命令centos6.5
2019年山东省职业院校技能大赛云计算技术与应用(高职组)赛题库第一部分:IaaS云计算基础架构平台任务一、IaaS云平台搭建基础环境:1.
使用命令行方式设置主机名,防火墙以及SELinux设置如下:(1)设置控制节点主机名controller;计算节点主机名:compute.
(2)各个节点关闭防火墙,设置开机不启动.
(3)设置各个节点selinux状态为permissive.
2.
使用命令查询控制/计算节点的主机名.
3.
使用命令查询控制/计算节点selinux的状态.
4.
在控制节点上通过SecureFX上传两个镜像文件CentOS-7-x86_64-DVD-1511.
iso,XianDian-IaaS-v2.
2.
iso到opt下,使用命令创建/opt下两个目录,并将以上镜像文件分别挂载到上述两个目录下,并使用命令查看挂载的情况(需显示挂载的文件系统类型和具体的大小).
5.
在控制节点上通过SecureFX上传两个镜像文件CentOS-7-x86_64-DVD-1511.
iso,XianDian-IaaS-v2.
2.
iso到opt下,通过命令行创建两个目录,并将以上镜像文件分别挂载到上述两个目录下.
6.
配置控制节点本地yum源文件local.
repo,搭建ftp服务器指向存放yum源路径;配置计算节点yum源文件ftp.
repo使用之前配置的控制节点ftp作为yum源,其中的两个节点的地址使用主机名表示.
使用cat命令查看上述控制/计算节点的yum源全路径配置文件.
7.
在控制节点和计算节点分别安装iaas-xiandian软件包,完成配置文件中基本变量的配置,并根据提供的参数完成指定变量的配置.
Mysql搭建:1.
根据平台安装步骤安装至数据库服务,使用一条命令安装提供的iaas-install-mysql.
sh脚本并查看脚本运行的时间.
2.
使用root用户登录数据库,查询数据库列表信息.
3.
使用root用户登录数据库,使用mysql数据库,查询所有表的信息.
4.
使用root用户登录数据库,使用mysql数据库,查询所有表的信息,并查询表user中的特定的信息.
Keystone搭建:1.
按要求安装完keystone脚本后,在数据库中查询keystone用户的远程访问权限信息.
2.
列出数据库keystone中的所有表.
3.
使用相关命令,查询角色列表信息.
4.
使用相关命令,查询admin项目信息.
5.
使用相关命令,查询用户列表信息.
6.
使用相关命令,查询admin用户详细信息.
7.
使用相关命令,查询服务列表信息.
8.
使用一条命令将keystone的数据库导出为当前路径下的keystone.
sql文件,并使用命令查询文件keystone.
sql的大小.
Glance搭建:1.
根据平台安装步骤安装至镜像服务,在控制节点使用提供的脚本iaas-install-glance.
sh安装glance组件.
使用镜像文件CentOS_7.
2_x86_64_XD.
qcow2创建glance镜像名为CentOS7.
2,格式为qcow2.
2.
使用相关命令查询镜像列表,并查询CentOS7.
2镜像的详细信息.
3.
使用相关命令,在一条命令中查询glance组件中所有服务的状态信息.
Nova搭建:1.
根据平台安装步骤安装至nova计算服务,在控制节点使用提供的脚本iaas-install-nova-controller.
sh、在计算节点使用提供的脚本iaas-install-nova-compute.
sh,安装nova组件.
2.
使用相关命令查询计算节点虚拟机监控器的状态.
3.
使用相关命令查询nova服务状态列表.
4.
使用相关命令查询网络的列表信息.
5.
使用相关命令查询nova资源使用情况的信息.
Neutron搭建:1.
根据平台安装步骤安装至neutron网络服务,在控制节点和计算节点通过提供的neutron脚本,完成neutron服务在控制节点和计算节点的安装,并配置为GRE网络.
2.
根据平台安装步骤安装至neutron网络服务,在控制节点和计算节点通过提供的neutron脚本,完成neutron服务在控制节点和计算节点的安装,并配置为VLAN网络.
3.
使用相关命令查询网络服务的列表信息,并以下图的形式打印出来.
4.
使用相关命令查询网络服务的列表信息中的"binary"一列.
5.
使用相关命令查询网络服务DHCPagent的详细信息.
6.
使用ovs-vswitchd管理工具的相关命令查询计算节点的网桥列表信息.
7.
使用ovs-vswitchd管理工具的相关命令查询控制节点的网桥br-ex的端口列表信息.
8.
创建云主机外部网络ext-net,子网为ext-subnet,云主机浮动IP可用网段为192.
168.
200.
100~192.
168.
200.
200,网关为192.
168.
200.
1.
创建云主机内部网络int-net1,子网为int-subnet1,云主机子网IP可用网段为10.
0.
0.
100~10.
0.
0.
200,网关为10.
0.
0.
1;创建云主机内部网络int-net2,子网为int-subnet2,云主机子网IP可用网段为10.
0.
1.
100~10.
0.
1.
200,网关为10.
0.
1.
1.
添加名为ext-router的路由器,添加网关在ext-net网络,添加内部端口到int-net1网络,完成内部网络int-net1和外部网络的连通.
9.
使用相关命令查询所创建路由器的详细信息.
10.
使用相关命令查询所创建子网的列表信息,并查看内网子网的详细信息.
11.
使用相关命令查询所创建网络的列表信息.
Dashboard搭建:1.
通过脚本iaas-install-dashboard.
sh安装dashboard组件,使用curl命令查询网址http://192.
168.
100.
10/dashboard.
2.
通过脚本iaas-install-dashboard.
sh安装dashboard组件,通过chrome浏览器使用admin账号登录云平台网页,进入管理员菜单中的系统信息页面.
Heat搭建:1.
在控制节点使用提供的脚本iaas-install-heat.
sh安装heat组件.
2.
使用heat相关命令,查询stack列表.
3.
从考试系统下载server.
yml文件,通过命令行使用server.
yml文件创建栈mystack,指定配置参数为镜像CentOS7.
2、网络int-net2.
4.
查询栈mystack状态为CREATE_COMPLETE的事件详细信息.
5.
查询栈mystack的事件列表信息.
Trove搭建:1.
在控制节点配置提供的脚本iaas-install-trove.
sh,使其连接的网络为int-net1,安装数据库trove服务,完成trove服务在控制节点的安装.
完成后查询所有的数据库实例列表.
2.
在控制节点上传提供的MySQL_5.
6_XD.
qcow2到系统内,并创建mysql的数据库存储类型,使用上传的镜像更新该数据库类型的版本信息和镜像信息.
3.
在控制节点查创建名称为mysql-1,大小为5G,数据库名称为myDB、远程连接用户为user,密码为r00tme,类型为m1.
small完成后查询trove列表信息,并查询mysql-1的详细信息.
4.
在控制节点查询所有数据的版本信息,完成后查询mysql数据库的详细信息.
任务二、IaaS云平台运维Rabbitmq运维:1.
按以下配置在云平台中创建云主机,完成本任务下的相关试题后关闭云主机.
云主机:(1)名称:IaaS(2)镜像文件:Xiandian-IaaS-All.
qcow2(3)云主机类型:4cpu、8G内存、100G硬盘(4)网络:网络1:int-net1,绑定浮动IP网络2:int-net2注:该镜像已安装IaaS平台所有可能使用的组件,用于完成IaaS平台相关运维操作题,必须按以上配置信息配置接入两个网络才能保证云主机运行正常.
根据题目要求,连接相应的云主机或各节点服务器,进行以下答题.
2.
使用rabbitmqctl创建用户xiandian-admin,密码为admin.
3.
使用rabbitmqctl命令查询所有用户列表.
4.
使用命令对xiandian-admin用户进行授权,对本机所有资源可写可读权限.
5.
使用rabbitmqctl命令查询集群状态.
6.
使用命令给xiandian-admin用户创建administrator角色,并查询.
7.
使用命令对用户xiandian-admin进行授权,对本机所有资源可写可读权限,然后查询xiandian-admin用户的授权信息.
8.
使用rabbitmqctl命令,查看队列信息,所包含的信息包括name,arguments,messages,memory.
9.
通过修改配置文件的方式修改memcache的缓存大小,使用ps相关命令查询memcahce进程的信息,将修改的配置文件全路径文件名、修改的参数以及相应的参数值、查询memcache进程信息.
10.
构建rabbitmq集群,并对集群进行运维操作.
Mysql运维:1.
使用数据库的相关命令查询数据库的编码方式.
2.
通过mysql相关命令查询当前系统时间.
3.
通过mysql相关命令,查看当前是什么用户.
4.
通过mysql相关命令,查看mysql的默认存储引擎信息,并查看mysql支持的存储引擎有哪些.
5.
进入数据库keystone,通过user表和local_user表做联合更新,u用来做user表别名,lu用来做local_user表别名,sql语句更新neutron用户的enabled状态为0,更新语句中user表在local_user前面.
6.
进入数据库keystone,通过user表和local_user表做联合查询,u用来做user表别名,lu用来做local_user表别名,两表联合查询nova用户的enabled状态,查询语句中user表在local_user前面.
7.
进入数据库,创建本地用户examuser,密码为000000,然后查询mysql数据库中的user表的特定字段.
最后赋予这个用户所有数据库的"查询""删除""更新""创建"的本地权限.
8.
登录iaas云主机,登录mysql数据库,使用keystone数据库,查询本地用户表中的所有信息,并按照id的降序排序.
(关于数据库的命令均使用小写)MongoDB运维1.
登录iaas云主机,登录MongoDB数据库,查看数据库,使用ceilometer数据库,查看此数据库下的集合,并查询此数据库用户,最后创建一个数据库并查询.
2.
登录iaas云主机,登录MongoDB数据库,新建一个数据库,使用这个数据库,向集合中插入数据,最后查询特定的一类数据.
3.
登录iaas云主机,登录MongoDB数据库,新建一个数据库,使用这个数据库,向集合中插入数据,插入完毕后,数据进行修改,修改完后,查询修改完的数据.
4.
登录iaas云主机,登录MongoDB数据库,新建一个数据库,使用这个数据库,向集合中插入数据(其中某一条数据插入两遍),插入数据完毕后,发现某条数据多插入了一遍需要删除,请使用命令删除多余的一行数据,最后将数据库删除.
5.
登录iaas云主机,登录MongoDB数据库,新建一个数据库,使用这个数据库,向集合中插入数据,插入完毕后,查询集合中的数据并按照某关键字的升序排序.
6.
登录iaas云主机,登录MongoDB数据库,新建一个数据库,使用这个数据库,向集合中批量插入多条数据,使用for循环,定义变量i=1,插入"_id":i,"name":"xiaoming","age":"21".
插入数据完毕后,统计集合中的数据条数,然后查询集合中满足特定条件的结果.
7.
登录iaas云主机,使用mongoimport命令,将给定的文件,导入至MongoDB下的相应数据库中的指定集合中.
导入后登录MongoDB数据库.
查询集合中满足特定条件的结果.
注:PPG--场均得分;PTS--总得分;FG%--投篮命中率;3P%--三分命中率;MPG--平均上场时间Keystone运维:1.
在keystone中创建用户testuser,密码为password.
2.
将testuser用户分配给admin项目,赋予用户user的权限.
3.
以管理员身份将testuser用户的密码修改为000000.
4.
通过openstack相关命令获取token值.
5.
使用命令查询认证服务的查询端点信息.
6.
使用命令列出认证服务目录.
7.
在keystone中创建用户testuser,密码为password,创建好之后,使用命令修改testuser密码为000000,并查看testuser的详细信息.
8.
在keystone中创建用户testuser,密码为password,创建好之后,使用命令修改testuser的状态为down,并查看testuser的详细信息.
9.
完成keystone证书加密的HTTPS服务提升.
Glance运维:1.
使用glance相关命令上传CentOS_6.
5_x86_64_XD.
qcow2镜像到云主机中,镜像名为testone,然后使用openstack相关命令,并查看镜像的详细信息.
2.
使用glance相关命令上传两个镜像,一个名字为testone,一个名字叫testtwo,使用相同的镜像源CentOS_6.
5_x86_64_XD.
qcow2,然后使用openstack命令查看镜像列表,接着检查这两个镜像的checksum值是否相同.
3.
登录iaas云主机,使用glance相关命令,上传镜像,源使用CentOS_6.
5_x86_64_XD.
qcow2,名字为testone,然后使用openstack命令修改这个镜像名改为examimage,改完后使用openstack命令查看镜像列表.
4使用glance相关命令,上传镜像,源使用CentOS_6.
5_x86_64_XD.
qcow2,名字为examimage,然后使用openstack命令查看镜像列表,然后给这个镜像打一个标签,标签名字为lastone,接着查询修改的结果.
5.
通过一条组合命令获取镜像列表信息,该组合命令包含:(1)使用curl命令获取镜像列表信息;(2)使用openstack相关命令获取的token值;(3)仅使用awk命令且用"|"作为分隔符获取token具体参数值.
6.
通过一条组合命令获取该镜像详细信息,该组合命令要求:(1)不能使用任何ID作为参数;(2)使用openstack相关命令获取详细信息;(3)使用glance相关命令获取镜像对应关系;(4)仅使用awk命令且用"|"作为分隔符获取ID值.
7.
查看glance配置文件,找到默认的镜像存储目录,进入到存储目录中,使用qemu命令查看任意的一个镜像信息.
Nova运维:1.
修改云平台中默认每个tenant的实例注入文件配额大小,并修改.
2.
通过nova的相关命令创建云主机类型,并查询该云主机的详细信息.
3.
使用nova相关命令,查询nova所有服务状态.
4.
修改云平台中默认每个tenant的实例配额个数并查询.
5.
使用nova相关命令,查询nova所有的监控列表,并查看监控主机的详细信息.
6.
使用grep命令配合-v参数控制节点/etc/nova/nova.
conf文件中有效的命令行覆盖输出到/etc/novaback.
conf文件.
7.
此题可使用物理iaas环境,使用nova相关命令,启动一个云主机,云主机类型使用m1.
small,镜像使用CentOS_6.
5_x86_64_XD.
qcow2,云主机名称为examtest.
8.
此题可使用物理iaas环境,使用openstack相关命令,启动一个云主机,云主机类型使用m1.
small,镜像使用centos6.
5,云主机名称为xxxtest,并使用openstack命令查看此云主机的详细信息.
9.
此题可使用物理环境,登录dashboard界面,创建一台虚拟机,将该虚拟机使用手动迁移的方式,迁移至另一个计算节点并查看.
(controller既是控制也是计算)10.
登录iaas-all云主机,修改nova后端默认存储位置.
11.
修改相应的配置文件,使得openstack云主机的工作负载实现所要求的性能、可靠性和安全性.
12.
配置NFS网络存储作为nova的后端存储.
Cinder运维:1.
使用分区工具,对/dev/vda进行分区,创建一个分区,使用命令将刚创建的分区创建为物理卷,然后使用命令查看物理卷信息.
2.
使用命令查看当前卷组信息,使用命令创建逻辑卷,查询该逻辑卷详细信息.
3.
创建一个卷类型,然后创建一块带这个卷类型标识的云硬盘,查询该云硬盘的详细信息.
4.
通过命令行创建云硬盘,将其设置为只读,查询该云硬盘的详细信息.
5.
通过命令行创建云硬盘,查询该云硬盘的详细信息.
6.
使用命令,对/dev/vda分区,并把这个分区创建成物理卷,然后再把这个物理卷加入到cinder-volumes卷组中,查看卷组详情.
7.
使用命令创建一个云硬盘,然后通过lvm相关命令查看该云硬盘的详细信息,最后通过cinder命令对这块云硬盘进行扩容操作,并查看详细信息.
8.
登录iaas云主机,使用命令对硬盘/dev/vda进行分区,将这个分区创建为物理卷并使用pvs查看,然后将这个物理卷添加到cinder-volumes卷组中并使用vgs查看.
9.
登录controller节点,创建云主机,镜像使用centos6.
5,flavor使用m1.
medium,配置好网络.
然后给云主机iaas挂载一个云硬盘,使用这块云硬盘,把云主机iaas的根目录扩容,最后在iaas云主机上用df-h命令查看.
10.
登录"iaas-all"云主机,使用命令对磁盘/dev/vda进行分区,然后使用命令,创建raid磁盘阵列,最后将md0格式化为ext4格式并查看该磁盘阵列的UUID.
12.
登录"iaas-all"云主机,查看cinder后端存储空间大小,将cinder存储空间扩容10个G大小,最后查看cinder后端存储空间大小.
13.
修改相应的配置文件,增加cinderbackup后端备份.
14.
配置NFS网络存储作为cinder的后端存储.
Swift运维:1.
使用命令查看swift服务状态,然后创建一个容器,并使用命令查看容器列表.
2.
使用swift相关命令,创建一个容器,然后使用命令查看该容器的状态.
3.
使用swift相关命令,查询swift对象存储服务可以存储的单个文件大小的最大值.
4.
使用swift相关命令,创建一个容器,然后往这个容器中上传一个文件(文件可以自行创建),上传完毕后,使用命令查看容器.
5.
登录iaas云主机,使用openstack命令,创建一个容器,并查询,上传一个文件(可自行创建)到这个容器中,并查询.
6.
登录IaaS云主机,创建swifter用户,并创建swift租户,将swifter用户规划到swift租户下,赋予swifter用户使用swift服务的权限,并通过url的方式使用该用户在swift中创建容器.
7.
使用url的方式,用admin账号在swift中创建容器,创建完之后用url的方式查看容器列表.
8.
配置swift对象存储为glance的后端存储,并查看.
KVM运维:1.
在物理云平台查询云主机IaaS在KVM中的真实实例名,在计算节点使用virsh命令找到该实例名对应的domain-id,使用该domain-id关闭云主机IaaS.
2.
在物理云平台查询云主机IaaS在KVM中的真实实例名,在计算节点使用virsh命令找到该实例名对应的domain-id,使用该domain-id重启云主机IaaS.
3.
此题使用物理iaas平台.
登录compute节点,使用命令将KVM进程绑定到特定的cpu上.
4.
此题使用物理平台.
登录controller节点,调优kvm的I/O调度算法,centos7默认的是deadline,使用命令将参数改为noop并查询.
5.
此题使用物理iaas平台.
登录controller节点,使用cat命令,只查看当前系统有多少大页,然后设置大页数量并查看,接着使用命令使配置永久生效,最后将大页挂载到/dev/hugepages/上.
6.
登录192.
168.
100.
10/dashboard,创建一个云主机.
在云主机所在的物理节点,进入virsh交互式界面,调整虚拟机的内存大小,最后使用命令查看该虚拟机的详情.
7.
KVM网络优化:让虚拟机访问物理网卡的层数更少,直至对物理网卡的单独占领,和物理机一样的使用物理网卡,达到和物理机一样的网络性能.
网络运维:1.
在控制节点安装配置JDK环境.
安装完成后,查询JDK的版本信息.
2.
在控制节点安装配置Maven环境.
安装完成后,查询Maven的版本信息.
3.
继续完成OpenDaylight的安装,完成后使用curl命令访问网页http://192.
168.
100.
10:8181/index.
html.
4.
创建网桥br-test,把网卡enp9s0从原网桥迁移到br-test,查询openvswitch的网桥信息和该网桥的端口信息.
5.
创建命名空间ns.
6.
在网桥br-test中创建内部通信端口tap.
7.
在命名空间ns中配置端口tap的地址为172.
16.
0.
10/24.
8.
在命名空间中查询端口tap的地址信息.
9.
通过openvswitch手动运维openstack中虚拟主机的通讯信息.
Ceilometer运维:1.
使用ceilometer相关命令,查询测量值的列表信息.
2.
使用ceilometer相关命令,查询给定名称的测量值的样本列表信息.
3.
使用ceilometer相关命令,查询事件列表信息.
4.
使用ceilometer相关命令,查询资源列表.
5.
按以下提供的参数及其顺序,使用ceilometer相关命令创建一个新的基于计算统计的告警.
以下题目都需在这个基础上完成.
(1)名字为:cpu_hi(2)测量值的名称为:cpu_util(3)阈值为:70.
0(4)对比的方式为:大于(5)统计的方式为:平均值(6)周期为:600s(7)统计的次数为:3(8)转为告警状态时提交的URL为:'log://'(9)关键字:resource_id=INSTANCE_ID6.
使用ceilometer相关命令,查询用户的告警列表信息.
7.
使用ceilometer相关命令,查询给定名称的告警的历史改变信息.
8.
使用ceilometer相关命令,修改给定名称的告警状态为不生效.
9.
使用ceilometer相关命令,删除给定名称的告警,并使用命令查看删除结果.
10.
使用Ceilometer相关命令,查看某云主机有哪些样本,然后使用Ceilometer命令查看云主机的特定样本信息.
Heat运维:1.
使用heat相关命令,查看heat的服务列表信息.
2.
使用heat相关命令,查询给定的详细资源类型信息.
3.
使用heat相关命令,查询heat模板的版本信息.
4.
使用heat相关命令,查询heat最新版本模板的功能列表.
5.
使用提供的文件server.
yml创建名为heat的stack,其中glance镜像使用centos7,网络使用int-net1.
查询stack列表信息.
6.
现有server.
yml文件,请使用该yml文件创建堆栈mystack,指定使用镜像centos6.
5,使用网络int-net1,待创建完成后,查询堆栈mystack的状态为CREATE_COMPLETE的事件信息.
7.
对提供的server.
yml模板进行修改,添加所需参数.
通过命令使用heat模板创建名为test-heat的stack,其中glance镜像使用centos7,网络使用int-net1.
查询stack列表信息.
数据加密:前提:按要求配置静态fixed_key,使cinder和nova组件可以使用加密过的BlockStorage卷服务,配置好之后,创建一个卷类型叫luks,并把这个类型配置为加密类型,cipher使用"aes-xts-plain64",key_size使用"512",control-location使用"front-end",Provider使用"nova.
volume.
encryptors.
luks.
LuksEncryptor".
1.
使用命令查看卷类型列表和加密卷类型列表.
2.
使用命令创建两个卷,前者不加密,后者使用luks卷类型加密.
然后查看卷列表.
3.
使用命令创建两个卷,前者不加密,后者使用luks卷类型加密.
使用nova命令,创建一个云主机,镜像使用提供的cirros镜像,然后使用命令分别将创建的两块云硬盘attach到云主机上,最后使用cinderlist查看.
4.
使用命令创建两个卷,前者不加密,后者使用luks卷类型加密.
使用nova命令,创建一个云主机,镜像使用提供的cirros镜像,然后使用命令分别将创建的两块云硬盘attach到云主机上,最后使用strings命令验证数据卷的加密功能.
负载均衡:1.
安装完neutron网络后,使用neutron命令查询lbaas服务的状态.
(物理环境)2.
使用负载均衡创建nginx资源池,使用http协议,选择轮循负载均衡方式.
创建完成后添加vip:nginx-vip,使用http协议,端口为80,HTTP_COOKIE会话持久化.
使用neutron命令查询资源池nginx详细信息、nginx-vip详细信息.
3.
使用负载均衡创建nginx资源池,使用http协议,选择轮循负载均衡方式.
创建完成后添加vip:nginx-vip,使用http协议,端口为80,HTTP_COOKIE会话持久化.
使用命令查看所创建资源池的haproxy配置文件.
(物理环境)防火墙:1.
防火墙规则创建,添加名为icmp的规则,拒绝所有源IP、源端口、目的IP、目的端口的ICMP规则.
使用neutron命令查询规则列表信息、详细信息.
(物理环境)2.
防火墙创建,创建名为nginx的防火墙,添加防火墙规则nginx-80,放行所有源IP、源端口、目的IP、目的端口为80的规则.
创建防火墙策略nginx-policy,添加nginx-80规则.
使用neutron命令查询防火墙详细信息、策略详细信息、规则详细信息.
(物理环境)Mariadb高可用:1.
申请两台虚拟机,构建mariadb高可用数据库集群,通过命令查询集群状态.
2.
申请两台虚拟机,构建mariadb主从数据库,通过命令查询数据库状态.
3.
配置mariadb高可用数据库,并对集群数据库进行运维操作.
系统排错:1.
使用awk相关命令,查询表格文件中以空格为分隔符,包含关键字"key"的一行中第一个字段和最后一个字段的内容,以","作为间隔.
2.
使用sed相关命令,显示文件中第10行内容.
3.
使用sed相关命令,替换文件中的关键词"key"为"guanjianci".
4.
使用grep相关命令,查询显示文件中以"["开始并以"]"结束的所有行.
5.
使用grep相关命令,查询显示文件中的包含关键词"key"的行.
6.
登录"iaas-all"云主机,使用curl的方式,获取token值,并使用该token值,获取用户信息.
7.
登录"iaas-all"云主机,使用curl的方式,获取token值,并使用该token值,获取指定用户信息.
8.
登录"iaas-all"云主机,获取token值,使用curl的方式,创建用户并使用命令查询验证.
9.
在云平台后台管理的过程中出现错误导致无法获取镜像信息,找出错误原因,并进行修复.
10.
在云平台后台管理的过程中出现错误导致无法登录数据库,找出错误原因,并进行修复.
11.
在云平台后台管理的过程中出现错误导致无法进行keystone验证,找出错误原因,并进行修复.
12.
在云平台后台管理的过程中对象存储功能无法使用,找出错误原因,并进行修复.
13.
在云平台后台管理的过程中块存储功能无法使用,找出错误原因,并进行修复.
14.
在云平台后台管理的过程中无法上传镜像,找出错误原因,并进行修复.
15.
在云平台后台管理的过程中无法将云硬盘挂载到云主机上,找出错误原因,并进行修复.
16.
在云平台后台管理的过程中无法获取云主机详细信息,找出错误原因,并进行修复.
17.
在云平台中创建云主机过程中出现错误无法成功创建,找出错误原因,并进行修复.
18.
在云平台后台管理的过程中发生错误,错误现象为无法创建可用的云硬盘,无法获取云主机信息,也无法将云硬盘挂载到云主机上.
找出错误原因,并进行修复.
19.
搭建Ceph分布式集群存储,配置Ceph作为openstack后端的统一存储,为glance、nova、cinder、swift提供存储支持.
第二部分:PaaS云计算开发服务平台任务一、PaaS云平台搭建1.
规划容器平台的部署架构,容器平台部署在IaaS平台的2台虚拟机上.
采用分开安装的方式部署,server部署容器平台server节点和registry节点,client部署容器平台client节点.
每个虚拟机配置如下:(1)系统配置:Server节点:2CPU,2G内存,60G硬盘Client节点:2CPU,4G内存,60G硬盘(2)操作系统:centos_7-x86_64(3)IP:Server和Client节点ip动态分配(4)主机名配置:Server节点的主机名为:Server;Client节点的主机名为:Client.
根据配置要求,完成配置文件的自定义与修改,搭建PaaS平台.
2.
根据提供的软件包,搭建rancher平台.
通过curl命令查询Rancher管理平台首页.
3.
根据提供的软件包,通过应用商店部署Gogs,修改网页访问端口为9093,通过curl命令访问用户列表.
4.
根据提供的软件包,通过应用商店部署Elasticsearch2.
x,修改网页访问端口为9094,通过curl命令访问首页.
5.
根据提供的软件包,通过应用商店部署Grafana,修改网页访问端口为9090,通过curl命令访问首页.
6.
根据提供的软件包,通过应用商店部署Grafana,访问3000端口,使用curl命令访问Grafana服务的3000端口.
7.
在server节点,修改配置文件,使仓库指向我们自己创建的registry节点,使用dockerinfo命令查看修改后docker的仓库指向.
8.
搭建rancher平台,打开系统的内核转发功能.
9.
当要使用dockerapi查询信息的时候,我们需要修改docker的配置文件,添加一条OPTIONS来使得api功能可以使用,请把添加的OPTIONS参数以文本形式提交到答题框.
10.
配置docker容器实现nginx的负载均衡,需要修改nginx的配置文件,请把定义tomcat负载均衡的参数以文本形式提交到答题框.
11.
根据提供的模板文件与资源包,在Rancher应用商店自定义应用,并部署、查询.
任务二、PaaS云平台运维1.
在server节点使用netstat命令查询仓库监听端口号,查询完毕后通过lsof命令(如命令不存在则手工安装)查询使用此端口号的进程.
2.
在server节点通过netstat命令(如命令不存在则手工安装)查询docker镜像仓库PID,使用top命令查询上一步查询到的PID的资源使用情况.
3.
在server节点通过docker命令查询dockerregistry容器最后几条日志.
4.
在server节点,查询rancher/server容器的进程号,建立命名空间/var/run/netns并与rancher/server容器进行连接,通过ipnetns相关命令查询该容器的ip.
5.
在server节点查询当前cgroup的挂载情况.
6.
在server节点创建memory控制的cgroup,名称为:xiandian,创建完成后将当前进程移动到这个cgroup中,通过cat相关命令查询cgroup中的进程ID.
7.
在server节点创建cpu控制的cgroup,名称为:xiandian.
假设存在进程号为8888的进程一直占用cpu,并且达到100%,严重影响系统的正常运行.
使用cgroup相关知识在创建的cgroup中将此进程操作cpu配额调整为30%.
8.
在server节点使用nginx镜像创建一个容器,只能使用特定的内核,镜像使用nginx:latest,并通过查看cgroup相关文件查看内核使用情况.
9.
在server节点创建目录,创建完成后启动镜像为nginx:latest的容器,并指定此目录为容器启动的数据卷,创建完成后通过inspect命令指定查看数据卷的情况.
10.
在server节点创建目录,创建完成后启动镜像为nginx:latest的容器,并指定此目录为容器数据卷/opt的挂载目录,设置该数据卷为只读模式,创建完成后通过inspect命令指定查看HostConfig内的Binds情况.
11.
在server节点使用docker相关命令使用mysql:8.
0镜像创建名为mysqldb的容器,使用镜像nginx:latest创建名为nginxweb容器,容器连接mysqldb容器内数据库,操作完成后使用inspect查看有关链接内容的字段.
12.
在server节点通过bridge命令(如果不存在则安装该命令bridge-utils)查看网桥列表.
13.
在server节点创建xd_br网桥,设立网络的网络地址和掩码为192.
168.
2.
1/24,创建完成后启动该网桥,完成后查看xd_br网卡和网桥详细信息.
14.
在server节点利用nginx:latest镜像运行一个无网络环境的容器,使用inspect命令只查看该容器的networks信息.
15.
在client节点拉取mysql:8.
0镜像,拉取完成后查询docker镜像列表目录.
16.
在server节点运行mysql:8.
0镜像,设置数据库密码为xd_root,将宿主机13306端口作为容器3306端口映射,进入容器后创建数据库xd_db,创建用户xiandian,密码为xd_pass,将此用户对xd_db拥有所有权限和允许此用户远程访问,完成后使用xiandian用户远程登录数据库查询数据库内的数据库列表.
17.
在server节点将mysql镜像导出,导出名称为mysql_images.
tar,放在/media目录下,导出后,查看目录.
18.
在server节点,运行数据库容器,设置数据库密码,使用镜像为mysql:8.
0,运行之后,使用命令将容器导出,导出名称为mysql_container.
tar,放在/media目录下,导出后,查看目录.
19.
在server节点将tomcat_latest.
tar镜像导入,并打标签,上传至仓库中.
20.
在server节点运行mysql容器,使用镜像为mysql:8.
0指定mysql密码,容器运行在后台,使用随机映射端口,容器运行完成后查询容器列表.
21.
在server节点运行mysql容器,使用镜像为mysql:8.
0指定mysql密码,容器运行在后台,使用随机映射端口,容器运行完成后查询容器列表,然后将运行的mysql容器停止,完成后查询容器状态.
22.
在server节点,将上题停止的容器启动运行,完成后查询容器状态.
23.
在server节点,将运行的mysql容器重启.
24.
在server节点,执行一条命令使用exec获取rancher/server容器正在运行的网络套接字连接情况.
25.
在server节点,使用inspect只查询rancher/server容器的NetworkSettings内Networks网桥信息.
26.
在server节点,使用inspect只查询rancher/server容器的PortBindings信息.
27.
在server节点,使用inspect只查询rancher/server容器的NetworkSettings内Ports信息.
28.
在server节点,使用inspect只查询rancher/server镜像的Volumes卷组信息.
29.
在server节点,使用inspect只查询rancher/server镜像的Entrypoint信息.
30.
在server节点,使用docker命令查询rancher/server容器的进程.
31.
在server节点,使用docker命令查列出rancher/server容器内发生变化的文件和目录.
32.
在server节点,使用docker命令查看最后退出的容器的ID.
33.
在server节点,将运行的mysql容器创建为镜像,完成后查询该镜像.
34.
在server节点查询registry容器的CPU、内存等统计信息.
35.
在server节点修改运行的rancher/server容器的名称,修改名称为xiandian_server,完成后查询容器列表.
36.
在server节点,使用docker命令列举所有的网络.
37.
在server节点,使用docker命令查询bridge网络的所有详情.
38.
在server节点,使用docker命令创建名为xd_net的网络,网络网段为192.
168.
3.
0/24,网关为192.
168.
3.
1,创建完成后查询网络列表.
39.
在server节点,使用docker命令创建名为xd_net的网络,网络网段为192.
168.
3.
0/24,网关为192.
168.
3.
1,创建完成后查询此网络的详细信息.
40.
在server节点,使用docker命令创建名为xd_net的网络,网络网段为192.
168.
3.
0/24,网关为192.
168.
3.
1,创建镜像为centos:latest,容器名称为centos,使用docker网络为xd_net,创建完成后查询容器使用的网络名称和查询该容器的运行状态.
41.
在server节点,使用docker命令创建名为xd_net的网络,网络网段为192.
168.
3.
0/24,网关为192.
168.
3.
1,创建镜像为centos:latest,容器名称为centos,使用docker网络为xd_net,创建完成后查询容器IP地址.
42.
在server节点,使用docker命令创建名为xd_net的网络,网络网段为192.
168.
3.
0/24,网关为192.
168.
3.
1,创建完成后,查询网络列表,接着删除docker网络xd_net,完成后查询docker网络列表.
43.
在server节点,使用docker命令只列举rancher/server容器的端口映射状态.
44.
在server节点,使用docker命令打印rancher/server镜像的大小.
45.
在server节点,使用docker命令运行centos镜像,运行输出打印"Helloworld".
46.
在server节点,使用docker命令运行centos镜像,运行输出打印"Helloworld",要求启动命令包含打印完成后自动删除此容器及产生的数据.
47.
在server节点,使用docker命令将rancher/server容器内的/opt/目录拷贝到宿主机的/media/目录下.
48.
在server节点,使用docker命令将当前操作系统的yum源的local.
repo文件拷贝到rancher/server容器内的/opt/目录下.
完成后使用exec命令查询容器的/opt目录下的所有文件列表.
49.
在server节点,使用docker查询当前系统使用的卷组信息.
50.
在server节点,使用centos:latest的镜像创建容器,容器挂载使用创建的xd_volume卷组挂载到root分区,完成后通过inspect指定查看容器的挂载情况.
51.
使用supermin5命令(若命令不存在则自己安装)构建centos7系统的docker镜像,镜像名称为centos-7,镜像预装yum、net-tools、initscripts和vi命令,构建完成后提交镜像仓库上传操作,并查看此镜像.
52.
编写以上题构建的centos-7镜像为基础镜像,构建http服务,Dockerfile要求删除镜像的yum源,使用当前系统的yum源文件,完成后安装http服务,此镜像要求暴露80端口.
构建的镜像名字叫http:v1.
0.
完成后查看Dockerfile文件并查看镜像列表.
53.
编写以上题构建的centos-7镜像为基础镜像,构建数据库服务,Dockerfile要求删除镜像的yum源,使用当前系统的yum源文件,完成后安装mariadb服务,使用mysql用户初始化数据库,添加MYSQL_USER=xiandian、MYSQL_PASS=xiandian环境变量,要求数据库支持中文,暴露端口3306,容器开机运行mysld_safe命令,完成后启动创建的镜像并查询Dockerfile文件,进入容器查看容器的数据库列表.
54.
编写以上题构建的centos-7镜像为基础镜像,构建Tomcat服务,Dockerfile要求删除镜像的yum源,使用当前系统的yum源文件,安装java和unzip服务,将提供的apache-tomcat.
zip文件添加到/root/目录下,暴露端口8080,将提供的index.
html文件添加到tomcat的网页运行的目录下,容器开机运行catalina.
sh脚本,完成后查询Dockerfile文件,查询镜像列表.
55.
在server节点通过dockerapi查询docker的系统信息.
56.
在server节点通过dockerapi查询docker的版本.
57.
在server节点通过dockerapi查询docker内所有容器.
58.
在server节点通过dockerapi查询docker内所有镜像.
59.
在server节点通过dockerapi相关命令查询rancher/server镜像的具体信息.
60.
根据提供的tomcat镜像,创建容器,使用该镜像,并创建/root/www1目录,在www1目录下编写index.
jsp文件,容器的默认项目地址连接到创建的www1目录,要求访问tomcat的时候输出一句话为thisisTomcat1,最后启动容器,并启动tomcat服务,使用curl命令查询tomcat的首页.
61.
在server节点,使用docker命令查看最近创建的2个容器的id.
62.
在server节点,创建容器,然后将容器的卷空间值扩容(不要求扩容文件系统),最后查看容器的卷空间值.
63.
在server节点,创建容器.
创建完之后进入容器,通过修改相应的文件来限制写磁盘的速度,最后验证.
64.
在server节点,查询私有仓库redistry中有哪些镜像.
65.
在server节点,创建两个容器为test1和test2,若只有这两个容器,该怎么设置容器的权重,才能使得test1和test2的CPU资源占比为33.
3%和66.
7%.
66.
在server节点,创建容器,并明确限制容器对CPU资源的使用上限.
67.
在容器使用的过程中,出现服务无法使用的情况,请排查容器中的错误,并修复运行.
68.
使用dockerfile结合dockercompose编排一组容器,形成容器组.
69.
修改docker使用的文件系统引擎从devicemapper改为overlayfs.
70.
优化docker后端存储.
第三部分:大数据平台任务一、大数据平台搭建1.
配置masterNode的主机名为:master;slaver1Node的主机名为:slaver1.
2.
修改2个节点的hosts文件,使用FQDN的方式,配置IP地址与主机名之间的映射关系.
查询hosts文件的信息.
3.
配置2个节点使用ApacheAmbari和iaas中的centos7的yum源.
其中Ambariyum源在XianDian-BigData-v2.
2.
iso软件包中.
4.
在master节点安装ntp时钟服务,使用文件/etc/ntp.
conf配置ntp服务;在slaver节点安装ntpdate软件包,将slaver1节点时钟同步到master节点.
5.
检查2个节点是否可以通过无密钥相互访问,如果未配置,则进行SSH无密码公钥认证配置.
6.
安装2个节点的JDK环境,其中jdk-8u77-linux-x64.
tar.
gz在XianDian-BigData-v2.
2.
iso软件包中,使用命令查看JAVA版本信息.
7.
在master节点安装配置HTTP服务,将软件包XianDian-BigData-v2.
2.
iso中的HDP-2.
6.
1.
0和HDP-UTILS-1.
1.
0.
21拷贝到/var/www/html目录中,并启动HTTP服务使用命令只查看http服务的状态.
8.
查询2个节点的yum源配置文件、JDK版本信息、slaver1节点同步master节点的命令及结果和HTTP服务的运行状态信息.
9.
在master节点上安装ambari-server服务和MariaDB数据库服务,创建ambari数据库和ambari用户,用户密码为bigdata.
赋予ambari用户访问ambari数据库的权限,并导入/var/lib/ambari-server/resources/Ambari-DDL-MySQL-CREATE.
sql文件至ambari数据库中.
配置完成后安装mysql-connector-java软件包.
查询master节点中ambari数据库中的所有表的列表信息.
10.
在master节点上安装ambari-server服务和MariaDB数据库服务,创建ambari数据库和ambari用户,用户密码为bigdata.
赋予ambari用户访问ambari数据库的权限,并导入/var/lib/ambari-server/resources/Ambari-DDL-MySQL-CREATE.
sql文件至ambari数据库中.
操作完成后进入MariaDB数据库,查询mysql数据库中user表中的文件内容.
11.
在master节点对ambari-server进行设置(ambari-serversetup),指定JDK安装路径和数据库的主机、端口、用户、密码等参数,并启动ambari-server服务.
配置完成后,通过curl命令在LinuxShell中查询http://master:8080界面内容.
12.
在master节点对ambari-server进行设置(ambari-serversetup),指定JDK安装路径和数据库的主机、端口、用户、密码等参数,并启动ambari-server服务.
配置完成后,查询ambari-server的运行状态信息.
13.
在2台节点中安装ambari-agent服务,修改/etc/ambari-agent/conf/ambari-agent.
ini文件server端主机位master节点,启动ambari-agent服务,查看agent端/var/log/ambari-agent/ambari-agent.
log日志文件.
14.
在先电大数据平台中创建Hadoop集群"XIANDIANHDP",选择安装栈为HDP2.
6,安装服务为HDFS、YARN+MapReduce2、Zookeeper、AmbariMetrics.
安装完成后,在master节点和slaver节点的LinuxShell中查看Hadoop集群的服务进程信息.
15.
在先电大数据平台中创建Hadoop集群"XIANDIANHDP",选择安装栈为HDP2.
6,安装服务为HDFS、YARN+MapReduce2、Zookeeper、AmbariMetrics.
安装完成后,在LinuxShell中查看Hadoop集群的基本统计信息.
16.
在master节点的数据库中创建hive数据库,并赋予hive数据库远程访问的权限.
17.
禁用TransparentHugePages.
18.
使用提供的模板文件和资源包,在ambari界面自定义添加服务,并部署验证.
任务二、大数据平台运维HDFS题:1.
在HDFS文件系统的根目录下创建递归目录"1daoyun/file",将中的BigDataSkills.
txt文件,上传到1daoyun/file目录中,使用相关命令查看文件系统中1daoyun/file目录的文件列表信息.
2.
在HDFS文件系统的根目录下创建递归目录"1daoyun/file",将中的BigDataSkills.
txt文件,上传到1daoyun/file目录中,并使用HDFS文件系统检查工具检查文件是否受损.
3.
在HDFS文件系统的根目录下创建递归目录"1daoyun/file",将中的BigDataSkills.
txt文件,上传到1daoyun/file目录中,上传过程指定BigDataSkills.
txt文件在HDFS文件系统中的复制因子为2,并使用fsck工具检查存储块的副本数.
4.
HDFS文件系统的根目录下存在一个/apps的文件目录,要求开启该目录的可创建快照功能,并为该目录文件创建快照,快照名称为apps_1daoyun,使用相关命令查看该快照文件的列表信息.
5.
当Hadoop集群启动的时候,会首先进入到安全模式的状态,该模式默认30秒后退出.
当系统处于安全模式时,只能对HDFS文件系统进行读取,无法进行写入修改删除等的操作.
现假设需要对Hadoop集群进行维护,需要使集群进入安全模式的状态,并检查其状态.
6.
为了防止操作人员误删文件,HDFS文件系统提供了回收站的功能,但过多的垃圾文件会占用大量的存储空间.
要求在先电大数据平台的WEB界面将HDFS文件系统回收站中的文件彻底删除的时间间隔为7天.
7.
为了防止操作人员误删文件,HDFS文件系统提供了回收站的功能,但过多的垃圾文件会占用大量的存储空间.
要求在LinuxShell中使用"vi"命令修改相应的配置文件以及参数信息,关闭回收站功能.
完成后,重启相应的服务.
8.
Hadoop集群中的主机在某些情况下会出现宕机或者系统损坏的问题,一旦遇到这些问题,HDFS文件系统中的数据文件难免会产生损坏或者丢失,为了保证HDFS文件系统的可靠性,现需要在先电大数据平台的WEB界面将集群的冗余复制因子修改为5.
9.
Hadoop集群中的主机在某些情况下会出现宕机或者系统损坏的问题,一旦遇到这些问题,HDFS文件系统中的数据文件难免会产生损坏或者丢失,为了保证HDFS文件系统的可靠性,需要将集群的冗余复制因子修改为5,在LinuxShell中使用"vi"命令修改相应的配置文件以及参数信息,完成后,重启相应的服务.
10.
使用命令查看hdfs文件系统中/tmp目录下的目录个数,文件个数和文件总大小.
MapReduce题:1.
在集群节点中/usr/hdp/2.
4.
3.
0-227/hadoop-mapreduce/目录下,存在一个案例JAR包hadoop-mapreduce-examples.
jar.
运行JAR包中的PI程序来进行计算圆周率π的近似值,要求运行5次Map任务,每个Map任务的投掷次数为5.
2.
在集群节点中/usr/hdp/2.
4.
3.
0-227/hadoop-mapreduce/目录下,存在一个案例JAR包hadoop-mapreduce-examples.
jar.
运行JAR包中的wordcount程序来对/1daoyun/file/BigDataSkills.
txt文件进行单词计数,将运算结果输出到/1daoyun/output目录中,使用相关命令查询单词计数结果.
3.
在集群节点中/usr/hdp/2.
4.
3.
0-227/hadoop-mapreduce/目录下,存在一个案例JAR包hadoop-mapreduce-examples.
jar.
运行JAR包中的sudoku程序来计算下表中数独运算题的结果.
.
8367925745713168851944.
在集群节点中/usr/hdp/2.
4.
3.
0-227/hadoop-mapreduce/目录下,存在一个案例JAR包hadoop-mapreduce-examples.
jar.
运行JAR包中的grep程序来统计文件系统中/1daoyun/file/BigDataSkills.
txt文件中"Hadoop"出现的次数,统计完成后,查询统计结果信息.
HBase题:1.
启动先电大数据平台的Hbase数据库,其中要求使用master节点的RegionServer.
在LinuxShell中启动Hbaseshell,查看HBase的版本信息.
(相关数据库命令语言请全部使用小写格式)2.
启动先电大数据平台的Hbase数据库,其中要求使用master节点的RegionServer.
在LinuxShell中启动Hbaseshell,查看HBase的状态信息.
(相关数据库命令语言请全部使用小写格式)3.
启动先电大数据平台的Hbase数据库,其中要求使用master节点的RegionServer.
在LinuxShell中启动Hbaseshell,查看进入HBaseshell的当前系统用户.
(相关数据库命令语言请全部使用小写格式)4.
在HBase数据库中创建表xiandian_user,列族为info,创建完成后查看xiandian_user表的描述信息.
(相关数据库命令语言请全部使用小写格式)5.
开启HBase的安全认证功能,在HBaseShell中设置root用户拥有表xiandian_user的读写与执行的权限,设置完成后,使用相关命令查看其权限信息.
(相关数据库命令语言请全部使用小写格式)6.
在HBaseShell创建表xiandian_user,列族为info,并list查询,之后删除这个表,并list查询.
7.
在HbaseShell中创建表xiandian,向表xiandian中插入一组数据为xiandian,row1,info:name,xiaoming,插入后查询表xiandian中rowkey为row1的记录.
8.
在HbaseShell中创建表xiandian,列族为"info"然后查询表中所有的记录.
9.
登录hbase数据库,使用命令创建一张表,列族为member_id','address','info',创建完毕后查看该表的详细信息,后来发现列族'member_id'这个列族是多余的,需要删除,使用命令将该列族删除并查看详细信息,最后查看该表是否是enabled的.
10.
登录hbase数据库,创建一张表,列族为'address','info',创建完之后,向该表插入数据,插入完毕后,使用命令按照要求查询所需信息.
11.
登录hbase数据库,新建一张表,列族为'address','info',创建完之后,向该表插入数据,插入之后查询这条信息,并修改信息,改完后,查询修改前和修改后的信息.
12.
登录hbase数据库,创建一张表,列族为'address','info',创建完之后,向该表插入数据,插入完毕后,使用scan命令查询该表指定startrow的信息.
13.
在关系数据库系统中,命名空间namespace是表的逻辑分组,同一组中的表有类似的用途.
登录hbase数据库,新建一个命名空间叫newspace并用list查询,然后在这个命名空间中创建表,列族为'address','info',创建完之后,向该表插入数据,插入完毕后,使用scan命令只查询表中特定的信息.
14.
登录master节点,在本地新建一个文件叫hbasetest.
txt文件,编写内容,要求新建一张表为'test',列族为'cf',然后向这张表批量插入数据,数据如下所示:'row1','cf:a','value1''row2','cf:b','value2''row3','cf:c','value3''row4','cf:d','value4'在插入数据完毕后用scan命令查询表内容,然后用get命令只查询row1的内容,最后退出hbaseshell.
Hive题:1.
启动先电大数据平台的Hive数据仓库,启动Hvie客户端,通过Hive查看hadoop所有文件路径(相关数据库命令语言请全部使用小写格式).
2.
使用Hive工具来创建数据表xd_phy_course,将phy_course_xd.
txt导入到该表中,其中xd_phy_course表的数据结构如下表所示.
导入完成后,通过hive查询数据表xd_phy_course中数据在HDFS所处的文件位置列表信息.
(相关数据库命令语言请全部使用小写格式)stname(string)stID(int)class(string)opt_cour(string)3.
使用Hive工具来创建数据表xd_phy_course,并定义该表为外部表,外部存储位置为/1daoyun/data/hive,将phy_course_xd.
txt导入到该表中,其中xd_phy_course表的数据结构如下表所示.
导入完成后,在hive中查询数据表xd_phy_course的数据结构信息.
(相关数据库命令语言请全部使用小写格式)stname(string)stID(int)class(string)opt_cour(string)4.
使用Hive工具来查找出phy_course_xd.
txt文件中某高校Software_1403班级报名选修volleyball的成员所有信息,其中phy_course_xd.
txt文件数据结构如下表所示,选修科目字段为opt_cour,班级字段为class.
(相关数据库命令语言请全部使用小写格式)stname(string)stID(int)class(string)opt_cour(string)5.
使用Hive工具来统计phy_course_xd.
txt文件中某高校报名选修各个体育科目的总人数,其中phy_course_xd.
txt文件数据结构如下表所示,选修科目字段为opt_cour,将统计的结果导入到表phy_opt_count中,通过SELECT语句查询表phy_opt_count内容.
(相关数据库命令语言请全部使用小写格式)stname(string)stID(int)class(string)opt_cour(string)6.
使用Hive工具来查找出phy_course_score_xd.
txt文件中某高校Software_1403班级体育选修成绩在90分以上的成员所有信息,其中phy_course_score_xd.
txt文件数据结构如下表所示,选修科目字段为opt_cour,成绩字段为score.
(相关数据库命令语言请全部使用小写格式)stname(string)stID(int)class(string)opt_cour(string)score(float)7.
使用Hive工具来统计phy_course_score_xd.
txt文件中某高校各个班级体育课的平均成绩,使用round函数保留两位小数.
其中phy_course_score_xd.
txt文件数据结构如下表所示,班级字段为class,成绩字段为score.
(相关数据库命令语言请全部使用小写格式)stname(string)stID(int)class(string)opt_cour(string)score(float)8.
使用Hive工具来统计phy_course_score_xd.
txt文件中某高校各个班级体育课的最高成绩.
其中phy_course_score_xd.
txt文件数据结构如下表所示,班级字段为class,成绩字段为score.
(相关数据库命令语言请全部使用小写格式)stname(string)stID(int)class(string)opt_cour(string)score(float)9.
在Hive数据仓库将网络日志weblog_entries.
txt中分开的request_date和request_time字段进行合并,并以一个下划线"_"进行分割,如下图所示,其中weblog_entries.
txt的数据结构如下表所示.
(相关数据库命令语言请全部使用小写格式)md5(STRING)url(STRING)request_date(STRING)request_time(STRING)ip(STRING)10.
在Hive数据仓库将网络日志weblog_entries.
txt中的IP字段与ip_to_country中IP对应的国家进行简单的内链接,输出结果如下图所示,其中weblog_entries.
txt的数据结构如下表所示.
(相关数据库命令语言请全部使用小写格式)md5(STRING)url(STRING)request_date(STRING)request_time(STRING)ip(STRING)11.
使用Hive动态地关于网络日志weblog_entries.
txt的查询结果创建Hive表.
通过创建一张名为weblog_entries_url_length的新表来定义新的网络日志数据库的三个字段,分别是url,request_date,request_time.
此外,在表中定义一个获取url字符串长度名为"url_length"的新字段,其中weblog_entries.
txt的数据结构如下表所示.
完成后查询weblog_entries_url_length表文件内容.
(相关数据库命令语言请全部使用小写格式)md5(STRING)url(STRING)request_date(STRING)request_time(STRING)ip(STRING)Sqoop题:1.
在master和slaver节点安装SqoopClients,完成后,在master节点查看Sqoop的版本信息.
2.
使用Sqoop工具列出master节点中MySQL中所有数据库.
3.
使用Sqoop工具列出master节点中MySQL中ambari数据库中所有的数据表.
4.
在MySQL中创建名为xiandian的数据库,在xiandian数据库中创建xd_phy_course数据表,其数据表结构如表1所示.
使用Hive工具来创建数据表xd_phy_course,将phy_course_xd.
txt导入到该表中,其中xd_phy_course表的数据结构如表2所示.
使用Sqoop工具将hive数据仓库中的xd_phy_course表导出到master节点的MySQL中xiandain数据库的xd_phy_course表.
表1stnameVARCHAR(20)stIDINT(1)classVARCHAR(20)opt_courVARCHAR(20)表2stname(string)stID(int)class(string)opt_cour(string)5.
在Hive中创建xd_phy_course数据表,其数据表结构如下表所示.
使用Sqoop工具将MySQL中xiandian数据库下xd_phy_course表导入到Hive数据仓库中的xd_phy_course表中.
stname(string)stID(int)class(string)opt_cour(string)Pig题:1.
在master节点安装PigClients,打开LinuxShell以MapReduce模式启动它的Grunt.
2.
在master节点安装PigClients,打开LinuxShell以Local模式启动它的Grunt.
3.
使用Pig工具在Local模式计算系统日志access-log.
txt中的IP的点击数,要求使用GROUPBY语句按照IP进行分组,通过FOREACH运算符,对关系的列进行迭代,统计每个分组的总行数,最后使用DUMP语句查询统计结果.
4.
使用Pig工具计算天气数据集temperature.
txt中年度最高气温,要求使用GROUPBY语句按照year进行分组,通过FOREACH运算符,对关系的列进行迭代,统计每个分组的最大值,最后使用DUMP语句查询计算结果.
5.
使用Pig工具统计数据集ip_to_country中每个国家的IP地址数.
要求使用GROUPBY语句按照国家进行分组,通过FOREACH运算符,对关系的列进行迭代,统计每个分组的IP地址数目,最后将统计结果保存到/data/pig/output目录中,并查看数据结果.
Mahout题:1.
在master节点安装MahoutClient,打开LinuxShell运行mahout命令查看Mahout自带的案例程序.
2.
使用Mahout工具将解压后的20news-bydate.
tar.
gz文件内容转换成序列文件,保存到/data/mahout/20news/output/20news-seq/目录中,并查看该目录的列表信息.
3.
使用Mahout工具将解压后的20news-bydate.
tar.
gz文件内容转换成序列文件,保存到/data/mahout/20news/output/20news-seq/目录中,使用-text命令查看序列文件内容(前20行即可).
4.
使用Mahout挖掘工具对数据集user-item-score.
txt(用户-物品-得分)进行物品推荐,要求采用基于项目的协同过滤算法,欧几里得距离公式定义,并且每位用户的推荐个数为3,设置非布尔数据,最大偏好值为4,最小偏好值为1,将推荐输出结果保存到output目录中,通过-cat命令查询输出结果part-r-00000中的内容.
Flume题:1.
在master节点安装启动Flume组件,打开LinuxShell运行flume-ng的帮助命令,查看Flume-ng的用法信息.
2.
根据提供的模板log-example.
conf文件,使用FlumeNG工具收集master节点的系统日志/var/log/secure,将收集的日志信息文件的名称以"xiandian-sec"为前缀,存放于HDFS文件系统的/1daoyun/file/flume目录中,并且定义在HDFS中产生的文件的时间戳为10分钟.
进行收集后,查询HDFS文件系统中/1daoyun/file/flume的列表信息.
3.
根据提供的模板hdfs-example.
conf文件,使用FlumeNG工具设置master节点的系统路径/opt/xiandian/为实时上传文件至HDFS文件系统的实时路径,设置HDFS文件系统的存储路径为/data/flume/,上传后的文件名保持不变,文件类型为DataStream,然后启动flume-ngagent.
Spark题:1.
在先电大数据平台部署Spark服务组件,打开LinuxShell启动spark-shell终端,将启动的程序进程信息以文本形式提交到答题框中.
2.
启动spark-shell后,在scala中加载数据"1,2,3,4,5,6,7,8,9,10",求这些数据的2倍乘积能够被3整除的数字,并通过toDebugString方法来查看RDD的谱系.
3.
启动spark-shell后,在scala中加载Key-Value数据("A",1),("B",2),("C",3),("A",4),("B",5),("C",4),("A",3),("A",9),("B",4),("D",5),将这些数据以Key为基准进行升序排序,并以Key为基准进行分组.
4.
启动spark-shell后,在scala中加载Key-Value数据("A",1),("B",3),("C",5),("D",4),("B",7),("C",4),("E",5),("A",8),("B",4),("D",5),将这些数据以Key为基准进行升序排序,并对相同的Key进行Value求和计算.
5.
启动spark-shell后,在scala中加载Key-Value数据("A",4),("A",2),("C",3),("A",4),("B",5),("C",3),("A",4),以Key为基准进行去重操作,并通过toDebugString方法来查看RDD的谱系.
6.
启动spark-shell后,在scala中加载两组Key-Value数据("A",1),("B",2),("C",3),("A",4),("B",5)、("A",1),("B",2),("C",3),("A",4),("B",5),将两组数据以Key为基准进行JOIN操作.
7.
登录spark-shell,定义i值为1,sum值为0,使用while循环,求从1加到100的值,最后使用scala的标准输出函数输出sum值.
8.
登录spark-shell,定义i值为1,sum值为0,使用for循环,求从1加到100的值,最后使用scala的标准输出函数输出sum值.
9.
登录spark-shell,定义变量i、sum,并赋i初值为1、sum初值为0、步长为3,使用while循环,求从1加到2018的值,最后使用scala的标准输出函数输出sum值.
10.
任何一种函数式语言中,都有map函数与faltMap这两个函数:map函数的用法,顾名思义,将一个函数传入map中,然后利用传入的这个函数,将集合中的每个元素处理,并将处理后的结果返回.
而flatMap与map唯一不一样的地方就是传入的函数在处理完后返回值必须是List,所以需要返回值是List才能执行flat这一步.
(1)登录spark-shell,自定义一个list,然后利用map函数,对这个list进行元素乘2的操作.
(2)登录spark-shell,自定义一个list,然后利用flatMap函数将list转换为单个字母并转换为大写.
11.
登录大数据云主机master节点,在root目录下新建一个abc.
txt,里面的内容为:hadoophivesolrrediskafkahadoopstormflumesqoopdockersparksparkhadoopsparkelasticsearchhbasehadoophivesparkhivehadoopspark然后登录spark-shell,首先使用命令统计abc.
txt的行数,接着对abc.
txt文档中的单词进行计数,并按照单词首字母的升序进行排序,最后统计结果行数.
12.
登录spark-shell,自定义一个List,使用spark自带函数对这个List进行去重操作.
13.
登录"spark-shell"交互界面.
给定数据,使用spark工具,统计每个日期新增加的用户数,最后显示统计结果.
14.
登录"spark-shell"交互界面.
定义一个函数,函数的作用是比较传入的两个变量,返回大的那个.
第四部分:SaaS云应用开发任务一、大数据学情分析1.
导入开发环境检查已安装的MongoDB,HBase,MySQL本地服务,解压guosai-xueqing.
rar学情开发框架项目,搭建大数据学情开发环境.
(1)导入三个MongoDB数据库目录employ,job_internet,question_survey;(2)导入MySQL的xueqing-client项目的sql文件xueqing-client.
sql;(3)导入xueqing-web项目并运行.
2.
HBase建表操作完成xueqing-server之中HBase建数据库表的过程,建立总表和相应的行业表,运行后提交代码与HBase中表的查询结果.
3.
爬取岗位信息通过解析网站(xueqing-web)源代码,抓取所有岗位页面信息中的岗位名称,发布日期,薪水条件,招聘人数,学历要求,工作经验年限,岗位描述等信息,爬取的信息存入指定的HBase表.
运行后提交代码与HBase中表的查询结果.
4.
对爬取的岗位信息清洗使用HBase中保存的岗位信息,根据指定的数据转换规则,对指定的列族和列的地区分布、学历分布、薪资分布、企业规模、企业性质、工作经验等数据进行清洗.
5.
岗位数据统计完成xueqing-server之中爬取的岗位信息数据进行数据统计,将数据保存至MongoDB之中,实现Web前端代码并通过指定EChart的图表可视化展示岗位地区分布、学历分布、薪资分布、企业规模、企业性质、工作经验等统计可视化数据开发.
6.
岗位聚类根据给定的岗位数据源,使用指定的聚类或分类算法,进行IT行业的云计算、大数据、移动互联、人工智能或物联网等行业进行岗位聚类分析,将数据保存至MongoDB之中,实现Web前端代码并通过指定EChart的图表可视化展示.
7.
聚类岗位的主要技能图谱完成xueqing-server之中的聚类结果,提取每一个聚类结果中的主要技能点,将数据保存至MongoDB之中,通过EChart指定的图表展示岗位的技能图谱.
8.
推荐岗位给定一个学生的技能数据,使用机器学习推荐算法,帮助该学生推荐三个最佳的招聘岗位,并通过EChart指定的图表展示推荐岗位和学生技能对比.
任务二、微信小程序开发1.
商店界面开发根据下面给出的效果图实现微信O2O商城商店界面的开发.
效果图:2.
预约界面开发根据下面给出的效果图实现微信O2O商城预约界面的开发.
效果图:3.
订单界面开发根据下面给出的效果图实现微信O2O商城订单界面的开发.
效果图:4.
账户界面开发根据下面给出的效果图实现微信O2O商城账户界面的开发.
效果图:5.
充值界面开发根据下面给出的效果图实现微信o2o商城充值界面的开发.
效果图:6.
消费记录界面开发根据下面给出的效果图实现微信o2o商城消费记录界面的开发.
效果图:7.
充值记录界面开发根据下面给出的效果图实现微信o2o商城充值记录界面的开发.
效果图:8.
我的资料界面开发根据下面给出的效果图实现微信o2o商城我的资料界面的开发.
效果图:9.
商品详情界面开发根据下面给出的效果图实现微信o2o商城商品详情界面的开发.
效果图:10.
订单详情界面开发根据下面给出的效果图实现微信o2o商城订单详情界面的开发.
效果图:11.
微信后台用户服务对接基于给定的数据库数据,开发后台Restful服务,实现O2O商城的用户信息、用户登录或登出等接口代码,实现用户模块相关功能.
12.
微信小程序商品服务对接基于给定的数据库数据,开发后台Restful服务,实现O2O商城的商品查询、搜索或获取商品等接口代码,实现商品模块相关功能对接.
13.
微信小程序订单服务对接基于给定的数据库数据,开发后台Restful服务,实现O2O商城的订单售后、订单详情或订单状态等接口代码,实现订单模块相关功能对接.
第五部分:文档及职业素养任务一、工作总结报告云架构设计和说明1.
绘制IaaS平台的架构组件图,组件包含本次项目实施中涉及到的IaaS组件服务,架构组件绘制各组件之间的关系.
并对架构图进行解释说明.
2.
绘制Hadoop分布式存储HDFS的架构图,并对架构图进行解释说明.
3.
构建存储型、高可用的IaaS平台的需求,设计包含存储节点3台、计算节点2台、控制节点3台的高可用IaaS方案.
包括硬件设备、网络拓扑、服务模块的架构图.
4.
绘制云计算SPI模型,并对各服务组成进行说明.
5.
绘制IaaS云平台新建云主机的流程图,并详细描述云主机创建的过程.
要求该流程从网页进行创建,使用keystone作为所有组件的权限认证方式,nova作为核心组件,neutron提供网络,由cinder提供持久化的存储.
6.
IaaS云平台中,用户请求云主机的流程涉及认证Keystone服务、计算Nova服务、镜像Glance服务,网络Neutron服务,在服务流程中,令牌(Token)作为流程认证传递.
绘制服务申请认证机制的流程并进行简要说明.
7.
由于镜像文件都比较大,镜像从创建到成功上传到Glance文件系统中,是通过异步任务的方式一步步完成的,状态包括Queued(排队)、Saving(保存中)、Acive(有效)、deactivated(无效)、Killed(错误)、Deleted(被删除)和Pending_delete(等待删除).
绘制镜像服务的状态图,并对各状态进行简要的说明.
8.
绘制cinder的架构图,并进行简要的说明.
9.
绘制cinderVolume的创建流程,并进行简要说明.
10.
绘制ceilometer采集监控数据到持久化存储的流程图,并进行简要的说明.
11.
swift使用称之为"Ring"的环形数据结构,在图中绘制swift的哈希Ring,并进行简要的说明.
12.
Swift采用层次数据模型,绘制Swift数据模型图,并进行简要说明.
13.
绘制GRE网络中,同一个host上同一个子网内云主机之间的通信过程.
14.
绘制GRE网络中,云主机访问外网的流程图,并简要说明数据包的流向.
15.
绘制Docker的系统架构图,并进行说明.
16.
绘制openstack中flat网络的网络模式图.
并做简要说明.
17.
绘制openstack中gre网络的网络模式图.
并做简要说明.
18.
绘制openstack中vlan网络的网络模式图.
并做简要说明.
19.
绘制openstacknova的服务进程图,并做简要说明.
运维及脚本解读1.
针对安装脚本iaas-pre-host.
sh,逐行进行解读,指出各行内容所进行的操作以及各自的作用.
2.
针对安装脚本iaas-install-mysql.
sh,逐行进行解读,指出各行内容所进行的操作以及各自的作用.
3.
针对安装脚本iaas-install-keystone.
sh,逐行进行解读,指出各行内容所进行的操作以及各自的作用.
4.
针对安装脚本iaas-install-glance.
sh,逐行进行解读,指出各行内容所进行的操作以及各自的作用.
5.
针对安装脚本iaas-install-nova-controller.
sh,逐行进行解读,指出各行内容所进行的操作以及各自的作用.
6.
针对安装脚本iaas-install-nova-compute.
sh,逐行进行解读,指出各行内容所进行的操作以及各自的作用.
7.
针对安装脚本iaas-install-neutron-controller.
sh,逐行进行解读,指出各行内容所进行的操作以及各自的作用.
8.
针对安装脚本iaas-install-neutron-controller-gre.
sh,逐行进行解读,指出各行内容所进行的操作以及各自的作用.
9.
针对安装脚本iaas-install-neutron-controller-vlan.
sh,逐行进行解读,指出各行内容所进行的操作以及各自的作用.
10.
针对安装脚本iaas-install-neutron-controller-flat.
sh,逐行进行解读,指出各行内容所进行的操作以及各自的作用.
11.
针对安装脚本iaas-install-swift-controller.
sh,逐行进行解读,指出各行内容所进行的操作以及各自的作用.
12.
针对安装脚本iaas-install-heat.
sh,逐行进行解读,指出各行内容所进行的操作以及各自的作用.
13.
针对安装脚本iaas-install-cinder-controller.
sh,逐行进行解读,指出各行内容所进行的操作以及各自的作用.
14.
针对安装脚本iaas-install-cinder-compute.
sh,逐行进行解读,指出各行内容所进行的操作以及各自的作用.
15.
针对安装脚本iaas-install-ceilometer-controller.
sh,逐行进行解读,指出各行内容所进行的操作以及各自的作用.
16.
针对安装脚本iaas-install-ceilometer-compute.
sh,逐行进行解读,指出各行内容所进行的操作以及各自的作用.
17.
针对安装脚本iaas-install-alarm.
sh,逐行进行解读,指出各行内容所进行的操作以及各自的作用.
18.
针对安装脚本iaas-install-dashboard.
sh,逐行进行解读,指出各行内容所进行的操作以及各自的作用.
19.
针对安装脚本iaas-install-trove.
sh,逐行进行解读,指出各行内容所进行的操作以及各自的作用.
20.
linux下给文件start.
sh设置权限为自己可读可修改可执行,组内用户为可读可执行不可修改,其余用户没有任何权限,那么设置该文件权限的命令是什么21.
简述raid0raid1raid5三种工作模式的工作原理及特点.
22.
Yum命令与rpm命令的区别如何使用rpm安装一个有依赖的包23.
当我们在IAAS平台中创建了一台云主机,硬盘大小为20G且全分给了根目录,随着使用的过程中,发现根目录的容量不够了,现在需要扩容这台云主机的根目录(云主机的分区是LVM形式的),请把操作的过程描述一下.
- 命令centos6.5相关文档
- EURASIPcentos6.5
- 检查centos6.5
- Bugcentos6.5
- 濮阳市政府采购濮阳市职业中等专业学校高水平专业群建设项目
- 项目编号:SDJC-2017-0222-XN
- luogocentos6.5
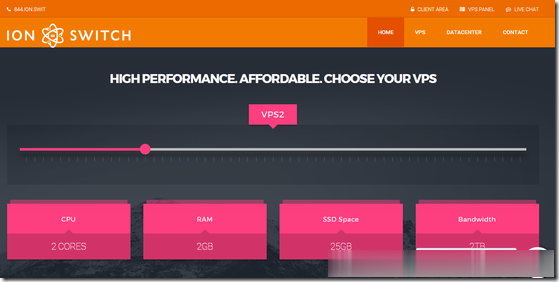
IonSwitch:$1.75/月KVM-1GB/10G SSD/1TB/爱达荷州
IonSwitch是一家2016年成立的国外VPS主机商,部落上一次分享的信息还停留在2019年,主机商提供基于KVM架构的VPS产品,数据中心之前在美国西雅图,目前是美国爱达荷州科德阿伦(美国西北部,西接华盛顿州和俄勒冈州),为新建的自营数据中心。商家针对新数据中心运行及4号独立日提供了一个5折优惠码,优惠后最低1GB内存套餐每月仅1.75美元起。下面列出部分套餐配置信息。CPU:1core内存...
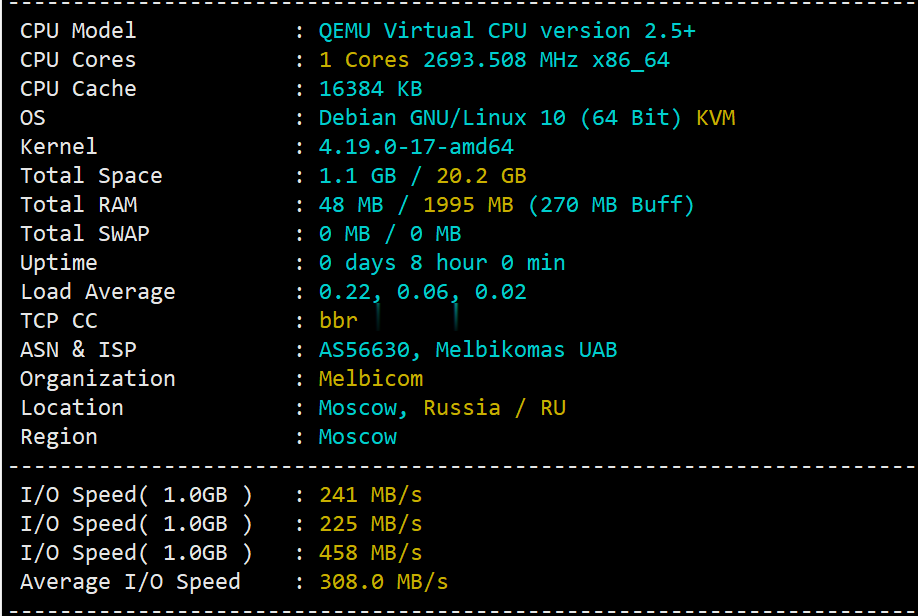
简单测评melbicom俄罗斯莫斯科数据中心的VPS,三网CN2回国,电信双程cn2
melbicom从2015年就开始运作了,在国内也是有一定的粉丝群,站长最早是从2017年开始介绍melbicom。上一次测评melbicom是在2018年,由于期间有不少人持续关注这个品牌,而且站长貌似也听说过路由什么的有变动的迹象。为此,今天重新对莫斯科数据中心的VPS进行一次简单测评,数据仅供参考。官方网站: https://melbicom.net比特币、信用卡、PayPal、支付宝、银联...
90IDC-香港云主机,美国服务器,日本KVM高性能云主机,创建高性能CLOUD只需60秒即可开通使用!
官方网站:点击访问90IDC官方网站优惠码:云八五折优惠劵:90IDCHK85,仅适用于香港CLOUD主机含特惠型。活动方案:年付特惠服务器:CPU均为Intel Xeon两颗,纯CN2永不混线,让您的网站更快一步。香港大浦CN2測速網址: http://194.105.63.191美国三网CN2測速網址: http://154.7.13.95香港购买地址:https://www.90idc.ne...

-
0.21网易yeah企业cms企业站cms哪个好搜狗360没有登录过搜狗浏览器,只是用搜狗高速浏览器等QQ淘宝会有事情么搜狗360360影视大全怎样免费看大片360退出北京时间电脑桌面右下放了时间不对了怎么可以准确调回北京时间特朗普吐槽iPhone为什么iphone x卖的这么好支付宝账户是什么什么是企业支付宝账户支付宝账户是什么支付宝的账号是什么啊ldapserver怎样打开DWA文件?请说详细点?财务单据出纳要用什么单据?