爬虫基于python的网络爬虫设计
基于pthon的网络爬虫设计
【摘要】近年来随着网络应用的逐渐扩展和深入,如何高效的获取网上数据成为了无数公司和个人的追求,在大数据时代,谁掌握了更多的数据谁就可以获得更高的利益而网络爬虫是其中最为常用的一种从网上爬取数据的手段。
网络爬虫 即WbSpi r,是一个很形象的名字。如果把互联网比喻成一个蜘蛛网,那么Spie就是在网上爬来爬去的蜘蛛。网络蜘蛛是通过网页的链接地址来寻找网页的。从网站某一个页面(通常是首页)开始读取网页的内容找到在网页中的其它链接地址,然后通过这些链接地址寻找下一个网页这样一直循环下去直到把这个网站所有的网页都抓取完为止。如果把整个互联网当成一个网站,那么网络蜘蛛就可以用这个原理把互联网上所有的网页都抓取下来。
那么既然网络爬虫有着如此先进快捷的特点,我们该如何实现它呢?在众多面向对象的语言中,首选yt 因为yt hon是一种“解释型的、面向对象的、带有动态语义的”高级程序,可以使人在编程时保持自己的风格,并且编写的程序清晰易懂,有着很广阔的应用前景。
关键词 yhon 爬虫 数据
1 前言
. 本编程设计的目的和意义
随着网络的迅速发展万维网成为大量信息的载体,如何有效地提取并利用这些信息成为一个巨大的挑战。搜索引擎(例如传统的通用搜索引擎A ta ta ahoo!和Goole等)作为一个辅助人们检索信息的工具成为用户访问万维网的入口和指南。但是,这些通用性搜索引擎也存在着一定的局限性如 ( )不同领域、不同背景的用户往往具有不同的检索目的和需求,通用搜索引擎所返回的结果包含大量用户不关心的网页。 (2)通用搜索引擎的目标是尽可能大的网络覆盖率有限的搜索引擎服务器资源与无限的网络数据资源之间的矛盾将进一步加深。 (3 万维网数据形式的丰富和网络技术的不断发展图片、数据库、音频视频多媒体等不同数据大量出现,通用搜索引擎往往对这些信息含量密集且具有一定结构的数据无能为力,不能很好地发现和获取。 (4) 通用搜索引擎大多提供基于关键字的检索,难以支持根据语义信息提出的查询。 为了解决上述问题,定向抓取相关网页资源的聚焦爬虫应运而生。聚焦爬虫是一个自动下载网页的程序,它根据既定的抓取目标有选择的访问万维网上的网页与相关的链接,获取所需要的信息。与通用爬虫geeralpurpo e eb rwle 不同,聚焦爬虫并不追求大的覆盖,而将目标定为抓取与某一特定主题内容相关的网页,为面向主题的用户查询准备数据资源。
1 编程设计目及思路
1.2. 1编程设计目的
学习了解并熟练掌握 thn的语法规则和基本使用,对网络爬虫的基础知识进行了一定程度的理解,提高对网页源代码的认知水平学习用正则表达式来完成匹配查找的工作,了解数据库的用途学习onob数据库的安装和使用及配合 hn的工作。
1.2 2设计思路
1)以世纪佳缘网为例,思考自己所需要的数据资源,并以此为基础设计自己的爬虫程序。2)应用pythn伪装成浏览器自动登陆世纪佳缘网,加入变量打开多个网页。
3)通过pthon的rl ib函数进行世纪佳缘网源代码的获取。
4)用正则表达式分析源代码,找到所需信息导入excel。
5)连接数据库将爬下的数据存储在数据库中。
1 3本编程设计应达到的要求
、对特定的网站爬取特定的数据;
2、实现代码和得到结果;
3、能够和数据库进行连接,将爬下的数据存储在数据库中。
4、将爬下的数据储存在exel中方便编辑。
2 编程设计方案
. 1爬取方案
. 1所需爬取的数据
以世纪佳缘网为例,所需要爬取的数据为注册世纪佳缘网的人的用户名、真实姓名、性别、年龄、学历、月收入这些直观信息。
. 2用ython获取世纪佳缘网的源代码
爬虫最主要的处理对象就是UL它根据RL地址取得所需要的文件内容然后对它进行进一步的处理。因此,准确地理解URL对理解网络爬虫至关重要。
R是URI的一个子集。它是n for Resource Lcator的缩写译为“统一资源定位符”。
通俗地说 UR是I e et上描述信息资源的字符串主要用在各种W客户程序和服务器程序上。采用URL可以用一种统一的格式来描述各种信息资源,包括文件、服务器的地址和目录等。 UR的格式由三部分组成:
①第一部分是协议(或称为服务方式。
②第二部分是存有该资源的主机I地址(有时也包括端口号。
③第三部分是主机资源的具体地址,如目录和文件名等。
第一部分和第二部分用“:/ ”符号隔开,
第二部分和第三部分用“/”符号隔开。
第一部分和第二部分是不可缺少的第三部分有时可以省略。
例如:其计算机域名为超级文本文件(文件类型为.hl是在目录/alk下的ak .h。这是瑞得聊天室的地址可由此进入瑞得聊天室的第1室。
yhon获取网页源代码可用ur 或u l ib函数进行极其方便快捷,代码如下imort u i2res s ur lib2 rlo n(' ' )
tml = eson . ead()
r nt html
2 1.3应用pthn伪装成浏览器自动登陆世纪佳缘网,加入变量打开多个网页。
有了源代码就可以进行数据的爬取了,但是因为世纪佳缘网近日进行了改版简单的爬虫程序已经无法在对其进行全网页的爬取工作了所以,在获取数据之前,需要对爬虫进行一下伪装,使其成为一个浏览器 以实现全网页的爬取工作。
应用 ene 和h er的基础知识即可实现伪装成浏览器这一步骤。在
伪装的同时需要加入变量来打开多个网页,是的爬取工作可以顺利进行。代码如下:
=0 w 013 hil 3012<w<99 9 =w+ k=str(w) logic = cokie .Cook Jar ) opener=urllib2. uild_oe r(r ib2.HTT ie oce or( j) )opener adh der = [ (' er-agen ' , Mzil a4 0 copt le; MS E 6. Windos NT 5. 1 ' ) data u ll .u lencode( {"am ":"8340549 q. m "passwor": b be 2 } pen .open lo npage ataop=o .oen(()
2. 4用正则表达式分析网页源代码
正则表达式是用于处理字符串的强大工具,它并不是yh 的一部分。其他编程语言中也有正则表达式的概念,区别只在于不同的编程语言实现支持的语法数量不同。它拥有自己独特的语法以及一个独立的处理引擎,在提供了正则表达式的语言里,正则表达式的语法都是一样的。
下图为使用正则表达式进行匹配的流程
正则表达式的大致匹配过程是:
1.依次拿出表达式和文本中的字符比较,
2.如果每一个字符都能匹配,则匹配成功一旦有匹配不成功的字符则匹配失败。
3.如果表达式中有量词或边界,这个过程会稍微有一些不同。
n是通过re模块实现对正则表达式的调用的。程序代码如下:fid_ =r . ompile " bslute.+? pan.*?</+?&g ;></a> * )</h >.+ />(. ?)</s.?/b *?)</ +/b>(.* )</p ?</b>(.*?)sp.+?/>", .DTL)
. 存储方案
2.2 1储存在ec l表格中
Exc l表格具有方便筛选、查找和编辑的特点,所以将网络爬虫爬取的数据储存在exce表格中是首选。
使用pyton建立xcel表格是十分容易代码如下
= xlw .Wrbok )she t = ( ae'
建立完成后可将数据写入ecel表格fr in
sh et.w ite(r, ,a .d code("ut " )seet i e(r, a[1 . cd ( tf-8") ) heet.w ite(r, [ ] .d cd ("ut - ) ) seet rit , a 3 .dc "ut -") ) ee .writ (r,4 a[4] . eoe("utf-8") )shet.w te( , , [ . ecoe "uf-8") )r=r+ print +301
(' test3 '
. . 储存在数据库中
数据库指的是以一定方式储存在一起、能为多个用户共享、具有尽可能小的冗余度、与应用程序彼此独立的数据集合。将数据储存在数据库中也具有直观简洁的特点。
Pyh 调用数据库是用pyog模块,创建与导入代码如下d = pym o.Connecti ) . for a :v lues=di ( mg=a[0] decd "t -8") , infora[1] .de de( u -8") ae=a[2 .decod "utf-8") ,are .decode("ut "mrry=a 4] decde( t -8")
) d.u r ins rt {'values au s )
on t us r f d( a n :pr nt img: +a[0 .decod ( ut -8" p n inor [1 d de( utf-8")print 'a : '+a[2 d cod "u - " pr nt ' dess +a deco "ut -8 ) prit 'mr '+a[] .d od ("tf-8"
3、总结
本程序利用了p on语言编写网络爬虫程序实现了从世纪佳缘网上爬取用户数据资料使用u lib函数以及r模块、 ymong模块进行源代码的获取、编辑和数据的导出,并针对网页代码中无性别显示的问题,采取爬取注册用户信息同时爬取注册用户照片地址的方式解决浏览所爬取信息时只需将照片地址输入浏览器地址栏 即可得到所查看用户上传的自拍照,得到形象信息。总的来说程序设计简便、实用性强、便于读取和再利用。
4、附录
. 1将爬取数据储存在excel表格
4 1. 1 源代码
#cod g=gbi rt r impor w imp rt ook e ib orturll ,urllib
xlwt.Worbo ()sh et = ('name' f nre=re.cmp l ( "aso ute +?span>(.* )</.?&t;>/a>(.* )/2>.?/b>.?)/s.+/b>.?)</s.+?</b>( *?)<sp.+?</b>(.*?)<sp +?<b", r .DOTALL) rw=013 while 30 <999: w=1 st w)log n_p = "" j = ook li.C i r(
pe r=rl ib uil_opener(u l ib.HTPookieProes r( j) ) op r.addhaer = [ ( s rg t , ' illa/4 comp tib e; 6 0; Winows NT
5 1) ) ] data = ur lib r ecde( {"name :"834 496@q.cm", assord": beb 12" opene .op logi=op.rea )x=finre.finall (html) frain x: heetw ite , .decod ("tf-8" seet.w i e( , 1,a 1] .d ode "u 8 ) )
he t. ite(r,2, [ .decode( ut -8") ee wri e ,a[3] .decod "uf-8" )
ee .rite(r,4,a[4] . code("ut - " ) heet.writ (r,5,a[ ] .d coe( utf " ) rr+1rint +3012 (' te t3. l ' )
4. 1. 爬取数据汇总截图
4.2将爬取数据写入数据库
4. 1 源代码
#odig=gbk mport r l i impor e mp ymogodb = pmogo.onec io ) te f idr = e.cmpiler"abso t .+ spn>(* )/.?gt;g ;</>.*?</h>.+/b( ?)</ +?<b>(.* ) s+?</>(.* )/sp?b ,r .DOTALL) w=11 wh le <w< w=1k t ()pageu l b r open( = h_v2_indx") ml=p ea (
x=f nd_r .find ll (tl) for a n x:valu sdic ( im=a[0] de ode("utf- " , nfora[1 . eco e("utf-8" ,gea[2] . e("tf-8" , are s=a[3 .de o ("utf-8 , marry= [4] .dec e " -8")
db. s ise t('v lu s :value } ) nten = b.u er.find() or a in x p int ' im : '+ [0] .dcde uf8")prin ' nfr: 'a[1 .de oe("utf8")print ae: ' [2 .decode "uf-8 ) pr nt dress 'a 3] . eco ("tf-" prit 'ry: 'a 4] .dco ("tf-8 )
4 爬取数据汇总截图
参考文献
1 Gu do v rs um 《Py o手册》
2 Manus L e H lar 《 thon基础教程》
3罗刚,王振东 《自己动手写网络爬虫》
DMIT(季度$28.88)调整洛杉矶CN2 GIA优化端口
对于DMIT商家已经关注有一些时候,看到不少的隔壁朋友们都有分享到,但是这篇还是我第一次分享这个服务商。根据看介绍,DMIT是一家成立于2017年的美国商家,据说是由几位留美学生创立的,数据中心位于香港、伯力G-Core和洛杉矶,主打香港CN2直连云服务器、美国CN2直连云服务器产品。最近看到DMIT商家有对洛杉矶CN2 GIA VPS端口进行了升级,不过价格没有变化,依然是季付28.88美元起。...

hostyun评测香港原生IPVPS
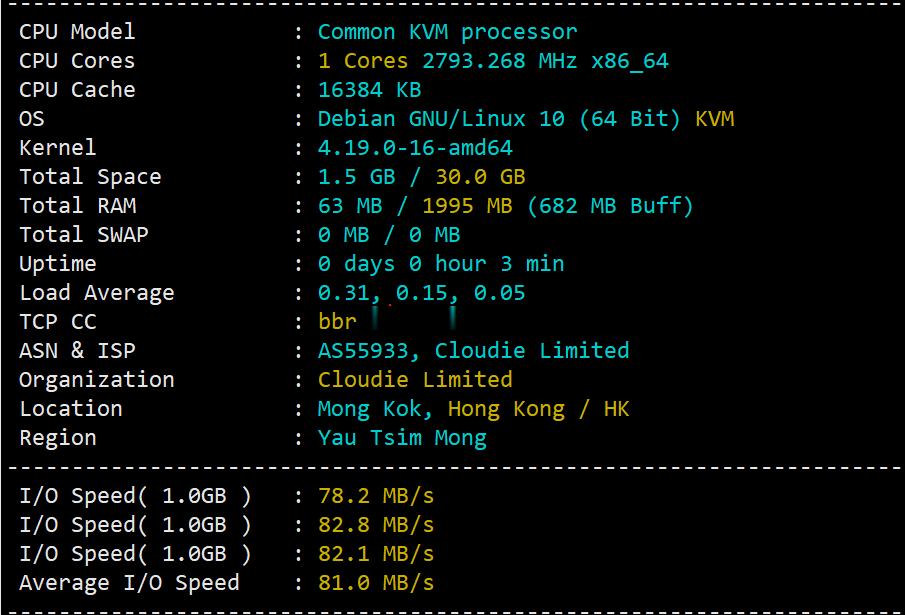
hostyun新上了香港cloudie机房的香港原生IP的VPS,写的是默认接入200Mbps带宽(共享),基于KVM虚拟,纯SSD RAID10,三网直连,混合超售的CN2网络,商家对VPS的I/O有大致100MB/S的限制。由于是原生香港IP,所以这个VPS还是有一定的看头的,这里给大家弄个测评,数据仅供参考!9折优惠码:hostyun,循环优惠内存CPUSSD流量带宽价格购买1G1核10G3...
收到几个新商家投稿(HostMem,无忧云,青云互联,TTcloud,亚洲云端,趣米云),一起发布排名不分先后
7月份已经过去了一半,炎热的夏季已经来临了,主机圈也开始了大量的夏季促销攻势,近期收到一些商家投稿信息,提供欧美或者亚洲地区主机产品,价格优惠,这里做一个汇总,方便大家参考,排名不分先后,以邮件顺序,少部分因为促销具有一定的时效性,价格已经恢复故暂未列出。HostMem部落曾经分享过一次Hostmem的信息,这是一家提供动态云和经典云的国人VPS商家,其中动态云硬件按小时计费,流量按需使用;而经典...

-
特朗普吐槽iPhone为什么iphone x卖的这么好重庆网站制作重庆网站制作哪家好,重庆做网站制作的公司有谁比较了解的,应该去哪里做好些?ipad代理想买个ipad,3000至4000元左右有什么好的易名网易名网交易域名是怎么收费的科创板首批名单首批公布的24个历史文化明城是那些12306.com如何登录12306curl扩展如何增加mysqli扩展瑞东集团福能集团是一个什么企业?三五互联科技股份有限公司厦门三五互联科技股份有限公司 怎么样?可信网站可信网站认证一定要办吗