人工智能内存不能为read
*史忠植高级人工智能*高级人工智能第十四章知识发现(二)史忠植中国科学院计算技术研究所*史忠植高级人工智能*主要内容研究背景WekaMSMiner体系结构元数据数据仓库平台数据采掘集成工具*史忠植高级人工智能*典型的知识发现系统SAS公司的SASEnterpriseMinerIBM公司的IntelligentMinerSolution公司的Clementine加拿大SimonFraserUniv.
的DBMiner中科院计算技术研究所的MSMiner等*史忠植高级人工智能*知识发现工具SASSAS公司的SASEnterpriseMiner是一种通用的数据挖掘工具.
通过收集分析各种统计资料和客户购买模式,SASEnterpriseMiner可以帮助您发现业务的趋势,解释已知的事实,预测未来的结果,并识别出完成任务所需的关键因素,以实现增加收入、降低成本.
*史忠植高级人工智能*知识发现工具SASSASEnterpriseMiner提供"抽样-探索-转换-建模-评估"(SEMMA)的处理流程.
数据挖掘算法有:·聚类分析,SOM/KOHONEN神经网络分类算法·关联模式/序列模式分析·多元回归模型·决策树模型(C45,CHAID,CART)·神经网络模型(MLP,RBF)·SAS/STAT,SAS/ETS等模块提供的统计分析模型和时间序列分析模型也可嵌入其中.
*史忠植高级人工智能*知识发现工具IntelligentMinerIBM公司的IntelligentMiner具有典型数据集自动生成、关联发现、序列规律发现、概念性分类和可视化显示等功能.
它可以自动实现数据选择、数据转换、数据发掘和结果显示.
若有必要,对结果数据集还可以重复这一过程,直至得到满意结果为止.
*史忠植高级人工智能*知识发现工具ClementineSolution公司的Clementine提供了一个可视化的快速建立模型的环境.
它由数据获取(DataAccess)、探查(Investigate)、整理(Manipulation)、建模(Modeling)和报告(Reporting)等部分组成.
都使用一些有效、易用的按钮表示,用户只需用鼠标将这些组件连接起来建立一个数据流,可视化的界面使得数据挖掘更加直观交互,从而可以将用户的商业知识在每一步中更好的利用.
*史忠植高级人工智能*数据挖掘工具:公用系统MLC++MatlabWeka*UniversityofWaikato*作者:IanH.
Witten/EibeFrank副标题:PracticalMachineLearningToolsandTechniques,SecondEdition(MorganKaufmannSeriesinDataManagementSystems)页数:525出版社:MorganKaufmann出版年:2005-06-08Weka关于WEKA的简介WEKA的全名是怀卡托智能分析环境(WaikatoEnvironmentforKnowledgeAnalysis),是一款免费的,非商业化(与之对应的是SPSS公司商业数据挖掘产品--Clementine)的,基于JAVA环境下开源的机器学习(machinelearning)以及数据挖掘(dataminining)软件.
它和它的源代码可在其官方网站下载.
非常有趣的是,该软件的缩写WEKA也是NewZealand独有的一种鸟名,而Weka的主要开发者同时恰好来自NewZealand的theUniversityofWaikato.
*UniversityofWaikato**UniversityofWaikato*WEKA:thebird(译:秧鸡)Copyright:MartinKramer(mkramer@wxs.
nl)关于WEKA的简介WEKA作为一个公开的数据挖掘工作平台,集合了大量能承担数据挖掘任务的机器学习算法,包括对数据进行预处理,分类,回归、聚类、关联规则以及在新的交互式界面上的可视化.
而开发者则可使用Java语言,利用WEKA的架构上开发出更多的数据挖掘算法.
用户如果想自己实现数据挖掘算法的话,可以查看WEKA的接口文档.
在WEKA中集成自己的算法甚至借鉴它的方法自己实现可视化工具并不是件很困难的事情.
*UniversityofWaikato*WEKA开发历史的介绍WEKA自1993年由位于NewZealand的theUniversityofWaikato进行开发,最初的软件基于C语言实现.
1997年,开发小组用JAVA语言重新编写了该软件,并且对相关的数据挖掘算法进行了大量的改进.
2005年8月,在第11届ACMSIGKDD国际会议上,theUniversityofWaikato的Weka小组荣获了数据挖掘和知识探索领域的最高服务奖,Weka系统得到了广泛的认可,被誉为数据挖掘和机器学习历史上的里程碑,是现今最完备的数据挖掘工具之一.
*UniversityofWaikato**UniversityofWaikato*WEKA:versionsThereareseveralversionsofWEKA:WEKA3.
4:"bookversion"compatiblewithdescriptionindataminingbookWEKA3.
6:"GUIversion"addsgraphicaluserinterfacesWEKA3.
7:"developmentversion"withlotsofimprovementsThistalkisbasedonthesnapshotofWEKA3.
3WEKA:FormatoftheData使用这个系统前,首先需要将用户的数据转变成为WEKA所需要的数据格式(ARFF格式).
大多数ARFF数据文件是一个包括所有事例的列表,还有每个事例的属性值,这些属性值用逗号分开.
当事例存在EXCEL或数据库中的时候,只需要将他们提出,转成数据间用逗号分割的形式,然后加上数据集的名字@relation,属性信息@attribute,值@data,然后再将该文件保存成ARFF格式即可.
需要注意的是WEKA中的分类方案缺省假定ARFF文件中的最后一个属性是分类属性.
*UniversityofWaikato**UniversityofWaikato*@relationheart-disease-simplified@attributeagenumeric@attributesex{female,male}@attributechest_pain_type{typ_angina,asympt,non_anginal,atyp_angina}@attributecholesterolnumeric@attributeexercise_induced_angina{no,yes}@attributeclass{present,not_present}@data63,male,typ_angina,233,no,not_present67,male,asympt,286,yes,present67,male,asympt,229,yes,present38,female,non_anginal,,no,not_present.
.
.
WEKAonlydealswith"flat"files*UniversityofWaikato*@relationheart-disease-simplified@attributeagenumeric@attributesex{female,male}@attributechest_pain_type{typ_angina,asympt,non_anginal,atyp_angina}@attributecholesterolnumeric@attributeexercise_induced_angina{no,yes}@attributeclass{present,not_present}@data63,male,typ_angina,233,no,not_present67,male,asympt,286,yes,present67,male,asympt,229,yes,present38,female,non_anginal,,no,not_present.
.
.
WEKAonlydealswith"flat"files*UniversityofWaikato**UniversityofWaikato**UniversityofWaikato**UniversityofWaikato*Explorer:pre-processingthedataDatacanbeimportedfromafileinvariousformats:ARFF,CSV,C4.
5,binaryDatacanalsobereadfromaURLorfromanSQLdatabase(usingJDBC)Pre-processingtoolsinWEKAarecalled"filters"WEKAcontainsfiltersfor:Discretization,normalization,resampling,attributeselection,transformingandcombiningattributes,…*UniversityofWaikato**UniversityofWaikato**UniversityofWaikato**UniversityofWaikato**UniversityofWaikato**UniversityofWaikato**UniversityofWaikato**史忠植高级人工智能*知识发现工具MSMiner中科院计算技术研究所智能信息处理开放实验室开发的MSMiner是一种多策略知识发现平台,能够提供快捷有效的数据挖掘解决方案,提供多种知识发现方法.
MSMiner具有下列特点:基于数据仓库和新型的元数据管理按照主题创建数据仓库,并通过元数据进行管理和维护.
.
数据的抽取、转换、装载等预处理方便,支持OLAP查询.
*史忠植高级人工智能*MSMiner的特点提供决策树、支持向量机、粗糙集、模糊聚类、基于范例推理、统计方法、神经计算等多种数据挖掘算法,支持特征抽取、分类、聚类、预测、关联规则发现、统计分析等数据挖掘功能,并支持高层次的决策分析功能.
实现了可视化的任务编辑环境,以及功能强大的任务处理引擎,能够快捷有效地实现各种数据转换和数据挖掘任务.
可扩展性好.
转换规则和挖掘算法是封装的、模块化的,系统提供了一个开放的、灵活通用的接口,使用户能够加入新的规则和算法.
容易进行二次开发.
*史忠植高级人工智能*数据仓库:特征面向主题集成性稳定性随时间变化*史忠植高级人工智能*数据仓库:OLAPROLAP:RelationalOLAPMOLAP:MultidimensionalOLAPHOLAP:HybridOLAP*史忠植高级人工智能*数据挖掘和数据仓库的结合数据仓库为数据挖掘提供经良好处理的数据源数据挖掘为数据仓库提供深层数据分析手段*史忠植高级人工智能*MSMiner体系结构设计目标:提供快捷有效的数据挖掘解决方案.
设计要求:开放性可扩展性效率易用性*史忠植高级人工智能*MSMiner体系结构MSMiner体系结构示意图客户端服务器端元数据模块执行数据挖掘任务编辑数据挖掘任务数据采掘集成工具数据抽取和集成主题组织OLAP可视化数据仓库管理器数据仓库OLEDBforODBC*史忠植高级人工智能*元数据的内容关于外部数据源的关于内部数据的(包括数据库、表、字段的信息)关于数据仓库的(包括事实表、维表、立方以及其它的中间表)关于用户信息的数据采掘算法(包括算法的参数信息)关于采掘任务的(包括采掘步骤、每个步骤的所用的参数)*史忠植高级人工智能*元数据:元数据库*史忠植高级人工智能*元数据:元数据对象模型设计思路一致性完备性易维护性*史忠植高级人工智能*元数据是层次的嵌套的封装的互相联系的采用面向对象的方法共有60多个类元数据的结构*史忠植高级人工智能*数据仓库平台:结构MSMiner数据仓库结构示意图外部数据数据仓库元数据数据抽取、清洗、聚集、转换主题2主题1主题nOLAP及可视化工具数据采掘集成工具.
.
.
*史忠植高级人工智能*数据仓库平台:数据抽取和集成数据的简单抽取和集成数据的复杂处理面向数据挖掘的数据预处理*史忠植高级人工智能*数据抽取和集成:MSETLMSETL系统作为MSMiner数据挖掘平台的一个重要组成部分,主要完成从业务数据源到分析数据源的转换功能.
具体包括从异质业务数据源中抽取需要的数据,对这些数据进行多种预处理,把经过处理后的数据装载入指定数据仓库/数据库*史忠植高级人工智能*数据抽取和集成:MSETL用户界面(ETL转换函数和ETL任务)逻辑处理元数据管理数据库服务器*史忠植高级人工智能*数据抽取和集成:MSETL支持多种数据源和目的数据库良好的可扩充性高效率的调度执行功能增量更新功能*史忠植高级人工智能*数据抽取和集成:MSETL*史忠植高级人工智能*数据抽取和集成:MSETL*史忠植高级人工智能*数据仓库平台:数据仓库建模产品号产品名称产品目录产品维表订单号订货日期订货维表客户号客户名称客户地址客户维表产品号客户号订单号时间标识地区名称产品数量总价事实表时间标识月季度年时间维表地区名称省别地区维表星型模型*史忠植高级人工智能*OLAPMOLAP,ROLAP,HOLAPOLAP的操作Slice(切片)Dice(切块)Rollup(上卷)Drilldown(下钻)Pivot(旋转)OLAP方案采用了自主开发的OLAPServer*史忠植高级人工智能*数据立方体*史忠植高级人工智能*数据仓库平台:OLAP的实现*史忠植高级人工智能*数据挖掘集成工具:结构数据挖掘集成工具结构示意图数据仓库平台任务编辑任务规划和执行算法库算法管理元数据任务模型库、算法描述*史忠植高级人工智能*数据挖掘集成工具:数据挖掘任务模型Step1Step2Step4Step3Step5DMTask=(V,R)V={x|x∈StepObjects}R={|P(x,y)∧x,y∈V}*史忠植高级人工智能*数据挖掘集成工具:数据挖掘任务模型步骤对象BNF语法定义:::=;::=[|;]::=,::=[|;]::=,::=[|]::=[|||]::=**史忠植高级人工智能*数据挖掘集成工具:编辑任务模型任务向导*史忠植高级人工智能*数据挖掘集成工具:编辑任务模型任务编辑图板*史忠植高级人工智能*数据挖掘集成工具:处理任务模型人机界面主控模块规划器解释器缓存函数库黑板任务模型库数据采掘任务处理引擎的结构*史忠植高级人工智能*数据挖掘集成工具:处理任务模型任务规划和解释执行S1S3S2S4S5S1-S2-S3-S4-S5*史忠植高级人工智能*数据挖掘集成工具:DML语言DML函数人机交互和控制台输入/输出数值计算字符串处理图形、图表展示文件操作数据库访问网络通讯对象访问消息处理和流程控制黑板操作外部功能调用其它辅助功能*史忠植高级人工智能*数据挖掘集成工具:内嵌决策树SOM神经网络粗糙集关联规则*史忠植高级人工智能*决策树*史忠植高级人工智能*知识约简知识约简——在保持知识库的分类或决策能力不变的条件下,删除其中不相关或不重要知识冗余知识——资源的浪费;干扰人们作出正确而简洁的决策RoughSet——把那些无法确认的个体都归属于边界线区域,而这种边界线区域被定义为上近似集和下近似集之差集(Z.
Pawlak)知识约简是粗糙集的核心内容之一*史忠植高级人工智能*RoughSet约简*史忠植高级人工智能*数据挖掘集成工具:外联BP神经网络统计分析模糊聚类超曲面分类SVM贝叶斯网络基于范例推理(CBR)隐马尔科夫模型(HMM)*史忠植高级人工智能*BP用于预测*史忠植高级人工智能*统计工具线性回归模型——一元线性回归、多元线性回归、逐步回归非线性回归模型——二次曲线、三次曲线、指数曲线、幂指数曲线、生产函数等模型确定型时间序列模型——指数平滑法、趋势移动平均法(水平趋势、线性趋势和二次曲线趋势)、成长曲线模型(Compertz曲线、Logistic曲线和修正指数曲线)、季节指数法随机型时间序列模型(自回归-移动平均模型ARMA)相关分析*史忠植高级人工智能*自回归移动平均(ARMA)*史忠植高级人工智能*模糊聚类基于传递闭包的模糊聚类——计算模糊相似矩阵的传递闭包,从而获得传递闭包法的模糊聚类基于摄动的模糊聚类——参数系相似矩阵的最优模糊等价阵及其等价标准型获得失真最小的模糊聚类*史忠植高级人工智能*数据挖掘集成工具:可扩展算法库算法注册*史忠植高级人工智能*MSMiner的应用:计算机选案决策树选案执行选案选案结果分析定义样本模板训练样本数据选案规则样本数据表数据汇总表税务稽查计算机选案系统功能结构*史忠植高级人工智能*MSMiner的应用:计算机选案挖掘结果:云计算时代的分布并行编程技术分布并行数据处理技术GoogleMap/ReduceHadoopMap/Reduce分布式文件系统GoogleFileSystemHadoopDistributedFileSystem分布式数据库GoogleBigTableHadoopHBase云计算时代的分布并行编程技术分布并行数据处理*软件工程国家重点实验室Map/Reduce用于大规模数据并行处理数据量大(超过1TB)在成百上千个CPU上并行处理用户只需实现下面接口map(in_key,in_value)->(out_key,intermediate_value)listreduce(out_key,intermediate_valuelist)->out_valuelist分布并行数据处理*软件工程国家重点实验室Map/Reduce架构分布并行数据处理MapReduce实现原理分布式文件系统*GoogleFileSystem(GFS)需求:在廉价、相对不可靠的计算机上对巨量数据进行冗余存储.
为什么不用现有的文件系统--Google面对特殊的挑战文件较大,每个都在100M以上,通常为几个GB文件通常需要频繁的追加用流方式读取高吞吐量低延迟针对上述问题,GFS在文件系统性能和可伸缩性方面进行了优化设计.
GFS的设计理念文件用块存储每个块固定为64MB通过冗余解决可靠性问题每个块同时拷贝在3个块服务器上主服务器负责协调访问和保存元数据简单化的集中管理定制化的API无数据缓存较大文件块和流式读取使得缓存效果不佳*分布式文件系统GFS架构分布式文件系统GFS集群一个GFS集群有一个主服务器和多个块服务器文件被分割成固定尺寸的块.
块服务器把块作为linux文件保存在本地硬盘上,并根据指定的块句柄和字节范围来读写块数据.
主服务器管理文件系统所有的元数据,包括名字空间、访问控制信息和文件到块的映射信息,以及块当前所在的位置.
客户端与主服务器交互,处理元数据客户端与块服务器交互,存取数据本身分布式文件系统分布式数据库系统GoogleBigTable为了处理Google内部大量的格式化以及半格式化数据而构建的大规模分布式数据存储系统特点面向大规模处理、容错性强的自我管理系统,拥有TB级的内存和PB级的存储能力,每秒可以处理数百万的读写操作能够保存记录的不同时段的版本构建于GFS和Map/Reduce基础之上软件工程国家重点实验室*BigTable的设计理念面向网页数据的发布、搜索和浏览等特定处理的需要,简化数据管理系统的设计,并提高性能不支持关联不支持SQL查询简化数据的一致性管理网页数据的管理对一致性要求不高简化事务管理网页数据的处理(搜索、发布)对事务管理要求不高面向海量数据管理要求设计分割和合并管理机制(基于元数据)设计自动伸缩功能(根据数据量调整资源用量)软件工程国家重点实验室*分布式数据库系统BigTable的实现GFS为表文件、元数据和日志提供存储服务Chubby提供分布式并行处理功能一个Table按照行被分割为多个tablet每一个tablet在物理层被存为SSTable文件通过维护keydiskblock索引,SSTable文件管理系统提供keyvalue的索引功能分布式数据库系统BigTable架构*分布式数据库系统*史忠植高级人工智能*进一步的工作与用户合作开发应用实例进一步完善工作流完善和丰富数据挖掘算法库算法评测功能.
- 人工智能内存不能为read相关文档
- http://math.ecnu.edu.cn/~jypan
- 如何在校园网内下载超星电子图书并复制到其他机器上阅读
- 滤波器内存不能为read
- 计算机内存不能为read
- 指针内存不能为read
- 四川大学期末考试试题(闭卷)
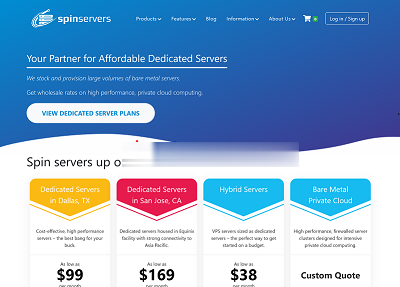
spinservers:圣何塞物理机7.5折,$111/月,2*e5-2630Lv3/64G内存/2T SSD/10Gbps带宽
spinservers美国圣何塞机房的独立服务器补货120台,默认接入10Gbps带宽,给你超高配置,这价格目前来看好像真的是无敌手,而且可以做到下单后30分钟内交货,都是预先部署好了的。每一台机器用户都可以在后台自行安装、重装、重启、关机操作,无需人工参与! 官方网站:https://www.spinservers.com 比特币、信用卡、PayPal、支付宝、webmoney、Payssi...
瓜云互联-美国洛杉矶高防CN2高防云服务器,新老用户均可9折促销!低至32.4元/月!
瓜云互联一直主打超高性价比的海外vps产品,主要以美国cn2、香港cn2线路为主,100M以内高宽带,非常适合个人使用、企业等等!安全防护体系 弹性灵活,能为提供简单、 高效、智能、快速、低成本的云防护,帮助个人、企业从实现网络攻击防御,同时也承诺产品24H支持退换,不喜欢可以找客服退现,诚信自由交易!官方网站:点击访问瓜云互联官网活动方案:打折优惠策略:新老用户购买服务器统统9折优惠预存返款活动...

BGPTO独服折优惠- 日本独服65折 新加坡独服75折
BGPTO是一家成立于2017年的国人主机商,从商家背景上是国内的K总和有其他投资者共同创办的商家,主营是独立服务器业务。数据中心包括美国洛杉矶Cera、新加坡、日本大阪和香港数据中心的服务器。商家对所销售服务器产品拥有自主硬件和IP资源,支持Linux和Windows。这个月,有看到商家BGPTO日本和新加坡机房独服正进行优惠促销,折扣最低65折。第一、商家机房优惠券码这次商家的活动机房是新加坡...
-
海外虚拟主机空间国外虚拟主机空间为什么能这么大呢?域名空间代理域名空间代理商哪个好?免费com域名注册有没有永久免费的.com之类的域名vps虚拟主机请问VPS和虚拟主机有什么不一样,为什么VPS贵那么多。广告的别来!租服务器租个一般的服务器大概多少钱啊?免费网站域名申请哪里可以申请到免费网站域名?免费网站域名申请那里 可以申请免费的 网站域名啊??便宜的虚拟主机哪儿有便宜的虚拟主机?便宜的虚拟主机低价虚拟主机那种类型的好呢?台湾vps香港vps和台湾vps哪个好用