkleyandCox1979)(i.
e.
,,Alogq(w,Θ|,A))andinstantaneousELBO(i.
e.
,logp(ΓH,Z,w,Θ)logq(w,Θ|,A))withrespecttoourvariationalposteriordistribution.
Thedetailedderivationof,AL(q)ispre-sentedin(Ranganath,Gerrish,andBlei2014).
Theformof,AL(q)isnotdirectlycomputable.
GiventhatandAareindependentparametersinourset-ting,wecomputeL(q)andAL(q)respectivelyandup-datethemseparately:=+ρ·L(q)A=A+ρA·AL(q)Thisalsoallowsustoapplythemean-eldassumptionthatgivesthefollowingfactorization:q(w,Θ|,A)=q(w|)·q(Θ|A)ThenwecanrewritethegradientofELBOasfollows:,AL(q)=Eq(w)Eq(Θ),A(logq(w|)+logq(Θ|A))·(logp(ΓH,Z,w,Θ)logq(w|)logq(Θ|A))]Takeq(w|)asanexample,followingthederivationsin(Ranganath,Gerrish,andBlei2014),thegradientofELBOwithrespecttobecomes:L(q)=Eq(w)[(logq(w|))·Eq(Θ)[logp(ΓH,Z,w,Θ)logq(w|)logq(Θ|A)]]NotethatthersttermEq(w)[(logq(w|)]=0(Ran-ganath,Gerrish,andBlei2014).
HencethelasttermintheinstantaneousELBOcanbeconsideredasaconstantwithrespecttoq(w)andcanceledout.
L(q)thenbecomes:L(q)=Eq(w)[(logq(w|))·(Eq(Θ)[logp(ΓH,Z,w,Θ)]logq(w|))](2)Differentfrom(Ranganath,Gerrish,andBlei2014),inourproblem,theexpectationofthelogjointprobabilitylogp(ΓH,Z,w,Θ)cannotbecanceledoutsincewandΘhappentobeintheMarkovblanketofeachother.
BasedontherelationshipamongthesevariablesasshowninFigure1,thelogprobabilitycanbefactorizedasfollows:logp(ΓH,Z,w,Θ)=logp(ΓH|Z,w,Θ)+logp(w)+logp(Θ)+logp(Z)(3)PuttingEquation(3)backintoEquation(2),weobtain:L(q)=Eq(w)[(logq(w|))·(Eq(Θ)[logp(ΓH|Z,w,Θ)]+logp(w)logq(w|))](4)wheretheexpectationofthetermslogp(Θ)andlogp(Z)withrespecttoq(Θ)areconstantsandcanbecanceledoutsinceEq(w)[(logq(w|)]=0.
NowwehaveobtainedthegradientofELBOwithrespecttothelatentvariableaspresentedinEquation(4).
Similarly,thegradientofELBOwithrespecttoeachαi∈Aisasfollows:αiL(q)=Eq(θi)[αi(logq(θi|αi))·(Eq(w)[logp(ΓH|Z,w,Θ)]+logp(θi)logq(θi|αi))]Bothp(w)andp(θi)arepriors,whichareassumedtofollowamultivariateGaussiandistributionandaDirichletdistribu-tionrespectively.
Intheequationsabove,logp(ΓH|Z,w,Θ)=logp(γH|ζ,w,Θ)sincethedemonstrationsandratingsareconditionallyindependentfromeachother.
p(γH|ζ,w,Θ)indicateshowlikelythehumanwouldgivearatingγHforthedemonstrationζgiventheparametersfortherewardfunctionandhuman'sbeliefabouttherobot.
WeassumeaGaussiandistributionN(γH|γH,ΣγH)whereγHistheestimatedmeanofthehuman'sratingsgivenwandΘ,andΣγHisassumedtobegiventosimplifythediscussion.
Asdiscussedearlier,theestimatedmeanratingofademonstrationisassumedtodependontwofactors,therewardfunctionandthehuman'sbeliefabouttherobot'sdomaindynamics.
Theytogetherdeterminethehuman'sexpectationoftherobot'sbehavior,whichcorrespondstotheoptimalpolicyfortherobotinthehuman'smind.
Inthispaper,weassumethattheratingisproportionaltothegeometricmeanofthehuman'ssoftmaxpolicyappliedtothedemonstration.
Moreover,wedeneγmaxtobeaconstantthatrepresentsthehighestratingthatmaybegiven.
Followingourdiscussion,theestimatedhuman'sratingcanbecomputedforademonstrationζ={(s1,a1),(s2,a2)sn,an)}as:γH=γmax·ni=1π(ai|si)1nwherenisthelengthofthedemonstration,andπisthees-timatedhuman'ssoftmaxpolicycomputedusingwandΘ.
VarianceReduction:ThecomputationofL(q)andαiL(q)abovecannotbeperformeddirectlyduetothein-tractabilityofcomputingtheexpectations.
Hence,weap-proximatethegradientsusingsamplingmethods(Hastings1970).
WithMonteCarlosamples,thegradientsareesti-matedasfollows:L(q)1SSs=1[(logq(ws|))·(logp(ΓH|Z,ws,Θs)+logp(ws)logq(ws|))]whereSisthenumberofsamples,andwsq(w),Θsq(Θ).
Theseestimatedgradients,however,mayhavealargevariancewhichcouldhindertheconvergenceofourap-proach.
Therefore,itisnecessarytoreducethevariance.
(Ross2002)introducedcontrolvariatethatrepresentsafam-ilyoffunctionswithequivalentexpectations.
Withcontrolvariate,wecaninsteadcomputetheexpectationofanalter-nativefunctionwhichhasasmallervariance.
Letfbethefunctiontobeapproximated,functionfisdenedas:f=fa·(gE[g])wheregservesasanauxiliaryfunctionthathasaniterstmoment.
fcanbeproventohavesmallervarianceswithanequivalentexpectation,wherethefactoraiscomputedtominimizethevariance(Ranganath,Gerrish,andBlei2014)asa=cov(f,g)var(g).
Inthispaper,weselecttheexpec-tationofthescorefunction(i.
e.
,Eq(w)[(logq(w|))]andEq(Θ)[αi(logq(Θ|αi))])tobeg.
WepresentGeReLinAlgorithm1.
Giventherobot'sdemonstrationsandthecorrespondingratings,weleveragethehuman'sratingstoupdatetheparametersandAofourvariationalposteriorsq(w)andq(Θ)viastochasticop-timization.
ThegradientsoftheELBOwithrespecttoandAareapproximatedusingMonteCarlosampling.
Fur-thermore,wetakeadvantageofcontrolvariatetoreducetheAlgorithm1GeneralizedRewardLearningwithBiasedBe-liefaboutDomainDynamics(GeReL)Input:therobot'sdemonstrationsZ,human'sratingsΓH,variationalposteriorsq(w)andq(Θ),MaxIterOutput:andA1:Initialize:freeparametersandAforq(w)andq(Θ)2:Lett=1.
3:whiletLastly,theparameters,andA,areupdatedineachiterationwithanadaptedlearn-ingratebasedonAdaGrad(Duchi,Hazan,andSinger2011).
GeReLterminateswhentheconvergencecriterionismet.
EvaluationToevaluateourapproach,weconducttwosetsofexperi-mentsinasimulatedgrid-worldnavigationdomainandaCoffeeRobotdomain(Boutilier,Dearden,andGoldszmidt2000;SigaudandBuffet2013)withauserstudy.
Thesim-ulationwillbefocusingonvalidatingourlearningmethodunderbiasedbeliefs.
Theuserstudywillservetwopurposes,showingthat1)humanusersareeasilybiasedinourprob-lemsetting;2)ouralgorithmlearnsthecorrecthumanpref-erencesundersuchbiases,whilepriormethodsthatignoresuchbiaseswouldfail.
SimulatedNavigationDomainIntherstexperiment,wetesttheperformanceofGeReLinagrid-worldnavigationdomainwhichcontains7*7=49states.
Wesetonerewardstate(i.
e.
,location)thathasalargepositiveweight(i.
e.
5)andonepenaltylocationwithalargenegativeweight(i.
e.
,-5).
Theyarerandomlylocatedatcornersofthegrid-world.
Therobotstartsatarandomstateanditsgoalistomaximizetherewards.
Therearefouractions,{1(Up),2(Down),3(Left),4(Right)},whichcantransfertheagentfromthecurrentstatetoanotherstate.
Totestouralgorithm,wesimulatetwotypesofbiasedhu-manbeliefsabouttherobot'sdomaindynamics.
1)ReversedUp&Down:thehumanbelievesthataction1wouldtaketherobotdownandaction2wouldmoveitupinstead.
2)Ro-tatedBelief:humanbelievesthattheaction1wouldmovetherobotleft,theaction2wouldmoveitright,theaction3wouldmoveitupandtheaction4wouldmoveitdown.
Figure2:Rewardslearnedbydifferentapproaches.
Thehuman'srewardfunctionforeachstateisdenedasaweightedsummationofaninversedistancemetrictothere-wardandpenaltystates(i.
e.
,thecloseritistothestate,themoreinuencethatstatehasonitsreward).
Thedemonstra-tionsarerandomlygeneratedviatherobot'struedynamicmodel.
Thehuman'sratingsaresimulatedusingthetruehu-manrewardfunctionandbiasedbeliefabouttherobot'sdo-maindynamicsfollowingaGaussiandistribution.
WecompareGeReLwithtwobaselinemethodsthatas-sumethatthehumanmaintainsthecorrectbeliefabouttherobot'sdomaindynamics,namelyMaxEnt-IRL(Ziebartetal.
2008)andGeReL,withthelatterbasicallyusesGeReLwithoutupdatingthedomaindynamics.
Inbothbaselinemethods,thetruerobot'sdomaindynamicsisusedduringlearning.
Inaddition,avariantoftheSimultaneousEstima-tionofRewardsandDynamics(SERD)algorithm(Hermanetal.
2016)implementedthatlearnsboththerewardfunc-tionanddynamicsbasedonratings(theoriginalmethoddoesnotapplytoourproblemsetting)isusedinthecom-parison,whichreliesonsoftvalueiterationthatrequiresthevaluefunctionstoassumecertainshapestoperformwell.
ToobtaindemonstrationsforMaxEnt-IRL,wegeneratethembasedonthesoftmaxpolicyofthehuman.
Allofthefourmethodsareprovidedwiththesameamountofdemonstra-tions.
Alltheresultsareaveragedovermultipleruns.
Figure3showstheresultfortheReversedUp&Downsetting.
TheresultshowsthatGeReLcansuccessfullyre-coverthehuman'srewardfunctionandbeliefabouttherobot'sdomaindynamicswhileGeReLandMaxEnt-IRLconvergeinthecompletelyoppositedirectionsincetheydonotconsiderthatthehuman'sbeliefcouldbebiased.
Ontheotherhand,SERDconvergesintherightdirection,butthelearnedvaluesarefartherfromthegroundtruththanGeReLinallcases.
Thisisduetothesmoothingeffectofsoftvalueiteration.
Inaddition,wecomputetheKLdivergenceofthesoftmaxpolicygeneratedbytheestimatedrewardfunctionandhuman'sbeliefwiththatofthegroundtruthtoexam-inehowwellwecanestimatethehuman'sexpectationoftherobot'sbehaviors.
Similartrendsareobservedamongallthemethods.
ThecomparisonoftherewardslearnedbythesefourmethodswiththegroundtruthispresentedinFig-ure2.
BothGeReLandSERDconvergetothecorrectpat-ternofrewardsintermsoftheirrelativemagnitudes.
SERDshowslesssensitivitytothemagnitudessincesoftBellmanequationwouldleadtoanentropyaugmentedrewardfunc-tion(Haarnojaetal.
2017).
TheadverseeffectoflearningfrombiasedratingsisclearfromthegureforGeReLandMaxEnt-IRL,whichbothfailtorecoverthetruepreferences.
TheresultsforbothsettingsarepresentedinTable1,whichFigure3:ComparisonoftheperformanceamongGeReL,SERD,GeReL,MaxEnt-IRLwiththeprioralsoshown.
Left:TheL2distancebetweenthelearnedrewards(whichiscomputedusingw)andthegroundtruth.
Middle:TheL2distancebetweentheestimatedhuman'sbelief(i.
e.
,Θ)andthegroundtruth.
Right:TheKLdivergencebetweentheestimatedhuman'sexpectationofrobot's(softmax)policy(whichiscomputedusingwandΘ)andthatunderthegroundtruth.
d(R)d(Θ)d(π)d(R)d(Θ)d(π)ReversedUp&DownRotatedBeliefGeReL12.
170.
060.
1112.
610.
080.
23SERD16.
430.
380.
4717.
620.
570.
63GeReL26.
720.
561.
4623.
960.
911.
43MaxEnt-IRL23.
320.
561.
6828.
020.
911.
55Table1:ComparisonofGeReL,SERD,GeReL,andMaxEnt-IRLforthetwosettingsinoursimulationwithre-specttotheL2distancebetweentheestimatedvaluesandthegroundtruth(i.
e.
,d(R),d(Θ)).
Thethirdcolumn(i.
e.
,d(π))showstheKLdivergencebetweentheestimatedhu-man'sexpectationoftherobot'ssoftmaxpolicyandthatun-derthegroundtruth.
showsimilarperformancesinbetweenthetwosettings.
ItconrmsthatGeReLcaneffectivelyestimatethehuman'srewardfunctionunderbiasedbeliefs.
UserStudywiththeCoffeeRobotDomainBesidestheexperimentsinasimulateddomain,wealsocon-ductauserstudy.
Throughthestudy,wehopetodemonstratethathumanscanbeeasilybiasedinourproblemsetting,whichmayleadtobiasedratingsthatcouldhaveledtoawronginterpretationofthehumanpreference.
Insuchcases,wewillshowthatGeReLcanaccuratelyidentifythesitua-tion.
WeapplytheCoffeeRobotdomain(Boutilier,Dear-den,andGoldszmidt2000;SigaudandBuffet2013)inthisuserstudy,whichisillustratedinFigure4.
ThisisatypicalfactoredMDPdomaindescribedby6binaryfeatureswhichrepresentwhetheritisraining,whethertherobothasacof-fee,etc.
Thetaskoftherobotistobuyacupofcoffeefromacafeanddeliverittoapersoninhisofce.
Whenitisrain-ing,therobotcouldchoosetoeitheroperateintherainoruseanumbrellatostaydry.
However,usinganumbrellawhileholdingthecoffeecupmaycausethecoffeetospill.
Tocreateasituationwherebiasesmaybepresent,wede-signtwoexperimentalsettingswithtwodifferenttypesofrobots:amobilerobotandahumanoid,asseeninFigure4.
Weanticipatethattheappearancewouldintroducehumanbiases(Haringetal.
2018)intermsoftheircapabilitiesofFigure4:TheCoffeeRobotdomain.
Theweathercouldberainyorsunny,andtherobotmaychoosetouseanumbrellaoroperateintherain.
Weusetwotypesofrobots(humanoidvs.
mobile)toperformthesamesetofdemonstrationsthatcoverthevarioussituationsthatmayoccur.
handlingthetask.
Toreducetheeffectsthatthehumansub-jectwouldimprovetheirunderstandingovertime,wegen-erateonly7demonstrationsforeachrobotthatincludevar-iousscenariosthatmayoccur,suchasforasunnyorrainyday,forwhetherornottherobottakestheumbrella,andforwhetherornottherobotspillsthecoffee.
Thegroundtruthforthedomaindynamicsissetsuchthatthehumanoidislesslikelytospillthecoffeewhileusingtheumbrellathanthemobilerobot.
WepublishtheexperimentsonAmazonMechanicalTurk(MTurk).
Toremoveinvalidresponses,weinsertasanitycheckdemonstrationwithrandomactions,whichshouldhavereceivedthelowestrating.
Werecruited20participantsforeachsetting.
Afterremovingthosethatfailedthesanitycheckorwithveryshortresponsetime(<3min),weob-tained12validresponsesforeachsettingwithagesrangingfrom23to61(theratioofmalestofemalesis2:1).
Eachparticipantisprovidedwithinstructionsaboutthedomainatthebeginning.
Toavoidtheinuencefromviewingthedemonstrations,immediatelyaftertheinstructions,weasktheparticipantstwoquestionsasfollows:Q1:HowmuchmorelikelydoyoufeelthattherobotmayspillthecoffeewhileusinganumbrellaQ2:HowmuchdoyoucareabouttherobotbeingwetTherstquestionisdesignedtoillicittheparticipant'sbeliefQuestionp-valueMobileHumanoid(Q1)DomainDynamics0.
0472.
923.
58(Q2)WeightPreference0.
0272.
833.
67Table2:Averagedparticipants'responsestothetwoques-tionsforeachsettingbeforeviewingthedemonstrations.
Theyareaskedina5-pointLikertscalewhere1isthelowestand5thehighest.
abouttherobot'sdomaindynamicswhilethesecondques-tionisfortheparticipant'spreference.
TheirfeedbackforeachsettingispresentedinTable2.
Theparticipantsofthemobilerobotsettingbelievedthattherobotwouldbelesslikelytospillthecoffeewhileholdingtheumbrellathantheparticipantsofthehumanoidsetting.
Noticethatthisisincontrasttothegroundtruth.
Meanwhile,theparticipantsexpressedmoreconcernabouttherobotgettingwetinthehumanoidsettingthanthemobilerobotsetting.
Afterthequestions,weaskedtheparticipantstoratethedemonstrations.
Accordingly,wendthattheratingsforthedemonstrationswheretherobotoperatesintherainwithoutanumbrella,ortakesanumbrellainasunnydaytoberatedlowinthehumanoidsetting.
Incontrast,inthemobileset-ting,fewerdemonstrationsreceivedlowratings.
Thesere-sultssupportedourassumptionthatthehumanareeasilybi-asedwhenworkingwithrobots.
Next,werunourmethodundereachsettingtoseewhetherourmethodcanrecoverfromsuchbiasedbeliefs.
Forcomparison,wealsorunGeReL,whichperformedsimilarlytoMaxEnt-IRLinoursimulationtask.
Weruneachmethodforeachparticipantinbothsettings.
Theratingsarenormalizedtoremoveinconsistenciesacrossdifferentpar-ticipants.
TheresultsarepresentedinFigure5.
WeobservedthatthelearnedprobabilityofspillingcoffeewhileholdinganumbrellabyGeReLforthehumanoidrobotsettingisgen-erallylargerthanthemobilerobotsetting.
Thisrepresentstheestimatedhumanunderstandingofthedomaindynamics,whichisconsistentwiththeparticipant'sfeedbackshowninTable2.
Furthermore,GeReLlearnedthattheparticipantscaredmoreabouttherobotgettingwetinthehumanoidset-tingthanthemobilerobotsetting,whichisalsoconsistentwiththeparticipant'struepreference.
Incontrast,GeReLdiscoveredjusttheopposite!
DiscussionsOncethebiaseddomaindynamicsisobtained,thenextques-tionishowtouseit.
Thesimplestmethodofcourseistoinformthehumanabouthisbiasesandhopethatitwouldwork.
Analternativemethodthatisoftenconsideredintheareaofhuman-awareplanningisthattherobotcould,in-steadofalwayspursueoptimalbehaviors,behavetomatchwiththehuman'sexpectationwheneverfeasible,soastobehaveinanexplicablemanner.
Incontrasttothemulti-objectiveMDPproblem(Roijersetal.
2013;Chatterjee,Ma-jumdar,andHenzinger2006)whichhasmorethanonere-wardfunctiontooptimize,inthisproblem,therobotmain-tainstwotransitionfunctions,oneforitsowndynamicsandtheotherforthehuman'sbeliefofit.
TherealreadyFigure5:FeatureweightslearnedbyGeReLandGeReL.
existsworkthatlooksatthisproblem(Zhangetal.
2017;Chakrabortietal.
2017).
Likeallrewardlearningproblems,thesolutionisnotunique.
Thisiscommonlyknownasthenon-identiabilityissue.
Ingeneralrewardlearning(GRL),anadditionalcom-plexityisthelearningofthetransitionfunction,whichun-fortunatelyonlyaggravatestheissue.
Sofar,wearenotawareofanysolutionstothisproblemexceptfortheonesthatintroduceinductivebiasesonthepriorsortheerrorfunctions,suchasBayesianIRL(RamachandranandAmir2007)andapprenticeshiplearningmethods(AbbeelandNg2004).
Inthisregard,ourworkalsointroducesaninductivebiasbyassumingaformoftheposteriorasamultivariateGaussiandistribution.
Intermsofsimultaneouslylearningdifferentfactors,thereexistpriorresults(ArmstrongandMindermann2018)thatargueagainstitandprovethatitisimpossibletodetermineonewithoutassumingsomeformoftheother.
However,wenotethatthenegativeresultsapplyonlytothesitua-tionwhereoneofthefactorsisthecomputationalprocess.
ConsiderthefunctionC(R,M)=Γ.
WhenCisgiven,thechoicesofr∈Randm∈Mareconnectedtothecor-respondingvalueofγ∈Γ.
However,ifonlymisgiven,wemaychooseanyrandthensimplyremap(choosingac∈C)(r,m)'stotheircorrespondingγ's.
Thisexibilityofthecomputationalprocessisthecorereasonofthenegativeresults.
However,thenon-identiabilityissueisstillthere.
ConclusionInthispaper,welookedtheGeneralizedRewardLearning(GRL)problemandproposedamethodcalledGeReLtoaddressit.
GeReLremovestheassumptionthatthehumanalwaysmaintainsthetruebeliefabouttherobot'sdomaindynamics.
Todevelopthemethod,weformulatedtheGRLprobleminavariationalinferenceframeworktoinfertheparametersgoverningtherewardfunctionandthehuman'sbeliefabouttherobotsimultaneously.
Toreducetheeffortforobtainingtrainingsamples,weusedthehuman'srat-ingsofrobotdemonstrations.
Weevaluatedourapproachexperimentallyusingasimulateddomainandwithauserstudy.
TheresultsshowedthatGeReLoutperformedpriorapproachesthatcouldhavemisinterpretedthehumanprefer-enceswhensuchbiasesarenotconsidered.
WeshowedthatGeReLcouldrecoverthetruehumanpreferenceseffectivelyevenundersuchachallengingsetting.
AcknowledgmentsThisresearchissupportedinpartbytheNSFgrantIIS-1844524,theNASAgrantNNX17AD06G,andtheAFOSRgrantFA9550-18-1-0067.
ReferencesAbbeel,P.
,andNg,A.
Y.
2004.
Apprenticeshiplearningviainversereinforcementlearning.
InProceedingsofthetwenty-rstinternationalconferenceonMachinelearning,1.
ACM.
Armstrong,S.
,andMindermann,S.
2018.
Occam'srazorisinsufcienttoinferthepreferencesofirrationalagents.
InAdvancesinNeuralInformationProcessingSystems,5598–5609.
Arnold,T.
;Kasenberg,D.
;andScheutz,M.
2017.
Valuealignmentormisalignment–whatwillkeepsystemsaccount-ableInWorkshopsattheThirty-FirstAAAIConferenceonArticialIntelligence.
Bishop,C.
M.
2006.
Patternrecognitionandmachinelearn-ing.
springer.
Boularias,A.
;Kober,J.
;andPeters,J.
2011.
Relativeentropyinversereinforcementlearning.
InProceedingsoftheFourteenthInternationalConferenceonArticialIntel-ligenceandStatistics,182–189.
Boutilier,C.
;Dearden,R.
;andGoldszmidt,M.
2000.
Stochasticdynamicprogrammingwithfactoredrepresenta-tions.
Articialintelligence121(1-2):49–107.
Chakraborti,T.
;Sreedharan,S.
;Zhang,Y.
;andKambham-pati,S.
2017.
Planexplanationsasmodelreconciliation:movingbeyondexplanationassoliloquy.
InIJCAI,156–163.
AAAIPress.
Chatterjee,K.
;Majumdar,R.
;andHenzinger,T.
A.
2006.
Markovdecisionprocesseswithmultipleobjectives.
InAn-nualSymposiumonTheoreticalAspectsofComputerSci-ence,325–336.
Springer.
Cui,Y.
,andNiekum,S.
2018.
Activerewardlearningfromcritiques.
InICRA,6907–6914.
IEEE.
Daniel,C.
;Viering,M.
;Metz,J.
;Kroemer,O.
;andPeters,J.
2014.
Activerewardlearning.
InRSS.
DorsaSadigh,A.
D.
D.
;Sastry,S.
;andSeshia,S.
A.
2017.
Activepreference-basedlearningofrewardfunctions.
InRSS.
Duchi,J.
;Hazan,E.
;andSinger,Y.
2011.
Adaptivesubgra-dientmethodsforonlinelearningandstochasticoptimiza-tion.
JMLR12(Jul):2121–2159.
Haarnoja,T.
;Tang,H.
;Abbeel,P.
;andLevine,S.
2017.
Reinforcementlearningwithdeepenergy-basedpolicies.
InProceedingsofthe34thInternationalConferenceonMa-chineLearning,1352–1361.
JMLR.
org.
Haring,K.
S.
;Watanabe,K.
;Velonaki,M.
;Tossell,C.
C.
;andFinomore,V.
2018.
Ffabtheformfunctionattributionbiasinhuman–robotinteraction.
IEEETransactionsonCog-nitiveandDevelopmentalSystems10(4):843–851.
Hastings,W.
K.
1970.
Montecarlosamplingmethodsusingmarkovchainsandtheirapplications.
Herman,M.
;Gindele,T.
;Wagner,J.
;Schmitt,F.
;andBur-gard,W.
2016.
Inversereinforcementlearningwithsimul-taneousestimationofrewardsanddynamics.
InArticialIntelligenceandStatistics,102–110.
Hinkley,D.
V.
,andCox,D.
1979.
Theoreticalstatistics.
ChapmanandHall/CRC.
Jordan,M.
I.
;Ghahramani,Z.
;Jaakkola,T.
S.
;andSaul,L.
K.
1999.
Anintroductiontovariationalmethodsforgraphicalmodels.
Machinelearning37(2):183–233.
Ng,A.
Y.
,andRussell,S.
2000.
Algorithmsforinversereinforcementlearning.
IninProc.
17thInternationalConf.
onMachineLearning.
Ramachandran,D.
,andAmir,E.
2007.
Bayesianinversereinforcementlearning.
InIJCAI,2586–2591.
Ranganath,R.
;Gerrish,S.
;andBlei,D.
2014.
Blackboxvariationalinference.
InArticialIntelligenceandStatistics,814–822.
Reddy,S.
;Dragan,A.
;andLevine,S.
2018.
Wheredoyouthinkyou'regoing:Inferringbeliefsaboutdynamicsfrombehavior.
InAdvancesinNeuralInformationProcess-ingSystems,1461–1472.
Robbins,H.
,andMonro,S.
1951.
Astochasticapproxima-tionmethod.
Theannalsofmathematicalstatistics400–407.
Roijers,D.
M.
;Vamplew,P.
;Whiteson,S.
;andDazeley,R.
2013.
Asurveyofmulti-objectivesequentialdecision-making.
JAIR48:67–113.
Ross,S.
M.
2002.
Simulation.
Elsevier.
Russell,S.
;Dewey,D.
;andTegmark,M.
2015.
Researchprioritiesforrobustandbenecialarticialintelligence.
AIMagazine36(4):105–114.
Russell,S.
J.
1998.
Learningagentsforuncertainenviron-ments.
InCOLT,volume98,101–103.
Sigaud,O.
,andBuffet,O.
2013.
Markovdecisionprocessesinarticialintelligence.
JohnWiley&Sons.
Unhelkar,V.
V.
,andShah,J.
A.
2019.
Learningmodelsofsequentialdecision-makingwithpartialspecicationofagentbehavior.
InAAAI.
Zakershahrak,M.
;Sonawane,A.
;Gong,Z.
;andZhang,Y.
2018.
Interactiveplanexplicabilityinhuman-robotteaming.
InRO-MAN,1012–1017.
IEEE.
Zhang,J.
,andDragan,A.
2019.
Learningfromextrapolatedcorrections.
InICRA,7034–7040.
IEEE.
Zhang,Y.
;Sreedharan,S.
;Kulkarni,A.
;Chakraborti,T.
;Zhuo,H.
H.
;andKambhampati,S.
2016.
Planexplicabilityforrobottaskplanning.
InProceedingsoftheRSSWork-shoponPlanningforHuman-RobotInteraction:SharedAu-tonomyandCollaborativeRobotics.
Zhang,Y.
;Sreedharan,S.
;Kulkarni,A.
;Chakraborti,T.
;Zhuo,H.
H.
;andKambhampati,S.
2017.
Planexplica-bilityandpredictabilityforrobottaskplanning.
InICRA,1313–1320.
IEEE.
Ziebart,B.
D.
;Maas,A.
;Bagnell,J.
A.
;andDey,A.
K.
2008.
Maximumentropyinversereinforcementlearning.
InAAAI.
eduAbstractRewardlearningasamethodforinferringhumanintentandpreferenceshasbeenstudiedextensively.
Priorapproachesmakeanimplicitassumptionthatthehumanmaintainsacor-rectbeliefabouttherobot'sdomaindynamics.
However,thismaynotalwaysholdsincethehuman'sbeliefmaybebiased,whichcanultimatelyleadtoamisguidedestimationofthehuman'sintentandpreferences,whichisoftenderivedfromhumanfeedbackontherobot'sbehaviors.
Inthispaper,weremovethisrestrictiveassumptionbyconsideringthatthehu-manmayhaveaninaccurateunderstandingoftherobot.
WeproposeamethodcalledGeneralizedRewardLearningwithbiasedbeliefsaboutdomaindynamics(GeReL)toinferboththerewardfunctionandhuman'sbeliefabouttherobotinaBayesiansettingbasedonhumanratings.
Duetothecom-plexformsoftheposteriors,weformulateitasavariationalinferenceproblemtoinfertheposteriorsoftheparametersthatgoverntherewardfunctionandhuman'sbeliefabouttherobotsimultaneously.
Weevaluateourmethodinasimulateddomainandwithauserstudywheretheuserhasabiasbasedontherobot'sappearances.
Theresultsshowthatourmethodcanrecoverthetruehumanpreferenceswhilesubjecttosuchbiasedbeliefs,incontrasttopriorapproachesthatcouldhavemisinterpretedthemcompletely.
IntroductionWiththerapidadvancementinAIandrobotics,intelli-gentagentsbegintoplayanimportantroleinourlivesinmanydifferentareas.
Robotswillsoonbeexpectedtonotonlyachievetasksalone,butalsoengageintasksthatre-quireclosecollaborationwiththeirhumanteammates.
Insuchsituations,theabilityoftherobottounderstandthehuman'sintentandpreferencesbecomesadeterminantforachievingeffectivehuman-robotteaming.
Theproblemofinferringhuman'sintentandpreferenceshasbeenstud-iedextensivelybefore.
Someresearchers(NgandRussell2000)formulatedthisproblemasanInverseReinforcementLearning(IRL)problem(Russell1998).
Therewardfunc-tionisrecoveredfromoptimalpoliciesorbehaviorsdemon-stratedbyhumanexperts.
Suchexpertdemonstrations,how-ever,areoftendifculttoobtaininreal-worldtasks.
Toad-Copyrightc2020,AssociationfortheAdvancementofArticialIntelligence(www.
aaai.
org).
Allrightsreserved.
dressthisproblem,learningmethodsbasedonnon-expertuserratingsoftherobot'sbehaviors(Danieletal.
2014;DorsaSadigh,Sastry,andSeshia2017;CuiandNiekum2018)aredeveloped.
Acommonassumptionmadeimplic-itlyinallthesepriorworksisthatthehumanalwaysmain-tainsacorrectunderstandingoftherobot'sdomaindynam-ics.
This,however,maynotbethecaseinmanyscenarioses-peciallywithnon-expertusers.
Havingabiasedbeliefabouttherobotcouldleadtobiased(notjustnoisy)ratingsfortherobot'sbehaviors,resultinginaninaccurateestimationofthehuman'srewardfunction.
Considerarobotvacuumcleanerthatistaskedtocleantheoorsinahouse.
Supposethattherobotvacuumisde-signedtocleanmostoortypesexceptforhardwoodsinceitistooslipperyfortherobottograsponto(soitmaybestuckinaroomwithahardwoodooronceentered).
Considerauserwhoisaskedtoratetherobot'sbehaviors.
Givenasetoftrajectoriesoftherobotcleaner(withmostoftheareascoveredexceptforthelivingroomwithahardwoodoor),therobotmaygetlowratingseventhoughitshouldhavereceivedhighratingshadtheuserknownabouttherobot'scapabilities(whichareexpressedintermsofdomaindynam-ics).
Ontheotherhand,therobotmayreceivehighratings(eventhoughitshouldnothave)whenitstays(stuck)inthelivingroombutsomehowmanagestocleanit(albeitmuchlessefciently),iftheuserhadthebeliefthattherobotwasdesignedtocleanonlyoneroomatatime.
Inthispaper,weremovetherestrictiveassumptionthathumanshaveacorrectbeliefabouttherobot'sdomaindy-namics.
Ourgoalistorecoverthetruerewardfunctionunderbiasedbeliefs.
WerefertothisproblemasGeneralizedRe-wardLearning(GRL)andproposeamethodcalledGener-alizedRewardLearningwithbiasedbeliefsaboutdomaindynamics(GeReL)thatinfersthelatentvariablesgovern-ingboththerewardfunctionandhuman'sbelieftogetherinaBayesiansettingbasedonhumanratingsoftherobot'sbehaviors.
Duetothecomplexformsoftheposteriors,theproblemisformulatedinavariationalinferenceframework(Jordanetal.
1999;Bishop2006).
Thevariationalposte-riordistributionofthelatentvariablesforestimatingthetrueposteriorisoptimizedusingablack-boxoptimizationmethod(Ranganath,Gerrish,andBlei2014).
ToreducethevarianceofMonteCarloestimatesofthevariationalgradi-ents,wefactorizetheupdatingrulesaccordingtotheinde-pendenceofthelatentvariablesandapplycontrolvariatetomaketheoptimizationconvergefaster.
Byinferringthere-wardfunctionandthehuman'sbeliefabouttherobotsimul-taneouslyinthisway,ourlearningmethodisabletorecoverthetruehumanpreferenceswhileatthesametimemain-tainanestimateofthehuman'sbiasedbelief.
Assuch,ourmethodaddressesakeylimitationoftheexistingmethodsandhencehasbroadimpactsonimprovingtheapplicabilityandsafetyofroboticsystemsthatworkcloselywithhumans.
Toevaluateourmethod,weperformexperimentsinasim-ulatednavigationdomainandwithauserstudyintheCoffeeRobotdomain(Boutilier,Dearden,andGoldszmidt2000;SigaudandBuffet2013)wherebiasesareintroducedbyvaryingtherobot'sappearances.
WecompareGeReLwithavariantofSimultaneousEstimationofRewardsandDy-namics(SERD)(Hermanetal.
2016),MaximumEntropyIRL(MaxEnt-IRL)(Ziebartetal.
2008),andanotherbase-lineapproachthatusesourinferencemethodbutmaintainsthesameassumptionasinMaxEnt-IRL(thatthehuman'sunderstandingoftherobotiscorrect).
Inthelattertwometh-ods,thetruedomaindynamicsisusedandheldxedduringlearning.
ResultsshowthatGeReLcanbetterrecoverthetruerewardfunctionundersuchbiasedbeliefswhencom-paredtotheseothermethods.
Furthermore,whenbiasesarepresent,thelearnedpreferencescouldbecompletelyoppo-sitetothegroundtruth,suggestingthatsuchamethodisin-deedvaluableforaddressingbiasesinroboticapplications.
RelatedWorkResearchershaveformulatedtheproblemofinferringthehuman'sintentandpreferencesasanIRLproblem(Rus-sell1998)wherethegoalistorecoverthehuman'spref-erencesasarewardfunction.
IRLisoftensolvedusingvariousoptimizationtechniqueswithexpertdemonstrationsastheinput(NgandRussell2000).
IRLhasalsobeenappliedtoapprenticeshiplearning(AbbeelandNg2004)todirectlyapproximatetheexpert'spolicy.
Inordertodealwithnoiseinthedemonstrations,(Ziebartetal.
2008;Boularias,Kober,andPeters2011)proposedaprobabilisticapproachbasedontheprincipleofmaximumentropy.
Fur-thermore,BayesianIRL(RamachandranandAmir2007)isintroducedthatincorporatespriorknowledge.
However,expertdemonstrations(withorwithoutnoise)areoftendifculttoobtaininreal-worldtasks.
Morere-cently,researchersstartfocusingonlearningwithnon-expertfeedbackonthequeriesoftherobot'sbehaviors,of-tenintheformsofratings(Danieletal.
2014),comparisons(DorsaSadigh,Sastry,andSeshia2017),orcritiques(CuiandNiekum2018;ZhangandDragan2019).
Allthesepriorworksrelyonanimplicitassumptionthatthenon-expertusermaintainsacorrectunderstandingoftherobot'sdomaindynamics.
However,whentheuserisbiased,whichislikelyundersuchanon-expertsetting,itmayleadtolearningawrongrewardfunction.
Thereexistspriorworkthatconsidersdifferencesbe-tweenthehumanandrobotintheformsofdifferencesindo-maindynamics(Zhangetal.
2016;2017;Chakrabortietal.
Figure1:WorkowofGeReL.
Usingtherobot'struetransi-tionmodelTR,therobotrandomlygeneratesasetofdemon-strationsZwhichareevaluatedbythehuman.
ThehumanisassumedtoprovidehisratingγH∈ΓHforeachinstanceζ∈ZaccordingtotherewardfunctionRHandhisbe-liefThRabouttherobot'sdomaindynamics.
TheratingswillbeusedtoupdatetheestimatedrewardfunctionRH(gov-ernedbytheparametersw)andhuman'sunderstandingoftherobotThR(governedbytheparametersΘ).
Graycirclesdenotethelatentvariableswhiletheobservedareinwhite.
2017)aswellasrewardfunctions(Arnold,Kasenberg,andScheutz2017;Russell,Dewey,andTegmark2015),wheretherstdirectionisparticularlyrelevanttoourwork.
(Zhangetal.
2016;2017;Zakershahraketal.
2018)approximatethehuman'sunderstandingoftherobot'sbehaviorsusingalearningapproachandintegrateitintotaskplanningtogenerateexplicableplanstobridgethedifferencesindo-maindynamics.
Researchershavealsoinvestigateddirectlylearningthehuman'sunderstandingofthedomaindynam-icsusingmodellearning.
(UnhelkarandShah2019)lever-ageafactoredmodelofbehaviorsandpartialspecicationstorecovertheagent'struegenerativemodelofbehaviors.
(Reddy,Dragan,andLevine2018)learnthehuman'sbeliefaboutthedomaindynamicsviainversesoftQ-learninggiventhehuman'srewardfunction.
Inthispaper,weconsiderthehuman'sbiasedbeliefabouttherobotinrewardlearning.
Weusethehuman'sratingsoftherobot'sbehaviorstoinferboththerewardfunctionandhuman'sbeliefwithoutassum-ingeitherisavailable.
Althoughsimultaneouslylearningtherewardsanddomaindynamicshasbeenstudiedbefore(Her-manetal.
2016),itisnotapplicabletoourproblemsettingwherenon-experthumanratingsareused.
Comparedtoop-timizingthelikelihoodofexpertdemonstrationsbycomput-ingthederivativesdirectly,theposteriorsforourmethodas-sumemorecomplexforms.
Furthermore,ourmethoddoesnotrequirethevaluefunctionstotakecertainforms(e.
g.
,usingsoftBellmanequation)toperformwellandhenceitismoregeneralandeffective.
Thereby,thesmoothingeffectofentropyregularizedrewardfunctioncausedbysoftBellmanequationisavoided,aswewillshow.
GeReLTheworkowofGeReLispresentedinFigure1.
Therobotwillrstrandomlygenerateasetofdemonstrationsforqueryingthehumanforratings.
Then,theratingsofthedemonstrationswillbeusedtoinferboththehuman'sre-wardfunctionandhisbelief.
Thesystemterminateswhenitmeetstheconvergencecriterion.
Similartopriorworkonre-wardlearning,weassumethatthehumanistoalwaysmax-imizetherewards(NgandRussell2000;AbbeelandNg2004),sothathisratingscanbeestimatedgiventherewardfunctionandhisbeliefofthedomaindynamics.
ProblemFormulationMorespecically,givenarobot'sdemonstrationζ,weas-sumethatthehumanwouldrateitaccordingtotwofactors,therewardfunctionRHandhisbeliefabouttherobot'sdo-maindynamicsThR.
Whenthehuman'sbeliefisdifferentfromthetruerobot'sdomaindynamics,theratingmaybebiasedandcouldthenleadtoawronginterpretationofthehuman'spreference.
ThissettingintroducestheGeneralizedRewardLearning(GRL)problemasfollows:Given:Robot'sdemonstrationsZ;Human'sratingsΓHforeachinstanceinZ.
Todetermine:Human'struerewardfunctionRH;Human'sbeliefThRaboutrobot'sdomaindynamics.
Tosolvethisproblem,weformulatetheenvironmentasaMarkovDecisionProcesses(MDP).
AnMDPisdenedbyatuple(S,A,R,T,λ)whereSisanitesetofstates,Aisanitesetofactions,andR:S→Ristherewardfunctionthatmapseachstatetoautilityvalue.
T:S*A*S→[0,1]isthetransitionfunctionthatspeciestheprobabilityoftransitioningtothenextstatewhenyoutakeanactioninthecurrentstate.
λisthediscountfactorthatdetermineshowtheagentfavorscurrentrewardsoverfuturerewards.
Similartopriorworkonrewardlearning(NgandRus-sell2000;AbbeelandNg2004),weformulatetherewardfunctionRHforastatesasfollows:RH(s)=w·Φ(s)whereΦ=[φ0,φ1,φk]Tdenotesasetofpredenedfeaturesforstatesandw=[w0,w1,wk]Tdenotesasetofweightsforthefeatures.
Therobot'sdomaindynam-ics(i.
e.
,thetruedomaindynamics)iscapturedbyatransi-tionfunctionandassumedtobegiven.
Likewise,thehu-man'sbeliefabouttherobot'sdomaindynamicsismod-eledalsoasatransitionfunctionThR,whichishidden.
ThRisassumedtofollowasetofprobabilitydistributionsΘ=[θ1,θ2,θ|S|*|A|]whereθi=p(s|s,a)isadistributionforaxedsanda.
Thesedistributionscapturethehuman'spriorbeliefabouttherobot.
Toratearobot'sbehaviorζ,weassumethatthehumanwillrstgeneratehisexpectationoftherobot'sbehaviorasanoptimalpolicygeneratedusinghisrewardfunctionRHandbeliefabouttherobotThR.
ThenthebehavioroftherobotiscomparedwiththeoptimalpolicytogeneratearatingγH.
Hence,ourlearningtaskinthispaperbecomestolearntheweightswandtransitionprobabilitydistributionsΘ.
MethodologyTheinferenceproblemaboveisoftensolvedbyoptimiz-ingtheposteriorprobabilitywithrespecttothelatentvari-ables.
However,duetothecomplexformsoftheposteriors,weformulatetheprobleminavariationalinferenceframe-work(Jordanetal.
1999;Bishop2006).
Ourgoalistoap-proximatetheposteriordistributionp(w,Θ|ΓH,Z),whereΓH,Zaretheobservationsandw,Θthelatentvariables.
WeassumethatwfollowsamultivariateGaussiandistri-butionN(,Σ).
Forsimplicity,weassumethatΣisgivenapriori.
ForΘ,weneedtoselectapriorforeachθiasaprobabilitydistribution.
WeassumethateachθifollowsaDirichletdistributionDIR(αi),whichencodesadistribu-tionoverdistributions.
LetA=[α1,α2,α|S|*|A|],andthereby,andAaretheparametersweneedtolearn.
Asaresult,ourvariationalposteriordistributionbecomesq(w,Θ|,A),whichistheposteriorofthelatentvariablesthatcorrespondtotherewardfunctionandhuman'sbeliefabouttherobot'sdomaindynamicsgovernedbyandA.
ItthustransformstheproblemofinferringRHandThRintoaproblemofndingandAtomakeq(w,Θ|,A)tobeclosetop(w,Θ|ΓH,Z).
Asavariationalinferenceproblem,weoptimizetheEvi-denceLowerBOund(ELBO):L(q)=Eq(w,Θ)[logp(ΓH,Z,w,Θ)logq(w,Θ)]wherep(ΓH,Z,w,Θ)isthejointprobabilityoftheobser-vationsΓH,Zandlatentvariablesw,Θ.
Inordertomakeitcomputableinourtask,weapplyblack-boxvariationalinference(Ranganath,Gerrish,andBlei2014)tomaximizeELBOviastochasticoptimization:,A=,A+ρ·,AL(q)wherethelearningrateρfollowstheRobbins-Monrorules(RobbinsandMonro1951).
WecomputethegradientofELBOwithrespecttothefreeparametersandAand,AL(q)isderivedasfollows:,AL(q)=Eq(w,Θ)[,Alogq(w,Θ|,A)·(logp(ΓH,Z,w,Θ)logq(w,Θ|,A))](1)FromEquation(1),wecanseethatthegradientofELBOistheexpectationofthemultiplicationofthescorefunction(HinkleyandCox1979)(i.
e.
,,Alogq(w,Θ|,A))andinstantaneousELBO(i.
e.
,logp(ΓH,Z,w,Θ)logq(w,Θ|,A))withrespecttoourvariationalposteriordistribution.
Thedetailedderivationof,AL(q)ispre-sentedin(Ranganath,Gerrish,andBlei2014).
Theformof,AL(q)isnotdirectlycomputable.
GiventhatandAareindependentparametersinourset-ting,wecomputeL(q)andAL(q)respectivelyandup-datethemseparately:=+ρ·L(q)A=A+ρA·AL(q)Thisalsoallowsustoapplythemean-eldassumptionthatgivesthefollowingfactorization:q(w,Θ|,A)=q(w|)·q(Θ|A)ThenwecanrewritethegradientofELBOasfollows:,AL(q)=Eq(w)Eq(Θ),A(logq(w|)+logq(Θ|A))·(logp(ΓH,Z,w,Θ)logq(w|)logq(Θ|A))]Takeq(w|)asanexample,followingthederivationsin(Ranganath,Gerrish,andBlei2014),thegradientofELBOwithrespecttobecomes:L(q)=Eq(w)[(logq(w|))·Eq(Θ)[logp(ΓH,Z,w,Θ)logq(w|)logq(Θ|A)]]NotethatthersttermEq(w)[(logq(w|)]=0(Ran-ganath,Gerrish,andBlei2014).
HencethelasttermintheinstantaneousELBOcanbeconsideredasaconstantwithrespecttoq(w)andcanceledout.
L(q)thenbecomes:L(q)=Eq(w)[(logq(w|))·(Eq(Θ)[logp(ΓH,Z,w,Θ)]logq(w|))](2)Differentfrom(Ranganath,Gerrish,andBlei2014),inourproblem,theexpectationofthelogjointprobabilitylogp(ΓH,Z,w,Θ)cannotbecanceledoutsincewandΘhappentobeintheMarkovblanketofeachother.
BasedontherelationshipamongthesevariablesasshowninFigure1,thelogprobabilitycanbefactorizedasfollows:logp(ΓH,Z,w,Θ)=logp(ΓH|Z,w,Θ)+logp(w)+logp(Θ)+logp(Z)(3)PuttingEquation(3)backintoEquation(2),weobtain:L(q)=Eq(w)[(logq(w|))·(Eq(Θ)[logp(ΓH|Z,w,Θ)]+logp(w)logq(w|))](4)wheretheexpectationofthetermslogp(Θ)andlogp(Z)withrespecttoq(Θ)areconstantsandcanbecanceledoutsinceEq(w)[(logq(w|)]=0.
NowwehaveobtainedthegradientofELBOwithrespecttothelatentvariableaspresentedinEquation(4).
Similarly,thegradientofELBOwithrespecttoeachαi∈Aisasfollows:αiL(q)=Eq(θi)[αi(logq(θi|αi))·(Eq(w)[logp(ΓH|Z,w,Θ)]+logp(θi)logq(θi|αi))]Bothp(w)andp(θi)arepriors,whichareassumedtofollowamultivariateGaussiandistributionandaDirichletdistribu-tionrespectively.
Intheequationsabove,logp(ΓH|Z,w,Θ)=logp(γH|ζ,w,Θ)sincethedemonstrationsandratingsareconditionallyindependentfromeachother.
p(γH|ζ,w,Θ)indicateshowlikelythehumanwouldgivearatingγHforthedemonstrationζgiventheparametersfortherewardfunctionandhuman'sbeliefabouttherobot.
WeassumeaGaussiandistributionN(γH|γH,ΣγH)whereγHistheestimatedmeanofthehuman'sratingsgivenwandΘ,andΣγHisassumedtobegiventosimplifythediscussion.
Asdiscussedearlier,theestimatedmeanratingofademonstrationisassumedtodependontwofactors,therewardfunctionandthehuman'sbeliefabouttherobot'sdomaindynamics.
Theytogetherdeterminethehuman'sexpectationoftherobot'sbehavior,whichcorrespondstotheoptimalpolicyfortherobotinthehuman'smind.
Inthispaper,weassumethattheratingisproportionaltothegeometricmeanofthehuman'ssoftmaxpolicyappliedtothedemonstration.
Moreover,wedeneγmaxtobeaconstantthatrepresentsthehighestratingthatmaybegiven.
Followingourdiscussion,theestimatedhuman'sratingcanbecomputedforademonstrationζ={(s1,a1),(s2,a2)sn,an)}as:γH=γmax·ni=1π(ai|si)1nwherenisthelengthofthedemonstration,andπisthees-timatedhuman'ssoftmaxpolicycomputedusingwandΘ.
VarianceReduction:ThecomputationofL(q)andαiL(q)abovecannotbeperformeddirectlyduetothein-tractabilityofcomputingtheexpectations.
Hence,weap-proximatethegradientsusingsamplingmethods(Hastings1970).
WithMonteCarlosamples,thegradientsareesti-matedasfollows:L(q)1SSs=1[(logq(ws|))·(logp(ΓH|Z,ws,Θs)+logp(ws)logq(ws|))]whereSisthenumberofsamples,andwsq(w),Θsq(Θ).
Theseestimatedgradients,however,mayhavealargevariancewhichcouldhindertheconvergenceofourap-proach.
Therefore,itisnecessarytoreducethevariance.
(Ross2002)introducedcontrolvariatethatrepresentsafam-ilyoffunctionswithequivalentexpectations.
Withcontrolvariate,wecaninsteadcomputetheexpectationofanalter-nativefunctionwhichhasasmallervariance.
Letfbethefunctiontobeapproximated,functionfisdenedas:f=fa·(gE[g])wheregservesasanauxiliaryfunctionthathasaniterstmoment.
fcanbeproventohavesmallervarianceswithanequivalentexpectation,wherethefactoraiscomputedtominimizethevariance(Ranganath,Gerrish,andBlei2014)asa=cov(f,g)var(g).
Inthispaper,weselecttheexpec-tationofthescorefunction(i.
e.
,Eq(w)[(logq(w|))]andEq(Θ)[αi(logq(Θ|αi))])tobeg.
WepresentGeReLinAlgorithm1.
Giventherobot'sdemonstrationsandthecorrespondingratings,weleveragethehuman'sratingstoupdatetheparametersandAofourvariationalposteriorsq(w)andq(Θ)viastochasticop-timization.
ThegradientsoftheELBOwithrespecttoandAareapproximatedusingMonteCarlosampling.
Fur-thermore,wetakeadvantageofcontrolvariatetoreducetheAlgorithm1GeneralizedRewardLearningwithBiasedBe-liefaboutDomainDynamics(GeReL)Input:therobot'sdemonstrationsZ,human'sratingsΓH,variationalposteriorsq(w)andq(Θ),MaxIterOutput:andA1:Initialize:freeparametersandAforq(w)andq(Θ)2:Lett=1.
3:whilet
GeReLterminateswhentheconvergencecriterionismet.
EvaluationToevaluateourapproach,weconducttwosetsofexperi-mentsinasimulatedgrid-worldnavigationdomainandaCoffeeRobotdomain(Boutilier,Dearden,andGoldszmidt2000;SigaudandBuffet2013)withauserstudy.
Thesim-ulationwillbefocusingonvalidatingourlearningmethodunderbiasedbeliefs.
Theuserstudywillservetwopurposes,showingthat1)humanusersareeasilybiasedinourprob-lemsetting;2)ouralgorithmlearnsthecorrecthumanpref-erencesundersuchbiases,whilepriormethodsthatignoresuchbiaseswouldfail.
SimulatedNavigationDomainIntherstexperiment,wetesttheperformanceofGeReLinagrid-worldnavigationdomainwhichcontains7*7=49states.
Wesetonerewardstate(i.
e.
,location)thathasalargepositiveweight(i.
e.
5)andonepenaltylocationwithalargenegativeweight(i.
e.
,-5).
Theyarerandomlylocatedatcornersofthegrid-world.
Therobotstartsatarandomstateanditsgoalistomaximizetherewards.
Therearefouractions,{1(Up),2(Down),3(Left),4(Right)},whichcantransfertheagentfromthecurrentstatetoanotherstate.
Totestouralgorithm,wesimulatetwotypesofbiasedhu-manbeliefsabouttherobot'sdomaindynamics.
1)ReversedUp&Down:thehumanbelievesthataction1wouldtaketherobotdownandaction2wouldmoveitupinstead.
2)Ro-tatedBelief:humanbelievesthattheaction1wouldmovetherobotleft,theaction2wouldmoveitright,theaction3wouldmoveitupandtheaction4wouldmoveitdown.
Figure2:Rewardslearnedbydifferentapproaches.
Thehuman'srewardfunctionforeachstateisdenedasaweightedsummationofaninversedistancemetrictothere-wardandpenaltystates(i.
e.
,thecloseritistothestate,themoreinuencethatstatehasonitsreward).
Thedemonstra-tionsarerandomlygeneratedviatherobot'struedynamicmodel.
Thehuman'sratingsaresimulatedusingthetruehu-manrewardfunctionandbiasedbeliefabouttherobot'sdo-maindynamicsfollowingaGaussiandistribution.
WecompareGeReLwithtwobaselinemethodsthatas-sumethatthehumanmaintainsthecorrectbeliefabouttherobot'sdomaindynamics,namelyMaxEnt-IRL(Ziebartetal.
2008)andGeReL,withthelatterbasicallyusesGeReLwithoutupdatingthedomaindynamics.
Inbothbaselinemethods,thetruerobot'sdomaindynamicsisusedduringlearning.
Inaddition,avariantoftheSimultaneousEstima-tionofRewardsandDynamics(SERD)algorithm(Hermanetal.
2016)implementedthatlearnsboththerewardfunc-tionanddynamicsbasedonratings(theoriginalmethoddoesnotapplytoourproblemsetting)isusedinthecom-parison,whichreliesonsoftvalueiterationthatrequiresthevaluefunctionstoassumecertainshapestoperformwell.
ToobtaindemonstrationsforMaxEnt-IRL,wegeneratethembasedonthesoftmaxpolicyofthehuman.
Allofthefourmethodsareprovidedwiththesameamountofdemonstra-tions.
Alltheresultsareaveragedovermultipleruns.
Figure3showstheresultfortheReversedUp&Downsetting.
TheresultshowsthatGeReLcansuccessfullyre-coverthehuman'srewardfunctionandbeliefabouttherobot'sdomaindynamicswhileGeReLandMaxEnt-IRLconvergeinthecompletelyoppositedirectionsincetheydonotconsiderthatthehuman'sbeliefcouldbebiased.
Ontheotherhand,SERDconvergesintherightdirection,butthelearnedvaluesarefartherfromthegroundtruththanGeReLinallcases.
Thisisduetothesmoothingeffectofsoftvalueiteration.
Inaddition,wecomputetheKLdivergenceofthesoftmaxpolicygeneratedbytheestimatedrewardfunctionandhuman'sbeliefwiththatofthegroundtruthtoexam-inehowwellwecanestimatethehuman'sexpectationoftherobot'sbehaviors.
Similartrendsareobservedamongallthemethods.
ThecomparisonoftherewardslearnedbythesefourmethodswiththegroundtruthispresentedinFig-ure2.
BothGeReLandSERDconvergetothecorrectpat-ternofrewardsintermsoftheirrelativemagnitudes.
SERDshowslesssensitivitytothemagnitudessincesoftBellmanequationwouldleadtoanentropyaugmentedrewardfunc-tion(Haarnojaetal.
2017).
TheadverseeffectoflearningfrombiasedratingsisclearfromthegureforGeReLandMaxEnt-IRL,whichbothfailtorecoverthetruepreferences.
TheresultsforbothsettingsarepresentedinTable1,whichFigure3:ComparisonoftheperformanceamongGeReL,SERD,GeReL,MaxEnt-IRLwiththeprioralsoshown.
Left:TheL2distancebetweenthelearnedrewards(whichiscomputedusingw)andthegroundtruth.
Middle:TheL2distancebetweentheestimatedhuman'sbelief(i.
e.
,Θ)andthegroundtruth.
Right:TheKLdivergencebetweentheestimatedhuman'sexpectationofrobot's(softmax)policy(whichiscomputedusingwandΘ)andthatunderthegroundtruth.
d(R)d(Θ)d(π)d(R)d(Θ)d(π)ReversedUp&DownRotatedBeliefGeReL12.
170.
060.
1112.
610.
080.
23SERD16.
430.
380.
4717.
620.
570.
63GeReL26.
720.
561.
4623.
960.
911.
43MaxEnt-IRL23.
320.
561.
6828.
020.
911.
55Table1:ComparisonofGeReL,SERD,GeReL,andMaxEnt-IRLforthetwosettingsinoursimulationwithre-specttotheL2distancebetweentheestimatedvaluesandthegroundtruth(i.
e.
,d(R),d(Θ)).
Thethirdcolumn(i.
e.
,d(π))showstheKLdivergencebetweentheestimatedhu-man'sexpectationoftherobot'ssoftmaxpolicyandthatun-derthegroundtruth.
showsimilarperformancesinbetweenthetwosettings.
ItconrmsthatGeReLcaneffectivelyestimatethehuman'srewardfunctionunderbiasedbeliefs.
UserStudywiththeCoffeeRobotDomainBesidestheexperimentsinasimulateddomain,wealsocon-ductauserstudy.
Throughthestudy,wehopetodemonstratethathumanscanbeeasilybiasedinourproblemsetting,whichmayleadtobiasedratingsthatcouldhaveledtoawronginterpretationofthehumanpreference.
Insuchcases,wewillshowthatGeReLcanaccuratelyidentifythesitua-tion.
WeapplytheCoffeeRobotdomain(Boutilier,Dear-den,andGoldszmidt2000;SigaudandBuffet2013)inthisuserstudy,whichisillustratedinFigure4.
ThisisatypicalfactoredMDPdomaindescribedby6binaryfeatureswhichrepresentwhetheritisraining,whethertherobothasacof-fee,etc.
Thetaskoftherobotistobuyacupofcoffeefromacafeanddeliverittoapersoninhisofce.
Whenitisrain-ing,therobotcouldchoosetoeitheroperateintherainoruseanumbrellatostaydry.
However,usinganumbrellawhileholdingthecoffeecupmaycausethecoffeetospill.
Tocreateasituationwherebiasesmaybepresent,wede-signtwoexperimentalsettingswithtwodifferenttypesofrobots:amobilerobotandahumanoid,asseeninFigure4.
Weanticipatethattheappearancewouldintroducehumanbiases(Haringetal.
2018)intermsoftheircapabilitiesofFigure4:TheCoffeeRobotdomain.
Theweathercouldberainyorsunny,andtherobotmaychoosetouseanumbrellaoroperateintherain.
Weusetwotypesofrobots(humanoidvs.
mobile)toperformthesamesetofdemonstrationsthatcoverthevarioussituationsthatmayoccur.
handlingthetask.
Toreducetheeffectsthatthehumansub-jectwouldimprovetheirunderstandingovertime,wegen-erateonly7demonstrationsforeachrobotthatincludevar-iousscenariosthatmayoccur,suchasforasunnyorrainyday,forwhetherornottherobottakestheumbrella,andforwhetherornottherobotspillsthecoffee.
Thegroundtruthforthedomaindynamicsissetsuchthatthehumanoidislesslikelytospillthecoffeewhileusingtheumbrellathanthemobilerobot.
WepublishtheexperimentsonAmazonMechanicalTurk(MTurk).
Toremoveinvalidresponses,weinsertasanitycheckdemonstrationwithrandomactions,whichshouldhavereceivedthelowestrating.
Werecruited20participantsforeachsetting.
Afterremovingthosethatfailedthesanitycheckorwithveryshortresponsetime(<3min),weob-tained12validresponsesforeachsettingwithagesrangingfrom23to61(theratioofmalestofemalesis2:1).
Eachparticipantisprovidedwithinstructionsaboutthedomainatthebeginning.
Toavoidtheinuencefromviewingthedemonstrations,immediatelyaftertheinstructions,weasktheparticipantstwoquestionsasfollows:Q1:HowmuchmorelikelydoyoufeelthattherobotmayspillthecoffeewhileusinganumbrellaQ2:HowmuchdoyoucareabouttherobotbeingwetTherstquestionisdesignedtoillicittheparticipant'sbeliefQuestionp-valueMobileHumanoid(Q1)DomainDynamics0.
0472.
923.
58(Q2)WeightPreference0.
0272.
833.
67Table2:Averagedparticipants'responsestothetwoques-tionsforeachsettingbeforeviewingthedemonstrations.
Theyareaskedina5-pointLikertscalewhere1isthelowestand5thehighest.
abouttherobot'sdomaindynamicswhilethesecondques-tionisfortheparticipant'spreference.
TheirfeedbackforeachsettingispresentedinTable2.
Theparticipantsofthemobilerobotsettingbelievedthattherobotwouldbelesslikelytospillthecoffeewhileholdingtheumbrellathantheparticipantsofthehumanoidsetting.
Noticethatthisisincontrasttothegroundtruth.
Meanwhile,theparticipantsexpressedmoreconcernabouttherobotgettingwetinthehumanoidsettingthanthemobilerobotsetting.
Afterthequestions,weaskedtheparticipantstoratethedemonstrations.
Accordingly,wendthattheratingsforthedemonstrationswheretherobotoperatesintherainwithoutanumbrella,ortakesanumbrellainasunnydaytoberatedlowinthehumanoidsetting.
Incontrast,inthemobileset-ting,fewerdemonstrationsreceivedlowratings.
Thesere-sultssupportedourassumptionthatthehumanareeasilybi-asedwhenworkingwithrobots.
Next,werunourmethodundereachsettingtoseewhetherourmethodcanrecoverfromsuchbiasedbeliefs.
Forcomparison,wealsorunGeReL,whichperformedsimilarlytoMaxEnt-IRLinoursimulationtask.
Weruneachmethodforeachparticipantinbothsettings.
Theratingsarenormalizedtoremoveinconsistenciesacrossdifferentpar-ticipants.
TheresultsarepresentedinFigure5.
WeobservedthatthelearnedprobabilityofspillingcoffeewhileholdinganumbrellabyGeReLforthehumanoidrobotsettingisgen-erallylargerthanthemobilerobotsetting.
Thisrepresentstheestimatedhumanunderstandingofthedomaindynamics,whichisconsistentwiththeparticipant'sfeedbackshowninTable2.
Furthermore,GeReLlearnedthattheparticipantscaredmoreabouttherobotgettingwetinthehumanoidset-tingthanthemobilerobotsetting,whichisalsoconsistentwiththeparticipant'struepreference.
Incontrast,GeReLdiscoveredjusttheopposite!
DiscussionsOncethebiaseddomaindynamicsisobtained,thenextques-tionishowtouseit.
Thesimplestmethodofcourseistoinformthehumanabouthisbiasesandhopethatitwouldwork.
Analternativemethodthatisoftenconsideredintheareaofhuman-awareplanningisthattherobotcould,in-steadofalwayspursueoptimalbehaviors,behavetomatchwiththehuman'sexpectationwheneverfeasible,soastobehaveinanexplicablemanner.
Incontrasttothemulti-objectiveMDPproblem(Roijersetal.
2013;Chatterjee,Ma-jumdar,andHenzinger2006)whichhasmorethanonere-wardfunctiontooptimize,inthisproblem,therobotmain-tainstwotransitionfunctions,oneforitsowndynamicsandtheotherforthehuman'sbeliefofit.
TherealreadyFigure5:FeatureweightslearnedbyGeReLandGeReL.
existsworkthatlooksatthisproblem(Zhangetal.
2017;Chakrabortietal.
2017).
Likeallrewardlearningproblems,thesolutionisnotunique.
Thisiscommonlyknownasthenon-identiabilityissue.
Ingeneralrewardlearning(GRL),anadditionalcom-plexityisthelearningofthetransitionfunction,whichun-fortunatelyonlyaggravatestheissue.
Sofar,wearenotawareofanysolutionstothisproblemexceptfortheonesthatintroduceinductivebiasesonthepriorsortheerrorfunctions,suchasBayesianIRL(RamachandranandAmir2007)andapprenticeshiplearningmethods(AbbeelandNg2004).
Inthisregard,ourworkalsointroducesaninductivebiasbyassumingaformoftheposteriorasamultivariateGaussiandistribution.
Intermsofsimultaneouslylearningdifferentfactors,thereexistpriorresults(ArmstrongandMindermann2018)thatargueagainstitandprovethatitisimpossibletodetermineonewithoutassumingsomeformoftheother.
However,wenotethatthenegativeresultsapplyonlytothesitua-tionwhereoneofthefactorsisthecomputationalprocess.
ConsiderthefunctionC(R,M)=Γ.
WhenCisgiven,thechoicesofr∈Randm∈Mareconnectedtothecor-respondingvalueofγ∈Γ.
However,ifonlymisgiven,wemaychooseanyrandthensimplyremap(choosingac∈C)(r,m)'stotheircorrespondingγ's.
Thisexibilityofthecomputationalprocessisthecorereasonofthenegativeresults.
However,thenon-identiabilityissueisstillthere.
ConclusionInthispaper,welookedtheGeneralizedRewardLearning(GRL)problemandproposedamethodcalledGeReLtoaddressit.
GeReLremovestheassumptionthatthehumanalwaysmaintainsthetruebeliefabouttherobot'sdomaindynamics.
Todevelopthemethod,weformulatedtheGRLprobleminavariationalinferenceframeworktoinfertheparametersgoverningtherewardfunctionandthehuman'sbeliefabouttherobotsimultaneously.
Toreducetheeffortforobtainingtrainingsamples,weusedthehuman'srat-ingsofrobotdemonstrations.
Weevaluatedourapproachexperimentallyusingasimulateddomainandwithauserstudy.
TheresultsshowedthatGeReLoutperformedpriorapproachesthatcouldhavemisinterpretedthehumanprefer-enceswhensuchbiasesarenotconsidered.
WeshowedthatGeReLcouldrecoverthetruehumanpreferenceseffectivelyevenundersuchachallengingsetting.
AcknowledgmentsThisresearchissupportedinpartbytheNSFgrantIIS-1844524,theNASAgrantNNX17AD06G,andtheAFOSRgrantFA9550-18-1-0067.
ReferencesAbbeel,P.
,andNg,A.
Y.
2004.
Apprenticeshiplearningviainversereinforcementlearning.
InProceedingsofthetwenty-rstinternationalconferenceonMachinelearning,1.
ACM.
Armstrong,S.
,andMindermann,S.
2018.
Occam'srazorisinsufcienttoinferthepreferencesofirrationalagents.
InAdvancesinNeuralInformationProcessingSystems,5598–5609.
Arnold,T.
;Kasenberg,D.
;andScheutz,M.
2017.
Valuealignmentormisalignment–whatwillkeepsystemsaccount-ableInWorkshopsattheThirty-FirstAAAIConferenceonArticialIntelligence.
Bishop,C.
M.
2006.
Patternrecognitionandmachinelearn-ing.
springer.
Boularias,A.
;Kober,J.
;andPeters,J.
2011.
Relativeentropyinversereinforcementlearning.
InProceedingsoftheFourteenthInternationalConferenceonArticialIntel-ligenceandStatistics,182–189.
Boutilier,C.
;Dearden,R.
;andGoldszmidt,M.
2000.
Stochasticdynamicprogrammingwithfactoredrepresenta-tions.
Articialintelligence121(1-2):49–107.
Chakraborti,T.
;Sreedharan,S.
;Zhang,Y.
;andKambham-pati,S.
2017.
Planexplanationsasmodelreconciliation:movingbeyondexplanationassoliloquy.
InIJCAI,156–163.
AAAIPress.
Chatterjee,K.
;Majumdar,R.
;andHenzinger,T.
A.
2006.
Markovdecisionprocesseswithmultipleobjectives.
InAn-nualSymposiumonTheoreticalAspectsofComputerSci-ence,325–336.
Springer.
Cui,Y.
,andNiekum,S.
2018.
Activerewardlearningfromcritiques.
InICRA,6907–6914.
IEEE.
Daniel,C.
;Viering,M.
;Metz,J.
;Kroemer,O.
;andPeters,J.
2014.
Activerewardlearning.
InRSS.
DorsaSadigh,A.
D.
D.
;Sastry,S.
;andSeshia,S.
A.
2017.
Activepreference-basedlearningofrewardfunctions.
InRSS.
Duchi,J.
;Hazan,E.
;andSinger,Y.
2011.
Adaptivesubgra-dientmethodsforonlinelearningandstochasticoptimiza-tion.
JMLR12(Jul):2121–2159.
Haarnoja,T.
;Tang,H.
;Abbeel,P.
;andLevine,S.
2017.
Reinforcementlearningwithdeepenergy-basedpolicies.
InProceedingsofthe34thInternationalConferenceonMa-chineLearning,1352–1361.
JMLR.
org.
Haring,K.
S.
;Watanabe,K.
;Velonaki,M.
;Tossell,C.
C.
;andFinomore,V.
2018.
Ffabtheformfunctionattributionbiasinhuman–robotinteraction.
IEEETransactionsonCog-nitiveandDevelopmentalSystems10(4):843–851.
Hastings,W.
K.
1970.
Montecarlosamplingmethodsusingmarkovchainsandtheirapplications.
Herman,M.
;Gindele,T.
;Wagner,J.
;Schmitt,F.
;andBur-gard,W.
2016.
Inversereinforcementlearningwithsimul-taneousestimationofrewardsanddynamics.
InArticialIntelligenceandStatistics,102–110.
Hinkley,D.
V.
,andCox,D.
1979.
Theoreticalstatistics.
ChapmanandHall/CRC.
Jordan,M.
I.
;Ghahramani,Z.
;Jaakkola,T.
S.
;andSaul,L.
K.
1999.
Anintroductiontovariationalmethodsforgraphicalmodels.
Machinelearning37(2):183–233.
Ng,A.
Y.
,andRussell,S.
2000.
Algorithmsforinversereinforcementlearning.
IninProc.
17thInternationalConf.
onMachineLearning.
Ramachandran,D.
,andAmir,E.
2007.
Bayesianinversereinforcementlearning.
InIJCAI,2586–2591.
Ranganath,R.
;Gerrish,S.
;andBlei,D.
2014.
Blackboxvariationalinference.
InArticialIntelligenceandStatistics,814–822.
Reddy,S.
;Dragan,A.
;andLevine,S.
2018.
Wheredoyouthinkyou'regoing:Inferringbeliefsaboutdynamicsfrombehavior.
InAdvancesinNeuralInformationProcess-ingSystems,1461–1472.
Robbins,H.
,andMonro,S.
1951.
Astochasticapproxima-tionmethod.
Theannalsofmathematicalstatistics400–407.
Roijers,D.
M.
;Vamplew,P.
;Whiteson,S.
;andDazeley,R.
2013.
Asurveyofmulti-objectivesequentialdecision-making.
JAIR48:67–113.
Ross,S.
M.
2002.
Simulation.
Elsevier.
Russell,S.
;Dewey,D.
;andTegmark,M.
2015.
Researchprioritiesforrobustandbenecialarticialintelligence.
AIMagazine36(4):105–114.
Russell,S.
J.
1998.
Learningagentsforuncertainenviron-ments.
InCOLT,volume98,101–103.
Sigaud,O.
,andBuffet,O.
2013.
Markovdecisionprocessesinarticialintelligence.
JohnWiley&Sons.
Unhelkar,V.
V.
,andShah,J.
A.
2019.
Learningmodelsofsequentialdecision-makingwithpartialspecicationofagentbehavior.
InAAAI.
Zakershahrak,M.
;Sonawane,A.
;Gong,Z.
;andZhang,Y.
2018.
Interactiveplanexplicabilityinhuman-robotteaming.
InRO-MAN,1012–1017.
IEEE.
Zhang,J.
,andDragan,A.
2019.
Learningfromextrapolatedcorrections.
InICRA,7034–7040.
IEEE.
Zhang,Y.
;Sreedharan,S.
;Kulkarni,A.
;Chakraborti,T.
;Zhuo,H.
H.
;andKambhampati,S.
2016.
Planexplicabilityforrobottaskplanning.
InProceedingsoftheRSSWork-shoponPlanningforHuman-RobotInteraction:SharedAu-tonomyandCollaborativeRobotics.
Zhang,Y.
;Sreedharan,S.
;Kulkarni,A.
;Chakraborti,T.
;Zhuo,H.
H.
;andKambhampati,S.
2017.
Planexplica-bilityandpredictabilityforrobottaskplanning.
InICRA,1313–1320.
IEEE.
Ziebart,B.
D.
;Maas,A.
;Bagnell,J.
A.
;andDey,A.
K.
2008.
Maximumentropyinversereinforcementlearning.
InAAAI.
- direction尼坤letitrain相关文档
- 原地尼坤letitrain
- storm尼坤letitrain
- guards尼坤letitrain
- 经营坤七药业2019年经营风险报告-智泽华
- 教师马子坤报告学习体会
- 质量标准坤和物业绿化质量标准
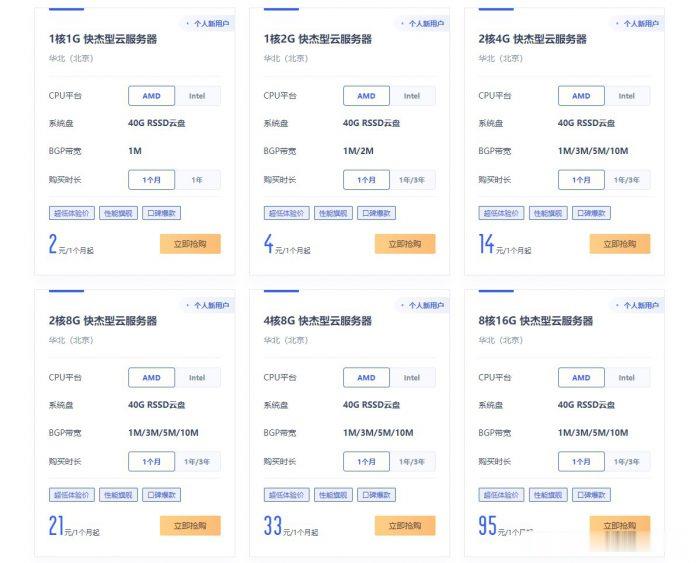
ucloud国内云服务器2元/月起;香港云服务器4元/首月;台湾云服务器3元/首月
ucloud云服务器怎么样?ucloud为了扩大云服务器市场份额,给出了超低价云服务器的促销活动,活动仍然是此前的Ucloud全球大促活动页面。目前,ucloud国内云服务器2元/月起;香港云服务器4元/首月;台湾云服务器3元/首月。相当于2-4元就可以试用国内、中国香港、中国台湾这三个地域的云服务器1个月了。ucloud全球大促仅限新用户,国内云服务器个人用户低至56元/年起,香港云服务器也仅8...
paypal$10的代金券,选购美国VPS
paypal贝宝可撸$10的代金券!这两天paypal出了活动,本次并没有其他的限制,只要注册国区的paypal,使用国内的手机号和62开头的银联卡,就可以获得10美元的代金券,这个代金券购买产品需要大于10.1美元,站长给大家推荐几个方式,可以白嫖一年的VPS,有需要的朋友可以看看比较简单。PayPal送10美元活动:点击直达活动sfz与绑定卡的号码可以重复用 注册的邮箱,手机号与绑的银联卡必须...

HostKvm新上联通CUVIP线路VPS,八折优惠后1G内存套餐$5.2/月起
最近上洛杉矶机房联通CUVIP线路主机的商家越来越多了,HostKvm也发来了新节点上线的邮件,适用全场8折优惠码,基于KVM架构,优惠后最低月付5.2美元起。HostKvm是一家成立于2013年的国人主机商,提供基于KVM架构的VPS主机,可选数据中心包括日本、新加坡、韩国、美国、中国香港等多个地区机房,君选择国内直连或优化线路,延迟较低,适合建站或者远程办公等。以洛杉矶CUVIP线路主机为例,...
尼坤letitrain为你推荐
-
云主机租用云主机到底是什么?租用以后该如何使用?网站空间租赁如何租用网站空间?怎么查看空间支持那些功能呢? 一般多少钱?中国互联网域名注册中国互联网络域名注册暂行管理办法的第三章 域名注册的申请vps试用求个免费现成的vps(可永久可试用)免费网站域名申请怎么免费上传我的网站呀和免费申请域名php虚拟空间我已经有一套网站php代码和模板,并且有自己的虚拟空间和域名,怎么才能把我的代码加入到网站上.成都虚拟空间成都市规划信息技术中心如何?深圳网站空间菜鸟问:网站空间如何选择,与空间的基本知识?网站空间免备案哪个网站有免费的免备案空间,海外港台都可虚拟主机评测网求推荐一些适合个人博客网站的虚拟主机的服务商