指令SNB有多强 AVX指令集的出现慢慢引起质变
S N B有多强AVX指令集的出现慢慢
引起质变
目前对于Sandy Bridge架构下AVX指令集的评价主要有两个方面一是说AVX完全没有摆脱X86的阴影角度出发这个笔者可以理解。毕竟X86都沿用了这么多年了有些网友可能处于对新事物的期待。另外就是称其为革命性变革虽然有点夸张不过笔者还是比较认可后者。我也希望可以有一种更新进的模式颠覆X86的时代不过这种可能性实现起来很困难。
某种角度上笔者比较赞同颠覆说网友的看法。 AVX并不是x86CPU的扩展指令集而是可以实现更高的效率 同时也和CPU硬件兼容性也更好并且也有着足够的扩展空间这都和其全新的命令格式系统有关。更加流畅的架构就是AVX发展的方向换言之就是摆脱传统x86的不足在SSE指令的基础上AVX也使SSE指令接口更加易用。我们可以从以下两个方面来分析…
一、 AVX革新的指令格式
AVX的256bits SIMD扩展支持是其最具革新的设计部分 同时也代表了指令编码格式的变更。头部增加prefix让扩展成为可能而增强的寄存器也使指令头部分不断增加prefix成为了可能。这就似乎是由一个房子出来站到了院子里一般摆在他面前的是更宽广的世界。
二、 AVX最新的编码系统
针对AVX的最新的命令编码系统 Intel也给出了更加详细的介绍其中包括了大幅度扩充指令集的可能性。 比如Sandy Bridge所带来的融合了乘法的双指令支持。从而可以更加容易地实现512bits和1024bits的扩展。而在2008年末到2009年推出的meni ikoaCPU"Larrabee(LARAB)"处理器就会采用AVX指令集。从地位上来看AVX也开始了Inte l处理器指令集的新篇章。
基于这些Intel AVX带来的前景似乎非常明朗下面我们来看看AVX的未来剑指何方。
AVX的未来指令格式
支持16路SIMD指令
VEX是AVX的编码系统简称。 由于VEX的支持AVX的长指令可以变得更短而VEX的payload也有着1字节和2字节两种 VEXprefix为1字节payload的C5和2字节的C1 以及1字节的payload等情况 同样的指令和之前的指令格式比较beru的1字节分指令相比也更短。 Intel的Bob Valentine先生在IDF峰会上曾经介绍过AVX带来的蓝图。
VEX编码格式的另外一个重要点就是有着强大的指令集扩展支持而对于同样命令长度的指令也更加容易地实现这样就使不断增长的命令兼容变得更加容易。
其中5字节版的payload也专门有着指令扩展的3比特空间而3bits也以为着1000条新指令的支持全新的ficha和新的寄存器以及vector也都可以更加容易地增加。
除了VEX指令格式外还有着1,024bits的SIMD的支持。 同时多重prefix的支持和之前的beru比较全部的指令在格式上都更小之前的1字节C5通过C4也可以决定op code的长度。而从硬件上来看的话指令的puridekodo实现也更加容易。
VEX解决x86 CPU瓶颈
AVX的VEX的编码系统从某一侧面上也反应了Intel处理器今后的进化趋势 因为它解决了x86系列CPU在decoding上的不足。 Core MA有着4条命令的执行通道不过front end却存在着不足首先L1缓存fetch端口也有着16字节的长度。而fetch的命令次数也被得到了限制。首先IA-32/Intel 64命令的puridekodo也有着先天的瓶颈而操作数和地址长度的指令prefix"LCP(Length Changing Prefixes) 使得puridekodo变得更慢所以必须要改变长标注的算法。fetch&puridekodo的最优化设计
Core MA在puridekodo&decoding方面的不足从根本上来看是IA-32/Intel 64指令集架构本身的问题。 IA-32/Intel 64架构为了增强长命令而增设的缓存使命令fetch拜年的更长并且更加复杂的命令格式也由此产生。RISC(Reduced Instruction Set Computer)的命令格式也决定了其长度decoding虽然容易但x86系CPU也就要以牺牲资源为代价 同时也带来了电力的额外消耗。
实际上最新的Nehalem也有着类似Core MA的不足从某种程度上来看也延续了其不足如果明确了这一问题的话那么Nehalem就必须要改进其中16bytesfetch和puridekodo等方面的改进就势在必行了。而改进所需要的庞大晶体管增加也会带来功耗的增加。
Nehalem的fetch&decoding Nehalem的设计其实存在着疑问不过从VEX格式来分析的话其意图就非常明确了。 Intel在完善了CPU的puridekodo&decoding硬件设计的同时必须要改进指令格式本身。 fetch的指令变短的同时指令的标注却更加复杂了而解决的唯一办法就是改进指令格式。
在充分考虑硬件方面设计后 intel做出了VEX格式开始的决策。 IDF上Valentine先生也对VEX格式进行了详细的说明。他是Core MA的front end的fetch开发以及decoding的高级架构师 同时也是IA-32/Intel 64指令编码器的设计专家。
从整体来看AVX指令的话可以看出intel公司都CPU开发的全部脉络Intel公司在对比beru的话产生改进Drastic的指令集的微架构的想法就变得顺理成章了如果分析原因的话那就是微架构本身的改进了。全新的CPU必然要有更好的性能表现想要提高CPU的性能那么指令集是最行之有效的手段。
AVX扩展指令包含了SSE指令这也有助于像AVX时代的过度。 日前的SSEVEX格式也并不需要绝对的转换过程。 Intel公司的Benny Eitan先生也提到 出于整体的考虑 Intel公司对于AVX普及的进行并不会泰国迅速并且也不会立刻停止SSE时代。 Sandy Bridge也增强了解码器的支持和之前的IA-32/Intel 64prefix相比 decoding也有了全新的VEX格式的支持。其中
VEX指令对于decoding的命令数的支持上更加强劲 同时VEX在执行效率上也更加出色。不过这些和Sandy Bridge真正到来的时候可能还存在差异。
- 指令SNB有多强 AVX指令集的出现慢慢引起质变相关文档
- 数据avx指令集
- 浮点SNB AVX指令集 浮点峰值翻一倍
- 指令深入分析AVX指令集
- 指令深入分析avx指令集
- 指令集AVX 指令集于 Btrfs 的应用
- 指令集Cannon Lake将是第一款支持AVX-512先进指令集的主流产品
白丝云-美国圣何塞4837/德国4837大带宽/美西9929,26元/月起
官方网站:点击访问白丝云官网活动方案:一、KVM虚拟化套餐A1核心 512MB内存 10G SSD硬盘 800G流量 2560Mbps带宽159.99一年 26一月套餐B1核心 512MB内存 10G SSD硬盘 2000G流量 2560Mbps带宽299.99一年 52一月套餐...
bgpto:BGP促销,日本日本服务器6.5折$93/月低至6.5折、$93/月
bgpto怎么样?bgp.to日本机房、新加坡机房的独立服务器在搞特价促销,日本独立服务器低至6.5折优惠,新加坡独立服务器低至7.5折优惠,所有优惠都是循环的,终身不涨价。服务器不限制流量,支持升级带宽,免费支持Linux和Windows server中文版(还包括Windows 10). 特色:自动部署,无需人工干预,用户可以在后台自己重装系统、重启、关机等操作!bgpto主打日本(东京、大阪...
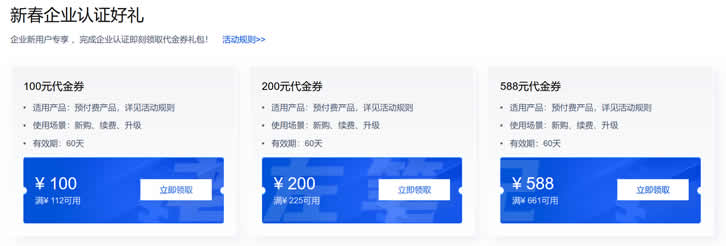
2022年腾讯云新春采购季代金券提前领 领取满减优惠券和域名优惠
2022年春节假期陆续结束,根据惯例在春节之后各大云服务商会继续开始一年的促销活动。今年二月中旬会开启新春采购季的活动,我们已经看到腾讯云商家在春节期间已经有预告活动。当时已经看到有抢先优惠促销活动,目前我们企业和个人可以领取腾讯云代金券满减活动,以及企业用户可以领取域名优惠低至.COM域名1元。 直达链接 - 腾讯云新春采购活动抢先看活动时间:2022年1月20日至2022年2月15日我们可以在...
-
网易网盘关闭入口网易网盘怎么打不开了京沪高铁上市首秀京沪高铁怎么老是出问题?高铁的核心技术是中国自己的吗?中老铁路一带一路的火车是什么火车李子柒年入1.6亿将55g铁片放入硫酸铜溶液中片刻,取出洗净,干燥后,称重为56.6g,问生成铜多少g??求解题步骤及答案罗伦佐娜维洛娜毛周角化修复液治疗毛周角化有用吗?谁用过?能告诉我吗?同ip网站同IP网站9个越来越多,为什么?mole.61.com摩尔大陆?????www.javmoo.comJAV编程怎么做?ww.66bobo.com有的网址直接输入***.com就行了,不用WWW, 为什么?www.ca800.com西门子plc仿真软件有什么功能