字节UTF到Unicode的编码转换(DOC X页)
UTF-8就是Unicode Transformation Format-8是Unicode的一种变换编码格式。
UTF-8有以下特性:
UCS字符U+0000到U+007F(ASCII)被编码为字节0x00到0x7F(ASCII兼容).这意味着只包含7位ASCII字符的文件在ASCII和UTF-8两种编码方式下是一样的.
所有>U+007F的UCS字符被编码为一个多个字节的串,每个字节都有标记位集.因此,ASCII字节(0x00-0x7F)不可能作为任何其他字符的一部分.
表示非ASCII字符的多字节串的第一个字节总是在0xC0到0xFD的范围里,并指出这个字符包含多少个字节.多字节串的其余字节都在0x80到0 xBF范围里.这使得重新同步非常容易,并使编码无国界,且很少受丢失字节的影响.
可以编入所有可能的231个UC S代码
UTF-8编码字符理论上可以最多到6个字节长,然而16位B MP字符最多只用到3字节长.
Bigendian UCS-4字节串的排列顺序是预定的.
字节0xFE和0xFF在UTF-8编码中从未用到.
下列字节串用来表示一个字符.用到哪个串取决于该字符在Unicode中的序号.
U-00000000 - U-0000007F: 0xxxxxxx
U-00000080 - U-000007FF: 110xxxxx 10xxxxxx
U-00000800 - U-0000FFFF: 1110xxxx 10xxxxxx 10xxxxxx
U-00010000 - U-001FFFFF: 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx
U-00200000 - U-03FFFFFF: 111110xx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx
U-04000000 - U-7FFFFFFF: 1111110x 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx10xxxxxx从上表还可以看出 UTF-8每个编码字符都不可能以“10”开头 “10”是以连接符的形式出现在后面的编码字节开头。因此UTF-8编码在存储和传输时是不容易出错的。
下面是UTF-8到Unicode的编码转换代码(J2 ME环境下的实现)UTFC2UniC方法包含了编码转换逻辑。/**
*将UTF-8字节数据转化为Unicode字符串
*@p aram ut f_data b yte[] -U TF-8编码字节数组
*@param len int -字节数组长度
*@return String-变换后的Unicode编码字符串
*/pub lic static String UTF2Uni(byte[]utf_data, int len){
StringBuffer unis=new StringBuffer();char unic=0;int ptr=0;int c ntB its=0;fo r(;p tr<len;)
{cntB its=getC ntB its(ut f_da ta[ptr]);if(c ntB its==-1)
{
++ptr;c o nt inue;
}elseif(c ntB its==0)
{unic=UTFC2UniC(utf_data,ptr,cntB its);
++ptr;
}else
{unic=UTFC2UniC(utf_data,ptr,cntB its);ptr+=cntBits;
}unis.appe nd(unic);
}return unis.to S tring();
}
/**
*将指定的UTF-8字节组合成一个Unicode编码字符
*@p aram ut f b yte[] -UTF-8字节数组
*@param sptr int -编码字节起始位置
*@param cntB its int -编码字节数
*@return char-变换后的Unicode字符
*/pub lic static char UTFC2UniC(byte[]utf, int sptr, int cntBits)
{
/*
Unicode<->UTF-8
U-00000000-U-0000007F: 0 xxxxxxx
U-00000080-U-000007FF: 110xxxxx 10 xxxxxx
U-00000800-U-0000FFFF: 1110xxxx 10xxxxxx 10xxxxxx
U-00010000-U-001 FFFFF: 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx
U-00200000-U-03FFFFFF: 111110xx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx
U-04000000-U-7FFFFFFF: 1111110x 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx
*/int uniC=0; // repre sent the unicode charbyte firstByte=utf[sptr];int ptr=0; // po inter 0~15
//resolve single byte UTF-8 encoding charif(c ntB its==0)return(c har)fir stByte;
//re so lve the first bytefirs tB yte&=(1<<(7-c nt B its)) - 1;
//resolve multiple bytes UTF-8 encoding char(except the first byte)fo r(int i=sptr+c ntB its - 1; i>sp tr; --i)
{byte utfb=utf[i];uniC|=(utfb&0x3 f)<<ptr;ptr+=6;
}uniC|=fir stB yte<<p tr;return(c har)uniC;
}
//根据给定字节计算UTF-8编码的一个字符所占字节数
//UTF-8规则定义字节标记只能为0或2~6
private static int getCntBits(byte b)
{int cnt=0;i f(b==0)re t ur n-1;for(int i=7; i>=0; --i)
{if(((b>>i)&0x1)==1)
++cnt;elseb re ak;
}return(cnt>6| |cnt==1)?-1 :cnt;
}
参考资料
《UTF-8 and Unicode FAQ》——http://www.linuxforum.net/books/UTF-8-Unicode.html
- 字节UTF到Unicode的编码转换(DOC X页)相关文档
- 函数unicode编码转换
- 汉字unicode编码转换
- 编码unicode编码转换
- 转换unicode编码转换
- 转换为unicode编码转换
- 编码高效Unicode_GB编码转换算法的设计和实现
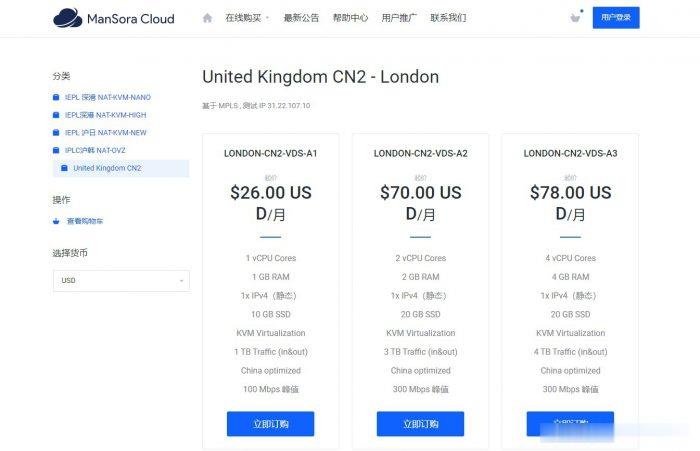
ManSora:英国CN2 VPS,1核/1GB内存/10GB SSD/1TB流量/100Mbps/KVM,$18.2/月
mansora怎么样?mansora是一家国人商家,主要提供沪韩IEPL、沪日IEPL、深港IEPL等专线VPS。现在新推出了英国CN2 KVM VPS,线路为AS4809 AS9929,可解锁 Netflix,并有永久8折优惠。英国CN2 VPS,$18.2/月/1GB内存/10GB SSD空间/1TB流量/100Mbps端口/KVM,有需要的可以关注一下。点击进入:mansora官方网站地址m...
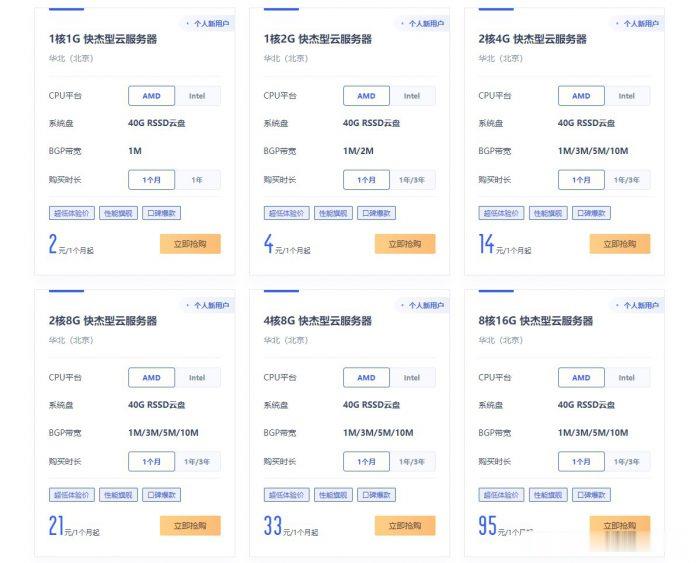
ucloud国内云服务器2元/月起;香港云服务器4元/首月;台湾云服务器3元/首月
ucloud云服务器怎么样?ucloud为了扩大云服务器市场份额,给出了超低价云服务器的促销活动,活动仍然是此前的Ucloud全球大促活动页面。目前,ucloud国内云服务器2元/月起;香港云服务器4元/首月;台湾云服务器3元/首月。相当于2-4元就可以试用国内、中国香港、中国台湾这三个地域的云服务器1个月了。ucloud全球大促仅限新用户,国内云服务器个人用户低至56元/年起,香港云服务器也仅8...
BuyVM($5/月)不限流量流媒体优化VPS主机 1GB内存
BuyVM商家属于比较老牌的服务商,早年有提供低价年付便宜VPS主机还记得曾经半夜的时候抢购的。但是由于这个商家风控非常严格,即便是有些是正常的操作也会导致被封账户,所以后来陆续无人去理睬,估计被我们风控的抢购低价VPS主机已经手足无措。这两年商家重新调整,而且风控也比较规范,比如才入手他们新上线的流媒体优化VPS主机也没有不适的提示。目前,BuyVM商家有提供新泽西、迈阿密等四个机房的VPS主机...
-
香港iphoneaccessdenied上网时电脑上显示access denied 是怎么回事重庆电信断网为什么重庆电信沙坪坝天星桥这网络老是掉线googlepr值如何提高Google PR值?163yeahyeah邮箱和163邮箱的区别在哪里 那个好用支持http曲目ios计算机cuteftp工资internal滴滴估值500亿开滴滴怎么才能月入一万,平均一天400纯收入,求指点