NCBImediawiki
mediawiki 时间:2021-04-13 阅读:()
Wikidata:AplatformfordataintegrationanddisseminationforthelifesciencesandbeyondElviraMitraka1,AndraWaagmeester2,SebastianBurgstaller-Muehlbacher3,LynnM.
Schriml1,AndrewI.
Su3,BenjaminM.
Good3UniversityofMarylandSchoolofMedicine,Baltimore,USA{emitraka,lschriml}@som.
umaryland.
eduMicelio,Antwerp,Belgiumandra@micelio.
beDepartmentofMolecularandExperimentalMedicine,ScrippsResearchInstitute,LaJolla,USA{sburgs,asu,bgood}@scripps.
eduAbstract.
Wikidataisanopen,SemanticWeb-compatibledatabasethatanyonecanedit.
This'datacommons'providesstructureddataforWikipediaarticlesandotherapplications.
EveryarticleonWikipediahasahyperlinktoaneditableiteminthisdatabase.
Thisuniqueconnectiontotheworld'slargestcommunityofvolunteerknowledgeeditorscouldhelpmakeWikidataakeyhubwithinthegreaterSemanticWeb.
Thelifesciences,asever,facescrucialchallengesindisseminatingandintegratingknowledge.
OurgroupisaddressingtheseissuesbypopulatingWikidatawiththeseedsofafoundationalsemanticnetworklink-inggenes,drugsanddiseases.
Usingthiscontent,weareenhancingWikipediaarticlestobothincreasetheirqualityandrecruithumaneditorstoexpandandimprovetheunderlyingdata.
Weencouragethecommunitytojoinusaswecollaborativelycreatewhatcanbecomethemostusedandmostcentralseman-ticdataresourceforthelifesciencesandbeyond.
Keywords:Wikidata,Wikipedia,LinkedData,SemanticWeb,Crowdsourcing,KnowledgeManagement1StoneDataSoupIntheStoneSoupfolktale[1],agroupofhungrytravelersarriveinavillagewithitsinhabitantsunwillingtosharetheirfood.
Withakettleofwaterandastonethetravelersmanagetotouchthecuriosityofthevillagers.
Thecuriosityfinallyspawnsacollaborativeefforttomakeagreatsoup.
Thisstoryisnowadaysusedtoexpressthepowerofcrowdsourcingandcollaborativeprojects[2],suchasWikipedia,wheremanyindividualseachmakesmallcontributionsbutcollectivelyproducesomethinglargerthanthesumofitsparts.
WikidataextendsthiscollaborativemodeltotheWebofdata[3].
InthisarticlewewilldescribeWikidataandthewaysthatthisopenpublicplatformcantakeacentralroleindatasharingandmanagementforthelifesciencecommunity.
2WikidataandWikipediaWikipediaisamongthemostvisitedsitesontheInternet.
Articlesaboutmedicaltopicswereviewedmorethan4.
88billiontimesin2013,anumberonparwithhttp://nih.
govandsignificantlygreaterthanWebMD[4].
Thisincrediblyimportantresource,createdthroughvolunteerlabor,isnowtightlycoupledtoWikidata-anopen,SemanticWeb-compatibledatabasethatanyonecanedit[3].
Wikipediainfoboxes-thetablesofdataoftenappearingontherightsideofarticles-cannowrendercontentstoredinWikidataandeachWikipediaarticlenowhasadirectlinktothecorrespondingWikidataitem,thusencouragingthecollaborativeeditingofthedata(Fig.
1).
Fig.
1.
Wikidataprovidesacentralizedresourceforstructureddata.
Applicationsincluding,butnotlimitedto,WikipediacannowreadandwritetoWikidata.
Infoboxesprovidethebridgebetweenmachine-readablestructureddataandtheunstructuredtextthatformsthemainbodyofeacharticle.
Since2008,theGeneWikiprojecthasautomaticallycreatedandmaintainedtheinfoboxesforaround10000articlesabouthumangenes[5].
Now,thisinitiativeisfocusedongeneratingafoundationofbiomedicalknowledgeinWikidatathatwillbeusedtoimproveinfoboxcontentonWikipediaandhelpdrivenewapplications.
Todate,wehaveloadedWikidatawithitemsabout:56451humanand73086mousegenesfromNCBIGene[6],6562conceptsintheDiseaseOntology[7],and1830FDA-approveddrugs.
ThisinitialdataloadgeneratedWikidataitemsforthesekeybiomedicalconcepts,mappedthemtoWikipediaarticlesandlinkedthemtothecorrespondingidentifiersinauthori-tativepublicdatabases.
Theidentifier-levelconnectionstothesourcedatabasesen-surethatWikidatacontentcanbeeasilyintegratedintotheexistingWebofbiomedi-caldata.
Moreover,theprovenanceofallWikidataclaimscanbeassessedthroughinspectionofthesupportingreferences.
Thedataiskeptuptodatebyperiodicallyrunning'bots'thatpropagatechangesfromauthoritativesourcestoWikidata.
WhenconflictsarisefromhumaneditstoWikidataitems,theseareflaggedformanualre-view.
Thenextphaseoftheprojectwillstitchtheseconceptsintoarichlyintercon-nectedsemanticnetwork.
3Takingasipofthedatasoup–WikidataandtheSemanticWebThefirstapplicationtouseWikidataextensivelyisWikipediabutthiscouldbethetipoftheiceberg.
TogiveapreviewofwhatWikidatacouldbecome,it'suse-fultobrieflyexamineitsclosestancestor,DBpedia.
TheDBpediaprojectminescon-tentfromWikipediabyparsinginfoboxes,mapsthiscontenttotheirownontology,andprovidesaccesstothisdataintheformofalargeRDFdatabaseavailablebothforbulkdownloadandSPARQLquery.
Whileenablinginterestingqueriesonitsown,itsmostimportantfunctionisasagloballinkinghubfortheSemanticWeb[8].
IncomparisontoDBpedia,Wikidatahasanumberofadvantages.
First,itcanbeediteddirectlyandchangesarereflectedinrealtime.
Second,itdoesnotrequireanyparsingbecausealldataismanagedinadatabasefromtheoutset.
Third,itcontainslargeamountsofcontentthatisnotpresentinWikipedia,suchasitemsforeverymousegene.
Finally,itsqueryAPIsupportsnotonlyqueriesalongitsassertedknowledgegraph,butalsoalongreferences,qualifiersandevenedithistories.
Theseadditionalcapabilities,viewedinlightofthesuccessoftheDBpediaproject,portendavitalfutureforWikidatainthecontextoftheSemanticWeb.
Withinthebiomedicaldomain,usefulqueriesarealreadypossibleasaresultofthe'single-pot'natureofWikidata.
Forexample,itispossibletouseWikidata'sSPARQLendpoint(https://query.
wikidata.
org/)toanswerquestionssuchas"whatclinicallyrelevantdrug-druginteractionsareknownforthedrugmethadone(CHEMBL651)"[9].
Importantly,thedatausedtoanswerthisquerycamefromtwogroupsworkingcompletelyindependently.
Our'drug_bot'botaddedtheCHEMBLidentifiers(aswellasmanyotheridentifiers)whileanotherbotdevelopedbyateamattheMedicalUniversityofViennaaddedthedrug-druginteractions[10].
Thishap-penedwithoutanydirectcoordinationbetweenourgroups.
Thiskindofserendipitous,automatic,cross-continentaldataintegrationistheprimarygoaloftheSemanticWeb,butisnotyetcommonplace.
ThekeybeautyandmainchallengeoftheSemanticWebisitsdistributednature.
InorderforthiskindofintegrationtohappenintheabsenceofacentralizedresourcelikeWikidata,severalmajorhurdleswouldneedtobeleaped.
First,bothteamswouldneedtoknowenoughaboutthefairlycomplexstackofsemantictechnologiestoprovidetheirdataasRDFthroughastable,publicSPARQLendpoint.
Second,theywouldhavetoworkwithoverlappingidentifiersystems.
Third,thewould-beconsumeroftheirdatawouldneedtodiscoverbothoftheirendpointsandbesophisticatedenoughwithSPARQLtoidentifyandissuetheappropriatedistributedquery.
Allofthisispossi-bleandcanwork,butitisnoteasy.
Byintegratingdatainacentralized,singlecommunitypot,Wikidatapro-videsaplatformthataddresseseachoftheseproblems.
DataprovidersdonothavetosetupandmaintaintheirownSPARQLendpoint–achallengethatveryfewteamshavesucceededatdoingforanylengthoftime[11].
Byvirtueofworkinginthesamedatabase,itisfarlesslikely-thoughnotimpossible-forindependentteamstogener-ateandpublishdifferentidentifiers,asthefirststepinworkingwithWikidataistoqueryittoseewhatisalreadythere.
Finally,thechallengeoffindingarelevantend-pointisnegatedwhenthereisonlyone.
NotethatWikidatacanbequeriedusingSPARQLortheWikidataQueryLanguage[12].
4ManyCooks.
.
.
ThefactthatWikidataisonecentralized,communityresourceimmediatelysurfacesthechallengesincurredinanycollaborativeontologydevelopmentpro-cess.
InWikidata,the'ontology'correspondstoitscollectionoflinkingpropertiesusedtodescribeitems.
AnewpropertyinWikidatahastobeproposedforcommuni-tydiscussionandisonlycreatedafteraconsensusregardingthevalueofthepropertyanditsrelationtoexistingpropertieshasbeenestablished.
Forthoseusedtocontrol-lingtheirowndataanddatamodels,thisprocesscanfeeltedious.
Butthissamefun-damentalprocessmustbeundertakeninanyattemptatdataintegration.
Thefactthatithappensupfront,whendataisfirstbeingloaded,shouldhelptokeepthedatacon-sistentandreducethedownstreamidentifierandontologicalmappingproblemsthatcontinuetoplaguebioinformatics.
ImaginethepowerofcombiningthestructureddatainWikidata,thehighaccessibilityanddedicatedcommunityofWikipediaandtheknowledgeofthescien-tificcommunity.
Contemplatefurtherthatallofthisdataisfreelyavailableandac-cessiblethroughastablequeryinterfaceandrobust,read/writeAPI.
Thismakesim-portant,high-qualityinformationeasilyaccessiblebyanyoneandopensupscientificknowledgeforpublicscrutiny.
Further,thebuilt-inprovenancetrackingcanprovidedetailedchainsofevidencetosupportorrefuteeachclaimandallofthiscanbedis-cussedusingthemanysocialtools,suchas'talkpages'foreverydataitem,bakedintotheMediaWikiinfrastructure.
Asidefromcreatingusefulwaystodisseminatedata,thissociotechnicalstructureprovidesaframeworkforthebroadcommunitytobroadcastfeedbackbacktotheoriginaldataowners.
Evenatthisearlystageofthisproject,thisprocesshasalreadyledtoimprovementsinsourcedata.
Forexample,intheDiseaseOntologytheterm'Ollierdisease'hadthesynonym'Maffuccisyndrome'.
UponimportingtheDiseaseOntologyintoWikidata,membersoftheWikidatacommunitypointedoutthatthetwoterms,thoughputativesynonyms,linkedtotwodifferentextantWikidataitems.
Uponcloserreviewitwasdeterminedthatthesetwotermsrepresenttwodif-ferent,albeitcloselyrelated,diseases,leadingtothecreationofanewtermintheDiseaseOntology.
AsWikidataexpandsitistobeexpectedthatadditionaldiffer-encesinrepresentationbetweenitandotherknowledgeresourceswillsurface.
ThesewillfirstbetriagedbytheWikidatacommunitytocheckforerrorsand,ifconsensusisachievedthatthereisanerrorintheoriginalsource,thiswillberelayedforconsid-eration.
Inthisway,theWikidatacommunitycanbecomethe'manyeyes'thatmakeallontologybugsshallow.
5.
.
.
CanMakeaDeliciousSoupWecancreateapowerfulcommonsofbiomedicalknowledgebybuildingonestablishedresourcesandthededicatedcommunitytoconnectgenes,proteins,drugs,diseases,phenotypesandsymptoms.
WikipediawillbethefirstapplicationtousethecontentinWikidata,butcertainlynotthelast.
Thefireisreadyandthepotisstartingtoheatup.
Somevillagersarealreadypeekingoutoftheirwindowsreadytojoinusaroundthepot,butitwilltaketheeffortofthewholecommunitytomakeadeliciousbiomedicaldatasoup.
Weinviteyoutojoinusinthiseffort.
References1.
HistoryoftheStoneSoupStoryfrom1720tonow.
Availablefrom:http://www.
stonesoup.
com/history-of-the-stone-soup-story-from-1720-to-now/.
2.
Taylor.
J.
TheStoneSoupofData.
20078May;Availablefrom:https://km.
aifb.
kit.
edu/ws/ckc2007/StoneSoup-www2007.
pdf.
3.
Vrandei,D.
andM.
Krtzsch,Wikidata:AFreeCollaborativeKnowledgebase,inCommunicationsoftheACM.
2014,ACM.
p.
78-85.
4.
Heilman,J.
M.
andA.
G.
West,Wikipediaandmedicine:quantifyingreadership,editors,andthesignificanceofnaturallanguage.
JMedInternetRes,2015.
17(3):p.
e62.
5.
Huss,J.
W.
,3rd,etal.
,Agenewikiforcommunityannotationofgenefunction.
PLoSBiol,2008.
6(7):p.
e175.
6.
Brown,G.
R.
,etal.
,Gene:agene-centeredinformationresourceatNCBI.
NucleicAcidsRes,2015.
43(Databaseissue):p.
D36-42.
7.
Kibbe,W.
A.
,etal.
,DiseaseOntology2015update:anexpandedandupdateddatabaseofhumandiseasesforlinkingbiomedicalknowledgethroughdiseasedata.
NucleicAcidsRes,2015.
43(Databaseissue):p.
D1071-8.
8.
Bizer,C.
,etal.
,DBpedia-AcrystallizationpointfortheWebofData.
WebSemantics:Science,ServicesandAgentsontheWorldWideWeb,2009.
7(3):p.
154-165.
9.
Getallthedrug-druginteractionsforMethadonebasedonitsCHEMBLidCHEMBL651.
2015[cited2015Sep.
14];Availablefrom:https://bitbucket.
org/sulab/wikidatasparqlexamples/overview#markdown-header-get-all-the-drug-drug-interactions-for-methadone-based-on-its-chembl-id-chembl651.
10.
Pfundner,A.
,etal.
,UtilizingtheWikidatasystemtoimprovethequalityofmedicalcontentinWikipediaindiverselanguages:apilotstudy.
JMedInternetRes,2015.
17(5):p.
e110.
11.
Buil-Arand,C.
,etal.
SPARQLWeb-QueryingInfrastructure:ReadyforActionin12thInternationalSemanticWebConference.
2013.
Sydney,Australia.
12.
WikidataQueryEditor.
[cited2015;Availablefrom:https://wdq.
wmflabs.
org/wdq/.
Schriml1,AndrewI.
Su3,BenjaminM.
Good3UniversityofMarylandSchoolofMedicine,Baltimore,USA{emitraka,lschriml}@som.
umaryland.
eduMicelio,Antwerp,Belgiumandra@micelio.
beDepartmentofMolecularandExperimentalMedicine,ScrippsResearchInstitute,LaJolla,USA{sburgs,asu,bgood}@scripps.
eduAbstract.
Wikidataisanopen,SemanticWeb-compatibledatabasethatanyonecanedit.
This'datacommons'providesstructureddataforWikipediaarticlesandotherapplications.
EveryarticleonWikipediahasahyperlinktoaneditableiteminthisdatabase.
Thisuniqueconnectiontotheworld'slargestcommunityofvolunteerknowledgeeditorscouldhelpmakeWikidataakeyhubwithinthegreaterSemanticWeb.
Thelifesciences,asever,facescrucialchallengesindisseminatingandintegratingknowledge.
OurgroupisaddressingtheseissuesbypopulatingWikidatawiththeseedsofafoundationalsemanticnetworklink-inggenes,drugsanddiseases.
Usingthiscontent,weareenhancingWikipediaarticlestobothincreasetheirqualityandrecruithumaneditorstoexpandandimprovetheunderlyingdata.
Weencouragethecommunitytojoinusaswecollaborativelycreatewhatcanbecomethemostusedandmostcentralseman-ticdataresourceforthelifesciencesandbeyond.
Keywords:Wikidata,Wikipedia,LinkedData,SemanticWeb,Crowdsourcing,KnowledgeManagement1StoneDataSoupIntheStoneSoupfolktale[1],agroupofhungrytravelersarriveinavillagewithitsinhabitantsunwillingtosharetheirfood.
Withakettleofwaterandastonethetravelersmanagetotouchthecuriosityofthevillagers.
Thecuriosityfinallyspawnsacollaborativeefforttomakeagreatsoup.
Thisstoryisnowadaysusedtoexpressthepowerofcrowdsourcingandcollaborativeprojects[2],suchasWikipedia,wheremanyindividualseachmakesmallcontributionsbutcollectivelyproducesomethinglargerthanthesumofitsparts.
WikidataextendsthiscollaborativemodeltotheWebofdata[3].
InthisarticlewewilldescribeWikidataandthewaysthatthisopenpublicplatformcantakeacentralroleindatasharingandmanagementforthelifesciencecommunity.
2WikidataandWikipediaWikipediaisamongthemostvisitedsitesontheInternet.
Articlesaboutmedicaltopicswereviewedmorethan4.
88billiontimesin2013,anumberonparwithhttp://nih.
govandsignificantlygreaterthanWebMD[4].
Thisincrediblyimportantresource,createdthroughvolunteerlabor,isnowtightlycoupledtoWikidata-anopen,SemanticWeb-compatibledatabasethatanyonecanedit[3].
Wikipediainfoboxes-thetablesofdataoftenappearingontherightsideofarticles-cannowrendercontentstoredinWikidataandeachWikipediaarticlenowhasadirectlinktothecorrespondingWikidataitem,thusencouragingthecollaborativeeditingofthedata(Fig.
1).
Fig.
1.
Wikidataprovidesacentralizedresourceforstructureddata.
Applicationsincluding,butnotlimitedto,WikipediacannowreadandwritetoWikidata.
Infoboxesprovidethebridgebetweenmachine-readablestructureddataandtheunstructuredtextthatformsthemainbodyofeacharticle.
Since2008,theGeneWikiprojecthasautomaticallycreatedandmaintainedtheinfoboxesforaround10000articlesabouthumangenes[5].
Now,thisinitiativeisfocusedongeneratingafoundationofbiomedicalknowledgeinWikidatathatwillbeusedtoimproveinfoboxcontentonWikipediaandhelpdrivenewapplications.
Todate,wehaveloadedWikidatawithitemsabout:56451humanand73086mousegenesfromNCBIGene[6],6562conceptsintheDiseaseOntology[7],and1830FDA-approveddrugs.
ThisinitialdataloadgeneratedWikidataitemsforthesekeybiomedicalconcepts,mappedthemtoWikipediaarticlesandlinkedthemtothecorrespondingidentifiersinauthori-tativepublicdatabases.
Theidentifier-levelconnectionstothesourcedatabasesen-surethatWikidatacontentcanbeeasilyintegratedintotheexistingWebofbiomedi-caldata.
Moreover,theprovenanceofallWikidataclaimscanbeassessedthroughinspectionofthesupportingreferences.
Thedataiskeptuptodatebyperiodicallyrunning'bots'thatpropagatechangesfromauthoritativesourcestoWikidata.
WhenconflictsarisefromhumaneditstoWikidataitems,theseareflaggedformanualre-view.
Thenextphaseoftheprojectwillstitchtheseconceptsintoarichlyintercon-nectedsemanticnetwork.
3Takingasipofthedatasoup–WikidataandtheSemanticWebThefirstapplicationtouseWikidataextensivelyisWikipediabutthiscouldbethetipoftheiceberg.
TogiveapreviewofwhatWikidatacouldbecome,it'suse-fultobrieflyexamineitsclosestancestor,DBpedia.
TheDBpediaprojectminescon-tentfromWikipediabyparsinginfoboxes,mapsthiscontenttotheirownontology,andprovidesaccesstothisdataintheformofalargeRDFdatabaseavailablebothforbulkdownloadandSPARQLquery.
Whileenablinginterestingqueriesonitsown,itsmostimportantfunctionisasagloballinkinghubfortheSemanticWeb[8].
IncomparisontoDBpedia,Wikidatahasanumberofadvantages.
First,itcanbeediteddirectlyandchangesarereflectedinrealtime.
Second,itdoesnotrequireanyparsingbecausealldataismanagedinadatabasefromtheoutset.
Third,itcontainslargeamountsofcontentthatisnotpresentinWikipedia,suchasitemsforeverymousegene.
Finally,itsqueryAPIsupportsnotonlyqueriesalongitsassertedknowledgegraph,butalsoalongreferences,qualifiersandevenedithistories.
Theseadditionalcapabilities,viewedinlightofthesuccessoftheDBpediaproject,portendavitalfutureforWikidatainthecontextoftheSemanticWeb.
Withinthebiomedicaldomain,usefulqueriesarealreadypossibleasaresultofthe'single-pot'natureofWikidata.
Forexample,itispossibletouseWikidata'sSPARQLendpoint(https://query.
wikidata.
org/)toanswerquestionssuchas"whatclinicallyrelevantdrug-druginteractionsareknownforthedrugmethadone(CHEMBL651)"[9].
Importantly,thedatausedtoanswerthisquerycamefromtwogroupsworkingcompletelyindependently.
Our'drug_bot'botaddedtheCHEMBLidentifiers(aswellasmanyotheridentifiers)whileanotherbotdevelopedbyateamattheMedicalUniversityofViennaaddedthedrug-druginteractions[10].
Thishap-penedwithoutanydirectcoordinationbetweenourgroups.
Thiskindofserendipitous,automatic,cross-continentaldataintegrationistheprimarygoaloftheSemanticWeb,butisnotyetcommonplace.
ThekeybeautyandmainchallengeoftheSemanticWebisitsdistributednature.
InorderforthiskindofintegrationtohappenintheabsenceofacentralizedresourcelikeWikidata,severalmajorhurdleswouldneedtobeleaped.
First,bothteamswouldneedtoknowenoughaboutthefairlycomplexstackofsemantictechnologiestoprovidetheirdataasRDFthroughastable,publicSPARQLendpoint.
Second,theywouldhavetoworkwithoverlappingidentifiersystems.
Third,thewould-beconsumeroftheirdatawouldneedtodiscoverbothoftheirendpointsandbesophisticatedenoughwithSPARQLtoidentifyandissuetheappropriatedistributedquery.
Allofthisispossi-bleandcanwork,butitisnoteasy.
Byintegratingdatainacentralized,singlecommunitypot,Wikidatapro-videsaplatformthataddresseseachoftheseproblems.
DataprovidersdonothavetosetupandmaintaintheirownSPARQLendpoint–achallengethatveryfewteamshavesucceededatdoingforanylengthoftime[11].
Byvirtueofworkinginthesamedatabase,itisfarlesslikely-thoughnotimpossible-forindependentteamstogener-ateandpublishdifferentidentifiers,asthefirststepinworkingwithWikidataistoqueryittoseewhatisalreadythere.
Finally,thechallengeoffindingarelevantend-pointisnegatedwhenthereisonlyone.
NotethatWikidatacanbequeriedusingSPARQLortheWikidataQueryLanguage[12].
4ManyCooks.
.
.
ThefactthatWikidataisonecentralized,communityresourceimmediatelysurfacesthechallengesincurredinanycollaborativeontologydevelopmentpro-cess.
InWikidata,the'ontology'correspondstoitscollectionoflinkingpropertiesusedtodescribeitems.
AnewpropertyinWikidatahastobeproposedforcommuni-tydiscussionandisonlycreatedafteraconsensusregardingthevalueofthepropertyanditsrelationtoexistingpropertieshasbeenestablished.
Forthoseusedtocontrol-lingtheirowndataanddatamodels,thisprocesscanfeeltedious.
Butthissamefun-damentalprocessmustbeundertakeninanyattemptatdataintegration.
Thefactthatithappensupfront,whendataisfirstbeingloaded,shouldhelptokeepthedatacon-sistentandreducethedownstreamidentifierandontologicalmappingproblemsthatcontinuetoplaguebioinformatics.
ImaginethepowerofcombiningthestructureddatainWikidata,thehighaccessibilityanddedicatedcommunityofWikipediaandtheknowledgeofthescien-tificcommunity.
Contemplatefurtherthatallofthisdataisfreelyavailableandac-cessiblethroughastablequeryinterfaceandrobust,read/writeAPI.
Thismakesim-portant,high-qualityinformationeasilyaccessiblebyanyoneandopensupscientificknowledgeforpublicscrutiny.
Further,thebuilt-inprovenancetrackingcanprovidedetailedchainsofevidencetosupportorrefuteeachclaimandallofthiscanbedis-cussedusingthemanysocialtools,suchas'talkpages'foreverydataitem,bakedintotheMediaWikiinfrastructure.
Asidefromcreatingusefulwaystodisseminatedata,thissociotechnicalstructureprovidesaframeworkforthebroadcommunitytobroadcastfeedbackbacktotheoriginaldataowners.
Evenatthisearlystageofthisproject,thisprocesshasalreadyledtoimprovementsinsourcedata.
Forexample,intheDiseaseOntologytheterm'Ollierdisease'hadthesynonym'Maffuccisyndrome'.
UponimportingtheDiseaseOntologyintoWikidata,membersoftheWikidatacommunitypointedoutthatthetwoterms,thoughputativesynonyms,linkedtotwodifferentextantWikidataitems.
Uponcloserreviewitwasdeterminedthatthesetwotermsrepresenttwodif-ferent,albeitcloselyrelated,diseases,leadingtothecreationofanewtermintheDiseaseOntology.
AsWikidataexpandsitistobeexpectedthatadditionaldiffer-encesinrepresentationbetweenitandotherknowledgeresourceswillsurface.
ThesewillfirstbetriagedbytheWikidatacommunitytocheckforerrorsand,ifconsensusisachievedthatthereisanerrorintheoriginalsource,thiswillberelayedforconsid-eration.
Inthisway,theWikidatacommunitycanbecomethe'manyeyes'thatmakeallontologybugsshallow.
5.
.
.
CanMakeaDeliciousSoupWecancreateapowerfulcommonsofbiomedicalknowledgebybuildingonestablishedresourcesandthededicatedcommunitytoconnectgenes,proteins,drugs,diseases,phenotypesandsymptoms.
WikipediawillbethefirstapplicationtousethecontentinWikidata,butcertainlynotthelast.
Thefireisreadyandthepotisstartingtoheatup.
Somevillagersarealreadypeekingoutoftheirwindowsreadytojoinusaroundthepot,butitwilltaketheeffortofthewholecommunitytomakeadeliciousbiomedicaldatasoup.
Weinviteyoutojoinusinthiseffort.
References1.
HistoryoftheStoneSoupStoryfrom1720tonow.
Availablefrom:http://www.
stonesoup.
com/history-of-the-stone-soup-story-from-1720-to-now/.
2.
Taylor.
J.
TheStoneSoupofData.
20078May;Availablefrom:https://km.
aifb.
kit.
edu/ws/ckc2007/StoneSoup-www2007.
pdf.
3.
Vrandei,D.
andM.
Krtzsch,Wikidata:AFreeCollaborativeKnowledgebase,inCommunicationsoftheACM.
2014,ACM.
p.
78-85.
4.
Heilman,J.
M.
andA.
G.
West,Wikipediaandmedicine:quantifyingreadership,editors,andthesignificanceofnaturallanguage.
JMedInternetRes,2015.
17(3):p.
e62.
5.
Huss,J.
W.
,3rd,etal.
,Agenewikiforcommunityannotationofgenefunction.
PLoSBiol,2008.
6(7):p.
e175.
6.
Brown,G.
R.
,etal.
,Gene:agene-centeredinformationresourceatNCBI.
NucleicAcidsRes,2015.
43(Databaseissue):p.
D36-42.
7.
Kibbe,W.
A.
,etal.
,DiseaseOntology2015update:anexpandedandupdateddatabaseofhumandiseasesforlinkingbiomedicalknowledgethroughdiseasedata.
NucleicAcidsRes,2015.
43(Databaseissue):p.
D1071-8.
8.
Bizer,C.
,etal.
,DBpedia-AcrystallizationpointfortheWebofData.
WebSemantics:Science,ServicesandAgentsontheWorldWideWeb,2009.
7(3):p.
154-165.
9.
Getallthedrug-druginteractionsforMethadonebasedonitsCHEMBLidCHEMBL651.
2015[cited2015Sep.
14];Availablefrom:https://bitbucket.
org/sulab/wikidatasparqlexamples/overview#markdown-header-get-all-the-drug-drug-interactions-for-methadone-based-on-its-chembl-id-chembl651.
10.
Pfundner,A.
,etal.
,UtilizingtheWikidatasystemtoimprovethequalityofmedicalcontentinWikipediaindiverselanguages:apilotstudy.
JMedInternetRes,2015.
17(5):p.
e110.
11.
Buil-Arand,C.
,etal.
SPARQLWeb-QueryingInfrastructure:ReadyforActionin12thInternationalSemanticWebConference.
2013.
Sydney,Australia.
12.
WikidataQueryEditor.
[cited2015;Availablefrom:https://wdq.
wmflabs.
org/wdq/.
- NCBImediawiki相关文档
- carsmediawiki
- naturemediawiki
- enteredmediawiki
- learnmediawiki
- demediawiki
- producemediawiki
提速啦香港独立物理服务器E3 16G 20M 5IP 299元
提速啦(www.tisula.com)是赣州王成璟网络科技有限公司旗下云服务器品牌,目前拥有在籍员工40人左右,社保在籍员工30人+,是正规的国内拥有IDC ICP ISP CDN 云牌照资质商家,2018-2021年连续4年获得CTG机房顶级金牌代理商荣誉 2021年赣州市于都县创业大赛三等奖,2020年于都电子商务示范企业,2021年于都县电子商务融合推广大使。资源优势介绍:Ceranetwo...
MechanicWeb免费DirectAdmin/异地备份
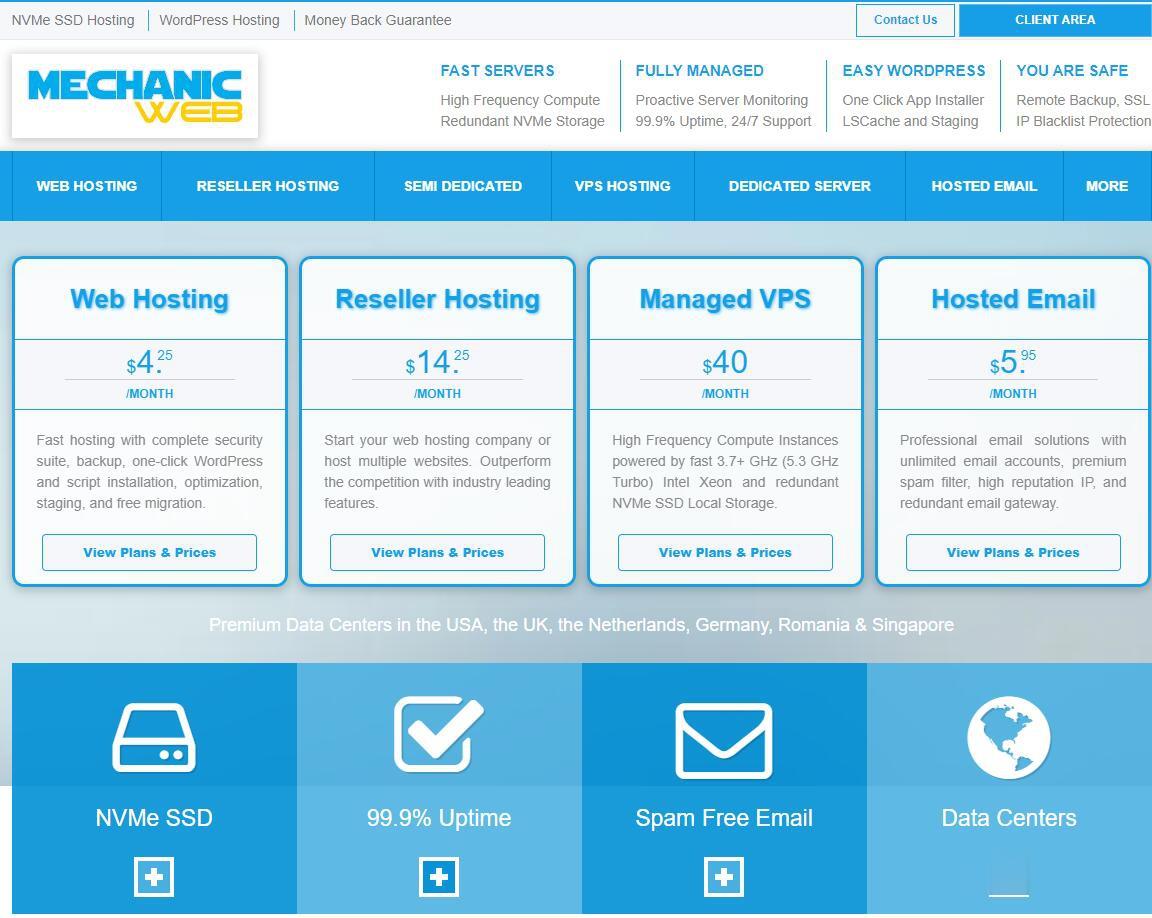
MechanicWeb怎么样?MechanicWeb好不好?MechanicWeb成立于2008年,目前在美国洛杉矶、凤凰城、达拉斯、迈阿密、北卡、纽约、英国、卢森堡、德国、加拿大、新加坡有11个数据中心,主营全托管型虚拟主机、VPS主机、半专用服务器和独立服务器业务。MechanicWeb只做高端的托管vps,这次MechanicWeb上新Xeon W-1290P处理器套餐,基准3.7GHz最高...
cera:秋季美国便宜VPS促销,低至24/月起,多款VPS配置,自带免费Windows
介绍:819云怎么样?819云创办于2019,由一家从2017年开始从业的idc行业商家创办,主要从事云服务器,和物理机器819云—-带来了9月最新的秋季便宜vps促销活动,一共4款便宜vps,从2~32G内存,支持Windows系统,…高速建站的美国vps位于洛杉矶cera机房,服务器接入1Gbps带宽,采用魔方管理系统,适合新手玩耍!官方网站:https://www.8...

mediawiki为你推荐
-
setOwnerjava现有新的ios更新可用请从ios14be苹果xr可不可以更新ios14重庆400年老树穿楼生长重庆的树为什么都长胡须?flashfxp下载怎样用FlashFXP从服务器下载到电脑上?重庆网站制作重庆网站制作,哪家专业,价格最优?重庆网站制作请问重庆那一家网站制作公司资信度比较好?技术实力雄厚呢?360防火墙在哪里360防火墙抢米网抢小米手机需要下什么软件 速求zhuo爱作文:温暖的( )电子商务世界世界前十大电子商务企业名字