nutch使用为什么说Lucene不好
nutch使用 时间:2021-06-09 阅读:()
您好,我看你在数据抓取方面是个专家,想请教一下您怎么用nutch1.2抓取数据?
1、只要将这个种子地址加入到nutch的种子地址文件中即可。2、怎么添加我也忘了,但是通过看我的日志中的相关博客应该能搞定。
最好再好好看下官方文档。
java如何用lucene+nutch搭建分布式搜索引擎?
1.可以用lucene,lucene现在已经发展到1.9.1版了,相当稳定,网上中英文资源很丰富,甚至关于这个工具包的书(lucene in action)都有了.如果只是做站内搜索,可以直接从读数据库中读数据,调用lucene做索引.再写一个前台查询界面,调用lucene查询索引并在前台显示结果. 想一点程序都不写的话可以参考下面2个方案 2.用heritrix + nutchwax,heritrix也是一个很成熟的crawler,他将网页下载并压缩保存到arc格式的文件中,一个arc文件一般100兆左右,heritrix不解析提取网页的内容,nutchwax负责解析网页,提取内容并建索引,nutchwax提供检索界面.缺点是nutchwax的安装很麻烦. 3.用nutch,一个超强的开源软件,作者就是lucene的作者,该软件的目标是做到和Google一样强大,nutch的很多分布式实现的思想来源于Google,目前已实现分布式crawler,和分布式检索,已经有人用他抓了几亿的网页,nutch功能包括了下载网页,解析网页,计算网页重要度,建索引,前台搜索等一个搜索引擎需要的绝大部分功能,用他来做站内搜索也很方便.该软件支持中文. nutch目前稳定的版本是0.7.2 用该软件的缺点是网上的中文资料不多.你要习惯看英文资料我想知道nutch是怎么进行搜索的?他的检索算法是什么,具体代码是哪部分?
其实这个问题很复杂,但分层之后,就显得清晰多了。1、nutch是一个搜索产品的半成品,自己完成网络爬虫的功能,参数配置非常复杂周详,而后加上lucene的搜索功能,再加上hadoop的云平台基础。
2、要想学习他检索要先学会lucene,他的检索的核心都是lucene,包括索引、查询、排序等核心环节。
3、具体代码我好长时间不看了,找下lucene in action等这样的书看吧,学习资料超多。
为什么说Lucene不好
对那些刚接触Lucene的人来说,这里是使用它的关键:Apache Lucene是一个由java编写的高性能,全方位的单词搜索引擎库。在批评它之前,我必须承认Lucene是一个高性能的划词搜索引擎。
几年来,Lucene已经被看作是用java编写的嵌入式搜索引擎中的一等公民。
它的声誉每日剧增,并且仍然是开源java搜索引擎中的最佳。
每个人都在说:“Doug Cutting做了一项伟大的工作”。
然而,最近的几个月内,开发的进程变得缓慢,我认为Lucene将不会满足现代的文档处理需求。
不要把东西搞糟:我不是搜索引擎开发者,我只是个开发者,使用搜索引擎,来提供合适信息的检索科技。
这贴是讨论为什么对未来的开发者而言,Lucene不是最好选择,至少对我们而言如此,并且情况并没有得到改变。
我们列出Lucene的局限性:Lingway公司基于语意来生成复杂的查询。
例如当你正在查找关于“中东地区冲突”的文章,你也许还需要找关于“伊拉克战争”文章。
在上面这个用例中,“战争”和“伊拉克”分别是“冲突”和“中东”的扩展。
我们使用一种技术能分析你的查询,产生相应的最合适的扩展,为它们生成查询。
然而,为了得到相关的结果,这些还是不够的:通过Lucene实现的类似Google的等级或是经常变化积分的并不能满足语意级别积分。
例如,一个包含“中”和“东”短语,但是被超过一个以上的单词隔开,这种情况并不是我们想要查找的。
更重要的是,相对常规的单词,我们应该给扩展更低的分数。
比如,我们应该给“中东地区冲突”这个短语更高的分数,而不是“伊拉克战争”。
在Lingway公司,我们认为这种文章相关性技术是一种未来的搜索引擎。
Google在文章搜索上做的很出色。
但我们想要的却是最相关的文章。
但是,大部分的当代搜索引擎都没有对这样复杂查询做相关的设计…Lucene被wikipedia使用,如果你注意到当你查询查过一个单词时,大多数的查询结果并不是由关联的…为了演示需求,这里有一个Lingway公司即将上线的KM3.7产品的界面截图。
这里我们用法语写一个查询,用来查找那些同样主题,而用英语写的文章。
注意,这可不仅仅是简简单单的翻译,我们称之为语言交叉模式:注意到那些绿色的匹配:chanteur变成了singer,但是我们也发现singing被匹配了。
同样情况流行乐成为蓝调的扩展。
6大理由不选用Lucene6. 没有对集群的内置支持。
如果你创建集群,你可以写出自己对Directory的实现,或是使用Solr或者使用Nutch+Hadoop。
Solr和Nutch都支持Lucene,但不是直接的替代。
Lucene是可嵌入的,而你必须支持Solr和Nutch..我认为Hadoop从Lucene团队中产生并不惊讶:Lucene并不是通用的。
它的内在性决定了对大多数场合来说它是非常快速的,但是对大型文档集合时,你不得不排除Lucene。
因为它在内核级别上并没有实现集群,你必须把Lucene转换到别的搜索引擎,这样做并不直接。
转换到Solr或者Nutch上的问题会让你遇到许多不必要的麻烦:Nutch中的集成crawling和Solr中的检索服务。
5.跨度查询太慢这对Lingway公司来说可能是个特殊的问题。
我们对跨度查询有很强要求,Lucene检索结构已经开始添加这一细节,但它们当初可没这么想。
最基础的实现导致了复杂的算法并且运行缓慢,尤其是当某些短语在一份文档中重复了许多次出现。
这是为什么我倾向说Lucene是一个高性能的划词检索引擎当你仅仅使用基本的布尔查询时。
4.积分不能被插件化Lucene有自己对积分算法的实现,当条件增加时使用Similarity类。
但很快它显示出局限性当你想要表示复杂的积分,例如基于实际匹配和元数据的查询。
如果你这样做,你不得不继承Lucene的查询类。
因为Lucene使用类似tf/idf的积分算法,然而在我们遇到的场合,在语意上的积分上Lucene的积分机制并不合适。
我们被迫重写每一个Lucene的查询类使得它支持我们自定义的积分。
这是一个问题。
3.Lucene并非良好设计作为一个系统架构师,我倾向认为(1)Lucene有一个非常糟糕的OO设计。
虽然有包,有类的设计,但是它几乎没有任何设计模式。
这让我想起一个由C(++)开发者的行为,并且他把坏习惯带到了java中。
这造成了,当你需要自定义Lucene来满足你的需求(你将来必定会遇到这样的需求),你必须面对这样的问题。
例如:几乎没有使用接口。
查询类(例如BooleanQuery,SpanQuery,TermQuery…)都是一个抽象类的子类。
如果你要添加其中的一个细节,你会首先想到写一个接口来描述你扩展的契约,但是抽象的Query类并没有实现接口,你必须经常的变化自己的查询对象到Query中并在本地Lucene中调用。
成堆的例子如(HitCollecor,…)这对使用AOP和自动代理来说也是一个问题. 别扭的迭代实现.没有hasNext()方法,next()方法返回布尔类型并刷新对象内容.这对你想要保持对迭代的元素跟踪来说非常的痛苦.我假定这是故意用来节省内存但是它又一次导致了算法上的杂乱和复杂. 2.一个关闭的API使得继承Lucene成为痛苦在Lucene的世界中,它被称之为特性。
当某些用户需要得到某些细节,方针是开放类。
这导致了大多数的类都是包保护级别的,这意味着你不能够继承他们(除非在你创建的类似在同一个包下,这样做会污染客户代码)或者你不得不复制和重写代码。
更重要的是,如同上面一点提到的,这个严重缺乏OO设计的结构,一些类应该被设为内部类却没有,匿名类被用作复杂的计算当你需要重写他们的行为。
关闭API的理由是让代码在发布前变得整洁并且稳定。
虽然想法很光荣,但它再一次让人感到痛苦。
因为如果你有一些代码和Lucene的主要思路并不吻合,你不得不经常回归Lucene的改进到你自己的版本直到你的补丁被接受。
然而当开发者开始越来越长的限制API的更改,你的补丁很少有机会被接受。
在一些类和方法上加上final修饰符会让你遇到问题。
我认为如果Spring框架有这样的限制,是觉不会流行起来。
1. Lucene搜索算法不适合网格计算Lucene被写出来的时候硬件还没有很大的内存,多处理器也不存在。
因此,索引结构是被设计成使用线性的内存开销很小的方式。
我花了很长的时间来重写跨度查询算法,并使用多线程内容(使用双核处理器),但是基于迭代器的目录读取算法几乎不能实现。
在一些罕见的场合你能做一些优化并能迭代一个索引通过并行方式,但是大多数场合这是不可能的。
我们遇到的情况是,当我们有一个复杂的,超过50+的内嵌跨度查询,CPU还在空闲但I/O却一直忙碌,甚至在使用了RAMDirectory.有没有替代品?我认为最后一个观点充满疑问:Lucene到达了它的极限当它在现在硬件基础的条件下,检索大型数据集合时。
那就是我为什么寻找下一个可以替代Lucene的出现。
在阅读了博客目录和 Wikia的讨论后,我发现并没有很多的替代品。
然而我最后推荐一个有希望的方案:MG4J。
它有一个良好的面向对象设计,性能良好的检索(索引比Lucene慢),内存开销上也很小,达到10倍于Lucene速度的跨度查询,在我的跨度查询基准上,并且是原生上支持集群。
同样它也内置了负载平衡,而Lucene最近才加入这项功能并且还是实验性质的。
然而MG4J仍然缺少一些特性例如简单的索引指数,文档移除和更简单的使用索引处理。
让我感到高兴的是我可以自定义Lucene上的功能在MG4J上只需花几个小时,而在Lucene上却需要数天。
我认为对开源的搜索引擎来说仍然有发展空间,它不是通过单台电脑用有限的内存来索引批量文档,而是通过透明的分布式索引来提供对大型数据集合检索更为快捷的答案。
你不必利用应用来获得集群特性。
Lucene对第一类搜索引擎有了很好的实现,单我认为它并不符合我们的需求:在一个合理的时间内找到最佳的答案。
基于tf/idf的搜索算法和google的等级并不是未来搜索引擎的趋势。
实现对原数据和语义的复杂查询并找出相关的信息,这是Lingway公司(通过Lucene和其他搜索引擎技术)所作的,不过它要求有更多支持新硬件的新技术。
使用Lucene的一个好理由无论我如何指责Lucene,它仍然是java开源解决方案中的最佳实现。
- nutch使用为什么说Lucene不好相关文档
- nutch使用使用Nutch能抓取针对性的内容吗
- nutch使用nutch hadoop实现什么功能
- nutch使用最近一直在玩nutch,现在数据抓取出来了,但是怎么把数据提取出来啊?
- nutch使用怎样编译,安装和配置nutch2.x
IonSwitch:$1.75/月KVM-1GB/10G SSD/1TB/爱达荷州
IonSwitch是一家2016年成立的国外VPS主机商,部落上一次分享的信息还停留在2019年,主机商提供基于KVM架构的VPS产品,数据中心之前在美国西雅图,目前是美国爱达荷州科德阿伦(美国西北部,西接华盛顿州和俄勒冈州),为新建的自营数据中心。商家针对新数据中心运行及4号独立日提供了一个5折优惠码,优惠后最低1GB内存套餐每月仅1.75美元起。下面列出部分套餐配置信息。CPU:1core内存...
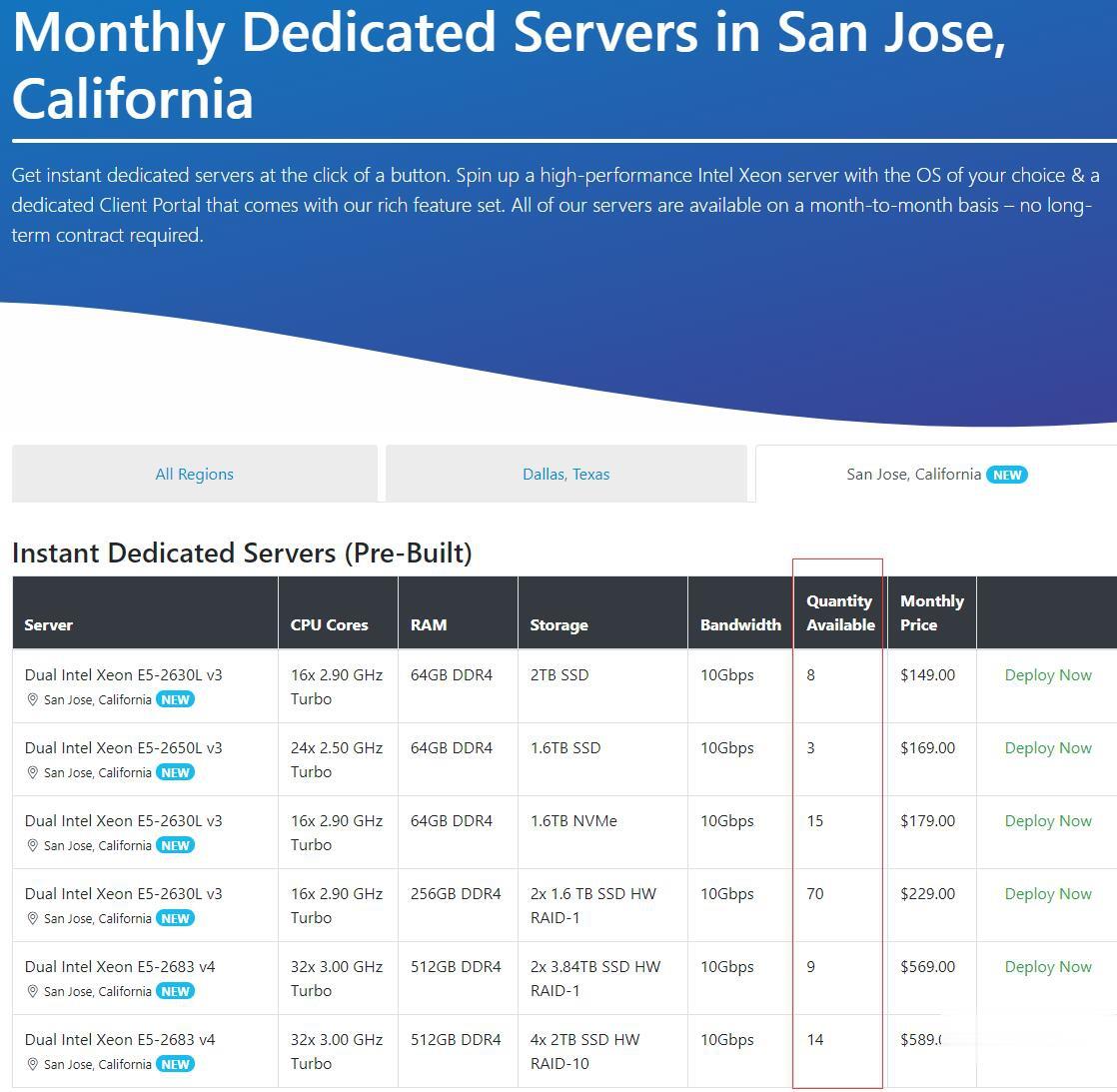
Spinservers:美国圣何塞机房少量补货/双E5/64GB DDR4/2TB SSD/10Gbps端口月流量10TB/$111/月
Chia矿机,Spinservers怎么样?Spinservers好不好,Spinservers大硬盘服务器。Spinservers刚刚在美国圣何塞机房补货120台独立服务器,CPU都是双E5系列,64-512GB DDR4内存,超大SSD或NVMe存储,数量有限,机器都是预部署好的,下单即可上架,无需人工干预,有需要的朋友抓紧下单哦。Spinservers是Majestic Hosting So...
亚洲云-浙江高防BGP.提供自助防火墙高防各种offer高防BGP!
亚洲云Asiayun怎么样?亚洲云Asiayun好不好?亚洲云成立于2021年,隶属于上海玥悠悠云计算有限公司(Yyyisp),是一家新国人IDC商家,且正规持证IDC/ISP/CDN,商家主要提供数据中心基础服务、互联网业务解决方案,及专属服务器租用、云服务器、云虚拟主机、专属服务器托管、带宽租用等产品和服务。Asiayun提供源自大陆、香港、韩国和美国等地骨干级机房优质资源,包括B...
nutch使用为你推荐
-
知识分享平台知识付费平台有哪些?virusscan已安全McAfee VirusScan 10.0 windows 还有安全报警数据监测运动手表的数据监测都准确吗?qq博客怎么开QQ博客啊!oa办公系统下载OA在哪里下载?腾讯技术腾讯是什么东西?asp大马问:ASP是什么?ASP根据什么制作木马的?ASP木马和大马有什么区别?什么是生态系统什么是生态环境?网络电话免费版有没有免费的网络电话?纯免费的点心os现有的基于安卓深度优化的MUUI、点心OS、CM7、乐众ROM、乐蛙,这些哪个好?各自特点?给个排名。