弗洛伊德算法弗洛伊德算法和地杰斯特拉算法的区别
弗洛伊德算法 时间:2021-07-22 阅读:()
matlab实现弗洛伊德算法的代码,。
function [d,r]=floyd(a) %floyd.m %采用floyd算法计算图a中每对顶点最短路 %d是矩离矩阵 %r是路由矩阵 n=size(a,1); d=a; for i=1:n for j=1:n r(i,j)=j; end end r for k=1:n for i=1:n for j=1:n if d(i,k)+d(k,j)【例】关键字序列(10,15,56,25,30,70)和(70,56,30,25,15,10)分别满足堆性质(1)和(2),故它们均是堆,其对应的完全二叉树分别如小根堆示例和大根堆示例所示。
2、大根堆和小根堆 根结点(亦称为堆顶)的关键字是堆里所有结点关键字中最小者的堆称为小根堆。
根结点(亦称为堆顶)的关键字是堆里所有结点关键字中最大者,称为大根堆。
注意: ①堆中任一子树亦是堆。
②以上讨论的堆实际上是二叉堆(Binary Heap),类似地可定义k叉堆。
3、堆排序特点 堆排序(HeapSort)是一树形选择排序。
堆排序的特点是:在排序过程中,将R[l..n]看成是一棵完全二叉树的顺序存储结构,利用完全二叉树中双亲结点和孩子结点之间的内在关系【参见二叉树的顺序存储结构】,在当前无序区中选择关键字最大(或最小)的记录。
4、堆排序与直接插入排序的区别 直接选择排序中,为了从R[1..n]中选出关键字最小的记录,必须进行n-1次比较,然后在R[2..n]中选出关键字最小的记录,又需要做n-2次比较。
事实上,后面的n-2次比较中,有许多比较可能在前面的n-1次比较中已经做过,但由于前一趟排序时未保留这些比较结果,所以后一趟排序时又重复执行了这些比较操作。
堆排序可通过树形结构保存部分比较结果,可减少比较次数。
5、堆排序 堆排序利用了大根堆(或小根堆)堆顶记录的关键字最大(或最小)这一特征,使得在当前无序区中选取最大(或最小)关键字的记录变得简单。
(1)用大根堆排序的基本思想 ① 先将初始文件R[1..n]建成一个大根堆,此堆为初始的无序区 ② 再将关键字最大的记录R[1](即堆顶)和无序区的最后一个记录R[n]交换,由此得到新的无序区R[1..n-1]和有序区R[n],且满足R[1..n-1].keys≤R[n].key ③ 由于交换后新的根R[1]可能违反堆性质,故应将当前无序区R[1..n-1]调整为堆。
然后再次将R[1..n-1]中关键字最大的记录R[1]和该区间的最后一个记录R[n-1]交换,由此得到新的无序区R[1..n-2]和有序区R[n-1..n],且仍满足关系R[1..n-2].keys≤R[n-1..n].keys,同样要将R[1..n-2]调整为堆。
…… 直到无序区只有一个元素为止。
(2)大根堆排序算法的基本操作: ① 初始化操作:将R[1..n]构造为初始堆; ② 每一趟排序的基本操作:将当前无序区的堆顶记录R[1]和该区间的最后一个记录交换,然后将新的无序区调整为堆(亦称重建堆)。
注意: ①只需做n-1趟排序,选出较大的n-1个关键字即可以使得文件递增有序。
②用小根堆排序与利用大根堆类似,只不过其排序结果是递减有序的。
堆排序和直接选择排序相反:在任何时刻,堆排序中无序区总是在有序区之前,且有序区是在原向量的尾部由后往前逐步扩大至整个向量为止。
(3)堆排序的算法: void HeapSort(SeqIAst R) { //对R[1..n]进行堆排序,不妨用R[0]做暂存单元 int i; BuildHeap(R); //将R[1-n]建成初始堆 for(i=n;i>1;i--){ //对当前无序区R[1..i]进行堆排序,共做n-1趟。
R[0]=R[1];R[1]=R[i];R[i]=R[0]; //将堆顶和堆中最后一个记录交换 Heapify(R,1,i-1); //将R[1..i-1]重新调整为堆,仅有R[1]可能违反堆性质 } //endfor } //HeapSort (4) BuildHeap和Heapify函数的实现 因为构造初始堆必须使用到调整堆的操作,先讨论Heapify的实现。
① Heapify函数思想方法 每趟排序开始前R[l..i]是以R[1]为根的堆,在R[1]与R[i]交换后,新的无序区R[1..i-1]中只有R[1]的值发生了变化,故除R[1]可能违反堆性质外,其余任何结点为根的子树均是堆。
因此,当被调整区间是R[low..high]时,只须调整以R[low]为根的树即可。
"筛选法"调整堆 R[low]的左、右子树(若存在)均已是堆,这两棵子树的根R[2low]和R[2low+1]分别是各自子树中关键字最大的结点。
若R[low].key不小于这两个孩子结点的关键字,则R[low]未违反堆性质,以R[low]为根的树已是堆,无须调整;否则必须将R[low]和它的两个孩子结点中关键字较大者进行交换,即R[low]与R[large](R[large].key=max(R[2low].key,R[2low+1].key))交换。
交换后又可能使结点R[large]违反堆性质,同样由于该结点的两棵子树(若存在)仍然是堆,故可重复上述的调整过程,对以R[large]为根的树进行调整。
此过程直至当前被调整的结点已满足堆性质,或者该结点已是叶子为止。
上述过程就象过筛子一样,把较小的关键字逐层筛下去,而将较大的关键字逐层选上来。
因此,有人将此方法称为"筛选法"。
算法实例: #include<stdio.h> #include<stdlib.h> inline int LEFT(int i); inline int RIGHT(int i); inline int PATENT(int i); void MAX_HEAPIFY(int A[],int heap_size,int i); void BUILD_MAX_HEAP(int A[],int heap_size); void HEAPSORT(int A[],int heap_size); void output(int A[],int size); int main() { FILE *fin; int m,size,i; fin = fopen("array.in","r"); int* a; fscanf(fin," %d",&size); a = (int *)malloc(size + 1); a[0]=size; for(i = 1;i <= size; i++ ) { fscanf(fin," %d",&m); a[i] = m; } HEAPSORT(a,a[0]); printf("$$$$$$$$$ Result$$$$$$$$ "); output(a,a[0]); free(a); return 0; } inline int LEFT(int i) { return 2 * i; } inline int RIGHT(int i) { return 2 * i + 1; } inline int PARENT(int i) { return i / 2; } void MAX_HEAPIFY(int A[],int heap_size,int i) { int temp,largest,l,r; largest = i; l = LEFT(i); r = RIGHT(i); if ((l <= heap_size) && (A[l] > A[i])) largest = l; if ((r <= heap_size) && (A[r] > A[largest])) largest = r; if (largest != i) { temp = A[largest]; A[largest] = A[i]; A[i] = temp; MAX_HEAPIFY(A,heap_size,largest); } } void BUILD_MAX_HEAP(int A[],int heap_size) { int i; for (i = heap_size / 2;i >= 1;i--) MAX_HEAPIFY(A,heap_size,i); } void HEAPSORT(int A[],int heap_size) { int i; BUILD_MAX_HEAP(A,heap_size); for (i = heap_size;i >= 2; i--) { int temp; temp = A[1]; A[1] = A[i]; A[i] = temp; MAX_HEAPIFY(A,i-1,1); } } void output(int A[],int size) { int i = 1; FILE *out = fopen("result.in","w+"); for (; i <= size; i++){ printf("%d ",A[i]); fprintf(out,"%d ",A[i]); } printf(" "); } ②BuildHeap的实现 要将初始文件R[l..n]调整为一个大根堆,就必须将它所对应的完全二叉树中以每一结点为根的子树都调整为堆。
显然只有一个结点的树是堆,而在完全二叉树中,所有序号 的结点都是叶子,因此以这些结点为根的子树均已是堆。
这样,我们只需依次将以序号为 , -1,…,1的结点作为根的子树都调整为堆即可。
具体算法【参见教材】。
5、大根堆排序实例 对于关键字序列(42,13,24,91,23,16,05,88),在建堆过程中完全二叉树及其存储结构的变化情况参见【动画演示】。
6、 算法分析 堆排序的时间,主要由建立初始堆和反复重建堆这两部分的时间开销构成,它们均是通过调用Heapify实现的。
堆排序的最坏时间复杂度为O(nlgn)。
堆排序的平均性能较接近于最坏性能。
由于建初始堆所需的比较次数较多,所以堆排序不适宜于记录数较少的文件。
堆排序是就地排序,辅助空间为O(1), 它是不稳定的排序方法。
参考资料:/wiki?title=%E5%A0%86%E6%8E%92%E5%BA%8F&;diff=prev&oldid=374531
求严蔚敏教材上弗洛伊德算法的时间复杂度,在网上查了下,说法不一,有O(n3),有O(n4),大家怎么看?
分n 个阶段,用邻接矩阵求关联和权值时间O(1),每个阶段需要对n^2个元素对比较 因此时间复杂度为O(n^3) 至于求路径,参加其原文,又多了一个循环,效率不高,最好是用路径矩阵,这样求路径的时间复杂度也是O(n^3)弗洛伊德算法和地杰斯特拉算法的区别
弗洛伊德是 求多个点对的最短路。运行一次可以算出图中任意两点的最短路 复杂度 o(n^3) 地杰斯特拉算法 是求单源点的最短路一次运算可以算出,从这个点出发到任意点的最短路。
复杂度可以优化到O(|E|log|v|)
- 弗洛伊德算法弗洛伊德算法和地杰斯特拉算法的区别相关文档
- 弗洛伊德算法弗洛伊德精神分析法,,谁给讲解一下啊
Hosteons:新上1Gbps带宽KVM主机$21/年起,AMD Ryzen CPU+NVMe高性能主机$24/年起_韩国便宜服务器
我们在去年12月分享过Hosteons新上AMD Ryzen9 3900X CPU及DDR4内存、NVMe硬盘的高性能VPS产品的消息,目前商家再次发布了产品更新信息,暂停新开100M带宽KVM套餐,新订单转而升级为新的Budget KVM VPS(SSD)系列,带宽为1Gbps端口,且配置大幅升级,目前100M带宽仅保留OpenVZ架构产品可新订购,所有原有主机不变,用户一直续费一直可用。Bud...

vdsina:俄罗斯VPS(datapro),6卢布/天,1G内存/1核(AMD EPYC 7742)/5gNVMe/10T流量
今天获得消息,vdsina上了AMD EPYC系列的VDS,性价比比较高,站长弄了一个,盲猜CPU是AMD EPYC 7B12(经过咨询,详细CPU型号是“EPYC 7742”)。vdsina,俄罗斯公司,2014年开始运作至今,在售卖多类型VPS和独立服务器,可供选择的有俄罗斯莫斯科datapro和荷兰Serverius数据中心。付款比较麻烦:信用卡、webmoney、比特币,不支持PayPal...

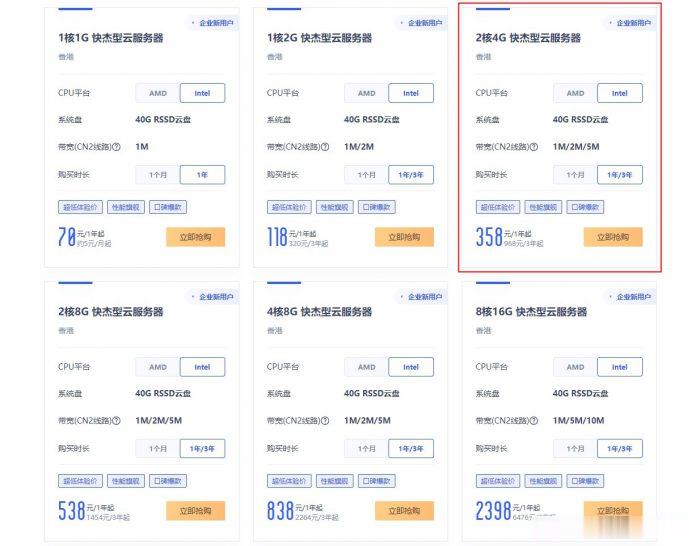
ucloud香港服务器优惠活动:香港2核4G云服务器低至358元/年,968元/3年
ucloud香港服务器优惠降价活动开始了!此前,ucloud官方全球云大促活动的香港云服务器一度上涨至2核4G配置752元/年,2031元/3年。让很多想购买ucloud香港云服务器的新用户望而却步!不过,目前,ucloud官方下调了香港服务器价格,此前2核4G香港云服务器752元/年,现在降至358元/年,968元/3年,价格降了快一半了!UCloud活动路子和阿里云、腾讯云不同,活动一步到位,...
弗洛伊德算法为你推荐
-
文件解压器下载压缩解压软件下载mobilepartnermobile partner拔不上号,信号60%,连不上网络,老是提示连接被中止stm32视频教程谁能发个STM32单片机的视频教程在线年龄查询器怎样喂熊熊?java学习思维导图如何成为一个很厉害的人思维导图智能机刷机软件请问有什么刷机软件,是刷安卓系统手机的软件,自己用过刷过机!多重阴影[讨论]《多重阴影》的中文配音好熟悉啊!微软将停止支持32位Win10系统电脑win10系统自带的office2016为什么是32位?bt4破解教程请问这个无线网络要如何破解?是用BT3还是BT4,求教!!!物联卡官网物联卡是正规流量卡吗?