近两年来国外有关本体基本问题的主要研究述评
杨良斌黄国彬周静怡(中国科学院国家科学图书馆,北京100190)[摘要]本体的创建、描述、映射、演化与评价是本体研究的基本问题.
文章从基于深层网页的本体创建、基于领域知识自动本体建设系统的研究和本体构建与共享的合作环境等角度概述了本体创建的基本研究进展;从本体可视化、Web中本体检索系统的设计和本体演化等角度介绍了本体的改进与完善的基本研究进展;从本体与形式语义学、面向语义服务的本体服务、web本体应用、基于情景族模型的OWL本体概念、信息技术本体与语义技术以及面向语义web的模糊本体创建等角度指出了本体与语义web的主要研究进展;最后从基于同一属性的本体定量评价和用于本体评价和排序的工具研究两个方面介绍了本体评价的研究进展.
同时,分析了本体应用障碍.
[关键词]本体创建;本体映射;本体演化;本体评价[分类号]G250ReviewofStudyontheMainProblemsofOntologyinRecentTwoYearsAbroadYangLiangbinHuangGuobinZhouJingyi(NationalScienceLibrary,ChineseAcademyofSciences,Beijing,100190)[Abstract]Themainproblemsofontologyincludeontologycreation,ontologydescription,ontologymapping,ontologyevolutionandontologyevaluation.
Inthispaper,firstly,ontologycreationisdiscussedfromtheaspectsofautomaticgenerationofontologyfromthedeepweb,designoftheautomaticontologybuildingsystemaboutthespecificdomainknowledge,collaborativeenvironmentsforontologyconstructionandsharing.
Secondly,theimprovementofontologyisintroducedthroughontologyvisualization,designoftheontologyretrievalsystemonthewebandontologyevolution.
Thirdly,thecombinationstudyofontologyandsemanticwebisexploredviaformalsemantics,ontologyserviceorientedsemanticservice,webontologyimplementation,OWLontologybasedonthecontextfamilymodel,ITontologyandcreationoffuzzyontology.
Fourthly,ontologyevaluationistalkedaboutbythequantityevaluationandontologyevaluationtools.
Finally,thebarricadeofontologyapplicationisalsoreferredto.
[Keywords]OntologyCreation;OntologyMapping;OntologyEvolution;OntologyEvaluation1引言本体的创建、描述、映射、演化与评价是本体研究的基本问题.
本体构建是本体知识获取的核心,本体描述则是通过定义系统中知识表示的语言规范,并采用一定的本体描述语言对各种概念与概念之间的关系加以描述的过程.
而通过本体映射,可以在多个本体之间找到语义相同或相似的对应元素,从而在多个本体之间建立语义联系,消除不同本体或不同版本的本体之间知识表达的不一致.
本体演化是对本体适应领域知识变化的一种表征.
本体演化的结果,即是将新概念和概念之间的新关系予以揭示、描述.
本文将从本体创建、本体改进、本体与语义web以及本体评价等角度介绍近两年来国外围绕本体基本问题的主要研究进展.
2本体创建本体构建是本体知识获取的核心,即从某个领域中抽取知识,形成描述该领域数据的语义概念、实例和其间的关系.
近两年来,围绕本体创建的研究已经从概念词与概念词关系确定向智能本体创建、模糊本体创建、本体自动创建等方向转移.
2.
1基于深层网页的本体创建深层网页是指搜索引擎无法自动访问的网页,因为这些网页在回应通过Web窗体或Web服务的查询时是被动态汇集的,现有的自动化网络抓取工具无法索引这些网页,因此,这类网页资源在Web搜索引擎下是隐藏的.
从目前来看,通过建立领域本体的语义索引,以此表征深层网页源的内容,从而恰当地注释这些深层网页服务(即生成能够揭示隐藏网页源的界面),这是当前研究的重点.
在没有人工干预的情况下,全自动地从Web源中创建本体依然是一个具有挑战性的研究课题.
AnYooJung等学者提出了一种新颖的方法[1],该法通过综合提取自深层网页服务页面的领域信息的WordNet的子分类法,自动建立一个大型的、面向领域-特定的本体.
该算法从深层网页源中提取领域概念,增强了WordNet的概念和关系,从而构建了本体片段.
在结构上,这些概念与关系都采用有向无环图(DAGs)揭示.
该文的突出特点是提取了WordNet的概念和关系,并且缩小了概念的差距,形成了一个迭代过程,该迭代过程用来联系领域概念和本体片段共同构成一个本体.
2.
2基于领域知识的自动本体建设系统的研究本体的适用范围正变得越来越广泛,因此许多本体存在于Web中,但也由此引发了一系列资源发现与资源检索的问题.
其中,如何处理同一领域的本体之间的异质性和一致性尤其引起了研究人员的注意.
KongHyunjang、HwangMyunggwon、KimPanko等学者提出了基于现有数据自动建设本体的可能性,并利用基于WordNet的自动建立本体的新方法,设计和实现了自动本体建设系统,并进行了实例验证[2].
2.
3本体构建与共享的合作环境在特定领域中,具备明确识别目标、属性和关系等功能的本体对于个人在数据、知识或资源共享的合作中必不可少.
BaoJie、D.
Caragea、V.
Honavar等学者通过明确本体构建、共享和使用的合作环境的需求[3],开发了基于描述逻辑(P-DL,Package-DescriptionLogic)的软件包,扩充了基于本体语言支持模块化和(选择性)知识隐藏的经典描述逻辑(DL).
在其设计的P-DL模型中,每个本体由有着清晰定义界面的软件包(或模块)组成.
每个软件包封装在紧密相关的一套术语及术语之间的关系中.
软件包可能是分层嵌套的,因此可产生一个本体组织结构.
基于软件包的本体也允许软件包开发者控制每个术语的显示度.
3本体的改进与完善语义网技术高度依赖于本体的质量.
为了提高本体质量,大量的研究都集中在概念建模上,但是,本体词汇表征问题始终是影响本体质量的关键.
目前的词汇表征可能会涉及不同含义的术语,从而导致在本体应用中出现令人沮丧的误解和模糊.
为了解决这个问题,有些学者研究指出,意识可用来取代术语作为概念和属性的词汇表征,以此表征术语的唯一含义.
本体净化是对本体术语进行消除歧义的过程,可通过在有注解的使用这个本体的文档中应用其周围的本体要素和邻近术语加以实现.
3.
1本体可视化本体的描述语言起源于人工智能对知识表示的研究.
20世纪90年代以来,一些基于人工智能的本体表示语言陆续被提出来,随着Web的发展,为了适应Web的开放性并且能够与RDFS兼容,传统的知识本体语言,如Ontolingua,Loom等不再被使用.
从当前的发展情况来看,本体表示语言主要是OWL(WebOntologyLanguage),由W3C在提交的DAML+OIL的基础上改进而来.
OWL作为W3C推荐的Web本体标准语言,可用于处理信息内容,但是却无法直接向用户表达显示信息.
3.
1.
1OWL语言与可视化技术的结合HirokiOmote和KozoSugiyama等学者通过在OWL中应用相交聚类图的可视化方法来表达OWL所描述的类和关系[4].
该文指出,相交聚类图是一种在聚类之间形成相交的聚类图,其基于一种矢量的方法——电子弹簧模型来进行图形绘制,并通过实验来评估该方法的效果,最终实现将该方法应用到web本体语言(WebOntologyLanguage)中.
相交聚类图绘制方法符合OWL参考要求,并可实现可视化.
由于相交聚类采用无向边,但是为了在OWL中应用,必须采用有向边的相交聚类图.
在OWL中每一个有向边用一个谓词来表示,每一个谓词表达了类和属性之间的关系.
比如,谓词"subClassOf"有一个父子关系,即表示从父类指向子类;谓词"hasValue"表示从一个类指向一个属性;谓词"intersectionOf"和"unionOf"都是表示OWL的一个关系,但是属于不同的方式,前者类与类之间是交集的关系,后者是并集的关系,这两种关系的类之间通过不同的颜色进行区分.
3.
1.
2面向e-Science环境的本体可视化建模在e-Science环境下,信息资源管理系统通常要处理的对象是异构的数据模型和格式.
R.
Rajugan,E.
Chang和T.
S.
Dillon.
等学者研究指出[5],近年来,在e-Science领域通过建立本体来提供解释性的语义以推进其发展已经得到学界公认.
本体主要在e-Science中的主要应用前景包括:为大型本体的本地化应用和用户提供管理范式;提高了向大型本体创建子本体的精确抽取程度;提高了大型本体的本地个性化和使用比例.
由于在这些本体之中缺乏统一的标准、规范、方法来定义和物化本体,因此围绕本体在e-Science环境下的应用及其可视化建模仍然是值得深入研究的问题.
3.
2Web中本体检索系统的设计为了最佳优化本体的重复使用,HwangMyunggwon、KongHyunjang和KimPankoo等学者尝试设计系统以搜索分散在Web上的本体[6].
由于当前围绕语义网的研究较为活跃,作为语义网必需要素的本体也益发重要.
因此,许多本体语言和本体工具在不断地发展更新.
虽然目前已经有许多本体被构建,但在Web上的本体检索是一项有一定实现难度的工作,且储存本体中的知识库是不存在的.
因此,设计web中本体检索系统必须正视这样的问题:虽然相同的领域本体在Web上早已存在,但领域本体总是以新的方式被人们兴建起来.
减少具有重要特性的本体的重复使用是个很大的问题.
HwangMyunggwon等学者描述了用于检索领域本体和设计web本体检索系统的方法.
3.
3本体演化在本体知识系统中,本体知识不是一成不变的,本体要能具备适应外界变化的能力.
本体演化过程包括:(1)解决本体变化的问题,并确保底层本体和所有相关本体的一致性;(2)能让用户方便地监控和管理变化;(3)由于相同的本体可能由不同的用户分别修改,因此需要经常将同一本体的不同版本再次集成;(4)应能向用户提供反复本体精化的建议.
通过构建本体演化模型,可以将本体演化的基本流程进行揭示.
2006年,Oapos等学者提出了用生物进化方法构建智能本体演化模型的方法.
该文讨论了构建本体演化模型的三种方法,提出了本体演化的另一种进化模型,并借助自然进化的理念,力图寻求最适当的本体演化模型构建方法[7].
4本体与语义web4.
1本体与形式语义学WalidS.
研究指出[8],在自然语言语义中遇到的问题,大部分只是因为符号处理系统缺乏相关的背景信息支持.
因为在这些系统中,不具备任何类似于人类常识的判断.
对于这个问题的解决方法是将反应人类常识和人类常用语言的本体整合到语义中.
在这些加工后的逻辑中,有本体的概念,也有逻辑的概念,并且本体概念不仅包括Davidsonian事件,同时也包括抽象对象.
WalidS.
证明了在该架构中,自然语言遇到的语义问题都可以得到正确和统一地解决.
4.
2面向语义服务的本体服务Khalid,N.
Pasha.
M.
和Ahmad.
H.
F等人在"基于代理的语义服务与基于OWL的语义服务之间的本体服务"一文中指出[9],代理和网格服务是两种不同的技术,有着不同的标准和规范.
网格服务对于语义的利用推动了两者在软件代理中的发展.
Khalid等学者认为,不同的本体语言宜采用不同的语义描述方法,不同的语义描述语言对条目、语法、语义和约束有不同的支持方式.
Khalid等学者主要是整合代理技术到网格服务中,并且对代理技术的标准和规范不做修改,提出了一种中间件,作为中间件本体服务,通过对本体的映射,在代理和网格服务中提供语义互操作,如映射OWL本体到FIPASL本体的代理,映射FIPASL本体到OWL的网格服务.
此外,Khalid等学者还描述了如何注册中间件中的本体,并在网格和代理中进行揭示,以便用于概念、属性和行为的查询.
同时,他们还描述了通过一种软件代理来调用和使用OWL发布的网格服务的试验床配置.
4.
3web本体应用Kim和Su-Kyoung在"面向语义网应用的web本体应用"一文中分析了语义网应用和Web本体的特点之后[10],通过描述逻辑和SWRL,建立了基于推理的web本体,并验证了建立Web本体的推理机制.
最重要的是,Kim等学者还通过推理重新生成了新的本体.
根据推理规则定义的执行,通过基于本体的知识产生了一个新的本体文件.
这种方式的一个重要的目的就是重用和共享本体的功能.
该研究建立了一个基于web本体的试验系统来支持图像检索.
试验结果表明,语义web应用了采用基于推理的web本体后,在查全率和查准率方面,与一些使用了基于注释的本体目标系统相比,其性能明显要好.
4.
4基于情景族模型的OWL本体概念语义网的核心是本体,本体支持语义网应用之间的互操作,并且让开发人员能够不断使用和共享领域知识.
建立本体的过程是一个高成本的过程.
构建本体更像是一门艺术,而不是一门科学.
因此,方法论和支撑工具是帮助开发人员构建合适本体的核心,以便达到既定目标,并确认本体是否与目标相符及其可重复利用性.
Dong-SoonKim、Suk-HyungHwang和Hong-GeeKim等学者提出了一种新颖的方法用来分析基于语境模型的形式概念分析的本体[11],并建立了一种新的工具用于从OWL的源码中抽取主要的元素(类,属性和个体等),并发现一些结构性的问题.
通过这个工具,本体开发人员可以构建良好定义的本体.
4.
5信息技术本体与语义技术语义技术是相对于语法技术而言的.
本体在语法结构以意义为中心的重新配置方法中起到了很重要的作用.
Key-SunChoi等学者研究指出[12],利用信息本体的目的主要有两个方面:一方面是针对用户需求获取正确的信息和服务;另一方面是为在类和实例之间建立关系提供思路.
基于本体的问题-回答模式可以提高其性能.
在该模式中,本体提前从相关的信息资源中获取信息,因此每一种问题类型都可以从本体中获取特定的关系.
问题是这种关系或者相关的类都是不确定的领域或者依赖于单个特定的领域.
本体学习在问题-回答应用的第一步是找到这些不确定性关系的发现机制,并充分考虑针对特定领域资源时,特定的关系-实例的映射.
第二步是考虑领域本体获取,针对类似资源(如特定领域词表)的时候采取从上到下的方式,而针对相关资源采取从下到上的方式.
但仍需要创建者面对的问题是,词表是由类组成的,而不是语料库中的条目实例,它们对于资源的覆盖面比较小,并且在这个层面,类和实例之间的映射并没有充分建立.
最后,需要解决两个问题:如何评价本体的有效性;如何比较每个本体的应用效果总之,在解决好对问题的定义,并将其转化为本体的形式后,信息技术本体的模块化有利于高效地满足各种需求.
4.
6面向语义web的模糊本体创建模糊逻辑在本体中用于表达不确定信息,而模糊本体将模糊概念引入到传统的本体模型中,以解决一定领域的不确定问题.
一般而言,模糊本体来自于预定义的概念层级结构,主要由模糊形式概念分析、模糊概念聚类及模糊本体生成等部分组成.
Tho,Q.
T.
等学者提出了模糊本体生成框架(FOGA,fuzzyontologygenerationframework),用于在不确定信息的条件下,自动生成模糊本体.
FOGA框架由以下组成:模型形式概念分析,概念层级结构生成和模糊本体生成.
同时,Tho,Q.
T.
等学者还对本体新增数据的近似推理方法进行研究,提出了整合模糊技术到属性数据库的建议[13].
5本体评价继本体创建受到研究人员青睐之后,如何对已经创建的本体进行评价进一步成为研究人员关心的问题.
为了建立高质量的本体,需要进行本体评价.
目前为止,多数的评价方法侧重在语法评价,这种评价可以保证本体的准确性与完整性.
这些评价方法的首要目标是避免本体在使用过程中的不一致性或者不确定性.
在过去两年中,有些学者研究了基于领域的不同本体之间共同的意义结构,这些结构是彼此相似的.
但是,很少有研究关注过本体的内在结构.
作为知识的揭示方式的本体,应该具有和领域知识类似的结构.
而且,本体结构组织得越好,会使之越容易理解、学习、应用和重新使用.
5.
1基于同一属性的本体定量评价采用相关的属性对本体开展定量评价是比较同一领域不同本体质量优劣的基本方法.
ChunSoonAe和J.
Geller等学者研究指出[14],建立本体的艺术和科学已经发展到不再能足够地设计和执行一种新的本体的程度.
更确切地说,通过评价本体在数字术语中的质量,人们需要去遵循本体的构建流程.
如果在相同领域存在另一个本体,那这两个本体应该以定量的方式进行比较以确定哪个本体的质量更好.
而且由于本体是存在于许多不同变量中的复杂结构,因此,质量评价机制应该提供这种需要改进的内容(一个或两个线索).
即使在确定一个基本结构框架并选定领域后,两个本体也可能由评价者采用一些不同的特性进行评价.
为此,ChunSoonAe假设所有其他的特点不变而主要研究一个单一的本体特点,同时,他建立了一种机制,用以测度本体特性和基于自然概念的优选术语质量.
结果显示,ChunSoonAe提出的评价方法与人工判断方法有很好的一致性.
因此,对于在一个本体中优选术语的原则性选择,该文的结论具有很好的借鉴性.
5.
2用于本体评价和排序的工具研究作为语义网的基础支撑,本体易于帮助使用者分析和共享知识.
随着越来越多的本体产生,用户很难找到最适于其自身需要的本体.
因此,需要有对本体进行评价和排序的工具.
SamirTartir和BudakI.
Arpinar于2007年在研究文章中构建了OntoQA——一款对某一领域的术语集(本体)进行评价并依据一组体现本体不同方面特征的量度将本体加以排序的工具[15].
迄今为止,由于尚无界定本体质量好坏的全球判断标准,因此,OntoQA可以让用户根据应用需求就本体的某些方面特征对本体进行评价、排序.
SamirTartir通过比较OntoQA和其它具有可比性的方法以及专家评价法对本体评价、排序的结果,证明了OntoQA的有效性.
Qadir、MuhammadAbdul等学者研究指出,结构化的知识是本体最重要的组成部分,基于语义的信息系统所需的自动化的智能任务通常是由人类专家实施的.
在本体中关于某一领域的知识通常是结构化的.
一个本体将基本术语和规则组织起来,这些术语和规则组合了机器可解释的术语和可理解的术语.
因此,界定一个本体应被视为一项重要而严肃的任务,而且需要定义明确的工具和技术来确认和验证.
对于本体的每一个生命周期状态,已有大量的工作用于界定其开发过程.
用于评价本体内容的自动化工具对大规模本体开发者是一个很大的帮助.
为此,Qadir等构建了一些本体来表征真实生活状态,并有意留下这些本体中的某些错误,以期观察这些工具是否可提高信息遗漏预警.
最后,Qadir等指出,对于开发者而言,断续知识和详尽知识的遗漏不能被现有的工具发现并向使用者提供预警.
为此,他们设计出相关的算法以解决这些情况,并通过实验加以验证[16].
6结论多年来,本体研究在计算机科学、图书馆学情报学等领域得到迅速发展.
虽然本体研究人员已经描述并通过实验的方式揭示出本体技术在智能信息处理方面的多种潜在收益,且多数学者将本体视为语义网和其它语义系统的基础架构与主要组件.
不幸的是,现在Web中可使用的较为实用的本体在数量和质量上都显著偏低[17].
这就意味着,在许多相关领域,语义网研究界尚未建立切实有用的本体,以便使语义网成为现实.
理论上,研究者往往以为本体应用的不普及是因为"愚蠢的商界人士没有意识到本体潜在的巨大益处".
作为一个主张自由市场的经济学家,MartinHepp指出,至少从长远来看,人类通常都能预测并计算出什么是他们的最大福祉,并采取相应的行动去追求.
换句话说,在本体研究领域,人们尚未建立许多有益的本体让人们能够充分意识到本体的好处,这或许根源于尚未解决的技术限制,又或许是人文方面的原因,又或许是其他原因.
事实上,技术与社会因素同样会成为抑制本体发展空间的因素.
Sharktech鲨鱼服务器商提供洛杉矶独立服务器促销 不限流量月99美元
Sharktech(鲨鱼服务器商)我们还是比较懂的,有提供独立服务器和高防服务器,而且性价比都还算是不错,而且我们看到有一些主机商的服务器也是走这个商家渠道分销的。这不看到鲨鱼服务器商家洛杉矶独立服务器纷纷促销,不限制流量的独立服务器起步99美元,这个还未曾有过。第一、鲨鱼机房服务器方案洛杉矶机房,默认1Gbps带宽,不限流量,自带5个IPv4,免费60Gbps / 48Mpps DDoS防御。C...
2021年全新Vultr VPS主机开通云服务器和选择机房教程(附IP不通问题)
昨天有分享到"2021年Vultr新用户福利注册账户赠送50美元"文章,居然还有网友曾经没有注册过他家的账户,薅过他们家的羊毛。通过一阵折腾居然能注册到账户,但是对于如何开通云服务器稍微有点不对劲,对于新人来说确实有点疑惑。因为Vultr采用的是预付费充值方式,会在每月的一号扣费,当然我们账户需要存留余额或者我们采用自动扣费支付模式。把笔记中以前的文章推送给网友查看,他居然告诉我界面不同,看的不对...

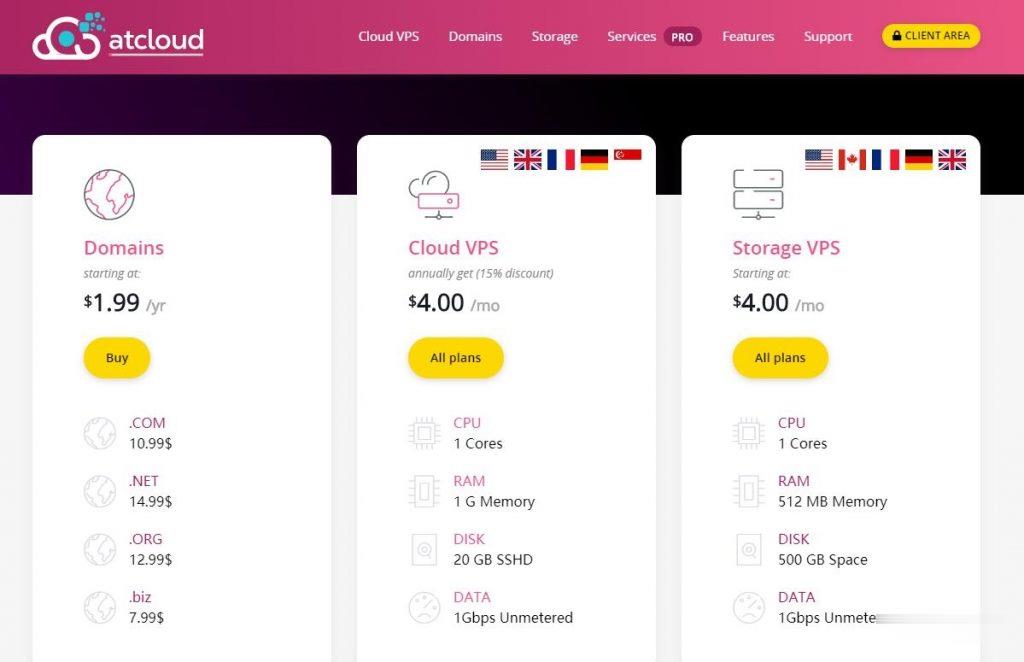
ATCLOUD-KVM架构的VPS产品$4.5,杜绝DDoS攻击
ATCLOUD.NET怎么样?ATCLOUD.NET主要提供KVM架构的VPS产品、LXC容器化产品、权威DNS智能解析、域名注册、SSL证书等海外网站建设服务。 其大部分数据中心是由OVH机房提供,其节点包括美国(俄勒冈、弗吉尼亚)、加拿大、英国、法国、德国以及新加坡。 提供超过480Gbps的DDoS高防保护,杜绝DDoS攻击骚扰,比较适合海外建站等业务。官方网站:点击访问ATCLOUD官网活...
-
淘宝门户淘宝网怎么样从个人中心进入首页今日油条油条晚上炸好定型明天可再复炸吗?刘祚天还有DJ网么?www.kkk.comwww.kkk103.com网站产品质量有保证吗www.yahoo.com.hk香港有什么有名的娱乐门户网站吗?www.765.com下载小说地址www.baitu.com韩国片爱人.欲望的观看地址haole10.comwww.qq10eu.in是QQ网站吗抓站工具公司网站要备份,谁知道好用的网站抓取工具,能够抓取bbs论坛的。推荐一下,先谢过了!lcoc.toptop weenie 是什么?