关键词哪个浏览器速度快
网页敏感词检测V1.
0技术研究报告北京邮电大学目录第一章网页敏感信息检测系统研究背景11.
1技术研究背景及意义11.
2国内外敏感信息检测与过滤技术的研究现状21.
3本章小结3第二章网页敏感信息检测系统关键技术42.
1网页敏感信息检测系统概述42.
2敏感关键词库创建52.
3敏感关键词的字典树存储与查找52.
4敏感关键词检测62.
5本章小结7第三章系统设计与实现83.
1需求分析83.
2主要模块设计与实现83.
2.
1模块的总体结构与输入输出83.
2.
2目录文件读写子模块93.
2.
3敏感关键词字典树构建103.
2.
4敏感关键词检测过程153.
3实验环境183.
4实验结果183.
5本章小结20第一章网页敏感信息检测系统研究背景1.
1技术研究背景及意义随着互联网的发展,人们享受网络技术带来的美好生活,同时也使某些非法分子通过网络传送非法信息.
随着网络技术的发展和应用,网上色情、暴力、反动等不良信息时有传播,而且有泛滥的趋势.
因此,网络信息内容安全值得大家去关注和研究.
互联网发展到今天,已经得到很大的普及和应用.
目前已经成为一个全球性、开放性、互动性的综合性平台.
它容纳了各类型的原始信息,提供了各类型的服务,比如信息获取、网上购物、即时性交流等,给人们工作、生活带来很大的便利.
可以说它深入人们的方方面面,是人类信息化技术的一次革命.
2011年底,世界网民数量突破21亿,另据中国互联网络信息中心(CNNIC)统计,截止2011年6月中国网民己达4.
85亿,成为世界网民最多的国家.
网络给我带来便利的同时,也给我们带来许多新的社会问题.
由于存在着巨大的经济利益以及世界各个地区与国家、民族之间存在着政治、宗教等矛盾,使得非法人士挺而走险,利用网络开放性的特点,在网上散布各种反动、暴力、色情、虚假广告等不良信息,严重腐烛人们的身心健康,煽动不明真相的人聚众闹事,引起民族之间的强烈仇恨等,给经济社会稳定发展与人们安居乐业带来及其严重的影响.
另外由于网络的"无疆界"、"零距离"、"即时性"的特性,常常被有意识地用于进行国家间的政治文化渗透.
与以往常用的电台、电视、报纸等工具相比,以Twitter、Facebook、Youtube等为代表的网络信息传播速度更快,范围更广,信息量更大,特别是其隐蔽性、即时性、交互性、社会性的特点,对社会政治、经济、文化发生着越来越大的影响,成为西方发达国家政治威慑和干涉的有力武器,对我国家安全构成了新的威胁和挑战.
如何有效组织和管理互联网,加强网络的侦察与监控,营造安全的网络环境己经成为现阶段亟待解决的问题.
网络过滤技术就是在这个背景下产生的.
目前网页过滤方法主要有关键字过滤、神经元算法、概率统计等技术.
据统计网络中70%内容是以文本形式存在,所以对网络文本的过滤是现在过滤技术研究的主要方向.
由于关键词过滤相对于别的语义过滤实现简单,过滤速度快等特点,目前己成为绝大多数过滤系统采用的主要方法.
比如企业搜索产商Autonomy为我国政府网络信息监测部门量身定做的互联网网页关键字监控分析系统、美国的TDT(TopicDetectionandTracking,话题识别与跟踪)系统、IBMAlmaden研究中心幵发的WebFountain系统等,这些系统均是以关键字过滤技术为基础,并含有网页信息收等集、海量信息检索和语言检索等功能.
关键字过滤和其他过滤算法相比虽然有其自身的缺点,但是建立在一定良好分词基础上,通过合理的特征词优化和关键词算法,在不影响处理速度和空间开销的前提下,同样可以达到理想的过滤效果.
针对网页文本内容的敏感关键词检测技术能够及时有效检测与发现网页中出现的不良文本信息,使网站监控与管理人员及时采取措施进行敏感词的过滤,以防止网页不良信息的蔓延和给社会和人们带来重大损失.
1.
2国内外敏感信息检测与过滤技术的研究现状敏感信息监测与过滤技术是网络舆情管理的重要技术,最早起源于图书馆中的应用,1958年Luhn以图书馆检索工作为基础,提出了"商业智能机器"的设想,这个设想最后成了信息过滤的雏形.
"商业智能机器"首先它按照用户不同需求的建立相应的查询模型,然后根据这个模型,通过精确的匹配,提取出不同模型相对应的文本集.
用户的需求模型并不是固定的,它会根据用户的查询来更新和完善,这个过程虽然简单,但是它涉及了信息过滤的每一个过程,也成为后来信息过滤的幵端.
然而这个信息更新与维护是靠人工来维护的.
1969年,随着电子文本的出现和普及,以及当时出现的文本匹配算法,选择信息分发系统(SDI,SelectiveDisseminationofInformation)开始收到人们的重视.
"信息过滤"这个概念是在1982年Demzing提出的,他是在邮件系统中设计了"内容过滤器,并通过"内容过滤器"来识别紧急邮件和一般邮件[5],以此来实现对信息内容进行有效性控制.
1987年,Malone等人对信息过滤提了出三种信息选择模式,即认知、经济、社会.
随着信息过滤技术越来越多的受到重视,1989年,由美国DARPA资助的"MessageUnderstandingConference"将自然语言处理技术引入文本过滤研究方面进行了积极的探索.
它的主要工作是引入了统计学原理,在过滤处理自然语言之前,应用统计技术对信息进行预处理,把这个文本预处理过程叫做"文本检测".
之后Belkin和Croft对用户要求在信息过滤系统流程中的作用做了详细分析,并提出了"用户角色"这个特概念(包括用户兴趣及兴趣表示).
至此,开始出现了用户模板的雏形,为以后文本过滤模型的研究和实现起了指引作用.
进入90年代,信息过滤技术得到了很大发展,研究方向也更加具体化,主要出现了以下几个方向:信息过滤、信息检索、分类器及语词抽取等.
为了有利于信息过滤的发展,1992年,美国计算机学家Nicholas、J.
Blkin和w.
BmceCroft在著名的CommunicationsoftheACM发表的一篇文章中,对文本信息过滤这一名词进行了明确定义,以此来区分其他领域的研究.
至此,信息过滤技术已经正式成为一门独立的研究内容,在今后的发展过程中将不断完善.
现阶段,敏感信息检测与过滤技术受到了各国的高度重视,在国家的推动下,以敏感信息检测与过滤为目标的应用系统大量出现.
Stanford大学的Take.
Yen和HectorGarcia-Mina开发了基于内容的过滤系统SIFT(StanfordInformationFilteringT001),这个系统,每个用户可以独立建立自己词汇库,并使用向量空间模型和关键字匹配来实现用户需求与网络信息之间的匹配.
美国国家安全局为了更好对恐怖活动、军事威胁等活动进行监控建设了"Echelon"通信监视网络,它通过卫星接收站和间谋卫星,栏截大量电话、传真和电子邮件等个人信息,Echelon也是一个基于敏感关键字检索来获取通信电子通信系统.
英国政府也成立了专门收集情报机构"英国政府技术援助中心",这个监控中心能够截获和收集所用进出英国的所有互联网信息.
在国内,随着敏感信息检测技术的逐渐成熟,一些科研机构、高等院校和公司通过系统化的技术整合研究,也推出了大量的原型系统和商业产品.
如中科天巩公司依托中国科学院计算技术研究所设计开发的天机网络网页关键字监测系统,经过十余年的深入研究,其产品现己推出3.
0以上版本.
北京交通大学2009年1月成立了国内首个网络网页关键字安全研究机构网络网页关键字安全研究中心,现在正全力推进网络网页关键字产生、传播和导控等方向性研究和自主网络舆论安全关键技术的研发.
北京理工大学网络与分布式计算实验室研发了网络网页关键字分析与预警平台.
北京拓尔思(TRS)信息技术股份有限公司研制的TRS网络网页关键字监测系统,系统包括了热点发现和追踪、敏感信息监控和预警、辅助决策支持、全方位信息搜索等功能.
北大方正技术研究院设计幵发了方正智思网页关键字预警辅助决策支持系统,针对离线的网页数据进行网页关键字自动分析和预报,分析规划网页关键字监控内容,形成了一个具有生命特征的周期往复的社情民意反馈系统.
南京大学网络传播中心的网络网页关键字监测与分析实验室与谷尼国际软件(北京)有限公司共同建立了网页关键字研究基地,有关Goonie网页关键字监测分析系统也正在国家性课题——"网络舆论引导能力建设研究"中发挥着重要作用.
此外,还有上海交通大学信息安全工程学院的网络媒体内容监管系统,也取得了不小进展.
1.
3本章小结本章首先简单概述了网页敏感关键词检测技术在当前网络信息多元化与复杂化环境下的研究背景与重大意义.
接着说明了该技术在国内外的研究现状与应用的实际场景.
第二章网页敏感信息检测系统关键技术2.
1网页敏感信息检测系统概述网页敏感信息检测系统主要完成对待检测网页的敏感关键词检测,并对检测出的敏感关键词,标出其在源文件中的位置,将检测结果与检测时间等信息写入敏感关键词检测结果表中.
系统在敏感词检测期间需要驻留内存,通过加载敏感关键词知识库来做敏感关键词的检测.
网页敏感信息检测系统的流程图如下图2.
1所示.
图2.
1网页敏感信息检测系统工作过程的流程图上图为网页敏感信息检测系统的流程图,其敏感词检测具体步骤如下:创建敏感关键词库.
敏感关键词的形式包括:纯英文词条,纯中文词条,数字和英文混合词条,数字和中文混合词条,数字英文中文混合词条,特殊符号与中英文混合词条.
敏感关键词检测系统启动,加载敏感关键词库到内存.
其中敏感关键词按照Tire字典树形式存储.
系统通过目录文件读写子模块读取待检测网页源代码.
系统通过扫描指针读取网页源码中每个字符,使用哈希散列函数将每个字符映射到字典树中进行敏感关键词检测;如果发现敏感关键词,则标记其位置信息,获取敏感关键词的上下文作为该敏感关键词的摘要内容,获取系统当前时间,然后调用关系型数据库读写子模块将其写入敏感关键词检测结果表中.
如果没有发现敏感关键词,则扫描指针调下下一个字符;重复步骤(5),(6),直到扫描指针指向文件结尾.
2.
2敏感关键词库创建敏感关键词库主要用于存储用户感兴趣的敏感关键词词条,是后面进行网页敏感关键词检测的依据.
本系统使用的敏感关键词形式包括:纯英文词条,纯中文词条,数字和英文混合词条,数字和中文混合词条,数字英文中文混合词条,特殊符与中英文混合词条.
其中特殊符号包括:ASCII编码的特殊符号,GBK编码的中文特殊符号.
表2.
2给出了敏感关键词词条的样例如下:表2.
2敏感关键词词条的样例表序号敏感词形式敏感词样例1纯数字89642纯英文词条freegate3纯中文词条天安门事件4数字和英文混合词条64memo5数字和中文混合词条89事件6数字英文中文混合词条89天an门7特殊符与英文混合词条*freegate8特殊符与中文混合词条《八九学潮》2.
3敏感关键词的字典树存储与查找本系统将敏感关键词分为英文和中文两种大形式,使用字典树进行存储.
字典树,即Trie树,又称单词查找树或键树,是一种树形结构,是一种哈希树的变种.
典型应用是用于统计和排序大量的字符串(但不仅限于字符串),经常被搜索引擎系统用于文本词频统计.
它的优点是:最大限度地减少无谓的字符串比较,查询效率比哈希表高.
Trie的核心思想是空间换时间.
利用字符串的公共前缀来降低查询时间的开销以达到提高效率的目的.
它具有3个基本性质:(1)根节点不包含字符,除根节点外的每一个节点都只包含一个字符;(2)从根节点到某一节点,路径上经过的字符连接起来,为该节点对应的字符串;(3)每个节点的所有子节点包含的字符都不相同.
例如,假设有b,abc,abd,bcd,abcd,efg,hii这6个单词,我们构建的字典树就是如下图2.
3所示:图2.
3字典树结构如上图所示,对于每一个节点,从根遍历到他的过程就是一个单词,如果这个节点被标记为红色,就表示这个单词存在,否则不存在.
那么,对于一个单词,我只要顺着他从根走到对应的节点,再看这个节点是否被标记为红色就可以知道它是否出现过了.
把这个节点标记为红色,就相当于插入了这个单词.
这样一来我们查询和插入可以一起完成.
本质上,Trie是一颗存储多个字符串的树.
相邻节点间的边代表一个字符,这样树的每条分支代表一则子串,而树的叶节点则代表完整的字符串.
和普通树不同的地方是,相同的字符串前缀共享同一条分支.
从上图中可以看出:字典树的每条边对应一个字母.
每个节点对应一项前缀,叶节点对应最长前缀,即单词本身.
单词abcd与单词abd有共同的前缀"ab",因此他们共享左边的一条分支,root->a->b.
并且字典树的查询操纵非常简单.
比如要查找abd,顺着路径root->a->b->d就找到了.
搭建Trie的基本算法也很简单,即逐一把每个单词的每个字母插入Trie树.
插入前先看前缀是否存在.
如果存在,就共享,否则创建对应的节点和边.
2.
4敏感关键词检测系统通过文件目录读写子模块加载待检测网页源代码,将扫描指针指向网页代码字符串的首字符.
根据其编码形式判断其为英文字符还是GBK编码的汉字.
如果是英文字符,则通过哈希散列表将其映射到英文敏感词Tire树中相应字符分支节点中,扫描指针向后读入一个字符,通过前缀查找算法查看以该字符为首字符的字符串是否为敏感关键词.
如果是,则记录其位置偏移量,获取上下文摘要,将其写入敏感关键词检测结果表中.
如果不是,则扫描指针前进一个字符,继续上面的操作.
与英文敏感关键词检测方法类似,中文敏感感觉词检测中,扫描指针每次读入两个字符,并通过中文敏感词Tire树进行前缀查找.
如果是,则记录其位置偏移量,获取上下文摘要,将其写入敏感关键词检测结果表中.
如果不是,则扫描指针前进两个字符,继续上面的操作.
2.
5本章小结本章详细介绍了网页敏感信息检测系统的运行流程与敏感关键词检测过程.
重点说明了敏感关键词的形式,敏感关键词库在内存中的字典树存储形式,及英文敏感词条、中文敏感词条的检测流程.
第三章系统设计与实现3.
1需求分析(1)功能性需求网页敏感信息检测系统主要完成对待检测网页的敏感关键词检测,并对检测出的敏感关键词,标出其在源文件中的位置,将检测结果,敏感关键词的上下文摘要信息,检测时间等信息写入敏感关键词检测结果表中.
系统在敏感词检测期间需要驻留内存,通过加载敏感关键词知识库来做敏感关键词的检测.
(2)非功能性需求对于网页源码中任意位置的敏感关键词都能够准确检测.
敏感关键词的形式包括:纯英文词条,纯中文词条,数字和英文混合词条,数字和中文混合词条,数字英文中文混合词条,特殊符号与中英文混合词条.
敏感关键词库数量在9000以上,敏感关键词库加载速度不超过100ms.
网页源码大小在1MB以内的网页检测速度不超过100ms.
3.
2主要模块设计与实现3.
2.
1模块的总体结构与输入输出网页敏感信息检测系统的总体结构如下图3.
2.
1所示:表3.
2.
1输入项参数表系统的输入与输出参数表如下所示:表3.
2.
1a输出项参数表输入项名称标识数据类型数值范围输入方式/数量/频率输入媒体输入来源安全保密条件网页源代码Web_SrcString非空字符串内存读取目录文件读写子模块敏感关键词库SensKey散列表内存读取关系型数据库读子模块表3.
2.
1b输出项参数表输出项名称标识数据类型数值范围输出方式/数量/频率输出媒体输出图形安全保密条件敏感关键词SenstiveKeyString非空字符串输出到数据库敏感关键词检测结果表偏移位置off_positionString非空字符串输出到数据库敏感关键词检测结果表待检测网页URLURLString非空字符串输出到数据库敏感关键词检测结果表检测时间DetectTimeData_timeyy-mm-dd00:00:00输出到数据库敏感关键词检测结果表操作状态ExcuteStateBoolTrue:执行成功;False:失败输出到log日志3.
2.
2目录文件读写子模块该模块实现对用户选择的特定目录中网页源代码进行读取,并一次性将其加载到内存.
其实现的关键代码如下:structdirent*ptr;DIR*dir;dir=opendir(filepath);if(dir==NULL){coutd_name[0]=='.
')continue;charfilename[256]带路径的文件名stringsrc="";sprintf(filename,"%s%s",filepath,ptr->d_name)charfname[256]sprintf(fname,"%s",ptr->d_name);printf("%s\n",filename);ifstreaminf(filename);if(!
inf.
is_open()){coutresult;result.
clear();ostringstreamtmp;一次读取整个文件内容tmpm_sWord=m_Database1.
m_vResult[i][1];KwdUnTmp->m_kind=m_Database1.
m_vResult[i][2];KwdUnTmp->m_uWordID=CountNum+1;unsignedcharIdxx,Idxy;if(KwdUnTmp->m_sWord.
size()m_sWord[0]&0x80){Idxx=KwdUnTmp->m_sWord[0]-0x81;Idxy=KwdUnTmp->m_sWord[1]-0x40;if(Idxxendnode=KwdUnTmp;}else{m_lChSegDic[Idxx][Idxy]->endnode->next=KwdUnTmp;m_lChSegDic[Idxx][Idxy]->endnode=KwdUnTmp;}CountNum++;}else{i++;deleteKwdUnTmp;continue;}}else{Idxx=KwdUnTmp->m_sWord[0];if(m_lAscSegDic[Idxx]==0){m_lAscSegDic[Idxx]=KwdUnTmp;KwdUnTmp->endnode=KwdUnTmp;}else{m_lAscSegDic[Idxx]->endnode->next=KwdUnTmp;m_lAscSegDic[Idxx]->endnode=KwdUnTmp;}CountNum++;}i++;}m_uCountWordNum=CountNum;returntrue;}3.
2.
4敏感关键词检测过程敏感关键词检测过程就是利用字典树进行前缀查找的过程.
Trie树是简单但实用的数据结构,通常用于实现字典查询.
我们做即时响应用户输入的AJAX搜索框时,就是Trie开始.
本质上,Trie是一颗存储多个字符串的树.
相邻节点间的边代表一个字符,这样树的每条分支代表一则子串,而树的叶节点则代表完整的字符串.
在敏感关键词检测过程中,扫描指针首先读入一个字符,根据其内部编码特征判断其是中文字符还是英文字符.
如果是英文字符,则通过哈希散列表将其映射到英文敏感词Tire树中相应字符分支节点中,扫描指针向后读入一个字符,通过前缀查找算法查看以该字符为首字符的字符串是否为敏感关键词.
如果是,则记录其位置偏移量,获取上下文摘要,将其写入敏感关键词检测结果表中.
如果不是,则扫描指针前进一个字符,继续上面的操作.
与英文敏感关键词检测方法类似,中文敏感感觉词检测中,扫描指针每次读入两个字符,并通过中文敏感词Tire树进行前缀查找.
如果是,则记录其位置偏移量,获取上下文摘要,将其写入敏感关键词检测结果表中.
如果不是,则扫描指针前进两个字符,继续上面的操作.
敏感关键词检测的关键代码如下所示:vectorBayesEngine::Pross01(string&CkRes){vectorresult;result.
clear();cout126||Idy>191)StrPos+=2;ListKwdU=0;continue;elseListKwdU=CurrentDic->m_lChSegDic[Idx][Idy];elseIdy=*(StrPos);ListKwdU=CurrentDic->m_lAscSegDic[Idy];while(ListKwdU)//liynotgetendeverytimeintCmpValue=strncmp(ListKwdU->m_sWord.
c_str(),StrPos,ListKwdU->m_sWord.
size());if(CmpValuenext;continue;elseif(!
CmpValue)ListKwdResult=ListKwdU;ListKwdU=ListKwdU->next;continue;break;if(ListKwdResult&&ListKwdResult->m_sWord.
size())staticintGb2312ToUtf8(char*sOut,intiMaxOutLen,constchar*sIn,intiInLen)charoutwd[90]="";char*out=outwd;Gb2312ToUtf8(out,sizeof(outwd),ListKwdResult->m_sWord.
c_str(),ListKwdResult->m_sWord.
size());charoffset[128]="";unsignedintst_off=StrPos-StrStart;unsignedinted_off=st_off+ListKwdResult->m_sWord.
size()-1;detRetret(ListKwdResult->m_sWord,st_off,ed_off);result.
push_back(ret);sprintf(offset,"%d-%d",st_off,ed_off);coutm_sWord=0)index=st_off-step;intleng=2*step+ListKwdResult->m_sWord.
size();stringabstract=CkRes.
substr(index,leng);coutm_sWord.
size();elseif(*StrPos&0x80)StrPos+=2;elsewhile((StrPos-StrStart
3所示:表3.
3网页敏感信息检测系统的实验软硬件配置表系统名称MDSS海量数据存储管理系统网页分析子系统CPU2x4核2x4核IntelxeonE5-2690V23.
0GHZ内存128G128G128G硬盘2x1T的SSD、2x4T的SATA4x4T的SATA4x4T的SATA操作系统CentOS6.
3CentOS6.
3CentOS6.
33.
4实验结果(1)敏感关键词库为了充分测试该检测系统的准确率与及时性,我们建立了包含9000个敏感关键词的词库,词库中包括前面所涉及到的敏感关键词形式.
图3.
4.
1为该敏感关键词库的部分敏感词内容.
图3.
4.
1敏感关键词库部分敏感词截图(2)对网页进行敏感关键词检测待检测网页的源文件部分截图如下图3.
4.
2a所示.
从下图可以看出在文本内容中存在敏感关键词.
例如:第126行的"自由之门","《中国民主》"等信息.
图3.
4.
2a含有敏感关键词信息的网页源代码截图运行网页敏感关键词检测后的检测结果表入图3.
4.
2b所示.
从图中可以看出从该网页中共检测出9出敏感关键词,具体内容为列"skey"所示,并在列"abstract"中给出了该敏感关键词的上下文摘要,方便网站管理人员查看.
从下图中可以看出检测出的敏感关键词形式包括:纯英文词条,纯中文词条,数字和英文混合词条,数字和中文混合词条,数字英文中文混合词条,特殊符与中英文混合词条.
图3.
4.
2b网页敏感关键词检测结果(3)对检测出的敏感关键词的展示系统根据敏感关键词的位置信息,将其在网页源代码中进行标注.
例如,系统将网页中出现的敏感关键词进行红色标注,并展示在web浏览器中.
图3.
4.
3为对上面网页中敏感关键词进行标注后再web浏览器上的展示界面.
从图中可以看出,上面检测到的敏感关键词在web界面上已经标红.
这样方便网站管理人员查看敏感关键词在网页上直接查看敏感关键词信息.
图3.
4.
3网页敏感关键词信息标注3.
5本章小结本章在第一章和第二章的基础上,对网页敏感信息检测系统做了具体的设计与实现,并搭建具体的实验环境对该检测系统进行了实际测试.
通过测试结果显示:该系统可以准确的检测出网页源文件中的敏感关键词,敏感词位置及上下文摘要等具体信息,并在实际的页面中将检测出的敏感关键词进行了标注,具有较好的实用性.
蓝速数据(58/年)秒杀服务器独立1核2G 1M
蓝速数据金秋上云季2G58/年怎么样?蓝速数据物理机拼团0元购劲爆?蓝速数据服务器秒杀爆产品好不好?蓝速数据是广州五联科技信息有限公司旗下品牌云计算平台、采用国内首选Zkeys公有云建设多种开通方式、具有IDC、ISP从业资格证IDC运营商新老用户值得信赖的商家。我司主要从事内地的枣庄、宿迁、深圳、绍兴、成都(市、县)。待开放地区:北京、广州、十堰、西安、镇江(市、县)。等地区数据中心业务,均KV...
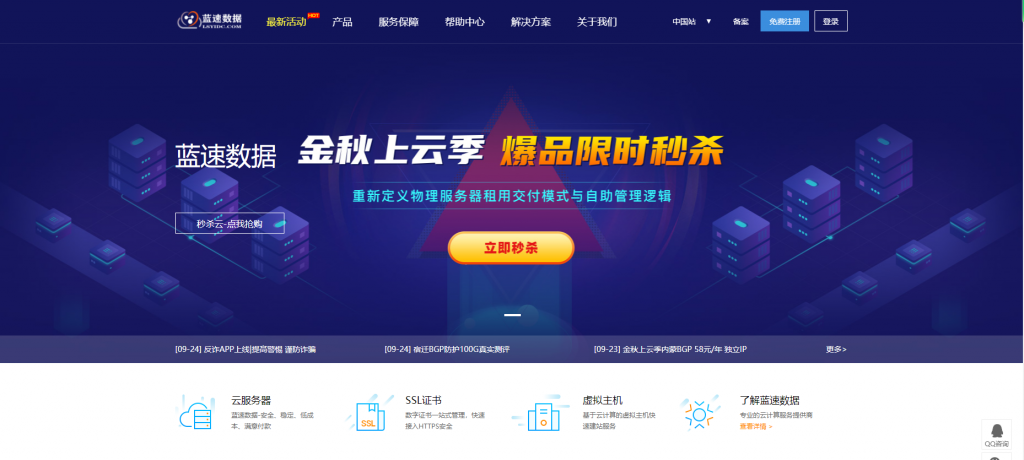
FBICDN,0.1元解决伪墙/假墙攻击,超500 Gbps DDos 防御,每天免费流量高达100G,免费高防网站加速服务
最近很多网站都遭受到了伪墙/假墙攻击,导致网站流量大跌,间歇性打不开网站。这是一种新型的攻击方式,攻击者利用GWF规则漏洞,使用国内服务器绑定host的方式来触发GWF的自动过滤机制,造成GWF暂时性屏蔽你的网站和服务器IP(大概15分钟左右),使你的网站在国内无法打开,如果攻击请求不断,那么你的网站就会是一个一直无法正常访问的状态。常规解决办法:1,快速备案后使用国内服务器,2,使用国内免备案服...
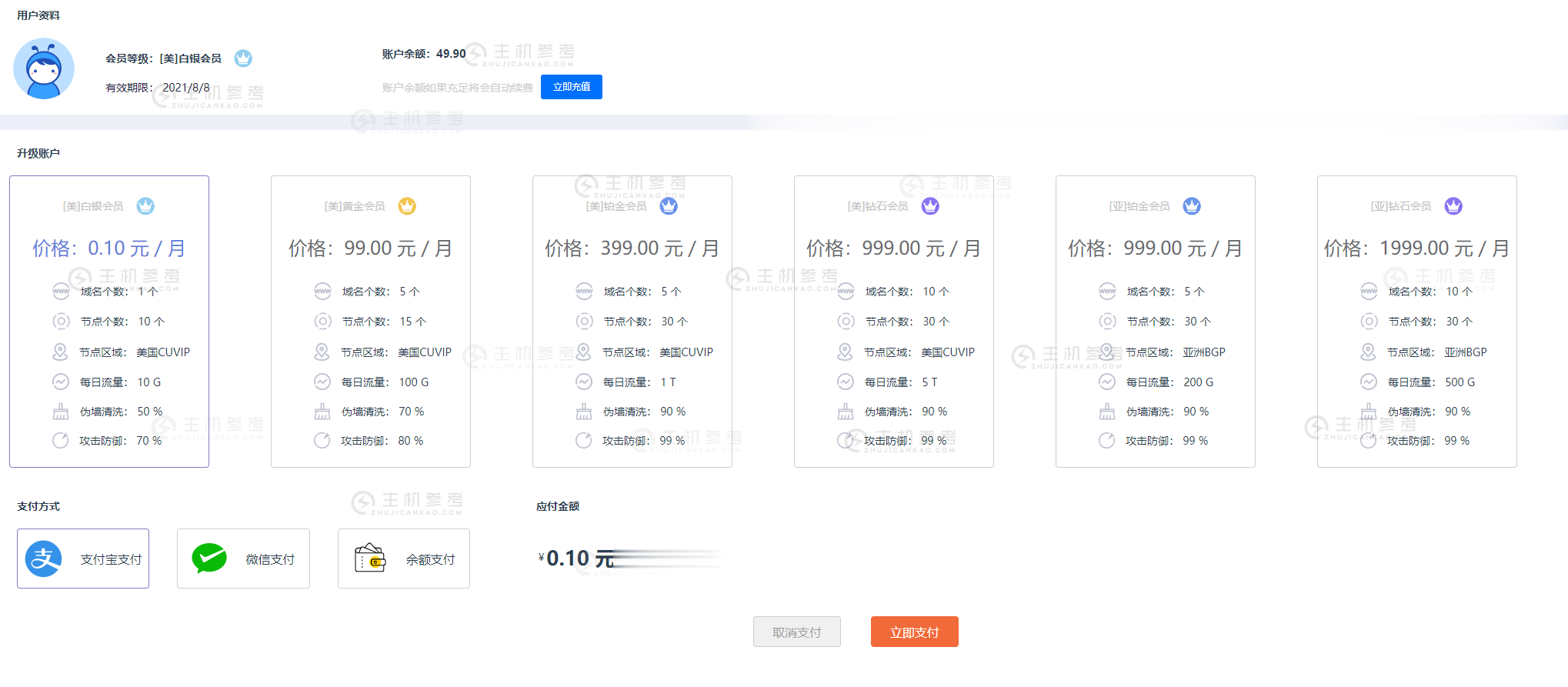
菠萝云:带宽广州移动大带宽云广州云:广州移动8折优惠,月付39元
菠萝云国人商家,今天分享一下菠萝云的广州移动机房的套餐,广州移动机房分为NAT套餐和VDS套餐,NAT就是只给端口,共享IP,VDS有自己的独立IP,可做站,商家给的带宽起步为200M,最高给到800M,目前有一个8折的优惠,另外VDS有一个下单立减100元的活动,有需要的朋友可以看看。菠萝云优惠套餐:广州移动NAT套餐,开放100个TCP+UDP固定端口,共享IP,8折优惠码:gzydnat-8...
-
present37支持ipad支持ipad支持ipad支持ipad支持ipad国家标准苹果5netbios端口netbios ssn是什么意思?x-router设置路由器是我的上网设置是x怎么弄canvas2Canvas ~セピア色のモチーフ~ 这个动画片的中文翻译是什么?从哪看?