识别扫描文字结果以图片格式(.bmp)存入电脑然后使用ORC识别系统进行转换最终用WORD进行修改编辑
扫描文字结果以图片格式(.bmp)存入电脑。然后使用ORC识别系统进行转换最终用WORD进行修改编辑。下面教你如何使用ORC:
OCR是英文Optical Character Recognition的缩写翻译成中文就是通过光学技术对文字进行识别的意思,是自动识别技术研究和应用领域中的一个重要方面。它是一种能够将文字自动识别录入到电脑中的软件技术是与扫描仪配套的主要软件属于非键盘输入范畴需要图像输入设备主要是扫描仪相配合。现在OCR主要是指文字识别软件在1996年清华紫光开始搭配中文识别软件之前市场上的扫描仪和OCR软件一直是分开销售的专业的OCR软件谠缧┦焙蚵舻帽壬 枰腔挂
蟆K孀派 枰欠直媛实奶嵘 琌CR软件也在不断升级扫描仪厂商现在已把专业的OCR软件搭配自己生产的扫描仪出售。 OCR技术的迅速发展与扫描仪的广泛使用是密不可分的近两年随着扫描仪逐渐普及和OCR技术的日臻完善 OCR己成为绝大多数扫描仪用户的得力助手。
一、 OCR技术的发展历程
自20世纪60年代初期出现第一代OCR产品开始经过30多年的不断发展改进包括手写体的各种OCR技术的研究取得了令人瞩目的成果人们对OCR产品的功能要求也从原来的单纯注重识别率发展到对整个OCR系统的识别速度、用户界面的友好性、操作的简便性、产品的稳定性、适应性、可靠性和易升级性、售前售后服务质量等各方面提出更高的要求。
IBM公司最早开发了O CR产品 1965年在纽约世界博览会上展出了IBM公司的O CR产品——IBM l287。 当时的这款产品只能识别印刷体的数字、英文字母及部分符号并且必须是指定的字体。 20世纪60年代末 日立公司和富士通公司也分别研制出各自的O CR产品。全世界第一个实现手写体邮政编码识别的信函自动分拣系统是由日本东芝公司研制的两年后N EC公司也推出了同样的系统。到了1974年信函的自动分拣率达到92左右并且广泛地应用在邮政系统中发挥着较好的作用。 1983年日本东芝公司发布了其识别印刷体日文汉字的OCR系统O CRV595其识别速度为每秒70100个汉字识别率为99 5。其后东芝公司又开始了手写体日文汉字识别的研究工作。
中国在OCR技术方面的研究工作相对起步较晚在20世纪70年代才开始对数字、英文字母及符号的识别技术进行研究 20世纪70年代末开始进行汉字识别的研究。 1986年 国家863计划信息领域课题组织了清华大学、北京信息工程学院、沈阳自动化所三家单位联合进行中文OCR软件的开发工作。至1989年清华大学率先推出了国内第一套中文OCR软件--清华文通TH-OCR1.0版至此中文OCR正式从实验室走向了市场。清华OCR印刷体汉字识别软件其后又推出了TH-OCR92高性能实用简繁体、多字体、多功能印刷汉字识别系统使印刷体汉字识别技术又取得重大进展。到1994年推出的TH-OCR94高性能汉英混排印刷文本识别系统则被专家鉴定为“是国内外首次推出的汉英混排印刷文本识别系统总体上居国际领先水平”。上个世纪90年代中后期清华大学电子工程系提出
并进行了汉字识别综合研究使汉字识别技术在印刷体文本、联机手写汉字识别、脱机手写汉字识别和脱机手写数字符号识别等领域全面地取得了重要成果。具有代表性的成果是TH-OCR97综合集成汉字识别系统它可以完成多文种(汉、英、 日)印刷文本、联机手写汉字、脱机手写汉字和手写数字的识别输入。几年来除清华文通TH-O CR外其它如尚书SH-OCR等各具风格的O CR软件也相继问世 中文OCR市场稳步扩大用户遍布世界各地。
可以说目前印刷体OCR的识别技术已经达到较高水平。 OCR产品已由早期的只能识别指定的印刷体数字、英文字母和部分符号发展成为可以自动进行版面分析、表格识别实现混合文字、多字体、多字号、横竖混排识别的强大的计算机信息快速录入工具。对印刷体汉字的识别率达到98以上 即使对印刷质量较差的文字其识别率也达到95以上。可识别宋体、黑体、楷体、仿宋体等多种字体的简、繁体并且可以对多种字体、不同字号混合排版进行识别对手写体汉字的识别率达到70以上。特别是我国的汉字OCR技术经过十几年的努力克服了起步晚、汉字字符集异常庞大等困难单字的识别速度(指在单位时间内所完成的从特征提取到识别结果输出的字数)可以达到70字秒以上。 由于印刷体O CR汉字识别技术已经比较成熟所以OCR产品被广泛地应用在新闻、印刷、 出版、 图书馆、办公自动化等各个行业。
专业型OCR产品多是面向特定的行业 即适用于每天需处理大量表格信息录入的部门如邮政、税务、海关、统计等等。这种面向特定行业的专业型OCR系统格式较为固定识别的字符集相对较小经常与专用的输入设备结合使用 因此具有速度快、效率高等特点 比如邮件自动分拣系统等。
手写文稿的识别直到1996、 1997年才开始有产品问世而且是作为印刷文稿识别产品的一项附加功能提供的。 由于人写字的习惯千差万别实现自由手写体识别相当困难所以手写体OCR技术的使用领域是联机手写体识别 即人一边写计算机一边识别是一种实时识别方式。
二、 OCR的基本原理
简单地说 O CR的基本原理就是通过扫描仪将一份文稿的图像输入给计算机然后由计算机取出每个文字的图像并将其转换成汉字的编码。其具体工作过程是扫描仪将汉字文稿通过电荷耦合器件CCD将文稿的光信号转换为电信号经过模拟数字转换器转化为数字信号传输给计算机。计算机接受的是文稿的数字图像其图像上的汉字可能是印刷汉字也可能是手写汉字然后对这些图像中的汉字进行识别。对于印刷体字符首先采用光学的方式将文档资料转换成原始黑白点阵的图像文件再通过识别软件将图像中的文字转换成文本格式 以便文字处理软件的进一步加工。其中文字识别是O CR的重要技术。
1 OCR识别的两种方式
与其它信息数据一样在计算机中所有扫描仪捕捉到的图文信息都是用0、 1这两个数字来记录和进行识别的所有信息都只是以0、 1保存的一串串点或样本点。OCR识别程序识别页面上的字符信息主要通过单元模式匹配法和特征提取法两种方式进行字符识别。
单元模式匹配识别法(Pattern Matc hing)是将每一个字符与保存有标准字体和字号位图的文件进行不严格的比较。如果应用程序中有一个已保存字符的大数据库则应用程序会选取合适的字符进行正确的匹配。软件必须使用一些处理技术找出最相似的匹配通常是不断试验同一个字符的不同版本来比较。有些软件可以扫描一页文本并鉴别出定义新字体的每一个字符。有些软件则使用自己的识别技术尽其所能鉴别页面上的字符然后将不可识别的字符进行人工选择或直接录入。特征提取识别法(Feature Extraction)是将每个字符分解为很多个不同的字符特征包括斜线、水平线和曲线等。然后又将这些特征与理解(识别)的字符进行匹配。举个简单的例子应用程序识别到两条水平横线它就会“认为”该字符可能是
“二”。特征提取法的优点是可以识别多种字体例如中文书法体就是采用特征提取法实现字符识别的。
多数OCR应用软件都加入了语法智能检查功能这种功能进一步提高了识别率。它主要通过上下文检查法实现拼写和语法的纠正在文字识别时 O CR应用程序会做多次的上下文衔接性检查根据程序中已经存在的词组、 固定的用词顺序对应的检查字符串的用词字。 比较高级的应用软件会自动用它“认为”正确的词语替换错误词语纠正语句意思。
2文字识别的几个步骤
文字识别包括以下几个步骤 图文输入、预处理、单字识别和后处理等。
1图文输入
是指通过输入设备将文档输入到计算机中也就是实现原稿的数字化。现在用得比较普遍的设备是扫描仪。文档图像的扫描质量是OCR软件正确识别的前提条件。恰当地选择扫描分辨率及相关参数是保证文字清楚、特征不丢失的关键。此外文档尽可能地放置端正 以保证预处理检测的倾斜角小在进行倾斜校正后文字图像的变形就小。这些简单的操作会使系统的识别正确率有所提高。反之由于扫描设置不当文字的断笔过多可能会分检出半个文字的图像。文字断笔和笔画粘连会造成有些特征丢失在将其特征与特征库比较时会使其特征距离加大识别错误率上升。
2预处理
扫描一幅简单的印刷文档的图像将每一个文字图像分检出来交给识别模块识别这一过程称为图像预处理。预处理是指在进行文字识别之前的一些准备工作包括图像净化处理去掉原始图像中的显见噪声(干扰)。主要任务是测量文档放置的倾斜角对文档进行版面分析对选出的文字域进行排版确认对横、竖排版的文字行进行切分每一行的文字图像的分离标点符号的判别等。这一阶段的工作非常重要处理的效果直接影响到文字识别的准确率。
版面分析是对文本图像的总体分析是将文档中的所有文字块分检出来区分出文本段落及排版顺序 以及图像、表格的区域。将各文字块的域界(域在图像中的始点、终点坐标)域内的属性(横、竖排版方式)以及各文字块的连接关系作为一种数据结构提供给识别模块自动识别。对于文本区域直接进行识别处理对于表格区域进行专用的表格分析及识别处理对于图像区域进行压缩或简单存储。行字切分是将大幅的图像先切割为行再从图像行中分离出单个字符的过程。
3单字识别
单字识别是体现OCR文字识别的核心技术。从扫描文本中分检出的文字图像 由计算机将其图形、 图像转变成文字的标准代码是让计算机“认字”的关键也就是所谓的识别技术。就像人脑认识文字是因为在人脑中已经保存了文字的各种特征如文字的结构、文字的笔画等。要想让计算机来识别文字也需要先将文字的特征等信息储存到计算机里但要储存什么样的信息及怎样来获取这些信息是一个很复杂的过程而且要达到非常高的识别率才能符合要求。通常采用的做法是根据文字的笔画、特征点、投影信息、点的区域分布等进行分析。
中国汉字常用的就有几千识别技术就是特征比较技术通过和识别特征库的比较找到特征最相似的字提取该文字的标准代码 即为识别结果。 比较是人们认识事物的一种基本方法汉字识别也是通过比较找出汉字之间的相同、相似、相异把握其量和质的关系 以及时间与空间的关系等。对于大字符集的汉字一般采用多级分类多特征、全方位动态匹配求相似集 以保证分类率高、适应性强、稳定性好细分类重点在于对相似集求异匹配、加权处理、结构判别定量、定性分析 以及前后联接词的关系最后进行判别。汉字识别实质上是比较科学或认知科学在人工智能方面的应用其关键技术是识别特征库。计算机有了这样的一个特征库才能完成认字的功能。
在图像文档的版面中除了有文字、 图片有时还会有表格存在为了使识别后的表格数字化需要在版面分析过程中对表格域进行特殊的处理它包括对表格线的结构信息的提取对表格内文字域的分检完成对表格线和对文字域的识别并根据表格线的数字化生成不同的文件格式。 由于文档中的表格随意性大格式多样有封闭式的也有开放式的特别是表格中的斜线给表格分析造成一定的困难。
4后处理
后处理是指对识别出的文字或多个识别结果采用词组方式进行上下匹配 即将单字识别的结果进行分词与词库中的词组进行比较 以提高系统的识别率减少误识率。
汉字字符识别是文字识别领域最为困难的问题它涉及模式识别、 图像处理、数字信号处理、 自然语言理解、人工智能、模糊数学、信息论、计算机、 中文信息处理等学科是一门综合性技术。近几年来 印刷汉字识别系统的单字识别正确率已经超过95为了进一步提高系统的总体识别率扫描图像、 图像的预处理以及识别后处理等方面的技术也都得到了深入的研究并取得了长足的进展有效地提高了印刷汉字识别系统的总体性能。清华大学在此方面的研究成果突出 已经成为世界上的最具权威的机构之一。 目前清华紫光的全系列扫描仪中都配装了清华OCR千禧版软件它在识别率、表格识别甚至规范手写体的识别方面均达到了较高水平。
三、 OCR文字识别技巧
在最近几年中 OCR识别技术随着扫描仪的普及得到了飞速的发展扫描、识别软件的性能不断强大并向智能化不断升级发展。但是要想快速地获取正确的扫描结果得到高效率的文字录入必须认真学习有关知识结合实践经验摸索出自己的全套解决方案。有时我们在作文字识别工作时识别率非常低根本达不到软件所说的95以上请先不要责怪硬件或软件其实这是没有掌握好扫描及OCR识别技巧的原因。
下面是文字识别操作中经常用到了一些方法和技巧。
1分辨率的设置是文字识别的重要前提。一般来讲扫描仪提供较多的图像信息识别软件比较容易得出识别结果。但也不是扫描分辨率设得越高识别正确率就越高。选择300dpi或400dpi分辨率适合大部分文档扫描。注意文字原稿的扫描识别设置扫描分辨率时千万不要超过扫描仪的光学分辨率不然会得不偿失。下面是部分典型设置仅供参考。
(1)1、 2、 3号字的文章段推荐使用200dpi。
(2)4、小4、 5号字的文章段推荐使用300dpl
(3)小5、 6号字的文章段推荐使用400dpl
(4)7、 8号字的文章段推荐使用600dpi。
2.扫描时适当地调整好亮度和对比度值使扫描文件黑白分明。这对识别率的影响最为关键扫描亮度和对比度值的设定以观察扫描后的图像中汉字的笔画较细但又不断开为原则。进行识别前先看看扫描得到的图像中文字质量如何如果图像
存在黑点或黑斑时或文字线条很粗很黑分不清笔画时说明亮度值太小了应该增加亮度值在试试如果文字线条凹凸不平有断线甚至图像中汉字轮廓严重残缺时说明亮度值太大了应减小亮度后再试试。
3选好扫描软件。选一款好的适合自己的OCR软件是作好文字识别工作的基础一般不要使用扫描仪自带的OEM软件 OEM的OCR软件的功能少、效果差有的甚至没有中文识别经过比较我认为清华紫光O CR2003专业版和尚书OCR6.0文本自动识别输入系统的识别能力与使用功能更突出一些。再选一个图像软件 OCR软件不是有扫描接口吗为什么还找图像软件第一 OCR软件不能识别所有的扫描仪第二也是最关键的利用图像软件的扫描接口扫描出来的图像便于处理一般选用PHO TO SHOP。
4如果要进行的文本是带有格式的如粗体、斜体、首行缩进等部分OCR软件识别不出来会丢失格式或出现乱码。如果必须扫描带有格式的文本事先要确保使用的识别软件是否支持文字格式的扫描。也可以关闭样式识别系统使软件集中注意力查找正确的字符不再顾及字体和字体格式。
- 识别扫描文字结果以图片格式(.bmp)存入电脑然后使用ORC识别系统进行转换最终用WORD进行修改编辑相关文档
- 识别orc识别
- 汉王orc识别
- "中国声谷"智能+应用场景"技术和产品指导目录",,,,,
- 公告orc识别
- 投标orc识别
- 系统orc识别
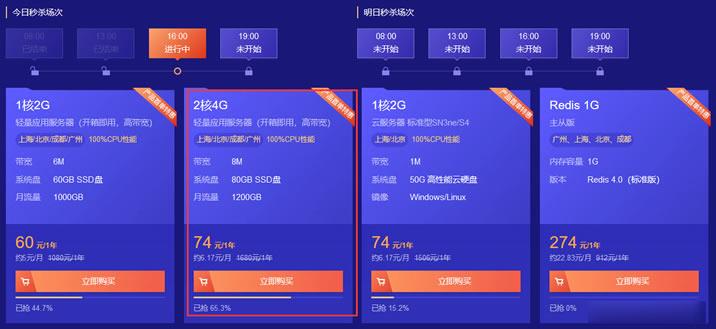
腾讯云轻量服务器两款低价年付套餐 2核4GB内存8M带宽 年74元
昨天,有在"阿里云秋季促销活动 轻量云服务器2G5M配置新购年60元"文章中记录到阿里云轻量服务器2GB内存、5M带宽一年60元的活动,当然这个也是国内机房的。我们很多人都清楚备案是需要接入的,如果我们在其他服务商的域名备案的,那是不能解析的。除非我们不是用来建站,而是用来云端的,是可以用的。这不看到其对手腾讯云也有推出两款轻量服务器活动。其中一款是4GB内存、8M带宽,这个比阿里云还要狠。这个真...
日本CN2、香港CTG(150元/月) E5 2650 16G内存 20M CN2带宽 1T硬盘
提速啦简单介绍下提速啦 是成立于2012年的IDC老兵 长期以来是很多入门级IDC用户的必选商家 便宜 稳定 廉价 是你创业分销的不二之选,目前市场上很多的商家都是从提速啦拿货然后去分销的。提速啦最新物理机活动 爆炸便宜的香港CN2物理服务器 和 日本CN2物理服务器香港CTG E5 2650 16G内存 20M CN2带宽 1T硬盘 150元/月日本CN2 E5 2650 16G内存 20M C...

数脉科技:阿里云香港CN2线路服务器;E3-1230v2/16G/240G SSD/10Mbps/3IP,月付374元
数脉科技怎么样?昨天看到数脉科技发布了7月优惠,如果你想购买香港服务器,可以看看他家的产品,性价比还是非常高的。数脉科技对香港自营机房的香港服务器进行超低价促销,可选择10M、30M的优质bgp网络。目前商家有优质BGP、CN2、阿里云线路,国内用户用来做站非常不错,目前E3/16GB阿里云CN2线路的套餐有一个立减400元的优惠,有需要的朋友可以看看。点击进入:数脉科技商家官方网站香港特价阿里云...

-
汉语163支付apple导致卡巴斯基contentgooglecontentcss支持ipadxp如何关闭445端口请大家帮帮忙,怎样关闭135和445端口?netbios端口netbios ssn是什么意思?netbios端口26917 8000 4001 netbios-ns 端口 是干什么的traceroute网络管理工具traceroute是什么程序