Engineer-to-Engineer指南
EE-263AnalogDevices公司DSP、处理器和开发工具的使用技术指南联系我们的技术支持中心:dsp.
support@analog.
com和dsptools.
support@analog.
com查看我们的在线资源:http://www.
analog.
com/ee-notes和http://www.
analog.
com/processorsCopyright2003,AnalogDevices公司.
版权全部所有.
AnalogDevices公司不为用户的产品设计或用户产品的使用或应用以及由ADI协助所可能产生的对任何专利权或其他人权利的侵犯而承担任何责任.
所有商标和标识所有权均属于其各自持有者.
AnalogDevices公司应用和开发工具工程师所提供的资料均视为准确、可靠.
但AnalogDevices公司不为本公司的Engineer-to-Engineer指南所提供内容的技术准确性承担任何责任.
TigerSHARC处理器上定点FFT的并行实现BorisLernerr提供第一版-2005年2月3日引言现代的高度并行式处理器的进展如AnalogDevices的TigerSHARC系列处理器,要求寻找更为有效的方法来并行实现许多标准算法的操作.
该应用手记不仅解释最快的16位FFT如何在TigerSHARC上的实现,而且提供指导算法的开发,使你能够将同一技术施于其他算法.
一般来说,大多数算法有几个层次的优化级,该手记将给予详细讨论.
第一和最直截了当的优化级是指令的并行,这是处理器架构所允许的.
这种工作是简单而又烦人的.
优化的第二级是循环体展开(loopunrolling)和软件的流水线操作,以取得最大并行性,避免流水线停止工作.
虽然比简单的一级并行复杂,但可按描述的步骤进行工作,无需深入了解算法,几乎没有独创性.
第三级是重建算法的数学操作,仍产生有效的结果,但更适合处理器的架构.
这需要彻底了解算法,不像软件的流水线操作那样,它没有既定的引导你走向最佳方案的步骤.
这在写最佳代码中是最有趣的.
在实际应用中,常常不需要用到所有的优化层次.
当所有的优化级需要时,最好以反向的顺序进行这些级的优化.
在代码完全被流水化操作以后,再来尝试改变基本的底层算法已经太迟了.
由此,程序师必须要先考虑算法结构,随后组织代码.
然后通常将优化层次1和2(并行、展开以及流水线操作)同时进行.
本手记中所参考使用的代码由模拟器件公司提供.
具体例子使用一个256-点FFT,但其中的数学算法和理念同样适于其它大小(不小于16点)的变换.
如同所见,重建的算法将FFT打散成更小的部分而后可被并行.
在256点FFT(其代码列表在该应用手记的尾部)的情形下,FFT被分成一个个16点的FFT有16个,16点FFT以基数4(radix-4)的格式来完成(即每个只有两个阶).
如果我们做一个512=点FFT,我们将不得不一次做16个32点的FFT(或者一次做32个16点的FFT),每个32点FFT以基数4格式先完成前两个阶,最后一阶做成基数2格式.
这种不同意味着书写FFT大小统配(FFTsize-generic)的代码是困难的.
虽然实现的算法是通用的,可同等地适于所有大小的FFT,但代码却不能这样,它必须针对每一种点大小FFT进行手工调整,以便能够完全达到最优化.
带上这些一并考虑,让我们进入TigerSHARC园地里迷人的定点FFT世界吧.
标准的基数2FFT算法图1给出了一种输入经过位反转(bitreversed)后的标准16点基数-2FFT实现方案.
传统来看,在这一算法中,阶1和2与所要求的位反转结合成一个单一的优化循环.
(由于两个阶不需要乘法运算,只进行加和减操作).
每个余留的阶通常将共享相同旋移因数的蝶形运算结合在一起组成群组(对于每一群组,旋移因子仅需读取一次).
图116点FFT的标准结构由于TigerSHARC处理器对打包数据提供矢量化的16位处理,因此我们需要把该算法并行到至少和TigerSHARC能处理的同等多的并行过程中.
TigerSHARC的一个加/减指令(有助于进行一个基本蝶形的计算)可以以每周期8个16-bit值进行并行操作(TigerSHARC处理器的每个computeblock有4个).
由于数据为复数,这就相当于每周期有4个数据加/减操作.
因此,我们需要把FFT打分成至少4个并行过程.
见图1中的图表,显然,我们可以通过简单地把数据组合成块来进行,例如一次4点:1stblock={x(0),x(8),x(4),x(12)}2ndblock={x(2),x(10),x(6),x(14)}3rdblock={x(1),x(9),x(5),x(13)}4thblock={x(3),x(11),x(7),x(15)}这些群组没有相互依赖性,针对FFT的头两个阶会并行得很好.
之后我们将遇到麻烦,并行性失去.
但是此时,我们可以将数据重组成不同的块以确保以后的工作中新块相互不干扰,从而做到可并行处理.
仔细观察显示,所需要的重组是一种以新块为基础的交插(或解交插)操作,新块由如下给出:1stblock={x(0),x(2),x(1),x(3)}2ndblock={x(8),x(10),x(9),x(11)}3rdblock={x(4),x(6),x(5),x(7)}4thblock={x(12),x(14),x(13),x(15)}TigerSHARC处理器上定点FFT的并行实现(EE263)2对待这些新块的另一种方法是4x4矩阵变换(块定义矩阵的行).
当然,有严重的副作用——当数据重组后,最后的阶将并行,但会不以正确的顺序产生数据.
或许,我们以有别于我们以位反转为开始的一种顺序开始,可以对此有所补偿,但还是让我们把这里面的细节留给后面严密的数学分析吧.
这时,对16点FFT的分析似乎建议我们,通常在给定一个N点FFT的情况下,我们需要把它看成一个二维的数据矩阵,进行行或列的并行处理,然后变换矩阵,再次并行处理行或列.
由此引出的另一个要求是N必须是一个完全平方数.
如所证,我们可以对这一要求进行处理,这将在后面讨论.
此刻我们所关心的是256点FFT,256=162.
于是,我们将并行哪一个是行还是列答案在TigerSHARC处理器的向量架构中.
当TigerSHARC处理器从存储器中获取数据时,它一次获取128位(即4个16位的复数数据点)的大块数据,并把它打包到四个或两个(对于SIMD取数来说)寄存器中.
而后它沿四个或两个寄存器进行矢量化处理.
这样,我们想要并行的是矩阵的列(即,我们需要构建我们的数学计算,以使矩阵的所有列相互无关联性).
现在我们知道了我们想要数学计算带给我们什么,这时也是严格按数学语言做工作时候了.
算法的数学原理下列符号将使用:N=原FFT的点数(例中为256点),将代表离散傅立叶变换(DiscreteFourierTransform,简称为DFT).
现在,已知信号x,这里是这种M点DFT的函数,我们把输出指数n看作安排在MxM矩阵中(即).
,由此,由于是一个M点DFT,它具有周期=M的周期性.
因此,这里是这个M点DFT的函数.
算法的实现TigerSHARC处理器上定点FFT的并行实现(EE263)3方程式(1),(2)和(3)示出怎样用下列步骤计算x的DFT(这时我们回到我们的具体例子N=256,M=16中):1.
线性安排输入数据x(n)的256点,但把它看作一个16x16矩阵:2.
用公式(1),再写为:3.
我们现在按列计算并行FFT(如前所述,TigerSHARC处理器做此很有效)获得:4.
我们对此作逐点(point-wise)矩阵乘得到这按照公式(3),它正好是5.
现在我们来计算的16点FFT,但它们在排列上并行为行而非列.
我们必须变换以得到6.
我们按列计算并行FFT,使用公式(2)得到这是我们想要的FFT结果,它的次序正确!
现在数学计算已完成,我们准备开始考虑编程实现.
在下列讨论中,我们将参照上面所概括的步骤1到6描述的六步.
编程实现我们将从头到尾检查前面部分的步骤,一次一步.
步骤1和2不需要进行编程.
输入数据已经以适当的顺序安排好.
TigerSHARC处理器上定点FFT的并行实现(EE263)4步骤3需要我们按输入矩阵的列计算16个并行的16点FFT.
如前所述,由于其向量处理功能,TigerSHARC可一次轻易并行4个FFT,这样我们可一次做4个FFT,并重复这一过程4次,便可计算全部16个FFT.
16点FFT以基数4的方式完成可做得非常有效,结果有2阶,每阶有4个蝶形运算.
为了使内部开销最小化,4组4个FFT中,每组都先仅计算第一阶更有效.
然后计算4组4个FFT中的每个第二阶(不是顺序计算每组的两阶).
步骤4是一个逐点式复数乘法(共256次相乘)运算,步骤5是一个矩阵变换.
这两步可以结合----在进行数据点的乘法运算时,我们可以以转置矩阵的方式存放它们.
步骤6与步骤3一样---我们必须按我们的新输入矩阵的列计算16个并行16点FFT.
这部分不需要书写.
我们可以简单地分支到步骤3的代码,记住,一旦FFT完成(而不是像以往继续进入步骤4),记住退出例行程序.
图2代表包含数据的缓冲器,并且箭头对应于数据在缓冲器之间的变换.
图2代码的结构图算法的流水线操作—第一阶段让我们先集中于步骤3.
记忆存储器操作F1取4个蝶形的4个复数Input1=4个32-bit值F2取4个蝶形的4个复数Input2=4个32-bit值F3取4个蝶形的4个复数Input3=4个32-bit值F4取4个蝶形的4个复数Input=4个32-bit值AS1F1+/-F2AS2F3+/-F4MPY1(F1-F2)*(-i)的前半部分注意我们每个周期只能做2个复数mpysM1将MPY1移入计算模块寄存器MPY2(F1-F2)*(-i)的第二部分注意我们每个周期只能做2个复数mpysM2将MPY2移入计算模块寄存器AS3(F3+F4)+/-(F1+F2)=4个蝶形的Output1和Output3AS4(F3–F4)+/-(F1-F2)*(-i)=4个蝶形的Output2和Output4S1存储4个蝶形(Output1)=4个32-bit值S2存储4个蝶形(Output2)=4个32-bit值S3存储4个蝶形(Output3)=4个32-bit值S4存储4个蝶形(Output4)=4个32-bit值TigerSHARC处理器上定点FFT的并行实现(EE263)5表1线性完成阶段1的单一蝶形——逻辑实现表1列出了以TigerSHARC处理器的向量形式进行阶段1四个并行的基数-4复数蝶形运算所必要的操作.
实际上,这个部分对各阶段来说是相同的,但除非其它阶段在蝶形开始时也要求一个复数的旋移相乘.
这使得其它阶段更为复杂,它们将在下一节内容涉及.
表2流水线操作的蝶形——阶段1表2示出流水线操作的蝶形.
操作中的一个"+"符号表示对应于下一组蝶形的操作,一个"-"号对应于上一组蝶形中的操作.
所有指令都是并行的,并且没有阻塞(stall).
算法的流水线操作-阶段2做一个阶段2的蝶形运算,必须进行和阶段1相同的计算,除非开始时16(4个并行的x4点)个输入中的每一个都存在一个附加的复数相乘操作.
这会产生一个问题.
原有的蝶形中已有二个SIMD复数相乘运算.
当ALU、取数和存储保留在4时,又增加8个便构成10个复数相乘.
这会使算法失衡,太多的乘法和太少的其他计算单元将不会很好地并行.
这样做的最好的办法是每蝶形向量10个周期.
结果,两个原有乘运算(是乘以-i)中的每一个便可由一个短的ALU(逻辑"非")和一个长循环替代.
另外,需要二个寄存器移位,以保证数据返回到长寄存器中被打包,以进行随后的并行加/减运算.
对向量式蝶形运算来说,这会留下共计8个乘法、6个ALU(4个加/减和2个逻辑"非")以及2个移位(循环移)——对于一个8周期的操作执行是完美的平衡.
还有,4取数和4存储为寄存器移位留下了大量的空间.
表3列出了在TigerSHARC处理器进行第二阶段向量式(即四个并行)基数-4复数蝶形运算所需要的操作.
事情变得大大地复杂化了!
表4示出流水线操作的蝶形.
一个"+"符号表示对应于下一组蝶形的操作,一个"-"号对应于上一组蝶形的操作.
TigerSHARC处理器上定点FFT的并行实现(EE263)6记忆存储器操作F1取4个蝶形中的4个复数Input1=4个32-bit值F2取4个蝶形中的4个复数Input2=4个32-bit值F3取4个蝶形中的4个复数Input3=4个32-bit值F4取4个蝶形中的4个复数Input4=4个32-bit值MPY1F1*旋移的第一个一半M1移动MPY1到计算模块寄存器MPY2F1*旋移的第二个一半M2移动MPY2到计算模块寄存器MPY3F2*旋移的第一个一半M3移动MPY3到计算模块寄存器MPY4F2*旋移的第二个一半M4移动MPY4到计算模块寄存器MPY5F3*旋移的第一个一半M5移动MPY5到计算模块寄存器MPY6F3*旋移的第二个一半M6移动MPY6到计算模块寄存器MPY7F4*旋移的第一个一半M7移动MPY7到计算模块寄存器MPY8F4*旋移的第二个一半M8移动MPY8到计算模块寄存器AS1M1,M2+/-M3,M4AS2M5,M6+/-M7,M8A1逻辑非(M1-M3)MV1移动(M1-M3)到一对含有A1的寄存器中R1旋动A1的长结果,MV1-现在低寄存器含有(M1-M3)*(-i)A2逻辑非(M2-M4)MV2移动(M2-M4)到一对含A2的寄存器中R2旋动A1的长结果,MV2–现在低寄存器含有(M2-M4)*(-i)AS3(F3+F4)+/-(F1+F2)AS4(F3–F4)+/-(F1-F2)*(-i)这里(F1-F2)*(-i)由R1和R2获得S1Store1存储4个蝶形=4个32-bit值S2Store2存储4个蝶形=4个32-bit值S3Store3存储4个蝶形=4个32-bit值S4Store4存储4个蝶形=4个32-bit值表3线性完成阶段2的单一蝶形——逻辑实现所有指令都是并行的,并且没有阻塞.
仍有一个旋移取数问题存在,未得到解决,但还有许多JALU和KALU指令时段(slot)可利用,依进度安排旋移取数不会造成任何问题(它们实际上具有相同的单位向量值,因此广播读取将带给它们高效率).
TigerSHARC处理器上定点FFT的并行实现(EE263)7ping_pong_bufferx是乒乓缓冲(pingpong)器.
所有缓冲器是以正常(没有位反转的)的顺序进行复数值打包.
ping_pong_buffer1和ping_pong_buffer2必须是二个不同的缓冲器.
但是,根据用户要求,进行一些内存优化是可能的.
ping_pong_buffer1在input不需要保留时可以同input一样施为.
同理,output可以和ping_pong_buffer2一样施为.
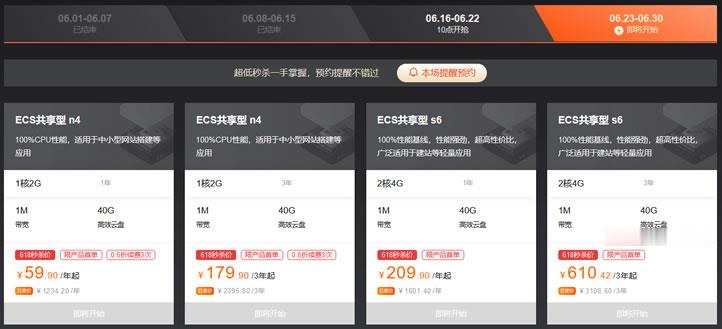
阿里云年中活动最后一周 - ECS共享型N4 2G1M年付59元
以前我们在参与到云服务商促销活动的时候周期基本是一周时间,而如今我们会看到无论是云服务商还是电商活动基本上周期都要有超过一个月,所以我们有一些网友习惯在活动结束之前看看商家是不是有最后的促销活动吸引力的,比如有看到阿里云年中活动最后一周,如果我们有需要云服务器的可以看看。在前面的文章中(阿里云新人福利选择共享性N4云服务器年79.86元且送2月数据库),(LAOZUO.ORG)有提到阿里云今年的云...
萤光云(13.25元)香港CN2 新购首月6.5折
萤光云怎么样?萤光云是一家国人云厂商,总部位于福建福州。其成立于2002年,主打高防云服务器产品,主要提供福州、北京、上海BGP和香港CN2节点。萤光云的高防云服务器自带50G防御,适合高防建站、游戏高防等业务。目前萤光云推出北京云服务器优惠活动,机房为北京BGP机房,购买北京云服务器可享受6.5折优惠+51元代金券(折扣和代金券可叠加使用)。活动期间还支持申请免费试用,需提交工单开通免费试用体验...
cera:秋季美国便宜VPS促销,低至24/月起,多款VPS配置,自带免费Windows
介绍:819云怎么样?819云创办于2019,由一家从2017年开始从业的idc行业商家创办,主要从事云服务器,和物理机器819云—-带来了9月最新的秋季便宜vps促销活动,一共4款便宜vps,从2~32G内存,支持Windows系统,…高速建站的美国vps位于洛杉矶cera机房,服务器接入1Gbps带宽,采用魔方管理系统,适合新手玩耍!官方网站:https://www.8...

-
域名注册域名注册大概要多长时间服务器租用服务器租用是什么?服务器托管是什么?两者有什么优点和缺点?海外主机租用为什么很多人选择国外服务器租用.net虚拟主机想买个同时支持php和.net的虚拟主机,哪里可以买到这样的空间?是同时支持的那种。linux虚拟主机如何配置linux虚拟主机vps国内VPS哪个好国外空间租用好用的国外空间虚拟主机控制面板虚拟主机控制面板是什么?虚拟主机系统虚拟主机上的系统与电脑操作系统差别?虚拟主机系统虚拟主机采用什么操作系统?