卷积显存不足
显存不足 时间:2021-04-03 阅读:()
收稿日期:2011唱03唱01;修回日期:2011唱04唱11基金项目:国家自然科学基金资助项目(10978016,11003027);天津市科技支撑重点项目(09ZCKFGX00400)作者简介:杨沐津(1988唱),男,天津人,硕士研究生,主要研究方向为并行计算;于策(1979唱),男(通信作者),博士,主要研究方向为分布式并行计算、天文信息技术(yuce@tju.
edu.
cn);孙济洲(1949唱),男,教授,博导,主要研究方向为分布式并行计算、计算机图形学;曹玮(1986唱),男(回族),硕士,主要研究方向为分布式并行计算;陈锦言(1974唱),男,讲师,博士,主要研究方向为分布式计算;商朝晖(1966唱),男,教授,博士,主要研究方向为南极天文学;刘强(1982唱),男,助理研究员,博士,主要研究方向为南极天文学.
GAISP:一种GPU加速的天文图像相减测光算法倡杨沐津1,于策1报,孙济洲1,曹玮1,陈锦言1,商朝晖2,刘强3(1.
天津大学计算机科学与技术学院,天津300072;2.
天津师范大学天体物理中心,天津300387;3.
中国科学院国家天文台,北京100012)摘要:为了解决天文图像相减测光存在的性能问题,满足特殊条件下天文观测的实时性要求,在充分分析原始测光算法整体性能的基础上,结合CUDA并行编程模型,并行优化测光算法中模板图像降晰的计算,提出并实现了一种GPU加速的测光算法GAISP.
实验结果表明,GAISP在处理较大规模天文图像时,图像相减部分耗时较原始算法降低2/3.
关键词:图形处理器;相减测光;并行化;性能优化中图分类号:TP302文献标志码:A文章编号:1001唱3695(2011)10唱3940唱04doi:10.
3969/j.
issn.
1001唱3695.
2011.
10.
093GAISP:GPUacceleratedastronomicalimagesubtractionphotometryalgorithmYANGMu唱jin1,YUCe1报,SUNJi唱zhou1,CAOWei1,CHENJin唱yan1,SHANGZhao唱hui2,LIUQiang3(1.
SchoolofComputerScience&Technology,TianjinUniversity,Tianjin300072,China;2.
CentreforAstrophysics,TianjinNormalUniversi唱ty,Tianjin300387,China;3.
NationalAstronomicalObservatories,ChineseAcademyofSciences,Beijing100012,China)Abstract:Toaddressperformanceproblemaboutastronomicalimagesubtractionphotometryandmeettheastronomicalobser唱vationreal唱timerequirementsunderthespecialconditions,thispaperanalyzedtheoverallperformanceoftheoriginalphotome唱tryalgorithmandoptimizedthetemplateimageprocessingpartofthephotometryalgorithmwithCUDAprogrammingmodel.
ItdesignedandimplementednewphotometryalgorithmbasedonGPUnamedGAISP.
Theexperimentalresultshowsthattheim唱agesubtractionpartofGAISPincreaseaverageperformanceof2/3comparedwithtraditionalphotometryalgorithmwhenpro唱cessingthelargescaleimage.
Keywords:GPU;subtractionphotometry;parallelization;performanceoptimization天文图像相减测光是对同一天区不同时间所拍摄图像的差异进行分析,从而发现在一定时间内亮度变化的天体和短时间内发生较大变化的天文现象[1].
这是发现新天体或天文现象的重要依据[2,3].
随着天文望远镜观测能力的不断提高,观测得到的天文图像规模也越来越大,使得实时测光所需要处理的数据量大幅增加.
原始测光算法已经不能满足实时处理的要求,在考虑观测条件的基础上,不可避免地要依赖于并行计算技术.
因此,本文提出并实现了一种GPU加速的天文图像相减测光算法GAISP.
它较基于OpenMP的CPU多核并行算法的加速效果更为明显.
1天文图像相减测光算法1畅1相关工作天文图像相减测光算法由Tomaney等人[4]在1996年第一次提出并成功实现.
Alard等人[5]在1998年提出最佳图像相减(OIS)对其作进一步发展.
由于它能够解决完全最小二乘问题,OIS算法能够以接近光子噪声极限的精度产生相减后的图像和光变曲线.
它对于密集的星区效率特别高,而且适于大规模处理望远镜数据.
但由于使用固定卷积核对模板图像卷积进行降晰,因此只适用于图像较小且拍摄过程积分时间较短的图像,即整幅图像的PSF[4]变化不大的情况.
2000年Alard将此算法推广到利用空间可变的卷积核进行图像卷积降晰的图像相减[1],从而可以在处理大规模图像时也能取得较精确的检测结果.
此后,Israel等人[6]于2007年,Bramich[7]于2008年均在Alard的基础上,又进行了其他方面的尝试来改进算法,但是以上研究中没有专门涉及到测光算法在处理大规模天文图像时存在的性能问题.
对于算法的性能研究,李继良等人[8]在2010年提出了基于OpenMP的多核并行实现.
然而受CPU的并行粒度和计算能力所限,在处理较大规模图像时,性第28卷第10期2011年10月计算机应用研究ApplicationResearchofComputersVol.
28No.
10Oct.
2011能优化效果不够理想.
迫切需要对其算法基本原理和性能瓶颈进行分析,研究一种更加高效的并行相减测光算法.
1畅2基本原理及性能分析图像相减测光的核心思想是将同一天区不同时间拍摄的图像分别与该天区的模板图像进行相减,通过对差异图像进行分析寻找可能存在的变星.
其中模板图像主要选择拍摄清晰的图像或经过多幅图像叠加后产生的深度图像.
该算法主要包括三个处理步骤:a)图像注册.
即对拍摄的天文图像进行一定预处理,包括去除宇宙线干扰,将待测图像与标准模板对齐,通过一些统计、插值的算法平抑其与模板间轻微的偏移与旋转.
b)图像相减.
将清晰的模板图像通过卷积的算法降晰,使其PSF值与待测图像的差异最小化,进而进行相减运算,保存相减结果.
c)变源检测.
通过分析相减后的图像,找出两幅图像的明显差异,排除干扰后,记录此变源的坐标及时域信息等,进而可将变源按时序组织,形成光变曲线.
测光算法的核心部分为步骤b)的图像卷积降晰相减,如图1所示,其基本原理为,同一天区不同时刻拍摄的天文图像不能直接进行相减处理.
受不同的大气状态和云层遮挡等因素的影响,不同时间拍摄图像的清晰程度不同,同一颗星相减后无法完全消除其轮廓,会有残留的边缘,而且不同的亮度,导致图像相减后每颗星都会留有与其大小相同的圆斑,这些都会导致不能准确判断是否有变星.
因此需要在相减之前,对较清晰的模板图像进行卷积作降晰处理,使其与待测图像的清晰程度相近,然后再进行图像相减.
对于空间可变卷积核的图像相减方法,首先需要根据图像的不同位置求解相应的卷积核.
设卷积核系数为a(x,y),(x,y)为图像坐标.
根据R(x,y)倡K(x,y)=I(x,y),其中模板图像为二维函数R(x,y),处理图像为I(x,y),卷积核函数为K(x,y),这里倡代表卷积.
通过将对此方程组的求解转换为解线性最小二乘拟合问题,完成对卷积核系数的求解.
an(x,y)=钞dm=0钞d-ml=0an,m,lxmyl(1)将式(1)中的每个系数an(x,y)乘以一个基向量Kn,如式(2),得出相应的卷积核.
K(x,y)=钞Nn=1an(x,y)Kn(2)对图像的每个子区域运用式(1)(2)计算合成该区域的卷积核,进而对该子图进行卷积运算.
因此模板图像的卷积计算的复杂度高,为O(mnk2),其中,n和m分别为模板图像的长和宽,k为卷积核的边长.
后续分析相减部分的高复杂度对测光算法整体性能的影响.
AST3[9]计划在南极大陆的最高点冰穹A建立三个施密特天文望远镜.
作为最新一代地面光学望远镜,AST3的每个望远镜配备了10K*10K的CCD相机,可以拍摄规模为10K*10K的天文图像.
基于此,事先制作好规模为10K*10K的模拟图像,使用相减测光算法测试单幅图像的一次测光流程耗时约为6min.
无法满足AST3的数据实时处理的要求.
考虑采用一种基于多任务的简单并行机制使原有程序在不作任何修改的条件下达到在多核处理器主机上的性能提升.
其思路是在计算机上同时启动多个针对不同输入的计算流程,通过多任务的并行来提高总的执行效率.
这种方式在小数据(256*256规模图像)情形下被证明是比较有效的[9].
然而随着输入图像规模的增大,单个任务所消耗的内存空间、计算时间等也随之增加,此时运行多任务将导致主存空间的耗尽.
由于需要使用位于磁盘的虚拟内存,系统性能严重下降.
分析相减测光中各部分计算比重,如表1所示.
图像相减部分占到了整个流程的50%以上,约为3min.
进一步分析卷积相减部分,其中模板图像的卷积降晰占据了图像相减80%的计算时间,是整个相减测光的主要瓶颈.
而在相减测光中,模板图像可以事先确定,也可能在测光的过程中,随着观测到的图像而不断制作更新.
在制作模板的过程中,同样需要多次进行图像的卷积相减.
因此需要对此瓶颈部分进行并行优化以提升性能.
表1相减测光流程各部分运行时间比例测光流程任务运行时间所占比例/%图像注册34.
65图像相减51.
02变源检测14.
32注:测试图像为10K*10K模拟图像2基于CUDA的GPU通用计算目前,图形处理单元(graphicsprocessingunit,GPU)已发展成为一种高度并行化、多线程、多核的处理器,与CPU有本质区别.
传统的CPU只有一个可执行线程,较为先进的CPU上会集成数量极其有限的几个处理器核心,仅可以进行小规模的并行计算处理.
GPU的设计能使更多晶体管用于数据处理,而非数据缓存和流控制.
因此,GPU可以存在成百上千个并行线程,且具有杰出的计算功率和极高的存储器带宽,相对CPU有明显的优势.
但是传统上,GPU的应用只是被局限于处理图形渲染的计算任务,随着GPU可编程性的不断提高,对GPU的通用计算研究越来越广泛[10].
由此,产生了一些为GPU通用计算研究应用的开发环境,如OpenCL[11]、NVIDIA公司的CUDA[12]等.
本文的工作主要借助CUDA展开.
CUDA是一种将GPU作为数据并行计算设备的软/硬件体系.
CUDA提供了一种具有线程组层次结构、共享存储器等特点的可伸缩并行编程模型并采用了SIMT(singleinstructionmultiplethread,单指令多线程)执行模型,将计算任务映射为大量可以并行执行的线程,并由拥有大量内核的GPU动态调度和执行这些线程,从而显著提高运算速度[13].
如图2所示,运行在GPU上的CUDA并行计算函数称为内核函数(kernel),一个kernel函数并不是一个完整的程序,而是整个CUDA程序中的一个可以被并行执行的步骤.
Kernel函数以线程网格(grid)的形式组织,每个线程网格由若干个线程块(block)组成,而每个线程块又由若干个线程(thread)组成.
因此,一个kernel函数中存在两个层次的并行,即grid中的block间并行和block中的thread间并行.
各block是并行执行的,block之间无法通信,也没有执行顺序.
这样,无论是只能同时处理一个线程块的GPU上,还是在能同时处理数十个乃至上百个线程块的GPU上,这一编程模型都能很好地适用[13].
·1493·第10期杨沐津,等:GAISP:一种GPU加速的天文图像相减测光算法由于CPU与GPU在对程序执行的方式上有很大的区别.
因此,一般来说,并非所有的算法都适合在GPU上运行,如复杂逻辑处理和事务管理等不适合数据并行的计算,不宜使用GPU.
而GPU对于处理程序中计算密集型的大规模数据的并行计算,尤其是CPU不擅长的浮点运算,往往能够取得十分明显的性能提升[13].
由于相减测光过程中图像数据和卷积核等都是浮点型数据,因此无论是在卷积核的求解还是计算卷积图像的过程中,都要进行大量的浮点运算.
当处理较大规模图像时,计算量更是大幅增加.
这就非常适合利用GPU处理这些计算任务.
基于以上原因,借助CUDA模型对此算法并行优化,并通过GPU获得比较理想的加速效果,是本文的工作重点,具体内容见第3章.
CUDA并行线程模型如图2所示.
3GAISP设计实现在原始串行算法的模板图像卷积降晰过程中,首先根据待测图像和模板图像反解某一部分图像的相应卷积核,之后对与卷积核大小相同的相应位置子图像进行卷积计算.
图像的各个部分都求解不同的卷积核并进行卷积,需要循环遍历图像各个部分并计算,所以其效率和计算速度都非常低.
结合CUDA编程模型中线程组织特点,分析原始算法,将整个待卷积处理的图像的所有计算任务交给一个GPU线程网格内的线程执行完成.
按照卷积核大小将图像分成大小相等的若干子区域,卷积核以规模为K*K的二维浮点数据存储,图像被分为多块K*K的子图,而在具有1.
3计算能力的支持CUDA编程模型的GPU中,每个线程块的最大线程数为512[12],则令K取19,可以使每一子区域的卷积核和图像卷积计算由一个包含19*19个线程的线程块计算完成,即块中每个线程只依次完成卷积核的一个点值的计算和图像的一个点的卷积计算,而且仍能取得与原始算法相同的模板图像的降晰效果.
此时计算任务以两级并行层次划分,即线程网格内处理图像各子区域的计算任务的并行,以及每个线程块内的线程处理一个卷积核对应的图像区域的计算任务的并行.
这样在CUDA的SIMT执行模型下,对计算任务进行细粒度的划分,能够充分发挥GPU强大并行运算能力.
对于采用空间可变卷积核的相减算法,每个线程块的线程都需要计算一个不同的卷积核.
如果同时为所有线程块的卷积核分配显存,当处理图像过大时,在仅启动一个GPU核函数时,由于需要向显存传递过多的数据,会因显存不足而导致线程发射失败.
而如果划分计算任务,启动多次GPU核函数时,主机与设备(主存与显存)之间多次的数据传递会严重影响性能.
结合CUDA存储模型,线程块内的所有线程共享访问共享存储器(sharedmemory)中的数据,共享存储的读写速度相比显存快得多[12].
因此为卷积核分配共享存储,能够保证块内卷积核数据可被块内线程共享利用,减少重复计算,避免因存储不同位置图像卷积核数据导致的大量显存空间消耗,并大幅提升性能.
在计算卷积核时,块内各线程不能做到刚好同时完成卷积核的计算任务,因此这里需要执行块内线程同步,使后续卷积计算是在整个卷积核计算完成的前提下进行,保证得到正确的计算结果.
这样,GAISP模板图像卷积降晰步骤如下:a)在设备端分配用于存放模板图像、卷积图像及系数向量的空间,将模板图像数据及之前由CPU负责计算的系数矩阵的结果由主机端拷贝至设备端相应的位置.
将图像按照卷积核大小分为多个K*K的子块(K为卷积核边长),每个子图部分分给一个线程块处理.
在子图范围内,每个点的值由一个线程计算,因此每个线程块中包括K*K个线程,以(x,y)二维坐标标志其ID.
b)每个线程块内部:每个线程根据其ID计算卷积核的相应项,保存到共享存储中,供后续卷积计算.
c)同步线程块内的线程,确保卷积核计算完成.
d)根据线程的二维ID(x,y)计算子图中相应位置的卷积值,并存入卷积结果图像数组的对应位置.
e)线程网格内所有线程块计算完成后,将卷积结果图像数据由设备端传回到主机端,释放设备端显存空间,并在主机端进行后续相减计算.
GPU核函数部分伪代码如下:doubled_image[]//模板图像doubled_conv_image[]//卷积后图像doubled_kernel_sol[]//系数向量doubled_kernel_vec[]//基向量__global__voidd_kernel_convolveGPU(){__shared__doubled_kernel_coeffs[]//将卷积核系数和卷积核声明为共享存储__shared__doubled_kernel[]//由线程块号定位相应的图像子区域i1←blockIdx.
xj1←blockIdx.
y//块内线程号定位单个线程具体计算任务i2←threadIdx.
xj2←threadIdx.
ykernel_coeffs[]←dokernel_coefficient(d_kernel_sol[])//计算卷积核系数__syncthreads();//块内线程同步kernel[]←dokernel(d_kernel_coeffs[])//计算卷积核__syncthreads();//块内线程同步fori0←ic_starttoic_enddo//计算图像卷积forj0←jc_starttojc_enddoqim←d_image[i0,j0]qk←d_kernel[ik,jk]doconvolve(qim,qk)endforendford_conv_image[i,j]←convolveresult//存储卷积计算结果}4性能与结果分析程序运行采用Linux平台,主机CPU为Intel溍CoreTMi72.
67GHzCPU,内存12GB.
用来运行CUDA程序的显卡采用具有1.
3计算能力的NVIDIAGeForceGTX260,其标量流处理器数量为192,核心频率576MHz,处理器频率1242MHz,显存1792MBGDDR3.
实验测试数据为fits格式的天文图像文件.
·2493·计算机应用研究第28卷4畅1性能分析分别采用1K*1K、2K*2K、2.
5K*2.
5K、10K*5K及10K*10K不同规模的fits图像作为输入,测试在不同计算量下GAISP与OpenMP多核CPU并行算法[8]、原始测光算法[1]的性能对比.
由图3可得,线程数设为4的OpenMP卷积程序的优化效果受限于CPU核心数量,仅仅在处理1K*1K图像时,性能优于原始串行算法和GAISP.
当数据规模变大时,虽然OpenMP卷积处理取得了将近4倍的加速效果,但由于CPU处理器核心数量的限制和不擅长浮点运算的架构限制,加速效果已接近极限.
从相对计算量来说,GAISP处理1K*1K图像时,并行部分的计算量在整个应用中所占的比例不大,此时主机设备之间的数据传递和其他CPU数据处理及调度执行的时间比例较大,整体速度提高仅2倍左右.
当图像规模增大时,GPU核函数的计算量大大增加,加速效果明显.
当处理10K*10K的图像时,卷积部分较原始算法速度提高10倍以上.
如图4所示,GAISP的图像相减部分耗时由178s左右缩短为54s左右,较原始算法缩短124s,相减部分耗时降低了2/3.
4畅2误差分析CPU和GPU的运算单元采用了不同的微架构,即使都符合IEEE754规范,结果也会有细微差别.
CPU可以使用更长字长的存储器来保存中间变量,因此通常使用CPU计算得到的结果准确性要略高一些.
图5(c)(d)分别为原始算法和GAISP相对待测图像(a),对模板图像(b)的卷积降晰结果,要对图5(d)的计算结果的准确性进行分析.
表2为GAISP计算结果相对原始算法产生的绝对误差和相对误差.
表2GAISP相对原始测光算法产生的误差最大相对误差平均相对误差最大绝对误差平均绝对误差9.
737e-082.
130e-149.
536e-072.
843e-13由表2所示,误差非常细微.
经过进一步测试,GAISP检测变源的结果包括变源数量和相应参数,均与原始算法的计算结果完全相同.
GAISP能够保证变源检测结果的正确性.
5结束语本文对传统天文图像相减测光算法进行分析,着重分析性能瓶颈,提出并实现了基于GPU加速的并行算法GAISP.
GAISP较原始算法和基于OpenMP的CPU多线程算法性能得到明显提升.
考虑到在南极进行越冬天文观测的能源条件限制,不可能采用功耗过大的高性能计算设备,必须在有限硬件条件下,通过并行优化现有算法来满足实时性的要求.
GAISP为满足AST3实时数据处理系统的每2.
4min200MB数据的实时处理[9],奠定了一定的基础.
而随着天文观测水平的不断提高,天文望远镜能够拍摄的图像规模也会不断增大,预计几年内观测图像规模可达70K*70K乃至更大,数据实时处理的任务也越来越艰巨.
因此,在未来能够提供足够能源的条件下,考虑结合使用具有更强计算能力的GPU和CPU,设计新的并行算法,或者结合算法和实验数据设计专用硬件从而满足数据实时处理的要求.
参考文献:[1]ALARDC.
Imagesubtractionusingaspace唱varyingkernel[J].
As唱tronomyandAstrophysicsSupplementSeries,2000,144(2):363唱370.
[2]LAYDENAC,BRODERICKAJ,POHLBL,etal.
Searchingforlong唱periodvariablesinglobularclusters:ademonstrationonNGC1851usingPROMPT[J].
PublicationsofTheAstronomicalSocie唱tyofthePacific,2010,122(895):1000唱1007.
[3]NATAFDM,STANEKKZ,BAKOSGA.
Findingthebrightestgalac唱ticbulgemicrolensingeventswithasmallaperturetelescopeandim唱agesubtraction[J].
ActaAstronomica,2009,59(3):255唱272.
[4]TOMANEYA,CROTTSA.
Expandingtherealmofmicrolensingsur唱veyswithdifferenceimagephotometry[J].
TheAstronomicalJour唱nal,1996,112(6):2872唱2895.
[5]ALARDC,LUPTONRH.
Amethodforoptimalimagesubtraction[J].
TheAstrophysicalJournal,1998,503(1):325唱331.
[6]ISRAELH,HESSMANFV,SCHUHS.
Optimisingoptimalimagesub唱traction[J].
AstronomischeNachrichten,2007,328(1):16唱24.
[7]BRAMICHDM.
Anewalgorithmfordifferenceimageanalysis[J].
MonthlyNoticesoftheRoyalAstronomicalSociety,2008,386(1):77唱81.
[8]李继良,于策,孙济洲,等.
基于OpenMP的并行图像相减算法实现与分析[J].
天文研究与技术,2010,7(3):146唱152.
[9]吕立强.
AST3_RPS系统架构和关键算法研究[D].
天津:天津大学,2009.
[10]王磊,张春燕.
基于图形处理器的通用计算模式[J].
计算机应用研究,2009,26(6):2356唱2358.
[11]KhronosOpenCLWorkingGroup.
TheOpenCLspecification[EB/OL].
(2010唱09唱30)[2011].
http://www.
khronos.
org/registry/cl/specs/opencl唱1.
1.
pdf.
[12]NVIDIACorporation.
NVIDIACUDACprogrammingguide[EB/OL].
(2010唱10唱22)[2011].
http://developer.
download.
nvidia.
com/compute/cuda/3_2/toolkit/docs/CUDA_C_Programming_Guide.
pdf.
[13]张舒,褚艳利,赵开勇,等.
GPU高性能运算之CUDA[M].
北京:中国水利水电出版社,2009:1唱21.
·3493·第10期杨沐津,等:GAISP:一种GPU加速的天文图像相减测光算法
edu.
cn);孙济洲(1949唱),男,教授,博导,主要研究方向为分布式并行计算、计算机图形学;曹玮(1986唱),男(回族),硕士,主要研究方向为分布式并行计算;陈锦言(1974唱),男,讲师,博士,主要研究方向为分布式计算;商朝晖(1966唱),男,教授,博士,主要研究方向为南极天文学;刘强(1982唱),男,助理研究员,博士,主要研究方向为南极天文学.
GAISP:一种GPU加速的天文图像相减测光算法倡杨沐津1,于策1报,孙济洲1,曹玮1,陈锦言1,商朝晖2,刘强3(1.
天津大学计算机科学与技术学院,天津300072;2.
天津师范大学天体物理中心,天津300387;3.
中国科学院国家天文台,北京100012)摘要:为了解决天文图像相减测光存在的性能问题,满足特殊条件下天文观测的实时性要求,在充分分析原始测光算法整体性能的基础上,结合CUDA并行编程模型,并行优化测光算法中模板图像降晰的计算,提出并实现了一种GPU加速的测光算法GAISP.
实验结果表明,GAISP在处理较大规模天文图像时,图像相减部分耗时较原始算法降低2/3.
关键词:图形处理器;相减测光;并行化;性能优化中图分类号:TP302文献标志码:A文章编号:1001唱3695(2011)10唱3940唱04doi:10.
3969/j.
issn.
1001唱3695.
2011.
10.
093GAISP:GPUacceleratedastronomicalimagesubtractionphotometryalgorithmYANGMu唱jin1,YUCe1报,SUNJi唱zhou1,CAOWei1,CHENJin唱yan1,SHANGZhao唱hui2,LIUQiang3(1.
SchoolofComputerScience&Technology,TianjinUniversity,Tianjin300072,China;2.
CentreforAstrophysics,TianjinNormalUniversi唱ty,Tianjin300387,China;3.
NationalAstronomicalObservatories,ChineseAcademyofSciences,Beijing100012,China)Abstract:Toaddressperformanceproblemaboutastronomicalimagesubtractionphotometryandmeettheastronomicalobser唱vationreal唱timerequirementsunderthespecialconditions,thispaperanalyzedtheoverallperformanceoftheoriginalphotome唱tryalgorithmandoptimizedthetemplateimageprocessingpartofthephotometryalgorithmwithCUDAprogrammingmodel.
ItdesignedandimplementednewphotometryalgorithmbasedonGPUnamedGAISP.
Theexperimentalresultshowsthattheim唱agesubtractionpartofGAISPincreaseaverageperformanceof2/3comparedwithtraditionalphotometryalgorithmwhenpro唱cessingthelargescaleimage.
Keywords:GPU;subtractionphotometry;parallelization;performanceoptimization天文图像相减测光是对同一天区不同时间所拍摄图像的差异进行分析,从而发现在一定时间内亮度变化的天体和短时间内发生较大变化的天文现象[1].
这是发现新天体或天文现象的重要依据[2,3].
随着天文望远镜观测能力的不断提高,观测得到的天文图像规模也越来越大,使得实时测光所需要处理的数据量大幅增加.
原始测光算法已经不能满足实时处理的要求,在考虑观测条件的基础上,不可避免地要依赖于并行计算技术.
因此,本文提出并实现了一种GPU加速的天文图像相减测光算法GAISP.
它较基于OpenMP的CPU多核并行算法的加速效果更为明显.
1天文图像相减测光算法1畅1相关工作天文图像相减测光算法由Tomaney等人[4]在1996年第一次提出并成功实现.
Alard等人[5]在1998年提出最佳图像相减(OIS)对其作进一步发展.
由于它能够解决完全最小二乘问题,OIS算法能够以接近光子噪声极限的精度产生相减后的图像和光变曲线.
它对于密集的星区效率特别高,而且适于大规模处理望远镜数据.
但由于使用固定卷积核对模板图像卷积进行降晰,因此只适用于图像较小且拍摄过程积分时间较短的图像,即整幅图像的PSF[4]变化不大的情况.
2000年Alard将此算法推广到利用空间可变的卷积核进行图像卷积降晰的图像相减[1],从而可以在处理大规模图像时也能取得较精确的检测结果.
此后,Israel等人[6]于2007年,Bramich[7]于2008年均在Alard的基础上,又进行了其他方面的尝试来改进算法,但是以上研究中没有专门涉及到测光算法在处理大规模天文图像时存在的性能问题.
对于算法的性能研究,李继良等人[8]在2010年提出了基于OpenMP的多核并行实现.
然而受CPU的并行粒度和计算能力所限,在处理较大规模图像时,性第28卷第10期2011年10月计算机应用研究ApplicationResearchofComputersVol.
28No.
10Oct.
2011能优化效果不够理想.
迫切需要对其算法基本原理和性能瓶颈进行分析,研究一种更加高效的并行相减测光算法.
1畅2基本原理及性能分析图像相减测光的核心思想是将同一天区不同时间拍摄的图像分别与该天区的模板图像进行相减,通过对差异图像进行分析寻找可能存在的变星.
其中模板图像主要选择拍摄清晰的图像或经过多幅图像叠加后产生的深度图像.
该算法主要包括三个处理步骤:a)图像注册.
即对拍摄的天文图像进行一定预处理,包括去除宇宙线干扰,将待测图像与标准模板对齐,通过一些统计、插值的算法平抑其与模板间轻微的偏移与旋转.
b)图像相减.
将清晰的模板图像通过卷积的算法降晰,使其PSF值与待测图像的差异最小化,进而进行相减运算,保存相减结果.
c)变源检测.
通过分析相减后的图像,找出两幅图像的明显差异,排除干扰后,记录此变源的坐标及时域信息等,进而可将变源按时序组织,形成光变曲线.
测光算法的核心部分为步骤b)的图像卷积降晰相减,如图1所示,其基本原理为,同一天区不同时刻拍摄的天文图像不能直接进行相减处理.
受不同的大气状态和云层遮挡等因素的影响,不同时间拍摄图像的清晰程度不同,同一颗星相减后无法完全消除其轮廓,会有残留的边缘,而且不同的亮度,导致图像相减后每颗星都会留有与其大小相同的圆斑,这些都会导致不能准确判断是否有变星.
因此需要在相减之前,对较清晰的模板图像进行卷积作降晰处理,使其与待测图像的清晰程度相近,然后再进行图像相减.
对于空间可变卷积核的图像相减方法,首先需要根据图像的不同位置求解相应的卷积核.
设卷积核系数为a(x,y),(x,y)为图像坐标.
根据R(x,y)倡K(x,y)=I(x,y),其中模板图像为二维函数R(x,y),处理图像为I(x,y),卷积核函数为K(x,y),这里倡代表卷积.
通过将对此方程组的求解转换为解线性最小二乘拟合问题,完成对卷积核系数的求解.
an(x,y)=钞dm=0钞d-ml=0an,m,lxmyl(1)将式(1)中的每个系数an(x,y)乘以一个基向量Kn,如式(2),得出相应的卷积核.
K(x,y)=钞Nn=1an(x,y)Kn(2)对图像的每个子区域运用式(1)(2)计算合成该区域的卷积核,进而对该子图进行卷积运算.
因此模板图像的卷积计算的复杂度高,为O(mnk2),其中,n和m分别为模板图像的长和宽,k为卷积核的边长.
后续分析相减部分的高复杂度对测光算法整体性能的影响.
AST3[9]计划在南极大陆的最高点冰穹A建立三个施密特天文望远镜.
作为最新一代地面光学望远镜,AST3的每个望远镜配备了10K*10K的CCD相机,可以拍摄规模为10K*10K的天文图像.
基于此,事先制作好规模为10K*10K的模拟图像,使用相减测光算法测试单幅图像的一次测光流程耗时约为6min.
无法满足AST3的数据实时处理的要求.
考虑采用一种基于多任务的简单并行机制使原有程序在不作任何修改的条件下达到在多核处理器主机上的性能提升.
其思路是在计算机上同时启动多个针对不同输入的计算流程,通过多任务的并行来提高总的执行效率.
这种方式在小数据(256*256规模图像)情形下被证明是比较有效的[9].
然而随着输入图像规模的增大,单个任务所消耗的内存空间、计算时间等也随之增加,此时运行多任务将导致主存空间的耗尽.
由于需要使用位于磁盘的虚拟内存,系统性能严重下降.
分析相减测光中各部分计算比重,如表1所示.
图像相减部分占到了整个流程的50%以上,约为3min.
进一步分析卷积相减部分,其中模板图像的卷积降晰占据了图像相减80%的计算时间,是整个相减测光的主要瓶颈.
而在相减测光中,模板图像可以事先确定,也可能在测光的过程中,随着观测到的图像而不断制作更新.
在制作模板的过程中,同样需要多次进行图像的卷积相减.
因此需要对此瓶颈部分进行并行优化以提升性能.
表1相减测光流程各部分运行时间比例测光流程任务运行时间所占比例/%图像注册34.
65图像相减51.
02变源检测14.
32注:测试图像为10K*10K模拟图像2基于CUDA的GPU通用计算目前,图形处理单元(graphicsprocessingunit,GPU)已发展成为一种高度并行化、多线程、多核的处理器,与CPU有本质区别.
传统的CPU只有一个可执行线程,较为先进的CPU上会集成数量极其有限的几个处理器核心,仅可以进行小规模的并行计算处理.
GPU的设计能使更多晶体管用于数据处理,而非数据缓存和流控制.
因此,GPU可以存在成百上千个并行线程,且具有杰出的计算功率和极高的存储器带宽,相对CPU有明显的优势.
但是传统上,GPU的应用只是被局限于处理图形渲染的计算任务,随着GPU可编程性的不断提高,对GPU的通用计算研究越来越广泛[10].
由此,产生了一些为GPU通用计算研究应用的开发环境,如OpenCL[11]、NVIDIA公司的CUDA[12]等.
本文的工作主要借助CUDA展开.
CUDA是一种将GPU作为数据并行计算设备的软/硬件体系.
CUDA提供了一种具有线程组层次结构、共享存储器等特点的可伸缩并行编程模型并采用了SIMT(singleinstructionmultiplethread,单指令多线程)执行模型,将计算任务映射为大量可以并行执行的线程,并由拥有大量内核的GPU动态调度和执行这些线程,从而显著提高运算速度[13].
如图2所示,运行在GPU上的CUDA并行计算函数称为内核函数(kernel),一个kernel函数并不是一个完整的程序,而是整个CUDA程序中的一个可以被并行执行的步骤.
Kernel函数以线程网格(grid)的形式组织,每个线程网格由若干个线程块(block)组成,而每个线程块又由若干个线程(thread)组成.
因此,一个kernel函数中存在两个层次的并行,即grid中的block间并行和block中的thread间并行.
各block是并行执行的,block之间无法通信,也没有执行顺序.
这样,无论是只能同时处理一个线程块的GPU上,还是在能同时处理数十个乃至上百个线程块的GPU上,这一编程模型都能很好地适用[13].
·1493·第10期杨沐津,等:GAISP:一种GPU加速的天文图像相减测光算法由于CPU与GPU在对程序执行的方式上有很大的区别.
因此,一般来说,并非所有的算法都适合在GPU上运行,如复杂逻辑处理和事务管理等不适合数据并行的计算,不宜使用GPU.
而GPU对于处理程序中计算密集型的大规模数据的并行计算,尤其是CPU不擅长的浮点运算,往往能够取得十分明显的性能提升[13].
由于相减测光过程中图像数据和卷积核等都是浮点型数据,因此无论是在卷积核的求解还是计算卷积图像的过程中,都要进行大量的浮点运算.
当处理较大规模图像时,计算量更是大幅增加.
这就非常适合利用GPU处理这些计算任务.
基于以上原因,借助CUDA模型对此算法并行优化,并通过GPU获得比较理想的加速效果,是本文的工作重点,具体内容见第3章.
CUDA并行线程模型如图2所示.
3GAISP设计实现在原始串行算法的模板图像卷积降晰过程中,首先根据待测图像和模板图像反解某一部分图像的相应卷积核,之后对与卷积核大小相同的相应位置子图像进行卷积计算.
图像的各个部分都求解不同的卷积核并进行卷积,需要循环遍历图像各个部分并计算,所以其效率和计算速度都非常低.
结合CUDA编程模型中线程组织特点,分析原始算法,将整个待卷积处理的图像的所有计算任务交给一个GPU线程网格内的线程执行完成.
按照卷积核大小将图像分成大小相等的若干子区域,卷积核以规模为K*K的二维浮点数据存储,图像被分为多块K*K的子图,而在具有1.
3计算能力的支持CUDA编程模型的GPU中,每个线程块的最大线程数为512[12],则令K取19,可以使每一子区域的卷积核和图像卷积计算由一个包含19*19个线程的线程块计算完成,即块中每个线程只依次完成卷积核的一个点值的计算和图像的一个点的卷积计算,而且仍能取得与原始算法相同的模板图像的降晰效果.
此时计算任务以两级并行层次划分,即线程网格内处理图像各子区域的计算任务的并行,以及每个线程块内的线程处理一个卷积核对应的图像区域的计算任务的并行.
这样在CUDA的SIMT执行模型下,对计算任务进行细粒度的划分,能够充分发挥GPU强大并行运算能力.
对于采用空间可变卷积核的相减算法,每个线程块的线程都需要计算一个不同的卷积核.
如果同时为所有线程块的卷积核分配显存,当处理图像过大时,在仅启动一个GPU核函数时,由于需要向显存传递过多的数据,会因显存不足而导致线程发射失败.
而如果划分计算任务,启动多次GPU核函数时,主机与设备(主存与显存)之间多次的数据传递会严重影响性能.
结合CUDA存储模型,线程块内的所有线程共享访问共享存储器(sharedmemory)中的数据,共享存储的读写速度相比显存快得多[12].
因此为卷积核分配共享存储,能够保证块内卷积核数据可被块内线程共享利用,减少重复计算,避免因存储不同位置图像卷积核数据导致的大量显存空间消耗,并大幅提升性能.
在计算卷积核时,块内各线程不能做到刚好同时完成卷积核的计算任务,因此这里需要执行块内线程同步,使后续卷积计算是在整个卷积核计算完成的前提下进行,保证得到正确的计算结果.
这样,GAISP模板图像卷积降晰步骤如下:a)在设备端分配用于存放模板图像、卷积图像及系数向量的空间,将模板图像数据及之前由CPU负责计算的系数矩阵的结果由主机端拷贝至设备端相应的位置.
将图像按照卷积核大小分为多个K*K的子块(K为卷积核边长),每个子图部分分给一个线程块处理.
在子图范围内,每个点的值由一个线程计算,因此每个线程块中包括K*K个线程,以(x,y)二维坐标标志其ID.
b)每个线程块内部:每个线程根据其ID计算卷积核的相应项,保存到共享存储中,供后续卷积计算.
c)同步线程块内的线程,确保卷积核计算完成.
d)根据线程的二维ID(x,y)计算子图中相应位置的卷积值,并存入卷积结果图像数组的对应位置.
e)线程网格内所有线程块计算完成后,将卷积结果图像数据由设备端传回到主机端,释放设备端显存空间,并在主机端进行后续相减计算.
GPU核函数部分伪代码如下:doubled_image[]//模板图像doubled_conv_image[]//卷积后图像doubled_kernel_sol[]//系数向量doubled_kernel_vec[]//基向量__global__voidd_kernel_convolveGPU(){__shared__doubled_kernel_coeffs[]//将卷积核系数和卷积核声明为共享存储__shared__doubled_kernel[]//由线程块号定位相应的图像子区域i1←blockIdx.
xj1←blockIdx.
y//块内线程号定位单个线程具体计算任务i2←threadIdx.
xj2←threadIdx.
ykernel_coeffs[]←dokernel_coefficient(d_kernel_sol[])//计算卷积核系数__syncthreads();//块内线程同步kernel[]←dokernel(d_kernel_coeffs[])//计算卷积核__syncthreads();//块内线程同步fori0←ic_starttoic_enddo//计算图像卷积forj0←jc_starttojc_enddoqim←d_image[i0,j0]qk←d_kernel[ik,jk]doconvolve(qim,qk)endforendford_conv_image[i,j]←convolveresult//存储卷积计算结果}4性能与结果分析程序运行采用Linux平台,主机CPU为Intel溍CoreTMi72.
67GHzCPU,内存12GB.
用来运行CUDA程序的显卡采用具有1.
3计算能力的NVIDIAGeForceGTX260,其标量流处理器数量为192,核心频率576MHz,处理器频率1242MHz,显存1792MBGDDR3.
实验测试数据为fits格式的天文图像文件.
·2493·计算机应用研究第28卷4畅1性能分析分别采用1K*1K、2K*2K、2.
5K*2.
5K、10K*5K及10K*10K不同规模的fits图像作为输入,测试在不同计算量下GAISP与OpenMP多核CPU并行算法[8]、原始测光算法[1]的性能对比.
由图3可得,线程数设为4的OpenMP卷积程序的优化效果受限于CPU核心数量,仅仅在处理1K*1K图像时,性能优于原始串行算法和GAISP.
当数据规模变大时,虽然OpenMP卷积处理取得了将近4倍的加速效果,但由于CPU处理器核心数量的限制和不擅长浮点运算的架构限制,加速效果已接近极限.
从相对计算量来说,GAISP处理1K*1K图像时,并行部分的计算量在整个应用中所占的比例不大,此时主机设备之间的数据传递和其他CPU数据处理及调度执行的时间比例较大,整体速度提高仅2倍左右.
当图像规模增大时,GPU核函数的计算量大大增加,加速效果明显.
当处理10K*10K的图像时,卷积部分较原始算法速度提高10倍以上.
如图4所示,GAISP的图像相减部分耗时由178s左右缩短为54s左右,较原始算法缩短124s,相减部分耗时降低了2/3.
4畅2误差分析CPU和GPU的运算单元采用了不同的微架构,即使都符合IEEE754规范,结果也会有细微差别.
CPU可以使用更长字长的存储器来保存中间变量,因此通常使用CPU计算得到的结果准确性要略高一些.
图5(c)(d)分别为原始算法和GAISP相对待测图像(a),对模板图像(b)的卷积降晰结果,要对图5(d)的计算结果的准确性进行分析.
表2为GAISP计算结果相对原始算法产生的绝对误差和相对误差.
表2GAISP相对原始测光算法产生的误差最大相对误差平均相对误差最大绝对误差平均绝对误差9.
737e-082.
130e-149.
536e-072.
843e-13由表2所示,误差非常细微.
经过进一步测试,GAISP检测变源的结果包括变源数量和相应参数,均与原始算法的计算结果完全相同.
GAISP能够保证变源检测结果的正确性.
5结束语本文对传统天文图像相减测光算法进行分析,着重分析性能瓶颈,提出并实现了基于GPU加速的并行算法GAISP.
GAISP较原始算法和基于OpenMP的CPU多线程算法性能得到明显提升.
考虑到在南极进行越冬天文观测的能源条件限制,不可能采用功耗过大的高性能计算设备,必须在有限硬件条件下,通过并行优化现有算法来满足实时性的要求.
GAISP为满足AST3实时数据处理系统的每2.
4min200MB数据的实时处理[9],奠定了一定的基础.
而随着天文观测水平的不断提高,天文望远镜能够拍摄的图像规模也会不断增大,预计几年内观测图像规模可达70K*70K乃至更大,数据实时处理的任务也越来越艰巨.
因此,在未来能够提供足够能源的条件下,考虑结合使用具有更强计算能力的GPU和CPU,设计新的并行算法,或者结合算法和实验数据设计专用硬件从而满足数据实时处理的要求.
参考文献:[1]ALARDC.
Imagesubtractionusingaspace唱varyingkernel[J].
As唱tronomyandAstrophysicsSupplementSeries,2000,144(2):363唱370.
[2]LAYDENAC,BRODERICKAJ,POHLBL,etal.
Searchingforlong唱periodvariablesinglobularclusters:ademonstrationonNGC1851usingPROMPT[J].
PublicationsofTheAstronomicalSocie唱tyofthePacific,2010,122(895):1000唱1007.
[3]NATAFDM,STANEKKZ,BAKOSGA.
Findingthebrightestgalac唱ticbulgemicrolensingeventswithasmallaperturetelescopeandim唱agesubtraction[J].
ActaAstronomica,2009,59(3):255唱272.
[4]TOMANEYA,CROTTSA.
Expandingtherealmofmicrolensingsur唱veyswithdifferenceimagephotometry[J].
TheAstronomicalJour唱nal,1996,112(6):2872唱2895.
[5]ALARDC,LUPTONRH.
Amethodforoptimalimagesubtraction[J].
TheAstrophysicalJournal,1998,503(1):325唱331.
[6]ISRAELH,HESSMANFV,SCHUHS.
Optimisingoptimalimagesub唱traction[J].
AstronomischeNachrichten,2007,328(1):16唱24.
[7]BRAMICHDM.
Anewalgorithmfordifferenceimageanalysis[J].
MonthlyNoticesoftheRoyalAstronomicalSociety,2008,386(1):77唱81.
[8]李继良,于策,孙济洲,等.
基于OpenMP的并行图像相减算法实现与分析[J].
天文研究与技术,2010,7(3):146唱152.
[9]吕立强.
AST3_RPS系统架构和关键算法研究[D].
天津:天津大学,2009.
[10]王磊,张春燕.
基于图形处理器的通用计算模式[J].
计算机应用研究,2009,26(6):2356唱2358.
[11]KhronosOpenCLWorkingGroup.
TheOpenCLspecification[EB/OL].
(2010唱09唱30)[2011].
http://www.
khronos.
org/registry/cl/specs/opencl唱1.
1.
pdf.
[12]NVIDIACorporation.
NVIDIACUDACprogrammingguide[EB/OL].
(2010唱10唱22)[2011].
http://developer.
download.
nvidia.
com/compute/cuda/3_2/toolkit/docs/CUDA_C_Programming_Guide.
pdf.
[13]张舒,褚艳利,赵开勇,等.
GPU高性能运算之CUDA[M].
北京:中国水利水电出版社,2009:1唱21.
·3493·第10期杨沐津,等:GAISP:一种GPU加速的天文图像相减测光算法
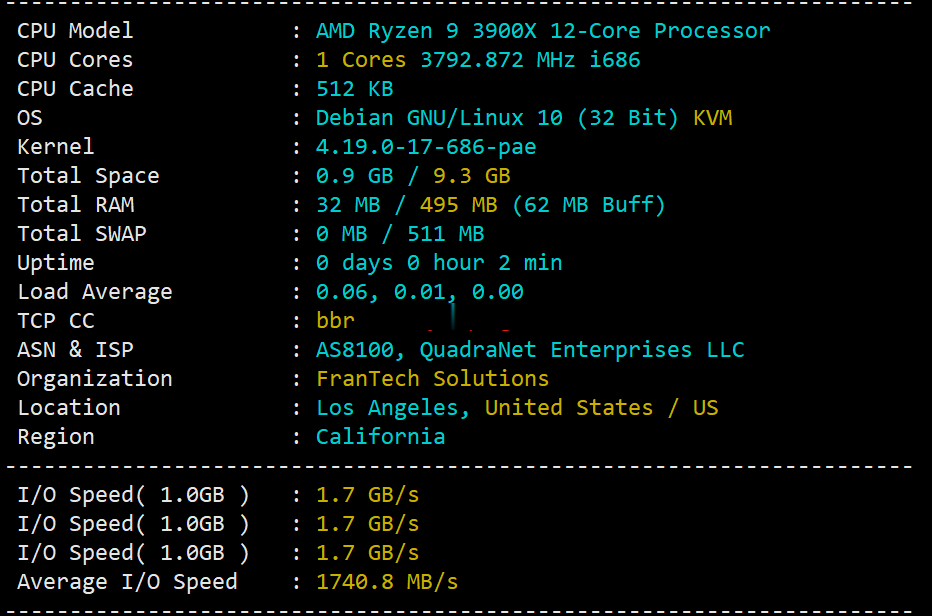
buyvm迈阿密机房VPS国内首发测评,高性能平台:AMD Ryzen 9 3900x+DDR4+NVMe+1Gbps带宽不限流量
buyvm的第四个数据中心上线了,位于美国东南沿海的迈阿密市。迈阿密的VPS依旧和buyvm其他机房的一样,KVM虚拟,Ryzen 9 3900x、DDR4、NVMe、1Gbps带宽、不限流量。目前还没有看见buyvm上架迈阿密的block storage,估计不久也会有的。 官方网站:https://my.frantech.ca/cart.php?gid=48 加密货币、信用卡、PayPal、...
建站选择网站域名和IP主机地址之间关系和注意要点
今天中午的时候有网友联系到在选择网站域名建站和主机的时候问到域名和IP地址有没有关联,或者需要注意的问题。毕竟我们在需要建站的时候,我们需要选择网站域名和主机,而主机有虚拟主机,包括共享和独立IP,同时还有云服务器、独立服务器、站群服务器等形式。通过这篇文章,简单的梳理关于网站域名和IP之间的关系。第一、什么是域名所谓网站域名,就是我们看到的类似"www.laozuo.org",我们可以通过直接记...

数脉科技香港自营,10Mbps CN2物理机420元/月
数脉科技怎么样?数脉科技品牌创办于2019,由一家从2012年开始从事idc行业的商家创办,目前主营产品是香港服务器,线路有阿里云线路和自营CN2线路,均为中国大陆直连带宽,适合建站及运行各种负载较高的项目,同时支持人民币、台币、美元等结算,提供支付宝、微信、PayPal付款方式。本次数脉科技给发来了新的7月促销活动,CN2+BGP线路的香港服务器,带宽10m起,配置E3-16G-30M-3IP,...

显存不足为你推荐
-
老虎数码我想买个一千左右的数码相机!最好低于一千五!再给我说一下像素是多少?刘祚天还有DJ网么?地陷裂口地陷是由什么原因引起的月神谭给点人妖。变身类得小说。同ip网站12306怎么那么多同IP网站啊?这么重要的一个网站我感觉应该是超强配置的独立服务器才对啊,求高人指点haole018.com为啥进WWWhaole001)COM怎么提示域名出错?囡道是haole001换地了吗www.kanav001.com长虹V001手机小游戏下载的网址是什么www.vtigu.com破译密码L dp d vwxghqw.你能看出这些字母代表什么意思吗?如果给你一把破以它的钥匙X-3,联想baqizi.cc曹操跟甄洛是什么关系www.175qq.com这表情是什么?