优化ai内存不足
YOURSUCCESS,WESUCCEED基于GPU的AI计算优化方法与案例:从训练到推理张清,浪潮AI首席架构师AI计算的发展趋势及其挑战基于GPU的AI计算优化方法:从训练到推理提纲CaseStudy:基于GPU实现AutoMLSuite计算优化Source:IDC2019AI计算的发展趋势US$M2,731.
74,478.
96,833.
89,674.
413,432.
317,468.
01,680.
62,686.
63,762.
94,639.
05,917.
67,303.
464.
0%52.
6%41.
6%38.
8%30.
0%59.
8%40.
0%23.
3%27.
6%23.
4%0.
0%10.
0%20.
0%30.
0%40.
0%50.
0%60.
0%70.
0%02,0004,0006,0008,00010,00012,00014,00016,00018,000201820192020202120222023中国人工智能总体市场规模及预测,2018-2023AISpendingGrowthRate整体投资中国人工智能服务器市场规模及预测,2018-2023AIServerGrowthRate算力投资趋势1:越来越多的场景将采用AI技术创新,未来计算投入会越来越大81.
3%73.
7%66.
6%59.
8%51.
7%47.
9%42.
7%18.
7%26.
3%33.
4%40.
2%48.
3%52.
1%57.
3%0%10%20%30%40%50%60%70%80%90%100%2017年2018年2019年2020年2021年2022年2023年TrainingInferenceSource:IDC2019AI计算的发展趋势趋势2:越来越多的AI应用将进入生产阶段,未来5年推理所需计算会迅速增加Source:FacebookAI计算的发展趋势趋势3:大数据+大模型,需要更大的计算16.
036.
087.
0153.
082.
2%84.
2%85.
1%85.
4%80.
0%81.
0%82.
0%83.
0%84.
0%85.
0%86.
0%020406080100120140160180200ResNeXt-10132*8dResNeXt-10132*16dResNeXt-10132*32dResNeXt-10132*48d单位:BFLOPS计算量准确度AI计算面临的挑战AI计算架构:芯片间异构与芯片内异构异构并行与协同计算–CPU/GPU,CUDACore/TensorCoreAI计算规模:K级节点、10K级GPU卡性能与性能的可扩展性–单模型K级以上GPU并行计算AI计算环境:不同用户、不同算法、不同数据、不同框架、不同GPU卡任务管理与资源调度–生产系统K级以上模型并发调度不同AI计算的发展趋势及其挑战基于GPU的AI计算优化方法:从训练到推理提纲CaseStudy:基于GPU实现AutoMLSuite计算优化基于GPU的AI计算优化方法AI应用特征分析GPU平台优化AI计算框架GPU优化AI应用GPU优化计算特征访存特征通信特征IO特征计算优化存储优化网络优化资源管理资源调度GPU系统管理优化数据模型划分单机优化算法不同通信机制数据模型聚合训练性能优化训练扩展优化推理吞吐优化推理延时优化AI应用特征分析CPUGPUTeye工具:从微架构层次分析AI应用与框架特征,实现性能优化MXNetTensorFlowCaffeCV应用特征分析案例CPU利用率:5%-25%CPU内存:20GB以下GPU利用率:80%-100%GPU内存:15GB左右GPU平台优化计算优化–训练:单机8-16V100GPU并行–推理:单机8-16T4GPU并行网络优化–训练:单机4-8个IB卡(100GB/s-200GB/s)实现1000卡以上并行–推理:单机万兆网络通信优化–训练:NVSwitch+RDMA–推理:PCIE存储优化:高性能并行存储+SSD/NVMe两级存储547.
23889.
64456.
811076.
551761.
27907.
392065.
93399.
91805.
034124.
376813.
023581.
968195.
8313473.
36976.
06050001000015000resnet101resnet50vgg16V100-SMX332GBbs=256(Images/s)(InspurAGX-5)1GPU2GPUs4GPUs8GPUs16GPUs6134077903102741020000400006000080000100000120000A厂商8*PCIeGPUServerB厂商8*NVLinkGPUServerInspur5488M5NLPTransformerBenchmark(每秒钟训练单词数)GPU系统管理优化数量:120GPU分配:共享用途:训练用户:ALLSSD缓存HAP100_share数量:96GPU分配:独享用途:训练用户:行为分析SSD缓存P100_exclusive数量:64GPU分配:共享用途:训练用户:ALLSSD缓存V100_share数量:120GPU分配:独享用途:训练用户:图像识别SSD缓存V100_exclusive用户数据:代码,模型云存储数量:32GPU分配:共享用途:开发调试,镜像定制用户:ALLSSD缓存P40_debug利用AIStation实现统一资源管理和调度–大规模AI生产平台:800+GPU卡–GPU利用率40%提升到80%–作业吞吐提升3倍训练数据下载AI计算框架GPU优化并行机制:数据并行/模型并行/数据+模型并行/Pipline并行GPU计算充分发挥:FP16与FP32混合精度计算,保持训练稳定下的大batchsize训练计算梯度同步通信机制:异步或半异步,ring-allreduce,2D-Torusall-reduce通信优化:合并小数据,提升通信效率;计算与通信异步,实现隐藏通信并行IO,采用多线程的数据读取机制数据预取、数据IO与计算异步并行IOAI计算框架GPU优化案例开源地址:https://github.
com/Caffe-MPI/Caffe-MPI.
github.
ioNo.
ofGPUsimages/sNo.
ofGPUsInspurCaffe-MPIInspurTensorFlow-Opt实现512块GPU24分钟完成imagenet数据集训练基于HPC架构,实现数据并行,并行IO读取数据基于NCCL,并采用环形通信方式计算与通信异步,实现计算与通信的异步隐藏实现主从模式到对等模式通信合并梯度,提升通信效率采用fp16通信,减少通信量AI应用面临的挑战分析及优化思路数据跟不上计算,GPU利用率低模型和数据大,GPU显存溢出,如何优化混合精度如何优化,TensorCore如何高效利用如何快速实现多机多GPU卡并行计算Pref/NVProfTensorflow-timelineHorovod-timelineTeyeGPU-driver/CUDA/cuDNN/NCCL计算框架版本匹配CPU/GPU端、Bios设置CPU与GPU、GPU与GPU、节点间通信拓扑应用瓶颈分析GPU系统级优化GPU代码级优化训练的性能训练的扩展效率推理的吞吐量推理的延时AI训练应用GPU优化方法数据IO优化数据格式、数据存储、数据处理、数据流水线混合精度优化使用CUDACore&TensorCore发挥GPU使用效率GPU并行优化使用ring(tree)-allreduce高效并行通信方式数据IO优化数据并行读取数据并行批量预处理数据与计算异步并行数据IO优化案例1某图像识别CNN模型(在P100平台训练)实测单卡计算性能只有2.
3TFlops,远低于P100的理论单精度浮点性能;分析GPU的利用率,发现GPU只有60%左右的时间在参与计算,剩余40%的时间处于空闲状态;在毫秒尺度观察GPU的使用情况,发现有周期性的0.
06s左右的GPU空闲时间数据IO优化案例1效果通过优化图片预处理方式,可以有效的提高GPU资源的利用率,优化后GPU的使用率提升到90%左右.
香港云服务器 1核 1G 29元/月 快云科技
快云科技: 12.12特惠推出全场VPS 7折购 续费同价 年付仅不到五折公司介绍:快云科技是成立于2020年的新进主机商,持有IDC/ICP等证件资质齐全主营产品有:香港弹性云服务器,美国vps和日本vps,香港物理机,国内高防物理机以及美国日本高防物理机产品特色:全配置均20M带宽,架构采用KVM虚拟化技术,全盘SSD硬盘,RAID10阵列, 国内回程三网CN2 GIA,平均延迟50ms以下。...

无忧云(25元/月),国内BGP高防云服务器 2核2G5M
无忧云官网无忧云怎么样 无忧云服务器好不好 无忧云值不值得购买 无忧云,无忧云是一家成立于2017年的老牌商家旗下的服务器销售品牌,现由深圳市云上无忧网络科技有限公司运营,是正规持证IDC/ISP/IRCS商家,主要销售国内、中国香港、国外服务器产品,线路有腾讯云国外线路、自营香港CN2线路等,都是中国大陆直连线路,非常适合免北岸建站业务需求和各种负载较高的项目,同时国内服务器也有多个BGP以及高...

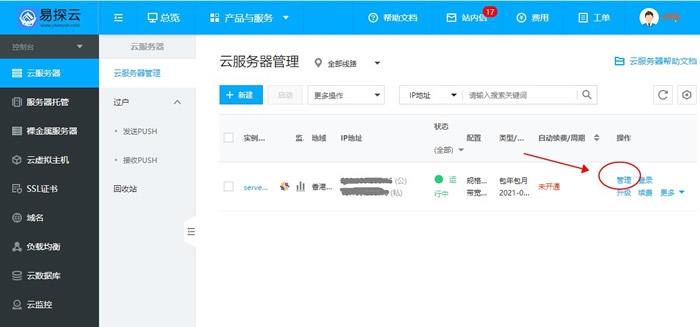
易探云服务器怎么过户/转让?云服务器PUSH实操步骤
易探云服务器怎么过户/转让?易探云支持云服务器PUSH功能,该功能可将云服务器过户给指定用户。可带价PUSH,收到PUSH请求的用户在接收云服务器的同时,系统会扣除接收方的款项,同时扣除相关手续费,然后将款项打到发送方的账户下。易探云“PUSH服务器”的这一功能,可以让用户将闲置云服务器转让给更多需要购买的用户!易探云服务器怎么过户/PUSH?1.PUSH双方必须为认证用户:2.买家未接收前,卖家...
-
域名价格域名费用大概是多少?海外主机租用请问如何租一个国外的服务器?大概需要多少钱?中国互联网域名注册中国互联网络域名注册暂行管理办法的第三章 域名注册的申请linux主机linux优点和缺点有哪些啊?域名购买域名注册和购买是一个意思吗?虚拟主机申请域名申请以及虚拟主机台湾主机台湾版本的主机好不好?美国网站空间我想买个国外的网站空间,那家好,懂的用过的来说说虚拟主机评测网哪里有可靠的免费虚拟主机虚拟主机控制面板万网的虚拟主机控制面板指的是什么呢?