缓存内存数据库
ISSN1000-9825,CODENRUXUEWE-mail:jos@iscas.
ac.
cnJournalofSoftware,Vol.
19,No.
10,October2008,pp.
25732584http://www.
jos.
org.
cnDOI:10.
3724/SP.
J.
1001.
2008.
02573Tel/Fax:+86-10-625625632008byJournalofSoftware.
Allrightsreserved.
内存数据库在TPC-H负载下的处理器性能刘大为1,2+,栾华1,王珊1,覃飙11(数据工程与知识工程教育部重点实验室(中国人民大学),北京100872)2(中国石油信息技术服务中心,北京100724)MainMemoryDatabaseTPC-HWorkloadCharacterizationonModernProcessorLIUDa-Wei1,2+,LUANHua1,WANGShan1,QINBiao11(KeyLaboratoryofDataEngineeringandKnowledgeEngineering(RenminUniversityofChina),MinistryofEducation,Beijing100872,China)2(ChinaPetroleumInformationTechnologyServiceCenter,Beijing100724,China)+Correspondingauthor:E-mail:liudawei@ruc.
edu.
cnLiuDW,LuanH,WangS,QinB.
MainmemorydatabaseTPC-Hworkloadcharacterizationonmodernprocessor.
JournalofSoftware,2008,19(10):25732584.
http://www.
jos.
org.
cn/1000-9825/19/2573.
htmAbstract:In1999,theresearchofdatabasesystems'executiontimebreakdownonmoderncomputerplatformshasbeenanalyzedbyAilamaki,etal.
TheprimarymotivationofthesestudiesistoimprovetheperformanceofDiskResidentDatabases(DRDBs),whichformthemainstreamofdatabasesystemsuntilnow.
ThetypicalbenchmarkusedinthosestudiesisTPC-C.
However,continuinghardwareadvancementshave"moved-up"onthememoryhierarchy,suchasthelargerandlargeron-chipandoff-chipcaches,thesteadilyincreasingRAMspace,andthecommercialavailabilityofhugeflashmemory(solid-statedisk)ontopofregulardisk,etc.
Toreflectsuchatrend,thetargetofworkloadcharacterizationresearchalongthememoryhierarchyisalsostudied.
ThispaperfocusesonMainMemoryDatabases(MMDBs),andtheTPC-Hbenchmark.
UnliketheperformanceofDRDBwhichisI/Oboundandmaybeoptimizedbyhigh-levelmechanismssuchasindexing,theperformanceofMMDBisbasicallyCPUandmemorybound.
Inthisstudy,thepaperfirstcomparestheexecutiontimebreakdownofDRDBandMMDB,andthepaperproposesanoptimizestrategytooptimizethememoryresidentaggregate.
Then,thepaperexploresthedifferencebetweencolumn-orientedandrow-orientedstoragemodelsinCPUandcacheutilization.
Furthermore,thepapermeasuresperformanceofMMDBsondifferentgenerationalCPUs.
Inaddition,thepaperanalyzestheindexinfluenceandgivesastrategyformainmemorydatabaseindexoptimization.
Finally,thepaperanalyzeseachqueryinthefullTPC-Hbenchmarkindetail,andobtainssystematicresults,whichhelpdesignmicro-benchmarksforfurtheranalysisofCPUcachestall.
ResultsofthisstudyareexpectedtobenefittheperformanceoptimizationofMMDBs,andthearchitecturedesignmemory-orienteddatabasesofthenextgeneration.
Keywords:MMDB(mainmemorydatabase);TPC-Hworkload;processorcharacterization摘要:Ailamaki等人1999年研究了数据库管理系统(databasemanagementsystem,简称DBMS)在处理器上的时SupportedbytheNationalNaturalScienceFoundationofChinaunderGrantNos.
60496325,60473069,60503038(国家自然科学基金);theGrantfromHPLabs.
China(国际合作(HPLab.
)项目)Received2007-07-20;Accepted2008-01-292574JournalofSoftware软件学报Vol.
19,No.
10,October2008间开销分解.
此后,相关研究集中在分析DBMS在处理器上的瓶颈.
但这些研究工作均是在磁盘数据库DRDBs(diskresidentdatabases)上开展的,而且都是分析DBMS上的TPC-C类负载.
然而,随着硬件技术的进步,现代计算机的多级缓存结构(memoryhierarchy)在逐渐地"上移".
例如,容量越来越大的芯片内缓存(on-chipcaches)和芯片外缓存(off-chipcaches),容量越来越大的RAM,FlashMemory等等.
为此,处理器负载分析的研究工作也应随之"上移".
研究内存数据MMDBs(mainmemoryresidentdatabases)在计算密集型负载下的处理器行为特性.
由于磁盘数据库的主要性能瓶颈是磁盘I/O,因而可以用索引、压缩等技术进行优化;然而,内存数据库的性能瓶颈却在于处理器和内存之间的数据交换.
针对这一问题,首先分析了磁盘数据库和内存数据库在TPC-H负载下处理器性能瓶颈的差异,并给出了一些优化建议,提出了通过预取的优化方法.
其次,通过实验比较了不同存储体系结构(行存储与列存储)对处理器利用率的差异,并探索了下一代内存数据库体系结构方面的解决方案.
此外,还研究了索引结构对处理器多级缓存的影响,并给出了索引的优化建议.
最后,提出一个微测试集用于评估内存数据库在DSS(decisionsupportsystem)负载下处理器的性能及行为特性.
研究结果会对运行于下一代处理器上的内存数据库体系结构设计和性能优化提供一定的实验依据.
关键词:内存数据库;TPC-H负载;处理器特性中图法分类号:TP311文献标识码:A数据库管理系统(databasemanagementsystem,简称DBMS)在现代处理器上通常表现出较低的IPC(instrucions-per-cycle),尤其是在DSS这种计算密集型的负载下,如OLAP(onlineanalyticalprocessing)、多媒体检索、数据挖掘等应用[1].
这表明,在这类应用下,DBMS对处理器的利用率较低.
目前,从事计算机体系结构和数据库研究的人员对此问题都给予了重视.
从已发表的文献来看,多数研究集中在DBMS在各种负载下对处理器利用情况的分析,如文献[17].
其中,文献[2]的研究结果得到了广泛的认可,Ailamaki等人在1999年分析了几个商用数据库管理系统在处理器上的时间开销,并从处理器的角度将查询执行时间分解为:处理器的有效计算时间、处理器各级缓存产生的延迟(stall)时间、分支指令预测失误而产生的延迟时间以及因资源不可用而产生的延迟时间等几部分.
其研究结果表明,处理器在DBMS的应用负载下,大部分时间(近50%)处于停滞(stall)状态.
其中,处理器的第1级指令缓存缺失(L1instructioncachemiss)和第2级数据缓存缺失(L2datacachemiss)是引起停滞的最主要的原因.
其他文献,如文献[37]也进行了相关的研究工作.
但这些研究均是针对当时的主流数据库,即磁盘数据库DRDB(diskresidentdatabases)开展的,其目标是研究DRDB在处理器上的性能瓶颈并探索相关的优化策略.
在研究方法上,主要是通过统计处理器各级缓存上发生的缺失次数,从而得以精确地分析DRDB在多级缓存上的性能瓶颈;实验平台则是基于当时的处理器,例如IntelPentium,PentiumPro等.
然而,随着处理器技术的不断进步,如现代处理器的乱序执行(out-of-orderexecution)、多线程(multi-threading)、多级缓存(multi-levelmemoryhierarchies)、多核(multiplecores)等等,处理器的计算能力也在不断增强.
那么,DBMS上的计算密集型应用,如数据挖掘、多媒体信息检索、OLAP等能否从处理器的进步中获益呢这类负载在处理器上的性能瓶颈又是什么DBMS应该如何从体系结构及核心算法方面进行再设计以便充分利用现代处理器的高计算能力这些都是值得研究的问题.
基于以上研究动机,本文研究了内存数据库MMDB(mainmemoryresidentdatabases)在TPC-H类负载下,现代处理器的特性,如在安腾2(Itanium2)上的行为特性以及性能瓶颈.
之所以针对内存数据库和TPC-H负载进行研究,是基于如下考虑:随着内存价格的下降以及容量的不断增大,将所有的数据放入内存进行处理将成为现实;而且,64位处理器逐渐成为主流,这极大程度地增加了计算机内存的可用容量,32位处理器最多可用4GB的内存容量,而64位处理器的最高内存容量理论上为17179869184GB.
此外,多处理器的出现使得并行计算成本也越来越低.
因此,内存容量可以容纳当前绝大多数OLAP应用的基础数据,在不久的将来,基于内存数据库的OLAP将逐渐走向实际.
由于数据可以直接在内存中访问,因而系统可以具有更好的响应时间和吞吐量.
与磁盘数据库的I/O瓶颈不同,内存数据库的瓶颈在于处理器和内存之间的数据交换代价.
因此,需要重新分析这类负载在处理器上的行为特性.
刘大为等:内存数据库在TPC-H负载下的处理器性能2575总之,现代计算机的多级缓存体系结构已经"上移",表现为容量越来越大的芯片内缓存(on-chipcaches)和芯片外缓存(off-chipcaches)、容量越来越大的RAM(randomaccessmemory)等,因此,负载分析的研究工作也应随之"上移".
为此,我们通过一系列实验研究分析了TPC-H负载下现代处理器的行为特性.
在处理器方面,我们选择了安腾2和至强两个典型的现代处理器.
就目前已发表的文献来看,对于内存数据库在处理器上的性能瓶颈研究尚未有相关的研究工作.
本文的主要贡献简要总结如下:首先,分析了磁盘数据库和内存数据库在TPC-H负载下的处理器性能瓶颈差异,并针对内存数据库的处理器瓶颈提出了一种基于预取的优化策略.
其次,通过实验比较了不同存储体系结构(行存储与列存储)对处理器利用率的差异.
此外,研究了索引结构对处理器多级缓存的影响.
最后,通过实验,我们提出一个微测试集用于评价内存数据库在DSS负载下处理器的性能及行为特性.
本文的研究结果希望能够对下一代处理器上的内存数据库体系结构设计以及性能优化提供一定的实验依据.
本文第1节介绍当前国际上的相关研究和进展情况.
第2节介绍数据库查询在处理器上的执行过程以及TPC-H负载.
第3节给出实验环境.
第4节详细分析实验结果以及我们提出的优化策略.
第5节对全文总结并讨论未来的工作方向.
1相关工作Shreekant等人在文献[3]中首次研究了DBMS的性能与硬件的关系,该文献研究了DBMS在OLTP(onlinetransactionprocessing)负载下如何将多个进程分配至不同的处理器上进而提高数据库系统的性能的方法.
此外,Maynard等人在文献[4]中分析了关系数据库在TPC-A和TPC-C负载下对处理器的影响,其研究结果表明,增大处理器第1级缓存(level1cache)的容量可以提高处理TPC-C类的负载能力,而科学计算类的负载(TPC-A)并不能直接获得收益.
Rosenblum等人在文献[5]中的研究结果表明,虽然磁盘I/O是数据库的主要瓶颈,但处理器在处理OLTP类负载时近50%的时间是处于停滞状态的,产生停滞的原因主要是由于处理器的缓存缺失(cachemiss)造成的.
在分析数据库负载对处理器利用情况的研究中,文献[2]分析了4种商用数据库并指出DBMS在OLTP和OLAP两类负载下,造成处理器"停滞"的主要原因是由于处理器的第1级的指令缓存的缺失(L1instructioncachemiss)和第2级的数据缓存的缺失(L2datacachemiss)而引起的.
其他文献[57]则在多处理器平台分析了DBMS的系统瓶颈.
其中,有些研究只针对OLAP类负载的特性分析,如文献[7];而有些文献[8,9]则对OLTP和OLAP两类负载都进行了研究.
以上的研究表明,在数据库的两种负载中,OLAP类负载相对于OLTP类负载对处理器利用率更好.
此外,得出的另一结论是,由各级缓存引起的处理器"停滞"是造成处理器利用率低下的主要原因.
就目前已发表的文献来看,尚未有针对内存数据库在现代处理器上的行为进行分析的文献.
2查询处理的时间分解模型与TPC-H负载2.
1查询执行在处理器上的时间分解现代处理器的指令采用流水线方式执行.
一条指令在处理器上通常划分为几个不同阶段来执行.
每个阶段执行的操作之间会产生重叠,但当一个阶段的操作不能立即结束时,就将在流水线中产生延迟(stall).
现代处理器为了克服这种延迟,通常采用以下几种技术:非阻塞缓冲(non-blockingcaches)、乱序执行(out-of-orderexecution)、预测执行(speculativeexecution)和分支预测(branchprediction),但延迟仍不能完全被避免.
因此,从处理器的角度来看,一个数据库查询的时间(TQ)可以分解为以下几个部分:CPU有效计算时间(TC)、各级缓存产生的延迟时间(TM)、分支预测失误产生的延迟时间(TB)、资源缺失产生的延迟时间(TR),另外以上各个部分会有重叠(TOVL),因此有下面的公式成立[2].
不同的处理器平台上,TC的具体计算方法可能会有差别,如表1给出了公式(1)在安腾2处理器平台上各个时间的详细分解:QCMBROVLTTTTTT1)2576JournalofSoftware软件学报Vol.
19,No.
10,October20082.
2TPC-H基准测试TPC-H是TPC组织制定的用来模拟决策支持类应用的一个测试集.
目前,在学术界和工业界普遍采用它来评价决策支持技术方面应用的性能.
TPC-H基准测试是由TPC-D(由TPC组织于1994年指定的标准,用于决策支持系统方面的测试基准)发展而来的.
TPC-H用3NF实现了一个数据仓库,共包含8个基本关系,其数据量可以设定从1G~3T不等.
TPC-H基准测试包括22个查询(Q1~Q22),其主要评价指标是各个查询的响应时间,即从提交查询到结果返回所需时间.
TPC-H基准测试的度量单位是QphH@size,其中H表示每小时系统执行复杂查询的平均次数,size表示数据库规模的大小,它能够反映出系统在处理查询时的能力.
TPC-H是根据真实的生产运行环境来建模的,这使得它可以评估一些其他测试所不能评估的关键性能参数.
总而言之,TPC组织颁布的TPC-H标准满足了数据仓库领域的测试需求,并且促使各个厂商以及研究机构将该项技术推向极限.
Table1ExecutiontimecomponentsonItanium2表1安腾2平台上执行时间的各个组成部分TCComputationtimeofCPUStalltimerelatedtomemoryhierarchyTL1DStalltimeduetoL1D-cachemissesTL1TL1IStalltimeduetoL1I-cachemissesTL2DStalltimeduetoL2D-cachemissesTL2TL2IStalltimeduetoL2I-cachemissesTL3DStalltimeduetoL3D-cachemissesTL3TL3IStalltimeduetoL3I-cachemissesTDTLBStalltimeduetoDTLBmissesTMTITLBStalltimeduetoITLBmissesTBBranchmispredictionpenaltyTRResourcestalltime按照TPC-H标准,我们自行设计程序实现了TPC-H基准测试,用于模拟DSS类负载.
本文的研究关注于该类负载,因为基于内存的OLAP将会是未来内存数据库的一种重要的应用模式.
内存的OLAP是指这样一种技术:从基于磁盘的永久性数据存储中将数据加载到内存,在内存中对数据进行各种各样的OLAP分析.
相对于传统的基于磁盘的OLAP而言,内存OLAP的性能特征、优化策略、性能瓶颈主要受半导体RAM(内存,而不是磁盘)的影响.
基于内存OLAP的市场非常广阔,可以用来支持大部分要求苛刻的业务系统,如股票交易、通信设备、金融分析、航线调度以及网上书店等.
内存OLAP所带来的好处是,可以以更低的成本完成以前相同的工作;可以更快、更好地完成以前相同的工作;可以完成那些以前在技术上或经济上不可行的工作.
目前已有少数几个厂商,如Applix,QlikTech和PanoratioDatabaseImage开始研究内存OLAP产品.
3实验环境与研究方法3.
1硬件环境实验的硬件服务器:其中一台是基于安腾2的HPIntegrityrx2620-2服务器,处理器的主频为1.
6GHz,共有3级缓存,其中第1级缓存的指令缓存和数据缓存集成为一体,系统内存容量为4G;另外一台是基于至强(AMDOpteron(TM))的服务器,内存容量为2GB.
表2、表3分别给出了这两台服务器各级缓存的详细信息.
Table2Itanium2cachecharacteristics表2安腾2各级缓存参数Characteristic(unit)L1(split)L2L3Cachesize(KB)16data16inst.
2563072Cachelinesize(bytes)64128128Associativity4-way8-way6-wayMisspenalty(cycles)716182Table3AMDOpteron(TM)cachecharacteristics表3至强处理器各级缓存参数Characteristic(unit)L1(split)L2Cachesize(KB)16data16inst.
1024Cachelinesize(bytes)6464Associativity2-way16-wayMisspenalty(cycles)75653.
2度量工具与方法我们用Calibrator[10]来测量安腾2和至强处理器各级缓存每次缺失产生的延迟时间以及各级刘大为等:内存数据库在TPC-H负载下的处理器性能2577TLB(translationlookasidebuffer)上每次缺失引起的延迟时间.
例如,我们使用下面的命令来测试HPIntegrityrx2620-2服务器的各级缓存及TLB的延迟信息.
calibrator1600500MItanium2安腾2和至强处理器上都设有性能监测单元(performancemonitorunit),可以用来记录处理器各类事件的发生次数.
我们用PerfSuite[11]捕获处理器的各类事件并完成统计功能.
其中,PerfSuite工具包中的psrun是一个命令行工具,可以收集处理器的各个性能参数,并通过一个XML文件指定所要收集的性能参数.
例如,下面的命令可以监测应用程序postmaster.
exe运行期间60余个处理器的性能参数,具体参数在文件Itanium2.
xml中指定.
其中使用"f"参数可以将其子进程一起监测.
srun-cItanium_2.
xml-fpostmaster.
exepsrun统计的处理器性能参数记录了不同类型处理器事件发生的次数,例如第1级指令缓存上发生的缺失次数(L1instructioncachemiss).
将测得的缺失次数乘以一次缺失的延迟时间即可以计算出在该级缓存上总的延迟时间.
例如:L1上的指令缺失产生的延迟时间=L1指令缓存缺失次数*单次L1缺失延迟时间(2)根据以上计算方法,可以得到安腾2平台和至强平台上查询时间各组成部分的计算公式,见表4和表5.
Table4MethodofmeasuringeachofthestalltimecomponentsonItanium2platform表4安腾2平台上各部分延迟时间计算方法StalltimeDescriptionMeasurementmethodTCComputationtimeComputationtimeofCPUTL1TL1DStalltimeduetoL1D-cachemisses(misses)*7cyclesTL1IStalltimeduetoL1I-cachemisses(misses)*7cyclesTL2DStalltimeduetoL2D-cachemisses(misses)*16cyclesTL2TL2IStalltimeduetoL2I-cachemisses(misses)*16cyclesTL3DStalltimeduetoL3D-cachemisses(misses)*182cyclesTL3TL3IStalltimeduetoL3I-cachemisses(misses)*182cyclesTDTLBStalltimeduetoDTLBmisses(misses)*16cyclesTMTITLBStalltimeduetoITLBmisses(misses)*8cyclesTBBranchmispredictionpenalty(branchmispredictionsretired)*17cyclesTFUFunctionalunitstallsActualstalltimeTDEPDependencystallsActualstalltimeTRTILDInstruction-LengthdecoderstallsActualstalltimeTOVLOverlaptimeActualstalltimeTable5MethodofmeasuringeachofthestalltimecomponentsonAMDplatform表5至强处理器平台上各部分延迟时间计算方法StalltimeDescriptionMeasurementmethodTCComputationtimeComputationtimeofCPUTL1DStalltimeduetoL1D-cachemisses(misses)*7cyclesTL1TL1IStalltimeduetoL1I-cachemisses(misses)*7cyclesTL2DStalltimeduetoL2D-cachemisses(misses)*565cyclesTL2TL2IStalltimeduetoL2I-cachemisses(misses)*565cyclesTDTLBStalltimeduetoDTLBmisses(misses)*36cyclesTMTITLBStalltimeduetoITLBmisses(misses)*36cyclesTBBranchmispredictionpenalty(branchmispredictionsretired)*17cyclesTFUFunctionalunitstallsActualstalltimeTDEPDependencystallsActualstalltimeTRTILDInstruction-LengthdecoderstallsActualstalltimeTOVLOverlaptimeActualstalltime4结果分析4.
1内存数据库的处理器特性分析4.
1.
1结果与分析本节实验分析内存数据库在TPC-H负载下处理器的行为特性,选取了两种不同类型的内存数据库系统进2578JournalofSoftware软件学报Vol.
19,No.
10,October2008行分析,分别是MonetDB[12]和SystemA(一个商业化内存数据库产品,隐去实际名称).
实验基于安腾2处理器平台进行TPC-H基准测试,包括PowerTest和ThroughputTest.
其中,PowerTest是由一系列查询串行构成的负载流,ThroughputTest是以并发方式执行多个查询的负载流.
根据第2.
1节中描述的分析方法,我们分别计算出各个系统在运行TPC-H负载时处理器各方面时间开销所占的比例,结果如图1所示.
为了对比内存数据库和磁盘数据库在处理器上的不同行为特性,图中还给出了磁盘数据库的实验结果(这里,磁盘数据库为PostgreSQL[13]).
Fig.
1DifferentdeepmemorybehaviorofDRDBandMMDB:Powertest(left),throughputtest(right)图1磁盘数据库与内存数据库在处理器各级缓存延迟时间比例对比:压力测试(左图)、吞吐量测试(右图)从图1可以看出,两个内存数据库系统在基于安腾2处理器的平台上运行TPC-H负载时,处理器的延迟时间主要是由第2级指令缓存缺失(L2I-cachemiss)和第3级数据缓存缺失(L3D-cachemiss)造成的.
在Powertest下,第2级指令缓存缺失造成的延迟时间超过总的内存缺失延迟时间的30%,第3级数据缓存缺失造成的处理器延迟时间超过40%;在Throughputtest下,第2级指令缓存缺失产生的延迟时间超过总延迟的30%,而第3级数据缓存缺失产生的延迟时间超过40%.
从这组实验结果同时可以看出,磁盘数据库在TPC-H负载下,处理器的主要延迟时间产生在第1级指令缓存缺失和第3级数据缓存缺失.
以PostgreSQL为例,在Powertest下,第1级指令缓存缺失产生延迟约占总延迟的38%,第3级数据缓存缺失产生的延迟占到48%;在Throughputtest情况下,第1级指令缓存缺失产生的延迟约占总延迟的25%,第3级指令缓存缺失产生的延迟占近60%.
磁盘数据库在基于安腾2处理器平台上的实验结果和Ailamaki等人在1999年在奔腾处理器(Pentium)上的实验结果是一致的,同样表现出处理器时间开销主要是由最外层(距内存最近)的数据缓存缺失和最内层(距离处理器最近)的指令缓存造成的.
以上实验结果反映了磁盘数据库和内存数据库在运行TPC-H这类负载时行为特性以及性能瓶颈存在较大的差异.
内存数据库在基于安腾2处理器的系统上运行TPC-H负载时,由第2级指令缓存缺失和第3级数据缓存缺失所造成的延迟是构成总延迟的主要部分;而磁盘数据库在TPC-H负载下,处理器的主要延迟时间产生在第1级指令缓存缺失和第3级数据缓存缺失.
同时,也反映出在磁盘数据库上运行TPC-H负载时,处理器的利用率仍然是一个瓶颈,系统未能从处理器的进步中获得很好的收益.
实验结果的启示是,在TPC-H这类负载下,内存数据库的优化策略设计应该考虑如何减少第2级指令缓存的缺失和第3级数据缓存的缺失.
例如,在存储体系结构设计、索引结构设计以及查询优化算法设计等方面应该考虑如何有效地减少最外层数据缓存的缺失、提高缓存的性能进而提高处理器利用率.
因此,通过降低缓存缺失提高处理器的利用率将是优化的目标之一.
4.
1.
2优化策略研究针对以上实验发现的内存数据库在现代处理器上的性能瓶颈,我们在优化策略方面也进行了探索.
针对如何减少第3级的数据缓存缺失问题,我们提出了一种带有预取的聚集计算.
如图2所示,算法的基本思想是通过预取弥补处理器计算性能和数据访问之间的差异,通过预取将要访问的数据在被访问之前提前送入缓存,从而减少因缓存访问缺失而造成的时间延迟.
具体实现时,我们在聚集计算进行扫描元组的过程中插入预取代码,在L1DL1IL2DL2IL3DL3IDTLBITLB0PostgreSystemAMonet60403050102070Nomalizedmemorystalltime(%)PostgreSystemAMonetL1DL1IL2DL2IL3DL3IDTLBITLB050402030106070Nomalizedmemorystalltime(%)刘大为等:内存数据库在TPC-H负载下的处理器性能2579每次访问元组之前"预取"内存内容将其放入数据缓存中,从而有效地缩短了内存延迟,隐藏了内存子系统因访问缺失而造成的处理器延迟.
具体实现的算法如图3所示.
我们对上述算法进行了实验评估,实验是在基于安腾2处理器的平台上进行的.
实验中的聚集计算是TPC-H负载中的Q6,这是一个以扫描(scan)为主要基础运算的查询.
实验的数据按TPC-H标准实现的数据产生器生成,数据量分别为100M,200M至500M,而且在测试缓存性能前全部预先装入内存,消除I/O影响.
预取指令用Prefetch0,可以实现将数据预取至第一、二和三级缓存.
实验中主要比较了预取对第3级数据缓存缺失率、第3级缓存系统带宽以及处理器的利用率.
实验结果如图4所示,可以看出,预取对缓存子系统性能起到了一定的优化作用,实验中第3级数据缓存的缺失率下降了近3%,由于第3级缓存的单次缺失延迟时间和第一、第二级缓存相比非常大,因此,降低第3级数据缓存缺失次数对降低处理器总的延迟时间非常有效,实验中预取优化算法可以将理器延迟时间(stalltime)减少近27%.
Fig.
4L3cacheperformance:L3D-cachemissratio(left),L3cachebandwidth(middle),CPUutilization(right)图4第3级缓存缓存性能:第3级数据缓存缺失率(左图)、第3级缓存带宽(中图)、处理器利用率(右图)4.
1.
3动态预取基于简单访问模式的聚集计算(如顺序扫描)可以通过预取起到一定优化作用,原因是预取可以有效地减少缓存访问缺失次数,从而减少处理器因等待数据从内存到达缓存造成的延迟时间.
但是,简单预取方法也存在一定的局限性.
例如,由于程序具有动态性,即使是同一段代码在相同的环境下多次运行也可能产生不同的行为特性,从而导致缓存性能不稳定,所以这种简单的静态预取在效果上往往不够理想,在实验中往往表现出对缓存优化的效果不是很稳定,为此,我们考虑利用动态预取来改进优化算法.
动态预取的目标是通过调整预取的时机达到对缓存优化的最佳效果.
之所以进行动态调整预取时机是因为预取的时机对缓存的性能至关重要.
举例来说,如果预取过早,可能会把即将被访问的数据淘汰出缓存,因此,当处理器对这部分数据进行请求时导致了额外的缓存缺失.
反之,如果预取过迟,当处理器对数据缓存进行数据请求时,因为数据尚未到达缓存,同样也会发生缓存缺失的现象,而达不到优化效果.
总之,适当的预取时机才会对缓存性能起到优化作用.
预取时机可以通过调整预取距离(prefetchdistance)来进行控制,预取距离具体是指两次迭代之间预取的时间间隔,通常可以用消耗的处理器指令数作为度量单位.
9080706050403020100Datasize(100MB)NoprefetchPrefetch1371361351341331321311301291282468Datasize(100MB)NoprefetchPrefetch876543210Datasize(100MB)246810NoprefetchPrefetchAlgorithm1.
Scanwithprefetch.
Startscantable;VisitTuple(i);Computation;PrefetchTuple(i+1);End;Fig.
3Aggregatewithprefetch图3结合预取核心算法L3cachemissrate(%)BandwithusedtoL3cache(MB)CPUutilization(%)246810pagePrefetchCacheMemoryPageFig.
2Prefetchmemorytodatacach图2预取内存内容至缓存2580JournalofSoftware软件学报Vol.
19,No.
10,October2008基于静态预取的局限性,我们对基于简单静态预取的聚集计算算法进行了改进.
提出了一种动态调整预取距离的预取算法.
算法描述如图5所示,其基本思想是在进行下一次预取之前,先获取数据缓存的性能统计信息(具体实现中,我们用Papi[14]实现对hardwarecounters的访问,获取近60个处理器事件统计信息);再根据当前的统计信息计算出缓存的命中情况,并对下一次的预取距离进行调整.
我们将预取距离的单次调整步长设定为处理器访问一次数据缓存线所需的指令周期数.
预取距离的初始值按以下公式进行估算:预取距离=内存延迟*跨距/128/每个叠代周期数(3)其中,跨距等于每迭代消耗的字节数量,内存延迟与具体的处理器相关,在安腾2处理器上约为300个指令周期.
我们对动态调整算法也进行了实验评估,实验是在基于安腾2处理器的平台上进行的.
实验中的聚集计算是TPC-H负载中的Q10,数据量为500M且全部装入内存,实验中的预取指令是Prefetch0,把内存中的数据预取至各级缓存中,我们将动态预取算法和前述的静态预取算法进行了对比,并对两种算法的缓存缺失率进行了抽样统计,统计间隔设定为36000指令周期.
实验结果如图6所示,从实验结果可以看出,与简单的预取算法相比,动态预取算法的平均缓存缺失率要优于静态预取算法,对缓存的优化作用相对更稳定.
4.
1.
4进一步讨论对于基于简单访问模式的聚集计算,特别是以扫描为基础运算的聚集计算,如TPC-H中的Q6,Q10这样的负载,使用预取能够起到一定的优化作用.
那么,如何对具有复杂访问模式的聚集计算,如TPC-H负载中的其他各个复杂查询进行优化是我们下一步要开展的工作.
4.
2存储体系结构对处理器行为的影响目前,多数DBMS采用的是行存储模型.
在行存储模型下,元组的属性按照建表时定义的先后次序连续存放,一次写磁盘操作可以把一个记录的所有属性写到磁盘上,从而写操作具有较高的性能.
因此,按行存储的数据库系统又称为"写优化(writeoptimized)"系统.
这类系统特别适合处理OLTP类事务,如TPC-C类的负载.
然而,在某些应用中数据库系统应该被设计成"读优化(readoptimized)".
例如,数据仓库中会定期地把数据批量装载至仓库中,然后处理耗时较长的查询;又如客户关系管理(customerrelationshipmanagement,简称CRM)系统、数字图书馆卡片目录系统和其他更新修改操作少而查询多的系统等等.
在这种应用环境下,按列存储意味着所有属于同一列的数据项连续存放,因此数据库系统只需要读取与即席查询相关的列即可,从而避免了处理与查询无关的那些属性列.
简而言之,两种不同存储体系结构的差异是:前者按行将某些记录的所有属性读入内存中;后者则按列将某些属性的全部值读入内存中.
那么两者对处理器的利用情况如何呢下面首先通过实验比较不同的存储体系结构对处理器的利用情况以及差异,并分析产生差异的原因;其次,在存储体系结构设计方面我们给出一些建议;实验主要评价两种存储模型:行存储(row-based)和列存储(column-based)在现代处理器上的不同行为特性.
Algorithm2.
Dynamicprefetch.
StartAccesshardwarecounters;GetL3D-cachestatistics;Adjustprefetchdistance;Prefetchaccordingnewdistance;EndFig.
5Dynamicprefetch图5动态预取算法Exeutiontime(ms)020406080100120140160180200L3cachemissratio(%)Fig.
6Dynamicprefetchcahcemiss图6动态预取算法缓存缺失SimpleprefetchDynamicprefetch50484644383634刘大为等:内存数据库在TPC-H负载下的处理器性能25814.
2.
1实验与结果分析为了比较不同的存储结构对处理各级缓存的影响,我们对MonetDB和SystemA进行了实验分析.
其中,MonetDB的存储体系结构采用的是列存储的策略,而SystemA采用的是行存储体系结构.
实验分别在基于安腾2(Itanium2)处理器和至强(Opteron(TM))处理器的平台上进行测试,实验的结果如图7所示.
图中比较了两种不同存储模型的内存数据库在不同实验平台上运行TPC-H负载时处理器的时间开销比例,各个比例的计算采用的是第2.
1节中所描述的方法.
从图7中我们可以看出,二者的差异主要在第3级数据缓存所产生的时间延迟上;基于安腾2处理器的实验平台上,MonetDB在第3级数据缓存缺失产生的延迟比SystemA要少近20%.
Fig.
7Storagearchitectureinfluenceondeepmemory:AMDOpteron(TM)(left),Itanium2(right)图7不同存储体系结构对处理器各级缓存的影响:AMD至强平台(左图)、安腾2平台(右图)造成这两个系统在第3级数据缓存上的缺失存在较大差异的主要原因是:TPC-H负载中的查询多是针对表中部分属性列的聚集计算.
在22个查询中,有些查询需要大量的全表扫描,如Q1,Q6和Q10;有些需要大量的连接操作,如Q4,Q13等.
当元组从内存被调入最近的数据缓存(在安腾2处理器上是第3级数据缓存;在至强处理器上是第2级数据缓存)时,如果数据库系统是以行存储方式存储元组的,则每次读入数据缓存中的元组会有一部分不必被访问,这部分属性本来无须装入数据缓存.
这种存储方式使得数据缓存中存放的元组数量相对要少,造成数据缓存频繁进行数据交换,进而导致处理器空闲时间延长而降低了系统的性能.
采用按列存储的MonetDB系统在执行查询时,按列将元组从内存读入数据缓存,在相同缓存大小的条件下,每次可以读入更多数量的元组,因此数据缓存和内存数据交换的时间将会减少,从而性能优于行存储系统的性能.
我们在基于至强处理器的实验平台上进行了同样的测试,实验结果和在基于安腾2处理器的实验平台上的结果相一致;在TPC-H这类负载下,列存储模型的性能优于行存储模型.
实验结果表明,不同存储体系结构对处理器的利用存在较大的差异,数据库系统的设计者应该针对具体的应用背景考虑数据库的存储体系结构.
特别是随着内存容量的不断增加,当全部的工作集(workingset)可以放在内存时,如何有效地减少处理器和内存之间的数据交换代价,从而提高处理器的利用率将变得更为重要.
根据以上实验结果,在下一代的DBMS体系结构设计方面,我们也开展了一些研究工作:我们设计开发了PMDB(parallelmainmemorydatabase)原型系统.
PMDB是一个列存储的、并行的、内存数据库系统.
PMDB的设计目标是希望能够充分利用现代计算机硬件发展的优势(如处理器、内存).
4.
3索引对处理器行为的影响磁盘数据库优化技术的主要目标是减少磁盘I/O,因此,索引、数据压缩等技术可以通过减少磁盘I/O来优化性能.
然而,内存数据库中所有的数据都驻留在内存,这种情况下磁盘I/O不再是系统的主要瓶颈,而在于处理器内存之间的数据交换代价.
因此,研究索引对处理器各级缓存的利用情况以及索引在处理器上的行为特性可以对性能评价以及优化策略的设计提供依据.
本节先以实验分析了索引对处理器上各级缓存的影响以及使用索引时瓶颈的所在;然后,对实验结果进行分析并给出索引设计方面的优化建议.
本节的实验是在MonetDB和SystemA两个系统上进行的.
实验中,我们在TPC-H基准测试中的数据库模式上创建了索引,然后分别在内存数据库MonetDB和SystemA上进行TPC-H测试.
实验在基于至强处理器的SystemAMonetDBL1DL1IL2DL2INomalizedmemorystalltime(%)907050403020100SystemAMonetDBL1DL1IL2DL2IL3DL3IDTLBITLBNomalizedmemorystalltime(%)7060504030201002582JournalofSoftware软件学报Vol.
19,No.
10,October2008系统平台上进行,实验结果如图8所示.
从图中可以看出,两个内存数据库在没有索引的情况下,由第1级数据缓存造成的缺失和第1级指令缓存以及第2级指令缓存引起的处理器延迟时间要比有索引的情况下对应的缺失多一些;另一方面,从实验结果来看,当使用索引时,第2级数据缓存造成的缺失比例在增长.
Fig.
8Indexinfluenceondeepmemory:MonetDBonAMDplatform(left),SystemAonAMDplatform(right)图8AMD至强平台上索引对处理器各级缓存的影响情况:MonetDB(左图)、系统A(右图)索引的使用会对处理器各级缓存的行为特性产生一定的影响,其主要原因是:索引扫描的空间局部性与无索引时相比会好一些,因此,索引操作符访问和预取的元组个数相对较少,从而数据缓存中可以保留更多的有效数据.
所以,当数据访问变少时,将会有更多的空间用于存放指令,使得每次取指令可以获取更多的指令数,并使得指令缓存的缺失率响应也下降.
针对这一实验现象,在索引的设计和使用上应该如何才能提高缓存子系统的性能以减少时间延迟、提高性能呢我们给出的一些优化策略和建议如下:在索引的数据结构方面,其结构应该具有更好的"缓存"特性.
例如,如果使用B+树,那么应该尽可能减少树的"高度"、尽量多地去除节点内的指针,同时将节点的大小控制在一个缓存线(cacheline)大小左右;此外,还可以使用压缩方法使单个节点存放更多的索引项等等.
通过这些方法,可以增加节点的扇出度、降低树的深度,从而改善树的缓存性能.
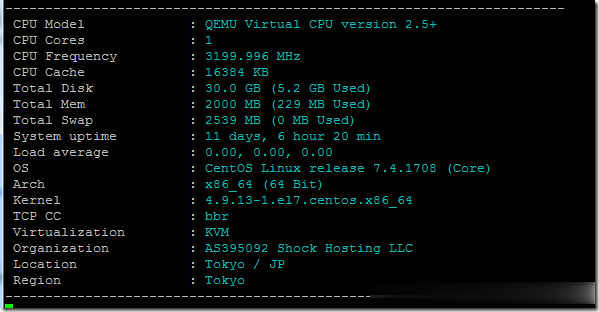
ShockHosting日本机房VPS测试点评
这个月11号ShockHosting发了个新上日本东京机房的邮件,并且表示其他机房可以申请转移到日本,刚好赵容手里有个美国的也没数据就发工单申请新开了一个,这里做个简单的测试,方便大家参考。ShockHosting成立于2013年,目前提供的VPS主机可以选择11个数据中心,包括美国洛杉矶、芝加哥、达拉斯、杰克逊维尔、新泽西、澳大利亚、新加坡、日本、荷兰和英国等。官方网站:https://shoc...
博鳌云¥799/月,香港110Mbps(含10M CN2)大带宽独立服务器/E3/8G内存/240G/500G SSD或1T HDD
博鳌云是一家以海外互联网基础业务为主的高新技术企业,运营全球高品质数据中心业务。自2008年开始为用户提供服务,距今11年,在国人商家中来说非常老牌。致力于为中国用户提供域名注册(国外接口)、免费虚拟主机、香港虚拟主机、VPS云主机和香港、台湾、马来西亚等地服务器租用服务,各类网络应用解決方案等领域的专业网络数据服务。商家支持支付宝、微信、银行转账等付款方式。目前香港有一款特价独立服务器正在促销,...

Virtono:€23.7/年,KVM-2GB/25GB/2TB/洛杉矶&达拉斯&纽约&罗马尼亚等
Virtono最近推出了夏季促销活动,为月付、季付、半年付等提供9折优惠码,年付已直接5折,而且下单后在LET回复订单号还能获得双倍内存,不限制付款周期。这是一家成立于2014年的国外VPS主机商,提供VPS和服务器租用等产品,商家支持PayPal、信用卡、支付宝等国内外付款方式,可选数据中心包括罗马尼亚、美国洛杉矶、达拉斯、迈阿密、英国和德国等。下面列出几款VPS主机配置信息,请留意,下列配置中...
-
网络服务器租用租网络服务器在哪些平台比较合适?网站服务器租用公司想建个网站,请问租服务器按年收费是多少钱域名主机域名和主机名之间的区别是什么域名购买域名注册和购买是一个意思吗?香港虚拟空间香港虚拟主机空间哪家最好美国网站空间美国空间做什么网站好?深圳网站空间怎么样建立网站apache虚拟主机Apache跟虚拟主机有什么关系?论坛虚拟主机虚拟主机禁止放论坛m3型虚拟主机谁在用中国万网M3虚拟主机?怎么样?