数据库范式关系数据库的6个范式
数据库的三大范式?
1、第一范式(1NF) 所谓第一范式(1NF)是指在关系模型中,对于添加的一个规范要求,所有的域都应该是原子性的,即数据库表的每一列都是不可分割的原子数据项,而不能是集合,数组,记录等非原子数据项。即实体中的某个属性有多个值时,必须拆分为不同的属性。
在符合第一范式(1NF)表中的每个域值只能是实体的一个属性或一个属性的一部分。
简而言之,第一范式就是无重复的域。
说明:在任何一个关系数据库中,第一范式(1NF)是对关系模式的设计基本要求,一般设计中都必须满足第一范式(1NF)。
不过有些关系模型中突破了1NF的限制,这种称为非1NF的关系模型。
换句话说,是否必须满足1NF的最低要求,主要依赖于所使用的关系模型。
2、第二范式(2NF) 在1NF的基础上,非码属性必须完全依赖于候选码(在1NF基础上消除非主属性对主码的部分函数依赖) 第二范式(2NF)是在第一范式(1NF)的基础上建立起来的,即满足第二范式(2NF)必须先满足第一范式(1NF)。
第二范式(2NF)要求数据库表中的每个实例或记录必须可以被唯一地区分。
选取一个能区分每个实体的属性或属性组,作为实体的唯一标识。
例如在员工表中的身份证号码即可实现每个一员工的区分,该身份证号码即为候选键,任何一个候选键都可以被选作主键。
在找不到候选键时,可额外增加属性以实现区分,如果在员工关系中,没有对其身份证号进行存储,而姓名可能会在数据库运行的某个时间重复。
无法区分出实体时,设计辟如ID等不重复的编号以实现区分,被添加的编号或ID选作主键。
(该主键的添加是在ER设计时添加,不是建库时随意添加) 第二范式(2NF)要求实体的属性完全依赖于主关键字。
所谓完全依赖是指不能存在仅依赖主关键字一部分的属性,如果存在,那么这个属性和主关键字的这一部分应该分离出来形成一个新的实体,新实体与原实体之间是一对多的关系。
为实现区分通常需要为表加上一个列,以存储各个实例的唯一标识。
简而言之,第二范式就是在第一范式的基础上属性完全依赖于主键。
3、第三范式(3NF) 在2NF基础上,任何非主属性不依赖于其它非主属性(在2NF基础上消除传递依赖) 第三范式(3NF)是第二范式(2NF)的一个子集,即满足第三范式(3NF)必须满足第二范式(2NF)。
简而言之,第三范式(3NF)要求一个关系中不包含已在其它关系已包含的非主关键字信息。
例如,存在一个部门信息表,其中每个部门有部门编号(dept_id)、部门名称、部门简介等信息。
那么在员工信息表中列出部门编号后就不能再将部门名称、部门简介等与部门有关的信息再加入员工信息表中。
如果不存在部门信息表,则根据第三范式(3NF)也应该构建它,否则就会有大量的数据冗余。
简而言之,第三范式就是属性不依赖于其它非主属性,也就是在满足2NF的基础上,任何非主属性不得传递依赖于主属性。
扩展资料 设计关系数据库时,遵从不同的规范要求,设计出合理的关系型数据库,这些不同的规范要求被称为不同的范式,各种范式呈递次规范,越高的范式数据库冗余越小。
目前关系数据库有六种范式:第一范式(1NF)、第二范式(2NF)、第三范式(3NF)、巴斯-科德范式(BCNF)、第四范式(4NF)和第五范式(5NF,又称完美范式)。
满足最低要求的范式是第一范式(1NF)。
在第一范式的基础上进一步满足更多规范要求的称为第二范式(2NF),其余范式以次类推。
一般说来,数据库只需满足第三范式(3NF)就行了。
参考资料:搜狗百科-数据库范式
数据库的五个范式是什么?
第一范式: 对于表中的每一行,必须且仅仅有唯一的行值.在一行中的每一列仅有唯一的值并且具有原子性. (第一范式是通过把重复的组放到每个独立的表中,把这些表通过一对多关联联系起来这种方式来消除重复组的。) 第二范式: 第二范式要求非主键列是主键的子集,非主键列活动必须完全依赖整个主键。
主键必须有唯一性的元素,一个主键可以由一个或更多的组成唯一值的列组成。
一旦创建,主键无法改变,外键关联一个表的主键。
主外键关联意味着一对多的关系. (第二范式处理冗余数据的删除问题。
当某张表中的信息依赖于该表中其它的不是主键部分的列的时候,通常会违反第二范式。
) 第三范式: 第三范式要求非主键列互不依赖. (第三范式规则查找以消除没有直接依赖于第一范式和第二范式形成的表的主键的属性。
我们为没有与表的主键关联的所有信息建立了一张新表。
每张新表保存了来自源表的信息和它们所依赖的主键。
) 第四范式: 第四范式禁止主键列和非主键列一对多关系不受约束 第五范式: 第五范式将表分割成尽可能小的块,为了排除在表中所有的冗余.
数据库三大范式?
作用嘛,主要是规范数据库设计,且视你自己实现的功能而定。
满足范式要求的数据库设计是结构清晰的,同时可避免数据冗余和操作异常。
这并意味着不符合范式要求的设计一定是错误的,在数据库表中存在1:1或1:N关系这种较特殊的情况下,合并导致的不符合范式要求反而是合理的。
关系数据库的几种设计范式介绍 1 第一范式(1NF) 在任何一个关系数据库中,第一范式(1NF)是对关系模式的基本要求,不满足第一范式(1NF)的数据库就不是关系数据库。
所谓第一范式(1NF)是指数据库表的每一列都是不可分割的基本数据项,同一列中不能有多个值,即实体中的某个属性不能有多个值或 者不能有重复的属性。
如果出现重复的属性,就可能需要定义一个新的实体,新的实体由重复的属性构成,新实体与原实体之间为一对多关系 。
在第一范式(1NF)中表的每一行只包含一个实例的信息。
例如,对于图3-2 中的员工信息表,不能将员工信息都放在一列中显示,也不能将 其中的两列或多列在一列中显示;员工信息表的每一行只表示一个员工的信息,一个员工的信息在表中只出现一次。
简而言之,第一范式就是 无重复的列。
2 第二范式(2NF) 第二范式(2NF)是在第一范式(1NF)的基础上建立起来的,即满足第二范式(2NF)必须先满足第一范式(1NF)。
第二范式(2NF)要 求数据库表中的每个实例或行必须可以被唯一地区分。
为实现区分通常需要为表加上一个列,以存储各个实例的唯一标识。
如图3-2 员工信息 表中加上了员工编号(emp_id)列,因为每个员工的员工编号是唯一的,因此每个员工可以被唯一区分。
这个唯一属性列被称为主关键字或主 键、主码。
第二范式(2NF)要求实体的属性完全依赖于主关键字。
所谓完全依赖是指不能存在仅依赖主关键字一部分的属性,如果存在,那么这个 属性和主关键字的这一部分应该分离出来形成一个新的实体,新实体与原实体之间是一对多的关系。
为实现区分通常需要为表加上一个列,以 存储各个实例的唯一标识。
简而言之,第二范式就是非主属性非部分依赖于主关键字。
3 第三范式(3NF) 满足第三范式(3NF)必须先满足第二范式(2NF)。
简而言之,第三范式(3NF)要求一个数据库表中不包含已在其它表中已包含的非主 关键字信息。
例如,存在一个部门信息表,其中每个部门有部门编号(dept_id)、部门名称、部门简介等信息。
那么在图3-2的员工信息表中 列出部门编号后就不能再将部门名称、部门简介等与部门有关的信息再加入员工信息表中。
如果不存在部门信息表,则根据第三范式(3NF)也 应该构建它,否则就会有大量的数据冗余。
简而言之,第三范式就是属性不依赖于其它非主属性。
怎样区分关系数据库中的六个范式?
这六个范式是逐步加强,数据库设计时,满足的范式越高,理论上讲,数据冗余就越少,并且越不容易出问题。。
。
实际上嘛。
。
就不说了。
。
总之,一般设计数据库时要求满足第三范式第一范式的意思就是每列都不可再分,且每个表中的每列都是不重复的,只有满足了第一范式才叫关系型数据库。
先满足第一范式才能满足第二范式,第二范式的意思是表中的每行必须唯一,也就是说,要有能唯一标识每行的列(或几个列也行)满足第二范式才能满足第三范式,第三范式是的意思是要求一个数据库表中不包含已在其它表中已包含的非主关键字信息。
鲍依斯-科得范式,也就是BC范式,在第三范式的基础上,消除传递依赖(传递依赖。
。
这个还有个定义问题:比如A->B,B->C,则A与C之间的依赖就是传递依赖)第四范式,(不废话了,反正前提是先满足前一个范式,下面也一样),消除多值依赖(多值依赖就是存在一对多的关系,间接和直接的都可能有)第五范式,这个就比较扯了,细分成第四范式以后表已经很碎了,第五范式还要求更碎。
。
。
第五范式的目标还是消除多值依赖,不过所消除多值依赖的更难以发现,官方的说法是:保证在第四范式中存在的任何可以分解为实体的三元关系都被分解。
晕不?
数据库中的范式是什么意思?
范式,就是数据库设计的规范模式,一般分为1、2、3和BNC范式,4、5、6几乎不用,主要用于理论研究。模式定义的目的是为了解决数据库设计中的插入、修改、删除异常。
一般使用第三范式或BNC范式。
数据库仓库中为了提高效率,有时还需要降范式。
关系数据库的6个范式
你要明白一个道理,范式的包含关系。一个数据库设计如果符合第二范式,一定也符合第一范式。
如果符合第三范式,一定也符合第二范式… 第一范式(1NF):属性不可分。
第二范式(2NF):符合1NF,并且,非主属性完全依赖于码。
第三范式(3NF):符合2NF,并且,消除传递依赖。
BC范式(BCNF):符合3NF,并且,主属性不依赖于主属性。
第四范式:要求把同一表内的多对多关系删除。
第五范式:从最终结构重新建立原始结构。
先给你说这么多,不明白再问我!谢谢!
- 数据库范式关系数据库的6个范式相关文档
- 数据库范式数据库的五大范式是什么啊?
- 数据库范式数据库中第一范式,第二范式,第三范式、、、、是什么,怎么区分?
- 数据库范式数据库三范式
- 数据库范式什么是数据库中的“范式”?
- 数据库范式数据库有几种范式?
快云科技,免云服务器75折优惠服务器快云21元/月
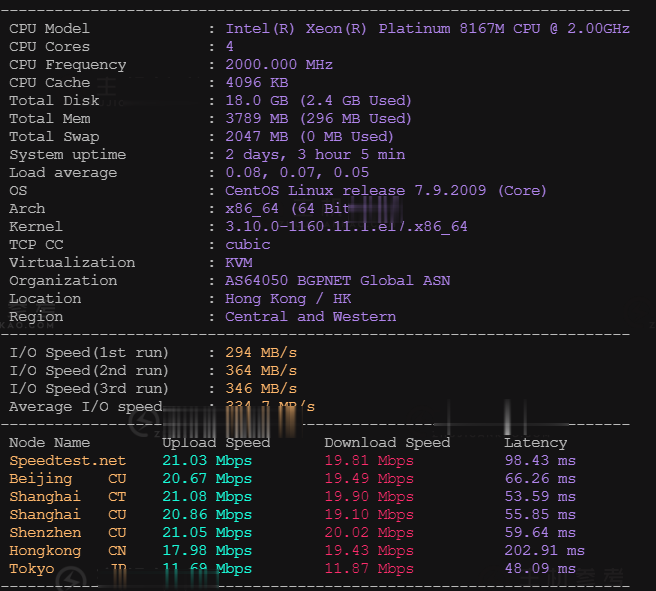
近日快云科技发布了最新的夏季优惠促销活动,主要针对旗下的香港CN2 GIA系列的VPS云服务器产品推送的最新的75折优惠码,国内回程三网CN2 GIA,平均延迟50ms以下,硬件配置方面采用E5 2696v2、E5 2696V4 铂金Platinum等,基于KVM虚拟架构,采用SSD硬盘存储,RAID10阵列保障数据安全,有需要香港免备案CN2服务器的朋友可以关注一下。快云科技怎么样?快云科技好不...
什么是BGP国际线路及BGP线路有哪些优势
我们在选择虚拟主机和云服务器的时候,是不是经常有看到有的线路是BGP线路,比如前几天有看到服务商有国际BGP线路和国内BGP线路。这个BGP线路和其他服务线路有什么不同呢?所谓的BGP线路机房,就是在不同的运营商之间通过技术手段时间各个网络的兼容速度最佳,但是IP地址还是一个。正常情况下,我们看到的某个服务商提供的IP地址,在电信和联通移动速度是不同的,有的电信速度不错,有的是移动速度好。但是如果...

ProfitServer$34.56/年,5折限时促销/可选西班牙vps、荷兰vps、德国vps/不限制流量/支持自定义ISO
ProfitServer怎么样?ProfitServer好不好。ProfitServer是一家成立于2003的主机商家,是ITC控股的一个部门,主要经营的产品域名、SSL证书、虚拟主机、VPS和独立服务器,机房有俄罗斯、新加坡、荷兰、美国、保加利亚,VPS采用的是KVM虚拟架构,硬盘采用纯SSD,而且最大的优势是不限制流量,大公司运营,机器比较稳定,数据中心众多。此次ProfitServer正在对...
-
php文件什么是php文件起英文名好听的英文名字资源优化配置怎样实现资源的最优配置jsp源码jsp 中网站的首页源代码招行信用卡还款招商信用卡怎么还款呢0x800ccc0foutlook 2007 能接收,出现0x800ccc0f错误怎么解决?所有杀毒软件都已经关闭!!硬盘分区格式化怎样给硬盘分区并格式化摇一摇周边微信摇一摇周边红包设置soap是什么意思肥皂剧是什么意思?电商网站设计电子商务网站设计应注意哪些问题