solrsolr的中文是什么意思
solr 时间:2021-08-25 阅读:()
有数据库为什么要solr
严格来说,lucene负责数据存储,而solr只是一个引擎提供搜索和插入而已,跟数据库的解释器一样,有什么好处呢,比如一个数据库有一个字段存了1000个字,你想从这些字里面搜一个词的时候,普通的数据库只会让你使用like去查询,他会遍历每个字去模糊匹配,效率很低,而且有些是无法查询的,当然除了像一些特殊的数据库带有分词,比如postgresql,那lucene做的事情就是分词,然后去匹配分词的词中是否有你想搜的词就好了,当然了,为了提高这种检索效率和内存节省底层做了很复杂的事情,可以这么简单的认为,全文搜索这件事情上数据库是无法满足的如何理解solr的core和collection
Collection:在SolrCloud集群中逻辑意义上的完整的索引。它常常被划分为一个或多个Shard,它们使用相同的Config Set。
如果Shard数超过一个,它就是分布式索引,SolrCloud让你通过Collection名称引用它,而不需要关心分布式检索时需要使用的和Shard相关参数。
solr和solrcloud速度有区别吗
5亿数据量,得考虑用solrcould分片了。使用solrcolud对索引分片,减小单个搜索实例的索引量来提高响应时间,当然使用replica可以提高并发效率。
solr 有几种导入数据的方式
solr数据导入,经过这几天的查资料,我觉得solr数据导入可以有三种方式: 1、编写数据xml文件,通过post.jar导入; 2、通过DIH导入; 3、利用solrj导入数据; 现针对第三种方式进行研究,在第一步中写了一段小的测试代码,可以参考:/solr/Solrj#Streaming_documents_for_an_update 具体的代码解释如下: String url = "http://localhost:8080/solr"; HttpSolrServer server = new HttpSolrServer(url); //If you wish to delete all the data from the index, do this //server.deleteByQuery( "*:*" ); //Construct a document SolrInputDocument doc1 = new SolrInputDocument(); doc1.addField( "id", "id1_solrj" ); doc1.addField( "type", "doc1_solrj" ); doc1.addField( "name", "name1_solrj" ); //Construct another document SolrInputDocument doc2 = new SolrInputDocument(); doc2.addField( "id", "id2" ); doc2.addField( "type", "doc2_solrj" ); doc2.addField( "name", "name2_solrj" ); //Create a collection of documents Collection<SolrInputDocument> docs = new ArrayList<SolrInputDocument>(); docs.add(doc1); docs.add(doc2); //Do mit try { server.add(docs); mit(); } catch (SolrServerException e) { System.out.println("mit error, error code:"); e.printStackTrace(); } catch (IOException e) { System.out.println("mit error, error code:"); e.printStackTrace(); } } 该端代码执行后报异常:expect mime type application/octet-stream but got text/html 没找到这个的解决办法,根据提示好像是说期望的类型和服务器反馈的类型不匹配 最后的解决办法是这样的: 之前在配置solr服务器的时候将solr解压路径solr-4.8.1examplesolr下的solr.xml用solr-4.8.1examplemulticore下的solr.xml文件进行了替换,目的是为了引入core0和core1,现在需要将这个动作进行回滚,并且修改collection1下的conf下的schema.xml文件,修改为对应的需要的列定义。然后执行以上的代码就不会产生问题。
原因我也不太明白,感觉应该是collection1的配置和core1、core0、乃至之前文章提到过的solrtest的配置应该不太一样。
原因待查。
不过现在已经可以通过客户端的方式将数据导入solr服务器,并在前端可以查询到相应的数据。
solr的中文是什么意思
Solr是一个独立的企业级搜索应用服务器,它对外提供类似于Web-service的API接口。用户可以通过http请求,向搜索引擎服务器提交一定格式的XML文件,生成索引;也可以通过Http Get操作提出查找请求,并得到XML格式的返回结果。
- solrsolr的中文是什么意思相关文档
- solrsolr是什么
- solr如何配置自己的 solr java 搜索
- solrsolr 多张表的配置问题,你回答的 uinquekey 一样导致数据更新
- solrJava框架solr用哪个版本的好?
青云互联19元/月,美国洛杉矶CN2GIA/香港安畅CN2云服务器低至;日本云主机
青云互联怎么样?青云互联美国洛杉矶cn2GIA云服务器低至19元/月起;香港安畅cn2云服务器低至19元/月起;日本cn2云主机低至35元/月起!青云互联是一家成立于2020年的主机服务商,致力于为用户提供高性价比稳定快速的主机托管服务。青云互联本站之前已经更新过很多相关文章介绍了,青云互联的机房有香港和洛杉矶,都有CN2 GIA线路、洛杉矶带高防,商家承诺试用7天,打死全额退款点击进入:青云互联...
hosthatch:14个数据中心15美元/年
hosthatch在做美国独立日促销,可能你会说这操作是不是晚了一个月?对,为了准备资源等,他们拖延到现在才有空,这次是针对自己全球14个数据中心的VPS。提前示警:各个数据中心的网络没有一个是针对中国直连的,都会绕道而且ping值比较高,想买的考虑清楚再说!官方网站:https://hosthatch.com所有VPS都基于KVM虚拟,支持PayPal在内的多种付款方式!芝加哥(大硬盘)VPS5...
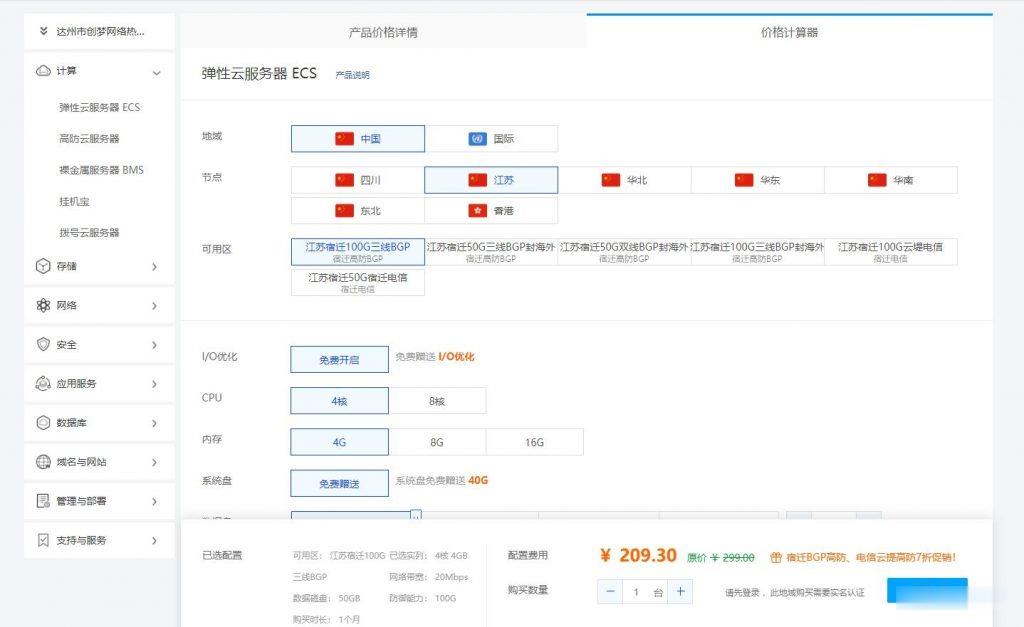
创梦网络-江苏宿迁BGP云服务器100G高防资源,全程ceph集群存储,安全可靠,数据有保证,防护真实,现在购买7折促销,续费同价!
官方网站:点击访问创梦网络宿迁BGP高防活动方案:机房CPU内存硬盘带宽IP防护流量原价活动价开通方式宿迁BGP4vCPU4G40G+50G20Mbps1个100G不限流量299元/月 209.3元/月点击自助购买成都电信优化线路8vCPU8G40G+50G20Mbps1个100G不限流量399元/月 279.3元/月点击自助购买成都电信优化线路8vCPU16G40G+50G2...
solr为你推荐
-
价格咨询心理咨询价格昂贵吗封包是什么灰指甲封包治疗是什么,真的管用吗?安卓手机用什么安全软件好现在的安卓手机用哪个应用下载软件好用?安卓手机用什么安全软件好手机应用软件下载哪个好用?我的手机是安卓系统的,帮忙推荐一个,谢谢ldap统一用户认证介绍NIPS是什么认证?锤子手机发布会视频我如果学习好会遇见长的漂亮而且优秀的人吗?如果我学习好,长的漂亮的人会对我有好感吗?小时代发布会完整版郭敬明《小时代2.0虚铜时代》限量版上市时间广州品牌网站设计广州品牌设计公司hadoop大数据平台大数据分析与应用平台 是什么样的系统终端设备电脑终端是什么意思