遇见数据仓库什么是数据仓库?
遇见数据仓库 时间:2022-02-12 阅读:()
数据库 数据仓库 数据集市有哪些联系和区别
数据库一般指面向事务处理的数据应用,比如最简单的一个网站系统的数据库; 数据仓库是面向主题的,主要面向用户的决策需求等,里面又大量历史数据,这些数据是从源数据(文本,来自数据库等方式)经过ETL过程产生的; 数据集市是在数据仓库基础上做得面向分析的,一般有很多报表 这些是我工作中遇到的,简单想了想这些特点,不是专业研究,请高手们指教。数据仓库的主要应用在哪些方面?
数据仓库是一个面向主题的,集成的,时变的和非易失的数据集合,支持管理部门的决策过程。面向主题是指数据仓库围绕一些主题来组织,区别于事务。 集成的是指数据仓库是将多个异构数据源集成在一起。 时变的是指数据存储从历史的角度提供数据。 非易失的是指数据仓库只在初始化装入和数据查询时操作数据,不存在更新,插入等操作,极大多为读操作,而非写操作。 数据仓库更多的是用于决策分析,通过分析储存的历史数据挖掘出规律,以及预测以后的发展。数据仓库的技术发展
从数据库到数据仓库 企业的数据处理大致分为两类:一类是操作型处理,也称为联机事务处理,它是针对具体业务在数据库联机的日常操作,通常对少数记录进行查询、修改。另一类是分析型处理,一般针对某些主题的历史数据进行分析,支持管理决策。 两者具有不同的特征,主要体现在以下几个方面。 1、处理性能 日常业务涉及频繁、简单的数据存取,因此对操作型处理的性能要求是比较高的,需要数据库能够在很短时间内做出反应。 2、数据集成 企业的操作型处理通常较为分散,传统数据库面向应用的特性使数据集成困难。 3、数据更新 操作型处理主要由原子事务组成,数据更新频繁,需要并行控制和恢复机制。 4、数据时限 操作型处理主要服务于日常的业务操作。 5、数据综合 操作型处理系统通常只具有简单的统计功能。 数据库已经在信息技术领域有了广泛的应用,我们社会生活的各个部门,几乎都有各种各样的数据库保存着与我们的生活息息相关的各种数据。作为数据库的一个分支,数据仓库概念的提出,相对于数据库从时间上就近得多。美国著名信息工程专家WilliamInmON博士在90年代初提出了数据仓库概念的一个表述,认为:“一个数据仓库通常是一个面向主题的、集成的、随时间变化的、但信息本身相对稳定的数据集合,它用于对管理决策过程的支持。” 这里的主题,是指用户使用数据仓库进行决策时所关心的重点方面,如:收入、客户、销售渠道等;所谓面向主题,是指数据仓库内的信息是按主题进行组织的,而不是像业务支撑系统那样是按照业务功能进行组织的。 集成,是指数据仓库中的信息不是从各个业务系统中简单抽取出来的,而是经过一系列加工、整理和汇总的过程,因此数据仓库中的信息是关于整个企业的一致的全局信息。 随时间变化,是指数据仓库内的信息并不只是反映企业当前的状态,而是记录了从过去某一时点到当前各个阶段的信息。 数据库安全 计算机攻击、内部人员违法行为,以及各种监管要求,正促使组织寻求新的途径来保护其在商业数据库系统中的企业和客户数据。 您可以采取八个步骤保护数据仓库并实现对关键法规的遵从。 1. 发现 使用发现工具发现敏感数据的变化。 2.漏洞和配置评估 评估数据库配置,确保它们不存在安全漏洞。这包括验证在操作系统上安装数据库的方式(比如检查数据库配置文件和可执行程序的文件权限),以及验证数据库自身内部的配置选项(比如多少次登录失败之后锁定帐户,或者为关键表分配何种权限)。 3. 加强保护 通过漏洞评估,删除不使用的所有功能和选项。 4. 变更审计 通过变更审计工具加强安全保护配置,这些工具能够比较配置的快照(在操作系统和数据库两个级别上),并在发生可能影响数据库安全的变更时,立即发出警告。 5. 数据库活动监控(DAM) 通过及时检测入侵和误用来限制信息暴露,实时监控数据库活动。 6. 审计 必须为影响安全性状态、数据完整性或敏感数据查看的所有数据库活动生成和维护安全、防否认的审计线索。 7.身份验证、访问控制和授权管理 必须对用户进行身份验证,确保每个用户拥有完整的责任,并通过管理特权来限制对数据的访问。 8. 加密 使用加密来以不可读的方式呈现敏感数据,这样攻击者就无法从数据库外部对数据进行未授权访问。 如何应对监控需求 数据,作为企业核心资产,越来越受到企业的关注,一旦发生非法访问、数据篡改、数据盗取,将给企业带来巨大损失。数据库作为数据的核心载体,其安全性就更加重要。 面对数据库的安全问题,企业常常遇到以下主要挑战:数据库被恶意访问、攻击、甚至遭到数据偷窃,而您不能及时地发现这些恶意的操作; 不了解数据使用者对数据库的访问细节,从而不能保证您对数据安全的管理; 信息安全同样会带来审计问题,当今全球对合规/ 审计要求越来越严格,由于不满足合规要求而导致处罚的事件屡见不鲜。美国《萨班斯法案》的强制性要求曾导致2007年7月5日中国第一家海外上市公司—华晨中国汽车控股有限公司从美国纽约证券交易所退市。 有关信息安全的合规/审计要求,中国政府也进行了大量的强化工作,例如,为了加强商业银行信息科技风险管理,银监会出台了《商业银行信息科技风险管理指引》规则,中国政府——财政部、证监会、银监会、保监会及审计署等五部委会联合发布“中国版萨班尼斯-奥克斯利法案(以下简称‘C-SOX法案’)”——《企业内部控制基本规范》。 面对合规/审计要求,企业往往面临以下挑战: ·不能做到持续性审计 用户审计主要是针对数据库、应用系统日志做审计,这些日志内容非常庞大,DBA(数 据库管理员)和信息安全审计人员的审计工作就只能做事后分析,分析时间也长。不能做到持续性审计。 ·审计并不规范 用户审计的内容和表格主要是根据外部审计人员要求和内部安全管理要素来考虑,这些 审计工作的好坏基本上取决于DBA和信息安全审计人员的经验和技能,这些不能有效成为公司规范和满足外部审计要求。 ·数据库管理员权责没有完全区分开,导致审计效果问题 数据库管理和审计原始数据的收集实际上都是由DBA来做的,这就导致了DBA的权责不明确,DBA没办法客观审计自己所做的工作,尽管用户设置了信息安全审计人员,但该角色的审计工作的部分证据建立在DBA初步审计基础上,因此审计效果与可靠性存问题。 ·审计并不完整 人工审计需要面对海量的日志,不可能对所有数据进行细致审计;审计报告就未必能满足 100%可见性。 为了满足企业的信息安全、合规、审计等需求,IBM公司推出了“CARS”企业信息架构,该架构主要从“法规遵从”(Compliance)、“信息可用”(Availability)、“信息保留”(Retention)、“信息安全”(Security) 四个方面进行了全面的满足和保护。不仅如此,IBM Guardium数据库安全、合规、审计、监控解决方案的推出,针对了“法规遵从”和“信息安全”进行了专项治理和加强。 Guardium数据库安全、合规、审计、监控解决方案,以软硬件一体服务器的方式,大大增强数据库安全性,满足并方便审计工作,提升性能,并简化了安装部署工作。可以防止对数据库的破坏、恶意访问、偷窃数据,可帮助判断客户关键敏感的数据在什么地方;谁在使用这些数据;控制对数据库中数据的访问,并可监控特权用户;帮助企业强制执行安全规范;检查薄弱环节、漏洞,防止对数据库配置的改动;满足合规/审计的要求,并可简化内部和外部审计、合规的过程并使其自动化,增强运作效率;管理安全的复杂性。数据仓库建模,星型模型大致了解,就是事实表对应许多维表;对雪花型模型就不是很理解了
详细和你说一下星型模型和雪花模型 星型模式 vs 雪花模型多维数据建模以直观的方式组织数据,并支持高性能的数据访问。每一个多维数据模型由多个多维数据模式表示,每一个多维数据模式都是由一个事实表和一组维表组成的。多维模型最常见的是星形模式。在星形模式中,事实表居中,多个维表呈辐射状分布于其四周,并与事实表连接。在星型的基础上,发展出雪花模式,下面就二者的特点做比较。 星型模式位于星形中心的实体是指标实体,是用户最关心的基本实体和查询活动的中心,为数据仓库的查询活动提供定量数据。每个指标实体代表一系列相关事实,完成一项指定的功能。位于星形图星角上的实体是维度实体,其作用是限制用户的查询结果,将数据过滤使得从指标实体查询返回较少的行,从而缩小访问范围。每个维表有自己的属性,维表和事实表通过关键字相关联。星形模式虽然是一个关系模型,但是它不是一个规范化的模型。在星形模式中,维度表被故意地非规范化了,这是星形模式与OLTP系统中的关系模式的基本区别。使用星形模式主要有两方面的原因:提高查询的效率。采用星形模式设计的数据仓库的优点是由于数据的组织已经过预处理,主要数据都在庞大的事实表中,所以只要扫描事实表就可以进行查询,而不必把多个庞大的表联接起来,查询访问效率较高。同时由于维表一般都很小,甚至可以放在高速缓存中,与事实表作连接时其速度较快;便于用户理解。对于非计算机专业的用户而言,星形模式比较直观,通过分析星形模式,很容易组合出各种查询。总结:非正规化;多维数据集中的每一个维度都与事实表连接(通过主键和外键);不存在渐变维度;有冗余数据;查询效率可能会比较高;不用过多考虑正规化因素,设计维护较为简单。 雪花模式 在实际应用中,随着事实表和维表的增加和变化,星形模式会产生多种衍生模式,包括星系模式、星座模式、二级维表和雪花模式。雪花模式是对星形模式维表的进一步层次化,将某些维表扩展成事实表,这样既可以应付不同级别用户的查询,又可以将源数据通过层次间的联系向上综合,最大限度地减少数据存储量,因而提高了查询功能。雪花模式的维度表是基于范式理论的,因此是界于第三范式和星形模式之间的一种设计模式,通常是部分数据组织采用第三范式的规范结构,部分数据组织采用星形模式的事实表和维表结构。在某些情况下,雪花模式的形成是由于星形模式在组织数据时,为减少维表层次和处理多对多关系而对数据表进行规范化处理后形成的。雪花模式的优点是:在一定程度上减少了存储空间;规范化的结构更容易更新和维护。同样雪花模式也存在不少缺点:雪花模式比较复杂,用户不容易理解;浏览内容相对困难;额外的连接将使查询性能下降。在数据仓库中,通常不推荐“雪花化”。因为在数据仓库中,查询性能相对OLTP系统来说更加被重视,而雪花模式会降低数据仓库系统的性能。总结:正规化;数据冗余少;有些数据需要连接才能获取,可能效率较低;规范化操作较复杂,导致设计及后期维护复杂;实际应用中,可以采取上述两种模型的混合体:如:中间层使用雪花结构以降低数据冗余度,数据集市部分采用星型以方便数据提取及和分析。 有时候规范化和效率是一组矛盾。一般我们会采取牺牲空间(规范化)来换取好的性能,把尽可能多的维度信息存在一张“大表”里面是最快的。通常会视情况而定,采取折中的策略。 星型有时会造成数据大量冗余,并且很有可能将事实表变的及其臃肿(上百万条数据×上百个维度)。 每次遇到需要更新维度成员的情况时,都必须连事实表也同时更新。 而雪花型,有时只需要更新雪花维度中的一层即可,无需更改庞大的事实表。 具体问题具体分析,如时间维度,年,季就没必要做雪花,而涉及到产品和产品的分类,如果分类信息也是我们需要分析的信息,那么,我肯定是建关于分类的查找表,也就是采用雪花模式 雪花型结构是一种正规化结构,他取除了数据仓库中的冗余数据。比如有一张销售事实表,然后有一张产品维度表与之相连,然后有一张产品类别维度表与产品维度表连。这种结构就是雪花型结构。雪花型结构取除了数据冗余,所以有些统计就需要做连接才能产生,所以效率不一定有星型架构高。正规化也是一种比较复杂的过程,相应数据库结构设计、数据的ETL、以及后期的维护都要复杂一些。 星型架构是一种非正规化的结构,多维数据集中的每一个维度都与事实表相连接,不存在渐变维度,所以数据有一定的冗余,正因为数据的冗余所以很多统计查询不需要做外部的连接所以一般情况下效率比雪花型要高。星型结构不用考虑很多正规化的因素,设计与实现都比较简单。 虽然两种结构有一定差别,我个人认为没有好坏之分,最主要的还是看项目的需求,看业务逻辑。数据仓库是干什么的,到现在,我终于看到了成
数据库是面向事务的设计,数据仓库是面向主题设计的。 数据库一般存储在线交易数据,数据仓库存储的一般是历史数据。 数据库设计是尽量避免冗余,一般采用符合范式的规则来设计,数据仓库在设计是有意引入冗余,采用反范式的方式来设计。 数据库是为捕获数据而设计,数据仓库是为分析数据而设计,它的两个基本的元素是维表和事实表。(维是看问题的角度,比如时间,部门,维表放的就是这些东西的定义,事实表里放着要查询的数据,同时有维的ID)可以导入access的文件库包括
大型的数据库开发中常常遇到数据源是平面文件(如文本文件)的情况,对于这样的数据源,无法使用数据库对其数据进行有效的管理,另外也无法使用SQL语句对其进行查询和操作,所以当务之急就是将这些平面文件导入到数据库中,然后就可以对其进行高效的操作了。 下面介绍几种常见的数据导入的方法,希望能够给大家启迪。另外,本文所涉及到的数据库均为ORACLE数据库,其实对于其他数据库而言,方法类似。 一、Sql*:Loader 该方法是Oracle数据库下数据导入的最重要的方法之一,该工具由Oracle客户端提供, 其基本工作原理是:首先要针对数据源文件制作一个控制文件,控制文件是用来解释如何对源文件进行解析,其中需要包含源文件的数据格式、目标数据库的字段等信息,一个典型的控制文件为如下形式: LOAD DATA INFILE '/ora9i/fengjie/agent/data/ipaagentdetail200410.txt' TRUNCATE INTO TABLE fj_ipa_agentdetail fields terminated "," trailing nullcols ( AGENT_NO char, AGENT_NAME char, AGENT_ADDRESS char, AGENT_LINKNUM char, AGENT_LINKMAN char ) 其中,INFILE '/ora9i/fengjie/agent/data/ipaagentdetail200410.txt'指明所要导入的源文件,其实源文件也可以直接通过命令行来输入获得,fj_ipa_agentdetail为目标表的名字,fields terminated ","是指源文件的各个字段是以逗号分隔,trailing nullcols表示遇到空字段依然写入到数据库表中,最后这5个字段是目标数据库表的字段结构。通过上面这个典型的控制文件的格式分析可知,控制文件需要与源文件的格式信息一致,否则导入数据会出现异常。 除了控制以外,sql*loader的还需要数据文件,即源文件。根据格式的不同,源文件可以分为固定字段长度和有分隔符这两大类,这里将分别说明这两种情况: 固定字段长度的文本文件 就是每个字段拥有固定的字段长度,比如: 602530005922 1012 602538023138 1012 602536920355 1012 602531777166 1012 602533626494 1012 602535700601 1012 有分隔符的文本文件 就是每个字段都有相同的分隔符分隔,比如: 1001,上海长途电信综合开发公司,南京东路34号140室 1002,上海桦奇通讯科技有限公司,武宁路19号1902室 1003,上海邦正科技发展有限公司,南京东路61号903室 对于上述两种文件格式sql*loader均可以做处理,下面就前面那个固定长度的文本来举例说明: 由于该文本只有两个字段,一个为设备号,一个是区局编号,两者的长度分别为20和5,那么可以编制控制文件如下: LOAD DATA INFILE '/ora9i/fengjie/agent/data/ipaagent20041掸弗侧煌乇号岔铜唱扩0.txt' TRUNCATE INTO TABLE fj_ipa_agent ( DEVNO POSITION(1:20) CHAR, BRANCH_NO POSITION(21:25) CHAR ) 其中,'/ora9i/fengjie/agent/data/ipaagent200410.txt'为该文件的完全路径,POSITION(M:N)表示该字段是从位置M到位置N。 对于有分隔符的数据文件,前面已经有一个例子,这里就不再赘述了。总之,使用Sql*Loader能够轻松将数据文件导入到数据库中,这种方法也是最常用的方法。 二、 使用专业的数据抽取工具 目前在数据仓库领域中,数据抽取与装载(ETL)是一重要的技术,这一技术对于一些大的数据文件或者文件数量较多尤其适合。这里简单介绍目前一款主流的数据抽取工具――Informatica。 该工具主要采用图形界面进行编程,其主要工作流程是:首先将源数据文件的结构(格式)导入为Informatica里,然后根据业务规则对该结构进行一定的转换(transformation),最终导入到目标表中。 以上过程仅仅只是做了一个从源到目标的映射,数据的实际抽取与装载需要在工作流(workflow)里进行。 使用专业的数据抽取工具,可以结合业务逻辑对多个源数据进行join,union,insect等操作,适合于大型数据库和数据仓库。 三、 使用ess工具导入 可以直接在ess里选择‘打开‘文本文件,这样按照向导来导入一个文本文件到ess数据库中,然后使用编程的方法将其导入到最终的目标数据库中。 这种方法虽然烦琐,但是其对系统的软件配置要求相对较低,所以也是有一定的使用范围。 四、 小结 总之,平面文件转化为数据库格式有利于数据的处理,显然,数据库强大的数据处理能力比直接进行文件I/O效率高出很多,希望本文能够对该领域做一个抛砖引玉的作用。如何提升数据仓库的数据质量
随着国内电信市场竞争的日趋激烈,各大电信运营商纷纷建立了各自的数据仓库或经营分析系统,这些系统功能强大,让用户眼前一亮,但是随之而来的问题就是,系统提供的这些数据准确吗?这种怀疑并非没有道理,很多时候,数据仓库生成的数据和已有生产系统进行数据核对时存在一定的差距,有些指标甚至相差甚远,用户对数据仓库的数据可用性心存疑虑,数据质量的问题困扰着数据仓库的进一步应用和发展。 数据质量不高,有人简单地以为数据是错误的,数据不可用。其实数据质量问题比较复杂,不能用简单的对错来区分。下面是数据质量问题所表现出来的几种典型情况: 1. 数据不完整。这种情况比较多,例如记录的缺失、字段信息的缺失、记录不完整等。最明显的例子就是用户入网登记的证件号码没有输入到系统。 2. 数据不一致。这种情况主要指由于系统之间或者功能模块之间记录不一致、编码不一致、引用不一致等。例如在97系统、计费系统、网管系统中由于业务受理处理流程不规范,或者系统之间同步时间不一致导致了不同系统中用户记录数不一致。 3.数据有错误。这种情况主要是指数据中存在各种不合法的情况,例如数据类型错误、数据范围越界、数据违反业务规则等。 除了第三种情况是明显的数据错误之外,其他两种都不能简单地认为是错误,这两种情况在数据仓库建设中是比较普遍遇到的,关键是对数据质量的状况有深入的认识,在应用上加以注意。下面从数据仓库的各个主要关键点来剖析数据质量产生的原因。 数据源 不可否认,数据质量问题有些是从生产系统带入到数据仓库的。在生产系统长期运作的过程中,很可能会引入一些噪音数据,直到有一天被数据仓库采集,并且被加工使用得出意外的结果之后,才发现有这个问题存在,这种情况在生产系统中并不少见。 ETL 在ETL过程中,有相当多的地方可能会产生数据质量问题: ● 数据抽取:从源系统中抽取数据,一般要编制数据抽取代码或者借助一些工具配置进行数据抽取,在这个过程,可能会出现编码错误或者工具配置不当,导致原始数据正确而抽取出来的数据不正确。 ● 数据转换:数据抽取完成之后,如果数据形式不一样还需要做形式的一致化处理,一致化处理如果不当就会引入数据质量问题。 ● 数据加载:数据转换完成之后要进行数据加载,在系统运作时可能会出现重复加载或者加载失败的情况,会导致数据量异常。 数据应用 在数据经过ETL之后,进入系统的应该是规范化的数据,用户一般是通过应用界面来访问数据,如果应用访问逻辑有误,输出的结果也会有问题,最常见的就是多表连接时,关联条件不正确,导致结果也不对。 在了解了数据质量的分类情况和可能产生数据质量问题的各个关键点和原因后,下一步是针对不同情况采取不同的措施,从而提升数据质量。在决定提升数据质量之前,首先要明确两个原则: ● 数据质量的提高和投入的成本是相关的。数据质量越高,所投入的人力物力成本就越高,因此数据质量提升工作应该量力而行。 ● 数据质量的高低和应用的需求是相关的。不是所有应用所需要的数据质量要求都一样,有些应用仅仅用于分析趋势的,要求可以不那么严格,但是对于严格统计意义上的信息,要求就比较高。 数据仓库中数据质量提升不仅仅是数据仓库本身的事情,还涉及到各个源系统本身的数据质量改进,需要从源头上杜绝一些问题数据,同时还涉及到数据仓库应用的数据质量改进。下面从产生数据质量的各个环节,考虑数据质量改善方法。 1. 数据源● 规范生产系统中的数据录入。对于新录入到系统中的数据需要严格审查,从源头上保障数据质量。 ● 清理历史数据:对于历史数据需要定期进行清理,对于缺失遗漏数据进行补充,对于错误数据进行改正,对于冗余数据予以清除,从而提高历史数据的准确性。 2. ETL● 数据抽取程序严格审核。抽取的结果要和源系统的数据定期核对,数据抽取逻辑和限制条件要注明。 ● 及时监控源系统的变更。一旦源系统发生变化,提供告警机制,对数据抽取代码和配置信息进行及时更新,以保障后续工作正常进行。 ● 建立故障检测机制。由于故障发生是不可避免的,因此需要建立一套故障检测机制,定期对系统进行扫描,以及时发现故障的发生,进而主动采取控制措施,保证系统ETL的正常运行。 ● 建立数据审核机制。在经过ETL处理之后,需要建立一个可追溯的控制点,这样可以层层对数据进行审核。 3. 数据应用 ● 数据应用程序严格审核。不同应用进行交叉核对,检查数据结果是否正常。 ● 应用结果核对。把应用输出的结果和同类系统提供的报表数据进行核对,检查差异率。 总体而言,数据质量管理是一个复杂艰苦的工作,需要持续不断地进行,才能有效地改善数据质量。只有有效的数据管理才能保证高质量的数据,高质量的数据才能支撑强大的数据仓库应用,才能保证更多的应用成果。数据仓库与ODS的区别,数据仓库和ODS并存方
DW 数据仓库存储是一个面向主题的,反映历史变化数据,用于支撑管理决策。 ODS 操作型数据存储,存储的是当前的数据情况,给使用者提供当前的状态,提供即时性的、操作性的、集成的全体信息的需求。 ODS作为数据库到数据仓库的一种过渡形式,与数据仓库在物理结构上不同,能提供高性能的响应时间,ODS设计采用混合设计方式。 ODS中的数据是"实时值",而数据仓库的数据却是"历史值",一般ODS中储存的数据不超过一个月,而数据仓库为10年或更多. 数据仓库和ODS并存方案 经过调研,发现大体上有三种解法: 1、业务数据 - ODS - 数据仓库 优点:这样做的好处是ODS的数据与数据仓库的数据高度统一;开发成本低,至少开发一次并应用到ODS即可;可见ODS是发挥承上启下的作用,调研阿里巴巴的数据部门也是这么实现的。 缺点:数据仓库需要的所有数据都需要走ODS,那么ODS的灵活性必然受到影响,甚至不利于扩展、系统的灵活性差 2、OB - ODS 优点:结构简单。一般的初创数据分析团队都是类似的结构,比如我们部门就应该归结到这一范畴 缺点:这样所有数据都归结到ODS,长期数据决策分析能力差,软硬件成本高,模块划分不清晰,通用性差 3、数据仓库和ODS并行 可见这个模型兼顾了上面提高的各自优点,且便于扩展,ODS和数据仓库各做各的,形成优势互补!可以解决现在互联网公司遇到的快速变化、快速开发等特点!特别是对于那些刚刚创建数据团队,数据开发人员紧缺的公司,可以尝试使用这个数据架构解决问题!数据仓库是什么
根据数据仓库概念的含义,数据仓库拥有以下四个特点: 1、面向主题。操作型数据库的数据组织面向事务处理任务,各个业务系统之间各自分离,而数据仓库中的数据是按照一定的主题域进行组织。主题是一个抽象的概念,是指用户使用数据仓库进行决策时所关心的重点方面,一个主题通常与多个操作型信息系统相关。 2、集成的。面向事务处理的操作型数据库通常与某些特定的应用相关,数据库之间相互独立,并且往往是异构的。而数据仓库中的数据是在对原有分散的数据库数据抽取、清理的基础上经过系统加工、汇总和整理得到的,必须消除源数据中的不一致性,以保证数据仓库内的信息是关于整个企业的一致的全局信息。 3、相对稳定的。操作型数据库中的数据通常实时更新,数据根据需要及时发生变化。数据仓库的数据主要供企业决策分析之用,所涉及的数据操作主要是数据查询,一旦某个数据进入数据仓库以后,一般情况下将被长期保留,也就是数据仓库中一般有大量的查询操作,但修改和删除操作很少,通常只需要定期的加载、刷新。 4、反映历史变化。操作型数据库主要关心当前某一个时间段内的数据,而数据仓库中的数据通常包含历史信息,系统记录了企业从过去某一时点(如开始应用数据仓库的时点)到目前的各个阶段的信息,通过这些信息,可以对企业的发展历程和未来趋势做出定量分析和预测。 企业数据仓库的建设,是以现有企业业务系统和大量业务数据的积累为基础。数据仓库不是静态的概念,只有把信息及时交给需要这些信息的使用者,供他们做出改善其业务经营的决策,信息才能发挥作用,信息才有意义。而把信息加以整理归纳和重组,并及时提供给相应的管理决策人员,是数据仓库的根本任务。因此,从产业界的角度看,数据仓库建设是一个工程,是一个过程。数据仓库与SQL数据库有什么区别
首先,定义三个概念:数据库软件、数据库、数据仓库。 数据库软件:是一种软件,可以看得见,可以操作。用来实现数据库逻辑功能。属于物理层。 数据库:是一种逻辑概念,用来存放数据的仓库。通过数据库软件来实现。数据库由很多表组成,表是二维的,一张表里可以有很多字段。字段一字排开,对应的数据就一行一行写入表中。数据库的美,在于能够用二维表现多维关系。目前市面上流行的数据库都是二维数据库。如:Oracle、DB2、MySQL、Sybase、MS SQL Server等。 数据仓库:是数据库概念的升级。从逻辑上理解,数据库和数据仓库没有区别,都是通过数据库软件实现的存放数据的地方,只不过从数据量来说,数据仓库要比数据库更庞大得多。数据仓库主要用于数据挖掘和数据分析。 接下来,就是详细说明了。在IT的架构体系中,数据库是必须存在的。必须要有地方存放数据。比如现在的网购,淘宝,京东等等。物品的存货数量,货品的价格,用户的账户余额之类的。这些数据都是存放在后台数据库中。或者最简单理解,我们现在微博,QQ等账户的用户名和密码。在后台数据库必然有一张user表,字段起码有两个,即用户名和密码,然后我们的数据就一行一行的存在表上面。当我们登录的时候,我们填写了用户名和密码,这些数据就会被传回到后台去,去跟表上面的数据匹配,匹配成功了,你就能登录了。匹配不成功就会报错说密码错误或者没有此用户名等。这个就是数据库,数据库在生产环境就是用来干活的。凡是跟业务应用挂钩的,我们都使用数据库。 而数据仓库则是BI下的其中一种技术。由于数据库是跟业务应用挂钩的,所以一个数据库不可能装下一家公司的所有数据。数据库的表设计往往是针对某一个应用进行设计的。比如刚才那个登录的功能,这张user表上就只有这两个字段,没有别的字段了。但是这张表符合应用,没有问题。但是这张表不符合分析。比如我想知道在哪个时间段,用户登录的量最多?哪个用户一年购物最多?诸如此类的指标。那就要重新设计数据库的表结构了。对于数据分析和数据挖掘,我们引入数据仓库概念。数据仓库的表结构是依照分析需求,分析维度,分析指标进行设计的。数据仓库的数据来源于那些后台持续不停运作的数据库表。数据的搬运就牵涉到另一个技术叫ETL。这个过程就是数据从一个数据库到了数据仓库什么是数据仓库 星型模式
展开全部 (星形模式是一种多维的数据关系,它由一个事实表(Fact Table)和一组维表(Dimension Table)组成。每个维表都有一个维作为主键,所有这些维的主键组合成事实表的主键。事实表的非主键属性称为事实(Fact),它们一般都是数值或其他 可以进行计算的数据;而维大都是文字、时间等类型的数据,按这种方式组织好数据我们就可以按照不同的维(事实表主键的部分或全部)来对这些事实数据进行求 和(summary)、求平均(average)、计数(count)、百分比(percent)的聚集计算,甚至可以做20~80分析。这样就可以从不 同的角度数字来分析业务主题的情况。) 在多维分析的商业智能解决方案中,根据事实表和维度表的关系,又可将常见的模型分为星型模型和雪花型模型。在设计逻辑型数据的模型的时候,就应考虑数据是按照星型模型还是雪花型模型进行组织。 当所有维表都直接连接到“ 事实表”上时,整个图解就像星星一样,故将该模型称为星型模型, 如图 2 。 星型架构是一种非正规化的结构,多维数据集的每一个维度都直接与事实表相连接,不存在渐变维度,所以数据有一定的冗余,如在地域维度表中,存在国家 A 省 B 的城市 C 以及国家 A 省 B 的城市 D 两条记录,那么国家 A 和省 B 的信息分别存储了两次,即存在冗余。 销售数据仓库中的星型模型 当有一个或多个维表没有直接连接到事实表上,而是通过其他维表连接到事实表上时,其图解就像多 个雪花连接在一起,故称雪花模型。雪花模型是对星型模型的扩展。它对星型模型的维表进一步层次化,原有的各维表可能被扩展为小的事实表,形成一些局部的 " 层次 " 区域,这些被分解的表都连接到主维度表而不是事实表。如图 2-3,将地域维表又分解为国家,省份,城市等维表。它的优点是 : 通过最大限度地减少数据存储量以及联合较小的维表来改善查询性能。雪花型结构去除了数据冗余 销售数据仓库中的雪花型模型 星型模型因为数据的冗余所以很多统计查询不需要做外部的连接,因此一般情况下效率比雪花型模型要高。星型结构不用考虑很多正规化的因素,设计与实现 都比较简单。 雪花型模型由于去除了冗余,有些统计就需要通过表的联接才能产生,所以效率不一定有星型模型高。正规化也是一种比较复杂的过程,相应的数据库结构设计、数 据的 ETL、以及后期的维护都要复杂一些。因此在冗余可以接受的前提下,实际运用中星型模型使用更多,也更有效率。数据集市的“独立” 性
企业规划数据仓库项目的时候,往往会遇到很多数据仓库软件供应商。各供应商除了推销相关的软件工具外, 同时也会向企业灌输许多概念。其中,数据仓库和数据集市是最常见的两个术语了。各个供应商术语定义不统一、销售策略不一样,这往往会给企业带来很大的混淆。最典型的问题是:到底是先上一个企业级的数据仓库呢?还是先上一个部门级的数据集市?这其实是是否要上独立型数据集市的问题。 数据集市可以分为两种类型——独立型数据集市和从属型数据集市。独立型数据集市直接从操作型环境获取数据,从属型数据集市从企业级数据仓库获取数据,带有从属型数据集市的体系结构。 数据仓库规模大、周期长,一些规模比较小的企业用户难以承担。因此,作为快速解决企业当前存在的实际问题的一种有效方法,独立型数据集市成为一种既成事实。独立型数据集市是为满足特定用户(一般是部门级别的)的需求而建立的一种分析型环境,它能够快速地解决某些具体的问题,而且投资规模也比数据仓库小很多。 独立型数据集市的存在会给人造成一种错觉,似乎可以先独立地构建数据集市,当数据集市达到一定的规模再直接转换为数据仓库。有些销售人员会推销这种观点,其实质却常常是因为建立企业级数据仓库的销售周期太长以至于不好操作。 多个独立的数据集市的累积,是不能形成一个企业级的数据仓库的,这是由数据仓库和数据集市本身的特点决定的—数据集市为各个部门或工作组所用,各个集市之间存在不一致性是难免的。因为脱离数据仓库的缘故,当多个独立型数据集市增长到一定规模之后,由于没有统一的数据仓库协调,企业只会又增加一些信息孤 岛,仍然不能以整个企业的视图分析数据。借用Inmon的比喻:人们不可能将大海里的小鱼堆在一起就构成一头大鲸鱼,这也说明了数据仓库和数据集市有本质的不同。 如果企业最终想建设一个全企业统一的数据仓库,想要以整个企业的视图分析数据,独立型数据集市恐怕不是合适的选择;也就是说“先独立地构建数据集市,当数据集市达到一定的规模再直接转换为数据仓库”是不合适的。从长远的角度看,从属型数据集市在体系结构上比独立型数据集市更稳定,可以说是数据集市未来建设的主要方向。请高手指点一下学习数据仓库和数据挖掘的步骤!
我也在学,我的方法就是边学边做项目,有好运气的话跟个爱分享知识和技术的老大,那么经验就会增长速度很快,但也要有自己的见解,平时也多在数据仓库论坛晃悠晃悠。我总觉得学东西要有用才行,所以工作中遇到需要学的我就学!最后再反思一下,总结一下,把缺少的地方在学习补充下,就成体系了。见笑教你如何测试数据仓库
分析源文件与其它项目一样,测试数据仓库部署时,通常都会有一份相关的说明文件。虽然这些文件对于创建基本的测试策略非常有用,但经常会缺少一些关于测试开发与执行的详细资料。有时会有一些其它文件解释技术上的细节问题,即从源到目标的转化(source-to-target mappings)说明文件。这些文件详细说明了数据的来源、如何对数据进行操作,以及存储到哪里。如果能拿到这些文件,关于系统设计的文件在设计测试策略时也会变得更加有用。 开发策略和测试计划 分析了各种各样的源文件后,就要开始创建测试策略。我发现从生命周期和质量的角度来看,增量测试是测试数据仓库的最好办法。这从本质上意味着开发团队会从开发过程的早期开始,将各种小组件交付给测试团队。这个办法的主要优点是避免交付让人吃惊的大块组件,可以从早期开始检验缺陷,并使调试变得简单。此外,这个方法还有助于在开发与测试周期中建立详细的过程。具体到数据仓库测试,即是对数据获取分段表,然后是增量表、基本的历史表格、BI视图等的测试。 另一个制定数据仓库测试策略的主要问题是基于分析(analysis-based)的测试方式和基于查询(analysis-based)的测试方式的选择。纯基于分析的方法是让测试分析师通过分析目标数据和相关标准计算出预期结果。基于查询的方法有相同的基本分析步骤,但更进一步,用SQL查询语言编写预期结果。这为将来建立回归测试过程节省了很大精力。如果测试是一次性的,那么用基于分析的方式就足够了,因为通常这种方式较快一些。反之,如果企业对回归测试有持续的需求,那么基于查询的方式会更为合适。 测试的开发与执行 不管在测试执行过程之前还是之后进行测试的开发,要根据上行需求的稳定性和分析过程决定。如果情况变动比较频繁,那么早期进行的测试开发可能大部分都会被废弃。这种场合,实时进行的整合的测试开发和执行过程通常会更有效果。不管怎样,在设计测试开发和执行过程的框架时,参考一下测试分类总是有用的。比如,一些数据仓库的测试分类可能有: 记录计数(预期与实际对比) 副本记录 参考数据有效性 参照完整性 错误与异常逻辑 增量过程与历史过程 控制栏值与默认值 除这些分类外,还可以参考缺陷分类学,比如Larry Greenfield的分类。 测试执行时,准确的状态报告过程是经常被忽略的一个方面。在确定团队里的其他人明白你的方法的前提下,测试分类和测试进度可以保证他们对测试状态也有一个清楚的概念。有了详细的规划并坚持到底,以及良好的沟通,就能建立一个数据仓库测试过程,帮助项目团队取得满意的成果。什么是数据仓库?
数据库是存放数据的仓库。它的2113存储空间很大,可以存放百万条、千万条、上亿条数据。但是数据库并不是随意地5261将数据进行存放,是有一定的规则的,否则查询的效率会很低4102。当今世界是一个充满着数据的互联网世界,充斥着大量的数据。即这个互联网世界就是1653数据世界。数据的来源有很多,比如出行记录、消费记录、浏览的网页、发专送的消属息等等。除了文本类型的数据,图像、音乐、声音都是数据
- 遇见数据仓库什么是数据仓库?相关文档
- 遇见数据仓库数据仓库是什么意思啊?
- 遇见数据仓库数据仓库是什么意思啊?通俗的讲
- 遇见数据仓库如何测试数据仓库
- 遇见数据仓库数据仓库的定义
- 遇见数据仓库数据库DB:SSAS项目部署的若干问题
- 遇见数据仓库元数据是什么
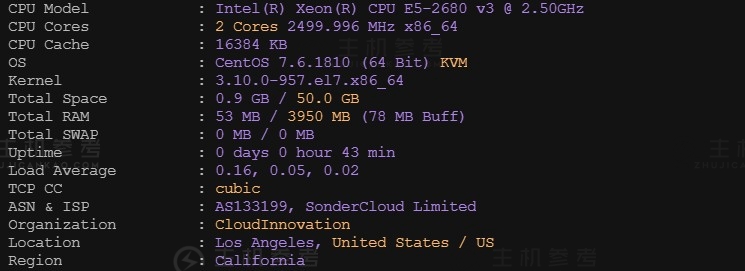
恒创科技SonderCloud,美国VPS综合性能测评报告,美国洛杉矶机房,CN2+BGP优质线路,2核4G内存10Mbps带宽,适用于稳定建站业务需求
最近主机参考拿到了一台恒创科技的美国VPS云服务器测试机器,那具体恒创科技美国云服务器性能到底怎么样呢?主机参考进行了一番VPS测评,大家可以参考一下,总体来说还是非常不错的,是值得购买的。非常适用于稳定建站业务需求。恒创科技服务器怎么样?恒创科技服务器好不好?henghost怎么样?henghost值不值得购买?SonderCloud服务器好不好?恒创科技henghost值不值得购买?恒创科技是...
易探云:香港CN2云服务器低至18元/月起,183.60元/年
易探云怎么样?易探云最早是主攻香港云服务器的品牌商家,由于之前香港云服务器性价比高、稳定性不错获得了不少用户的支持。易探云推出大量香港云服务器,采用BGP、CN2线路,机房有香港九龙、香港新界、香港沙田、香港葵湾等,香港1核1G低至18元/月,183.60元/年,老站长建站推荐香港2核4G5M+10G数据盘仅799元/年,性价比超强,关键是延迟全球为50ms左右,适合国内境外外贸行业网站等,如果需...

HostKvm - 夏季云服务器七折优惠 香港和韩国机房月付5.95美元起
HostKvm,我们很多人都算是比较熟悉的国人服务商,旗下也有多个品牌,差异化多占位策略营销的,商家是一个创建于2013年的品牌,有提供中国香港、美国、日本、新加坡区域虚拟化服务器业务,所有业务均对中国大陆地区线路优化,已经如果做海外线路的话,竞争力不够。今天有看到HostKvm夏季优惠发布,主要针对香港国际和韩国VPS提供7折优惠,折后最低月付5.95美元,其他机房VPS依然是全场8折。第一、夏...

遇见数据仓库为你推荐
-
bch云虚拟主机是什么解释以下几个名词:主机, 虚拟主机,VPS,云主机各是什么意思,它们之间哪个最好?免费web虚拟主机哪个网站可以申请免费的虚拟主机?虚拟主机空间教程虚拟主机空间如何与mysq数据库l连接?虚拟主机的功能是有谁知道虚拟主机的作用呢?它都有什么种类呢?虚拟主机评测网源码买的虚拟主机怎么使用要安装的源码nas当虚拟主机高分请教如何用旧台式机组建一个家用NAS服务器(性能与中档的群晖NAS行当)万网有国外虚拟主机万网怎么转到阿里云了河南虚拟主机托管云主机到底是什么?租用以后该如何使用?昆明本地虚拟主机本机访问本机虚拟机国内虚拟主机租赁哪有性价比高的虚拟主机租用?或者是服务合租的?