估算网络网
网络网 时间:2021-04-18 阅读:()
ISSN1000-9825,CODENRUXUEWE-mail:jos@iscas.
ac.
cnJournalofSoftware,Vol.
20,No.
4,April2009,pp.
10231037http://www.
jos.
org.
cndoi:10.
3724/SP.
J.
1001.
2009.
03282Tel/Fax:+86-10-62562563byInstituteofSoftware,theChineseAcademyofSciences.
Allrightsreserved.
基于分簇的传感器网络数据聚集估算机制谢磊1,2,陈力军1,2+,陈道蓄1,2,谢立1,21(南京大学计算机软件新技术国家重点实验室,江苏南京210093)2(南京大学/香港理工大学无线与移动传感器网络联合实验室,江苏南京210093)Clustering-BasedApproximateSchemeforDataAggregationoverSensorNetworksXIELei1,2,CHENLi-Jun1,2+,CHENDao-Xu1,2,XIELi1,21(StateKeyLaboratoryforNovelSoftwareTechnology,NanjingUniversity,Nanjing210093,China)2(NJU-POLYUCooperativeLaboratoryforWirelessSensorNetwork,NanjingUniversity,Nanjing210093,China)+Correspondingauthor:E-mail:chelj@nju.
edu.
cn,http://dislab.
nju.
edu.
cnXieL,ChenLJ,ChenDX,XieL.
Clustering-Basedapproximateschemefordataaggregationoversensornetworks.
JournalofSoftware,2009,20(4):10231037.
http://www.
jos.
org.
cn/1000-9825/3282.
htmAbstract:Inthispaper,ahierarchicalclustering-basedapproximateschemeforin-networkaggregationoversensornetworkscalledCASA(clustering-basedapproximateschemefordataaggregation)isproposed,CASAachievesagoodperformanceintermsoflifetimebyminimizingoverallenergyconsumptionforcommunicationsandbalancingenergyloadamongallnodes,whilemaintaininguser-specifiedqualityofdatarequirement.
CASAadoptsanoptimalparameterfortheclustersize,whichcanwellhandlethehierarchicalapproximateworkforin-networkaggregationwiththeminimizedcommunicationcost.
Furthermore,anadaptivetolerance-reallocatingschemeisleveragedtofurtherreducetheoverallcommunicationcostandmaintainaloadbalanceaccordingtovariousdatachangeratesoverdeploymentregions.
ExperimentalresultsindicatethatsignificantbenefitscanbeachievedthroughthisCASAapproximatescheme.
Keywords:sensornetwork;dataaggregation;approximation;cluster摘要:提出一种基于簇结构的传感器网络数据聚集估算机制CASA(clustering-basedapproximateschemefordataaggregation).
在保证用户对数据精确度需求的前提下,CASA通过最小化网络通信开销以及协调节点间的负载均衡,有效地提高了估算机制的节能性能.
CASA采用最优的分簇规模参数,在基于分簇的网内聚集估算架构中能够最小化网络节点的总体通信开销.
此外,CASA考虑到部署区域感知数据变化率的差异性,采用自适应的误差分配方案来进一步降低网络节点的通信开销,维护节点间的负载均衡.
模拟实验结果表明,CASA估算机制能够显著地提升传感器网络网内数据聚集机制的节能性能,同时保证聚集数据的精确程度.
关键词:传感器网络;数据聚集;估算;分簇中图法分类号:TP393文献标识码:ASupportedbytheNationalNaturalScienceFoundationofChinaunderGrantNos.
60573132,60873026,60573106(国家自然科学基金);theNationalHigh-TechResearchandDevelopmentPlanofChinaunderGrantNo.
2006AA01Z199(国家高技术研究发展计划(863));theNationalBasicResearchProgramofChinaunderGrantNo.
2006CB303000(国家重点基础研究发展计划(973))Received2007-09-24;Accepted2008-02-211024JournalofSoftware软件学报Vol.
20,No.
4,April2009随着传感器技术、嵌入式计算技术以及低功耗无线通信技术的发展,大量具备感知、计算和通信能力的传感器节点共同组织成大规模的无线传感器网络,已经广泛出现在多种相关的应用领域中.
这些传感器节点[1]能够收集不同的感知数据,例如光照和温度,同时能够对这些数据进行一些更为复杂的操作,如缓存、聚集和过滤等.
这种由大量传感器节点组成的网络往往在通信能力、计算能力尤其是能量消耗上存在严重的资源限制,因此,设计一种高效、节能的数据收集策略对大规模部署的传感器网络便至为重要.
考虑到在传感器网络中节点的通信能量开销远大于节点计算能量开销,因此,通过合理利用节点的本地计算能力去降低网络的通信开销能够有效地节省大量能量开销.
近年来,基于数据库的处理方案[2,3]被引入到传感器网络的研究与实现中,以有效地利用网内处理(innetworkprocessing)的特性来降低传感器网络的能量消耗.
在对传感器网络的数据进行收集和处理时,将整个传感器网络看成一个大型的分布式数据库,采用类似于SQL(structuredquerylanguage)的说明性查询语言对传感器网络进行查询的方式来获取感知信息.
通过这种方式,传感器网络中每个节点可以根据用户需求,有效地对相关数据在网内进行过滤、聚集、缓存等操作,最后传至基站终端用户.
网内聚集机制(in-networkaggregation)[4,5]作为一种高效、节能的数据聚集方式,能够充分利用传感器节点的本地处理能力,在将原始数据发送到基站之前,在中间节点就进行数据的聚集合并.
目前对于传感器网络数据收集估算机制的研究[69]已经得到越来越广泛的关注,通过合理权衡获取数据的精确度和能量消耗,在保证获取的数据在指定的精确度范围内这一前提下,能够有效地降低网络的能量开销.
在本文中,我们针对网内聚集机制提出了一种基于分簇的估算机制CASA(clustering-basedapproximateschemefordataaggregation),不同于以前的研究工作,我们提出了一种基于层次结构的估算机制,能够根据部署的环境信息计算获取最优的分簇规模参数,以最小化网络节点的总体通信开销.
此外,针对部署区域感知数据变化率的差异性,CASA采用自适应的误差分配方案进一步降低网络节点的通信开销,维护节点间的负载均衡,并通过理论证明和模拟实验证实,自适应的误差分配结果收敛于理论最优方案.
本文第1节介绍相关工作.
第2节对本文的动因以及采用的系统模型进行描述.
第3节给出CASA的详细设计.
第4节进行模拟实验,对CASA性能进行分析.
最后总结全文.
1相关工作对于网内聚集工作的研究,Krishnamachari[4]等人对传感器网络中数据聚集机制的节能效果做出了全面分析.
Madden等人提出了TAG(tinyaggregation)[5],一种基于管道(pipeline)的网内数据聚集方案,文中对不同的聚集函数的属性进行了详细的分类,并利用管道技术对网内数据聚集执行有效的调度,以保证子节点能够在指定时间段内将数据聚集并传输给父节点.
Demers等人提出了一种基于推拉(pushandpull)技术的聚集节点选择方案和聚集路由树的构建机制[10].
对于网内聚集机制的路由构建,相比于传统树形结构的路由机制,分簇路由具有拓扑管理方便、能量利用高效、数据融合简单等优点,成为当前重点研究的路由技术.
Heinzelman等人提出一种基于簇的数据收集协议LEACH(lowenergyadaptiveclusteringhierarchy)[11],其基本思想是构建一个两跳的分簇路由结构,每个簇内成员节点向簇头发送感知数据,由簇头将处理后的数据直接发送给基站.
Liu等人提出了一种分布式的传感器网络数据收集和聚合协议DEEG(distributedenergy-efficientdatagathering)[12],与LEACH有所不同,簇头之间以多跳方式将收集到的数据发送到指定簇头节点,然后通过该节点将整个网络收集的数据发送到基站.
在文献[13]中,沈波等人对目前无线传感器网络簇算法进行了详细的分析和比较.
对于数据收集估算机制的研究,当前的研究工作主要集中于权衡数据精确度和能量消耗的关系,在满足用户对数据精确度需求的前提下,采用估算机制允许适量误差以有效降低网络的整体能量开销.
Sharaf等人提出了一套基于树形路由结构的网内聚集估算机制TiNA[6],利用误差率TCT(temporalcoherencytolerence)对聚集数据的精确度进行控制.
Deshpande等人提出了一种基于统计模型的传感器网络估算机制[8],在基站通过机器学习的方法维护一个数据模型,用户通过查询的方式与该模型交互获取估算结果,该模型按照特定需求定期更新,通过这种方式显著减少了网络传输量,从而达到节能的效果.
Tulone等人继而提出了PAQ(probabilisticadaptablequerysystem)估算机制[9],通过在节点本地维护一个轻量级的自回归模型(autoregressivemodel)来达到基于时间谢磊等:基于分簇的传感器网络数据聚集估算机制1025序列进行数据估算的目的.
Hellerstein等人提出了一套基于小波压缩技术的聚集数据估算机制[7].
Olston等人针对分布式数据源的聚集查询提出了基于缓存的估算机制[14],能够动态地自适应调整各数据源的精度需求以最小化数据更新的开销.
Goel等人提出了PREMON(prediction-basedmonitoring)[15],利用感知数据的时空相关性来对移动目标的属性进行估算.
上述研究工作大都从设计性能高效的估算模型入手来解决传感器网络的节能问题,不同于以前的研究工作,本文主要结合传感器网络多跳路由结构特性,从设计良好的支持估算机制的网络架构入手,有效地解决传感器网络的节能问题,本文是我们在前期研究工作[16]的基础上进一步深入和扩展的研究成果.
2系统模型与问题描述2.
1系统模型本文假设N个传感器节点随机、均匀分布在一个MM*的二维正方形区域A内,并假设该传感器网络具有如下性质:传感器网络为静态网络,即节点部署后不再移动.
基站部署在区域A以外的一个固定位置,且基站是唯一的.
节点可以获知其位置信息.
节点依靠GPS、有向天线或定位算法等辅助设施或算法获取位置信息.
节点的无线发射功率可控,即节点可以根据接收者的距离来调整其发射功率.
对于节点通信能量消耗的计算,我们使用文献[11]中LEACH提出的能耗模型,该能耗模型给出一个阈值dcrossover,当发送节点与接收节点的距离小于dcrossover时,发送方发送数据的能量损耗与距离的平方成正比,否则与距离的4次方成正比.
上述的两种能量衰减模型分别称为自由空间(freespace)模型和多路衰减(multipathfading)模型.
因此,每发送l比特的数据到d距离处的节点,本地节点需要能耗:24,,elecfscrossoverTxTxelecTxampelecmpcrossoverlEldddEldElEldlEldddεε+(Blow,Bup)*tct,如果成立,则发送消息更新数据V,否则,父节点利用本地的估算值Vappr来估算V,通过这种方式可以有效地避免过多的通信开销,从而达到节能的目的.
为了在传感器网络多跳路由结构上实现上述网内聚集的估算机制,需要考虑合理的路由结构来支持聚集估算机制的实现.
如图3所示,传统的树形路由方案对于数据聚集的估算存在这样的问题:由于估算机制只是针对于原始感知数据进行估算操作,对于传统的树形路由结构,仅有少部分分布在边界的叶节点能够产生原始感知数据,而大部分中间节点通过聚集产生部分聚集数据PSR(partialstaterecord),不能使用估算机制来减少网络传输量.
因此传统的树形路由方案并不能充分利用网内聚集的估算机制来达到高效节能的目的.
如图4所示,基于分簇的路由结构由于感知数据仅在少数簇头节点进行聚集,对于簇内大部分的节点都产生原始的感知数据,因此能够有效支持和实现估算机制的节能效果.
Fig.
3Tree-BasedarchitectureFig.
4Cluster-Basedarchitecture图3树形路由方案图4分簇路由方案根据以上分析,在基于分簇的路由结构下如何有效地建立层次结构的估算机制,如何决定分簇的大小以使网络节点总体通信能耗接近最低,以及考虑到地区数据变化率的差异,如何在分布式环境中自适应地合理分配误差区间,在达到负载均衡目的的同时使网络节点总体能耗接近最低,便成为迫切需要解决的一些问题,本文提出的CASA估算机制旨在解决上述问题,在下一节中我们对CASA数据聚集估算机制进行具体的描述.
3CASA数据聚集估算机制3.
1估算机制的架构对于节点间估算值的计算,文献[69]提出了多种构建估算模型的方案,本文中我们考虑采用基于缓存窗口的估算模型:在路由结构中的父子节点之间,双方节点都维护一个缓存窗口(window),窗口大小设为m,用来缓存最近m轮之内的数据,则估算值Vc取值最近m轮数据的平均数,计算如下:11miiVcVm==∑(3)LowerboundUpperboundZeroboundtctBBTlowup=)(upBlowBSELECTAggregateFunction(attributes)FROMsensorssWHEREs.
locinRangeREPOCHDURATIONiVALUESWITHINtctBaseStationBaseStation谢磊等:基于分簇的传感器网络数据聚集估算机制1027当初始时窗口中缓存数据少于m个缓存数据时,估算值Vc则取窗口中所有数据的平均值.
这种基于缓存窗口的估算模型相比于文献[69]中提出的估算模型更为简单,有效降低了节点的计算复杂度.
同时,通过窗口机制维护估算数据的稳定,减少了感知数据剧烈动荡或接收到错误数据(outlierdata)对估算数据产生的影响.
基于缓存窗口估算模型,我们结合分簇的路由结构建立一套具有层次结构的估算机制,如图5所示.
Fig.
5Cluster-Basedhierarchicalapproximatearchitecture图5基于分簇的层次估算架构图5所示的基于分簇的层次估算架构针对网内聚集的实现,分为两个处理层次:第1个层次在每个簇内部实现,簇头CHj对簇内Nj个成员中每个节点产生的感知数据Vi进行聚集,获得部分聚集数据PSRj,第2个层次在所有k个簇头和基站之间实现,在基站对每个簇头产生的PSR进行聚集:1jNjiiPSRV==∑(4)1kjjAggValuePSR==∑(5)因此,CASA估算机制针对这两个聚集层次,分别提出了两个层次上的估算方案:在簇内聚集层次,对簇内原始感知数据进行估算,维护估算误差α;在簇间聚集层次,对部分聚集数据PSR进行估算,维护估算误差β.
在每个层次内均一的误差分配机制下,存在下面的误差分配关系:11()jNuplowuplowijBBBBNαα=∑(6)11()kuplowuplowjBBBBkββ=∑(7)这种具有层次结构的聚集数据估算机制,分别在原始感知数据和部分聚集数据层次进行估算操作:在原始感知数据层次进行估算操作,有效地降低了大量簇内成员节点向簇头节点传输数据的能量开销;在部分聚集数据层次进行估算操作,由于簇头节点相对基站的距离往往远大于簇内通信的距离,其通信开销相对簇内传输要高很多,通过估算机制降低了簇头与基站通信的概率,从而达到高效节能的目的.
CASA估算机制不仅适用于类似于LEACH[11]的两跳分簇路由结构,也适用于类似于DEEG[12]的簇头之间以多跳方式传输数据的分簇路由结构,其差别仅在于对前者簇间聚集层次估算适用于所有簇头节点,对后者簇间聚集层次估算适用于簇头节点组成多跳路由的所有叶节点,因此,对于不同分簇路由结构具有良好的可扩展性.
下文中为了便于讨论CASA估算机制的性质,以LEACH分簇路由结构为模型进行分析,但其相关性质同样适用于其他分簇路由结构.
下面我们通过定理证明,这种层次结构的聚集数据估算机制的总体误差tct接近于两层误差之和α+β.
定理1.
当Cαβ+≤(C为常数)时,有总体误差(),tctαβ≈+且有2()/4tctCαβ+≤.
证明:根据相对误差α,β的定义,有0(Blow,Bup)*αi,如果成立,则向簇头发送数据Vi,簇头递增刷新次数Ui,成员节点和簇头同时更新Vci,维持误差αi不变;否则,成员节点无须向簇头发送数据Vi,成员节点和簇头同时利用上次估算值更新Vci,并缩小误差αi,有:αi=αi*(1θ),θ为设定的缩小比例,0α*|BupBlow|)Vci=[Vci*(m1)+Vi]/mV′i=ViUi=Ui+1elseVci=[Vci*(m1)+V′i]/mendifendwhileCalculateparametersforprobabilityfunctionP(α)andP′(β)[kopt,αopt]=calculateOptimalClusterSize(P(α),P′(β))Send[kopt,αopt,βopt]toeachsensornodeiSensorNodeSide:while(thetimer(T)forlearningphaseisnotexpired)VigetLocalSensorData()sendVitothebasestationendwhilereceive[kopt,αopt,βopt]fromthebasestationP=kopt/Ngeneratearandomnumbern,where0P)electitselftobetheclusterhead,broadcastHEAD_AD_MSGtoneighbournodeselsewaitforHEAD_AD_MSGandjointhefirst-heardclusterheadendif谢磊等:基于分簇的传感器网络数据聚集估算机制10311jNjijiSUMAvgNααα===∑(24)对于基站节点,基站为每个簇j维护一个负荷指数Wj,用来刻画每个簇的总体负荷:()()()()jjrAvgCAvgPNWAvgAvgEα=(25)基站在每T轮根据Wj为各簇重新分配误差区间,首先保证分配各簇的误差下界值SUMj(α),对剩下的误差区间ΔD根据权重按比例为每个簇j分配Δdj,即有:1()kjjDNSUMΔαα=26)111()kjjjjkkjjjjjWWdDNSUMWWΔΔαα=====∑∑∑(27)在完成分配计算后,基站将为各簇分配的误差区间Δdj发送给相应的簇头.
在每T轮,簇头根据基站分配出的误差区间Δdj,在簇内为每个成员节点分配误差量.
簇头以每个成员节点的负荷指数Bi为权重,为每个节点再次按权重比例分配富余的误差值Δαi,对分配到富余误差值的成员节点i更新其误差值αi.
1111()jjkijiijjNNkjiijjjjBWBdNSUMBBWΔαΔαα======∑∑∑∑(28)通过对每个节点以负荷指数为权重分配富余误差值的策略,使得当前簇内通信能耗较高并且误差分配量相对较小的那些节点能够获得较大的富余误差量补给,能够有效地均衡各节点的负荷并且降低整体网络通信开销.
自适应误差分配的算法流程如图7所示.
3.
5自适应误差分配机制分析第3.
4节提出了自适应的误差分配方案,其目的是为了均衡各节点间的通信负载,同时有效降低整体的网络通信能耗.
下面我们来证明在簇内聚集估算层次自适应误差分配方案的节能效果是接近理论最优的.
定理3.
在簇内聚集估算层次自适应误差分配方案的节能效果收敛于非均一误差分配的理论最优方案.
证明:考虑在簇内聚集估算层次采用非均一的误差分配方案,如何在固定的总体误差范围内合理分配误差以使簇内聚集层次总体通信能耗最低,便成为一个优化问题.
我们使用效用函数(utilityfunction)C(α)来表示簇内聚集层次总体通信能耗:1()()NkiiiCCPαα==∑(29)C(α)包括Nk个成员节点的通信开销,Ci为节点i的通信开销,P(αi)为节点i的通信概率,αi为分配给节点i的误差量,根据式(20)可以推导出对于所有的成员节点误差,其满足约束关系:1()NkiiNtctNααβ=∑(30)其中,tctβ即为簇内聚集估算分配的误差量α,在这里为常数.
我们的优化问题便为如何在满足约束关系(32)的前提下调整αi以最小化总体能量开销C(α)的数值.
针对这样的优化问题,我们可以利用拉格朗日乘子法[17](Lagrangemultiplier)计算最优解,存在目标函数f(α)=C(α):1()()NkiiifCPαα==∑(31)以及约束函数g(α):1()()NkiigtctNααβ==∑(32)1032JournalofSoftware软件学报Vol.
20,No.
4,April2009Fig.
7Pseudo-Codeforadaptivetoleranceallocatealgorithm图7自适应误差分配算法伪码构造辅助函数Ffgααλα=,λ为某一常数,则根据拉格朗日乘子法有()0Fαα=,我们得到:1()()NkiiiiCPNkαλα==∑(33)根据随机行走的模型,对P(αi)有:221()(2)iiPsαα≈,根据上式我们得到下面的约束关系:()iiiCPDαλα=(34)其中,Dλ为常数,D=1/2.
由负荷指数Bi的定义,存在下面的等式关系:()iiiiCPBDαλα==(35)上式表明,当所有节点的负荷指数趋向于一个相等的常数时,总体通信能耗最低,而根据我们的自适应误差分配方案,通过在数据变化快,即P(αi)高的节点上逐步提高误差αi的取值,以及在数据变化慢,即P(αi)低的节点上逐步降低误差αi取值的方式,最终能够使所有节点的负荷指数Bi收敛于一个相等的数值,使得整体能耗最低.
由定理3我们得知,通过自适应误差分配方案,其节能效果最终可以收敛于非均一误差分配的理论最优方案.
其收敛速度受到自适应调整的时间间隔T的影响,考虑到调整的时间间隔T越小,其收敛速度越快,但同时带AlgorithmforBaseStation.
round=0if(round==0)receiveAvg(Ci)fromeachclusterround=round+1endifforeachround>0receivePSRjfromeachclusterjwithapproximateschemeif(round%T==(T1))receiveAvgj(Er),Avgj(P),Avgj(α)fromeachclusterjendifif(round%T==0)calculateWiandnewallocatedΔdjforeachclusterjsendΔdjtoeachclusterheadjendifround=round+1endforAlgorithmforClusterMember.
round=0if(round==0)sendCitoitsclusterheadround=round+1endifforeachround>0VigetLocalSensorData()if(|ViVci|>(Blow,Bup)*αi)Vci=[Vci*(m1)+Vi]/mV′i=VisendVitoitsclusterheadelse(1)iiααθ=Vci=[Vci*(m1)+V′i]/mendifif(round%T==(T1))sendEritotheclusterheadendifif(round%T==0)receivenewallocatedΔαiαi=αi+Δαiendifround=round+1endforAlgorithmforClusterHead.
round=0if(round==0)receiveCifromeachnode,calculateAvg(Ci)andsendAvg(Ci)tobasestationround=round+1endifforeachround>0if(receiveVifrommembernodei)Vc=[Vci*(m1)+Vi]/mV′i=ViUi=Ui+1else(1)iiααθ=Vci=[Vci*(m1)+V′i]/mendifcalculatePSRjandsendPSRjtothebasestationwithapproximateschemeif(round%T==(T1))calculateAvgj(Er),Avgj(P)andAvgj(α)andsendtobasestationendifif(round%T==0)receiveallocatedtoleranceΔdjfrombasestation,calculateBiandnewallocatedΔαiforeachnodesendΔαitonodeiendifround=round+1endfor谢磊等:基于分簇的传感器网络数据聚集估算机制1033来的控制信息传输开销也会越大.
因此,选择合适的自适应调整的时间间隔T对提高自适应误差分配方案的节能性能有很重要的影响,这将成为我们下一步研究工作需要考虑的问题.
4性能评价4.
1模拟实验环境设置和参数本节通过模拟实验来对CASA估算机制的性能进行评估,我们基于Glomosim模拟实验平台实现了本文提出的估算算法.
实验设备是一台运行WinXP,具有P4处理器、1G内存的PC.
模拟实验环境中节点随机分布在大小为100*100(m2)的监测区域内,部署节点总数为100.
实验中,我们使用随机行走模型(randomwalkmodel)来模拟生成感知数据,其中使用随机度(randomnessdegree)来描述感知数据相比前一轮样本发生变化的概率,使用随机步长(randomstepsize)来描述每次数据变化的幅度,用百分比表示.
具体的实验参数设置见表1.
我们通过以下方面来评估CASA的性能:首先通过性能对比来验证估算架构的节能效果,然后通过实验结果验证最优分簇规模算法的有效性,最后通过性能对比来对自适应误差分配方案的节能效果进行验证.
Table1Parametersofsimulation表1模拟实验参数列表ParameterValueParameterValueArea(m2)100*100Randomdegree0.
0~1.
0,0.
5defaultNumberofnodes100Randomstepsize0.
0~1.
0,0.
5defaultBasestationposition(50,100),(50,150),(50,200)(Blow,Bup)(10,40)Packetsize(bits)4000Eelec(nJ/bit)50Numberofrounds1000εfs(pJ/bit/m2)13TctreallocateintervalT10εmp(pJ/bit/m4)0.
0013tct0%~30%,10%(default)dcrossover(m)75Initialenergy(J)2Standarddeviationα0.
05Windowsize1~10,5default4.
2估算架构的性能验证图8给出了在不同误差tct情况下各种数据收集机制的性能比较.
我们针对随机生成的同一节点分布分别构造出传统的树形路由结构和分簇的路由结构,在这两种不同的路由结构上,我们分别实现带有估算机制的传输方案和不带有估算机制的传输方案.
可以看到,在没有估算机制的支持下,传统的树形路由和分簇路由方案需要大量的能量开销,而使用估算机制的树形路由方案在tct=0.
2时,可以减少40%的能量开销,相比于前3种方案,可以看到,基于分簇路由的CASA估算机制能够进一步有效地降低网络的能量开销,在tct=0.
2时,相比树形结构的估算方案能够进一步减少38%的能量开销.
图9给出了具有不同误差的分簇估算机制的性能受数据变化率的影响,随着随机度RD的增加,数据的变化率进一步加快.
可以看到,不使用估算机制的分簇方案不受任何影响,但一直处于一个高能耗开销的水平42J,使用估算机制的分簇方案的能耗开销随之增长,此时具有更大误差量的估算方案(tct=0.
3)相比于小误差量的估算方案(tct=0.
1),面对较高的数据变化率有更好的节能效果.
在RD=0.
9时,前者比后者可以节省53%的能量开销,但即使在这种情况下,tct=0.
1的估算方案相比不使用估算机制的分簇方案仍能减少31%的能量开销.
图8和图9的实验结果表明,基于分簇的估算架构在不同数据变化率的观测环境下都能够有效降低网络的总体能耗.
图10描述了缓存窗口大小面对不同数据变化幅度时对估算机制节能效果的影响,实验中,我们利用数据变化的随机步长RSS来调整数据的变化幅度.
可以看到,对于较小的数据变化幅度,不同缓存窗口大小的估算机制具有基本相同的能量开销,随着变化幅度的进一步增大,当RSS=0.
9时,具有较小窗口的估算机制(windowsize=1)能量开销高达43J,而同时具有较大窗口的估算机制(windowsize=10)其能量开销也有38J.
相比而言,窗口大小适中的估算机制(windowsize=5)则仅有31J的能量开销.
这是因为,对于较小窗口的估算机制,由于只缓存为数很少的数据,因此估算值受数据波动的影响非常大,总是受制于最新接收的波动数据,估算效果受到极大影响.
而对于较大窗口的估算机制,由于其缓存过多的历史数据,估算值受历史数据影响,其变化非常缓慢,不能及时反映当前数据的变化状况,估算效果也受到很大影响.
窗口大小适中的估算机制,由于既能及时反映当前数据的变化状况,又能不受数据波动的太大影响,能够达到很好的节能效果.
因此,图101034JournalofSoftware软件学报Vol.
20,No.
4,April2009的实验结果表明,选择合理的估算窗口大小对估算机制的节能效果有很重要的影响.
Fig.
8Energyconsumptionvs.
tctFig.
9Energyconsumptionvs.
randomdegree图8不同估算机制的能量消耗图9能量消耗与随机度的关系Fig.
10Energyconsumptionvs.
cachewindowsize图10能量消耗与缓存窗口大小关系4.
3最优分簇算法的验证图11给出了分簇规模对网络总体能耗的影响.
我们将分簇数量在1~50间加以变化,可以看到,当分簇数量在6~10之间时能够使传感器网络达到整体最低能量消耗约24J,而我们在基站通过最优分簇规模计算方法计算出的kopt=8正好处在这个范围之内,通过实验数据有效验证了最优分簇规模计算方法的有效性.
图12进一步给出了基站位置对kopt和α取值的影响.
可以看到,随着基站位置进一步远离观测区域,kopt和α的取值都相对减少.
这是因为,随着基站位置的进一步远离,簇头与基站之间的通信开销逐步增大,而根据CASA基于层次结构的估算机制,进一步降低kopt有助于减少簇头数量,从而降低簇头与基站通信的整体开销,进一步降低簇内聚集估算误差α,从而提升簇间聚集估算误差β,有助于充分利用PSR的估算机制有效降低簇头与基站通信的概率,达到降低总体通信能耗的效果.
图11和图12的实验结果充分验证了最优分簇规模算法的有效性.
0.
100.
150.
200.
250.
30tct454035302520151050Overallenergyconsumption(J)TreebasedroutingClusterbasedroutingTreebasedroutingwithtctClusterbasedroutingwith0.
00.
20.
40.
60.
81.
0Randomdegree50454035302520151050Overallenergyconsumption(J)ClusterbasedroutingwithnotctClusterbasedroutingwithtct=0.
1Clusterbasedroutingwithtct=0.
2Clusterbasedroutingwithtct=0.
3Overallenergyconsumption(J)0.
00.
20.
40.
60.
81.
0Randomstepsize454035302520151050Windowsize=1Windowsize=5Windowsize=10谢磊等:基于分簇的传感器网络数据聚集估算机制1035Fig.
11Energyconsumptionvs.
clustersizeFig.
12BSlocationvs.
koptandα图11能量消耗与分簇规模的关系图12基站位置与kopt和α的关系4.
4自适应误差分配方案的性能验证在本节性能验证实验中均设定tct=0.
1,感知数据变化率均方差α=0.
05,自适应调整的时间间隔T=10.
图13给出不同误差分配方案的能量消耗对比.
实验中,我们构造出3种估算传输方案,分别为均一的误差分配方案、自适应的误差分配方案和理论最优的非均一误差分配方案,对于理论最优的非均一误差分配方案,其参数是根据当前的各节点区域的变化数值计算而得.
可以看到,自适应的误差分配方案其能量消耗在round=0时与均一的误差分配方案有相同的能量开销,随着轮数的递增,自适应的误差分配方案能够逐步调整误差分配,降低能量开销,逐渐收敛于非均一方案最优配置.
可以看到,在T=10时,其收敛速度还是很快的,在round=1000时,其能量开销已经十分接近非均一方案最优配置的能量开销,此时,自适应的误差分配方案比均一的误差分配方案能够减少24%的能量开销.
图14给出不同误差分配方案网络寿命的对比.
这里,我们分别构造出不使用估算机制的分簇路由方案、使用均一误差的分配方案以及使用自适应的误差分配方案.
我们定义网络寿命为网络中第1个节点死亡的时间.
可以看到,对于不使用估算机制的分簇路由方案,其网络寿命为372,使用均一误差分配方案的网络寿命为596,而使用自适应的误差分配方案网络寿命为674,图13和图14的实验表明,自适应的误差分配方案不仅能够迅速收敛于最小化整体通信能耗的方案,同时能够通过均衡各节点的负载,有效地延长网络的寿命.
Fig.
13EnergyconsumptionfordifferenttoleranceFig.
14Measurementofnetworklifetimeallocationstrategies图13不同误差分配方案的能量消耗图14网络寿命的比较100908070605040302001020304050NumberofclustersOverallenergyconsumption(J)BSlocationα02004006008001000Numberofround2826242220181614121086420Energyconsumptionperround(103J/perround)UniformtoleranceallocationAdaptivetoleranceallocationOptimalnon-uniformtoleranceallocation02004006008001000Numberofround100806040200NumberofnodesaliveClusterbasedroutingClusterbasedroutingwithuniformtctClusterbasedroutingwithadaptiveadjustedtct1036JournalofSoftware软件学报Vol.
20,No.
4,April2009图15分析了地区性数据变化差异程度对不同误差分配方案性能的影响,实验通过调整感知数据变化率均方差σ来改变数据变化差异程度.
可以看到,均一的误差分配方案不受任何数据变化差异程度的影响,始终维持一个较高的能耗水平25.
2J,而自适应的误差分配方案随着地区数据的变化,其差异程度逐渐增加,能够更为有效地利用非均一的误差分配方案来更合理地分配误差以降低网络通信开销,在具有较大的地区数据变化差异程度α=0.
1时,自适应的误差分配方案能够比均一的误差分配方案节省33%的能量开销.
Fig.
15Impactofdeviationfordatachangerates图15数据变化差异对能耗的影响5总结和下一步工作本文针对传感器网络的网内聚集问题提出了一种基于分簇层次结构的估算机制CASA.
CASA采用最优分簇规模参数,在基于分簇的网内聚集估算架构中能够最小化网络节点的总体通信开销.
此外,CASA考虑到部署区域感知数据变化率的差异性,采用自适应的误差分配方案进一步降低网络节点的通信开销,维护节点间的负载均衡.
实验结果表明,CASA估算机制能够显著提升传感器网络网内聚集机制的节能性能,同时保证聚集数据的精确程度.
在下一步的研究工作中,我们考虑将该估算机制由基于LEACH的两跳分簇路由结构进一步应用到更为普遍的多跳分簇路由结构中,研究如何在多个层次结构间以及层次结构内分配估算误差,决定最优的α,β误差分配参数;同时对自适应调整机制,将进行对自适应调整时间间隔T最优取值的研究,以充分提高节能效果.
References:[1]HillJ,CullerD.
Mica:Awirelessplatformfordeeplyembeddednetworks.
IEEEMicro,2002,22(6):1224.
[2]GehrkeJ,MaddenS.
Queryprocessinginsensornetworks.
IEEEPervasiveComputing,2004,3(1):4655.
[3]LiJZ,LiJB,ShiSF.
Concepts,issuesandadvanceofsensornetworksanddatamanagementofsensornetworks.
JournalofSoftware,2003,14(10):17171727(inChinesewithEnglishabstract).
http://www.
jos.
org.
cn/1000-9825/14/1717.
htm[4]KrishnamachariB,EstrinD,WickerSB.
Theimpactofdataaggregationinwirelesssensornetworks.
In:Proc.
ofthe22ndInt'lConf.
onDistributedComputingSystems.
Washington:IEEEComputerSociety,2002.
575578.
[5]MaddenS,FranklinMJ,HellersteinJM,HongW.
TAG:Atinyaggregationserviceforad-hocsensornetworks.
In:Proc.
oftheOSDI.
2002.
http://doi.
acm.
org/10.
1145/844128.
844142[6]SharafMA,BeaverJ,LabrinidisA,ChrysanthisPK.
TiNA:Aschemefortemporalcoherency-awarein-networkaggregation.
In:Proc.
oftheMobiDE.
2003.
6976.
http://doi.
acm.
org/10.
1145/940923.
940937[7]HellersteinJM,HongW,MaddenS,StanekK.
Beyondaverage:Towardsophisticatedsensingwithqueries.
In:Proc.
oftheIPSN.
2003.
6379.
0.
000.
020.
040.
060.
080.
10Standarddeviationamongdatachangerates2520151050Overallenergyconsumption(103J/perround)UniformtoleranceallocationAdaptivetoleranceallocation谢磊等:基于分簇的传感器网络数据聚集估算机制1037[8]DeshpandeA,GuestrinC,MaddenS,HellersteinJM,HongW.
Model-Basedapproximatequeryinginsensornetworks.
VLDBJournal,2005,14(4):417443.
[9]TuloneD,MaddenS.
PAQ:Timeseriesforecastingforapproximatequeryansweringinsensornetworks.
In:Proc.
oftheEWSN.
2006.
2137.
[10]DemersAJ,GehrkeJ,RajaramanR,TrigoniA,YaoY.
Thecougarproject:Awork-in-progressreport.
SIGMODRecord,2003,32(4):5359.
[11]HeinzelmanWB,ChandrakasanAP,BalakrishnanH.
Anapplication-specificprotocolarchitectureforwirelessmicrosensornetworks.
IEEETrans.
onWirelessCommunications,2002,1(4):660670.
[12]LiuM,GongHG,MaoYC,ChenLJ,XieL.
Adistributedenergy-efficientdatagatheringandaggregationprotocolforwirelesssensornetworks.
JournalofSoftware,2005,16(12):21062116(inChinesewithEnglishabstract).
http://www.
jos.
org.
cn/1000-9825/16/2106.
htm[13]ShenB,ZhangSY,ZhongYP.
Cluster-Basedroutingprotocolsforwirelesssensornetworks.
JournalofSoftware,2006,17(7):15881600(inChinesewithEnglishabstract).
http://www.
jos.
org.
cn/1000-9825/17/1588.
htm[14]OlstonC,WidomJ.
Approximatecachingforcontinuousqueriesoverdistributeddatasources.
TechnicalReport,ComputerScienceDepartment,StanfordUniversity,2002.
http://dbpubs.
stanford.
edu/pub/2002-8[15]GoelS,ImielinskiT.
Prediction-Basedmonitoringinsensornetworks:TakinglessonsfromMPEG.
ACMSIGCOMMComputerCommunicationReview,2001,31(5):8298.
[16]XieL,ChenLJ,ChenDX,XieL.
Aclustering-basedapproximationschemeforin-networkaggregationoversensornetworks.
In:Proc.
oftheUIC.
2007.
503513.
[17]StewartJ.
Calculus:EarlyTranscendentals.
2nded.
,Brooks/Cole,1991.
附中文参考文献:[3]李建中,李金宝,石胜飞.
传感器网络及其数据管理的概念、问题与进展.
软件学报,2003,14(10):17171727.
http://www.
jos.
org.
cn/1000-9825/14/1717.
htm[12]刘明,龚海刚,毛莺池,陈力军,谢立.
高效节能的传感器网络数据收集和聚合协议.
软件学报,2005,16(12):21062116.
http://www.
jos.
org.
cn/1000-9825/16/2106.
htm[13]沈波,张世永,钟亦平.
无线传感器网络分簇路由协议.
软件学报,2006,17(7):15881600.
http://www.
jos.
org.
cn/1000-9825/17/1588.
htm谢磊(1982-),男,江苏南通人,博士生,主要研究领域为分布式计算,传感器网络技术.
陈道蓄(1947-),男,教授,博士生导师,CCF高级会员,主要研究领域为分布式计算.
陈力军(1961-),男,博士,教授,主要研究领域为移动网络,分布式计算.
谢立(1942-),男,教授,博士生导师,CCF高级会员,主要研究领域为分布式计算,网络安全.
ac.
cnJournalofSoftware,Vol.
20,No.
4,April2009,pp.
10231037http://www.
jos.
org.
cndoi:10.
3724/SP.
J.
1001.
2009.
03282Tel/Fax:+86-10-62562563byInstituteofSoftware,theChineseAcademyofSciences.
Allrightsreserved.
基于分簇的传感器网络数据聚集估算机制谢磊1,2,陈力军1,2+,陈道蓄1,2,谢立1,21(南京大学计算机软件新技术国家重点实验室,江苏南京210093)2(南京大学/香港理工大学无线与移动传感器网络联合实验室,江苏南京210093)Clustering-BasedApproximateSchemeforDataAggregationoverSensorNetworksXIELei1,2,CHENLi-Jun1,2+,CHENDao-Xu1,2,XIELi1,21(StateKeyLaboratoryforNovelSoftwareTechnology,NanjingUniversity,Nanjing210093,China)2(NJU-POLYUCooperativeLaboratoryforWirelessSensorNetwork,NanjingUniversity,Nanjing210093,China)+Correspondingauthor:E-mail:chelj@nju.
edu.
cn,http://dislab.
nju.
edu.
cnXieL,ChenLJ,ChenDX,XieL.
Clustering-Basedapproximateschemefordataaggregationoversensornetworks.
JournalofSoftware,2009,20(4):10231037.
http://www.
jos.
org.
cn/1000-9825/3282.
htmAbstract:Inthispaper,ahierarchicalclustering-basedapproximateschemeforin-networkaggregationoversensornetworkscalledCASA(clustering-basedapproximateschemefordataaggregation)isproposed,CASAachievesagoodperformanceintermsoflifetimebyminimizingoverallenergyconsumptionforcommunicationsandbalancingenergyloadamongallnodes,whilemaintaininguser-specifiedqualityofdatarequirement.
CASAadoptsanoptimalparameterfortheclustersize,whichcanwellhandlethehierarchicalapproximateworkforin-networkaggregationwiththeminimizedcommunicationcost.
Furthermore,anadaptivetolerance-reallocatingschemeisleveragedtofurtherreducetheoverallcommunicationcostandmaintainaloadbalanceaccordingtovariousdatachangeratesoverdeploymentregions.
ExperimentalresultsindicatethatsignificantbenefitscanbeachievedthroughthisCASAapproximatescheme.
Keywords:sensornetwork;dataaggregation;approximation;cluster摘要:提出一种基于簇结构的传感器网络数据聚集估算机制CASA(clustering-basedapproximateschemefordataaggregation).
在保证用户对数据精确度需求的前提下,CASA通过最小化网络通信开销以及协调节点间的负载均衡,有效地提高了估算机制的节能性能.
CASA采用最优的分簇规模参数,在基于分簇的网内聚集估算架构中能够最小化网络节点的总体通信开销.
此外,CASA考虑到部署区域感知数据变化率的差异性,采用自适应的误差分配方案来进一步降低网络节点的通信开销,维护节点间的负载均衡.
模拟实验结果表明,CASA估算机制能够显著地提升传感器网络网内数据聚集机制的节能性能,同时保证聚集数据的精确程度.
关键词:传感器网络;数据聚集;估算;分簇中图法分类号:TP393文献标识码:ASupportedbytheNationalNaturalScienceFoundationofChinaunderGrantNos.
60573132,60873026,60573106(国家自然科学基金);theNationalHigh-TechResearchandDevelopmentPlanofChinaunderGrantNo.
2006AA01Z199(国家高技术研究发展计划(863));theNationalBasicResearchProgramofChinaunderGrantNo.
2006CB303000(国家重点基础研究发展计划(973))Received2007-09-24;Accepted2008-02-211024JournalofSoftware软件学报Vol.
20,No.
4,April2009随着传感器技术、嵌入式计算技术以及低功耗无线通信技术的发展,大量具备感知、计算和通信能力的传感器节点共同组织成大规模的无线传感器网络,已经广泛出现在多种相关的应用领域中.
这些传感器节点[1]能够收集不同的感知数据,例如光照和温度,同时能够对这些数据进行一些更为复杂的操作,如缓存、聚集和过滤等.
这种由大量传感器节点组成的网络往往在通信能力、计算能力尤其是能量消耗上存在严重的资源限制,因此,设计一种高效、节能的数据收集策略对大规模部署的传感器网络便至为重要.
考虑到在传感器网络中节点的通信能量开销远大于节点计算能量开销,因此,通过合理利用节点的本地计算能力去降低网络的通信开销能够有效地节省大量能量开销.
近年来,基于数据库的处理方案[2,3]被引入到传感器网络的研究与实现中,以有效地利用网内处理(innetworkprocessing)的特性来降低传感器网络的能量消耗.
在对传感器网络的数据进行收集和处理时,将整个传感器网络看成一个大型的分布式数据库,采用类似于SQL(structuredquerylanguage)的说明性查询语言对传感器网络进行查询的方式来获取感知信息.
通过这种方式,传感器网络中每个节点可以根据用户需求,有效地对相关数据在网内进行过滤、聚集、缓存等操作,最后传至基站终端用户.
网内聚集机制(in-networkaggregation)[4,5]作为一种高效、节能的数据聚集方式,能够充分利用传感器节点的本地处理能力,在将原始数据发送到基站之前,在中间节点就进行数据的聚集合并.
目前对于传感器网络数据收集估算机制的研究[69]已经得到越来越广泛的关注,通过合理权衡获取数据的精确度和能量消耗,在保证获取的数据在指定的精确度范围内这一前提下,能够有效地降低网络的能量开销.
在本文中,我们针对网内聚集机制提出了一种基于分簇的估算机制CASA(clustering-basedapproximateschemefordataaggregation),不同于以前的研究工作,我们提出了一种基于层次结构的估算机制,能够根据部署的环境信息计算获取最优的分簇规模参数,以最小化网络节点的总体通信开销.
此外,针对部署区域感知数据变化率的差异性,CASA采用自适应的误差分配方案进一步降低网络节点的通信开销,维护节点间的负载均衡,并通过理论证明和模拟实验证实,自适应的误差分配结果收敛于理论最优方案.
本文第1节介绍相关工作.
第2节对本文的动因以及采用的系统模型进行描述.
第3节给出CASA的详细设计.
第4节进行模拟实验,对CASA性能进行分析.
最后总结全文.
1相关工作对于网内聚集工作的研究,Krishnamachari[4]等人对传感器网络中数据聚集机制的节能效果做出了全面分析.
Madden等人提出了TAG(tinyaggregation)[5],一种基于管道(pipeline)的网内数据聚集方案,文中对不同的聚集函数的属性进行了详细的分类,并利用管道技术对网内数据聚集执行有效的调度,以保证子节点能够在指定时间段内将数据聚集并传输给父节点.
Demers等人提出了一种基于推拉(pushandpull)技术的聚集节点选择方案和聚集路由树的构建机制[10].
对于网内聚集机制的路由构建,相比于传统树形结构的路由机制,分簇路由具有拓扑管理方便、能量利用高效、数据融合简单等优点,成为当前重点研究的路由技术.
Heinzelman等人提出一种基于簇的数据收集协议LEACH(lowenergyadaptiveclusteringhierarchy)[11],其基本思想是构建一个两跳的分簇路由结构,每个簇内成员节点向簇头发送感知数据,由簇头将处理后的数据直接发送给基站.
Liu等人提出了一种分布式的传感器网络数据收集和聚合协议DEEG(distributedenergy-efficientdatagathering)[12],与LEACH有所不同,簇头之间以多跳方式将收集到的数据发送到指定簇头节点,然后通过该节点将整个网络收集的数据发送到基站.
在文献[13]中,沈波等人对目前无线传感器网络簇算法进行了详细的分析和比较.
对于数据收集估算机制的研究,当前的研究工作主要集中于权衡数据精确度和能量消耗的关系,在满足用户对数据精确度需求的前提下,采用估算机制允许适量误差以有效降低网络的整体能量开销.
Sharaf等人提出了一套基于树形路由结构的网内聚集估算机制TiNA[6],利用误差率TCT(temporalcoherencytolerence)对聚集数据的精确度进行控制.
Deshpande等人提出了一种基于统计模型的传感器网络估算机制[8],在基站通过机器学习的方法维护一个数据模型,用户通过查询的方式与该模型交互获取估算结果,该模型按照特定需求定期更新,通过这种方式显著减少了网络传输量,从而达到节能的效果.
Tulone等人继而提出了PAQ(probabilisticadaptablequerysystem)估算机制[9],通过在节点本地维护一个轻量级的自回归模型(autoregressivemodel)来达到基于时间谢磊等:基于分簇的传感器网络数据聚集估算机制1025序列进行数据估算的目的.
Hellerstein等人提出了一套基于小波压缩技术的聚集数据估算机制[7].
Olston等人针对分布式数据源的聚集查询提出了基于缓存的估算机制[14],能够动态地自适应调整各数据源的精度需求以最小化数据更新的开销.
Goel等人提出了PREMON(prediction-basedmonitoring)[15],利用感知数据的时空相关性来对移动目标的属性进行估算.
上述研究工作大都从设计性能高效的估算模型入手来解决传感器网络的节能问题,不同于以前的研究工作,本文主要结合传感器网络多跳路由结构特性,从设计良好的支持估算机制的网络架构入手,有效地解决传感器网络的节能问题,本文是我们在前期研究工作[16]的基础上进一步深入和扩展的研究成果.
2系统模型与问题描述2.
1系统模型本文假设N个传感器节点随机、均匀分布在一个MM*的二维正方形区域A内,并假设该传感器网络具有如下性质:传感器网络为静态网络,即节点部署后不再移动.
基站部署在区域A以外的一个固定位置,且基站是唯一的.
节点可以获知其位置信息.
节点依靠GPS、有向天线或定位算法等辅助设施或算法获取位置信息.
节点的无线发射功率可控,即节点可以根据接收者的距离来调整其发射功率.
对于节点通信能量消耗的计算,我们使用文献[11]中LEACH提出的能耗模型,该能耗模型给出一个阈值dcrossover,当发送节点与接收节点的距离小于dcrossover时,发送方发送数据的能量损耗与距离的平方成正比,否则与距离的4次方成正比.
上述的两种能量衰减模型分别称为自由空间(freespace)模型和多路衰减(multipathfading)模型.
因此,每发送l比特的数据到d距离处的节点,本地节点需要能耗:24,,elecfscrossoverTxTxelecTxampelecmpcrossoverlEldddEldElEldlEldddεε+(Blow,Bup)*tct,如果成立,则发送消息更新数据V,否则,父节点利用本地的估算值Vappr来估算V,通过这种方式可以有效地避免过多的通信开销,从而达到节能的目的.
为了在传感器网络多跳路由结构上实现上述网内聚集的估算机制,需要考虑合理的路由结构来支持聚集估算机制的实现.
如图3所示,传统的树形路由方案对于数据聚集的估算存在这样的问题:由于估算机制只是针对于原始感知数据进行估算操作,对于传统的树形路由结构,仅有少部分分布在边界的叶节点能够产生原始感知数据,而大部分中间节点通过聚集产生部分聚集数据PSR(partialstaterecord),不能使用估算机制来减少网络传输量.
因此传统的树形路由方案并不能充分利用网内聚集的估算机制来达到高效节能的目的.
如图4所示,基于分簇的路由结构由于感知数据仅在少数簇头节点进行聚集,对于簇内大部分的节点都产生原始的感知数据,因此能够有效支持和实现估算机制的节能效果.
Fig.
3Tree-BasedarchitectureFig.
4Cluster-Basedarchitecture图3树形路由方案图4分簇路由方案根据以上分析,在基于分簇的路由结构下如何有效地建立层次结构的估算机制,如何决定分簇的大小以使网络节点总体通信能耗接近最低,以及考虑到地区数据变化率的差异,如何在分布式环境中自适应地合理分配误差区间,在达到负载均衡目的的同时使网络节点总体能耗接近最低,便成为迫切需要解决的一些问题,本文提出的CASA估算机制旨在解决上述问题,在下一节中我们对CASA数据聚集估算机制进行具体的描述.
3CASA数据聚集估算机制3.
1估算机制的架构对于节点间估算值的计算,文献[69]提出了多种构建估算模型的方案,本文中我们考虑采用基于缓存窗口的估算模型:在路由结构中的父子节点之间,双方节点都维护一个缓存窗口(window),窗口大小设为m,用来缓存最近m轮之内的数据,则估算值Vc取值最近m轮数据的平均数,计算如下:11miiVcVm==∑(3)LowerboundUpperboundZeroboundtctBBTlowup=)(upBlowBSELECTAggregateFunction(attributes)FROMsensorssWHEREs.
locinRangeREPOCHDURATIONiVALUESWITHINtctBaseStationBaseStation谢磊等:基于分簇的传感器网络数据聚集估算机制1027当初始时窗口中缓存数据少于m个缓存数据时,估算值Vc则取窗口中所有数据的平均值.
这种基于缓存窗口的估算模型相比于文献[69]中提出的估算模型更为简单,有效降低了节点的计算复杂度.
同时,通过窗口机制维护估算数据的稳定,减少了感知数据剧烈动荡或接收到错误数据(outlierdata)对估算数据产生的影响.
基于缓存窗口估算模型,我们结合分簇的路由结构建立一套具有层次结构的估算机制,如图5所示.
Fig.
5Cluster-Basedhierarchicalapproximatearchitecture图5基于分簇的层次估算架构图5所示的基于分簇的层次估算架构针对网内聚集的实现,分为两个处理层次:第1个层次在每个簇内部实现,簇头CHj对簇内Nj个成员中每个节点产生的感知数据Vi进行聚集,获得部分聚集数据PSRj,第2个层次在所有k个簇头和基站之间实现,在基站对每个簇头产生的PSR进行聚集:1jNjiiPSRV==∑(4)1kjjAggValuePSR==∑(5)因此,CASA估算机制针对这两个聚集层次,分别提出了两个层次上的估算方案:在簇内聚集层次,对簇内原始感知数据进行估算,维护估算误差α;在簇间聚集层次,对部分聚集数据PSR进行估算,维护估算误差β.
在每个层次内均一的误差分配机制下,存在下面的误差分配关系:11()jNuplowuplowijBBBBNαα=∑(6)11()kuplowuplowjBBBBkββ=∑(7)这种具有层次结构的聚集数据估算机制,分别在原始感知数据和部分聚集数据层次进行估算操作:在原始感知数据层次进行估算操作,有效地降低了大量簇内成员节点向簇头节点传输数据的能量开销;在部分聚集数据层次进行估算操作,由于簇头节点相对基站的距离往往远大于簇内通信的距离,其通信开销相对簇内传输要高很多,通过估算机制降低了簇头与基站通信的概率,从而达到高效节能的目的.
CASA估算机制不仅适用于类似于LEACH[11]的两跳分簇路由结构,也适用于类似于DEEG[12]的簇头之间以多跳方式传输数据的分簇路由结构,其差别仅在于对前者簇间聚集层次估算适用于所有簇头节点,对后者簇间聚集层次估算适用于簇头节点组成多跳路由的所有叶节点,因此,对于不同分簇路由结构具有良好的可扩展性.
下文中为了便于讨论CASA估算机制的性质,以LEACH分簇路由结构为模型进行分析,但其相关性质同样适用于其他分簇路由结构.
下面我们通过定理证明,这种层次结构的聚集数据估算机制的总体误差tct接近于两层误差之和α+β.
定理1.
当Cαβ+≤(C为常数)时,有总体误差(),tctαβ≈+且有2()/4tctCαβ+≤.
证明:根据相对误差α,β的定义,有0(Blow,Bup)*αi,如果成立,则向簇头发送数据Vi,簇头递增刷新次数Ui,成员节点和簇头同时更新Vci,维持误差αi不变;否则,成员节点无须向簇头发送数据Vi,成员节点和簇头同时利用上次估算值更新Vci,并缩小误差αi,有:αi=αi*(1θ),θ为设定的缩小比例,0α*|BupBlow|)Vci=[Vci*(m1)+Vi]/mV′i=ViUi=Ui+1elseVci=[Vci*(m1)+V′i]/mendifendwhileCalculateparametersforprobabilityfunctionP(α)andP′(β)[kopt,αopt]=calculateOptimalClusterSize(P(α),P′(β))Send[kopt,αopt,βopt]toeachsensornodeiSensorNodeSide:while(thetimer(T)forlearningphaseisnotexpired)VigetLocalSensorData()sendVitothebasestationendwhilereceive[kopt,αopt,βopt]fromthebasestationP=kopt/Ngeneratearandomnumbern,where0P)electitselftobetheclusterhead,broadcastHEAD_AD_MSGtoneighbournodeselsewaitforHEAD_AD_MSGandjointhefirst-heardclusterheadendif谢磊等:基于分簇的传感器网络数据聚集估算机制10311jNjijiSUMAvgNααα===∑(24)对于基站节点,基站为每个簇j维护一个负荷指数Wj,用来刻画每个簇的总体负荷:()()()()jjrAvgCAvgPNWAvgAvgEα=(25)基站在每T轮根据Wj为各簇重新分配误差区间,首先保证分配各簇的误差下界值SUMj(α),对剩下的误差区间ΔD根据权重按比例为每个簇j分配Δdj,即有:1()kjjDNSUMΔαα=26)111()kjjjjkkjjjjjWWdDNSUMWWΔΔαα=====∑∑∑(27)在完成分配计算后,基站将为各簇分配的误差区间Δdj发送给相应的簇头.
在每T轮,簇头根据基站分配出的误差区间Δdj,在簇内为每个成员节点分配误差量.
簇头以每个成员节点的负荷指数Bi为权重,为每个节点再次按权重比例分配富余的误差值Δαi,对分配到富余误差值的成员节点i更新其误差值αi.
1111()jjkijiijjNNkjiijjjjBWBdNSUMBBWΔαΔαα======∑∑∑∑(28)通过对每个节点以负荷指数为权重分配富余误差值的策略,使得当前簇内通信能耗较高并且误差分配量相对较小的那些节点能够获得较大的富余误差量补给,能够有效地均衡各节点的负荷并且降低整体网络通信开销.
自适应误差分配的算法流程如图7所示.
3.
5自适应误差分配机制分析第3.
4节提出了自适应的误差分配方案,其目的是为了均衡各节点间的通信负载,同时有效降低整体的网络通信能耗.
下面我们来证明在簇内聚集估算层次自适应误差分配方案的节能效果是接近理论最优的.
定理3.
在簇内聚集估算层次自适应误差分配方案的节能效果收敛于非均一误差分配的理论最优方案.
证明:考虑在簇内聚集估算层次采用非均一的误差分配方案,如何在固定的总体误差范围内合理分配误差以使簇内聚集层次总体通信能耗最低,便成为一个优化问题.
我们使用效用函数(utilityfunction)C(α)来表示簇内聚集层次总体通信能耗:1()()NkiiiCCPαα==∑(29)C(α)包括Nk个成员节点的通信开销,Ci为节点i的通信开销,P(αi)为节点i的通信概率,αi为分配给节点i的误差量,根据式(20)可以推导出对于所有的成员节点误差,其满足约束关系:1()NkiiNtctNααβ=∑(30)其中,tctβ即为簇内聚集估算分配的误差量α,在这里为常数.
我们的优化问题便为如何在满足约束关系(32)的前提下调整αi以最小化总体能量开销C(α)的数值.
针对这样的优化问题,我们可以利用拉格朗日乘子法[17](Lagrangemultiplier)计算最优解,存在目标函数f(α)=C(α):1()()NkiiifCPαα==∑(31)以及约束函数g(α):1()()NkiigtctNααβ==∑(32)1032JournalofSoftware软件学报Vol.
20,No.
4,April2009Fig.
7Pseudo-Codeforadaptivetoleranceallocatealgorithm图7自适应误差分配算法伪码构造辅助函数Ffgααλα=,λ为某一常数,则根据拉格朗日乘子法有()0Fαα=,我们得到:1()()NkiiiiCPNkαλα==∑(33)根据随机行走的模型,对P(αi)有:221()(2)iiPsαα≈,根据上式我们得到下面的约束关系:()iiiCPDαλα=(34)其中,Dλ为常数,D=1/2.
由负荷指数Bi的定义,存在下面的等式关系:()iiiiCPBDαλα==(35)上式表明,当所有节点的负荷指数趋向于一个相等的常数时,总体通信能耗最低,而根据我们的自适应误差分配方案,通过在数据变化快,即P(αi)高的节点上逐步提高误差αi的取值,以及在数据变化慢,即P(αi)低的节点上逐步降低误差αi取值的方式,最终能够使所有节点的负荷指数Bi收敛于一个相等的数值,使得整体能耗最低.
由定理3我们得知,通过自适应误差分配方案,其节能效果最终可以收敛于非均一误差分配的理论最优方案.
其收敛速度受到自适应调整的时间间隔T的影响,考虑到调整的时间间隔T越小,其收敛速度越快,但同时带AlgorithmforBaseStation.
round=0if(round==0)receiveAvg(Ci)fromeachclusterround=round+1endifforeachround>0receivePSRjfromeachclusterjwithapproximateschemeif(round%T==(T1))receiveAvgj(Er),Avgj(P),Avgj(α)fromeachclusterjendifif(round%T==0)calculateWiandnewallocatedΔdjforeachclusterjsendΔdjtoeachclusterheadjendifround=round+1endforAlgorithmforClusterMember.
round=0if(round==0)sendCitoitsclusterheadround=round+1endifforeachround>0VigetLocalSensorData()if(|ViVci|>(Blow,Bup)*αi)Vci=[Vci*(m1)+Vi]/mV′i=VisendVitoitsclusterheadelse(1)iiααθ=Vci=[Vci*(m1)+V′i]/mendifif(round%T==(T1))sendEritotheclusterheadendifif(round%T==0)receivenewallocatedΔαiαi=αi+Δαiendifround=round+1endforAlgorithmforClusterHead.
round=0if(round==0)receiveCifromeachnode,calculateAvg(Ci)andsendAvg(Ci)tobasestationround=round+1endifforeachround>0if(receiveVifrommembernodei)Vc=[Vci*(m1)+Vi]/mV′i=ViUi=Ui+1else(1)iiααθ=Vci=[Vci*(m1)+V′i]/mendifcalculatePSRjandsendPSRjtothebasestationwithapproximateschemeif(round%T==(T1))calculateAvgj(Er),Avgj(P)andAvgj(α)andsendtobasestationendifif(round%T==0)receiveallocatedtoleranceΔdjfrombasestation,calculateBiandnewallocatedΔαiforeachnodesendΔαitonodeiendifround=round+1endfor谢磊等:基于分簇的传感器网络数据聚集估算机制1033来的控制信息传输开销也会越大.
因此,选择合适的自适应调整的时间间隔T对提高自适应误差分配方案的节能性能有很重要的影响,这将成为我们下一步研究工作需要考虑的问题.
4性能评价4.
1模拟实验环境设置和参数本节通过模拟实验来对CASA估算机制的性能进行评估,我们基于Glomosim模拟实验平台实现了本文提出的估算算法.
实验设备是一台运行WinXP,具有P4处理器、1G内存的PC.
模拟实验环境中节点随机分布在大小为100*100(m2)的监测区域内,部署节点总数为100.
实验中,我们使用随机行走模型(randomwalkmodel)来模拟生成感知数据,其中使用随机度(randomnessdegree)来描述感知数据相比前一轮样本发生变化的概率,使用随机步长(randomstepsize)来描述每次数据变化的幅度,用百分比表示.
具体的实验参数设置见表1.
我们通过以下方面来评估CASA的性能:首先通过性能对比来验证估算架构的节能效果,然后通过实验结果验证最优分簇规模算法的有效性,最后通过性能对比来对自适应误差分配方案的节能效果进行验证.
Table1Parametersofsimulation表1模拟实验参数列表ParameterValueParameterValueArea(m2)100*100Randomdegree0.
0~1.
0,0.
5defaultNumberofnodes100Randomstepsize0.
0~1.
0,0.
5defaultBasestationposition(50,100),(50,150),(50,200)(Blow,Bup)(10,40)Packetsize(bits)4000Eelec(nJ/bit)50Numberofrounds1000εfs(pJ/bit/m2)13TctreallocateintervalT10εmp(pJ/bit/m4)0.
0013tct0%~30%,10%(default)dcrossover(m)75Initialenergy(J)2Standarddeviationα0.
05Windowsize1~10,5default4.
2估算架构的性能验证图8给出了在不同误差tct情况下各种数据收集机制的性能比较.
我们针对随机生成的同一节点分布分别构造出传统的树形路由结构和分簇的路由结构,在这两种不同的路由结构上,我们分别实现带有估算机制的传输方案和不带有估算机制的传输方案.
可以看到,在没有估算机制的支持下,传统的树形路由和分簇路由方案需要大量的能量开销,而使用估算机制的树形路由方案在tct=0.
2时,可以减少40%的能量开销,相比于前3种方案,可以看到,基于分簇路由的CASA估算机制能够进一步有效地降低网络的能量开销,在tct=0.
2时,相比树形结构的估算方案能够进一步减少38%的能量开销.
图9给出了具有不同误差的分簇估算机制的性能受数据变化率的影响,随着随机度RD的增加,数据的变化率进一步加快.
可以看到,不使用估算机制的分簇方案不受任何影响,但一直处于一个高能耗开销的水平42J,使用估算机制的分簇方案的能耗开销随之增长,此时具有更大误差量的估算方案(tct=0.
3)相比于小误差量的估算方案(tct=0.
1),面对较高的数据变化率有更好的节能效果.
在RD=0.
9时,前者比后者可以节省53%的能量开销,但即使在这种情况下,tct=0.
1的估算方案相比不使用估算机制的分簇方案仍能减少31%的能量开销.
图8和图9的实验结果表明,基于分簇的估算架构在不同数据变化率的观测环境下都能够有效降低网络的总体能耗.
图10描述了缓存窗口大小面对不同数据变化幅度时对估算机制节能效果的影响,实验中,我们利用数据变化的随机步长RSS来调整数据的变化幅度.
可以看到,对于较小的数据变化幅度,不同缓存窗口大小的估算机制具有基本相同的能量开销,随着变化幅度的进一步增大,当RSS=0.
9时,具有较小窗口的估算机制(windowsize=1)能量开销高达43J,而同时具有较大窗口的估算机制(windowsize=10)其能量开销也有38J.
相比而言,窗口大小适中的估算机制(windowsize=5)则仅有31J的能量开销.
这是因为,对于较小窗口的估算机制,由于只缓存为数很少的数据,因此估算值受数据波动的影响非常大,总是受制于最新接收的波动数据,估算效果受到极大影响.
而对于较大窗口的估算机制,由于其缓存过多的历史数据,估算值受历史数据影响,其变化非常缓慢,不能及时反映当前数据的变化状况,估算效果也受到很大影响.
窗口大小适中的估算机制,由于既能及时反映当前数据的变化状况,又能不受数据波动的太大影响,能够达到很好的节能效果.
因此,图101034JournalofSoftware软件学报Vol.
20,No.
4,April2009的实验结果表明,选择合理的估算窗口大小对估算机制的节能效果有很重要的影响.
Fig.
8Energyconsumptionvs.
tctFig.
9Energyconsumptionvs.
randomdegree图8不同估算机制的能量消耗图9能量消耗与随机度的关系Fig.
10Energyconsumptionvs.
cachewindowsize图10能量消耗与缓存窗口大小关系4.
3最优分簇算法的验证图11给出了分簇规模对网络总体能耗的影响.
我们将分簇数量在1~50间加以变化,可以看到,当分簇数量在6~10之间时能够使传感器网络达到整体最低能量消耗约24J,而我们在基站通过最优分簇规模计算方法计算出的kopt=8正好处在这个范围之内,通过实验数据有效验证了最优分簇规模计算方法的有效性.
图12进一步给出了基站位置对kopt和α取值的影响.
可以看到,随着基站位置进一步远离观测区域,kopt和α的取值都相对减少.
这是因为,随着基站位置的进一步远离,簇头与基站之间的通信开销逐步增大,而根据CASA基于层次结构的估算机制,进一步降低kopt有助于减少簇头数量,从而降低簇头与基站通信的整体开销,进一步降低簇内聚集估算误差α,从而提升簇间聚集估算误差β,有助于充分利用PSR的估算机制有效降低簇头与基站通信的概率,达到降低总体通信能耗的效果.
图11和图12的实验结果充分验证了最优分簇规模算法的有效性.
0.
100.
150.
200.
250.
30tct454035302520151050Overallenergyconsumption(J)TreebasedroutingClusterbasedroutingTreebasedroutingwithtctClusterbasedroutingwith0.
00.
20.
40.
60.
81.
0Randomdegree50454035302520151050Overallenergyconsumption(J)ClusterbasedroutingwithnotctClusterbasedroutingwithtct=0.
1Clusterbasedroutingwithtct=0.
2Clusterbasedroutingwithtct=0.
3Overallenergyconsumption(J)0.
00.
20.
40.
60.
81.
0Randomstepsize454035302520151050Windowsize=1Windowsize=5Windowsize=10谢磊等:基于分簇的传感器网络数据聚集估算机制1035Fig.
11Energyconsumptionvs.
clustersizeFig.
12BSlocationvs.
koptandα图11能量消耗与分簇规模的关系图12基站位置与kopt和α的关系4.
4自适应误差分配方案的性能验证在本节性能验证实验中均设定tct=0.
1,感知数据变化率均方差α=0.
05,自适应调整的时间间隔T=10.
图13给出不同误差分配方案的能量消耗对比.
实验中,我们构造出3种估算传输方案,分别为均一的误差分配方案、自适应的误差分配方案和理论最优的非均一误差分配方案,对于理论最优的非均一误差分配方案,其参数是根据当前的各节点区域的变化数值计算而得.
可以看到,自适应的误差分配方案其能量消耗在round=0时与均一的误差分配方案有相同的能量开销,随着轮数的递增,自适应的误差分配方案能够逐步调整误差分配,降低能量开销,逐渐收敛于非均一方案最优配置.
可以看到,在T=10时,其收敛速度还是很快的,在round=1000时,其能量开销已经十分接近非均一方案最优配置的能量开销,此时,自适应的误差分配方案比均一的误差分配方案能够减少24%的能量开销.
图14给出不同误差分配方案网络寿命的对比.
这里,我们分别构造出不使用估算机制的分簇路由方案、使用均一误差的分配方案以及使用自适应的误差分配方案.
我们定义网络寿命为网络中第1个节点死亡的时间.
可以看到,对于不使用估算机制的分簇路由方案,其网络寿命为372,使用均一误差分配方案的网络寿命为596,而使用自适应的误差分配方案网络寿命为674,图13和图14的实验表明,自适应的误差分配方案不仅能够迅速收敛于最小化整体通信能耗的方案,同时能够通过均衡各节点的负载,有效地延长网络的寿命.
Fig.
13EnergyconsumptionfordifferenttoleranceFig.
14Measurementofnetworklifetimeallocationstrategies图13不同误差分配方案的能量消耗图14网络寿命的比较100908070605040302001020304050NumberofclustersOverallenergyconsumption(J)BSlocationα02004006008001000Numberofround2826242220181614121086420Energyconsumptionperround(103J/perround)UniformtoleranceallocationAdaptivetoleranceallocationOptimalnon-uniformtoleranceallocation02004006008001000Numberofround100806040200NumberofnodesaliveClusterbasedroutingClusterbasedroutingwithuniformtctClusterbasedroutingwithadaptiveadjustedtct1036JournalofSoftware软件学报Vol.
20,No.
4,April2009图15分析了地区性数据变化差异程度对不同误差分配方案性能的影响,实验通过调整感知数据变化率均方差σ来改变数据变化差异程度.
可以看到,均一的误差分配方案不受任何数据变化差异程度的影响,始终维持一个较高的能耗水平25.
2J,而自适应的误差分配方案随着地区数据的变化,其差异程度逐渐增加,能够更为有效地利用非均一的误差分配方案来更合理地分配误差以降低网络通信开销,在具有较大的地区数据变化差异程度α=0.
1时,自适应的误差分配方案能够比均一的误差分配方案节省33%的能量开销.
Fig.
15Impactofdeviationfordatachangerates图15数据变化差异对能耗的影响5总结和下一步工作本文针对传感器网络的网内聚集问题提出了一种基于分簇层次结构的估算机制CASA.
CASA采用最优分簇规模参数,在基于分簇的网内聚集估算架构中能够最小化网络节点的总体通信开销.
此外,CASA考虑到部署区域感知数据变化率的差异性,采用自适应的误差分配方案进一步降低网络节点的通信开销,维护节点间的负载均衡.
实验结果表明,CASA估算机制能够显著提升传感器网络网内聚集机制的节能性能,同时保证聚集数据的精确程度.
在下一步的研究工作中,我们考虑将该估算机制由基于LEACH的两跳分簇路由结构进一步应用到更为普遍的多跳分簇路由结构中,研究如何在多个层次结构间以及层次结构内分配估算误差,决定最优的α,β误差分配参数;同时对自适应调整机制,将进行对自适应调整时间间隔T最优取值的研究,以充分提高节能效果.
References:[1]HillJ,CullerD.
Mica:Awirelessplatformfordeeplyembeddednetworks.
IEEEMicro,2002,22(6):1224.
[2]GehrkeJ,MaddenS.
Queryprocessinginsensornetworks.
IEEEPervasiveComputing,2004,3(1):4655.
[3]LiJZ,LiJB,ShiSF.
Concepts,issuesandadvanceofsensornetworksanddatamanagementofsensornetworks.
JournalofSoftware,2003,14(10):17171727(inChinesewithEnglishabstract).
http://www.
jos.
org.
cn/1000-9825/14/1717.
htm[4]KrishnamachariB,EstrinD,WickerSB.
Theimpactofdataaggregationinwirelesssensornetworks.
In:Proc.
ofthe22ndInt'lConf.
onDistributedComputingSystems.
Washington:IEEEComputerSociety,2002.
575578.
[5]MaddenS,FranklinMJ,HellersteinJM,HongW.
TAG:Atinyaggregationserviceforad-hocsensornetworks.
In:Proc.
oftheOSDI.
2002.
http://doi.
acm.
org/10.
1145/844128.
844142[6]SharafMA,BeaverJ,LabrinidisA,ChrysanthisPK.
TiNA:Aschemefortemporalcoherency-awarein-networkaggregation.
In:Proc.
oftheMobiDE.
2003.
6976.
http://doi.
acm.
org/10.
1145/940923.
940937[7]HellersteinJM,HongW,MaddenS,StanekK.
Beyondaverage:Towardsophisticatedsensingwithqueries.
In:Proc.
oftheIPSN.
2003.
6379.
0.
000.
020.
040.
060.
080.
10Standarddeviationamongdatachangerates2520151050Overallenergyconsumption(103J/perround)UniformtoleranceallocationAdaptivetoleranceallocation谢磊等:基于分簇的传感器网络数据聚集估算机制1037[8]DeshpandeA,GuestrinC,MaddenS,HellersteinJM,HongW.
Model-Basedapproximatequeryinginsensornetworks.
VLDBJournal,2005,14(4):417443.
[9]TuloneD,MaddenS.
PAQ:Timeseriesforecastingforapproximatequeryansweringinsensornetworks.
In:Proc.
oftheEWSN.
2006.
2137.
[10]DemersAJ,GehrkeJ,RajaramanR,TrigoniA,YaoY.
Thecougarproject:Awork-in-progressreport.
SIGMODRecord,2003,32(4):5359.
[11]HeinzelmanWB,ChandrakasanAP,BalakrishnanH.
Anapplication-specificprotocolarchitectureforwirelessmicrosensornetworks.
IEEETrans.
onWirelessCommunications,2002,1(4):660670.
[12]LiuM,GongHG,MaoYC,ChenLJ,XieL.
Adistributedenergy-efficientdatagatheringandaggregationprotocolforwirelesssensornetworks.
JournalofSoftware,2005,16(12):21062116(inChinesewithEnglishabstract).
http://www.
jos.
org.
cn/1000-9825/16/2106.
htm[13]ShenB,ZhangSY,ZhongYP.
Cluster-Basedroutingprotocolsforwirelesssensornetworks.
JournalofSoftware,2006,17(7):15881600(inChinesewithEnglishabstract).
http://www.
jos.
org.
cn/1000-9825/17/1588.
htm[14]OlstonC,WidomJ.
Approximatecachingforcontinuousqueriesoverdistributeddatasources.
TechnicalReport,ComputerScienceDepartment,StanfordUniversity,2002.
http://dbpubs.
stanford.
edu/pub/2002-8[15]GoelS,ImielinskiT.
Prediction-Basedmonitoringinsensornetworks:TakinglessonsfromMPEG.
ACMSIGCOMMComputerCommunicationReview,2001,31(5):8298.
[16]XieL,ChenLJ,ChenDX,XieL.
Aclustering-basedapproximationschemeforin-networkaggregationoversensornetworks.
In:Proc.
oftheUIC.
2007.
503513.
[17]StewartJ.
Calculus:EarlyTranscendentals.
2nded.
,Brooks/Cole,1991.
附中文参考文献:[3]李建中,李金宝,石胜飞.
传感器网络及其数据管理的概念、问题与进展.
软件学报,2003,14(10):17171727.
http://www.
jos.
org.
cn/1000-9825/14/1717.
htm[12]刘明,龚海刚,毛莺池,陈力军,谢立.
高效节能的传感器网络数据收集和聚合协议.
软件学报,2005,16(12):21062116.
http://www.
jos.
org.
cn/1000-9825/16/2106.
htm[13]沈波,张世永,钟亦平.
无线传感器网络分簇路由协议.
软件学报,2006,17(7):15881600.
http://www.
jos.
org.
cn/1000-9825/17/1588.
htm谢磊(1982-),男,江苏南通人,博士生,主要研究领域为分布式计算,传感器网络技术.
陈道蓄(1947-),男,教授,博士生导师,CCF高级会员,主要研究领域为分布式计算.
陈力军(1961-),男,博士,教授,主要研究领域为移动网络,分布式计算.
谢立(1942-),男,教授,博士生导师,CCF高级会员,主要研究领域为分布式计算,网络安全.
TNAHosting($5/月)4核/12GB/500GB/15TB/芝加哥机房
TNAHosting是一家成立于2012年的国外主机商,提供VPS主机及独立服务器租用等业务,其中VPS主机基于OpenVZ和KVM架构,数据中心在美国芝加哥机房。目前,商家在LET推出芝加哥机房大硬盘高配VPS套餐,再次刷新了价格底线,基于OpenVZ架构,12GB内存,500GB大硬盘,支持月付仅5美元起。下面列出这款VPS主机配置信息。CPU:4 cores内存:12GB硬盘:500GB月流...

VirMach:$27.3/月-E3-1240v1/16GB/1TB/10TB/洛杉矶等多机房
上次部落分享过VirMach提供的End of Life Plans系列的VPS主机,最近他们又发布了DEDICATED MIGRATION SPECIALS产品,并提供6.5-7.5折优惠码,优惠后最低每月27.3美元起。同样的这些机器现在订购,将在2021年9月30日至2022年4月30日之间迁移,目前这些等待迁移机器可以在洛杉矶、达拉斯、亚特兰大、纽约、芝加哥等5个地区机房开设,未来迁移的时...
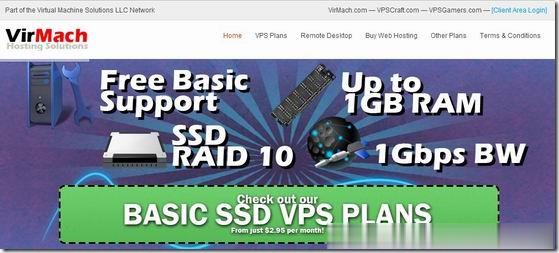
简单测评melbicom俄罗斯莫斯科数据中心的VPS,三网CN2回国,电信双程cn2
melbicom从2015年就开始运作了,在国内也是有一定的粉丝群,站长最早是从2017年开始介绍melbicom。上一次测评melbicom是在2018年,由于期间有不少人持续关注这个品牌,而且站长貌似也听说过路由什么的有变动的迹象。为此,今天重新对莫斯科数据中心的VPS进行一次简单测评,数据仅供参考。官方网站: https://melbicom.net比特币、信用卡、PayPal、支付宝、银联...
网络网为你推荐
-
支付宝蜻蜓发布蜻蜓支付怎样实现盈利重庆电信断网为什么重庆电信沙坪坝天星桥这网络老是掉线cisco2960配置思科的交换机怎么配置ldapserverLDAP3是什么银花珠树晓来看下雪喝酒的诗句科创板首批名单中国兰男队员名单泉州商标注册泉州本地商标注册要怎么注册?具体流程是什么?123456hd手机上有电话的标志,后面有个HD是什么意思什么是通配符什么是直女癌?艾泰科技艾泰的品牌介绍