http://www.arocmag.com/article/02-2019-11-036.html
更胜一筹 时间:2021-05-04 阅读:()
计算机应用研究收稿日期:2018-03-20;修回日期:2018-05-16基金项目:国家自然科学基金资助项目(11672044,11172047);北京信息科技大学教改项目(2016JGYB09);,2018北京信息科技大学研究生科技创新项目作者简介:石杰(1993-),男,河北保定人,硕士研究生,主要研究方向为深度学习图像处理;周亚丽(1968-),女,辽宁沈阳人,教授,博士,主要研究方向为机器人控制及信号处理究(zhouyali@bistu.
edu.
cn).
;张奇志(1963-),男,辽宁阜新人,教授,博士,主要研究方向为机器人控制.
基于FasterR-CNN的服务机器人物品识别研究*石杰,周亚丽,张奇志(北京信息科技大学自动化学院,北京100192)摘要:随着机器人在服务行业中的应用推广,尤其在家庭服务中有着重要的作用,对服务机器人的信息采集或目标识别需求也越来越强烈.
传统的日用商品识别流程通常使用较为经典的图像识别和机器学习算法,如支持向量机(SVM)、随机森林或Adaboost,然后利用目标图像的梯度、纹理或颜色的基本特征来对日用商品进行识别,可以在比较简单的背景中得到应用,但是在复杂的背景环境中很难有比较突出的表现,并且难以达到较高的准确率.
目前在目标识别中表现比较优异的是卷积神经网络(CNN),并成为很多目标识别场景中的首选.
考虑到服务机器人的硬件配置成本,将基于区域的卷积神经网络(R-CNN)的快速算法FasterR-CNN引入系统中,并以CPU计算的方式进行物品识别.
利用CNN网络提取图像特征,在其后面接入一个区域提议层.
实验结果表明,将深度学习的识别方法应用到服务机器人平台是可行的,识别效果准确,且在实验中得到较好的检测效果.
关键词:服务机器人;深度学习;FasterR-CNN;物品识别中图分类号:TP391.
4doi:10.
3969/j.
issn.
1001-3695.
2018.
03.
0311ItemrecongnitionbasedonfasterR-CNNinservicerobotShiJi,ZhouYali,ZhangQizhi(SchoolofAutomation,BeijingInformationScience&TechnologyUniversity,Beijing100192,China)Abstract:Withthepromotionandapplicationofrobotsintheserviceindustry,especiallyinthefamilyservice,thedemandforinformationcollectionortargetrecognitionforservicerobotsisalsogettingstrongerandstronger.
Traditionalcommodityrecognitionprocessestypicallyusethemoreclassicimagerecognitionandmachinelearningalgorithmssuchassupportvectormachines(SVM),randomforestoradaboost,thenusethebasiccharacteristicsofthegradient,textureorcolorofthetargetimage.
Itcanbeappliedinarelativelysimplebackground,butitishardtohaveamoreprominentperformanceinacomplicatedbackgroundenvironment,anditisdifficulttoachieveahighaccuracy.
Atpresent,theconvolutionneuralnetwork(CNN),whichissuperiorintargetrecognition,hasbecomethefirstchoiceinmanytargetrecognitionscenarios.
Consideringthehardwareconfigurationcostofservicerobot,FasterR-CNN,afastalgorithmofregion-basedconvolutionalneuralnetwork(R-CNN),isintroducedintothesystemandidentifiedbyCPU.
TheCNNnetworkisusedtoextractimagefeaturesandaccesstoaregionalproposallayerbehindit.
Theexperimentalresultsshowthatitisfeasibletoapplythedeeplearningrecognitionmethodtotheservicerobotplatform.
Therecognitioneffectisaccurateandthetestresultsaregood.
Keywords:servicerobot;deeplearning;FasterR-CNN;commodityrecognition0引言近年来,随着机器人行业的迅猛发展,服务型机器人开始进入大众视野,而人工智能相关技术的快速发展使得服务机器人得到了越来越多的技术支持.
服务机器人具有非常广泛的应用前景,其发展是实现自动化服务的重要一步.
同时,日用商品识别是智能服务行业的一个基础的研究问题,也是用于采集和分析超市日用商品大数据信息的前提和基础.
在服务机器人平台实现物品识别是未来行业发展的重要趋势.
一方面,服务机器人具有较为完善的硬件基础,可以完成基础的任务,功能强大;另一方面,深度学习在识别领域不仅能够完成多目标识别任务,还有很高的准确率.
物体检测识别依赖于计算机视觉的发展,一直以来是图像工程领域重要的研究热点.
但由于技术发展的落后、大众对物体识别的认知度不强和算法应用场景的限制,物体检测真正快速的发展起始于20世纪90年代.
人的肉眼通过视野内物体的chinaXiv:201808.
00076v1ChinaXiv合作期刊录用稿石杰,等:基于FasterR-CNN的服务机器人物品识别研究纹理特征、颜色特征、深度信息等,定位、识别目标物体非常简单.
然而计算机在处理图像时,面对的是数值化的三通道矩阵(即RGB矩阵),难以直接得到货架、物品这种抽象的概念,再加上图片背景的复杂度、物品摆放姿态的多样性和不同的光照强度等其他外界干扰因素,使得物体检测更加困难.
与传统的物品识别检测相比,服务机器人采集的图像具有背景更为复杂、采集现场光亮强度不一、识别目标距离的远近、相同物品不同形状等难题.
传统的物品识别方法主要采用基本图像处理方法,如背景建模[1]、HOG[2](histogramoforientedgridients)、K-means聚类算法[3]、特征点匹配算法[4]、加速稳健特征(speededuprobustfeatures,SURF)[5]等.
在传统的目标检测方法中,2001年Viola等人在论文"鲁棒实时目标检测"中提出的Viola-Jones框架[6]得到了广泛的关注.
这种方法速度快、相对简单,傻瓜相机的实时脸部检测就是使用这种算法,它的运算量很小.
它使用Harr特征[7]来生成不同的简单的二分类,这些分类被级联的多尺度滑动窗口来处理,并且会及时丢弃错误分类.
深度学习作为机器学习领域的延伸已经众人皆知了,尤其在计算机视觉领域.
与深度学习模型在图像分类领域优于传统模型类似,深度学习现在也是目标检测领域中最好的方法.
过去几年深度学习目标检测方法有了很大的进步,纽约大学的研究人员在2013年提出了Overfeat[8],并在目标检测领域取得很大进展,他们提出了一种使用卷积的多尺度滑动窗口算法.
在Overfea提出不久,伯克利大学的Girshick等人[9]提出了基于区域的卷积特征(region-basedconvolutionalneuralnetwork,R-CNN)算法,这也是深度学习在目标检测领域的重大突破,该算法在目标检测效果上相比传统方法取得了50%的性能提升.
R-CNN提出了一个三阶段的方法:a)使用区域提议方法提取可能目标,现在流行的方法是选择性搜索(selectivesearch)[10];b)使用卷积神经网络(convolutionneuralnetwork,CNN)在区域上提取特征;c)使用支持向量机(supportvectormachine,SVM)[11]对区域进行分类.
虽然R-CNN在当时目标检测领域取得了非常不错的成绩,但是在训练过程中有很多问题.
首先需要生成训练集的建议区域,然后在每个区域使用CNN特征提取器来提取特征,最后训练SVM分类器.
这个过程需要消耗大量的时间.
在2015年Girshick[12]发表了FastR-CNN,这种方法迅速进化成一个纯深度学习方法.
与R-CNN相似,它使用选择性搜索来生成区域建议;但与R-CNN不同的是,FastR-CNN在整张图上使用CNN来提取特征,然后在特征图上使用区域兴趣池化(regionofinterest,ROI),最后是一个反向传播网络来做分类和边框回归.
这种方法不仅快,而且因为区域兴趣池化层和全连接层,该模型可以进行端对端的差分,训练也很容易.
最大的不足是该模型仍旧依赖于选择性搜索,这也成为了模型推理阶段的一个瓶颈.
随后,Ren等人[13]发表了FasterR-CNN,这是R-CNN系列的第三个迭代.
FasterR-CNN增加了一个区域建议网络(regionproposalnetwork,RPN)[14],试图摆脱选择性搜索算法,从而让模型实现完全端对端的训练.
RPN的作用是根据"物体"的分数来输出可能目标.
这些目标区域被后面的ROI池化和全链接层来做分类.
随着深度学习在近些年的爆炸性发展和机器人在服务行业的广泛应用,本文在上述成果的基础上,将深度学习的方法应用到智能服务机器人平台.
考虑到识别准确率和识别时间,本文主要利用FasterR-CNN作为目标检测算法,硬件平台采用自主研发的服务机器人.
该机器人具有路径规划、行人跟踪、物体抓取、自主导航等功能.
本文实现的是机器人自主识别物品,为未来实现自主抓取、导航打下基础.
FasterR-CNN主要有两种训练模式,一种是2015年NIPS中的"alternatingoptimization"(alt-opt)[15]方法,它的训练特点是迭代,先训练RPN,随后用建议框去训练FastR-CNN,被FastR-CNN微调的网络用来初始化RPN,以此迭代;另一种是"EndtoEnd",其训练特点是将RPN和FastR-CNN融合到一个网络中进行训练,在每次随机梯度下降(SGD)迭代过程中,前向传递时RPN产生区域建议框,这些建议框被当做固定的、提前计算好的建议框来训练FastR-CNN检测器.
反向传递时,对于共享层来说,来自RPN的损失函数与FastR-CNN的损失函数结合.
但是这种方法不考虑边界框(boundingboxes),忽略了建议框的坐标也是网络的输出.
这两种算法主要推荐第二种方法,因为"EndtoEnd"使用的显存小,而且训练更快,同时准确率略高于alt-opt算法,实验也将会对比两种算法的测试效果.
本文主要将深度学习FasterR-CNN应用到家庭服务机器人平台,通过竞赛和实际实验得出了将深度学习算法应用服务机器人的可行性和有效性,并且识别效果要强于传统方法.
1物品识别算法1.
1FastR-CNN算法虽然R-CNN使用了选择性搜索等预处理步骤来提取潜在的boundingbox作为输入,但是R-CNN仍会有严重的速度瓶颈.
原因也很明显,就是计算机对所有区域进行特征提取时会有重复计算.
FastR-CNN正是为了解决这个问题诞生的.
FastR-CNN算法解决了R-CNN算法的三个问题:a)测试速度慢.
FastR-CNN解决方法:FastR-CNN将整张图像归一化后直接送入CNN.
在最后的卷积层输出的特征图上,加入建议框信息,使得在此之前的CNN运算得以共享.
b)训练速度慢.
FastR-CNN解决方法:FastR-CNN在训练时,只需要将一张图像送入网络,每张图像一次性提取CNN特征和建议区域,训练数据在GPU内存里直接进Loss层,这样候选区域的前几层特征不需要再重复计算,并且不再需要把大量数据存储在硬盘上.
c)训练所需空间大.
FastR-CNN解决方法:FastR-CNN把类别判断和位置回归统一用深度网络实现,不再需要额外存储.
FastR-CNN模型同样采用CNN的结构.
图1为CNN的传统架构.
采样层交替插入在卷积层中,这样图像在经过卷积层chinaXiv:201808.
00076v1ChinaXiv合作期刊录用稿石杰,等:基于FasterR-CNN的服务机器人物品识别研究后所提取的特征,再经过筛选组合形成新的特征图,这个特征图是对原始图片更抽象的描述,最后把这些更加抽象的参数归一化成计算更加方便的一维数组,就形成全链接层,通过得分函数进行物品的分类、检测.
图1CNN网络架构1.
2FasterR-CNN算法FasterR-CNN的一大特点是利用RPN,其经过训练可以直接预测出建议框,比选择性搜索预测所提取的预测框数量更少、速度更快,且RPN的预测绝大部分在GPU中完成,同时卷积网和FastR-CNN部分共享,这些对于提升物品检测速度起到至关重要的作用.
FasterR-CNN不同于其他分类检测网络的两个关键点是:a)使用区域推荐网络替代原有的选择性搜索方法产生建议窗口;b)产生建议窗口的卷积神经网络和目标检测的卷积神经网络的共享.
FasterR-CNN的整体框架大致为:FasterR-CNN把整张图片输入CNN,进行特征提取生成区域推荐窗口,FasterR-CNN用区域推荐窗口生成建议窗口,对于输入的每一张图片都会生成300个建议窗口;FasterR-CNN把建议窗口映射到ROI生成的最后一层特征图上;利用SoftmaxLoss和SmoothL1Loss对分类概率和边框回归(boundingboxregression)联合训练.
图2是FasterR-CNN网络结构.
图2FasterR-CNN网络结构1.
2.
1区域推荐网络(RPN)为了将一个物体可以在不同尺寸下识别出来,有两种主要方式:a)对输入进行裁剪;b)对特征图进行不同大小的滑框卷积运算.
而区域推荐网络采取了不同的方式.
RPN的输入是任意大小的图像,输出是一组打过分的候选框.
RPN的核心思想是使用卷积神经网络直接产生建议区域,使用的方法本质就是滑动窗口,并且只需要在最后的卷积层上滑动一遍,在每一个滑动窗口的位置,同时预测k个区域推荐,所以回归层有4k个输出,k个box的坐标编码;分类层输出2k个得分.
生成训练数据的过程为:先检查anchor覆盖目标的真正区域(groundtruth)是否超过75%,如查超过就将当前anchor的目标分类标记为"存在";如果没有超过就选择一个覆盖比例最大的标记为"存在",即对每个建议框是目标/非目标的估计概率.
因为anchor机制和边框回归可以得到多尺度长宽比的RPN网络也是全卷积网络(fully-convolutionalnetwork,FCN[16]),可以针对生成检测建议框的任务端对端地训练,能够预测出物体的边界和分数,只是在CNN上额外增加了2个卷积层(全卷积层cls和reg).
一般为了应对尺寸迥异的物体,FasterR-CNN应用了3种长宽比类型不同的Anchor,即1:1、2:1、1:2.
再将这3种Anchor分别用3个尺度缩放,即128、256、512,共9种类型的Anchorboxes.
这9种窗口在卷积特征图上经过卷积运算形成256维向量(FasterR-CNN有三种训练模式,即ZF[17]、VGG[18]、VGG16.
这里的256维针对的是ZF模型,VGG模型需要形成512维的向量),最后挑选出得分最高的300个窗口作为最终的建议窗口.
RPN模型网络结构如图3所示.
图3RPN模型网络结构RPN的目标函数是分类和回归损失的和.
根据文献[19]分类采用了交叉熵,回归采用了稳定的SmoothL1,公式为(1)整体的损失函数具体为(2)在式(2)中,i是一个mini-batch中anchor的索引;是i作为一个目标的anchor的预测概率.
如果这个anchor为正,则ground-truth的标签就为1;如果这个anchor为负,则就为0.
表示预测边界框的4个参数化坐标的矢量,并且是与anchor相关联的ground-truth的矢量.
chinaXiv:201808.
00076v1ChinaXiv合作期刊录用稿石杰,等:基于FasterR-CNN的服务机器人物品识别研究RPN中分类损失函数为(3)对于边界回归框,本文采用以下4个坐标的参数公式:(4)其中:、y、w和h表示框的中心坐标及其宽度和高度;变量、、分别代表预测框、anchor框和ground-truth(同样用于y、w、h).
这可以被认为是从一个anchor框到附近的ground-truth的边界回归框.
1.
2.
2训练RPN网络RPN网络一般通过方向传播和随机梯度下降(stochasticgradientdescent,SGD)方法来进行端对端训练.
本文遵循"以图像为中心"的采样策略来训练这个网络.
每个mini-batch包含很多正、负样本anchor的单个图像.
对所有anchor的损失函数进行优化是可能的,但是使优化结果偏向于负样本,因为它们是占据主导地位的.
相反,本文在图像中随机采样256个anchor,以计算mini-batch的损失函数,取样的正负样本比例高达1:1.
如果图像中的正样本少于128个,则使用负样本来填充mini-batch.
2实验研究2.
1实验平台图4是北京信息科技大学家庭服务机器人团队的Sun@Home机器人.
图4Sun@Home家庭服务机器人本实验平台主要由一个kinectⅡ代摄像头[20]、可调升降机构、3自由度机械臂、全向轮底盘和一个检测范围为270°的激光雷达组成.
本次实验使用到的传感器装置是kinectⅡ代代摄像头.
相比于第一代kinect,第二代kinect感应器具备了更高的分辨率和色彩识别度,使识别更加精准.
其彩色摄像头分辨率为1920*1080;深度感知器分辨率为512*424;帧率为30fps;检测范围为0.
5~4.
5m.
同时其拍摄的高清图片可提高算法对物品定位、识别的精度和准确度.
2.
2数据集由于FasterR-CNN官方使用的是1000类ImageNet数据集,在分类检测时有比较高的准确率和较好的识别效果,所以本次实验使用官方的预训练模型对重新制作的VOC数据集进行微调,这样在不用采集千万张图片基础上也可以得到较为稳定的参数.
1)数据集的采集与制作由于机器人自身带有kinect传感器,所以使用kinect对10类目标物品进行录制,并分解成2010张JPG图片,Labels共有2010个XML文件.
训练集和训练验证集共有总图片的90%,即1809张;测试集和验证集共有总图片的10%,即201张.
最后将XML文件,训练集、测试集、验证集,图片分别放入Annotation、ImageSets下的Main、JPEGImages中,最终制作成VOC2007数据集.
图5为机器人采集数据的实际场景.
图5机器人采集数据的实际场景2)数据集的具体内容可乐(cola)、牛奶(milk)、酸奶(yoghourt)、牙膏(toothpaste)、咖啡(coffee)、绿茶(tea)、沐浴露(bath)、洗发水(shampoo)、水(water)、香皂(soap).
3)数据集的训练平台考虑到服务机器人的硬件设计没有加入高性能GPU,训练使用的服务器配置是:因特尔酷睿i7-6700KCPU4000GHz*8,GeforceGTX1080,ubuntu14.
0464-bit,硬盘SSD256GB.
同时训练不同的模型所用的时间也不同.
2.
3提取特征图FasterR-CNN特征提取的核心是CNN,它会学习到物品的颜色、形状、纹理等特征,同时也学习到背景,利用Caffe的可视化方法可以直观地看到目标的关键信息.
图6是各卷积层提取的特征图.
其中conv1和conv2对浅层特征的提取,如物品的颜色、边缘等;conv3提取到目标的纹理特征;conv4、conv5提取到更为关键的特征.
而图7是池化层对特征的精提取.
从chinaXiv:201808.
00076v1ChinaXiv合作期刊录用稿石杰,等:基于FasterR-CNN的服务机器人物品识别研究图中可以看出物品的关键信息更加明显.
图6各卷积层提取特征图图7池化层对特征的精提取2.
4实验结果与分析本实验中误检测为检测到物品但错误地识别;漏检测为未检测到物品.
1)FasterR-CNN与FastR-CNN实验对比在本实验中采用了FasterR-CNN算法,并与FastR-CNN的实验效果进行了对比.
由于FasterR-CNN多训练了RPN网络,所以在识别准确率上有很大的不同.
对于RPN网络的训练,同样采用预训练模型对RPN微调的方法,将RPN训练得到的候选框训练FastR-CNN网络;将FastR-CNN网络训练得到的参数固定卷积层微调RPN;随后在固定FastR-CNN卷积层的前提下,通过RPN训练得到的候选框对FastR-CNN进行微调;重复上述步骤,直到网络收敛.
测试实验图中物品摆放的原则是:尽可能将外形、颜色相近的物品摆放在一起;同品牌的物品摆放间隔尽可能大.
同时物品间的距离对最终的测试结果有一定影响.
图8是实际测试场景图,包含了所有数据集中的物品.
测试结果预期目标:正确地定位识别出所有物品.
图9是FastR-CNN识别效果.
图10是FasterR-CNN识别效果.
从图中可以看出,将两种算法分别应用在机器人平台中得到的检测结果大不相同.
由图10可见,机器人使用FastR-CNN算法,正确地识别出咖啡、绿茶、沐浴露、牛奶、可乐、洗发水,但将酸奶误识别成牛奶和未识别出香皂,这可能是由于酸奶和奶有相似的颜色和外形特征,香皂与背景的颜色相近并且目标较小,在提取其特征时会得到不明显的特征,所以造成未识别.
而由图11可看到,机器人使用FasterR-CNN算法可以正确地定位、识别出所有物品.
FastR-CNN网络对于物品识别的效果以及准确率都没有FasterR-CNN网络好,FastR-CNN网络出现误检测和漏检测,而FasterR-CNN网络将物品全部识别准确.
图8测试场景图图9FastR-CNN识别效果图10FasterR-CNN识别效果再加载其他测试图继续进行误检、漏检实验.
实验物品主要包括奶茶、一次性纸杯、香皂、纸卷,其中只有香皂是数据集中的物品,奶茶、一次性纸杯、纸卷不是数据集中物品.
测试结果预期目标:只定位识别出香皂,其他物品不识别.
图11为FastR-CNN测试图.
图12为FasterR-CNN测试图.
图11FastR-CNN测试图图12FasterR-CNN测试图选取该四件物品作为误检、漏检测试的原因是:奶茶、一次性纸杯、纸卷的形状与颜色和训练数据集中的物品,像奶、酸奶、香皂等,有很高的相似度.
对比图11和12的实验结果可以看出,FastR-CNN能够正chinaXiv:201808.
00076v1ChinaXiv合作期刊录用稿石杰,等:基于FasterR-CNN的服务机器人物品识别研究确地识别出香皂,但将纸卷同样识别成香皂,并且置信度(即准确度)只有74.
2%,造成这个结果的原因是FastR-CNN在测试时提取到纸卷和香皂具有相同的颜色、纹理特征.
而FasterR-CNN可以正确地识别出香皂,同时不会造成误检.
两种算法都不会误检奶茶、一次性纸杯.
下一步选取多件物品,其中只有一件不是训练数据集中的物品,同时实验测试角度,与数据集中部分物品采集样本的角度有些差别,即实验两种算法的环境适应性.
实验物品包括香皂、沐浴露、咖啡(两种)、奶茶、洗发水,其中除奶茶外,剩余物品全部是数据集中的物品.
测试结果预期目标:除奶茶外,正确地定位识别所有物品.
图13为FastR-CNN测试图.
图14为FasterR-CNN测试图.
图13FastR-CNN测试图图14FasterR-CNN测试图对比图13和14的实验结果可以发现,两种算法都能够正确地识别出部分训练数据集中的物品,但将罐装咖啡误识别成可乐.
经过多次实验发现,在该角度下两种算法提取到的罐装咖啡与可乐有部分相似的特征,数据集中罐装可乐没有该角度下的样本,而可乐有多角度的样本,同时在该光照下的罐装咖啡的颜色特征与可乐的颜色特征相似,因此造成此类识别结果.
所以,机器人控制kinect拍摄图片的角度与数据集中的物品拍摄角度应高度相似,即对样本进行尺度变换和增强,这对算法在识别过程中提取非常突出的物品特征和对物品的定位、识别有重要的作用.
最后改变实验图片采集的角度,分别使用FastR-CNN和FasterR-CNN两种算法对多张不同角度的图片进行测试.
通过大量实验结果可以得出,FastR-CNN和FasterR-CNN测试实验结果都并不非常理想.
FastR-CNN能够正确地识别数据集中的部分物品;而FasterR-CNN除了能够正确地识别出数据集中的物品外,对非数据集中的物品产生了误检.
造成上述两个实验结果的原因在于机器人拍摄物品的角度与训练数据集中物品拍摄角度不同,所以可适当地增加训练数据,对图片进行尺度变换,通过数据增强的方式,弥补机器人平台采集数据的劣势.
最后结合上述实验结果和其他测试图片的实验结果,将FastR-CNN和FasterR-CNN网络在家庭服务机器人竞赛中的各项参数统计在表1中.
表1FastR-CNNFasterR-CNN参数对比算法mAP训练耗时测试耗时误检率漏检率FastR-CNN75%约10h2.
1s20%5%FasterR-CNN90%约14h1.
5s6%4%由表1分析可得,FastR-CNN检测准确率在75%左右,训练耗时约10h,测试耗时2.
1s左右,误检率20%,漏检率5%;FasterR-CNN检测准确率在90%左右,训练耗时约14h,测试耗时1.
5s左右,误检率6%,漏检率4%.
由于训练方式的不同,FasterR-CNN多训练一个RPN网络,所以训练耗时要比FastR-CNN略长.
考虑到开发成本较高和服务机器人的内部空间不足等问题,虽然在耗时上两者都没有达到实时的级别,但FasterR-CNN的测试耗时明显低于FastR-CNN.
分析原因是FasterR-CNN使用卷积网络自行产生建议框,并且和目标检测网络共享卷积网络,使得建议框数目从原有的约2000个减少为300个,且建议框的质量也有很大的提高.
2)EndtoEnd训练方法与alt-opt训练方法对比FasterR-CNN提供了两种不同的训练算法,两种方法都会得到优于FastR-CNN的检测效果.
首先对多目标进行实验.
机器人拍摄到角度正常的测试图片,为了增加实验难度,选择的实验物品有相似的形状特征、颜色特征,且会出现非数据集中的物品.
通过多次实验可以得出以下结论:在服务机器人平台拍摄的测试图片角度正常的情况下,机器人使用FasterR-CNN中的alt-opt算法检测的准确率接近EndtoEnd检测的准确率,在对正常角度图片测试时,EndtoEnd算法可以正确地定位识别出数据集中的物品,同时不会检测非数据集物品.
为了进一步检测算法效果,下一步将测试非正常角度的物品.
实验物品包括洗发水、洁面乳、瓶装咖啡.
三种物品有相似的轮廓,但在两种算法中得出了不同的结果,其中洗发水和瓶装咖啡是数据集中的物品,洁面乳不是数据集中的物品.
测试结果预期目标:可以正确地定位识别出洗发水和瓶装咖啡,不会识别洁面乳.
图15为alt-opt训练方法测试图.
图16为EndtoEnd训练方法测试图.
图15alt-opt训练方法测试图chinaXiv:201808.
00076v1ChinaXiv合作期刊录用稿石杰,等:基于FasterR-CNN的服务机器人物品识别研究图16EndtoEnd训练方法测试图通过多次实验可以看出,图15使用alt-opt训练方法得到的模型正确地将洗发水和瓶装咖啡识别出来,但出现了误检测,洁面乳被识别成咖啡.
出现这种结果的原因很可能是洁面乳和瓶装咖啡有相似的暗色和轮廓,在特征提取时得到了近似的特征.
而图16是使用EndtoEnd方法测试的结果,该方法训练的模型正确地检测到洗发水和瓶装咖啡,没有出现误检测.
同时EndtoEnd算法检测时间较alt-op算法检测时间略快,这是由于alt-opt算法在训练模型过程中分四个阶段,EndtoEnd算法不分阶段,所以alt-opt算法较EndtoEnd算法产生更多的权重值.
综上所述,对于本实验平台,EndtoEnd方法更适用.
综合两种训练算法,表2为多次实验测试结果的参数.
表2alt-opt与EndtoEnd参数对比算法mAP训练耗时测试耗时误检率漏检率alt-opt89%约14h1.
6s6%5%EndtoEnd90%约11h1.
5s5%4%由表2分析可得,alt-opt检测准确率在89%左右,训练耗时约14h,测试耗时1.
6s左右,误检率6%,漏检率5%;EndtoEnd检测准确率在90%左右,训练耗时约11h,测试耗时1.
5s左右,误检率5%,漏检率4%.
由于alt-opt算法训练分为四个阶段,每个阶段在训练完后都会进行模型检测,所以在训练过程中耗时更多.
在检测速度、误检率和漏检率方面,EndtoEnd训练方法略胜一筹.
而EndtoEnd算法在测试时占用的内存较alt-opt算法小,因此检测速度更快.
分析实验结果:目标检测网络中,在特定场景下,FasterR-CNN的网络检测性能要优于FastR-CNN;对于本实验平台应用的FasterR-CNN算法中,EndtoEnd训练方法要略优于alt-opt算法.
在实际测试中,机器人使用FasterR-CNN能够识别出更多的物品.
同时,适当地增加样本集中物品的数量会对最终检测结果有更好影响,多卷积层可提取更多的物品特征,保证识别准确率.
3结束语近年来随着人工智能技术的飞速发展,传统的物品识别方法不仅效率低、检测速度慢,而且误检率和漏检率高.
然而深度学习的方法将物品特征交给神经网络去提取,通过反向传播算法与正向传播构成反馈自动地调整学习到的参数,避免了单个算法在识别过程中的劣势,很大程度上解决了这些问题.
本文利用深度学习中识别效果较好的FasterR-CNN算法,将物品识别方法转向将深度学习应用到家庭服务机器人平台,通过选择适用于实验平台的训练算法实现机器人自主识别物品并提高准确率.
通过实验和竞赛结果对比发现,FasterR-CNN算法应用在服务机器人可达到90%的识别准确率.
考虑到服务机器人平台的造价和内部空间的前提下,本次实验未配置GPU,因此所有实验结果均是在CPU上得到,在CPU上运行EndtoEnd训练方法的检测速率在1.
5s左右,运行alt-opt训练方法的检测速率在1.
6s左右,准确率均在90%左右,相比传统图像识别算法,深度学习更胜一筹.
因此采用FasterR-CNN加EndtoEnd训练算法更适用于服务机器人平台.
但是该方法对于光线有一定的要求,如果光线过暗,机器人拍摄的图片可能无法进行正常的识别.
经过多次实验发现,较小目标的识别也有一定困难.
考虑到GPU对算法运行的速率和准确性,团队最终会依据硬件平台加入适用版本的GPU.
同时,实时性也是工业级机器人发展的方向.
对于这些问题,Sun@Home物品识别团队将会继续开发和深入研究.
参考文献:[1]宋欢欢.
复杂场景下背景建模方法的研究与实现[D].
南昌:南昌大学,2015.
(SongHuanhuan.
Reseearchandimplementationofbackgroundmodelingmethodundercomplexscene[D].
Nanchang:NanchangUniversity,2015.
)[2]TaigmanY,YangMing,RanzatoMA,etal.
Deepface:closingthegaptohuman-levelperformanceinfaceverification[C]//ProcofIEEEConferenceonComputerVisionandPatternRecognition.
[S.
l.
]:IEEEPress,2014:1701-1708.
[3]潘威,左欣,沈构强,等.
物品识别系统的设计与实现[J].
科技视界,2015(5):167.
(PanWei,ZuoXin,ShenGouqiang,etal.
Thedesignandimplementationofitemidentificationsystem[J].
Science&TechnologyVision,2015(5):167.
)[4]林汀.
图像特征点匹配算法的研究[J].
现代计算机:专业版,2016(10):28-32.
(LinTing.
Researchonfeaturepointsmatchingalgorithmsequenceimage[J].
ModernComputer,2016(10):28-32.
)[5]胡修祥.
基于RGB-D数据的物品识别与定位[D].
天津:中国民航大学,2016.
(HuXiuxiang.
ObjeectrecongnitionandlocalizationbasedonRGB-Ddata[D].
Tianjin:CivilAviationUniversityofChina,2016.
)[6]ViolaP,JonesMJ.
Robustreal-timefacedetection[J].
InternationalJournalofComputerVision,2004,57(2):137-154.
[7]史东承,倪康.
压缩感知W-HOG特征的运动手势跟踪[J].
智能系统学报,2016,11(1):124-128.
(ShiDongcheng,NiKang.
MotiongesturetrackingbasedoncompressedsensingW-HOGfeatures[J].
CAAITransonIntelligentSystems,2016,11(1):124-128.
)[8]SermanetP,EigenD,ZhangX,etal.
OverFeat:integratedrecognition,localizationanddetectionusingconvolutionalnetworks.
[C]//AdvancesinNeuralInformationProcessingSystems.
[S.
l.
]:ICLRPress,2014:1055-1061.
chinaXiv:201808.
00076v1ChinaXiv合作期刊录用稿石杰,等:基于FasterR-CNN的服务机器人物品识别研究[9]GirshickR,DonahueJ,DarrellT,etal.
Richfeaturehierarchiesforaccurateobjectdetectionandsemanticsegmentation[C]//ProcofImageNetLarge-ScaleVisualRecognitionChallengeWorkshop.
[S.
l.
]:ICCVPress,2013:10-15.
[10]GirshickR,DonahueJ,DarrellT,etal.
Richfeaturehierarchiesforaccurateobjectdetectionandsemanticsegmentation[C]//ProcofImageNetLarge-ScaleVisualRecognitionChallengeWorkshop.
[S.
l.
]:ICCVPress,2013:10-15.
[11]KazemiFM,SamadiS,PoorrezaHR,etal.
VehiclerecognitionusingcurvelettransformandSVM[C]//Procofthe4thInternationalConferenceonInformationTechnology.
[S.
l.
]:IEEEPress,2007:516-521.
[12]GirshickR.
FastR-CNN[C]//ProcofIEEEInternationalConferenceonComputerVision.
[S.
l.
]:ICCVPress,2015:10-15.
[13]RenS,HeK,GirshickR,etal.
FasterR-CNN:towardsreal-timeobjectdetectionwithregionproposalnetworks[C]//ProcofConferenceonNeuralInformationProcessingSystems.
[S.
l.
]:NIPSPress,2015:1-15.
[14]FelzenszwalbPF,GirshickRB,McAllesterD,etal.
Objectdetectionwithdiscriminativelytrainedpart-basedmodels[C]//ProcofIEEETransactionsonPatternAnalysisandMachineIntelligence.
[S.
l.
]:TPAMIPress,2010:201-205.
[15]LongJ,ShelhamerE,DarrellT.
Fullyconvolutionalnetworksforsemanticsegmentation[C]//ProcofIEEEConferenceonComputerVisionandPatternRecognition.
2015.
[16]ZeilerMD,FergusR.
Visualizingandunderstandingconvolutionalneuralnetworks[C]//ProcofEuropeanConferenceonComputerVision.
2014.
[17]万士宁.
基于卷积神经网络的人脸识别研究与实现[D].
成都:电子科技大学,2016.
(WanShining.
Researchandimplementationoffacerecongnitionbasedonconvolutionneturalnetwork[D].
Chengdu:UniversityofElectronicScienceandTechnologyofChina,2016.
)[18]宋焕生,张向清,郑宝峰,等.
基于深度学习方法的复杂场景下车辆目标检测[J].
计算机应用研究,2018,35(4):1270-1273.
(SongHuansheng,ZhangXiangqing,ZhengBaofeng,etal.
Vehicledetectionbasedondeeplearningincomplexscene[J].
ApplicationResearchofComputers,2018,35(4):1270-1273.
)[19]沈莉丽.
基于Kinect视觉识别的智能居家机器人系统[J].
组合机床与自动化加工技术,2017(12):78-80,84.
(ShenLili.
Intelligenthomerobotcontrolsystembasedonthevisualidentitybykinect[J].
ModularMachineTool&AutomaticManufacturingTechnique,2017(12):75-80,84.
)chinaXiv:201808.
00076v1ChinaXiv合作期刊
edu.
cn).
;张奇志(1963-),男,辽宁阜新人,教授,博士,主要研究方向为机器人控制.
基于FasterR-CNN的服务机器人物品识别研究*石杰,周亚丽,张奇志(北京信息科技大学自动化学院,北京100192)摘要:随着机器人在服务行业中的应用推广,尤其在家庭服务中有着重要的作用,对服务机器人的信息采集或目标识别需求也越来越强烈.
传统的日用商品识别流程通常使用较为经典的图像识别和机器学习算法,如支持向量机(SVM)、随机森林或Adaboost,然后利用目标图像的梯度、纹理或颜色的基本特征来对日用商品进行识别,可以在比较简单的背景中得到应用,但是在复杂的背景环境中很难有比较突出的表现,并且难以达到较高的准确率.
目前在目标识别中表现比较优异的是卷积神经网络(CNN),并成为很多目标识别场景中的首选.
考虑到服务机器人的硬件配置成本,将基于区域的卷积神经网络(R-CNN)的快速算法FasterR-CNN引入系统中,并以CPU计算的方式进行物品识别.
利用CNN网络提取图像特征,在其后面接入一个区域提议层.
实验结果表明,将深度学习的识别方法应用到服务机器人平台是可行的,识别效果准确,且在实验中得到较好的检测效果.
关键词:服务机器人;深度学习;FasterR-CNN;物品识别中图分类号:TP391.
4doi:10.
3969/j.
issn.
1001-3695.
2018.
03.
0311ItemrecongnitionbasedonfasterR-CNNinservicerobotShiJi,ZhouYali,ZhangQizhi(SchoolofAutomation,BeijingInformationScience&TechnologyUniversity,Beijing100192,China)Abstract:Withthepromotionandapplicationofrobotsintheserviceindustry,especiallyinthefamilyservice,thedemandforinformationcollectionortargetrecognitionforservicerobotsisalsogettingstrongerandstronger.
Traditionalcommodityrecognitionprocessestypicallyusethemoreclassicimagerecognitionandmachinelearningalgorithmssuchassupportvectormachines(SVM),randomforestoradaboost,thenusethebasiccharacteristicsofthegradient,textureorcolorofthetargetimage.
Itcanbeappliedinarelativelysimplebackground,butitishardtohaveamoreprominentperformanceinacomplicatedbackgroundenvironment,anditisdifficulttoachieveahighaccuracy.
Atpresent,theconvolutionneuralnetwork(CNN),whichissuperiorintargetrecognition,hasbecomethefirstchoiceinmanytargetrecognitionscenarios.
Consideringthehardwareconfigurationcostofservicerobot,FasterR-CNN,afastalgorithmofregion-basedconvolutionalneuralnetwork(R-CNN),isintroducedintothesystemandidentifiedbyCPU.
TheCNNnetworkisusedtoextractimagefeaturesandaccesstoaregionalproposallayerbehindit.
Theexperimentalresultsshowthatitisfeasibletoapplythedeeplearningrecognitionmethodtotheservicerobotplatform.
Therecognitioneffectisaccurateandthetestresultsaregood.
Keywords:servicerobot;deeplearning;FasterR-CNN;commodityrecognition0引言近年来,随着机器人行业的迅猛发展,服务型机器人开始进入大众视野,而人工智能相关技术的快速发展使得服务机器人得到了越来越多的技术支持.
服务机器人具有非常广泛的应用前景,其发展是实现自动化服务的重要一步.
同时,日用商品识别是智能服务行业的一个基础的研究问题,也是用于采集和分析超市日用商品大数据信息的前提和基础.
在服务机器人平台实现物品识别是未来行业发展的重要趋势.
一方面,服务机器人具有较为完善的硬件基础,可以完成基础的任务,功能强大;另一方面,深度学习在识别领域不仅能够完成多目标识别任务,还有很高的准确率.
物体检测识别依赖于计算机视觉的发展,一直以来是图像工程领域重要的研究热点.
但由于技术发展的落后、大众对物体识别的认知度不强和算法应用场景的限制,物体检测真正快速的发展起始于20世纪90年代.
人的肉眼通过视野内物体的chinaXiv:201808.
00076v1ChinaXiv合作期刊录用稿石杰,等:基于FasterR-CNN的服务机器人物品识别研究纹理特征、颜色特征、深度信息等,定位、识别目标物体非常简单.
然而计算机在处理图像时,面对的是数值化的三通道矩阵(即RGB矩阵),难以直接得到货架、物品这种抽象的概念,再加上图片背景的复杂度、物品摆放姿态的多样性和不同的光照强度等其他外界干扰因素,使得物体检测更加困难.
与传统的物品识别检测相比,服务机器人采集的图像具有背景更为复杂、采集现场光亮强度不一、识别目标距离的远近、相同物品不同形状等难题.
传统的物品识别方法主要采用基本图像处理方法,如背景建模[1]、HOG[2](histogramoforientedgridients)、K-means聚类算法[3]、特征点匹配算法[4]、加速稳健特征(speededuprobustfeatures,SURF)[5]等.
在传统的目标检测方法中,2001年Viola等人在论文"鲁棒实时目标检测"中提出的Viola-Jones框架[6]得到了广泛的关注.
这种方法速度快、相对简单,傻瓜相机的实时脸部检测就是使用这种算法,它的运算量很小.
它使用Harr特征[7]来生成不同的简单的二分类,这些分类被级联的多尺度滑动窗口来处理,并且会及时丢弃错误分类.
深度学习作为机器学习领域的延伸已经众人皆知了,尤其在计算机视觉领域.
与深度学习模型在图像分类领域优于传统模型类似,深度学习现在也是目标检测领域中最好的方法.
过去几年深度学习目标检测方法有了很大的进步,纽约大学的研究人员在2013年提出了Overfeat[8],并在目标检测领域取得很大进展,他们提出了一种使用卷积的多尺度滑动窗口算法.
在Overfea提出不久,伯克利大学的Girshick等人[9]提出了基于区域的卷积特征(region-basedconvolutionalneuralnetwork,R-CNN)算法,这也是深度学习在目标检测领域的重大突破,该算法在目标检测效果上相比传统方法取得了50%的性能提升.
R-CNN提出了一个三阶段的方法:a)使用区域提议方法提取可能目标,现在流行的方法是选择性搜索(selectivesearch)[10];b)使用卷积神经网络(convolutionneuralnetwork,CNN)在区域上提取特征;c)使用支持向量机(supportvectormachine,SVM)[11]对区域进行分类.
虽然R-CNN在当时目标检测领域取得了非常不错的成绩,但是在训练过程中有很多问题.
首先需要生成训练集的建议区域,然后在每个区域使用CNN特征提取器来提取特征,最后训练SVM分类器.
这个过程需要消耗大量的时间.
在2015年Girshick[12]发表了FastR-CNN,这种方法迅速进化成一个纯深度学习方法.
与R-CNN相似,它使用选择性搜索来生成区域建议;但与R-CNN不同的是,FastR-CNN在整张图上使用CNN来提取特征,然后在特征图上使用区域兴趣池化(regionofinterest,ROI),最后是一个反向传播网络来做分类和边框回归.
这种方法不仅快,而且因为区域兴趣池化层和全连接层,该模型可以进行端对端的差分,训练也很容易.
最大的不足是该模型仍旧依赖于选择性搜索,这也成为了模型推理阶段的一个瓶颈.
随后,Ren等人[13]发表了FasterR-CNN,这是R-CNN系列的第三个迭代.
FasterR-CNN增加了一个区域建议网络(regionproposalnetwork,RPN)[14],试图摆脱选择性搜索算法,从而让模型实现完全端对端的训练.
RPN的作用是根据"物体"的分数来输出可能目标.
这些目标区域被后面的ROI池化和全链接层来做分类.
随着深度学习在近些年的爆炸性发展和机器人在服务行业的广泛应用,本文在上述成果的基础上,将深度学习的方法应用到智能服务机器人平台.
考虑到识别准确率和识别时间,本文主要利用FasterR-CNN作为目标检测算法,硬件平台采用自主研发的服务机器人.
该机器人具有路径规划、行人跟踪、物体抓取、自主导航等功能.
本文实现的是机器人自主识别物品,为未来实现自主抓取、导航打下基础.
FasterR-CNN主要有两种训练模式,一种是2015年NIPS中的"alternatingoptimization"(alt-opt)[15]方法,它的训练特点是迭代,先训练RPN,随后用建议框去训练FastR-CNN,被FastR-CNN微调的网络用来初始化RPN,以此迭代;另一种是"EndtoEnd",其训练特点是将RPN和FastR-CNN融合到一个网络中进行训练,在每次随机梯度下降(SGD)迭代过程中,前向传递时RPN产生区域建议框,这些建议框被当做固定的、提前计算好的建议框来训练FastR-CNN检测器.
反向传递时,对于共享层来说,来自RPN的损失函数与FastR-CNN的损失函数结合.
但是这种方法不考虑边界框(boundingboxes),忽略了建议框的坐标也是网络的输出.
这两种算法主要推荐第二种方法,因为"EndtoEnd"使用的显存小,而且训练更快,同时准确率略高于alt-opt算法,实验也将会对比两种算法的测试效果.
本文主要将深度学习FasterR-CNN应用到家庭服务机器人平台,通过竞赛和实际实验得出了将深度学习算法应用服务机器人的可行性和有效性,并且识别效果要强于传统方法.
1物品识别算法1.
1FastR-CNN算法虽然R-CNN使用了选择性搜索等预处理步骤来提取潜在的boundingbox作为输入,但是R-CNN仍会有严重的速度瓶颈.
原因也很明显,就是计算机对所有区域进行特征提取时会有重复计算.
FastR-CNN正是为了解决这个问题诞生的.
FastR-CNN算法解决了R-CNN算法的三个问题:a)测试速度慢.
FastR-CNN解决方法:FastR-CNN将整张图像归一化后直接送入CNN.
在最后的卷积层输出的特征图上,加入建议框信息,使得在此之前的CNN运算得以共享.
b)训练速度慢.
FastR-CNN解决方法:FastR-CNN在训练时,只需要将一张图像送入网络,每张图像一次性提取CNN特征和建议区域,训练数据在GPU内存里直接进Loss层,这样候选区域的前几层特征不需要再重复计算,并且不再需要把大量数据存储在硬盘上.
c)训练所需空间大.
FastR-CNN解决方法:FastR-CNN把类别判断和位置回归统一用深度网络实现,不再需要额外存储.
FastR-CNN模型同样采用CNN的结构.
图1为CNN的传统架构.
采样层交替插入在卷积层中,这样图像在经过卷积层chinaXiv:201808.
00076v1ChinaXiv合作期刊录用稿石杰,等:基于FasterR-CNN的服务机器人物品识别研究后所提取的特征,再经过筛选组合形成新的特征图,这个特征图是对原始图片更抽象的描述,最后把这些更加抽象的参数归一化成计算更加方便的一维数组,就形成全链接层,通过得分函数进行物品的分类、检测.
图1CNN网络架构1.
2FasterR-CNN算法FasterR-CNN的一大特点是利用RPN,其经过训练可以直接预测出建议框,比选择性搜索预测所提取的预测框数量更少、速度更快,且RPN的预测绝大部分在GPU中完成,同时卷积网和FastR-CNN部分共享,这些对于提升物品检测速度起到至关重要的作用.
FasterR-CNN不同于其他分类检测网络的两个关键点是:a)使用区域推荐网络替代原有的选择性搜索方法产生建议窗口;b)产生建议窗口的卷积神经网络和目标检测的卷积神经网络的共享.
FasterR-CNN的整体框架大致为:FasterR-CNN把整张图片输入CNN,进行特征提取生成区域推荐窗口,FasterR-CNN用区域推荐窗口生成建议窗口,对于输入的每一张图片都会生成300个建议窗口;FasterR-CNN把建议窗口映射到ROI生成的最后一层特征图上;利用SoftmaxLoss和SmoothL1Loss对分类概率和边框回归(boundingboxregression)联合训练.
图2是FasterR-CNN网络结构.
图2FasterR-CNN网络结构1.
2.
1区域推荐网络(RPN)为了将一个物体可以在不同尺寸下识别出来,有两种主要方式:a)对输入进行裁剪;b)对特征图进行不同大小的滑框卷积运算.
而区域推荐网络采取了不同的方式.
RPN的输入是任意大小的图像,输出是一组打过分的候选框.
RPN的核心思想是使用卷积神经网络直接产生建议区域,使用的方法本质就是滑动窗口,并且只需要在最后的卷积层上滑动一遍,在每一个滑动窗口的位置,同时预测k个区域推荐,所以回归层有4k个输出,k个box的坐标编码;分类层输出2k个得分.
生成训练数据的过程为:先检查anchor覆盖目标的真正区域(groundtruth)是否超过75%,如查超过就将当前anchor的目标分类标记为"存在";如果没有超过就选择一个覆盖比例最大的标记为"存在",即对每个建议框是目标/非目标的估计概率.
因为anchor机制和边框回归可以得到多尺度长宽比的RPN网络也是全卷积网络(fully-convolutionalnetwork,FCN[16]),可以针对生成检测建议框的任务端对端地训练,能够预测出物体的边界和分数,只是在CNN上额外增加了2个卷积层(全卷积层cls和reg).
一般为了应对尺寸迥异的物体,FasterR-CNN应用了3种长宽比类型不同的Anchor,即1:1、2:1、1:2.
再将这3种Anchor分别用3个尺度缩放,即128、256、512,共9种类型的Anchorboxes.
这9种窗口在卷积特征图上经过卷积运算形成256维向量(FasterR-CNN有三种训练模式,即ZF[17]、VGG[18]、VGG16.
这里的256维针对的是ZF模型,VGG模型需要形成512维的向量),最后挑选出得分最高的300个窗口作为最终的建议窗口.
RPN模型网络结构如图3所示.
图3RPN模型网络结构RPN的目标函数是分类和回归损失的和.
根据文献[19]分类采用了交叉熵,回归采用了稳定的SmoothL1,公式为(1)整体的损失函数具体为(2)在式(2)中,i是一个mini-batch中anchor的索引;是i作为一个目标的anchor的预测概率.
如果这个anchor为正,则ground-truth的标签就为1;如果这个anchor为负,则就为0.
表示预测边界框的4个参数化坐标的矢量,并且是与anchor相关联的ground-truth的矢量.
chinaXiv:201808.
00076v1ChinaXiv合作期刊录用稿石杰,等:基于FasterR-CNN的服务机器人物品识别研究RPN中分类损失函数为(3)对于边界回归框,本文采用以下4个坐标的参数公式:(4)其中:、y、w和h表示框的中心坐标及其宽度和高度;变量、、分别代表预测框、anchor框和ground-truth(同样用于y、w、h).
这可以被认为是从一个anchor框到附近的ground-truth的边界回归框.
1.
2.
2训练RPN网络RPN网络一般通过方向传播和随机梯度下降(stochasticgradientdescent,SGD)方法来进行端对端训练.
本文遵循"以图像为中心"的采样策略来训练这个网络.
每个mini-batch包含很多正、负样本anchor的单个图像.
对所有anchor的损失函数进行优化是可能的,但是使优化结果偏向于负样本,因为它们是占据主导地位的.
相反,本文在图像中随机采样256个anchor,以计算mini-batch的损失函数,取样的正负样本比例高达1:1.
如果图像中的正样本少于128个,则使用负样本来填充mini-batch.
2实验研究2.
1实验平台图4是北京信息科技大学家庭服务机器人团队的Sun@Home机器人.
图4Sun@Home家庭服务机器人本实验平台主要由一个kinectⅡ代摄像头[20]、可调升降机构、3自由度机械臂、全向轮底盘和一个检测范围为270°的激光雷达组成.
本次实验使用到的传感器装置是kinectⅡ代代摄像头.
相比于第一代kinect,第二代kinect感应器具备了更高的分辨率和色彩识别度,使识别更加精准.
其彩色摄像头分辨率为1920*1080;深度感知器分辨率为512*424;帧率为30fps;检测范围为0.
5~4.
5m.
同时其拍摄的高清图片可提高算法对物品定位、识别的精度和准确度.
2.
2数据集由于FasterR-CNN官方使用的是1000类ImageNet数据集,在分类检测时有比较高的准确率和较好的识别效果,所以本次实验使用官方的预训练模型对重新制作的VOC数据集进行微调,这样在不用采集千万张图片基础上也可以得到较为稳定的参数.
1)数据集的采集与制作由于机器人自身带有kinect传感器,所以使用kinect对10类目标物品进行录制,并分解成2010张JPG图片,Labels共有2010个XML文件.
训练集和训练验证集共有总图片的90%,即1809张;测试集和验证集共有总图片的10%,即201张.
最后将XML文件,训练集、测试集、验证集,图片分别放入Annotation、ImageSets下的Main、JPEGImages中,最终制作成VOC2007数据集.
图5为机器人采集数据的实际场景.
图5机器人采集数据的实际场景2)数据集的具体内容可乐(cola)、牛奶(milk)、酸奶(yoghourt)、牙膏(toothpaste)、咖啡(coffee)、绿茶(tea)、沐浴露(bath)、洗发水(shampoo)、水(water)、香皂(soap).
3)数据集的训练平台考虑到服务机器人的硬件设计没有加入高性能GPU,训练使用的服务器配置是:因特尔酷睿i7-6700KCPU4000GHz*8,GeforceGTX1080,ubuntu14.
0464-bit,硬盘SSD256GB.
同时训练不同的模型所用的时间也不同.
2.
3提取特征图FasterR-CNN特征提取的核心是CNN,它会学习到物品的颜色、形状、纹理等特征,同时也学习到背景,利用Caffe的可视化方法可以直观地看到目标的关键信息.
图6是各卷积层提取的特征图.
其中conv1和conv2对浅层特征的提取,如物品的颜色、边缘等;conv3提取到目标的纹理特征;conv4、conv5提取到更为关键的特征.
而图7是池化层对特征的精提取.
从chinaXiv:201808.
00076v1ChinaXiv合作期刊录用稿石杰,等:基于FasterR-CNN的服务机器人物品识别研究图中可以看出物品的关键信息更加明显.
图6各卷积层提取特征图图7池化层对特征的精提取2.
4实验结果与分析本实验中误检测为检测到物品但错误地识别;漏检测为未检测到物品.
1)FasterR-CNN与FastR-CNN实验对比在本实验中采用了FasterR-CNN算法,并与FastR-CNN的实验效果进行了对比.
由于FasterR-CNN多训练了RPN网络,所以在识别准确率上有很大的不同.
对于RPN网络的训练,同样采用预训练模型对RPN微调的方法,将RPN训练得到的候选框训练FastR-CNN网络;将FastR-CNN网络训练得到的参数固定卷积层微调RPN;随后在固定FastR-CNN卷积层的前提下,通过RPN训练得到的候选框对FastR-CNN进行微调;重复上述步骤,直到网络收敛.
测试实验图中物品摆放的原则是:尽可能将外形、颜色相近的物品摆放在一起;同品牌的物品摆放间隔尽可能大.
同时物品间的距离对最终的测试结果有一定影响.
图8是实际测试场景图,包含了所有数据集中的物品.
测试结果预期目标:正确地定位识别出所有物品.
图9是FastR-CNN识别效果.
图10是FasterR-CNN识别效果.
从图中可以看出,将两种算法分别应用在机器人平台中得到的检测结果大不相同.
由图10可见,机器人使用FastR-CNN算法,正确地识别出咖啡、绿茶、沐浴露、牛奶、可乐、洗发水,但将酸奶误识别成牛奶和未识别出香皂,这可能是由于酸奶和奶有相似的颜色和外形特征,香皂与背景的颜色相近并且目标较小,在提取其特征时会得到不明显的特征,所以造成未识别.
而由图11可看到,机器人使用FasterR-CNN算法可以正确地定位、识别出所有物品.
FastR-CNN网络对于物品识别的效果以及准确率都没有FasterR-CNN网络好,FastR-CNN网络出现误检测和漏检测,而FasterR-CNN网络将物品全部识别准确.
图8测试场景图图9FastR-CNN识别效果图10FasterR-CNN识别效果再加载其他测试图继续进行误检、漏检实验.
实验物品主要包括奶茶、一次性纸杯、香皂、纸卷,其中只有香皂是数据集中的物品,奶茶、一次性纸杯、纸卷不是数据集中物品.
测试结果预期目标:只定位识别出香皂,其他物品不识别.
图11为FastR-CNN测试图.
图12为FasterR-CNN测试图.
图11FastR-CNN测试图图12FasterR-CNN测试图选取该四件物品作为误检、漏检测试的原因是:奶茶、一次性纸杯、纸卷的形状与颜色和训练数据集中的物品,像奶、酸奶、香皂等,有很高的相似度.
对比图11和12的实验结果可以看出,FastR-CNN能够正chinaXiv:201808.
00076v1ChinaXiv合作期刊录用稿石杰,等:基于FasterR-CNN的服务机器人物品识别研究确地识别出香皂,但将纸卷同样识别成香皂,并且置信度(即准确度)只有74.
2%,造成这个结果的原因是FastR-CNN在测试时提取到纸卷和香皂具有相同的颜色、纹理特征.
而FasterR-CNN可以正确地识别出香皂,同时不会造成误检.
两种算法都不会误检奶茶、一次性纸杯.
下一步选取多件物品,其中只有一件不是训练数据集中的物品,同时实验测试角度,与数据集中部分物品采集样本的角度有些差别,即实验两种算法的环境适应性.
实验物品包括香皂、沐浴露、咖啡(两种)、奶茶、洗发水,其中除奶茶外,剩余物品全部是数据集中的物品.
测试结果预期目标:除奶茶外,正确地定位识别所有物品.
图13为FastR-CNN测试图.
图14为FasterR-CNN测试图.
图13FastR-CNN测试图图14FasterR-CNN测试图对比图13和14的实验结果可以发现,两种算法都能够正确地识别出部分训练数据集中的物品,但将罐装咖啡误识别成可乐.
经过多次实验发现,在该角度下两种算法提取到的罐装咖啡与可乐有部分相似的特征,数据集中罐装可乐没有该角度下的样本,而可乐有多角度的样本,同时在该光照下的罐装咖啡的颜色特征与可乐的颜色特征相似,因此造成此类识别结果.
所以,机器人控制kinect拍摄图片的角度与数据集中的物品拍摄角度应高度相似,即对样本进行尺度变换和增强,这对算法在识别过程中提取非常突出的物品特征和对物品的定位、识别有重要的作用.
最后改变实验图片采集的角度,分别使用FastR-CNN和FasterR-CNN两种算法对多张不同角度的图片进行测试.
通过大量实验结果可以得出,FastR-CNN和FasterR-CNN测试实验结果都并不非常理想.
FastR-CNN能够正确地识别数据集中的部分物品;而FasterR-CNN除了能够正确地识别出数据集中的物品外,对非数据集中的物品产生了误检.
造成上述两个实验结果的原因在于机器人拍摄物品的角度与训练数据集中物品拍摄角度不同,所以可适当地增加训练数据,对图片进行尺度变换,通过数据增强的方式,弥补机器人平台采集数据的劣势.
最后结合上述实验结果和其他测试图片的实验结果,将FastR-CNN和FasterR-CNN网络在家庭服务机器人竞赛中的各项参数统计在表1中.
表1FastR-CNNFasterR-CNN参数对比算法mAP训练耗时测试耗时误检率漏检率FastR-CNN75%约10h2.
1s20%5%FasterR-CNN90%约14h1.
5s6%4%由表1分析可得,FastR-CNN检测准确率在75%左右,训练耗时约10h,测试耗时2.
1s左右,误检率20%,漏检率5%;FasterR-CNN检测准确率在90%左右,训练耗时约14h,测试耗时1.
5s左右,误检率6%,漏检率4%.
由于训练方式的不同,FasterR-CNN多训练一个RPN网络,所以训练耗时要比FastR-CNN略长.
考虑到开发成本较高和服务机器人的内部空间不足等问题,虽然在耗时上两者都没有达到实时的级别,但FasterR-CNN的测试耗时明显低于FastR-CNN.
分析原因是FasterR-CNN使用卷积网络自行产生建议框,并且和目标检测网络共享卷积网络,使得建议框数目从原有的约2000个减少为300个,且建议框的质量也有很大的提高.
2)EndtoEnd训练方法与alt-opt训练方法对比FasterR-CNN提供了两种不同的训练算法,两种方法都会得到优于FastR-CNN的检测效果.
首先对多目标进行实验.
机器人拍摄到角度正常的测试图片,为了增加实验难度,选择的实验物品有相似的形状特征、颜色特征,且会出现非数据集中的物品.
通过多次实验可以得出以下结论:在服务机器人平台拍摄的测试图片角度正常的情况下,机器人使用FasterR-CNN中的alt-opt算法检测的准确率接近EndtoEnd检测的准确率,在对正常角度图片测试时,EndtoEnd算法可以正确地定位识别出数据集中的物品,同时不会检测非数据集物品.
为了进一步检测算法效果,下一步将测试非正常角度的物品.
实验物品包括洗发水、洁面乳、瓶装咖啡.
三种物品有相似的轮廓,但在两种算法中得出了不同的结果,其中洗发水和瓶装咖啡是数据集中的物品,洁面乳不是数据集中的物品.
测试结果预期目标:可以正确地定位识别出洗发水和瓶装咖啡,不会识别洁面乳.
图15为alt-opt训练方法测试图.
图16为EndtoEnd训练方法测试图.
图15alt-opt训练方法测试图chinaXiv:201808.
00076v1ChinaXiv合作期刊录用稿石杰,等:基于FasterR-CNN的服务机器人物品识别研究图16EndtoEnd训练方法测试图通过多次实验可以看出,图15使用alt-opt训练方法得到的模型正确地将洗发水和瓶装咖啡识别出来,但出现了误检测,洁面乳被识别成咖啡.
出现这种结果的原因很可能是洁面乳和瓶装咖啡有相似的暗色和轮廓,在特征提取时得到了近似的特征.
而图16是使用EndtoEnd方法测试的结果,该方法训练的模型正确地检测到洗发水和瓶装咖啡,没有出现误检测.
同时EndtoEnd算法检测时间较alt-op算法检测时间略快,这是由于alt-opt算法在训练模型过程中分四个阶段,EndtoEnd算法不分阶段,所以alt-opt算法较EndtoEnd算法产生更多的权重值.
综上所述,对于本实验平台,EndtoEnd方法更适用.
综合两种训练算法,表2为多次实验测试结果的参数.
表2alt-opt与EndtoEnd参数对比算法mAP训练耗时测试耗时误检率漏检率alt-opt89%约14h1.
6s6%5%EndtoEnd90%约11h1.
5s5%4%由表2分析可得,alt-opt检测准确率在89%左右,训练耗时约14h,测试耗时1.
6s左右,误检率6%,漏检率5%;EndtoEnd检测准确率在90%左右,训练耗时约11h,测试耗时1.
5s左右,误检率5%,漏检率4%.
由于alt-opt算法训练分为四个阶段,每个阶段在训练完后都会进行模型检测,所以在训练过程中耗时更多.
在检测速度、误检率和漏检率方面,EndtoEnd训练方法略胜一筹.
而EndtoEnd算法在测试时占用的内存较alt-opt算法小,因此检测速度更快.
分析实验结果:目标检测网络中,在特定场景下,FasterR-CNN的网络检测性能要优于FastR-CNN;对于本实验平台应用的FasterR-CNN算法中,EndtoEnd训练方法要略优于alt-opt算法.
在实际测试中,机器人使用FasterR-CNN能够识别出更多的物品.
同时,适当地增加样本集中物品的数量会对最终检测结果有更好影响,多卷积层可提取更多的物品特征,保证识别准确率.
3结束语近年来随着人工智能技术的飞速发展,传统的物品识别方法不仅效率低、检测速度慢,而且误检率和漏检率高.
然而深度学习的方法将物品特征交给神经网络去提取,通过反向传播算法与正向传播构成反馈自动地调整学习到的参数,避免了单个算法在识别过程中的劣势,很大程度上解决了这些问题.
本文利用深度学习中识别效果较好的FasterR-CNN算法,将物品识别方法转向将深度学习应用到家庭服务机器人平台,通过选择适用于实验平台的训练算法实现机器人自主识别物品并提高准确率.
通过实验和竞赛结果对比发现,FasterR-CNN算法应用在服务机器人可达到90%的识别准确率.
考虑到服务机器人平台的造价和内部空间的前提下,本次实验未配置GPU,因此所有实验结果均是在CPU上得到,在CPU上运行EndtoEnd训练方法的检测速率在1.
5s左右,运行alt-opt训练方法的检测速率在1.
6s左右,准确率均在90%左右,相比传统图像识别算法,深度学习更胜一筹.
因此采用FasterR-CNN加EndtoEnd训练算法更适用于服务机器人平台.
但是该方法对于光线有一定的要求,如果光线过暗,机器人拍摄的图片可能无法进行正常的识别.
经过多次实验发现,较小目标的识别也有一定困难.
考虑到GPU对算法运行的速率和准确性,团队最终会依据硬件平台加入适用版本的GPU.
同时,实时性也是工业级机器人发展的方向.
对于这些问题,Sun@Home物品识别团队将会继续开发和深入研究.
参考文献:[1]宋欢欢.
复杂场景下背景建模方法的研究与实现[D].
南昌:南昌大学,2015.
(SongHuanhuan.
Reseearchandimplementationofbackgroundmodelingmethodundercomplexscene[D].
Nanchang:NanchangUniversity,2015.
)[2]TaigmanY,YangMing,RanzatoMA,etal.
Deepface:closingthegaptohuman-levelperformanceinfaceverification[C]//ProcofIEEEConferenceonComputerVisionandPatternRecognition.
[S.
l.
]:IEEEPress,2014:1701-1708.
[3]潘威,左欣,沈构强,等.
物品识别系统的设计与实现[J].
科技视界,2015(5):167.
(PanWei,ZuoXin,ShenGouqiang,etal.
Thedesignandimplementationofitemidentificationsystem[J].
Science&TechnologyVision,2015(5):167.
)[4]林汀.
图像特征点匹配算法的研究[J].
现代计算机:专业版,2016(10):28-32.
(LinTing.
Researchonfeaturepointsmatchingalgorithmsequenceimage[J].
ModernComputer,2016(10):28-32.
)[5]胡修祥.
基于RGB-D数据的物品识别与定位[D].
天津:中国民航大学,2016.
(HuXiuxiang.
ObjeectrecongnitionandlocalizationbasedonRGB-Ddata[D].
Tianjin:CivilAviationUniversityofChina,2016.
)[6]ViolaP,JonesMJ.
Robustreal-timefacedetection[J].
InternationalJournalofComputerVision,2004,57(2):137-154.
[7]史东承,倪康.
压缩感知W-HOG特征的运动手势跟踪[J].
智能系统学报,2016,11(1):124-128.
(ShiDongcheng,NiKang.
MotiongesturetrackingbasedoncompressedsensingW-HOGfeatures[J].
CAAITransonIntelligentSystems,2016,11(1):124-128.
)[8]SermanetP,EigenD,ZhangX,etal.
OverFeat:integratedrecognition,localizationanddetectionusingconvolutionalnetworks.
[C]//AdvancesinNeuralInformationProcessingSystems.
[S.
l.
]:ICLRPress,2014:1055-1061.
chinaXiv:201808.
00076v1ChinaXiv合作期刊录用稿石杰,等:基于FasterR-CNN的服务机器人物品识别研究[9]GirshickR,DonahueJ,DarrellT,etal.
Richfeaturehierarchiesforaccurateobjectdetectionandsemanticsegmentation[C]//ProcofImageNetLarge-ScaleVisualRecognitionChallengeWorkshop.
[S.
l.
]:ICCVPress,2013:10-15.
[10]GirshickR,DonahueJ,DarrellT,etal.
Richfeaturehierarchiesforaccurateobjectdetectionandsemanticsegmentation[C]//ProcofImageNetLarge-ScaleVisualRecognitionChallengeWorkshop.
[S.
l.
]:ICCVPress,2013:10-15.
[11]KazemiFM,SamadiS,PoorrezaHR,etal.
VehiclerecognitionusingcurvelettransformandSVM[C]//Procofthe4thInternationalConferenceonInformationTechnology.
[S.
l.
]:IEEEPress,2007:516-521.
[12]GirshickR.
FastR-CNN[C]//ProcofIEEEInternationalConferenceonComputerVision.
[S.
l.
]:ICCVPress,2015:10-15.
[13]RenS,HeK,GirshickR,etal.
FasterR-CNN:towardsreal-timeobjectdetectionwithregionproposalnetworks[C]//ProcofConferenceonNeuralInformationProcessingSystems.
[S.
l.
]:NIPSPress,2015:1-15.
[14]FelzenszwalbPF,GirshickRB,McAllesterD,etal.
Objectdetectionwithdiscriminativelytrainedpart-basedmodels[C]//ProcofIEEETransactionsonPatternAnalysisandMachineIntelligence.
[S.
l.
]:TPAMIPress,2010:201-205.
[15]LongJ,ShelhamerE,DarrellT.
Fullyconvolutionalnetworksforsemanticsegmentation[C]//ProcofIEEEConferenceonComputerVisionandPatternRecognition.
2015.
[16]ZeilerMD,FergusR.
Visualizingandunderstandingconvolutionalneuralnetworks[C]//ProcofEuropeanConferenceonComputerVision.
2014.
[17]万士宁.
基于卷积神经网络的人脸识别研究与实现[D].
成都:电子科技大学,2016.
(WanShining.
Researchandimplementationoffacerecongnitionbasedonconvolutionneturalnetwork[D].
Chengdu:UniversityofElectronicScienceandTechnologyofChina,2016.
)[18]宋焕生,张向清,郑宝峰,等.
基于深度学习方法的复杂场景下车辆目标检测[J].
计算机应用研究,2018,35(4):1270-1273.
(SongHuansheng,ZhangXiangqing,ZhengBaofeng,etal.
Vehicledetectionbasedondeeplearningincomplexscene[J].
ApplicationResearchofComputers,2018,35(4):1270-1273.
)[19]沈莉丽.
基于Kinect视觉识别的智能居家机器人系统[J].
组合机床与自动化加工技术,2017(12):78-80,84.
(ShenLili.
Intelligenthomerobotcontrolsystembasedonthevisualidentitybykinect[J].
ModularMachineTool&AutomaticManufacturingTechnique,2017(12):75-80,84.
)chinaXiv:201808.
00076v1ChinaXiv合作期刊
- http://www.arocmag.com/article/02-2019-11-036.html相关文档
- 韦伯更胜一筹
- 原子结构更胜一筹
- 战争中被英军炮火炸毁的桑给巴尔苏尔坦宫
- 宁波更胜一筹
- 生肖更胜一筹
- 童装更胜一筹
HostKvm($4.25/月),俄罗斯CN2带宽大升级,俄罗斯/香港高防限量5折优惠进行中
HostKvm是一家成立于2013年的国外VPS服务商,产品基于KVM架构,数据中心包括日本、新加坡、韩国、美国、俄罗斯、中国香港等多个地区机房,均为国内直连或优化线路,延迟较低,适合建站或者远程办公等。本月,商家旗下俄罗斯、新加坡、美国、香港等节点带宽进行了大幅度升级,俄罗斯机房国内电信/联通直连,CN2线路,150Mbps(原来30Mbps)带宽起,目前俄罗斯和香港高防节点5折骨折码继续优惠中...
Vultr VPS韩国首尔机房速度和综合性能参数测试
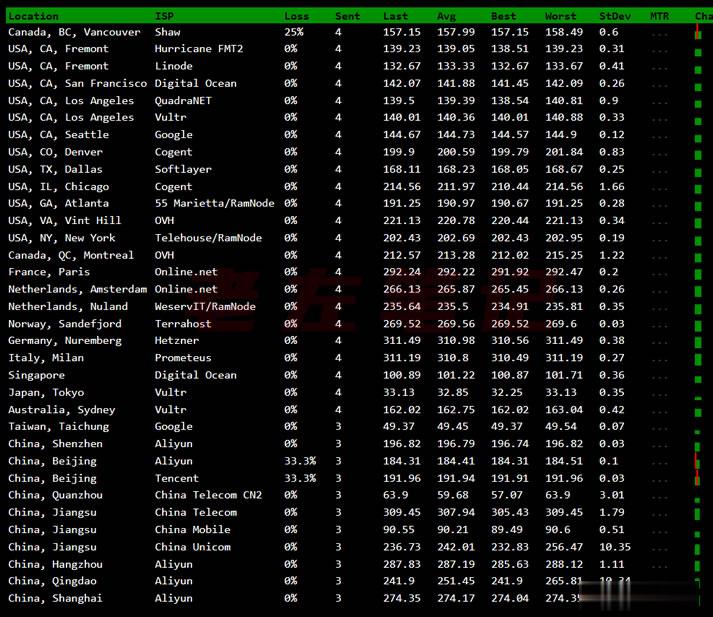
Vultr 商家有新增韩国首尔机房,这个是继日本、新加坡之后的第三个亚洲机房。不过可以大概率知道肯定不是直连中国机房的,因为早期的日本机房有过直连后来取消的。今天准备体验看看VULTR VPS主机商的韩国首尔机房的云服务器的速度和性能。1、全球节点PING速度测试这里先通过PING测试工具看看全球几十个节点的PING速度。看到好像移动速度还不错。2、路由去程测试测试看看VULTR韩国首尔机房的节点...
提速啦母鸡 E5 128G 61IP 1200元
提速啦(www.tisula.com)是赣州王成璟网络科技有限公司旗下云服务器品牌,目前拥有在籍员工40人左右,社保在籍员工30人+,是正规的国内拥有IDC ICP ISP CDN 云牌照资质商家,2018-2021年连续4年获得CTG机房顶级金牌代理商荣誉 2021年赣州市于都县创业大赛三等奖,2020年于都电子商务示范企业,2021年于都县电子商务融合推广大使。资源优势介绍:Ceranetwo...
更胜一筹为你推荐
-
!'UIDETO"UILDING3ECURE7EB!PPLICATIONS操作http杭州市网易yeah申请支付宝账户支付宝账户怎么申请?degradeios开心001开心001与开心网怎么不一样,哪个是真的?我爱试用网我发现我对性爱这个话题好敏感!来吧看谁能把我下面说湿了?要200以上的才好评啊!我爱e书网侯龙涛小说那里有下载的灌水机什么是论坛灌水机?在哪里可以下载到呢?qq挂件qq空间挂件大全!