通用论坛正文提取算法
一、背景介绍在当今的大数据时代里,伴随着互联网和移动互联网的高速发展,人们产生的数据总量呈现急剧增长的趋势,当前大约每六个月互联网中产生的数据总量就会翻一番.
互联网产生的海量数据中蕴含着大量的信息,已成为政府和企业的一个重要数据来源,互联网数据处理也已成为一个有重大需求的热门行业.
借助网络爬虫技术,我们能够快速从互联网中获取海量的公开网页数据,对这些数据进行分析和挖掘,从中提取出有价值的信息,能帮助并指导我们进行商业决策、舆论分析、社会调查、政策制定等工作.
但是,大部分网页数据是以半结构化的数据格式呈现的,我们需要的信息在页面上往往淹没在大量的广告、图标、链接等"噪音"元素中.
如何从网页中有效提取所需要的信息,一直是互联网数据处理行业关注的重点问题之一.
网页通常采用超级文本标记语言(英文缩写:HTML)来编写,页面上的不同元素如作者、主题、发布日期等出现在一对特定的标记符之间.
例如当我们看到如下一个论坛网页:图1我们可以通过查看这个网页的源代码,查看到与之对应的信息(1)标题信息:图2(2)题主信息:图3(3)题主发帖内容图4(4)回帖信息图5图中的网页源代码就是超级文本标记语言(HTML),关于超级文本标记语言百度百科中是这样描述的:超级文本标记语言是标准通用标记语言下的一个应用,也是一种规范,一种标准,它通过标记符号来标记要显示的网页中的各个部分.
网页文件本身是一种文本文件,通过在文本文件中添加标记符,可以告诉浏览器如何显示其中的内容(如:文字如何处理,画面如何安排,图片如何显示等).
维基百科中对HTML语言的标记、元素、属性、数据类型等也有详细的描述和样例说明.
对于给定的一个具体网页,通常的做法是,人工分析这个网页的源代码,找到特定内容对应的标签,然后通过关键字匹配(例如标签匹配)的方法就可以从网页源代码中获取到我们所关心的数据,如下表所示:表1HTML标签与内容的对应标题:题主:发帖内容:回帖信息:但是,不同网站甚至网页所使用的网页格式、网页结构和标签体系都可能是不一样的,对于从互联网中获取的海量网页的批量处理,如果还利用传统的方法去对每个有差异的网页逐一做人工分析,是不可行的.
如何从这些存在差异的网页中快速有效的提取所需信息,就成为互联网数据处理中一个急需解决的问题.
- 通用论坛正文提取算法相关文档
- 伪卫星技术及其应用
- 中国discuz
- 业务DiscuzNT 系统架构分析
- 的是当DiscuzNT遇上了Loadrunner(上)
- 脚本当DiscuzNT遇上了Loadrunner(中)
- 帖子DiscuzNT简介
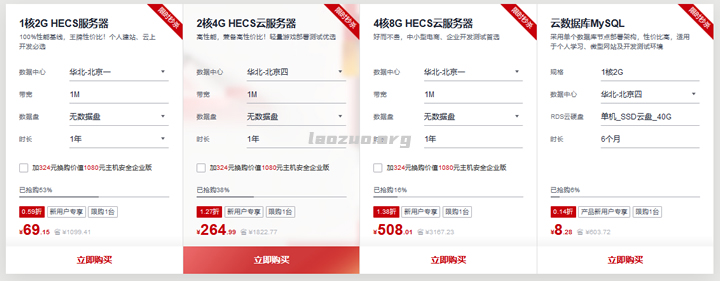
3C云1核1G 9.9元 4核4G 16元 美国Cera 2核4G 24元
3C云互联怎么样?3C云互联专注免备案香港美国日本韩国台湾云主机vps服务器,美国高防CN2GIA,香港CN2GIA,顶级线路优化,高端品质售后无忧!致力于对互联网云计算科技深入研发与运营的极客共同搭建而成,将云计算与网络核心技术转化为最稳定,安全,高速以及极具性价比的云服务器等产品提供给用户!专注为个人开发者用户,中小型,大型企业用户提供一站式核心网络云端服务部署,促使用户云端部署化简为零,轻松...
华为云(69元)828促销活动 2G1M云服务器
华为云818上云活动活动截止到8月31日。1、秒杀限时区优惠仅限一单!云服务器秒杀价低至0.59折,每日9点开抢秒杀抢购活动仅限早上9点开始,有限量库存的。2G1M云服务器低至首年69元。2、新用户折扣区优惠仅限一单!购云服务器享3折起加购主机安全及数据库。企业和个人的优惠力度和方案是不同的。比如还有.CN域名首年8元。华为云服务器CPU资源正常没有扣量。3、抽奖活动在8.4-8.31日期间注册并...
数脉科技香港自营,10Mbps CN2物理机420元/月
数脉科技怎么样?数脉科技品牌创办于2019,由一家从2012年开始从事idc行业的商家创办,目前主营产品是香港服务器,线路有阿里云线路和自营CN2线路,均为中国大陆直连带宽,适合建站及运行各种负载较高的项目,同时支持人民币、台币、美元等结算,提供支付宝、微信、PayPal付款方式。本次数脉科技给发来了新的7月促销活动,CN2+BGP线路的香港服务器,带宽10m起,配置E3-16G-30M-3IP,...

-
weipin唯品宝是什么?和唯品金融有什么关系?刷网站权重如何提高网站权重和流量中国电信互联星空电信不明不白收了我200元互联星空信息费 求解快速美白好方法有什么好方法能快速美白?依赖注入依赖注入是什么意思?手机区号手机电话号码开头95共15位号码是什么手机号码?ps抠图技巧ps抠图多种技巧,越详细越好,急~~~~~~~办公协同软件最好用的协同办公软件是哪个qq空间装扮qq空间怎么装扮如何建立一个网站要建立一个网站怎么弄啊?