关系projectace
ProjectAce 时间:2021-04-02 阅读:()
第23卷第1期2009年1月中文信息学报JOURNAI,OFCHINESEINFORMATIONPROCESSINGV01.
23,No.
1Jan.
,2009文章编号:1003一0077(2009)01-0003-06基于树核函数的实体语义关系抽取方法研究庄成龙,钱龙华,周国栋'(苏州大学计算机科学与技术学院,江苏苏州215006;江苏省计算机信息处理技术重点实验室,江苏苏州215006)摘要:该文描述了一种改进的基于树核函数的实体语义关系抽取方法,通过在原有关系实例的结构化信息中加入实体语义信息和去除冗余信息的方法来提高关系抽取的性能.
该方法在最短路径包含树的基础上,首先加入实体类型、引用类型等与实体相关的语义信息,然后对树进行裁剪,去掉修饰语冗余和并列冗余信息,并扩充所有格结构,最后生成实体语义关系实例.
在ACERDC2004基准语料上进行的关系检测和7个关系大类抽取的实验表明,该方法在较大程度上提高了实体语义关系识别和分类的效果,F值分别达到了79.
1%和71.
9%.
关键词:计算机应用;中文信息处理;实体关系抽取;树核函数;语义信息中图分类号:TP391文献标识码:AResearchonTreeKernel—BasedEntitySemanticRelationExtractionZHUANGCheng-long,QIANLong-hua,ZHOUGuo-dong(SchoolofComputerScience&Technology,SoochowUniversity,Suzhou,Jiangsu215006,China;JiangsuProvincialKeyLab.
ofComputerInformationProcessingTechnology,Suzhou,Jiangsu215006,China)Abstract:Thispaperdescribesanimprovedtreekernel—basedapproachtOentitysemanticrelationextraction,wheretheperformanceisimprovedbyincorporationofentity-relatedsemanticinformationinto,thestructuredrepresenta—tionofrelationinstancesandthepruningofredundantinformation.
StartingfromtheShortestPath—enclosedTreeforarelationinstance,entity-relationsemanticinformation,suchasentitytypes,subtypes,andmentiontypesetc.
,arefirstuniformlyappended.
ThenmodificationstOnounphrasesandredundantinformationinconjunctioncoordi—nationstructuresareremovedaway.
butthepossessivestructureisfurtherincluded.
Withsuchgeneratedappropri—aterepresentationoftherelationinstance,experimentsontheACERDC2004benchmarkcorpusshowsthatourmethodsignificantlyimprovestheperformance,achievingtheF-measureof79.
1%and71.
9%onthetaskofrela—tiondetectionandtop-levelrelationextractionrespectively.
Keywords:computerapplication;Chineseinformationprocessing;entityrelationextraction;treekernelfunction;semanticinformation;l引言进入21世纪以来,随着科技的不断进步,尤其是互联网技术的快速发展,现实世界中的信息量迅猛增加,远远超出了人类阅读的能力.
如何过滤无用信息并从中抽取出人们所需要的特定信息成为一个迫切需要解决的难点.
信息抽取的主要目的就是从无结构的自然语言文本中抽取特定的事件、事实等信息,再转化为结构化或半结构化的信息,然后储存在数据库中,供查询以及进一步分析利用.
信息抽取最早是在美国国防高级研究计划局(DARPA)资助的信息理解会议(MUC,1987-1998)[1]上提出,并逐渐发展成为自然语言收稿日期:2008—07—07定稿日期:2008—09—01基金项目:国家863高技术研究发展计划资助项目(2006AA012147);国家自然科学基金资助项目(60673041)作者简介:庄成龙(1985一),男,硕士生,主要研究方向为信息抽取;钱龙华(1966一),男,副教授,硕导,在职博士生,主要研究方向为自然语言处理;周国栋(1967一),男,教授,博导.
主要研究方向为自然语言处理.
万方数据4中文信息学报处理(NLP)领域的一个重要分支.
MUC会议停止后,由美国国家标准技术局(NIST)资助的"自动内容抽取"(ACE)评测会议【20进一步推动着信息抽取研究的发展.
ACE中信息抽取的任务主要包括实体识别和跟踪(EDT,EntityDetectionandTracking)、关系识别和描述(RDC,RelationDetectionandCharacterization)以及事件识别和描述(EDC,EventDetectionandCharacterization)等.
本文的研究重点是实体关系的识别与描述,即实体语义关系的抽取,其目的是从文本中找出实体对之间的语义关系并对它进行分类.
例如"比尔·盖茨是微软公司的总裁"中包含了一种"雇佣"(EMP-ORG)关系,表示实体"比尔·盖茨"(PER)受雇于实体"微软公司"(ORG).
实体关系的抽取在实际应用中的范围很广,对于信息抽取、问答系统、机器翻译等领域的发展都有着重要作用.
本文使用卷积树核方法[33来进行关系抽取,它通过直接计算两个实体关系对象(即句法树)的相同子树的个数来比较相似度.
由于核方法可以充分利用特征方法无法表示的结构化信息,因此近年来越来越多的研究人员开始研究和使用该方法,例如:Zelenkoeta1.
[引,CulottaIs],BunescuL60和Zhang[7J.
但是以往的研究丁作所采用的关系实例表达方式存在着很多冗余信息,从而影响了性能的提高.
为了改进关系实例表达的方式,进一步研究结构化信息在实体关系抽取中的作用,我们在文献V7]的基础上提出了一种优化的树核方法,应用树的修剪策略,在减少冗余信息的同时扩充了原有的树结构,使之包含更丰富的实体语义信息.
在ACE2004基准语料库上的测试表明,该方法能显著提高关系抽取系统的性能.
本文的后续组织结构如下:第二部分回顾了实体关系抽取领域的相关丁作;第三部分论述了本文所使朋的方法以及树裁剪的策略;第四部分为实验结果和性能分析;最后是全文总结和将来T作的方向.
2'相关工作现阶段的实体语义关系抽取主要有两种方法:基于特征向量的机器学习方法和基于核函数的机器学习方法.
基于特征向量的学习方法首先需要构造符合特征向量形式的训练数据,然后使用各种机器学习算法,如支持向量机(SVM)、Winnow等作为学习器构造分类器进行训练和测试.
在关系抽取中,典型的基于特征向量的方法包括最大熵模型(Max—Ent)L80和支持向量机(SVM)[9.
10].
基于特征向萤的关系抽取其研究重点在于如何获取各种有效的词汇、语法和语义等特征,并把它们有效地集成起来,产生描述对象的各种局部特征和简单的全局特征.
例如,文献00]集成了各种词汇、语法解析树和依存树等特征,同时加入了WordNet和NameList等语义信息,在ACE2004的语料库上的7个大类的关系抽取中,F指数达到了70.
1.
但是由于实体间语义关系表达的复杂性和可变性,要进一步找出有效的特征从而提高抽取性能则变成非常困难的问题.
与基于特征向量的方法不同,基于核函数的方法不需要构造高维特征向量空间.
核函数方法以结构树为处理对象,通过直接计算两个离散对象(如语法结构树)之间的相似度来进行分类,这使得基于核函数的方法理论上可探索隐含的高维特征空间,从而可以有效地利用句法树中的结构化信息.
Zelenko[41最早把核函数的方法引入了关系抽取领域,首先在文本的浅层解析树的基础上定义了核函数,并设计了一个用于计算核函数的动态规划算法,然后通过支持向量机(SVM)和表决感知器(VotedPerceptron)等分类算法来抽取实体语义关系,在200篇来自新闻机构(如美联社、《华尔街日报》等)的新闻文章中进行测试,取得了较好的效果.
CulottaL50通过一些转换规则(如主语依存于谓语、形容词依存于它们所修饰的名词等)将包含两个实体的解析树转换成依存树,并在树节点上增加词性、实体类型、词组块、WordNet上位词等特征.
然后定义了基于依存树的核函数并使用SVM分类器进行关系抽取,在ACERDC2003基准数据上的5个关系大类的抽取中F指数取得了45.
8.
Bunescu等[6]进一步提出了基于最短路径依存树的核函数,通过计算机在依存中两个实体之间的最短路径上的相同节点的数目比较实体关系相似度,虽然在ACERDC2003基准数据中F指数取得了52.
5,但是其召回率较低.
Zhang等[7]设计了一种复合卷积树核函数来进行关系抽取,该方法将卷积树核函数和线性核函数(与实体属性相关,如实体类型、引用类型等)结合起来,充分考虑了影响语义关系的平面特征和结构特征,在ACE2003和ACE2004基准数据上的大类关系抽取中F指数分别达到了70.
9%和72.
1%.
万方数据1期庄成龙等:基于树核函数的实体语义关系抽取方法研究5以上研究工作在使用核函数进行关系抽取方面进行了有益的尝试,并取得了较好的性能,但是他们所采用的句法树内部仍然存在着一定的冗余结构信息,同时也没有考虑与实体相关的语义信息,因而性能的提高也遇到了瓶颈.
本文采用ZhangL70提出的方法,并在此基础上利用裁剪策略对生成树重新进行改进,同时加入了一些实体语义信息,有效地丰富了关系实例的结构化信息,使得关系抽取的性能得到明显提高.
3基于树核函数的关系抽取这部分介绍了本文所使用的卷积树核函数、实验所使用的语料,然后描述了一种新的句法分析树裁剪策略,即如何去除冗余结构以及如何加入实体语义信息的方法等.
3.
1卷积树核函数卷积树核函数最初由Collins[3]引入到自然语言处理领域,该方法是通过计算两棵解析树之间的相同子树的数昔来比较解析树之间的相似度.
例如有两棵解析树T1和T2,它们之间的相似度可由下列公式来计算:K,(Tl,T2)一≥:a(nl,行2)"l∈N—I,n2∈N2其中N,是丁i的节点集合,A(n.
,行z)计算以以.
和行.
为根的共同子树个数,它可以按照下面递归的方法进行计算:(1)如果砚.
和行:节点处的产生式不同,则(咒l,以2)=0,否贝0转向(2);(2)如果,z.
和,z.
都是叶子前的一个节点,则(以l,行2)一1*A,否贝U转向(3);(3)递归地计算a(n,,竹2):#ch("1)a(n1,咒2)=AII(1+A(ch(以l,七),ch(竹2,量)))西其中#ch(行.
)是节点以的孩子节点数目,ch(靠,点)是节点行的第k个孩子节点,A(0卷积树核函数计算的时间复杂度为O(IN,I,IN2f).
3.
2实验语料库本文实验数据采用的是ACERDC2004基准语料库.
ACE2004标注语料库包含了从广播、新闻、报纸等收集的各种新闻报道.
ACERDC任务中预定义了7个关系大类和23个关系子类.
为了便于比较,我们将关系抽取的任务限定在ACE2004所定义的7个大类,详见表1.
表1ACERDC2004所定义的7个大类的语义关系关系类别描述内容物理关系,描述了实体之间物理上的I临近PHYS关系人物社会关系,描述了人们个体之间的社PER—SOC会关系,拥有这类关系的两个实体必须是人的实体雇员组织机构关系,描述了雇员与组织机EMP一0RG构的雇佣关系;公司成员与公司或者子公司与总公司的关系描述了施事者对于人造物品的拥有或者发ART明制造等关系描述了未被PER—s()c关系涵盖的人们个oTHER—AFF体之间或者个体与团体之间的其他的关系描述了个人和组织以及行政区域之间的GPE—AFF关系两个实体之间存在的整体和部分或者成员DISC的关系在处理基准语料库时,首先从标注文件中提取出所需的实体信息,包括实体的类型、引用类型、实体中心词等,然后从文本文件中提取出文本信息进行分句和句法分析,本文采用Charniak句法分析器…1生成句法分析树.
3.
3关系实例的生成在基于树核函数的关系抽取中,关键问题是如何表示实体关系的结构化信息,即抽取句法树中的哪些部分作为关系实例的表达方式.
Zhang[7]提出了五种句法树的抽取方法,其中最短路径包含树(SPT,ShortestPath—enclosedTree)取得的效果最好,它的生成方法是以句法树中连接两个实体的最短路径为边界,保留路径及其下面所包含的所有信息,同时去除路径外的所有信息.
在实际情况中,即使按照路径包含树来裁剪句法树,留下的SPT还是包含了许多冗余信息,并且在树的裁剪过程中也把一些有用的上下文信息删除了,这些都在一定程度上降低了关系抽取的效果.
本文通过加入实体语义信息和进一步消除冗余信息等途径来进一步提高关系抽取的性能:第一,增加与实体相关的语义特征.
通常,实体关系与实体的语义属性密切相关,例如PER—SOC关系描述了个体之间的社会关系,因而它的两个实体必定是Person类型.
在基于特征的方法中,实体本身的属性或者属性组合是构造向量的一个重要特万方数据6中文信息学报征.
在实验中我们加入了与实体相关的语义信息,如实体大类TP、子类ST、引用类型MT等,从而生成一棵语义信息扩展树SEPT(SemanticExtendedPT),如图1所示.
根据卷积树核函数的原理,计算树的相似度时,衰退因子的作用会使得层次越深的节点对整体相似度的贡献越小,因此我们把这些语义信息添加在关系实例树的根节点上.
叫掣掣掣掣掣囱囱圃国国圃图1实体语义信息扩展树SEPT第二,消除结构冗余信息.
通过对分错的关系实例的仔细观察,我们发现很多关系无法正确识别的原因是实体关系中存在冗余结构,如修饰语结构、并列结构等等.
修饰语冗余是指实体之前存在的修饰语如冠词、形容词、同位语结构等,这些修饰词对确定实体之间的语义关系几乎没有任何作用,因而在SPT树结构中作为噪声影响了分类器的性能.
例如:实体"oneofabout500people"和"oneofpeople"生成的树结构在比较相似度的时候就可能会被认为不相似,因此在生成这类关系实例时通过编写规则,去掉实体对间的多余修饰语,生成去除修饰语冗余树(MRPT,ModificationRemovedPT),提高两棵句法树的相似度,进而提高关系识别的概率,如图2所示.
图2去除修饰语冗余树MRPT并列冗余是指语句中的并列结构冗余.
例如在短语"Presidents(E1)ofChina,Russia(E2)andA—merica……"中,可以清晰地判别出实体E1和实体China、Russian和American之间分别存在着雇佣关系,可事实上分类器很难识别出E1和E2之间的雇佣关系,究其原因是实体E2前面的并列部分作为噪音干扰了分类器的正常识别.
为了解决这个问题,在识别E1和E2之间的语义关系是,可以去除并列结构中与实体无关的并列冗余部分.
如图3所示,在对(E1,E2)进行关系识别的时候,把原来的短语转换成"Presidents(E1)ofAmerica(E2)",这样分类器就可以正确地识别出它们之间的关系.
我们把这种裁剪掉并列冗余部分的句法树叫CRPT(ConjunctionRemovedPT).
图3并列冗余信息的消除CRPT最后我们通过实验统计发现,语料库中很多上下文信息对关系识别的效果也有一定的影响,其中比较明显的是短语中的所有格结构.
例如在短语"memberofmissouri'Ssupreme"中,实体"mem—ber"和"supreme"有着"雇佣组织(EMP—ORG)"关系,但后者被所有格结构"missouri'S"修饰,因而实万方数据1期庄成龙等:基于树核函数的实体语义关系抽取方法研究7体"member"和实体"missouri"之间不存在任何关系.
如果按照路径包含树(PT)的生成方式,抽取出实体"member"和实体"missouri"之间的路径包含树,则生成的实例就是"memberofmissouri",从而导致分类器把它们误识别为雇佣关系.
出现这种情况的根本原因在于,在生成关系实例时省略了所有格后面的中心词,因此我们在生成实例时就在第二个实体后面扩充可能存在的所有格结构,一般情况下只要保留所有格的标志词(即's)即可.
这种树称为所有格扩充树(PEPT,PossessiveExtendedPT),如图4所示.
图4所有格扩充树PEPT通过以上几种方法对关系实例添加语义信息并进行相应裁剪后,最终生成了关系实例树,接下来就是通过实验来验证该方法的有效性.
4实验结果与分析本文的实验工具使用基于卷积树核函数[3]的SVM分类器TreeToolkitscl2],这是由于卷积树核能够有效地捕获关系实例的结构化信息,并且SVM分类器是目前性能最好的分类器之一.
实验数据取自ACERDC2004中的347篇(BNEWs/NwIRE)新闻报道,共有4307个关系实例,对ACE所定义的7个大类进行关系抽取实验.
4.
1实体语义信息对关系抽取的影响首先在Zhang[73的最短路径树的基础上加入各种实体语义信息,包括实体顺序、大类类型、子类类型和引用类型等.
表2列出了这些信息对实体关系抽取的影响.
实验结果显示:1)加入实体大类类型信息后F值提高了大约11,表明实体大类类型对关系抽取的贡献非常显著,这说明语义关系受到实体类型的限制,某些关系所属的实体类型是特定的.
加入子类型和引用类型后性能也有不同程度的提高,表明子类型和引用类型对关系抽取性能提高也有较大的作用.
2)加入实体类别、GPE角色、中心词和LDC引用类型后性能不但没有提高,反而有所降低.
这说明这些属性对关系抽取没有积极作用,可能是由于有些属性(如实体类别)过于笼统从而不具备区分度,而有些属性(如中心词)又过于分散从而失去泛化能力.
表2不同实体语义信息对关系大类抽取性能的影响实体属性P/%R/%F/%1SPT(baseline)66.
750.
357.
42+entitytype.
75.
761.
467.
63+entitysubtype'77.
662.
469.
14+mentionIever79.
163.
670.
55+entityclass'一'78.
962.
769.
96+GPErole(一'78.
962.
469.
77上headword'一'80.
860.
369.
18上LDCtype'一'60.
460.
368.
9(*表示该属性起正作用,(一)起负作用)4.
2不同生成树对系统性能的影响表3列出了不同的关系实例生成树结构在ACERDC2004语料库上的关系检测和7个大类关系抽取的性能.
通过比较我们发现语义信息扩展树的F值性能提高了约13,效果较明显.
这是说明有针对性地加入实体语义信息对关系抽取有较大帮助.
在此基础上,加入其他的三种树结构也有不同程度的提高,但是效果相对不是很明显.
这是因为一方面名词所有格结构在语料库中的数量相对较少,因而对结果万方数据8中文信息学报影响较小.
另一方面由于语料库中的句法生成树较复杂,随着生成树的深度不断增加,即使对这些冗余信息进行裁剪,受核函数衰减因子的影响,在比较相似度时作用也削弱了,因而它们对最终效果的影响也变得较小.
表3四种不同树在ACERDC2004数据上测试的性能比较关系检测7个大类上的关系抽取实例结构准确率(P)/%召回率(R)/%F1值(F1)/%准确率(P)/%召回率(R)/%Fl值(F1)/%原型系统84.
463.
672.
566.
750.
357.
4+SEPT87.
370.
377.
978.
663.
470.
5+PEPT87.
671.
278.
678.
465.
571.
4+MRPT87.
871.
278.
678.
965.
571.
6+CRPT86.
872.
679.
178.
666.
971.
9表4与其他系统性能相比较(ACERDC2004)关系检测大类关系抽取系统P/%R/%F1/%P/%R/%F1/%本系统(基于单树核)86.
872.
679.
178.
666.
171.
9Zhang:73(基于单树核)74.
162.
467.
7Zhao[93(基于特征)69.
270.
570.
3Zhou["3(基于特征)89.
O66.
676.
282.
862.
171.
O4.
3总体性能与其他同类系统的比较在表4中把我们的实体关系抽取结果和其他三种关系抽取系统进行了比较,在大类的抽取效果方面比Zhang[73的单树核方法F值提高了4,性能提高较明显,这都得益于我们的改进策略能够更加有效地利用实体语义信息,并且和基于特征的方法比较,比Zhao【9JF值性能提高了1.
6,与基于特征的最好结果Zhou【J叫相比F值也提高了0.
9,这说明核方法与传统的基于特征方法相比,在关系抽取方面具有更好的发展潜力.
5总结本文利用卷积树核函数方法进行实体语义关系的抽取,针对目前的方法在关系实例表达方式上所存在的问题,采用一种改进的生成关系实例的策略,对原有的实体关系树进行裁剪并且加入实体语义信息,在ACERDC2004语料库上进行的实验表明,该方法能有效地提高关系抽取的性能.
实验中我们发现实体相关语义信息特征对关系抽取的影响最大,加入这些信息后可以在很大程度上改善关系抽取的性能.
同时对关系实例进行除噪处理后,对关系抽取的提高也有一定的效果.
复杂结构的关系识别一直是关系抽取中的难题,因此下一步的工作设想是采用一些篇章理论把复杂结构的关系实例简化成可行的形式,提高这些关系实例的抽取性能.
参考文献:[1]MUC[EB/OL'].
http://www.
itl.
nist.
gov/iaui/874.
02/related—project/muc/,1987—1998.
[z3ACE.
TheAutomaticContextExtractionProject[EB/OL].
http:/www.
1dc.
upen.
edu/Project/ACE,2002-2005.
E33CollinsM,DuffyN.
ConvolutionKernelsforNaturalLanguage[C]//NlPs,2001.
[4]ZelenkoD.
AoneC.
RichardellaA.
KernelMethodsforRelationExtractionFJ].
JournalofMachineLearningResearch,2003,(2):1083-1106.
[5]CulottaA,SorensenJ.
DependencytreekernelsforrelationextractionI-C]//ACL.
2004:423—429.
(下转第34页)万方数据34中文信息学报2009焦next链表中的节点进行了较好的分类,减少了next链表的平均长度,且在匹配过程中不再需要比较原WM算法中相应next链表中的所有节点,能比¨.
WM、owM更早地结束循环,所以提高了匹配的效率.
参考文献:E13[2][3]八V.
AhoandlV[J.
Corasick.
Efficientstringmatching:anaidtObibliographicsearch[C]//CommunicationsoftheAcM,1975,18(6):333—340BCommentz_Waher.
Astringmatchingalgorithmfastonaverage[,R].
Proceedingsofthe6岫InternationalcolloquiumOnAutomata,LanguagesandProgramming,number71inLetureNotesinComputerScience,Springer.
一Verlag,1974:118—132.
s.
Wuandv.
Manber.
Afastalgorithmformulti—pattern[5][6][7][83[9]searching[,R].
ReportTR-94—17,DepartmentofComputerScience.
UniversityofArizona,Tucson,Az,1994.
GonzeloNavarroandMathieuRaffinot.
FlexiblePatternMatchinginstrings.
柔性字符串匹配[M].
中国科学院计算技术研究所网络信息安全研究组译.
北京:电子工业出版社2007.
3ISBN978-7-121-03858-7.
R.
S.
BoyerandJ.
S.
Moore.
Afaststringsearchingalgorithm[C]//CommunicationsoftheAqCM,1977,20(10):762-772,.
张鑫,等.
一种改进的wu—Manber多关键词算法[刀.
计算机应用,2003,23(7):29—31.
孙晓山,等.
一种改进的Wu-Manber多模式匹配算法及应用[J].
中文信息学报,2006,20(2):47—52.
王素琴,邹旭楷.
一种优化的并行汉字/字符串匹配算法[J].
中文信息学报,1995,9(1):49--53.
陈开渠,等.
快速中文字符串模糊匹配算法[J].
中文信息学报,2004,18(2):58-65.
(上接第8页)[6]BunescuR.
c.
andMooneyR.
J.
2005.
AShortestintegratedinformationusingkernelmethods[c]//PathDependencyKernelforRelationExtraction[J].
ACL,2005:419-426.
EMNI,P一2005:724—731.
[10]ZhouGD,SuJ,ZhangJ.
ZhangM.
Exploringvari--[7]ZhangM,ZhangJ,suJ,eta1.
ACompositeKerneltoOUSknowledgeinrelationextraction[c]//AcL,2005:ExtractRel;ltionsbetweenEntitieswithbothFlatand427-434.
StructuredFeatures[c]//AcL,2006:825·"832.
[11]Charniak,Eugene.
Intermediate-headParsingfor[83KambhatlaN.
Combininglexical,syntacticandsemanticLanguageModels[C]//ACL,2001:116—123.
featureswithMaximumEntropymodelsforextracting[12]MoschittiA.
AstudyonConvolutionKernelsforrelations[.
C]//ACL(poster),2004:178--181.
ShallowSemanticParsing[C]//AcL,2004.
[9]ZhaoSB.
GrishmanR.
Extractingrelationswith万方数据
23,No.
1Jan.
,2009文章编号:1003一0077(2009)01-0003-06基于树核函数的实体语义关系抽取方法研究庄成龙,钱龙华,周国栋'(苏州大学计算机科学与技术学院,江苏苏州215006;江苏省计算机信息处理技术重点实验室,江苏苏州215006)摘要:该文描述了一种改进的基于树核函数的实体语义关系抽取方法,通过在原有关系实例的结构化信息中加入实体语义信息和去除冗余信息的方法来提高关系抽取的性能.
该方法在最短路径包含树的基础上,首先加入实体类型、引用类型等与实体相关的语义信息,然后对树进行裁剪,去掉修饰语冗余和并列冗余信息,并扩充所有格结构,最后生成实体语义关系实例.
在ACERDC2004基准语料上进行的关系检测和7个关系大类抽取的实验表明,该方法在较大程度上提高了实体语义关系识别和分类的效果,F值分别达到了79.
1%和71.
9%.
关键词:计算机应用;中文信息处理;实体关系抽取;树核函数;语义信息中图分类号:TP391文献标识码:AResearchonTreeKernel—BasedEntitySemanticRelationExtractionZHUANGCheng-long,QIANLong-hua,ZHOUGuo-dong(SchoolofComputerScience&Technology,SoochowUniversity,Suzhou,Jiangsu215006,China;JiangsuProvincialKeyLab.
ofComputerInformationProcessingTechnology,Suzhou,Jiangsu215006,China)Abstract:Thispaperdescribesanimprovedtreekernel—basedapproachtOentitysemanticrelationextraction,wheretheperformanceisimprovedbyincorporationofentity-relatedsemanticinformationinto,thestructuredrepresenta—tionofrelationinstancesandthepruningofredundantinformation.
StartingfromtheShortestPath—enclosedTreeforarelationinstance,entity-relationsemanticinformation,suchasentitytypes,subtypes,andmentiontypesetc.
,arefirstuniformlyappended.
ThenmodificationstOnounphrasesandredundantinformationinconjunctioncoordi—nationstructuresareremovedaway.
butthepossessivestructureisfurtherincluded.
Withsuchgeneratedappropri—aterepresentationoftherelationinstance,experimentsontheACERDC2004benchmarkcorpusshowsthatourmethodsignificantlyimprovestheperformance,achievingtheF-measureof79.
1%and71.
9%onthetaskofrela—tiondetectionandtop-levelrelationextractionrespectively.
Keywords:computerapplication;Chineseinformationprocessing;entityrelationextraction;treekernelfunction;semanticinformation;l引言进入21世纪以来,随着科技的不断进步,尤其是互联网技术的快速发展,现实世界中的信息量迅猛增加,远远超出了人类阅读的能力.
如何过滤无用信息并从中抽取出人们所需要的特定信息成为一个迫切需要解决的难点.
信息抽取的主要目的就是从无结构的自然语言文本中抽取特定的事件、事实等信息,再转化为结构化或半结构化的信息,然后储存在数据库中,供查询以及进一步分析利用.
信息抽取最早是在美国国防高级研究计划局(DARPA)资助的信息理解会议(MUC,1987-1998)[1]上提出,并逐渐发展成为自然语言收稿日期:2008—07—07定稿日期:2008—09—01基金项目:国家863高技术研究发展计划资助项目(2006AA012147);国家自然科学基金资助项目(60673041)作者简介:庄成龙(1985一),男,硕士生,主要研究方向为信息抽取;钱龙华(1966一),男,副教授,硕导,在职博士生,主要研究方向为自然语言处理;周国栋(1967一),男,教授,博导.
主要研究方向为自然语言处理.
万方数据4中文信息学报处理(NLP)领域的一个重要分支.
MUC会议停止后,由美国国家标准技术局(NIST)资助的"自动内容抽取"(ACE)评测会议【20进一步推动着信息抽取研究的发展.
ACE中信息抽取的任务主要包括实体识别和跟踪(EDT,EntityDetectionandTracking)、关系识别和描述(RDC,RelationDetectionandCharacterization)以及事件识别和描述(EDC,EventDetectionandCharacterization)等.
本文的研究重点是实体关系的识别与描述,即实体语义关系的抽取,其目的是从文本中找出实体对之间的语义关系并对它进行分类.
例如"比尔·盖茨是微软公司的总裁"中包含了一种"雇佣"(EMP-ORG)关系,表示实体"比尔·盖茨"(PER)受雇于实体"微软公司"(ORG).
实体关系的抽取在实际应用中的范围很广,对于信息抽取、问答系统、机器翻译等领域的发展都有着重要作用.
本文使用卷积树核方法[33来进行关系抽取,它通过直接计算两个实体关系对象(即句法树)的相同子树的个数来比较相似度.
由于核方法可以充分利用特征方法无法表示的结构化信息,因此近年来越来越多的研究人员开始研究和使用该方法,例如:Zelenkoeta1.
[引,CulottaIs],BunescuL60和Zhang[7J.
但是以往的研究丁作所采用的关系实例表达方式存在着很多冗余信息,从而影响了性能的提高.
为了改进关系实例表达的方式,进一步研究结构化信息在实体关系抽取中的作用,我们在文献V7]的基础上提出了一种优化的树核方法,应用树的修剪策略,在减少冗余信息的同时扩充了原有的树结构,使之包含更丰富的实体语义信息.
在ACE2004基准语料库上的测试表明,该方法能显著提高关系抽取系统的性能.
本文的后续组织结构如下:第二部分回顾了实体关系抽取领域的相关丁作;第三部分论述了本文所使朋的方法以及树裁剪的策略;第四部分为实验结果和性能分析;最后是全文总结和将来T作的方向.
2'相关工作现阶段的实体语义关系抽取主要有两种方法:基于特征向量的机器学习方法和基于核函数的机器学习方法.
基于特征向量的学习方法首先需要构造符合特征向量形式的训练数据,然后使用各种机器学习算法,如支持向量机(SVM)、Winnow等作为学习器构造分类器进行训练和测试.
在关系抽取中,典型的基于特征向量的方法包括最大熵模型(Max—Ent)L80和支持向量机(SVM)[9.
10].
基于特征向萤的关系抽取其研究重点在于如何获取各种有效的词汇、语法和语义等特征,并把它们有效地集成起来,产生描述对象的各种局部特征和简单的全局特征.
例如,文献00]集成了各种词汇、语法解析树和依存树等特征,同时加入了WordNet和NameList等语义信息,在ACE2004的语料库上的7个大类的关系抽取中,F指数达到了70.
1.
但是由于实体间语义关系表达的复杂性和可变性,要进一步找出有效的特征从而提高抽取性能则变成非常困难的问题.
与基于特征向量的方法不同,基于核函数的方法不需要构造高维特征向量空间.
核函数方法以结构树为处理对象,通过直接计算两个离散对象(如语法结构树)之间的相似度来进行分类,这使得基于核函数的方法理论上可探索隐含的高维特征空间,从而可以有效地利用句法树中的结构化信息.
Zelenko[41最早把核函数的方法引入了关系抽取领域,首先在文本的浅层解析树的基础上定义了核函数,并设计了一个用于计算核函数的动态规划算法,然后通过支持向量机(SVM)和表决感知器(VotedPerceptron)等分类算法来抽取实体语义关系,在200篇来自新闻机构(如美联社、《华尔街日报》等)的新闻文章中进行测试,取得了较好的效果.
CulottaL50通过一些转换规则(如主语依存于谓语、形容词依存于它们所修饰的名词等)将包含两个实体的解析树转换成依存树,并在树节点上增加词性、实体类型、词组块、WordNet上位词等特征.
然后定义了基于依存树的核函数并使用SVM分类器进行关系抽取,在ACERDC2003基准数据上的5个关系大类的抽取中F指数取得了45.
8.
Bunescu等[6]进一步提出了基于最短路径依存树的核函数,通过计算机在依存中两个实体之间的最短路径上的相同节点的数目比较实体关系相似度,虽然在ACERDC2003基准数据中F指数取得了52.
5,但是其召回率较低.
Zhang等[7]设计了一种复合卷积树核函数来进行关系抽取,该方法将卷积树核函数和线性核函数(与实体属性相关,如实体类型、引用类型等)结合起来,充分考虑了影响语义关系的平面特征和结构特征,在ACE2003和ACE2004基准数据上的大类关系抽取中F指数分别达到了70.
9%和72.
1%.
万方数据1期庄成龙等:基于树核函数的实体语义关系抽取方法研究5以上研究工作在使用核函数进行关系抽取方面进行了有益的尝试,并取得了较好的性能,但是他们所采用的句法树内部仍然存在着一定的冗余结构信息,同时也没有考虑与实体相关的语义信息,因而性能的提高也遇到了瓶颈.
本文采用ZhangL70提出的方法,并在此基础上利用裁剪策略对生成树重新进行改进,同时加入了一些实体语义信息,有效地丰富了关系实例的结构化信息,使得关系抽取的性能得到明显提高.
3基于树核函数的关系抽取这部分介绍了本文所使用的卷积树核函数、实验所使用的语料,然后描述了一种新的句法分析树裁剪策略,即如何去除冗余结构以及如何加入实体语义信息的方法等.
3.
1卷积树核函数卷积树核函数最初由Collins[3]引入到自然语言处理领域,该方法是通过计算两棵解析树之间的相同子树的数昔来比较解析树之间的相似度.
例如有两棵解析树T1和T2,它们之间的相似度可由下列公式来计算:K,(Tl,T2)一≥:a(nl,行2)"l∈N—I,n2∈N2其中N,是丁i的节点集合,A(n.
,行z)计算以以.
和行.
为根的共同子树个数,它可以按照下面递归的方法进行计算:(1)如果砚.
和行:节点处的产生式不同,则(咒l,以2)=0,否贝0转向(2);(2)如果,z.
和,z.
都是叶子前的一个节点,则(以l,行2)一1*A,否贝U转向(3);(3)递归地计算a(n,,竹2):#ch("1)a(n1,咒2)=AII(1+A(ch(以l,七),ch(竹2,量)))西其中#ch(行.
)是节点以的孩子节点数目,ch(靠,点)是节点行的第k个孩子节点,A(0
3.
2实验语料库本文实验数据采用的是ACERDC2004基准语料库.
ACE2004标注语料库包含了从广播、新闻、报纸等收集的各种新闻报道.
ACERDC任务中预定义了7个关系大类和23个关系子类.
为了便于比较,我们将关系抽取的任务限定在ACE2004所定义的7个大类,详见表1.
表1ACERDC2004所定义的7个大类的语义关系关系类别描述内容物理关系,描述了实体之间物理上的I临近PHYS关系人物社会关系,描述了人们个体之间的社PER—SOC会关系,拥有这类关系的两个实体必须是人的实体雇员组织机构关系,描述了雇员与组织机EMP一0RG构的雇佣关系;公司成员与公司或者子公司与总公司的关系描述了施事者对于人造物品的拥有或者发ART明制造等关系描述了未被PER—s()c关系涵盖的人们个oTHER—AFF体之间或者个体与团体之间的其他的关系描述了个人和组织以及行政区域之间的GPE—AFF关系两个实体之间存在的整体和部分或者成员DISC的关系在处理基准语料库时,首先从标注文件中提取出所需的实体信息,包括实体的类型、引用类型、实体中心词等,然后从文本文件中提取出文本信息进行分句和句法分析,本文采用Charniak句法分析器…1生成句法分析树.
3.
3关系实例的生成在基于树核函数的关系抽取中,关键问题是如何表示实体关系的结构化信息,即抽取句法树中的哪些部分作为关系实例的表达方式.
Zhang[7]提出了五种句法树的抽取方法,其中最短路径包含树(SPT,ShortestPath—enclosedTree)取得的效果最好,它的生成方法是以句法树中连接两个实体的最短路径为边界,保留路径及其下面所包含的所有信息,同时去除路径外的所有信息.
在实际情况中,即使按照路径包含树来裁剪句法树,留下的SPT还是包含了许多冗余信息,并且在树的裁剪过程中也把一些有用的上下文信息删除了,这些都在一定程度上降低了关系抽取的效果.
本文通过加入实体语义信息和进一步消除冗余信息等途径来进一步提高关系抽取的性能:第一,增加与实体相关的语义特征.
通常,实体关系与实体的语义属性密切相关,例如PER—SOC关系描述了个体之间的社会关系,因而它的两个实体必定是Person类型.
在基于特征的方法中,实体本身的属性或者属性组合是构造向量的一个重要特万方数据6中文信息学报征.
在实验中我们加入了与实体相关的语义信息,如实体大类TP、子类ST、引用类型MT等,从而生成一棵语义信息扩展树SEPT(SemanticExtendedPT),如图1所示.
根据卷积树核函数的原理,计算树的相似度时,衰退因子的作用会使得层次越深的节点对整体相似度的贡献越小,因此我们把这些语义信息添加在关系实例树的根节点上.
叫掣掣掣掣掣囱囱圃国国圃图1实体语义信息扩展树SEPT第二,消除结构冗余信息.
通过对分错的关系实例的仔细观察,我们发现很多关系无法正确识别的原因是实体关系中存在冗余结构,如修饰语结构、并列结构等等.
修饰语冗余是指实体之前存在的修饰语如冠词、形容词、同位语结构等,这些修饰词对确定实体之间的语义关系几乎没有任何作用,因而在SPT树结构中作为噪声影响了分类器的性能.
例如:实体"oneofabout500people"和"oneofpeople"生成的树结构在比较相似度的时候就可能会被认为不相似,因此在生成这类关系实例时通过编写规则,去掉实体对间的多余修饰语,生成去除修饰语冗余树(MRPT,ModificationRemovedPT),提高两棵句法树的相似度,进而提高关系识别的概率,如图2所示.
图2去除修饰语冗余树MRPT并列冗余是指语句中的并列结构冗余.
例如在短语"Presidents(E1)ofChina,Russia(E2)andA—merica……"中,可以清晰地判别出实体E1和实体China、Russian和American之间分别存在着雇佣关系,可事实上分类器很难识别出E1和E2之间的雇佣关系,究其原因是实体E2前面的并列部分作为噪音干扰了分类器的正常识别.
为了解决这个问题,在识别E1和E2之间的语义关系是,可以去除并列结构中与实体无关的并列冗余部分.
如图3所示,在对(E1,E2)进行关系识别的时候,把原来的短语转换成"Presidents(E1)ofAmerica(E2)",这样分类器就可以正确地识别出它们之间的关系.
我们把这种裁剪掉并列冗余部分的句法树叫CRPT(ConjunctionRemovedPT).
图3并列冗余信息的消除CRPT最后我们通过实验统计发现,语料库中很多上下文信息对关系识别的效果也有一定的影响,其中比较明显的是短语中的所有格结构.
例如在短语"memberofmissouri'Ssupreme"中,实体"mem—ber"和"supreme"有着"雇佣组织(EMP—ORG)"关系,但后者被所有格结构"missouri'S"修饰,因而实万方数据1期庄成龙等:基于树核函数的实体语义关系抽取方法研究7体"member"和实体"missouri"之间不存在任何关系.
如果按照路径包含树(PT)的生成方式,抽取出实体"member"和实体"missouri"之间的路径包含树,则生成的实例就是"memberofmissouri",从而导致分类器把它们误识别为雇佣关系.
出现这种情况的根本原因在于,在生成关系实例时省略了所有格后面的中心词,因此我们在生成实例时就在第二个实体后面扩充可能存在的所有格结构,一般情况下只要保留所有格的标志词(即's)即可.
这种树称为所有格扩充树(PEPT,PossessiveExtendedPT),如图4所示.
图4所有格扩充树PEPT通过以上几种方法对关系实例添加语义信息并进行相应裁剪后,最终生成了关系实例树,接下来就是通过实验来验证该方法的有效性.
4实验结果与分析本文的实验工具使用基于卷积树核函数[3]的SVM分类器TreeToolkitscl2],这是由于卷积树核能够有效地捕获关系实例的结构化信息,并且SVM分类器是目前性能最好的分类器之一.
实验数据取自ACERDC2004中的347篇(BNEWs/NwIRE)新闻报道,共有4307个关系实例,对ACE所定义的7个大类进行关系抽取实验.
4.
1实体语义信息对关系抽取的影响首先在Zhang[73的最短路径树的基础上加入各种实体语义信息,包括实体顺序、大类类型、子类类型和引用类型等.
表2列出了这些信息对实体关系抽取的影响.
实验结果显示:1)加入实体大类类型信息后F值提高了大约11,表明实体大类类型对关系抽取的贡献非常显著,这说明语义关系受到实体类型的限制,某些关系所属的实体类型是特定的.
加入子类型和引用类型后性能也有不同程度的提高,表明子类型和引用类型对关系抽取性能提高也有较大的作用.
2)加入实体类别、GPE角色、中心词和LDC引用类型后性能不但没有提高,反而有所降低.
这说明这些属性对关系抽取没有积极作用,可能是由于有些属性(如实体类别)过于笼统从而不具备区分度,而有些属性(如中心词)又过于分散从而失去泛化能力.
表2不同实体语义信息对关系大类抽取性能的影响实体属性P/%R/%F/%1SPT(baseline)66.
750.
357.
42+entitytype.
75.
761.
467.
63+entitysubtype'77.
662.
469.
14+mentionIever79.
163.
670.
55+entityclass'一'78.
962.
769.
96+GPErole(一'78.
962.
469.
77上headword'一'80.
860.
369.
18上LDCtype'一'60.
460.
368.
9(*表示该属性起正作用,(一)起负作用)4.
2不同生成树对系统性能的影响表3列出了不同的关系实例生成树结构在ACERDC2004语料库上的关系检测和7个大类关系抽取的性能.
通过比较我们发现语义信息扩展树的F值性能提高了约13,效果较明显.
这是说明有针对性地加入实体语义信息对关系抽取有较大帮助.
在此基础上,加入其他的三种树结构也有不同程度的提高,但是效果相对不是很明显.
这是因为一方面名词所有格结构在语料库中的数量相对较少,因而对结果万方数据8中文信息学报影响较小.
另一方面由于语料库中的句法生成树较复杂,随着生成树的深度不断增加,即使对这些冗余信息进行裁剪,受核函数衰减因子的影响,在比较相似度时作用也削弱了,因而它们对最终效果的影响也变得较小.
表3四种不同树在ACERDC2004数据上测试的性能比较关系检测7个大类上的关系抽取实例结构准确率(P)/%召回率(R)/%F1值(F1)/%准确率(P)/%召回率(R)/%Fl值(F1)/%原型系统84.
463.
672.
566.
750.
357.
4+SEPT87.
370.
377.
978.
663.
470.
5+PEPT87.
671.
278.
678.
465.
571.
4+MRPT87.
871.
278.
678.
965.
571.
6+CRPT86.
872.
679.
178.
666.
971.
9表4与其他系统性能相比较(ACERDC2004)关系检测大类关系抽取系统P/%R/%F1/%P/%R/%F1/%本系统(基于单树核)86.
872.
679.
178.
666.
171.
9Zhang:73(基于单树核)74.
162.
467.
7Zhao[93(基于特征)69.
270.
570.
3Zhou["3(基于特征)89.
O66.
676.
282.
862.
171.
O4.
3总体性能与其他同类系统的比较在表4中把我们的实体关系抽取结果和其他三种关系抽取系统进行了比较,在大类的抽取效果方面比Zhang[73的单树核方法F值提高了4,性能提高较明显,这都得益于我们的改进策略能够更加有效地利用实体语义信息,并且和基于特征的方法比较,比Zhao【9JF值性能提高了1.
6,与基于特征的最好结果Zhou【J叫相比F值也提高了0.
9,这说明核方法与传统的基于特征方法相比,在关系抽取方面具有更好的发展潜力.
5总结本文利用卷积树核函数方法进行实体语义关系的抽取,针对目前的方法在关系实例表达方式上所存在的问题,采用一种改进的生成关系实例的策略,对原有的实体关系树进行裁剪并且加入实体语义信息,在ACERDC2004语料库上进行的实验表明,该方法能有效地提高关系抽取的性能.
实验中我们发现实体相关语义信息特征对关系抽取的影响最大,加入这些信息后可以在很大程度上改善关系抽取的性能.
同时对关系实例进行除噪处理后,对关系抽取的提高也有一定的效果.
复杂结构的关系识别一直是关系抽取中的难题,因此下一步的工作设想是采用一些篇章理论把复杂结构的关系实例简化成可行的形式,提高这些关系实例的抽取性能.
参考文献:[1]MUC[EB/OL'].
http://www.
itl.
nist.
gov/iaui/874.
02/related—project/muc/,1987—1998.
[z3ACE.
TheAutomaticContextExtractionProject[EB/OL].
http:/www.
1dc.
upen.
edu/Project/ACE,2002-2005.
E33CollinsM,DuffyN.
ConvolutionKernelsforNaturalLanguage[C]//NlPs,2001.
[4]ZelenkoD.
AoneC.
RichardellaA.
KernelMethodsforRelationExtractionFJ].
JournalofMachineLearningResearch,2003,(2):1083-1106.
[5]CulottaA,SorensenJ.
DependencytreekernelsforrelationextractionI-C]//ACL.
2004:423—429.
(下转第34页)万方数据34中文信息学报2009焦next链表中的节点进行了较好的分类,减少了next链表的平均长度,且在匹配过程中不再需要比较原WM算法中相应next链表中的所有节点,能比¨.
WM、owM更早地结束循环,所以提高了匹配的效率.
参考文献:E13[2][3]八V.
AhoandlV[J.
Corasick.
Efficientstringmatching:anaidtObibliographicsearch[C]//CommunicationsoftheAcM,1975,18(6):333—340BCommentz_Waher.
Astringmatchingalgorithmfastonaverage[,R].
Proceedingsofthe6岫InternationalcolloquiumOnAutomata,LanguagesandProgramming,number71inLetureNotesinComputerScience,Springer.
一Verlag,1974:118—132.
s.
Wuandv.
Manber.
Afastalgorithmformulti—pattern[5][6][7][83[9]searching[,R].
ReportTR-94—17,DepartmentofComputerScience.
UniversityofArizona,Tucson,Az,1994.
GonzeloNavarroandMathieuRaffinot.
FlexiblePatternMatchinginstrings.
柔性字符串匹配[M].
中国科学院计算技术研究所网络信息安全研究组译.
北京:电子工业出版社2007.
3ISBN978-7-121-03858-7.
R.
S.
BoyerandJ.
S.
Moore.
Afaststringsearchingalgorithm[C]//CommunicationsoftheAqCM,1977,20(10):762-772,.
张鑫,等.
一种改进的wu—Manber多关键词算法[刀.
计算机应用,2003,23(7):29—31.
孙晓山,等.
一种改进的Wu-Manber多模式匹配算法及应用[J].
中文信息学报,2006,20(2):47—52.
王素琴,邹旭楷.
一种优化的并行汉字/字符串匹配算法[J].
中文信息学报,1995,9(1):49--53.
陈开渠,等.
快速中文字符串模糊匹配算法[J].
中文信息学报,2004,18(2):58-65.
(上接第8页)[6]BunescuR.
c.
andMooneyR.
J.
2005.
AShortestintegratedinformationusingkernelmethods[c]//PathDependencyKernelforRelationExtraction[J].
ACL,2005:419-426.
EMNI,P一2005:724—731.
[10]ZhouGD,SuJ,ZhangJ.
ZhangM.
Exploringvari--[7]ZhangM,ZhangJ,suJ,eta1.
ACompositeKerneltoOUSknowledgeinrelationextraction[c]//AcL,2005:ExtractRel;ltionsbetweenEntitieswithbothFlatand427-434.
StructuredFeatures[c]//AcL,2006:825·"832.
[11]Charniak,Eugene.
Intermediate-headParsingfor[83KambhatlaN.
Combininglexical,syntacticandsemanticLanguageModels[C]//ACL,2001:116—123.
featureswithMaximumEntropymodelsforextracting[12]MoschittiA.
AstudyonConvolutionKernelsforrelations[.
C]//ACL(poster),2004:178--181.
ShallowSemanticParsing[C]//AcL,2004.
[9]ZhaoSB.
GrishmanR.
Extractingrelationswith万方数据
- 关系projectace相关文档
- ulatoryprojectace
- potentialprojectace
- lOOprojectace
- calculatingprojectace
- clubsprojectace
- OWLprojectace
Fiberia.io:$2.9/月KVM-4GB/50GB/2TB/荷兰机房
Fiberia.io是个新站,跟ViridWeb.com同一家公司的,主要提供基于KVM架构的VPS主机,数据中心在荷兰Dronten。商家的主机价格不算贵,比如4GB内存套餐每月2.9美元起,采用SSD硬盘,1Gbps网络端口,提供IPv4+IPv6,支持PayPal付款,有7天退款承诺,感兴趣的可以试一试,年付有优惠但建议月付为宜。下面列出几款主机配置信息。CPU:1core内存:4GB硬盘:...
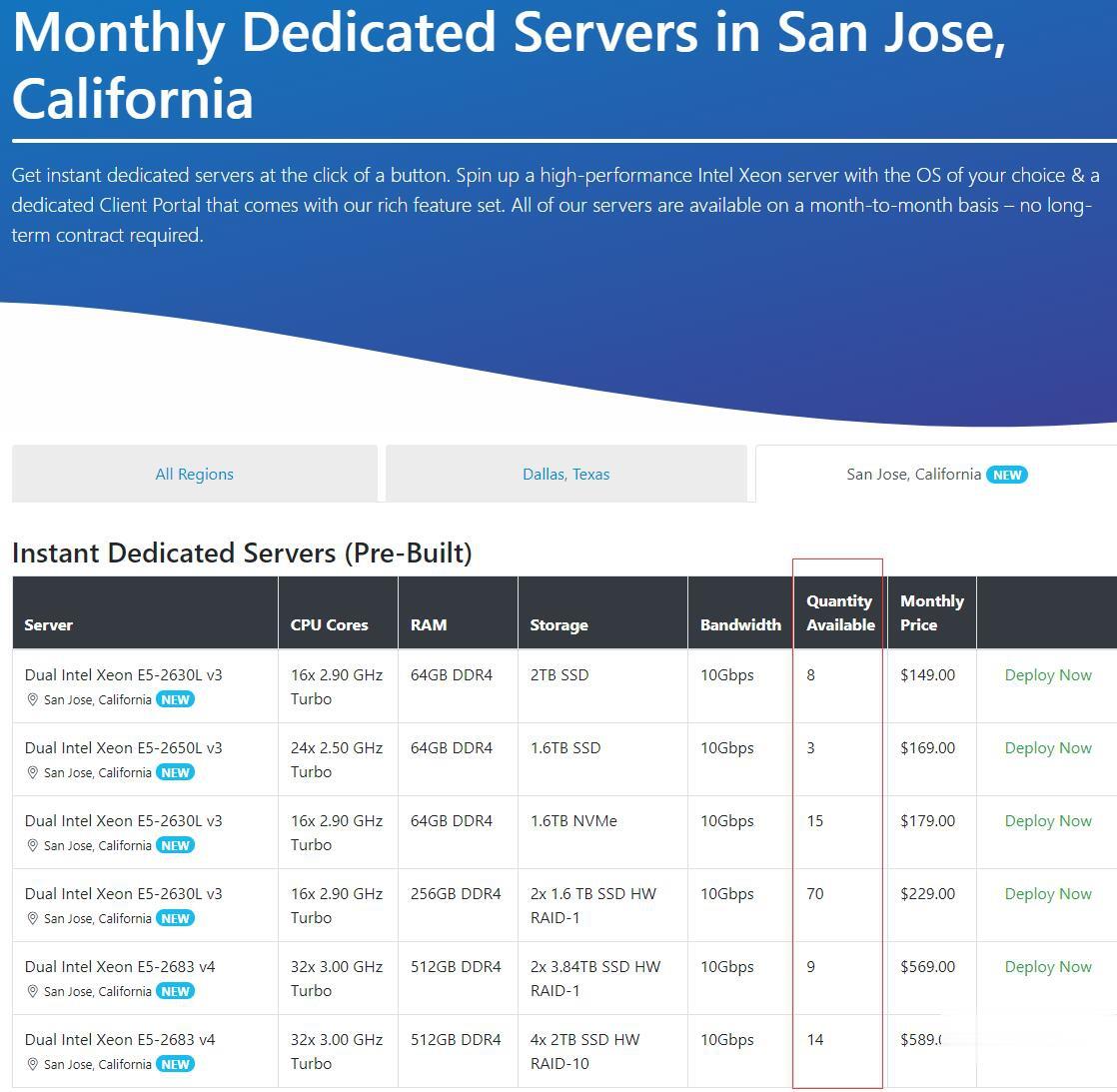
Spinservers:美国圣何塞机房少量补货/双E5/64GB DDR4/2TB SSD/10Gbps端口月流量10TB/$111/月
Chia矿机,Spinservers怎么样?Spinservers好不好,Spinservers大硬盘服务器。Spinservers刚刚在美国圣何塞机房补货120台独立服务器,CPU都是双E5系列,64-512GB DDR4内存,超大SSD或NVMe存储,数量有限,机器都是预部署好的,下单即可上架,无需人工干预,有需要的朋友抓紧下单哦。Spinservers是Majestic Hosting So...
捷锐数据399/年、60元/季 ,香港CN2云服务器 4H4G10M
捷锐数据官网商家介绍捷锐数据怎么样?捷锐数据好不好?捷锐数据是成立于2018年一家国人IDC商家,早期其主营虚拟主机CDN,现在主要有香港云服、国内物理机、腾讯轻量云代理、阿里轻量云代理,自营香港为CN2+BGP线路,采用KVM虚拟化而且单IP提供10G流量清洗并且免费配备天机盾可达到屏蔽UDP以及无视CC效果。这次捷锐数据给大家带来的活动是香港云促销,总共放量40台点击进入捷锐数据官网优惠活动内...

ProjectAce为你推荐
-
bbs2.99nets.com西安论坛、西安茶馆网、西安社区、西安bbs 的网址是多少?广告法广告法有什么字不能用www.1diaocha.com手机网赚是真的吗hao.rising.cn我一打开网页就是瑞星安全网站导航,怎么修改?鹤城勿扰黑龙江省的那个 城市是被叫做鹤城?网页源代码网页的HTML代码猴山条约游猴山,观猴子长房娇古诗长一点苗惟妮最新青春偶像剧2010www.38.com俺去也的最新网址是什么?